- The paper's main contribution is the introduction of an agentic multimodal search framework that scales to long-horizon interactions using externalized UID management.
- It employs a novel file-based system to store visual assets, reducing token costs while ensuring persistent evidence retrieval through lightweight textual identifiers.
- Empirical results on established benchmarks demonstrate significant performance improvements, confirming the benefits of decoupling reasoning from heavy visual perception.
Towards Long-horizon Agentic Multimodal Search: An In-depth Analysis of LMM-Searcher
Introduction and Motivation
LMM-Searcher introduces a novel agentic framework for long-horizon multimodal deep search with a primary objective: to efficiently manage and reason over heterogeneous (textual and visual) information spanning 100 or more interaction turns. The crucial bottleneck being addressed is the context explosion generated by high token costs when naively serializing images and long textual histories into the agent's context window. Existing context management, predominantly text-based, is insufficient for the fundamentally distinct data properties of multimodal content, especially in scenarios that require multi-hop, multi-turn, cross-modal reasoning and persistent access to visual signals.
File-based Multimodal Context Representation and Tool Interface
LMM-Searcher’s principal innovation is its externalized visual asset management. All visual information encountered during search is persistently stored outside the context in a file system and mapped via lightweight, unique textual identifiers (UIDs). Rather than embedding visual tokens directly in context, all previously encountered visual assets are referenced using UIDs, allowing the agent to remember all past evidence at negligible context cost, with precise semantics retained for future on-demand retrieval.
This is enabled by a set of agentic tools operating on UIDs:
- Search tools support conventional, image-based, and visual similarity-based search, returning results always as compressed references (UIDs).
- Browse tools include a
scrape_website function for extracting structured text and image references and a critical fetch_image tool that loads raw images only when detailed perception is required.
- Visual processing tools like
zoom_in enable the agent to actively refine its perception by extracting and inspecting regions of interest within stored images through new UID assignments.
This decoupling of reasoning (UID tracking as low-overhead semantic pointers) from heavy-weight perception (on-demand, progressive visual loading) provides strong context scaling properties and guarantees against information loss through the entire search horizon.
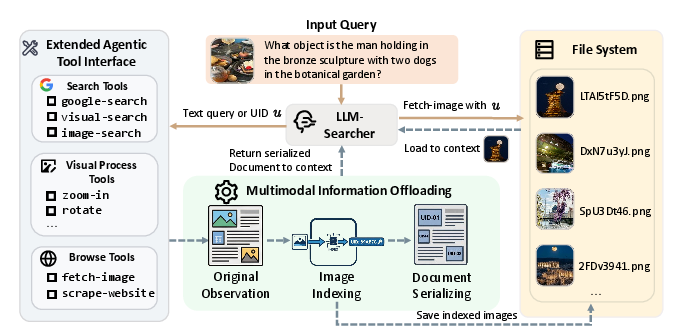
Figure 1: A high-level functional illustration of the LMM-Searcher file-based representation and tool interface workflow.
Automated Multimodal Data Synthesis Pipeline
A robust agentic framework requires intricate, high-quality supervision. To stimulate long-horizon, cross-modal reasoning, the authors introduce a sophisticated VQA-centric data synthesis pipeline:
- Multimodal webpages are parsed to extract entity-image pairs, and MLLMs are prompted to generate visual questions unanswerable by text alone, necessitating fine-grained visual inspection.
- To scale and enhance task complexity, the pipeline constructs multi-hop knowledge graphs, expanding from core entities through attributes and obfuscating nodes to compel multi-stage evidence accumulation.
- The resulting queries and reasoning chains drive the collection of agent trajectories, further filtered using strong open-source models and rejection sampling for quality assurance.
Empirically, the synthesized dataset features significantly longer average trajectory lengths and greater frequency/diversity of vision-intensive tool calls compared to existing datasets.
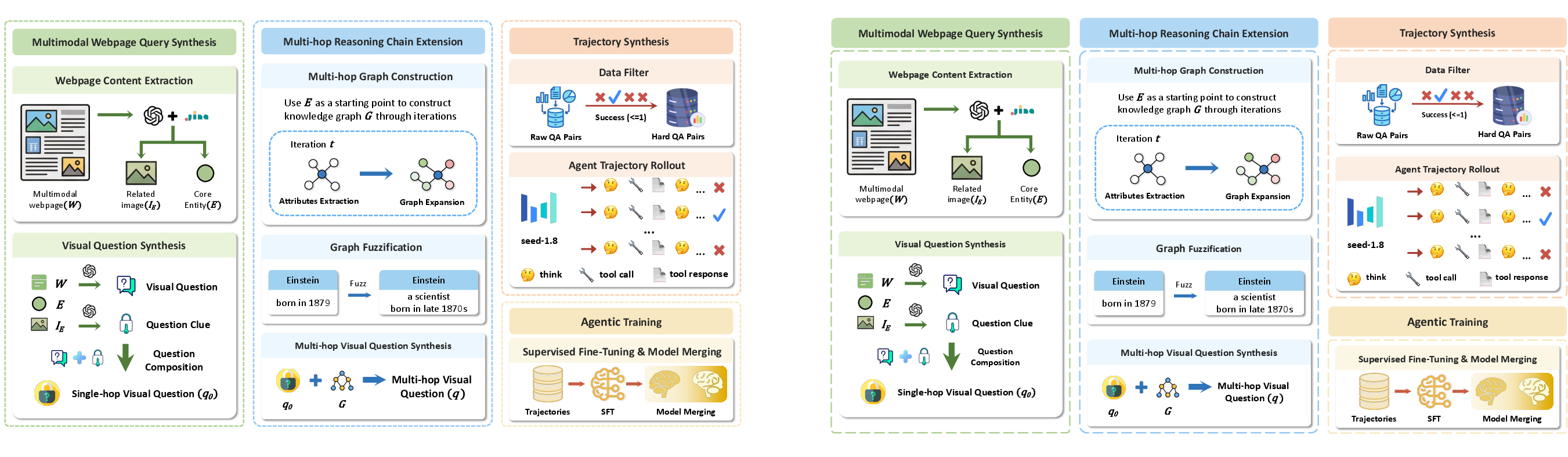
Figure 3: Overview of the automated VQA data synthesis pipeline generating deep search queries and trajectories.
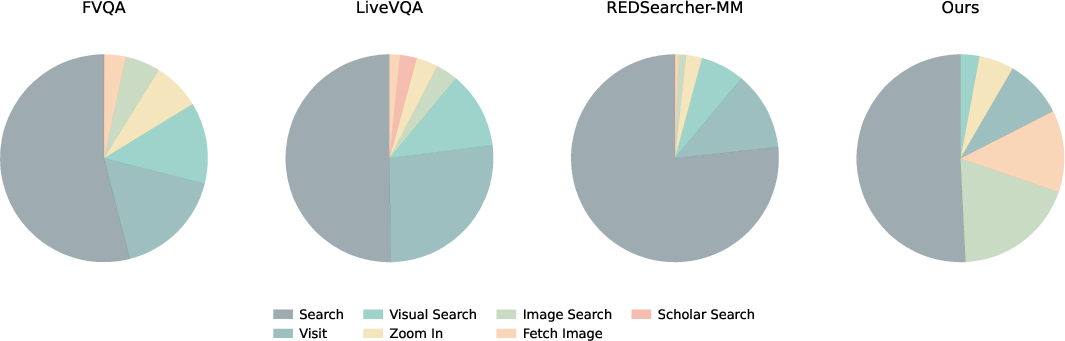
Figure 2: Tool call distribution in the synthesized dataset, demonstrating an increased demand for vision-centric interactions.
Model Architecture and Training
The authors fine-tune Qwen3-VL-Thinking-30A3B using 12,736 high-complexity agentic search trajectories, masking tool responses to optimize exclusively for reasoning and tool invocation. To enhance language-centric scaling, the model is subsequently merged, via parameter interpolation (α=0.8), with MiroThinker-1.7-mini, inheriting large-scale language-based search capabilities. This hybridization is crucial for generalizing beyond the relatively modest size of multimodal datasets and is empirically justified by substantial improvements in scaling behavior.
Experimental Evaluation and Results
Experiments are conducted on four multimodal search benchmarks, including MM-BrowseComp and MMSearch-Plus. Results indicate:
- Direct parametric models show consistently inferior performance (e.g., 10.1 on MM-BrowseComp) versus agentic search-capable models.
- LMM-Searcher-30B, with file-based context and full tool suite, achieves state-of-the-art results among open-source models: 22.3 (MM-BrowseComp) and 32.9 (MMSearch-Plus) for 30-turn interaction limits, further improved to 30.1 and 34.8, respectively, when scaling to 100 turns with aggressive context management.
- Context offloading (via UIDs and progressive fetch) enables robust performance even in 100-turn regimes, preserving critical signals and ensuring scalable interaction without significant performance degradation.
- Tool ablation studies demonstrate that removing the
fetch_image capability results in substantial performance drops for tasks requiring intensive visual evidence accumulation (e.g., -9.5 on VisBrowse), confirming the necessity of on-demand, persistent visual retrieval.
- Data ablations reveal that while open-source visual queries boost baseline performance, the synthesized multi-hop queries described herein are essential for further gains on true long-horizon, multi-modal benchmarks.
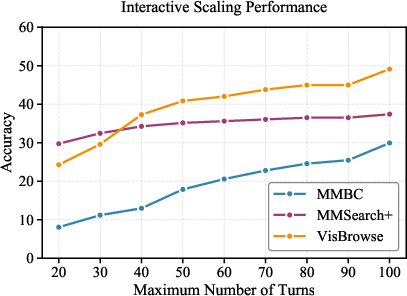
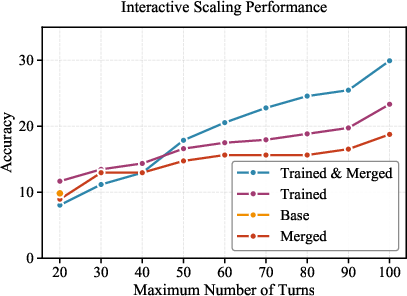
Figure 4: Scaling results displaying robust performance retention and improvement as the number of search turns is increased—highlighting the long-horizon generalization capacity of LMM-Searcher.
Practical, Theoretical Implications and Future Trajectories
Practically, this paradigm directly extends the feasible scope of agentic multimodal search to complex, real-world, multi-document, and multi-hop settings, previously bottlenecked by token limitations. It enables AI agents to support information synthesis tasks analogous to human research with persistent evidence tracking across dozens to hundreds of steps and offers a roadmap for robust context management in other domains with heavy non-linguistic signals (e.g., video, audio, code).
Theoretically, this approach demonstrates the power of decoupling perception from reasoning at the context representation level—a principle likely applicable to future models handling even larger, more heterogeneous data modalities and action spaces. The explicit UID pointer mechanism is, in principle, extensible to other resource types (files, videos, database records), offering a unifying abstraction for scalable cognitive architectures.
The authors highlight potential for advancing model merging strategies, integrating more sophisticated memory and caching policies, and developing more diverse data synthesis pipelines to cover under-explored multimodal reasoning skills.
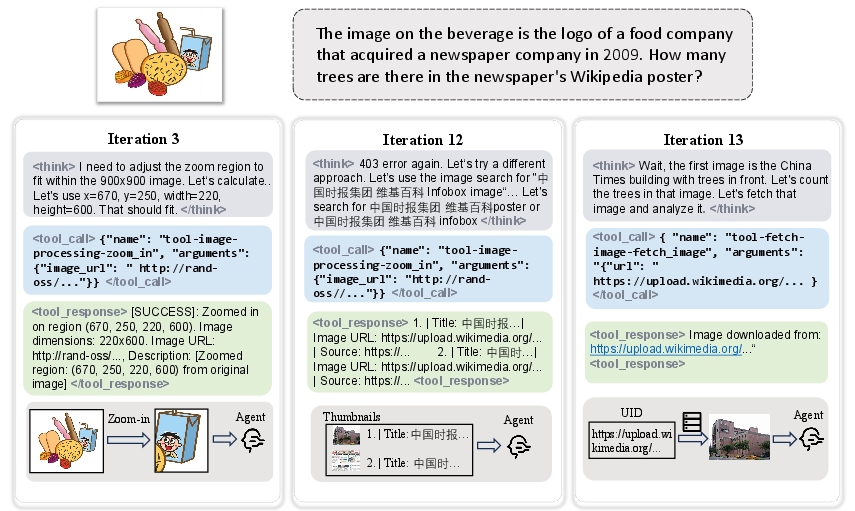
Figure 5: Detailed depiction of the agent’s trajectory and dynamic visual evidence loading across search steps.
Conclusion
LMM-Searcher presents a compelling solution to the limitations of current multimodal search agents in long-horizon, high-operational-complexity settings by externalizing and abstracting multimodal context through file-based UID management and agentic tool chains. The approach yields strong empirical gains through both architectural and data-centric innovations, validated via extensive benchmark evaluation. The framework lays essential groundwork for developing scalable, robust, and generalizable multimodal agents for real-world research and evidence synthesis tasks.