EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Abstract: Video understanding with multimodal LLMs (MLLMs) remains challenging due to the long token sequences of videos, which contain extensive temporal dependencies and redundant frames. Existing approaches typically treat MLLMs as passive recognizers, processing entire videos or uniformly sampled frames without adaptive reasoning. Recent agent-based methods introduce external tools, yet still depend on manually designed workflows and perception-first strategies, resulting in inefficiency on long videos. We present EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agent, which enables planning-before-perception through iterative summary-plan-action-reflection reasoning. EVA autonomously decides what to watch, when to watch, and how to watch, achieving query-driven and efficient video understanding. To train such agents, we design a simple yet effective three-stage learning pipeline - comprising supervised fine-tuning (SFT), Kahneman-Tversky Optimization (KTO), and Generalized Reward Policy Optimization (GRPO) - that bridges supervised imitation and reinforcement learning. We further construct high-quality datasets for each stage, supporting stable and reproducible training. We evaluate EVA on six video understanding benchmarks, demonstrating its comprehensive capabilities. Compared with existing baselines, EVA achieves a substantial improvement of 6-12% over general MLLM baselines and a further 1-3% gain over prior adaptive agent methods. Our code and model are available at https://github.com/wangruohui/EfficientVideoAgent.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
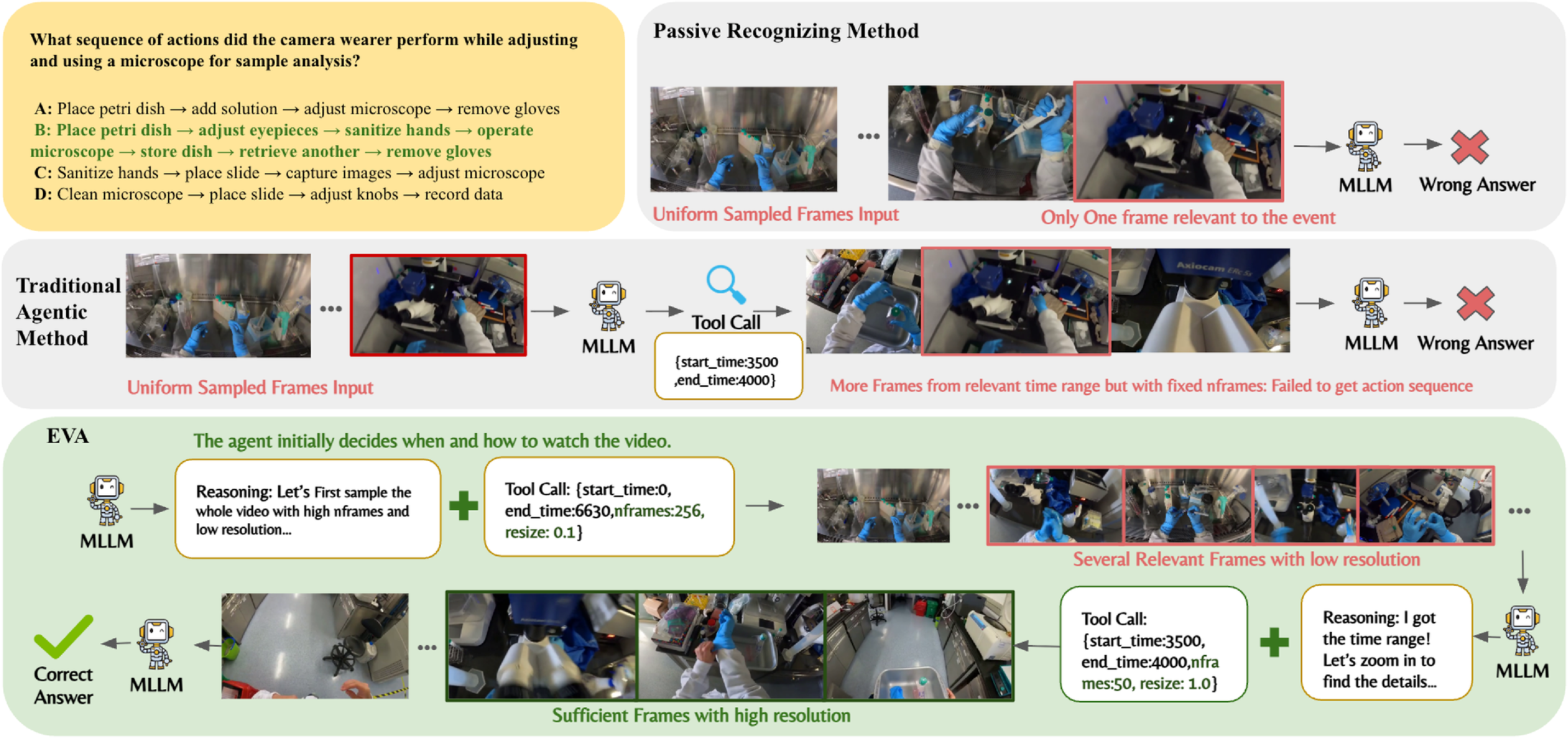
This paper introduces EVA, a smart “video-watching” AI agent that doesn’t just passively look at every frame of a video. Instead, it plans first, then decides what parts to watch, when to watch them, and at what quality. The goal is to answer questions about very long videos quickly and accurately, without wasting time on unimportant parts.
What questions did the researchers ask?
The researchers focused on three big questions, explained in simple terms:
- Can an AI learn to “skim” a long video and then zoom in on important moments to answer a question?
- Can it plan before it looks—deciding what to watch based only on the question—and then adjust as it learns more?
- Can it do all this efficiently (using fewer “tokens,” or small chunks of information) while still being accurate?
How did they do it?
EVA is built as an “agent” that works in a loop:
- It starts with the question and makes a plan.
- It chooses what part of the video to watch and how (for example: short clip vs. long clip, low vs. high resolution).
- It watches, reflects on what it learned, and decides what to do next.
- It repeats until it has enough evidence to answer.
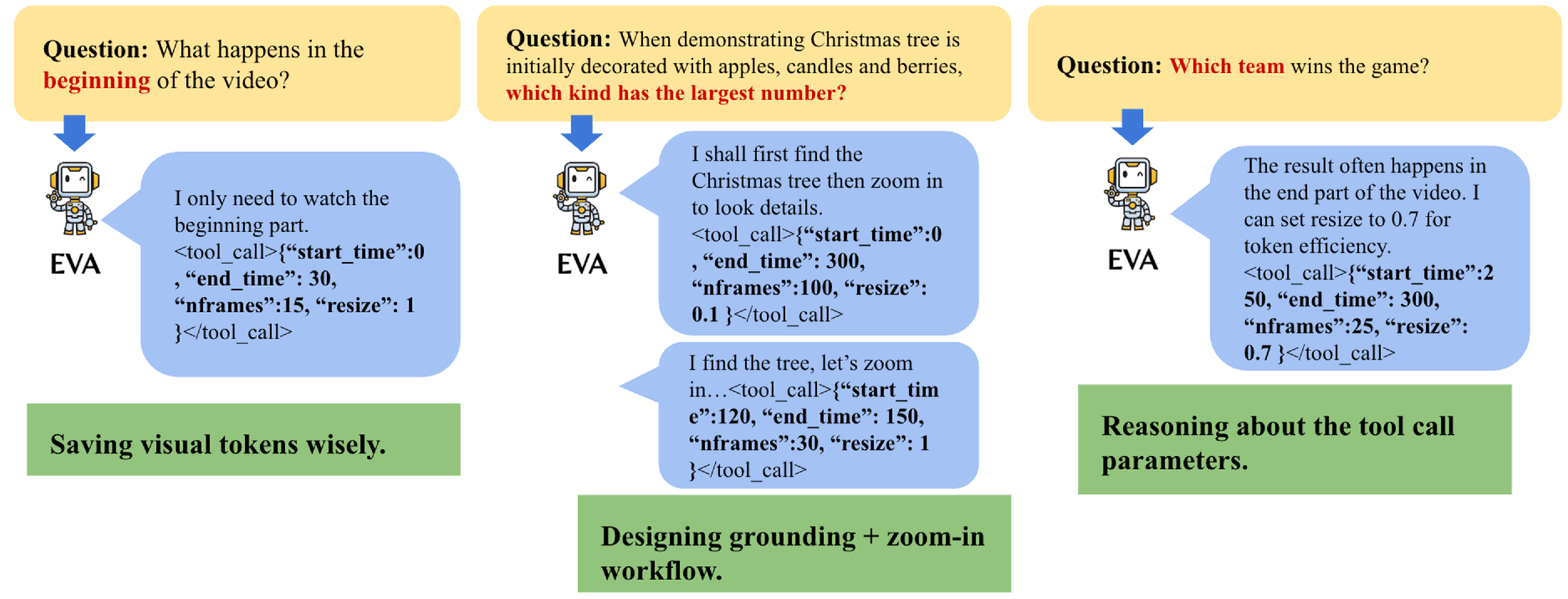
Think of it like how you’d handle a 2-hour video when you only need to answer one question: first skim quickly to find the right section, then rewatch that part carefully in high quality.
The “tool” EVA uses
EVA has a flexible video-sampling tool it can call with settings like:
- start_time and end_time (when in the video to look)
- nframes (how many frames to sample)
- resize (how sharp or blurry the frames should be)
This lets EVA first get a fast, low-res overview and then zoom in with more frames and higher resolution where it matters.
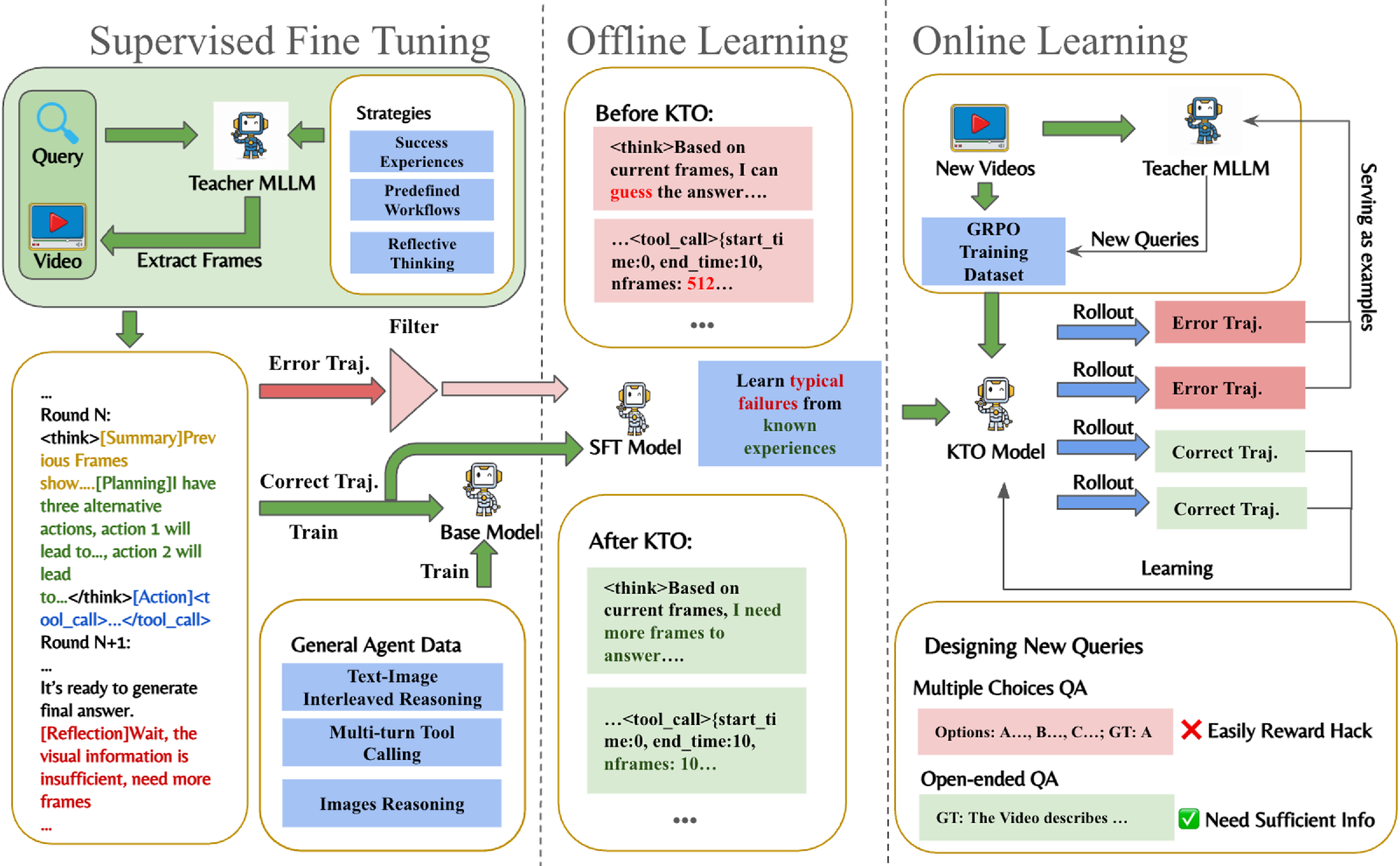
How EVA was trained (3 stages)
The team trained EVA in three steps so it could plan, watch, and learn like a skilled problem-solver.
Stage 1: Supervised Fine-Tuning (SFT)
- Like learning by example.
- A larger “teacher” model shows EVA how to:
- Write plans,
- Call the tool properly,
- Describe frames,
- Decide whether it has enough evidence to answer or should look more.
Stage 2: KTO (Kahneman–Tversky Optimization)
- Like learning from common mistakes.
- EVA studies both good and bad strategies (for example: guessing without enough evidence, or sampling too many/too few frames).
- This helps it avoid wasteful or risky behavior.
Stage 3: GRPO (Generalized Reward Policy Optimization)
- Like practice with a score.
- EVA tries different strategies and gets rewarded for correct, well-supported answers.
- For multiple-choice questions, it only gets full credit if it both picks the right answer and clearly used the right frames.
- For open-ended answers, it earns points based on how closely its answer matches the correct one (measured by text overlap scores like ROUGE).
The team also built three high-quality datasets for these stages (EVA-SFT, EVA-KTO, and EVA-RL) so the training is stable and reproducible.
What did they find?
EVA was tested on six video benchmarks, including ones with very long videos. The main takeaways:
- It’s more accurate: EVA improved scores by about 6–12% over regular multimodal models and by 1–3% over other “agent” methods.
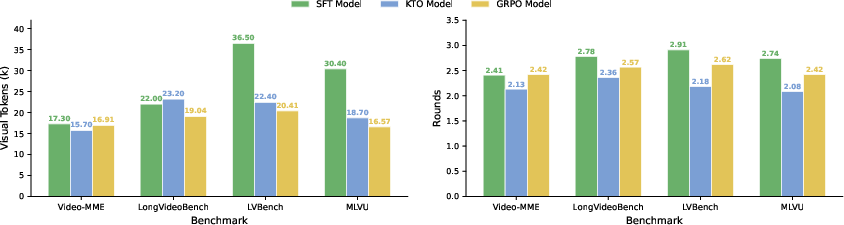
- It’s more efficient: Instead of watching tons of frames, EVA uses far fewer visual tokens by smartly choosing when and how to watch.
- It works well on long videos: EVA is especially strong when the video is very long, where uniform sampling (just grabbing frames evenly) often misses key moments.
- It generalizes: Even without special training for certain tests (zero-shot), EVA performed competitively on a challenging reasoning benchmark (Video-Holmes).
Why this matters: EVA shows that “planning before looking” beats “look at everything and hope for the best,” especially when videos are long and time is limited.
Why is this important?
- Smarter, faster assistants: EVA could help summarize lectures, analyze sports games, or spot key events in security footage much faster.
- Less compute, more impact: By watching fewer, better-chosen frames, it saves time and computing power.
- More human-like strategy: EVA acts more like a thoughtful student—skimming, focusing, and double-checking—rather than a brute-force machine.
- A step toward autonomous agents: This planning–action–reflection loop could be useful beyond videos, in any task where selective attention and efficient reasoning matter.
Simple caveat: EVA still relies on the tools and data it’s given, and very unusual or noisy questions can still be hard. Future work will explore more flexible tools and memory, so the agent can adapt even better over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of the key uncertainties and unexplored areas that remain after this work.
- Generalization beyond predefined tools: EVA relies on a fixed frame-selection API (
start_time,end_time,nframes,resize). It is unclear how policies transfer to unseen or richer tool ecosystems (e.g., ROI cropping, multi-crop, object tracking, optical flow, ASR) or how to automatically discover/adapt to new tool interfaces. - Missing modalities: The agent only reasons over frames; audio, subtitles/ASR, and motion cues (e.g., optical flow) are not integrated. It is unknown how incorporating these signals affects planning and accuracy for audio-dependent or fine-grained motion tasks.
- No explicit budget-aware objective: The RL rewards optimize answer quality but do not penalize visual-token usage or latency directly. How to design and tune budget-sensitive rewards (e.g., cost per frame, per round, or wall-clock) to produce controllable efficiency–accuracy trade-offs remains open.
- Reward reliability and bias:
- Open-ended rewards use ROUGE, which favors lexical overlap and may not reflect semantic correctness or grounding.
- The CSV reward uses the same base model as the judge, risking bias and overfitting to the judge’s preferences.
- How to build robust, calibrated, and independent reward models (or human-in-the-loop signals) for both factuality and grounding remains unresolved.
- Reward hacking and hallucination: While the paper notes reward hacking, there is no formal assessment or automatic detection of unsupported answers. Systematic metrics and training-time safeguards against hallucinations and ungrounded reasoning are needed.
- Data quality and leakage risk: Large portions of SFT/KTO/RL data are generated by an MLLM teacher. The extent of teacher hallucinations, label noise, and potential benchmark overlap (train–test leakage) is not quantified. Robust deduplication, data audits, and error analyses are lacking.
- Scalability to very long or streaming video: Although EVA handles long videos, there is no evaluation on hours-long or live-stream settings, nor a streaming memory mechanism for continual processing. How to maintain performance with bounded memory and online updates is an open question.
- Efficiency reporting: Token counts are estimated (e.g., “650 tokens per frame”), but actual wall-clock latency, FLOPs, memory, and encoder reuse/caching are not measured. A standardized, end-to-end efficiency evaluation is missing.
- Stopping policy and uncertainty: The reflection step lacks a principled stopping rule or confidence calibration. How to decide when to answer versus continue exploration under uncertainty (and budget constraints) requires investigation.
- Robustness to noise and tool failures: Sensitivity to compression artifacts, timestamp misalignment, dropped frames, or faulty tool outputs is not studied. Failure-mode analysis and robustness benchmarks are needed.
- Comparative ablations: The paper does not isolate the contribution of individual tool knobs (
nframesvsresize) or rigorously compare planning-before-perception against perception-first baselines under matched token/latency budgets. - Task coverage: Evaluation focuses on QA. Transfer to tasks requiring temporal grounding, dense captioning, summarization, action segmentation, or spatiotemporal detection remains untested.
- Grounding metrics: There is no direct evaluation of whether selected frames genuinely support answers (e.g., temporal localization precision/recall, grounding fidelity). Developing and reporting grounding-specific metrics would enable better diagnosis.
- Stability and sensitivity: The impact of key RL hyperparameters (e.g., KL coefficient, rollout count), initialization, and random seeds on convergence and final performance is not reported. Stability across runs and ablation of KTO vs alternative preference/RL methods remain open.
- Model/backbone generality: Experiments use a single base model (Qwen2.5-VL-7B). How EVA’s policy and training pipeline transfer across model sizes and families (and whether larger vision encoders reduce reliance on tools) is not explored.
- Dataset availability and reproducibility: While code/model are linked, it is unclear whether EVA-SFT/KTO/RL datasets (including teacher prompts/trajectories) will be released with licensing, curation, and deduplication details necessary for reproducibility.
- Compute requirements: Training uses substantial resources (e.g., 32×H100 with multiple rollouts). Strategies for low-resource training, sample efficiency, and cost–performance trade-offs are not examined.
- Action space limitations: EVA cannot explicitly crop regions, track entities across time, or request specialized analyses (OCR, face/pose tracking). Assessing the marginal gains of expanding the action space is an open design question.
Practical Applications
Immediate Applications
These applications can be prototyped or deployed with current capabilities (planning-before-perception, adjustable frame/time/resolution tool calls, and the SFT–KTO–GRPO training pipeline) while keeping a human-in-the-loop for high-stakes use.
Media, Software, and Content Workflows
- Video QA and navigation assistant for editors and analysts
- Sector: Media production, sports, advertising, UX research
- What it does: Ask free-form questions (“When does player 12 score?”, “Find all wide shots of the skyline”) over long footage; EVA scans at low-res/high-fps for an overview, then zooms into relevant segments with higher resolution and fps, returning precise timestamps and evidence frames.
- Tools/products/workflows: NLE plug‑ins (Premiere/Final Cut/DaVinci), searchable “video QA” API with evidence-linked answers, highlight-reel pre-cuts, timeline auto-annotations.
- Assumptions/dependencies: GPU-backed inference; access to frame extraction/transcoding APIs; acceptance of ~55–68% benchmark accuracy implies human verification for critical edits.
- Efficient lecture and tutorial indexing
- Sector: Education, corporate L&D
- What it does: Answer “Where is backprop explained?” or “Show the moment the code demo fails,” creating study bookmarks and summaries across multi-hour lectures.
- Tools/products/workflows: LMS integration; study-guide generator that logs evidence frames and timestamps; instructor dashboard for Q&A gaps.
- Assumptions/dependencies: Access to long-form lecture recordings; domain adaptation for technical content.
- Screen-recording and bug triage assistant
- Sector: Software engineering, QA
- What it does: Locate “first error dialog,” “when did FPS drop below 30,” or “where was the misclick,” over hours of test videos.
- Tools/products/workflows: CI pipeline hook; Jira/GitHub bot that attaches evidence frames and steps; build gate for regression detection.
- Assumptions/dependencies: Screen capture quality; custom prompts/rewards for domain metrics (e.g., OCR checks).
Security, Retail, and Industrial Operations
- Post-hoc incident search on CCTV and dashcams
- Sector: Security, insurance, transportation
- What it does: Query “any person entering emergency exit,” “vehicle lane change without signal,” or “pedestrian near crosswalk at night” and retrieve evidence without scanning every frame.
- Tools/products/workflows: VMS plug‑in for query-driven triage; insurer dashboard for crash forensics; FOIA/claims pre-screening packs with evidence frames.
- Assumptions/dependencies: Privacy/compliance governance; storage/compute budgets; accuracy limits necessitate human review.
- Retail shelf audit and compliance checks (offline)
- Sector: Retail
- What it does: Find “out-of-stock moments,” “planogram violations,” and “open fridge doors > 30s” across long recordings.
- Tools/products/workflows: Audit reports with timestamped clips; exception queues for store associates.
- Assumptions/dependencies: Camera placement/quality; store policy integration; potential domain-specific fine-tuning.
- Assembly-line quality checks from recorded video
- Sector: Manufacturing
- What it does: Identify anomalies (“missing screws on station 3,” “misalignment during press fit”) via targeted zoom after low-res sweeps.
- Tools/products/workflows: MES integration; shift-summaries with evidence; retraining on failure modes using KTO/GRPO loops.
- Assumptions/dependencies: Consistent lighting/angles; data security; curated failure exemplars.
Research and Academia
- Reproducible agentic video RL baseline
- Sector: AI research, academia
- What it does: Provides an end-to-end framework (SFT → KTO → GRPO), tool schemas (start_time, end_time, nframes, resize), and datasets (EVA-SFT/KTO/RL) for studying planning-before-perception at scale.
- Tools/products/workflows: Baseline repo; ablation-ready datasets; reward shaping templates (CSV, ROUGE, format reward).
- Assumptions/dependencies: Access to teacher MLLMs for data generation; compute (multi-GPU) for GRPO.
Policy and Governance Pilots
- Body-cam and traffic-cam triage for requests and audits (offline)
- Sector: Public safety, municipal services
- What it does: Speed FOIA responses by auto-locating requested events with evidence frames and a reasoning log (summary–plan–action–reflection).
- Tools/products/workflows: Evidence-linked reports; redaction pipeline integration (low-res sweeps first).
- Assumptions/dependencies: Privacy/chain-of-custody compliance; human oversight; policy for acceptable error rates.
Daily Life
- Home security and personal media search
- Sector: Consumer
- What it does: “When did the package arrive?,” “Find moments the dog jumped on the couch,” “Locate the child’s first steps.”
- Tools/products/workflows: Smart-camera app feature; personal archival search with timestamped clips.
- Assumptions/dependencies: On-device or private-cloud compute; consent and privacy settings.
- Dashcam event helper
- Sector: Consumer auto
- What it does: After a trip, automatically locate hard brakes, cut-ins, or near-misses and produce a concise, evidence-backed montage.
- Tools/products/workflows: Mobile companion app; claims export.
- Assumptions/dependencies: GPS/IMU sync helpful but not required; model robustness to motion blur/night scenes.
Long-Term Applications
These applications are feasible with further research, domain-specific datasets, stronger reliability guarantees, or real-time/edge scaling.
Healthcare and Life Sciences
- Surgical and endoscopic video decision support
- Sector: Healthcare
- What it could do: Detect critical steps/events (bleeding onset, instrument insertion, polyp detection) in long procedures; summarize with evidence.
- Tools/products/workflows: OR integration; post-op review dashboards; training feedback loops using KTO on error trajectories.
- Assumptions/dependencies: Rigorous clinical validation; FDA/CE approval; de-identification and PHI safeguards; high-quality annotated datasets.
- Longitudinal patient activity monitoring
- Sector: Digital health, elder care
- What it could do: Detect risky events (falls, wandering) from long in-home streams with compute-aware attention.
- Tools/products/workflows: Edge devices with low-res overview + targeted high-res capture; alert systems with evidence frames.
- Assumptions/dependencies: Strong privacy guarantees; on-device acceleration; reliable fall/anomaly labels.
Robotics and Autonomy
- Embodied agents with active visual attention
- Sector: Robotics, logistics, home robotics
- What it could do: Use planning-before-perception to decide when/where/how to look (camera pan/zoom/fps), saving energy and bandwidth while executing tasks.
- Tools/products/workflows: Policy distillation from EVA loops; integration with perception stacks; self-improvement via Data-Enhanced GRPO on failure cases.
- Assumptions/dependencies: Real-time constraints; sim-to-real transfer; safety and calibration.
- ADAS/AV log mining and incident forecasting
- Sector: Automotive
- What it could do: Efficient analysis of petabytes of driving video logs; “find all unprotected left turns with pedestrians.”
- Tools/products/workflows: Fleet analytics; active curation for training datasets; QA validation with evidence.
- Assumptions/dependencies: Multi-sensor alignment; strict reliability thresholds; privacy and location compliance.
Smart Cities, Energy, and Infrastructure
- Real-time incident detection under compute budgets
- Sector: Smart city ops, traffic management, public safety
- What it could do: Live streams triaged by low-res sweeps and zoom-in sampling to flag accidents, congestion, or crowding.
- Tools/products/workflows: VMS add-ons; city dashboards; escalation with evidence clips.
- Assumptions/dependencies: Streaming inference at scale; SLAs for latency/recall; edge/cloud orchestration.
- Industrial inspection via drones and robots
- Sector: Energy, utilities, construction, agriculture
- What it could do: Query-driven inspection of long flights (“any corrosion on joints?”, “cracks on turbine blade?”), minimizing bandwidth and compute.
- Tools/products/workflows: Flight post-processing; autonomous waypoint re-tasking based on EVA’s plan/reflect loop.
- Assumptions/dependencies: Domain-specific visual cues; harsh conditions; integration with maintenance CMMS.
Media and Broadcast
- Live highlight generation and compliance monitoring
- Sector: Sports broadcast, news, streaming
- What it could do: On-air event detection (goals, fouls, ads rule compliance) with evidence-linked clips and low computational footprint.
- Tools/products/workflows: Broadcast control-room assistants; automated clipping and metadata generation.
- Assumptions/dependencies: Real-time guarantees; league/policy constraints; robustness to camera switching.
Privacy-Preserving and Edge AI
- On-device video agents with budgeted attention
- Sector: Consumer devices, IoT
- What it could do: Always-on but compute-aware assistants that watch “how” and “when” to look, storing only evidence snippets.
- Tools/products/workflows: Mobile/edge accelerators; low-res-first pipelines; encrypted evidence buffers.
- Assumptions/dependencies: Efficient small models; hardware acceleration; local reward proxies for continual learning.
Legal, Compliance, and Governance
- Evidence-auditable AI video analysis
- Sector: Legal, compliance
- What it could do: Produce answers with verifiable provenance (timestamps, selected frames, plan/reflect logs) as part of admissible audit trails.
- Tools/products/workflows: “Evidence mode” enforcing CSV-like verification; immutable logs; policy templates.
- Assumptions/dependencies: Standards for AI evidence; explainability requirements; human review mandates.
Foundation Model and Data Ecosystems
- Continual domain dataset generation via Data-Enhanced GRPO
- Sector: AI tooling, MLOps
- What it could do: Close the loop on failure cases by auto-generating new QA tasks and training data for niche domains (sports, surgery, retail).
- Tools/products/workflows: Dataset curation service; RL pipelines with composite rewards and anti-reward-hacking safeguards.
- Assumptions/dependencies: High-quality teacher models; governance for synthetic data; monitoring for distribution shift and bias.
Notes on feasibility across applications:
- Compute and latency: EVA’s token-efficient planning-before-perception reduces cost, but multi-round tool calls add orchestration overhead. Real-time variants need optimized frame extractors and edge acceleration.
- Reliability and safety: Current benchmark accuracy (often ~55–68%) necessitates human-in-the-loop or conservative thresholds in safety-critical domains.
- Domain adaptation: Many high-value uses require domain-specific rewards, prompts, and curated failure trajectories (KTO/GRPO) to avoid reward hacking and hallucination.
- Privacy and regulation: Surveillance and healthcare uses depend on rigorous privacy controls, consent, and regulatory approvals.
Glossary
- Agentic Video Understanding: A paradigm where video models act as agents that plan and use tools to explore video content actively rather than passively processing frames. "agentic video understanding methods enable MLLM-based agents to actively explore video content using external tools."
- belief state: In an MDP, the agent’s internal representation of what it knows so far (query, history, and gathered evidence). "the agent observes a belief state:"
- Cold-Start: An initial training phase or dataset designed to bootstrap core behaviors before more advanced optimization. "Supervised Fine-Tuning (SFT) Cold-Start dataset"
- Completeness Self-Verification (CSV) reward: A reward that checks whether the agent identified the correct supporting frames rather than guessing. "we adopt the Completeness Self-Verification (CSV) reward~\cite{pan2025timesearch}"
- Data-Enhanced GRPO: A reinforcement learning pipeline that augments training by collecting failures and generating new data iteratively. "we introduce a Data-Enhanced GRPO pipeline."
- Direct Preference Optimization (DPO): A preference-learning method that trains models from pairwise comparisons of outputs. "Unlike DPO~\citep{rafailov2023direct}, which requires pairwise preference data"
- frame-selection tool: A tool interface that lets the agent choose when and how many frames to sample and at what resolution. "we design a flexible frame-selection tool that allows both temporal and spatial control."
- Group Relative Policy Optimization (GRPO): A KL-regularized policy optimization algorithm used to fine-tune policies with reward signals while staying close to a reference model. "We employ Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmathpushinglimitsmathematical}, a KL-regularized policy optimization method"
- interleaved image–text reasoning: Reasoning that alternates or integrates visual frames and text within the same chain of thought. "tool-call formatting, interleaved imageâtext reasoning, frame-level understanding"
- Kahneman–Tversky Optimization (KTO): A preference-learning method that uses single-sample labels to align strategies without requiring paired comparisons. "KahnemanâTversky Optimization (KTO)~\citep{ethayarajh2024ktomodelalignmentprospect} dataset"
- KL-regularized policy optimization: Policy optimization with a penalty on divergence from a reference policy to stabilize learning. "a KL-regularized policy optimization method"
- LLM As Judge: Using a LLM as an automated evaluator to label or verify agent outputs or trajectories. "we use LLM As Judge to select the trajectories"
- long-context challenge: The difficulty of reasoning over very long videos where processing all frames is inefficient. "effectively addressing the long-context challenge in video understanding."
- long-horizon video understanding: Tasks requiring reasoning over extended temporal spans and complex sequences of events. "long-horizon video understanding."
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, and rewards. "We formulate the active video understanding problem as a Markov Decision Process (MDP)."
- multimodal LLMs (MLLMs): LLMs that jointly process and reason over multiple modalities, such as text and video. "Video understanding with multimodal LLMs (MLLMs) remains challenging"
- Multiple-Choice Questions (MCQ): A supervised format where the model selects an answer from predefined options. "with 90\% open-ended QA and 10\% MCQ."
- online reinforcement learning: Learning where the policy is updated from trajectories it generates during training. "GRPO is an online reinforcement learning framework"
- open-ended QA: Question answering where the model must generate free-form textual answers rather than choose from options. "open-ended video QA pairs"
- planning-before-perception: A strategy where the agent devises a plan from the query before consuming visual input. "we advocate a planning-before-perception paradigm"
- preference labels: Single-sample signals (e.g., chosen/rejected) indicating which outputs or trajectories are preferable. "KTO only requires single-sample preference labels (âchosenâ or ârejectedâ)."
- reward hacking: Exploiting weaknesses in the reward function to get high scores without truly solving the task. "mitigates reward hacking caused by answer guessing"
- reward shaping: Modifying or augmenting rewards to guide learning toward desired behaviors. "Reward Shaping"
- rollouts: Sequences of actions and observations generated by the current policy during training. "the model generates multiple rollouts by itself"
- self-play: Training by interacting with the environment using the model’s own policy, often without external demonstrations. "rather than self-play"
- Supervised Fine-Tuning (SFT): Training a model on labeled data to imitate desired behavior before RL. "Supervised Fine-Tuning (SFT) Cold-Start dataset"
- teacher MLLM: A stronger or larger MLLM used to synthesize data, provide guidance, or label examples for training. "the teacher MLLM is prompted to produce open-ended QA pairs"
- temporal granularity: The fineness of temporal sampling (e.g., number of frames over time) used to perceive motion or events. "with flexible control over spatial resolution and temporal granularity."
- temporal window: A selected time interval within a video from which to sample frames. "The start_time and end_time specify the temporal window"
- trajectory (in RL): A sequence of states, actions, and outcomes produced by following a policy. "successful and failed strategy trajectories"
- visual tokens: Tokenized representations of visual inputs consumed by an MLLM, contributing to context length and cost. "without costing too many visual tokens."
- zero-shot: Evaluating a model on tasks it was not specifically trained on, without task-specific fine-tuning. "evaluated in a zero-shot setting"
- zoom-in and zoom-out operations: Adjusting spatial resolution to trade detail for token cost when inspecting frames. "zoom-in and zoom-out operations."
Collections
Sign up for free to add this paper to one or more collections.