- The paper presents a novel RL-driven method for dynamic, modular skill curation in self-evolving agents.
- It integrates a frozen executor with a trainable curator, achieving up to a 9.8% improvement in task performance.
- The approach employs grouped task streams and composite rewards, enabling efficient and transferable skill evolution.
SkillOS: Reinforcement Learning for Modular Skill Curation in Self-Evolving Agents
Introduction and Motivation
Recent developments in LLM-based agents underscore the need to move beyond stateless, "one-off" problem solvers toward agents capable of learning from sequential task exposure—“self-evolving” agents. The main bottleneck inhibiting robust self-evolution is effective procedural memory: the capability to curate, refine, and reuse experiences as actionable skills. Existing works either depend on human-driven skill specification, utilize heuristics for skill editing, or target purely short-horizon skill adaptation, all of which fail to yield scalable, generalizable mechanisms for long-term skill curation from indirect, delayed feedback.
SkillOS addresses this gap as a modular, RL-driven system for skill curation. It pairs a frozen agent executor—which retrieves and executes skills from a repository—with a trainable skill curator, which manages (inserts, updates, deletes) the skill repository based on observed trajectories. The literature survey positions SkillOS as a substantive leap over prior heuristic-based experience distillation, RL-based skill adaptation, and short-horizon memory editing approaches.
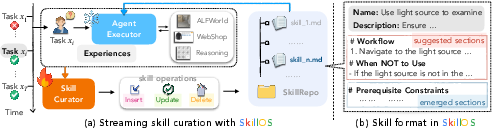
Figure 1: SkillOS pairs a frozen Agent Executor with a trainable Skill Curator. The executor retrieves relevant skills from SkillRepo to act; the curator edits the repo (insert/update/delete) based on the resulting experiences, with Markdown as the skill format.
System Architecture
SkillOS structures the agent as a closed loop: for each encountered task, the executor retrieves a subset of relevant skills (via BM25) from the SkillRepo and produces a trajectory; the skill curator then observes the trajectory, any self-assessment signal, and retrieved skills, and outputs edits to the SkillRepo. Crucially, the skills are represented in a Markdown-based format, encapsulating both YAML descriptors and natural-language procedural specifications for ease of retrieval and modification.
Each operation (insert, update, delete) is executed as a function call with explicit signatures. RL optimization focuses exclusively on the skill curator; the executor remains frozen throughout training to enforce modularity, executor-agnosticism, and efficient credit assignment.
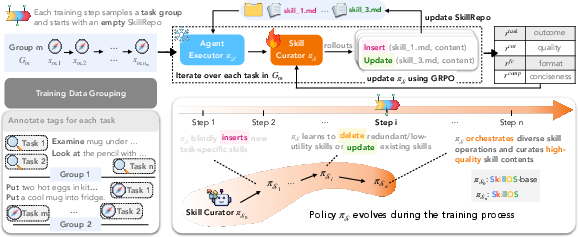
Figure 2: SkillOS training pipeline. Each training step samples a group of related tasks and initializes an empty SkillRepo. The curator is optimized with composite rewards, enabling self-evolution.
Training Procedure
SkillOS leverages an experience-driven RL scheme for optimizing the curator:
- Grouped Task Streams: Training instances are constructed as coherent groups of related tasks, mimicking realistic streaming deployment. By updating the SkillRepo based on early tasks and evaluating on later ones, the system attributes credit for skill curation decisions more effectively (handling the sparse, delayed reward regime).
- Composite Reward Design: The RL reward for each curation sequence aggregates several axes:
- Downstream task performance (primary executor-grounded signal)
- Validity of function calls (operation-level supervision)
- Skill content quality (external LLMA judge)
- Repository compression (discouraging raw trajectory copying)
Policy optimization uses Grouped Reward Policy Optimization (GRPO) for stability and sample efficiency.
Experimental Evaluation
Experiments encompass multi-turn agentic tasks (ALFWorld, WebShop) and single-turn reasoning tasks (AIME, GPQA), under various model scales for both executor and curator (Qwen3-8B/32B, Gemini-2.5-Pro, Gemini-3.1-Flash-Lite). SkillOS is benchmarked against both memory-free (no skill memory) and strong memory-based methods (ReasoningBank, MemP), as well as internal ablations (SkillOS-base, SkillOS-gemini).
Key empirical findings include:
Behavioral and Structural Analysis
Ablations confirm the importance of reward shaping (content quality, compression) and proper grouping of training tasks; removing these components degrades success rates and efficiency. Analysis of operation ratios evidences a transition during RL training: insertion dominates initially but gives way to more update operations, with deletion increasing modestly, reinforcing that RL fostered adaptive, focused memory refinement.
Skill evolution studies show the transition from verbose, generic skills to execution-relevant, compositional, and meta-strategy skills. Rather than merely accumulating skills, SkillOS curates increasingly structured and abstract procedural knowledge over time.
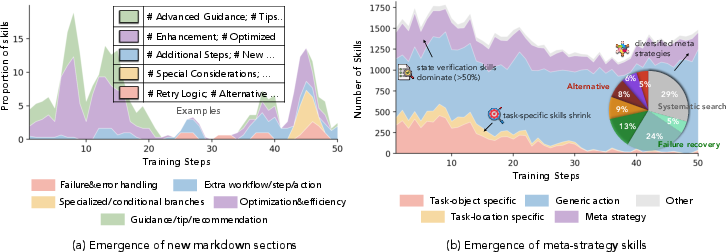
Figure 4: Evolution dynamics of the curated skills under RL training.
Attribution experiments on ALFWorld indicate that SkillOS-curated skills are more precisely targeted, more widely used, and yield higher task success—while requiring fewer skills per instance—relative to baselines. This supports the claim that targeted RL training on curation, rather than scale or static heuristics, primarily drives gains.
Case Studies
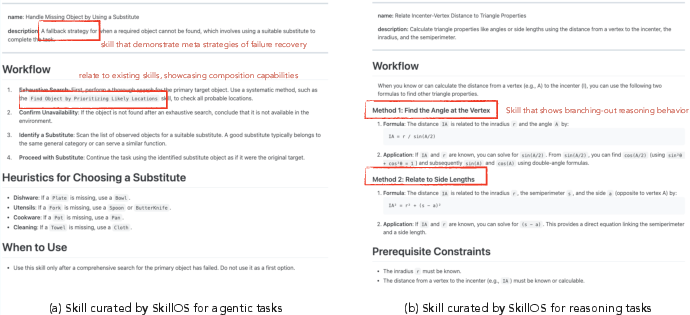
Figure 5: Case studies of curated skills by SkillOS.
For agentic tasks, SkillOS synthesizes compositional meta-skills (e.g., recovery workflows referencing other skills). For reasoning tasks, the system generates multi-path, constraint-explicit procedural strategies, tailored to support different solution avenues within a domain.

Figure 6: Case study on math-reasoning skill curation. SkillOS-base produces a generic partitioning recipe, while SkillOS curates a concrete and reusable counting framework with explicit constraints, equations, and a worked example.
Implications and Future Directions
SkillOS establishes RL-based, modular skill curation as a practical and effective path toward procedural memory in LLM agents. It demonstrates that small, well-trained curators can outperform larger, unoptimized LLMs in this regime. Modular decoupling facilitates transfer, plug-and-play compatibility, and opens avenues for joint curation-retrieval optimization, hierarchical/compositional skill formation, and multi-agent shared memory architectures.
Anticipated developments include agentic search over exponentially large, compositional skill repositories; extension to hierarchical skill graphs; and shared/exchangeable skill memories for collaborative agent settings.
Conclusion
SkillOS delivers a principled RL framework for skill curation in self-evolving agents, enabling substantial improvements in effectiveness and efficiency over state-of-the-art baselines. Its modular architecture, executor-agnosticism, and robust learning signal design position it as an adaptable foundation for future research in procedural memory, compressed experience embedding, and long-term agent adaptation.


