SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Abstract: LLM agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily store raw trajectories, which are often redundant and noise-heavy. This prevents agents from extracting high-level, reusable behavioral patterns that are essential for generalization. In this paper, we propose SkillRL, a framework that bridges the gap between raw experience and policy improvement through automatic skill discovery and recursive evolution. Our approach introduces an experience-based distillation mechanism to build a hierarchical skill library SkillBank, an adaptive retrieval strategy for general and task-specific heuristics, and a recursive evolution mechanism that allows the skill library to co-evolve with the agent's policy during reinforcement learning. These innovations significantly reduce the token footprint while enhancing reasoning utility. Experimental results on ALFWorld, WebShop and seven search-augmented tasks demonstrate that SkillRL achieves state-of-the-art performance, outperforming strong baselines over 15.3% and maintaining robustness as task complexity increases. Code is available at this https://github.com/aiming-lab/SkillRL.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SkillRL: A Simple Explanation for Teens
What is this paper about?
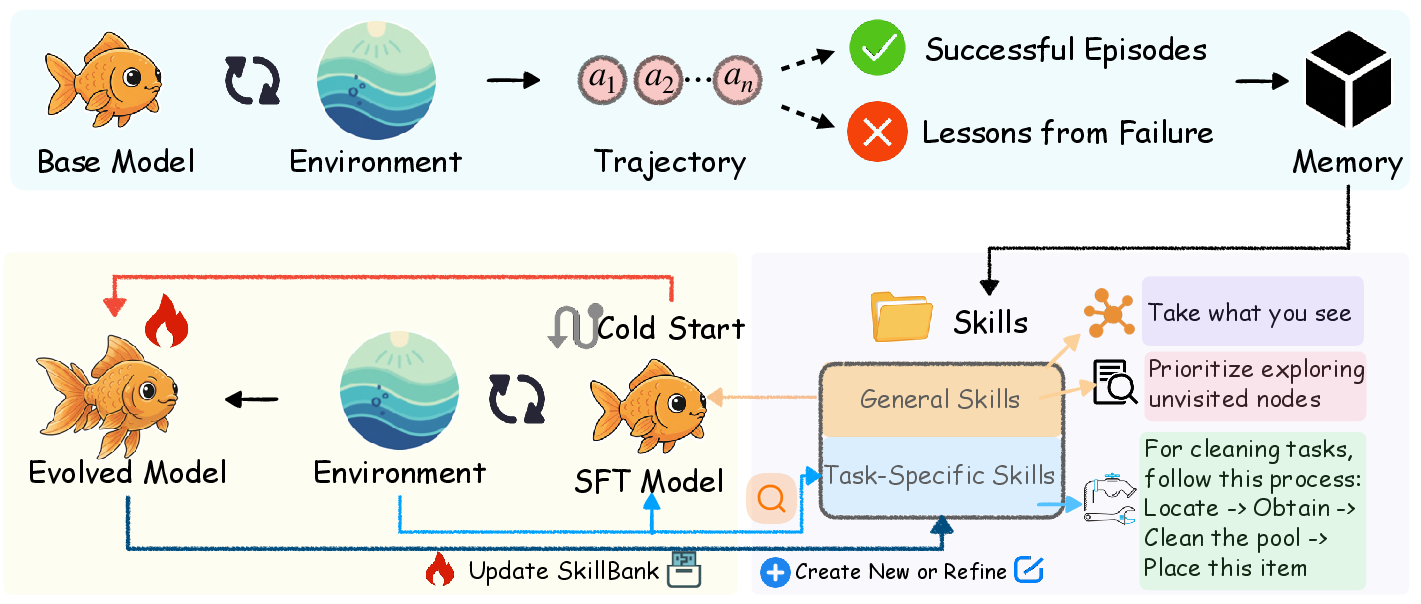
This paper is about making AI “agents” (computer programs powered by LLMs) get better over time by learning useful skills from their past experiences—just like a person who practices, reflects, and writes down tips that work. The authors introduce SkillRL, a method that turns long, messy past attempts into short, reusable “skills,” stores them in a library, and then keeps improving that library as the agent learns.
What questions are the researchers trying to answer?
The paper focuses on three easy-to-understand questions:
- How can an AI agent learn from both its successes and mistakes instead of starting from zero every time?
- Can we turn messy “play-by-play” logs into short, reusable tips (skills) that help on new tasks?
- If we keep updating these skills while training, will the agent learn faster and solve harder problems better?
How does SkillRL work? (Using everyday language)
Think of teaching someone to solve problems (like cooking recipes, cleaning a room, or shopping online) and helping them improve:
- From experiences to skills:
- Instead of saving every single step the agent took (which is long and noisy), the system summarizes what mattered.
- For successes: it extracts what worked (“Always check the item is in the cart before checking out.”).
- For failures: it writes a “lesson learned” (“I forgot to preheat the oven; next time do it first.”).
- These short tips are called “skills.”
- Building a skill library (SkillBank):
- The skills are stored in a library with two shelves:
- General skills: common advice useful almost everywhere (like “double-check the goal before finishing”).
- Task-specific skills: tips for a particular type of task (like “for picking two objects, confirm the first before searching for the second”).
- When facing a new problem, the agent looks up the most relevant skills—like grabbing the right recipe cards from a box—so the instructions it reads are short and actually helpful.
- Teaching the agent to use skills (cold start):
- Before training with rewards, the agent is shown examples of how to pick and apply the right skills. This is a quick “lesson” phase so it knows how to use the skill library.
- Learning and evolving with reinforcement learning (RL):
- Reinforcement learning here works like practicing many times and getting a score for each attempt.
- The agent tries multiple solutions, compares which ones do better, and updates its behavior.
- After each round, the system looks at what still fails, creates new skills, or improves old ones. So both the agent and the skill library grow together. This is the “recursive evolution” part—learn, update, repeat.
- A quick note on GRPO (the training method):
- GRPO is a flavor of RL where the agent tries several answers, scores them, and nudges itself toward better ones, without needing a separate “critic” model. Think of it as “learn by comparing your own attempts.”
What did they find, and why does it matter?
The authors tested SkillRL on three kinds of challenges:
- ALFWorld: text-based household tasks (like “pick up, heat, cool” objects using written commands).
- WebShop: a realistic online shopping simulator (find and buy the right product).
- Search-augmented questions: answering questions by searching and gathering facts.
Here are the key results:
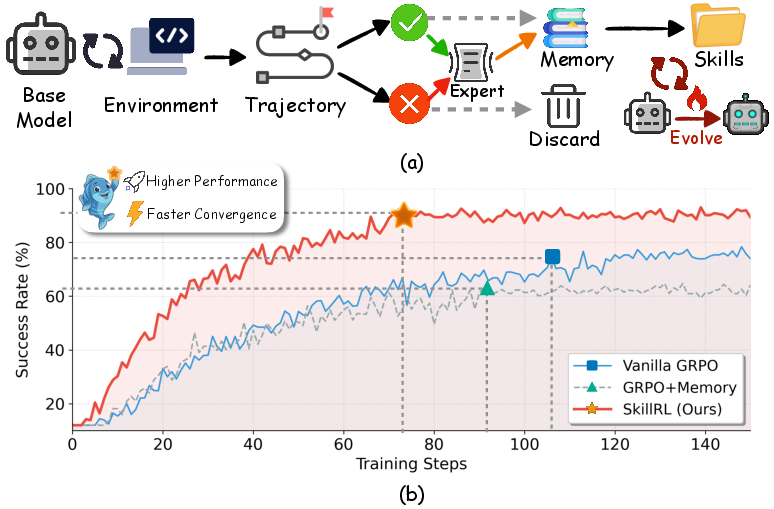
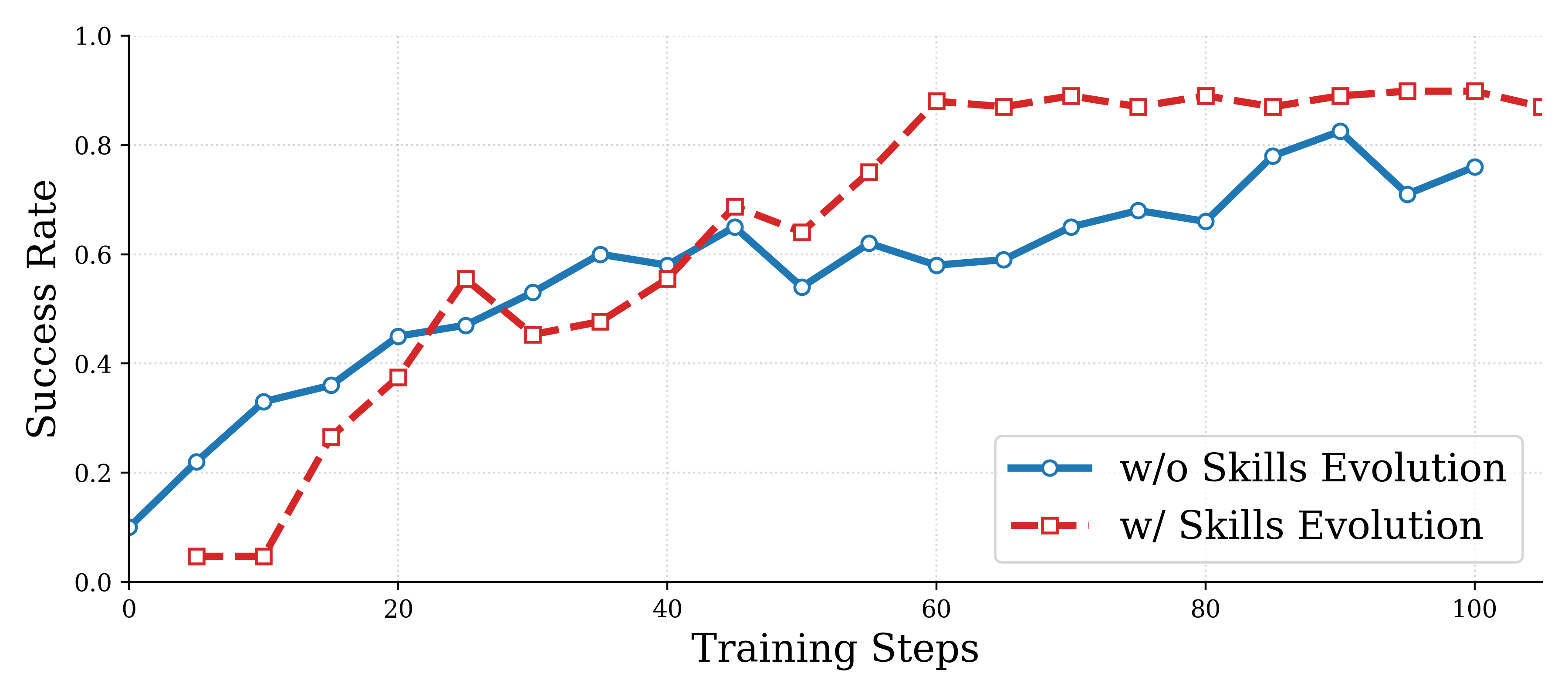
- Higher success rates: SkillRL beat strong baselines by about 15% on average, and reached around 90% success on ALFWorld and about 73% on WebShop.
- Faster learning: It reached high performance quicker than regular RL, because the skills give it a head start and better guidance.
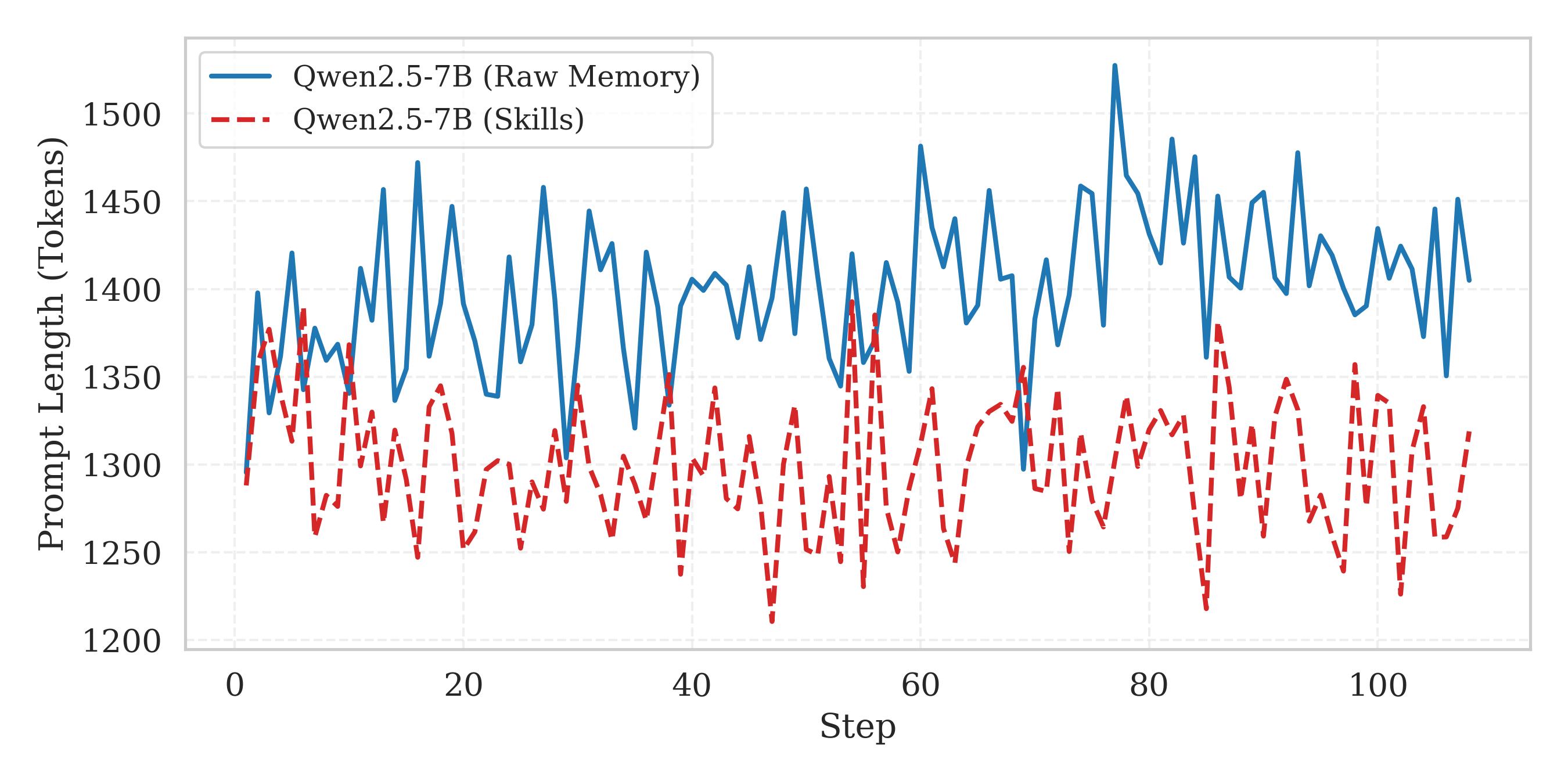
- Shorter, cleaner context: Instead of stuffing long past histories into the prompt, SkillRL uses short skills, which compress information a lot (often 10–20× shorter than raw logs) and reduce prompt length while improving decisions.
- Strong generalization: On question-answering tasks that require web search and multi-step reasoning, SkillRL achieved the best average performance across seven datasets, including tasks it wasn’t directly trained on.
- Small beats big (in some cases): Using a smaller open-source model with SkillRL even outperformed much larger, closed-source models on ALFWorld. This shows that better learning strategies can sometimes beat pure size.
Why is this important?
This work shows a practical way for AI agents to:
- Learn like people do—by turning messy experiences into short, reusable skills.
- Keep improving over time by updating those skills based on new failures.
- Use less text while thinking better, which saves cost and makes agents more efficient.
- Transfer what they learned to new tasks, not just repeat old steps.
In simple terms: SkillRL helps AI agents grow smarter, faster, and more reliably by building and evolving a “toolbox of tips” from real practice—making them better teammates for complex, real-world tasks like web use, planning, and research.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Dependence on a closed-source teacher model (OpenAI o3): quantify how performance and skill quality vary with teacher choice, prompts, temperature, and sampling; evaluate reproducibility with open-source teachers and the risk of teacher-induced bias or hallucinations in distilled skills.
- Skill distillation reliability: establish automatic verification for distilled skills (e.g., unit tests or simulators per skill), measure hallucination/error rates, and define criteria for accepting/rejecting skills from failed trajectories.
- Formal skill representation: specify a canonical schema or grammar for skills (preconditions, effects, constraints, failure modes), including machine-checkable “when_to_apply” conditions and conflict resolution between overlapping or contradictory skills.
- Retrieval design and sensitivity: study the impact of embedding model choice, similarity threshold δ, TopK, and negative retrieval (blocking irrelevant/conflicting skills); compare heuristic retrieval to learned retrieval (e.g., bandit or RL-based skill selection).
- General skills inclusion policy: evaluate “always-include general skills” vs. learned selection; measure the harm from irrelevant general guidance and develop mechanisms to gate or weight general skills by context.
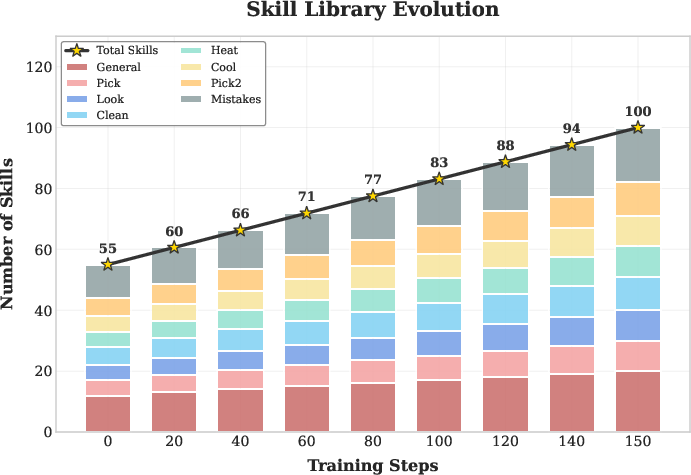
- Library growth management: develop pruning, de-duplication, clustering/merging, and aging policies; quantify retrieval latency, token footprint, and performance as the SkillBank scales beyond ~100 skills.
- Skill quality metrics: design coverage, specificity, and effectiveness metrics per skill; track skill usage statistics, success attribution, and counterfactual impact (what fraction of successes are due to particular skills).
- Co-evolution stability: analyze non-stationarity introduced by evolving context during RL; study convergence, catastrophic forgetting, and stability under different KL anchors (fixed vs. periodically updated π_ref).
- Validation-triggered evolution: assess overfitting risk when using validation failures to add/refine skills; enforce proper train/val/test splits and evaluate on unseen held-out tasks to prevent validation leakage.
- Reward design: compare binary rewards to shaped or dense rewards (e.g., subgoal completion, consistency checks); study credit assignment improvements and the effect of different group sizes G and GRPO hyperparameters.
- Cost and compute reporting: measure the training/inference cost, teacher-in-the-loop overhead, token savings vs. retrieval/processing overhead, and sample efficiency (steps to desired success rate) across methods.
- Baseline fairness and breadth: ensure comparable optimization budgets and memory mechanisms for baselines; include stronger or diverse agent frameworks (e.g., actor-critic with verifiers, offline RL), and provide statistical significance tests.
- Domain and modality breadth: test SkillRL in visual/embodied robotics, code agents, tool-using multi-modal environments, and dynamic web; analyze cross-domain transfer of skills from one environment to another.
- Cross-lingual and multilingual robustness: evaluate skill distillation, retrieval, and application in non-English settings and multilingual tasks.
- Online/deployment-time evolution: explore real-time skill evolution during deployment (not only at validation checkpoints), with safeguards against drift or skill pollution from noisy streams.
- Safety and alignment: audit skills for harmful or biased strategies; add guardrails (verifiers/filters) and assess robustness to adversarial or misleading trajectories.
- Failure trajectory utilization: quantify how many and which types of failed episodes are needed; assess robustness to noisy/adversarial failures and the teacher’s ability to extract correct counterfactuals.
- Interaction with ephemeral memory: integrate short-term working memory or scratchpads with SkillBank; study when to prefer memory vs. skills and how they complement each other.
- Alternative optimization paradigms: compare GRPO to actor-critic, offline RL with skill-conditioned policies, imitation learning from distilled demonstrations, and hybrid RL+planning approaches.
- Skill transfer and compositionality: evaluate whether skills learned in one task category compose effectively in novel tasks; test zero-shot transfer and systematic generalization beyond the current benchmarks.
- Interpretability and human-in-the-loop: perform human evaluations of skill clarity, correctness, and usefulness; explore semi-automatic curation or editing workflows for SkillBank maintenance.
- Embedding and similarity infrastructure: specify and compare embedding models for skills/tasks; measure retrieval robustness under paraphrase, long-context descriptions, and distribution shift.
- Token compression claims: reconcile the reported 10–20× compression goal with the observed ~10.3% prompt reduction; provide standardized compression benchmarks and utility-preservation metrics.
- Skill conflict detection and resolution: create mechanisms to detect contradictions among retrieved skills and implement tie-breaking, weighting, or meta-reasoning policies.
- Continual learning properties: track knowledge retention over long horizons, measure interference among newly added skills, and develop metrics/strategies to mitigate forgetting.
Practical Applications
Below is a concise mapping from the paper’s contributions (experience-based skill distillation, hierarchical SkillBank, adaptive retrieval, and recursive skill evolution with GRPO) to practical, real-world applications. Each item includes sectors, implementation notes, and key dependencies that may affect feasibility.
Immediate Applications
- Bold e-commerce shopping assistants and product search optimization (WebShop-proven)
- Sectors: Retail, e-commerce
- What to deploy: A web-shopping agent that replaces raw trajectory memory with a SkillBank of general web-navigation/search skills (e.g., “prioritize core keywords,” “verify constraints before checkout”) and category-specific skills (budget handling, filtering, spec matching). Use cold-start SFT to teach skill use; optional GRPO with success metrics (purchase completed, constraints satisfied).
- Dependencies/assumptions: Well-defined success signals (e.g., exact match, conversion), stable site structure or API, access to a teacher LLM for initial distillation.
- Bold enterprise web automation/RPA for routine workflows
- Sectors: Software, RPA, back-office operations
- What to deploy: Agent-driven form-filling, approval routing, account updates that reuse a SkillBank distilled from analyst/robot logs. Adaptive retrieval reduces prompt size and cost, while failure lessons capture edge cases (e.g., missing preconditions, auth problems).
- Dependencies/assumptions: Repeatable workflows and deterministic success criteria, browser automation tools or APIs, data governance for using historical logs.
- Bold Search-augmented research assistant for knowledge work
- Sectors: Education, software, media, consulting
- What to deploy: A research agent that uses general search heuristics (structured query expansion, source verification) and task-specific skills (e.g., multi-hop evidence chaining) distilled from prior queries/tasks; optional RL on “answer correctness” or user ratings.
- Dependencies/assumptions: Browser or API-based search tools, lightweight verifiers for correctness, access to interaction logs for distillation.
- Bold Customer support triage and resolution
- Sectors: Customer service, SaaS, telecom, consumer electronics
- What to deploy: SkillBank built from helpdesk runbooks and resolved tickets. General skills (state tracking, escalation policy) plus task-specific skills (diagnostics per product line). Measure rewards via resolution rate, first-contact resolution, or customer satisfaction.
- Dependencies/assumptions: Guardrails/compliance policies, high-quality labeled outcomes, integration with ticketing systems (e.g., Zendesk/ServiceNow).
- Bold Automated QA and UI testing agents
- Sectors: Software engineering, QA, DevOps
- What to deploy: Use skills for systematic exploration, precondition checks, and failure pattern detection in web/app UIs. Distill from QA scripts and failure logs; RL reward is pass/fail against test specs.
- Dependencies/assumptions: Stable test environments, clear pass/fail verifiers, CI/CD integration for iterative evolution.
- Bold Document processing and verification assistants
- Sectors: Finance ops, insurance ops, HR, legal
- What to deploy: Distill skills for parsing, cross-referencing, anomaly checks (e.g., “verify totals before proceeding,” “validate entity consistency”). Use adaptive retrieval to minimize prompt size and latency.
- Dependencies/assumptions: OCR/PDF tools, ground-truth checks or validators, data privacy constraints.
- Bold Data/ETL pipeline monitoring and remediation playbooks
- Sectors: Data engineering, analytics, BI
- What to deploy: SkillBank from incident post-mortems and playbooks (e.g., “check upstream schema first,” “roll back and re-run partition”). Rewards from pipeline health metrics and SLA adherence.
- Dependencies/assumptions: Observability signals, deterministic mitigation steps, secure access to logs/metadata.
- Bold Educational problem-solving tutors (structured domains)
- Sectors: Education, edtech
- What to deploy: Skills for step-wise reasoning in algebra, physics, logic puzzles (e.g., “decompose into subgoals,” “verify preconditions for next step”), with failure lessons from common misconceptions. No online RL needed; rely on SFT with skill demonstrations and correctness checks.
- Dependencies/assumptions: Item banks with verified solutions, safeguards against overfitting, clear correctness metrics.
- Bold SOC/IT operations runbook executors (in sandboxed settings)
- Sectors: Cybersecurity, IT operations
- What to deploy: Distill runbooks into general incident-response skills (triage, evidence gathering) and task-specific steps (malware class, misconfig class). Evaluate in a sandbox with simulated incidents; optional RL on timely resolution and false-positive/negative rates.
- Dependencies/assumptions: High-quality simulations, strict guardrails, post-action audit trails.
- Bold Cost-efficient agent deployment using smaller models
- Sectors: Cross-sector AI ops
- What to deploy: Replace large, closed models with smaller, open models enhanced by SkillBank and cold-start SFT. Leverage observed 10–20× token compression and improved success rates to cut inference costs while maintaining or improving performance.
- Dependencies/assumptions: High-quality skill distillation, reliable retrieval index, careful RL regularization (KL to SFT reference).
Long-Term Applications
- Bold Home and service robotics with skill abstraction and evolution
- Sectors: Robotics, healthcare support, hospitality
- What to build: Transfer SkillRL to embodied tasks: distill teleop/sim logs into general manipulation/navigation skills and device/task-specific skills; evolve via safe RL in high-fidelity sim before deployment.
- Dependencies/assumptions: Sim2real transfer, safety layers and verifiers, high-quality sensors/actuators, reward shaping beyond binary success.
- Bold Clinical administrative automation and decision support
- Sectors: Healthcare
- What to build: Skills for EHR workflows (coding, prior auth, scheduling) and clinical reasoning heuristics with rigorous human-in-the-loop. Failure lessons formalize boundary conditions to prevent repeat errors.
- Dependencies/assumptions: Regulatory compliance (HIPAA/GDPR), robust medical verifiers, conservative rollout with clinician oversight.
- Bold Autonomous lab assistants for scientific discovery
- Sectors: Pharma, biotech, materials, chemistry
- What to build: Skills for experimental planning, instrument operation, and error recovery; recursive skill evolution guided by lab results and safety constraints.
- Dependencies/assumptions: Instrument APIs/digital twins, experiment verifiers, long-horizon reward design, safety protocols.
- Bold Autonomous enterprise agents that learn cross-department runbooks
- Sectors: Enterprise IT, operations, finance ops
- What to build: Organization-wide SkillBanks with general governance skills (compliance checks, audit) and department-specific skills (AP/AR, procurement, HR). Skill versioning and co-evolution via policy-aligned rewards.
- Dependencies/assumptions: Data-sharing agreements, role-based access, skill governance and audit tooling.
- Bold Personalized on-device digital assistants that learn routines
- Sectors: Consumer software, mobile, smart home
- What to build: Private SkillBanks for user routines (calendar triage, travel booking, budgeting), with local retrieval to minimize data leakage; skill evolution under explicit user consent.
- Dependencies/assumptions: On-device models or hybrid edge/cloud, privacy-preserving distillation, user-controlled reward signals (ratings, corrections).
- Bold Finance and trading agents with auditable strategy skills
- Sectors: Finance
- What to build: Strategy SkillBanks that encode precondition checks, risk controls, and market microstructure heuristics; evolve skills via backtesting and live feedback under strict risk limits.
- Dependencies/assumptions: Regulatory compliance, risk-aware RL (constraints, VaR limits), robust simulators and slippage models.
- Bold Energy and industrial control assistants
- Sectors: Energy, manufacturing
- What to build: Skills capturing operator best practices for grid balancing or line control; failure lessons from incident reviews; RL in high-fidelity simulators before constrained live deployment.
- Dependencies/assumptions: Digital twins, safety interlocks, clear KPIs (stability, efficiency), human override.
- Bold Government/policy case management and compliance agents
- Sectors: Public sector, legal
- What to build: Skill libraries that codify policy rules, procedural steps, and audit trails; dynamic evolution to incorporate updated regulations; human-in-the-loop validation.
- Dependencies/assumptions: Transparent, auditable skill representations; access control; rigorous evaluation for fairness and bias.
- Bold Standards and tooling for skill representation, exchange, and governance
- Sectors: AI infrastructure, MLOps, compliance
- What to build: A “Skill Markup Language,” skill registries, and governance dashboards that version, review, and approve skills; blacklisting/whitelisting and lineage tracking for safety.
- Dependencies/assumptions: Industry coordination, interoperable formats, integration with model providers and vector DBs.
- Bold Safer RL with richer rewards and human feedback for agents
- Sectors: Cross-sector AI safety
- What to build: Extend binary rewards to multi-dimensional objectives (safety, efficiency, novelty), integrate human preference models and verifiers, and evolve SkillBanks with explicit safety constraints.
- Dependencies/assumptions: Scalable human feedback pipelines, verifiable constraints, principled off-policy evaluation.
Notes on cross-cutting tools/products and workflows that may emerge:
- Skill distiller service: A teacher-LMM-driven pipeline that turns success/failure logs into general and task-specific skills plus failure lessons.
- SkillBank and retriever: A hierarchical skill repository with semantic indexing (Top-K, threshold filtering) and metadata (when_to_apply, provenance).
- Cold-start SFT packager: Automatically generates skill-augmented demonstrations to prime models for skill use.
- Skill-aware RL trainer: GRPO-based trainer with KL to SFT reference and validation-driven recursive skill evolution.
- MLOps for skill governance: Dashboards for skill quality, evolution diffs, audit trails, and deployment gates.
Key assumptions and dependencies across applications:
- Availability of a capable teacher model for initial distillation (closed-source or open-source substitute).
- Access to sufficient interaction logs and unambiguous success/failure signals (or proxies/verifiers) to enable both SFT and RL.
- Safe deployment and compliance frameworks, especially in regulated domains (healthcare, finance, energy).
- Retrieval and context-length limits: Skill abstraction helps, but production systems still require robust vector indexes and context management.
- Compute budget for periodic SFT and RL; smaller models with SkillBank may mitigate operational cost relative to very large LLMs.
Glossary
- Advantage (normalized advantage): A measure of how good an action/trajectory is relative to others, normalized within a group to stabilize policy updates. "GRPO computes normalized advantages and updates the policy with a PPO-style clipped objective"
- Agentic AI: An AI paradigm emphasizing autonomous, goal-directed agents that plan and act in complex environments. "Agentic AI"
- ALFWorld: A text-based interactive environment aligned with ALFRED for evaluating embodied task completion via language. "Performance on ALFWorld and WebShop."
- Binary reward: A reward signal that takes on only two values (e.g., success or failure) for each trajectory. "Each trajectory τ{(i)} receives a binary reward R_i = r(τ{(i)}) ∈ {0, 1} indicating task successfulness."
- Cold-Start Initialization: An initial stage that prepares a model (e.g., via demonstrations/SFT) to effectively use new components (like skills) before RL. "Cold-Start Initialization."
- Counterfactuals: Concise descriptions of what should have been done differently; used here to summarize failures for learning. "This transforms verbose failed episodes into counterfactuals."
- Cross-entropy loss: A standard supervised learning loss measuring the difference between predicted and target distributions. "where 𝓛_{CE} denotes the cross-entropy loss."
- Diversity-aware stratified sampling: A sampling strategy that preserves category balance and diversity when selecting examples (e.g., failures) for analysis. "using a diversity-aware stratified sampling strategy"
- Embeddings: Vector representations of texts (e.g., tasks, skills) enabling similarity-based retrieval. "where e_d, e_s are embeddings of the task description and skill respectively"
- Embodied AI: AI agents that perceive and act in environments (often simulated), focusing on interaction with objects and spaces. "aligned with the ALFRED embodied AI benchmark."
- Experience-based distillation mechanism: A process that converts raw interaction trajectories into concise, reusable knowledge (skills). "introduces an experience-based distillation mechanism"
- Group Relative Policy Optimization (GRPO): An RL method that optimizes a policy using relative rewards within sampled groups, avoiding a separate critic. "Group Relative Policy Optimization (GRPO)."
- Hierarchical skill library: A structured repository that organizes skills at different levels (e.g., general vs. task-specific) for retrieval and reuse. "a hierarchical skill library SkillBank"
- Importance ratio: The ratio of current to past policy probabilities for the same output, used in importance sampling for stable updates. "is the importance ratio"
- In-context learning (ICL): A capability where models adapt behavior based on examples/instructions provided in the prompt, without parameter updates. "in-context learning (ICL)"
- Kullback–Leibler (KL) penalty: A regularization term that penalizes divergence between the current policy and a reference policy to maintain stability. "The KL penalty anchored to π_ref"
- KL regularization: The practice of constraining policy updates by penalizing KL divergence from a reference policy. "the reference policy π_ref for KL regularization."
- LLM agents: Agents powered by LLMs that perceive, reason, and act via natural language. "LLM agents"
- Memory-augmented RL: Reinforcement learning approaches that integrate external memory mechanisms to leverage past experiences during training or inference. "memory-augmented RL frameworks"
- Multi-hop QA: Question answering tasks requiring reasoning across multiple pieces of information or steps. "multi-hop QA datasets"
- Out-of-domain (OOD): Data or tasks that differ significantly from those seen during training, testing generalization. "OOD tasks like TriviaQA and 2Wiki"
- PPO-style clipped objective: An objective from Proximal Policy Optimization that clips large policy updates to improve training stability. "PPO-style clipped objective"
- Reference policy: A fixed or slowly changing policy used as a baseline for KL regularization during RL. "the reference policy π_ref for KL regularization."
- Reinforcement learning (RL): A learning paradigm where agents learn policies to maximize cumulative reward through interaction with an environment. "during reinforcement learning (RL)"
- Retrieval-Augmented Generation (RAG): Methods that retrieve external information to condition generation and improve factuality or reasoning. "a static RAG paradigm"
- Rollout: Executing a policy in an environment to collect trajectories of observations, actions, and rewards. "gathers diverse trajectories from environment rollouts"
- Round-robin sampling: A selection procedure that cycles through categories or groups in turn to ensure balanced coverage. "selected via round-robin sampling"
- Search-augmented QA: QA settings where the model uses search tools to find evidence before answering. "search-augmented QA tasks"
- Semantic similarity: A measure of how similar two texts are in meaning, used here for skill retrieval. "Task-specific skills are retrieved via semantic similarity"
- SkillBank: The named hierarchical skill library that stores general and task-specific skills distilled from experience. "a hierarchical skill library SkillBank"
- Sparse-reward environments: Settings where meaningful rewards are rare, making exploration and credit assignment challenging. "sparse-reward environments"
- Supervised fine-tuning (SFT): Training a model on labeled demonstrations to teach desired behaviors before or alongside RL. "we therefore perform a cold-start supervised fine-tuning (SFT) stage"
- Token footprint: The number of tokens consumed in a prompt/context, impacting cost and context limits. "reduce the token footprint while enhancing reasoning utility."
- Top-K retrieval: Selecting the K most similar or relevant items (e.g., skills) according to a similarity metric. "TopK"
- Trajectory: A sequence of states, actions, and rewards collected during one episode of interaction. "A trajectory τ = (o_0, a_0, r_0, …, o_T, a_T, r_T) captures one episode of interaction."
- Validation epoch: A periodic evaluation phase during training used to assess performance and trigger updates (e.g., skill evolution). "After each validation epoch, we monitor the success rate"
Collections
Sign up for free to add this paper to one or more collections.