Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
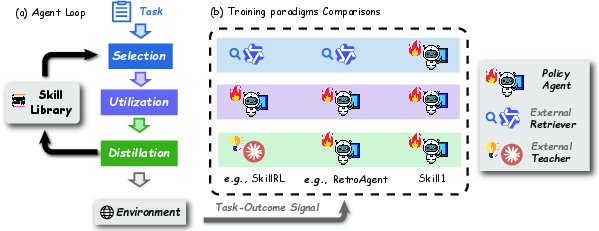
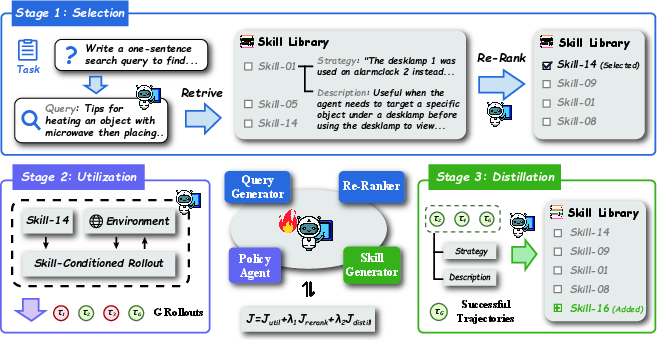
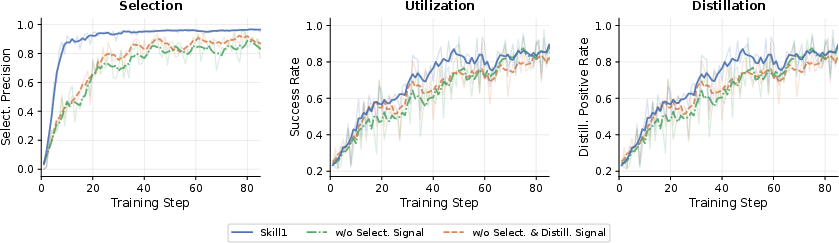
Abstract: A persistent skill library allows LLM agents to reuse successful strategies across tasks. Maintaining such a library requires three coupled capabilities. The agent selects a relevant skill, utilizes it during execution, and distills new skills from experience. Existing methods optimize these capabilities in isolation or with separate reward sources, resulting in partial and conflicting evolution. We propose Skill1, a framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective. The policy generates a query to search the skill library, re-ranks candidates to select one, solves the task conditioned on it, and distills a new skill from the trajectory. All learning derives from a single task-outcome signal. Its low-frequency trend credits selection and its high-frequency variation credits distillation. Experiments on ALFWorld and WebShop show that Skill1 outperforms prior skill-based and reinforcement learning baselines. Training dynamics confirm the co-evolution of the three capabilities, and ablations show that removing any credit signal degrades the evolution.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Skill1: A simple explanation for teens
What is this paper about?
This paper introduces Skill1, a way to train AI “agents” (think smart chatbots that can click, search, or plan) to build and use a shared “skill library.” A skill is a short, plain‑language tip like “how to find a mug in a kitchen” or “how to search a website for the right product.” The key idea is to teach the agent to:
- pick the right skill for the job,
- use that skill to solve the task,
- and write down new useful skills for next time,
all at the same time and all guided by one simple goal: did the agent finish the task or not?
What questions are the researchers asking?
In everyday words, they ask:
- How can an AI learn to choose, use, and create skills together instead of separately?
- How can all three get better using the same success signal (like “mission accomplished”) instead of juggling different, possibly conflicting, signals?
- Will this make agents solve tasks more reliably than previous methods?
How does Skill1 work? (Methods in everyday language)
Think of the agent as a gamer with a growing playbook:
- The playbook (skill library) stores short strategies the agent can reuse.
- Every time the agent faces a new level (task), it does three things in order.
Here’s the simple loop, with real‑world analogies:
- Skill selection — “Find the right page in the playbook”
- The agent writes a short search query describing what it needs.
- It retrieves a few likely skills from its library.
- It then ranks those candidates and picks the best one.
- Analogy: You search your notes for “clean a kitchen,” then pick the most helpful page.
- Skill utilization — “Use the chosen play”
- The agent follows the chosen skill’s advice while interacting step by step with the environment.
- Analogy: You follow your checklist to find and clean a mug.
- Skill distillation — “Add a better tip to the playbook”
- After finishing, the agent summarizes what worked into a new skill: a short “how‑to” plus when to use it.
- It only adds this new skill if the task was successful, so the library stays high‑quality.
- If the library gets too big, the least useful and least used skills are removed.
- Analogy: You write a neat, short tip when your plan worked, and you toss old notes you never use.
One reward to rule them all
- The only feedback the agent gets is whether it succeeded on the task () or not (). No extra teacher scores.
- To fairly assign “credit,” the paper splits this single success signal into two views:
- Long‑term “trend” (low‑frequency): a running average of how often each skill leads to success. This teaches the agent which skills are reliably good and helps it rank skills better.
- Analogy: a player’s season average, not just one game.
- Short‑term “surprise” (high‑frequency): how much this run was better or worse than what the best retrieved skill usually achieves. This teaches the agent to add new skills only when they genuinely improve the library.
- Analogy: did you beat your usual performance today?
Training setup
- The agent is trained with reinforcement learning (learning by trial and error with rewards).
- It’s tested in two text‑based worlds:
- ALFWorld: a virtual home where you complete household tasks by text (like “find and heat a mug”).
- WebShop: a simulated online store where you search for products matching a description.
What did they find? (Main results and why they matter)
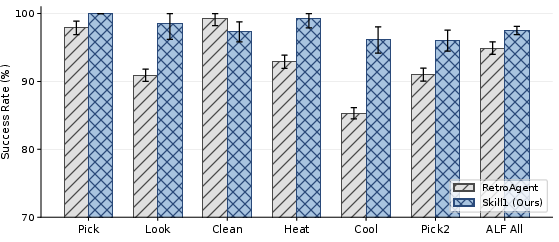
- Higher success rates: On ALFWorld, Skill1 reaches about 97.5% success, beating previous best methods. It also performs best or near‑best on WebShop.
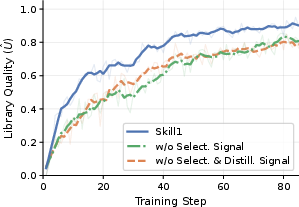
- Everything improves together: Over training, skill choosing, skill using, and skill making all get better at the same time. When they removed any one of the credit signals, all three parts got worse.
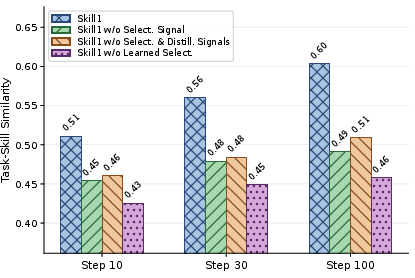
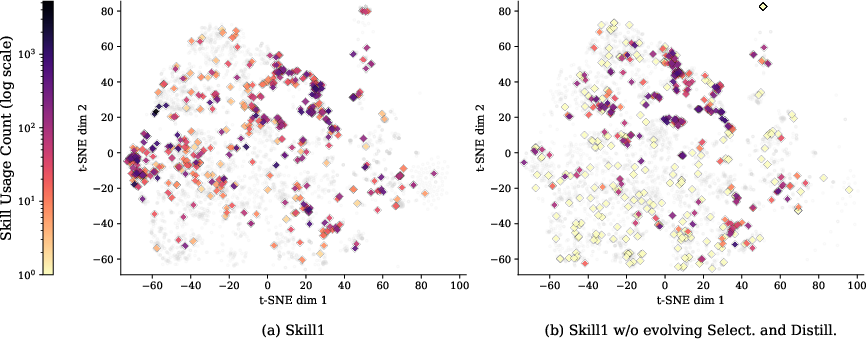
- Better skill libraries: The library grows with diverse, genuinely helpful skills rather than repeating the same kind of tip. The agent uses more of its skills instead of relying on just a few.
- Reasonable cost: Training is slower than not having a skill library, but the gains in performance are significant. Distilling concise skills helps keep the library efficient.
Why this is important
- Reuse beats starting from scratch: Instead of re‑figuring out a plan every time, the agent builds a memory of good strategies and applies them fast.
- One clear goal prevents conflicts: Using a single “did you finish the task?” signal keeps all parts aligned, avoiding mixed messages from different reward sources.
What does this mean for the future? (Implications and limitations)
Implications
- More capable assistants: Agents could learn reusable tips for coding help, web research, or app navigation—speeding up complex tasks over time.
- Less hand‑holding: Because Skill1 uses just the task outcome, it needs fewer special rules, labels, or teacher models.
- Lifelong learning: As tasks vary, the agent’s playbook improves, making it more adaptable and efficient.
Limitations and what’s next
- Tested on two text environments: We don’t yet know how well this works in visual or more complex worlds.
- Library size: They capped the library at 5,000 skills; very large or messy libraries may need smarter organization later.
- Compute cost: There’s extra training time to manage and learn from the library, though skill distillation helps keep it under control.
In short: Skill1 teaches an AI to pick the best strategy, use it, and write new, better strategies—all guided by one simple success signal. That unified approach makes the agent smarter, faster, and more reliable over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- External validity beyond two text-only environments: assess generalization to additional domains (e.g., more complex web tasks, procedurally generated games, software engineering agents), real websites with drift, and multi-episode tasks.
- Multimodal settings: extend the framework to environments with visual or audio observations, and evaluate how skills encode and retrieve multimodal cues.
- Single-skill conditioning per episode: investigate dynamic skill switching, sequencing, or composition within a trajectory (options/skills per subgoal, termination conditions, arbitration across skills).
- Frozen retriever
𝔈: replace the frozen encoder with a learnable retriever co-trained with the policy; compare end-to-end vs. frozen retrieval and study domain-shift robustness of retrieval embeddings. - Retrieval hyperparameters: quantify sensitivity to
K(top-K), embedding dimension, and ANN indexing choices; evaluate retrieval latency and quality at scale. - Selection credit assignment via
U(s)(EMA): analyze bias/variance from updating all co-retrieved candidates; compare updating only the selected skill vs. all candidates; study sensitivity to EMA smoothingalpha. - Popularity and self-reinforcement bias: examine whether the NDCG reward and
U(s)updates entrench early popular skills (Matthew effects) and evaluate debiasing strategies (e.g., inverse propensity weighting, uncertainty-aware updates). - Distillation credit as immediate variation
r(τ) - max U: test whether this proxy predicts future utility; run controlled “holdout” experiments where new skills are only evaluated on future tasks to validate the proxy. - Distillation under high library ceilings: when
max Uis already high, does the variation reward suppress discovery of niche but valuable skills? Explore novelty/diversity bonuses or coverage-aware objectives. - Admission policy
r(τ) = 1only: evaluate whether accepting only successful rollouts misses partially useful strategies; consider confidence-weighted or multi-criteria admission (e.g., near-miss, subgoal success). - Library maintenance and scaling: provide systematic scaling laws for performance vs. library size; compare the current retirement heuristic
U(s) * log(n(s))against alternatives (e.g., age-based decay, contextual bandits, submodular selection). - Duplicate and near-duplicate skill handling: implement and evaluate deduplication (e.g., clustering, canonicalization) to curb redundancy and improve retrieval precision.
- Hierarchical or compositional skill organization: study hierarchical libraries (skills grouped by domains/subgoals) to reduce retrieval noise and improve routing.
- Robustness to non-stationarity: assess how
U(s)EMA and retirement react to shifting task distributions; explore forgetting/refresh mechanisms for outdated skills. - Noise and sparsity of terminal rewards: evaluate robustness when
r(τ)is noisy, delayed, or dense; extend the low/high-frequency decomposition to non-binary or multi-objective rewards. - Theoretical foundations: provide formal analysis for the “trend vs. variation” credit decomposition—conditions for unbiasedness, convergence, and when it improves exploration vs. exploitation.
- Variance and stability of the ranking objective: compare the REINFORCE listwise training with lower-variance alternatives (pairwise ranking, differentiable surrogates) and off-policy corrections.
- Interference in multitask generation heads: analyze whether training a single model to produce queries, rankings, actions, and distilled skills causes gradient interference; compare with multi-head architectures or adapters.
- Early training stability and cold start: characterize behavior when the library is empty or small (e.g.,
z = ∅); design warm-start strategies and curricula to avoid early routing/pathologies. - Hyperparameter sensitivity: report thorough sensitivity analyses for
lambda1,lambda2,alpha,G(rollouts), and library capacityN_max, with guidance for choosing values across environments. - Ablations on the retriever and reward decomposition: isolate the contribution of the frozen retriever quality and the trend/variation split to final performance and co-evolution dynamics.
- Safety and failure modes: evaluate whether distilled skills encode brittle shortcuts or environment exploits; add filters or human-in-the-loop vetting for skill admission.
- Negative transfer and lock-in: measure how early suboptimal skills can hinder later learning via selection bias; explore mechanisms to encourage periodic exploration of underused skills.
- Compute and memory scaling: quantify end-to-end cost as a function of library size and retrieval parameters; explore compressed skill representations or retrieval-time pruning to control latency.
- Transfer and lifelong learning: test reusing a library across different tasks/domains (cross-environment transfer), continual updates without catastrophic interference, and performance under persistent distribution shift.
- Skill interpretability and editability: assess human readability and editability of
s.stratands.desc, and whether human edits improve routing, reuse, and safety. - Alternative selection signals: evaluate credit signals based on counterfactuals (e.g., bandit-style off-policy evaluation of unselected skills) instead of EMA over co-retrieved items.
- Mid-trajectory fallback and recovery: introduce mechanisms to detect poor skill choices and switch or refine skills during execution, and study the trade-offs with increased control complexity.
Practical Applications
Immediate Applications
The following use cases can be deployed today in settings where tasks are text-centric, have clear success/failure signals, and allow agents to reuse and evolve natural-language “skills” from past episodes.
- E-commerce shopping and product search assistants (Retail): Skill libraries encode effective query refinement, comparison, and purchase strategies (validated on WebShop); Potential tools/products: shopping chatbots that improve routing to “find similar,” “filter by spec,” “compare across sellers”; Dependencies/assumptions: sandboxed web environments or APIs with measurable success (e.g., correct item purchased), reliable embedding retrieval for skill search, logs for distillation; safe admission policy (only admit skills from successful rollouts).
- Customer support triage and resolution macros (Software, Telecom, Utilities): Distill reusable resolution strategies from solved tickets and route new tickets to the best “playbook” skill; Potential tools/products: “SkillOps for Support” that auto-retrieves and ranks runbook-like skills and continuously improves them from outcomes; Dependencies/assumptions: labeled resolution outcomes (closed/CSAT), access to case histories and SOPs, guardrails to prevent low-quality skill admission, privacy controls.
- Back-office robotic process automation (RPA) for repetitive workflows (Finance/Ops/HR): Encode and reuse multi-step procedures for invoice matching, reconciliations, onboarding, etc.; Potential tools/products: agents that select the right procedure skill and adapt it to each case; Dependencies/assumptions: deterministic or simulatable environments (forms, APIs), pass/fail checks (e.g., reconciliation balances), reliable tool-use integration.
- Test-driven coding assistants with reusable fix/refactor skills (Software/DevTools): Learn and route to skills like “resolve import errors,” “refactor loops,” “write unit tests,” with outcome reward from tests passing; Potential tools/products: IDE plugins that maintain a skill library and use CI results as ; Dependencies/assumptions: stable unit/e2e tests as outcome signals, repository-level context for retrieval, secure code handling.
- DevOps/SRE incident runbook agents (IT Operations): Route incidents to historical runbook skills and distill new runbooks when novel fixes succeed; Potential tools/products: incident bots that re-rank candidate runbooks by utility trends and maintain retirement heuristics; Dependencies/assumptions: clear incident resolution signals, integrations with observability and ticketing, human-in-the-loop approval for new/changed runbooks.
- Enterprise knowledge workflows and SOP execution (Knowledge Management): Convert SOPs and high-performing execution traces into concise skills for future reuse; Potential tools/products: “Skill library” layer on top of knowledge bases that retrieves scenario-matched strategies and continuously distills improvements; Dependencies/assumptions: accessible SOPs and usage logs, vector search quality, governance for updating canonical procedures.
- Analytics/report generation with reusable analysis templates (Data/BI): Skills capture effective query patterns and visualization sequences; Potential tools/products: analytics copilots that pick the best skill for data cleaning, feature engineering, or KPI dashboards; Dependencies/assumptions: deterministic checks (e.g., validation assertions) as outcome signal, reproducible notebook/SQL execution.
- Sales operations and CRM assistants (Sales/Marketing): Reusable skills for prospect qualification, email sequencing, and objection handling conditioned on account context; Potential tools/products: CRM-integrated agents that route to proven playbooks and retire low-utility ones; Dependencies/assumptions: proxy outcome metrics (e.g., reply/open rates), privacy and compliance (PII handling).
- Education content assembly and micro-tutoring (Education): Skills represent “teaching strategies” for specific misconceptions or topics; Potential tools/products: tutoring agents that retrieve the best strategy and distill new ones when a quiz or formative check succeeds; Dependencies/assumptions: measurable outcomes (quiz correctness), curriculum-aligned skill descriptions, content safety review.
- Web QA/testing bots for UI workflows (Quality Engineering): Skills for UI navigation and DOM state checks; Potential tools/products: browser automation agents that select reusable interaction strategies per app; Dependencies/assumptions: sandboxed test environments with pass/fail assertions, consistent selectors, CI/CD integration.
- Agent benchmarking and algorithmic research (Academia): Use Skill1’s unified objective and credit assignment to study co-evolution dynamics and to build new benchmarks; Potential tools/products: open-source training pipelines with GRPO, utility tracking dashboards, ablation suites; Dependencies/assumptions: simulators with clear terminal rewards (e.g., ALFWorld-like tasks), compute budget for RL fine-tuning.
- Skill lifecycle management and governance (“SkillOps”) (Cross-sector): Operationalize the library—utility tracking, NDCG-based ranking evaluation, retirement policies, and audit trails; Potential tools/products: dashboards and APIs for U(s), selection precision, distillation acceptance criteria; Dependencies/assumptions: centralized skill registry, vector index, role-based access control, versioning.
Long-Term Applications
These applications require additional research, safety measures, scaling, or multimodal integration beyond the paper’s text-based environments and 5k-skill library.
- Clinical decision support and healthcare administration (Healthcare): Route to validated care-pathway skills and evolve prior-auth/coding workflows; Potential tools/products: CDS agents that retrieve and adapt clinical runbooks under oversight; Dependencies/assumptions: regulatory compliance, human signoff, high-fidelity outcomes (beyond binary), robust guardrails for distillation, domain-curated libraries.
- Autonomous trading and advisory agents (Finance): Skills for order execution, risk hedging, and compliance checks learned from backtests/simulations; Potential tools/products: backtesting-integrated skill evolution engines; Dependencies/assumptions: safe offline RL/simulation signals (to avoid live market risk), stringent compliance, interpretability and auditability of skill changes.
- Embodied robotics with language-mediated skill libraries (Robotics): Map natural-language skills to control primitives for manipulation and navigation; Potential tools/products: robot controllers that retrieve “pick-and-place” or “clean-and-inspect” strategies and continually distill improved variants; Dependencies/assumptions: multimodal perception-action loops, sim-to-real transfer, shaped rewards, temporal credit assignment in noisy environments.
- Autonomous cyber-defense runbook evolution (Security): Co-evolve IR and detection skills from successful mitigations; Potential tools/products: SOC copilots that retrieve and adapt response playbooks; Dependencies/assumptions: adversarial robustness, strict approval workflows, red-teaming for skill admission, high-quality ground truth for outcomes.
- Personal AI for cross-app smart home and life orchestration (Consumer IoT): Skills for routines (e.g., travel booking, bill payment, home automation) that evolve from successes; Potential tools/products: assistants that route to personalized, scenario-tagged skills; Dependencies/assumptions: reliable cross-app integrations, privacy-preserving logs, explicit success signals (confirmation emails, device states).
- Public-sector service navigation and policy assistants (Government/Policy): Skills to navigate benefit applications or public services; Potential tools/products: e-gov chatbots that retrieve best-known application strategies and distill improvements; Dependencies/assumptions: standardized APIs, secure handling of citizen data, outcome verification, bias and accessibility audits.
- Scientific workflow automation and lab assistants (R&D/Pharma/Materials): Skills for experimental protocols, data cleaning, and analysis pipelines; Potential tools/products: ELN-integrated agents that reuse and refine protocols based on experiment outcomes; Dependencies/assumptions: multimodal data handling, stringent reproducibility, physical lab integration for outcome signals.
- Cross-organization skill marketplaces with trust and provenance (Platforms): Share, rate, and transact on skills with utility metrics; Potential tools/products: skill registries with signing, provenance, and differential privacy; Dependencies/assumptions: IP and security standards, sandboxed evaluation for U(s), governance for malicious or stale skills.
- Multimodal agentic systems (Vision/Language/Audio): Extend Skill1 to skills conditioned on images, videos, or sensor streams (e.g., document understanding, visual inspection); Potential tools/products: multimodal retrieval and trend tracking for skills; Dependencies/assumptions: multimodal encoders for retrieval, outcome signals with partial observability, compute scaling.
- Ultra-large, hierarchical skill libraries (Platforms/Infra): Scaling beyond 5,000 skills with hierarchical indexing, sharding, and advanced eviction; Potential tools/products: vector DB-backed hierarchical routing, learned retrieval encoders; Dependencies/assumptions: specialized indexing, latency-aware selection, new credit assignment for overlapping/hierarchical skills.
- Open-world web agents and tool ecosystems (General Automation): Agents that perform broad web tasks with evolving skill sets (search, fill forms, compare terms); Potential tools/products: browser-native agents with safe sandboxes and real-time monitoring; Dependencies/assumptions: robust tool APIs, dynamic content handling, reliable success detection, security sandboxing.
Notes on Core Assumptions and Dependencies Across Applications
- Measurable outcome signal: Skill1’s training depends on a task-outcome reward —binary or scalar—available per episode or via proxy (tests passing, ticket closed, form submitted).
- Text-centric environments: The paper’s results are on text-only simulators (ALFWorld, WebShop). Multimodal or embodied deployments require additional perception and control integration.
- Retrieval quality: A frozen encoder (e.g., sentence-transformer) underpins candidate skill retrieval; poor embeddings reduce selection quality and co-evolution efficacy.
- Compute and data: RL fine-tuning with GRPO and multiple rollouts per task needs non-trivial compute and logging infrastructure; production deployments should budget for training, evaluation, and monitoring.
- Safety and governance: Only admit skills distilled from successful trajectories; implement audit trails, versioning, and retirement heuristics (as in the paper) and add domain-specific guardrails for safety-critical contexts.
- Library management: Capacity limits, eviction strategies, and indexing impact latency and performance; scaling may require hierarchical or learned retrieval beyond top-K similarity search.
Glossary
- Ablation: The controlled removal or disabling of components to assess their impact on performance. "ablations show that removing any credit signal degrades the evolution."
- ALFWorld: A text-based household environment for evaluating interactive agents on multi-step tasks. "Experiments on ALFWorld and WebShop show that Skill1 outperforms prior skill-based and reinforcement learning baselines."
- Co-evolution: Simultaneous improvement of multiple capabilities under a shared training signal. "Training dynamics confirm the co-evolution of the three capabilities,"
- Credit assignment: The process of attributing observed outcomes to specific decisions or components for learning. "We achieve co-evolution of all three capabilities through credit assignment on a single task-outcome signal ."
- Exponential moving average: A running average that weights recent outcomes more heavily to smooth trends over time. "updated after each rollout via exponential moving average:"
- Frozen encoder: A retrieval or representation model whose parameters are kept fixed during training. "A frozen encoder retrieves the top- candidates by semantic similarity:"
- GRPO: Group-Relative Policy Optimization; a reinforcement learning method for training LLM agents using group-normalized advantages. "We train with GRPO under and lr ."
- High-frequency variation: Rapid deviations of outcomes around a trend, used here to credit improvements from new skills. "Its low-frequency trend credits selection and its high-frequency variation credits distillation."
- Intrinsic rewards: Auxiliary rewards not directly tied to the external task outcome, often used to guide learning. "RetroAgent optimizes utilization and distillation with separate intrinsic rewards but provides no gradient signal for selection."
- Low-frequency trend: A smoothed baseline of outcomes across episodes, used here to estimate consistent skill utility. "Its low-frequency trend credits selection and its high-frequency variation credits distillation."
- Normalized discounted cumulative gain (NDCG): An information-retrieval metric that evaluates ranking quality against graded relevance. "Here we use normalized discounted cumulative gain (NDCG) as the rubric:"
- Observation function: In a POMDP, the mapping from hidden environment state to the agent’s partial observation. "The observation function exposes a partial view ,"
- Policy gradient: A family of RL methods that directly optimize policy parameters via gradient ascent on expected return. "so selection is directly optimizable through the policy gradient."
- POMDP: Partially Observable Markov Decision Process; a framework for decision-making with hidden state and partial observations. "We formulate the skill-augmented agent learning problem as a POMDP~\citep{pomdp-survey} ."
- REINFORCE-style objective: A Monte Carlo policy gradient objective using sampled returns to weight log-probabilities. "We thus optimize each permutation independently with a REINFORCE-style~\citep{reinforce} objective:"
- Re-ranking: Ordering retrieved candidates to select the most appropriate item for a task. "The policy then re-ranks these candidates by generating a permutation"
- Retirement score: A criterion for evicting skills from the library that balances utility and usage frequency. "the skill with the lowest retirement score is removed,"
- Rollout: A sampled episode of interaction with the environment, producing a trajectory for learning. "For each task, rollouts are sampled independently, each performing its own selection, utilization, and distillation."
- Semantic similarity: A measure of how similar two texts are in meaning, used for retrieval. "retrieves the top- candidates by semantic similarity:"
- Skill distillation: Condensing a successful trajectory into a reusable natural-language strategy and its applicability conditions. "and skill distillation, where the agent derives new reusable skills from the trajectories."
- Skill library: A persistent collection of reusable strategies (skills) accumulated from past experience. "A persistent skill library allows LLM agents to reuse successful strategies across tasks."
- Skill selection: Choosing an appropriate skill from the library to guide task execution. "skill selection, where the agent selects a relevant skill from the library for the current task;"
- Skill utilization: Executing actions conditioned on a selected skill to solve the current task. "skill utilization, where the agent executes guided by the selected skill;"
- Task-outcome signal: The scalar feedback indicating task success or performance that drives learning. "All learning derives from a single task-outcome signal."
- Top-K retrieval: Selecting the K most similar candidates from a collection according to a similarity metric. "retrieves the top- candidates by semantic similarity:"
- Trajectory: The full sequence of decisions and observations in an episode. "A complete trajectory takes the form ,"
- T-SNE: A nonlinear dimensionality reduction technique for visualizing high-dimensional data. "T-SNE visualization of the skill libraries after convergence, with and without RL-trained selection and distillation."
- Utility score: A per-skill estimate of effectiveness, used to guide selection and library management. "We maintain the trend of each skill as a per-skill utility score, updated after each rollout via exponential moving average:"
Collections
Sign up for free to add this paper to one or more collections.