SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Abstract: Agent skills, structured packages of procedural knowledge and executable resources that agents dynamically load at inference time, have become a reliable mechanism for augmenting LLM agents. Yet inference-time skill augmentation is fundamentally limited: retrieval noise introduces irrelevant guidance, injected skill content imposes substantial token overhead, and the model never truly acquires the knowledge it merely follows. We ask whether skills can instead be internalized into model parameters, enabling zero-shot autonomous behavior without any runtime skill retrieval. We introduce SKILL0, an in-context reinforcement learning framework designed for skill internalization. SKILL0 introduces a training-time curriculum that begins with full skill context and progressively withdraws it. Skills are grouped offline by category and rendered with interaction history into a compact visual context, teaching he model tool invocation and multi-turn task completion. A Dynamic Curriculum then evaluates each skill file's on-policy helpfulness, retaining only those from which the current policy still benefits within a linearly decaying budget, until the agent operates in a fully zero-shot setting. Extensive agentic experiments demonstrate that SKILL0 achieves substantial improvements over the standard RL baseline (+9.7\% for ALFWorld and +6.6\% for Search-QA), while maintaining a highly efficient context of fewer than 0.5k tokens per step. Our code is available at https://github.com/ZJU-REAL/SkillZero.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Skill0: In-Context Agentic Reinforcement Learning for Skill Internalization”
What is this paper about?
This paper is about teaching AI agents (like smart chatbots that can act) to truly “learn” useful skills instead of constantly reading instructions from a long prompt. The authors introduce Skill0, a training method that helps an AI practice with written skills at first and then gradually removes those instructions, so the AI can perform tasks on its own without extra hints.
The big questions the paper asks
- Can we move from “using skills at runtime” (copying tips into the prompt every time) to “knowing the skills” (the model remembers them and acts independently)?
- How do we give enough guidance for the AI to learn complex, multi-step tasks, but still make sure it doesn’t become dependent on that guidance forever?
- Can we make the AI faster and cheaper to run by using much shorter prompts?
How the method works (in simple terms)
Think of teaching someone to ride a bike:
- At first, you use training wheels (written skills added to the AI’s prompt).
- As they get better, you slowly raise the training wheels off the ground.
- Eventually, you remove them entirely—and they ride on their own.
Skill0 follows the same idea for AI agents:
- The problem with “skills at runtime”
- They can be noisy: sometimes the retrieved tips are irrelevant or wrong.
- They are expensive: long prompts cost time and memory, especially in multi-step tasks.
- They don’t stick: the AI is just following instructions, not truly learning.
- The Skill0 solution
- Start with skills in the prompt during training, then gradually remove them.
- Only keep skills that are still helping the model learn; drop the ones that no longer help.
- By the end, the AI uses no extra skills at all—this is called “zero-shot” (no hints at runtime).
- Key ideas inside Skill0
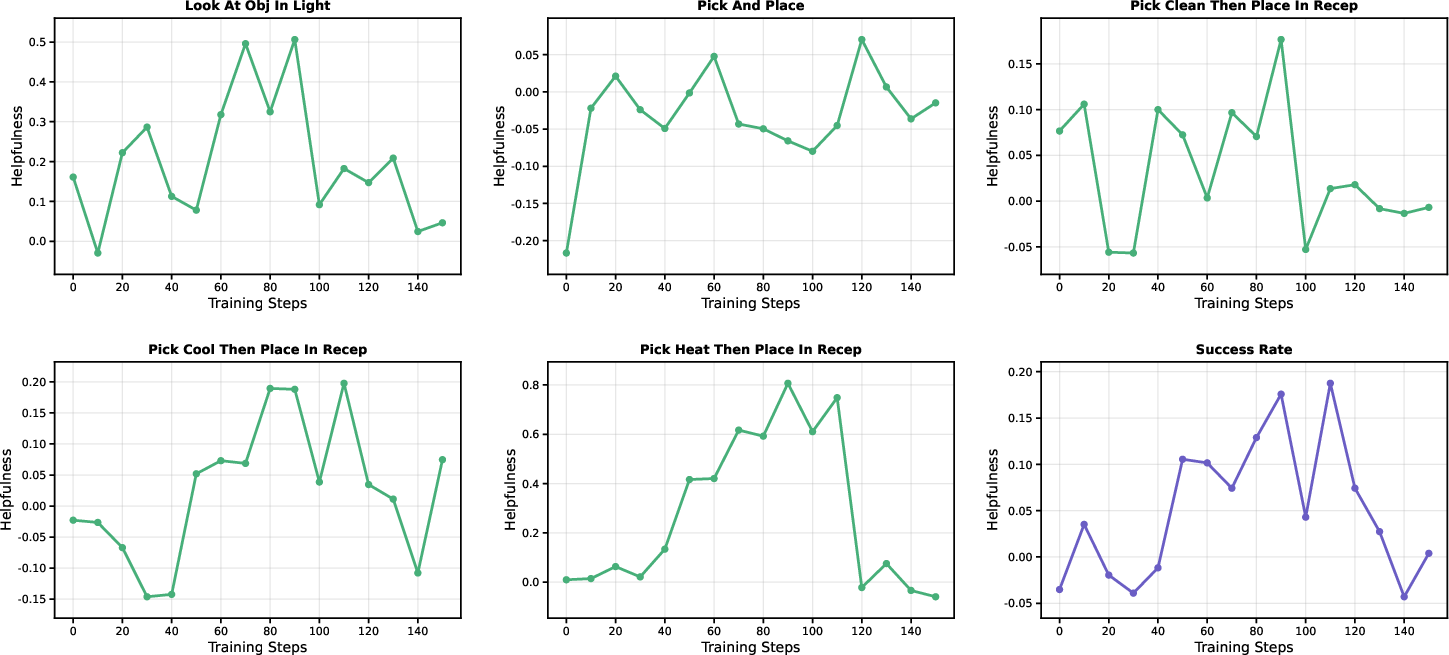
- Dynamic Curriculum: Every so often, the system checks whether each skill is still useful by comparing performance with and without that skill. If a skill stops helping, it’s removed. Over time, the “skill budget” shrinks to zero.
- Visual Context Rendering: Instead of stuffing lots of text into the prompt, the system compresses the history and selected skills into a compact “picture-like” representation. It’s like turning a long study guide into a neat cheat-sheet image. This saves a lot of space.
- Smart Compression: The agent also decides how much to compress this context. It gets rewarded not just for finishing tasks, but also for keeping the context small, encouraging efficiency.
- In-Context Reinforcement Learning (ICRL): The agent practices tasks step by step, tries actions, gets feedback (rewards), and improves its policy. At first it learns with skill prompts, and as training progresses, those prompts fade away, forcing the knowledge to be internalized.
What did they test and what did they find?
They tested Skill0 on two types of tasks:
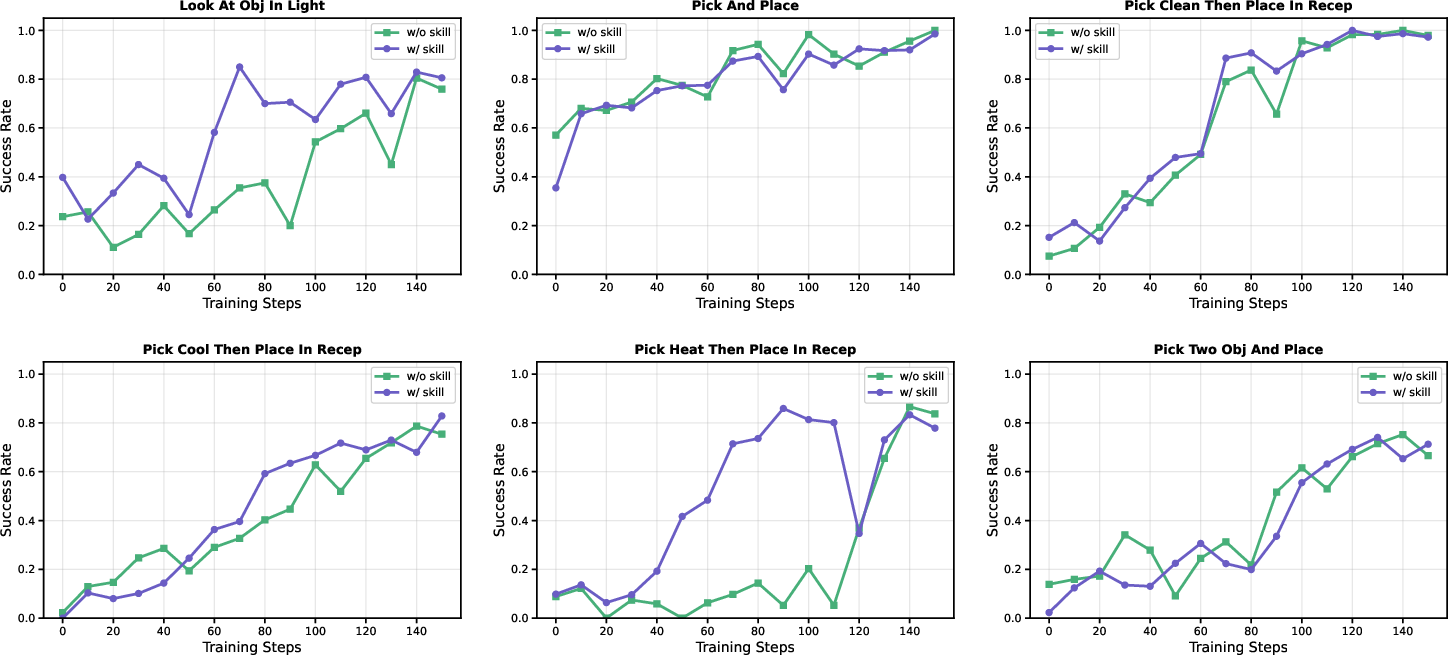
- ALFWorld: A text-based “virtual home” where the agent must do chores like picking up, cleaning, heating, and placing items—a lot of multi-step planning.
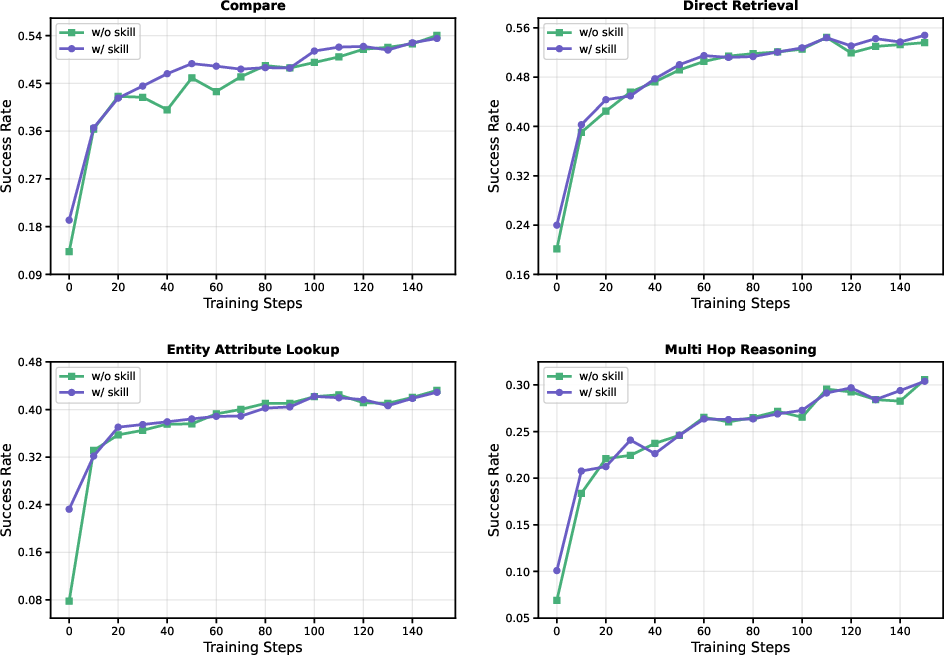
- Search-QA: Answering questions by searching the web (single-hop and multi-hop questions).
Main results:
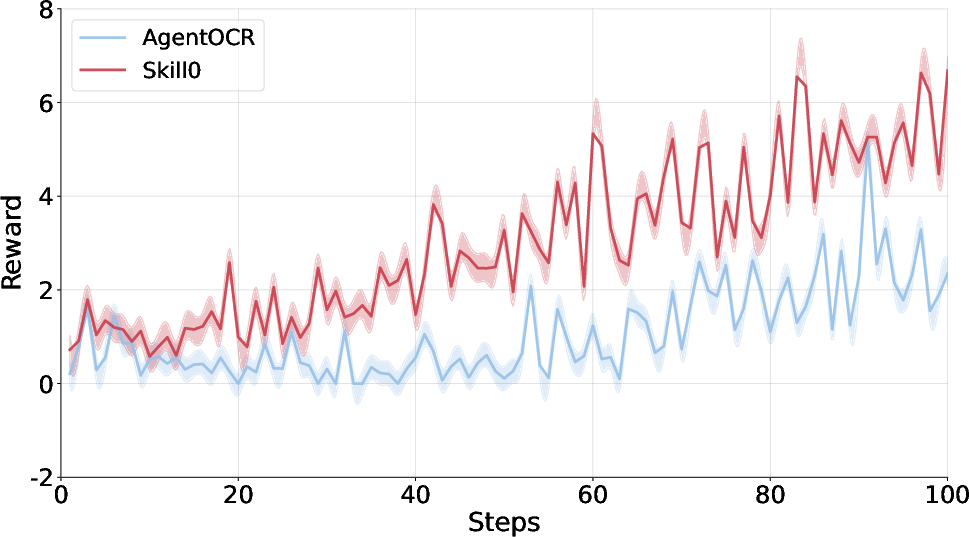
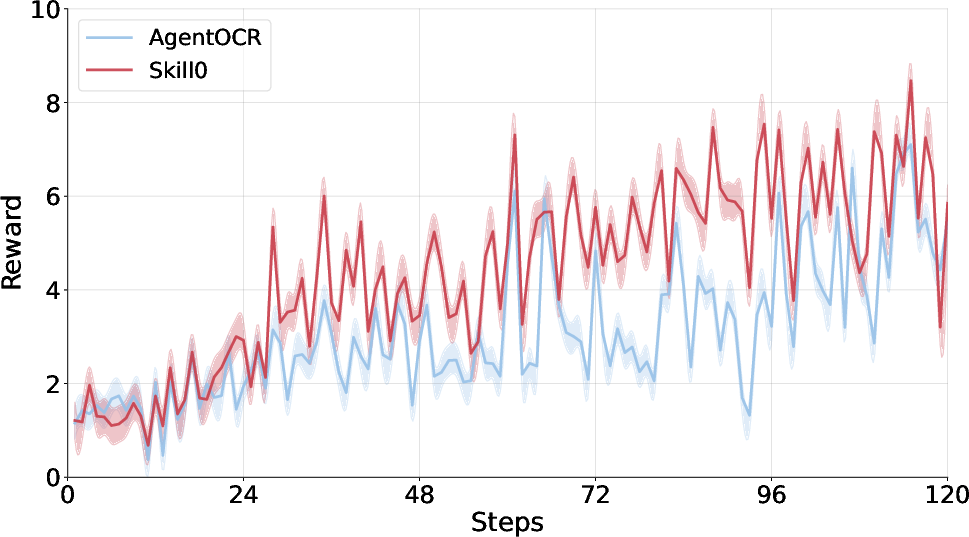
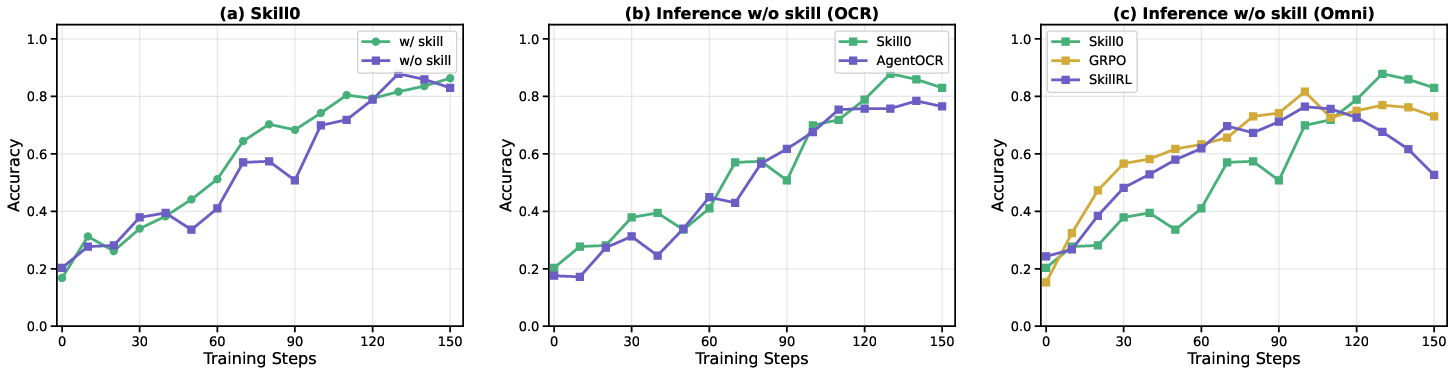
- Better success rates than strong reinforcement learning baselines:
- About +9.7% improvement on ALFWorld.
- About +6.6% improvement on Search-QA.
- Much lower “context cost” during use:
- Fewer than 0.5k tokens per step on average—far less than methods that keep injecting skills.
- No skills at test time:
- Skill0 trains with skills but removes them completely at inference. Despite that, it still performs very well, showing the skills were truly learned, not just copied.
Why this matters:
- The agent becomes more autonomous and reliable because it doesn’t depend on long prompts full of instructions.
- Running the model becomes cheaper and faster because prompts stay short.
- The training process encourages deep learning of strategies, not superficial prompt-following.
Why this is important
- It’s a step toward AI agents that can remember and apply skills on their own.
- It reduces the need for complicated skill-retrieval systems at runtime.
- It helps prevent errors from noisy or irrelevant instructions.
- It scales better: shorter prompts are easier to handle, especially in long, multi-turn tasks.
Limits and future impact
- Skill0 depends on having a decent initial set of skills to train with. If the skill library is poor or badly organized, training can suffer.
- Grouping skills to the right validation tasks takes effort, and may need re-doing for new domains.
Overall, Skill0 shows a practical way to move from “skills in the prompt” to “skills in the model,” making AI agents more independent, efficient, and ready for real-world use.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved, intended to guide future research directions.
- SkillBank dependence and construction: The method assumes a high-quality, pre-existing SkillBank and does not address how to automatically discover, curate, de-duplicate, or evolve skills from trajectories or external corpora.
- Offline relevance grouping scalability: Mapping each skill file to a “dedicated” validation sub-task requires manual or heuristic grouping; it is unclear how this scales to thousands of skills, multi-skill tasks, or many-to-many skill–task relationships.
- Skill interaction and credit assignment: The helpfulness metric Δk is measured skill-by-skill (w/ vs w/o), ignoring synergistic or redundant interactions among skills; combinatorial selection, joint credit assignment, and interaction-aware pruning are not explored.
- Helpfulness estimation robustness: Δk relies on accuracy deltas over small validation subsets without uncertainty estimates; there is no statistical testing, confidence intervals, or noise-robust selection (e.g., bootstrapping, Bayesian treatment, or hysteresis to avoid thrashing).
- Curriculum budget design: The budget linearly decays and is global; the paper does not study adaptive schedules (e.g., bandit or performance-triggered), per-domain/per-skill budgets, or rollback mechanisms when premature pruning harms learning.
- KL reference and regularization: The choice of reference policy πref, the KL coefficient β, and their effect on stability, exploration, and final performance are not analyzed or ablated.
- Reward shaping clarity and sensitivity: The composite reward (success plus ln(ct) term) has sign/interpretation ambiguities for encouraging compression; there is no sensitivity study over λ, nor analysis of the trade-off between performance and compression under different λ.
- Compression action learning: The policy co-optimizes actions and the compression ratio ct, but there is no ablation comparing learned vs fixed ct, nor analysis of ct dynamics, calibration, or effects on stability and performance across tasks.
- Visual context rendering details and fairness: The vision encoder Enc design, training/fine-tuning status, resolution limits, and robustness to text density are under-specified; fairness vs text-only baselines (compute/FLOPs, patch tokens, latency) is not rigorously controlled.
- Compute and efficiency accounting: Token savings are reported, but end-to-end compute costs (image encoding, VLM inference, wall-clock time, FLOPs) and throughput/latency comparisons to baselines are missing.
- Generalization beyond evaluated domains: Evidence is limited to ALFWorld and Search-QA; it remains unclear how Skill0 performs on long-horizon web automation, GUI control, robotics, or novel tool APIs not seen during training.
- OOD robustness and novelty: The approach is not tested on tasks requiring entirely new skills/tools (zero-shot skill transfer) or adversarial OOD shifts; how internalized skills adapt (or fail) under novelty is unknown.
- Continual/online skill addition: There is no mechanism for incrementally adding skills during deployment, avoiding catastrophic interference, or re-internalizing new skills without full retraining and re-grouping.
- Safety and noisy/malicious skills: Robustness to misleading, noisy, or malicious skill files is untested; safeguards for filtering harmful skills or preventing harmful internalization are not addressed.
- Stability and reproducibility: Results lack multiple seeds, variance/error bars, or significance tests; sensitivity to dataset splits, random seeds, and hyperparameters (e.g., G, d, NS) is not reported.
- Validation leakage risk: The helpfulness-driven selection uses a validation subset derived from the same distributions; potential overfitting to this validation for curriculum decisions is not analyzed.
- Skill coverage and representativeness: The composition, diversity, and coverage of the initialized SkillBank (sourced from SkillRL) are not documented; reproducibility of the reported gains with different skill sources is uncertain.
- Many-to-many skill–task mapping: The method assumes one validation sub-task per skill file; tasks that require multiple skills or skills applicable to many tasks are not systematically handled.
- Curriculum update granularity: Although the budget decays smoothly, set membership can change abruptly at each validation; mechanisms to enforce gradual skill-set changes (e.g., inertia/regularization on selected skills) are not explored.
- Exploration strategy: The framework relies on RL but does not detail exploration enhancements (e.g., intrinsic rewards, diversity bonuses) that might be crucial when skills are withdrawn.
- Catastrophic forgetting and negative transfer: There is no longitudinal analysis of whether internalizing some skills impairs others, especially as the budget goes to zero; retention of earlier competencies is unmeasured.
- Interpretability and auditability: Methods to extract, verify, or visualize internalized skills (e.g., probing, behavior cloning from internal policy) are absent; auditing correctness and safety of internalized behaviors is open.
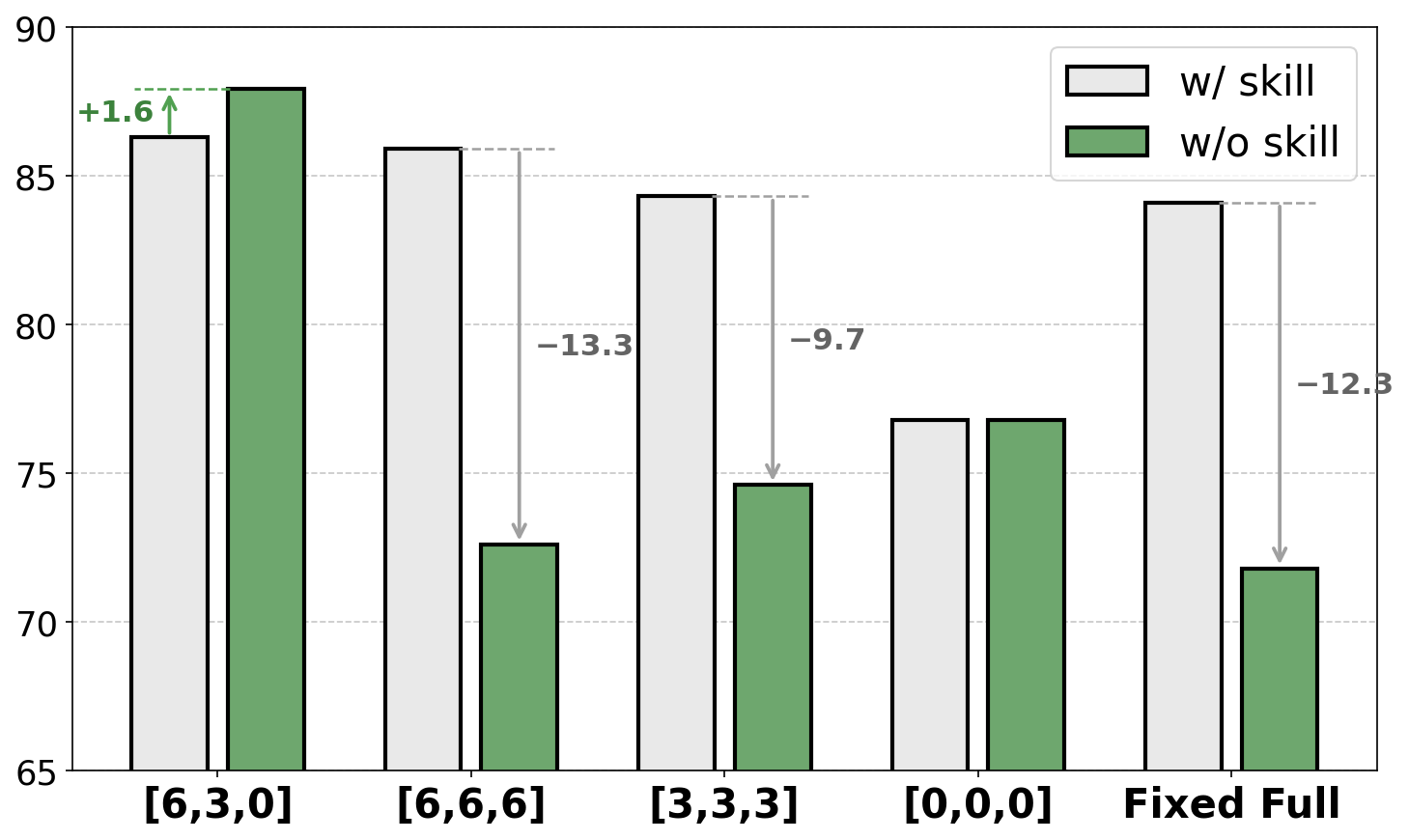
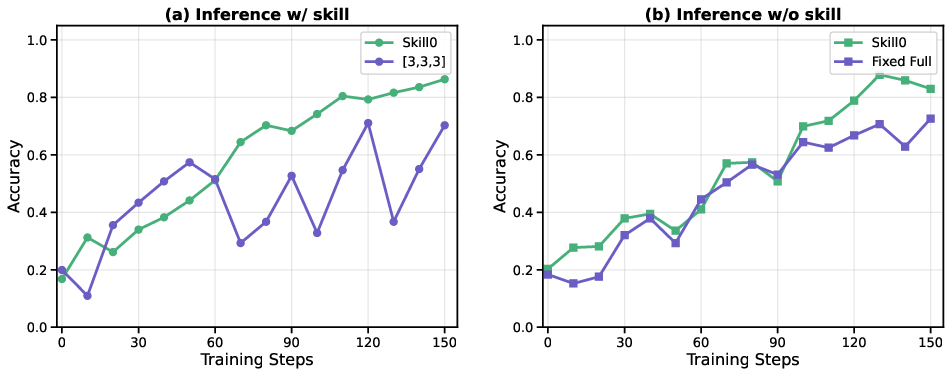
- Hyperparameter choices: The number of stages NS is fixed (3) without ablation; the impact of NS and budget sequences on convergence and final performance is unknown.
- Objective/equation clarity: Several equations contain typos/ambiguities (e.g., reward indicator, importance ratio, KL term), hindering precise replication and theoretical analysis.
- Evaluation breadth: Beyond success rates, analyses of error modes, per-category failure cases, and qualitative examples of internalized behaviors (vs prompt-following) are limited.
- Benchmark diversity and long-horizon difficulty: The evaluated tasks may not stress extremely long interaction horizons or delayed rewards; performance under sparse rewards and very long episodes remains an open question.
- Scaling laws: The behavior of Skill0 across larger model sizes, longer contexts, and larger SkillBanks (compute–performance–efficiency trade-offs) is not characterized.
- Alternative internalization routes: Comparisons to other skill-to-parameter transfer methods (e.g., supervised distillation from skill-augmented rollouts, offline RL with skill-annotated datasets) are missing.
Practical Applications
Overview
Skill0 introduces an in-context reinforcement learning (ICRL) framework and a Dynamic Curriculum to internalize “agent skills” (procedural knowledge) into model parameters, eliminating inference-time skill retrieval while maintaining high performance and low token cost. Below are practical applications derived from these findings, methods, and innovations, grouped by deployment horizon and linked to relevant sectors. Each item notes key assumptions or dependencies that influence feasibility.
Immediate Applications
The following applications can be piloted or deployed now with existing LLM/VLM backbones, a curated SkillBank, and standard MLOps.
- Cost-optimized agent deployments with zero skill retrieval — software, enterprise IT, cloud ops, finance, e-commerce (industry)
- What: Replace retrieve-then-prompt agents with Skill0-trained agents that run with <0.5k tokens/step, reducing latency and API cost while avoiding retrieval noise.
- Outcomes: 3–10× context cost reduction; improved robustness versus retrieval drift/noise; lower production errors from irrelevant skills.
- Tools/workflows: “Skill Internalizer” training job; Dynamic Curriculum Orchestrator; lightweight inference service; telemetry on success/latency.
- Assumptions/dependencies: High-quality SkillBank seeded from existing procedures; access to fine-tunable base models; evaluation harnesses for success signals.
- Search QA and research assistants with internalized workflows — software, search, education (industry/academia/daily life)
- What: Train assistants to internalize multi-hop search strategies (query planning, evidence aggregation) for question answering and study support.
- Outcomes: Higher accuracy on in-domain QA; fewer brittle prompt chains; predictable inference budgets.
- Tools/workflows: Retriever (e.g., BM25/E5) kept simple or optional; ICRL reward from task success; curated validation sub-tasks for helpfulness scoring.
- Assumptions/dependencies: Clear success metrics; stable domains (FAQs, knowledge bases); acceptance of reduced on-the-fly novelty vs retrieval-heavy systems.
- GUI and web automation co-pilots with internalized procedures — RPA, IT helpdesk, back-office ops (industry/daily life)
- What: Skills for login flows, form filling, error recovery, and auditing internalized to enable reliable desktop/browser automation without long prompts.
- Outcomes: Higher success rates in repetitive workflows; lower supervision; improved privacy by avoiding external retrieval calls.
- Tools/workflows: Visual context renderer to compress UI history; scripted simulators for reward; cataloged SkillBank of macros/SOPs; rollout in staging VMs.
- Assumptions/dependencies: Access to representative UIs or simulators; policy-compliant sandboxing; versioning of skills across app updates.
- Call-center and back-office SOP internalization — telecom, retail, logistics (industry)
- What: Internalize routine SOPs (refunds, returns, KYC checks, ticket triage) to reduce reliance on runtime skill injection or retrieval from SOP repositories.
- Outcomes: Lower handle time; fewer context injection failures; stable performance across shifts and load spikes.
- Tools/workflows: SkillBank built from SOP docs + annotated transcripts; helpfulness evaluation per SOP; A/B tests skill-free vs skill-augmented inference.
- Assumptions/dependencies: Accurate success labels; legal approval for RL training on transcripts; drift monitoring for policy/SOP changes.
- Safer prompt governance by minimizing runtime content injection — compliance, trust & safety (policy/industry)
- What: Reduce exposure to unvetted external prompt material by shifting knowledge into parameters during training.
- Outcomes: Lower attack surface for prompt injection; clearer audit trail (training data vs runtime inputs).
- Tools/workflows: Pre-deployment skill vetting; curriculum logs for which skills were retained; change-management when SOPs evolve.
- Assumptions/dependencies: Governance for model updates; versioned SkillBank provenance; incident response playbooks for re-training.
- Academic replication and benchmarking of agentic RL under curriculum — ML research (academia)
- What: Use Skill0 as a reference pipeline to study skill internalization, curriculum schedules, and visual context compression trade-offs.
- Outcomes: Standard baselines for ALFWorld/Search-QA; ablation studies on budget schedules; open-source benchmarks for skill helpfulness.
- Tools/workflows: Released code/checkpoints; evaluation suites; logging of Δ helpfulness per skill and stage.
- Assumptions/dependencies: Access to GPUs; availability of the released SkillBank and environments; reproducible seeds and simulators.
- Edge-friendly agent deployments — IoT, field service, mobile (industry/daily life)
- What: Deploy agents on constrained hardware thanks to small inference contexts and no retrieval pipeline.
- Outcomes: Lower bandwidth and energy use; higher availability in offline/limited-connectivity scenarios.
- Tools/workflows: Quantized VLM backbones; on-device inference runtimes; compact SkillBank distilled into parameters.
- Assumptions/dependencies: Suitable model size and hardware acceleration; acceptable on-device privacy/security posture.
Long-Term Applications
These applications require further research, scaling, safety validation, or ecosystem development before broad deployment.
- Regulated-domain autonomous assistants with certified internalized skills — healthcare, finance, legal (industry/policy)
- What: Internalize regulated workflows (prior auth, claims review, AML casework, adverse event reporting) with verifiable safety and auditability.
- Outcomes: Reduced reliance on retrieval from sensitive stores at runtime; predictable behavior and latency; certifiable competence.
- Tools/products: “Skill Certification Pipeline” (traceable skill provenance, unit tests, safety cases); policy packs; offline simulators with realistic distributions.
- Dependencies/assumptions: Regulatory approval; robust red-teaming and verification; post-deployment monitoring for drift; data governance for training.
- Embodied and industrial robotics with parameterized skills — manufacturing, logistics, domestic robotics (industry)
- What: Transfer skill internalization from text/sim to visuomotor domains (pick-place, inspection, tool use) to reduce dependence on large prompt memories.
- Outcomes: Lower latency control loops; fewer context failures; improved repeatability under partial observability.
- Tools/workflows: Multimodal encoders for sensor fusion; reward shaping and safety constraints; sim-to-real transfer curricula; skill helpfulness on physical tasks.
- Dependencies/assumptions: High-fidelity simulators; safe exploration methods; hardware-in-the-loop training; reliability standards.
- Continual skill internalization with lifecycle management — enterprise AI platforms (industry)
- What: Ongoing ingest → validate → internalize → retire skills as SOPs change, with automatic re-partitioning of validation sub-tasks.
- Outcomes: Reduced regression from outdated prompts; controlled “unlearning” of deprecated procedures; predictable release cycles.
- Tools/workflows: SkillBank Manager (versioning, provenance, deprecation); Curriculum Scheduler as a managed service; CI/CD for skill-aware agent updates.
- Dependencies/assumptions: Strong MLOps; robust change detection; cost management for periodic RL tune-ups; rollback strategies.
- Standardization of agent skills and helpfulness telemetry — open standards, marketplaces (industry/policy/academia)
- What: Define portable skill packaging, metadata (scope, preconditions, risks), and helpfulness metrics for cross-org sharing and auditing.
- Outcomes: Interoperability across agents/vendors; marketplaces for vetted skills; common telemetry for evaluation and compliance.
- Tools/products: Skill package schema; Δ-helpfulness benchmarks; conformance tests; governance frameworks for sharing.
- Dependencies/assumptions: Community/consortium alignment; IP and licensing models; security review processes.
- On-device personal AI with private skill internalization — consumer, privacy tech (daily life/policy)
- What: Train or fine-tune personal agents to internalize recurring user workflows (email triage, calendar, budgeting) entirely on-device or with federated methods.
- Outcomes: Strong privacy; responsiveness without network; personalized competence that persists without prompts.
- Tools/workflows: Federated ICRL; differentially private telemetry; lightweight validation tasks; local rollback and safety rails.
- Dependencies/assumptions: Efficient training on edge; privacy-preserving reward signals; user consent and UX for updates.
- Safety-aligned curriculum learning and verification — AI safety (academia/policy)
- What: Combine skill internalization with formal verification, interpretability of internalized strategies, and fail-safe fallbacks.
- Outcomes: Measurable reduction in prompt-injection risk; bounded behavior for high-stakes tasks; certifiable training artifacts.
- Tools/workflows: Property tests for skills; counterfactual helpfulness analyses; interpretable policy probes; monitoring for distribution shift.
- Dependencies/assumptions: Mature verification techniques for LLM policies; standardized safety KPIs; regulatory acceptance.
- Hybrid RAG–internalization strategies for evolving knowledge — knowledge management, search (industry/academia)
- What: Internalize stable procedures while retaining a minimal, high-precision retrieval channel for fast-changing facts, governed by a learned “when to retrieve” policy.
- Outcomes: Best of both worlds: low cost/latency for stable steps, targeted retrieval for freshness; reduced hallucination in dynamic domains.
- Tools/workflows: Gating policies; freshness detectors; curriculum that phases out skills but preserves controlled retrieval for facts.
- Dependencies/assumptions: Reliable freshness signals; careful evaluation of trade-offs; governance for retrieval sources.
- Multi-agent skill distillation and sharing — complex workflows (industry/academia)
- What: Learn composite workflows by internalizing inter-agent protocols and then distilling them into single agents or smaller teams.
- Outcomes: Simpler orchestration; fewer runtime dependencies; robust end-to-end behavior under failures.
- Tools/workflows: Protocol-aware rewards; role-based SkillBank partitioning; cross-agent helpfulness metrics.
- Dependencies/assumptions: Stable interfaces; scalable training for multi-agent rollouts; monitoring emergent behaviors.
- Energy-efficient AI operations — sustainability (policy/industry)
- What: Use reduced-token inference and minimized retrieval to lower energy per task across fleets of agents.
- Outcomes: Measurable carbon and cost reductions; eligibility for green incentives and compliance reporting.
- Tools/workflows: Carbon accounting tied to token budgets; fleet schedulers that prioritize internalized agents.
- Dependencies/assumptions: Accurate telemetry; alignment with reporting standards; organizational buy-in.
Cross-cutting assumptions and risks
- SkillBank quality and coverage are critical; gaps or noisy skills can hinder internalization or encode undesirable behaviors.
- The visual context renderer assumes a capable vision-language backbone; pure-text models may need alternative compression strategies.
- Reward specification and success signals must be reliable; weak or sparse rewards can lead to superficial learning or brittleness.
- Domain drift requires re-validation and periodic re-training; Dynamic Curriculum depends on relevant validation sub-tasks for helpfulness measurement.
- Legal, privacy, and licensing constraints apply when training on proprietary SOPs or user data; governance and auditability must be in place.
Glossary
- Advantage: In policy gradient RL, a measure of how much better an action is compared to a baseline at a state. Example: "where the advantage is computed by normalizing the total rewards"
- Agent loop: The iterative perception–decision–action process an agent follows while interacting with an environment. Example: "To incentivize both efficient context compression and skill internalization within the agent loop"
- Agentic RL: Reinforcement learning applied to autonomous LLM agents to improve decision-making in interactive settings. Example: "agentic RL has emerged as a crucial post-training recipe for equipping LLM agents with robust decision-making capabilities"
- Annealing: A training schedule that gradually reduces or modifies a quantity (e.g., skill reliance) over time to aid learning stability. Example: "undergoes a controlled annealing process"
- Composite reward: A reward that combines multiple objectives (e.g., task success and compression efficiency) into a single signal. Example: "we introduce a composite reward ... which jointly optimizes task success and compression efficiency."
- Compression ratio: The fraction indicating how much the context is compressed when rendered into visual form. Example: "the compression ratio "
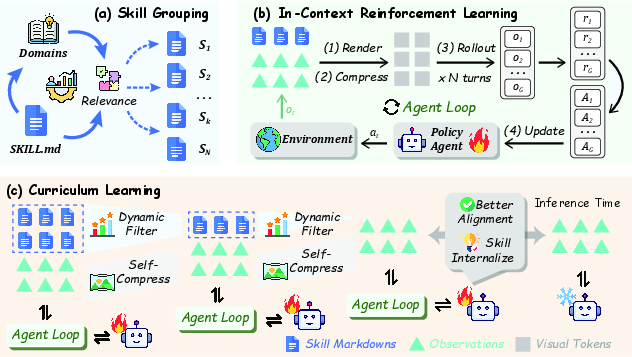
- Context rendering: Converting textual interaction history and skills into a compact image embedding to reduce token usage. Example: "we introduce a context rendering mechanism"
- Context window: The token-limited input buffer for LLM prompts and retrieved content. Example: "making direct injection into the context window inefficient"
- Curriculum learning: Structuring training in stages that adjust difficulty or support to guide learning progression. Example: "We formulate this curriculum as a linear decay of the skill budget"
- Distribution shift: A change in input/context distribution that can harm model performance if abrupt or uncontrolled. Example: "This ensures the distribution shift of the policy remains smooth and stable"
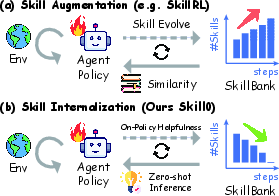
- Dynamic Curriculum: An adaptive schedule that selects and removes skills based on measured helpfulness to encourage internalization. Example: "We propose {Dynamic Curriculum}, a helpfulness-driven annealing mechanism"
- Episodic memory: A memory store of past experiences/trajectories that an agent can consult for future decisions. Example: "Skills serve as a form of episodic memory that agents can consult at decision time"
- Helpfulness metric: A measured performance difference indicating how much a skill improves the current policy on aligned sub-tasks. Example: "We quantify the helpfulness metric of each skill file to the current policy "
- In-Context Reinforcement Learning (ICRL): Using skill prompts during training with RL, then removing them at inference to drive parameter-level internalization. Example: "Skill0 introduces In-Context Reinforcement Learning (ICRL)"
- Importance sampling ratio: The ratio of probabilities under new vs. old policies for off-policy correction or PPO-style updates. Example: "is the importance sampling ratio."
- Kullback–Leibler (KL) divergence: A regularization term that penalizes deviation from a reference policy to stabilize training. Example: "\mathbb{D}{\text{KL}[\pi\theta | \pi_{\text{ref}]"
- Linearly decaying budget: A skill budget that decreases linearly across stages to wean the model off external skill prompts. Example: "retaining only those from which the current policy still benefits within a linearly decaying budget"
- Multi-turn: Tasks requiring multiple sequential interactions or steps to complete. Example: "teaching the model tool invocation and multi-turn task completion."
- On-policy helpfulness: The usefulness of a skill measured under the behavior induced by the current policy. Example: "A Dynamic Curriculum then evaluates each skill file's on-policy helpfulness"
- Policy: The mapping from states (and context) to action distributions parameterized by model weights. Example: "the current policy "
- Reference model: A fixed or slowly changing policy used as a baseline for KL regularization during RL fine-tuning. Example: "\Require Initial policy ; reference model $\pi_{\text{ref}$;"
- Reinforcement learning (RL): A learning paradigm where agents optimize actions by maximizing cumulative rewards via interaction with environments. Example: "Reinforcement learning offers a natural path to the second"
- Retrieval noise: Irrelevant or misleading information introduced by imperfect retrieval systems. Example: "retrieval noise introduces irrelevant or misleading guidance"
- Rollout: A sequence of states, actions, and rewards generated by executing a policy in an environment. Example: "This rollout continues until the task is successfully completed or the max step threshold is reached."
- Skill augmentation: Injecting retrieved skill descriptions into the prompt at inference time to guide agent behavior. Example: "The prevailing paradigm is inference-time skill augmentation"
- Skill bank (SkillBank): A hierarchical library of general and task-specific skills used during training. Example: "we organize reusable behavioral knowledge into a hierarchical skill library SkillBank"
- Skill budget: The capped number of skill files allowed in context during a curriculum stage. Example: "We split training process into progressive stages with a decreasing skill budget "
- Skill internalization: Transferring skill knowledge from prompts into model parameters so it can act without external skill context. Example: "formulates skill internalization as an explicit training objective."
- Token overhead: The extra token cost incurred by adding skills and histories to the prompt, especially in multi-step tasks. Example: "injected skill content imposes token overhead that compounds across multi-turn interactions"
- Tool invocation: The act of calling external tools/APIs as part of an agent’s action strategy. Example: "teaching the model tool invocation and multi-turn task completion."
- Trajectory: The full sequence of states, actions, and rewards for a single episode. Example: "the binary success indicator for trajectory "
- Validation sub-task: A sub-partition of validation data aligned to specific skill categories for measuring skill helpfulness. Example: "a dedicated validation sub-task"
- Visual context: A compact image-based representation of textual context and skills used to reduce token usage. Example: "into a compact visual context"
- Vision encoder: A model component that encodes rendered images of context into embeddings for the policy. Example: "the vision encoder Enc"
- Zero-shot: Performing tasks without task-specific examples or skill prompts at inference time. Example: "fully zero-shot setting"
Collections
Sign up for free to add this paper to one or more collections.