Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
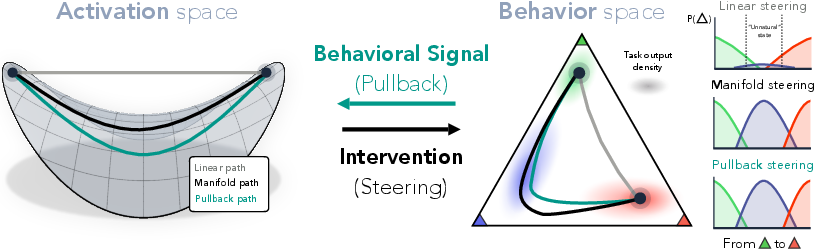
Abstract: Neural representations carry rich geometric structure; but does that structure causally shape behavior? To address this question, we intervene along paths through activation space defined by different geometries, and measure the behavioral trajectories they induce. In particular, we test whether interventions that respect the geometry of activation space will yield behaviors close to those the model exhibits naturally. Concretely, we first fit an activation manifold $M_h$ to representations and a behavior manifold $M_y$ to output probability distributions. We then test the link $M_h \leftrightarrow M_y$ via interventions: we find that steering along $M_h$, which we term manifold steering, yields behavioral trajectories that follow $M_y$, while linear steering -- which assumes a Euclidean geometry -- cuts through off-manifold regions and hence produces unnatural outputs. Moreover, optimizing interventions in activation space to produce paths along $M_y$ recovers activation trajectories that trace the curvature of $M_h$. We demonstrate this bidirectional relationship between the geometry of representation and behavior across tasks and modalities. In LLMs, we use reasoning tasks with cyclic and sequential geometries as well as in-context learning tasks with more complex graph geometries. In a video world model, we use a task with geometry corresponding to physical dynamics. Overall, our work shows that geometry in neural representation is not merely incidental, but is in fact the proper object for enabling principled control via intervention on internals. This recasts the core problem of steering from finding the right direction to finding the right geometry.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple overview
This paper asks a big question about AI models (like LLMs): do the shapes of the patterns inside a model actually cause the way it behaves? The authors show that the internal “shape” of a model’s thoughts and the “shape” of its outputs match each other. Using that idea, they propose a better way to steer a model called manifold steering: instead of pushing the model straight toward an answer, you guide it along the curved paths it naturally follows. This makes the model’s behavior smoother, more natural, and more predictable.
What questions did the paper ask?
- Do the internal representations of a model (its “hidden activations”) have a geometric shape that matters for its behavior?
- If we intervene inside the model in a way that respects this shape, will the outputs change in a smooth, sensible way?
- Is the shape of the model’s internal space and the shape of its output space essentially the same (just viewed in two different places)?
- Can this idea work across different tasks (like days of the week), different structures (grids or cycles), and even different types of models (like a video world model)?
How did they investigate?
Think of the model’s hidden activity like a city of roads and neighborhoods, and its outputs (probabilities over answers) like destinations on a map. The key idea is that the model naturally “drives” along certain roads (curved paths), not straight lines across buildings.
Key steps
- Build two maps:
- Activation map: the “roads” the model naturally uses inside its brain (hidden activations).
- Behavior map: the “roads” the model naturally uses in its outputs (probability distributions over answers).
- These maps are called manifolds. You can imagine a manifold as a smooth curve or surface that the model sticks to when it thinks.
- Fit smooth paths:
- They gathered many examples for simple, structured tasks (like “What day is 4 days after Monday?”).
- They averaged activations and outputs for each concept (e.g., Monday, Tuesday) to find “centers” for each.
- They connected these centers with smooth curves/surfaces (splines) to outline the natural paths.
- Compare two ways to steer:
- Linear steering: push the internal activations in a straight line from start to end. This ignores the natural roads.
- Manifold steering: move along the fitted activation manifold—the model’s natural road network.
- Measure “naturalness”:
- If the output path stays close to the behavior manifold (the outputs the model naturally produces), it’s “natural.”
- They used a distance-based score (you can think of it like how far the car leaves the road). Lower is better.
- Go both directions:
- Forward: steer along the activation manifold and see if outputs follow the behavior manifold.
- Reverse (pullback): pick a smooth path on the behavior manifold and find which activation path produces it. If they match, it shows a deep connection.
- Test across settings:
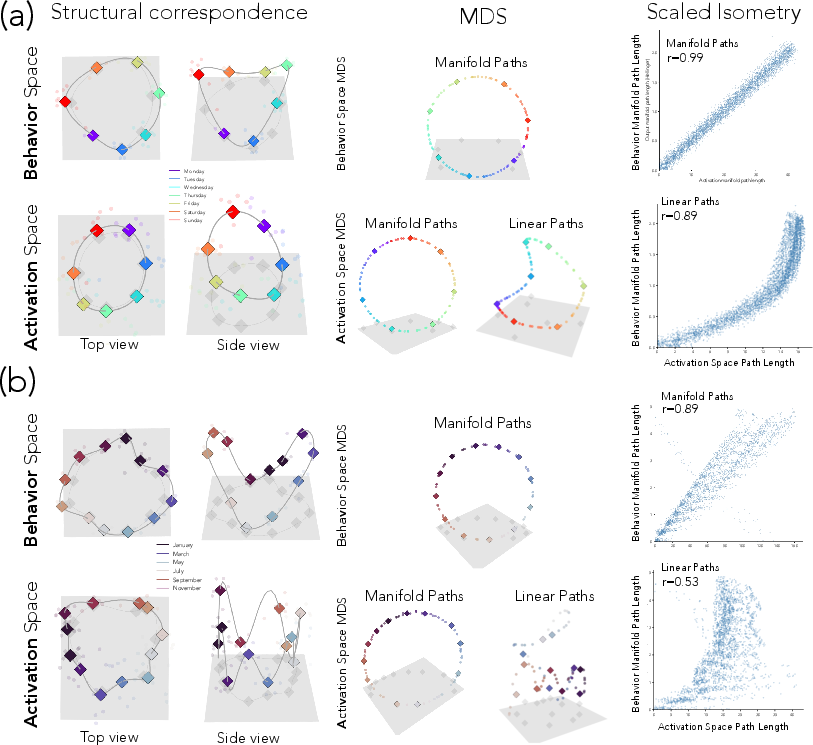
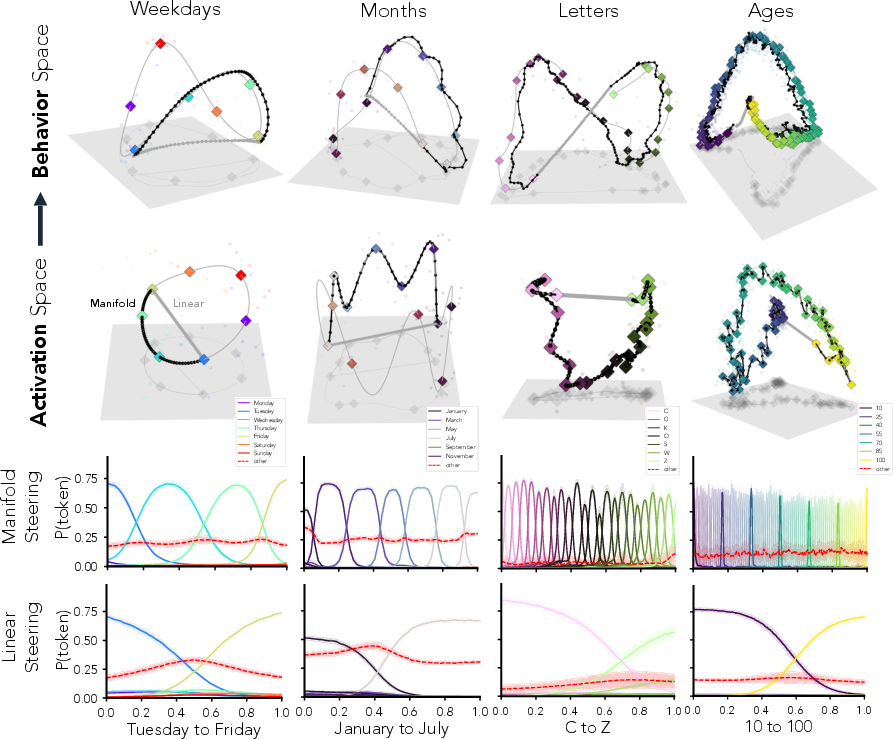
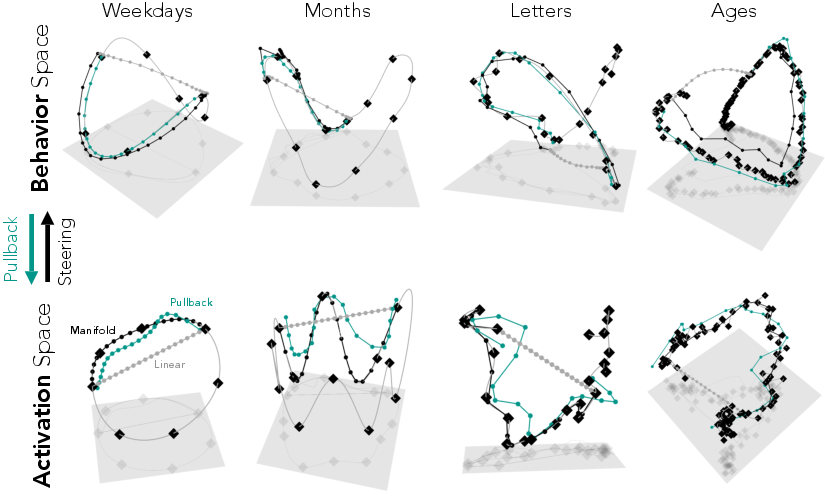
- Language tasks with known shapes:
- Cycles: weekdays, months
- Sequences: letters, ages
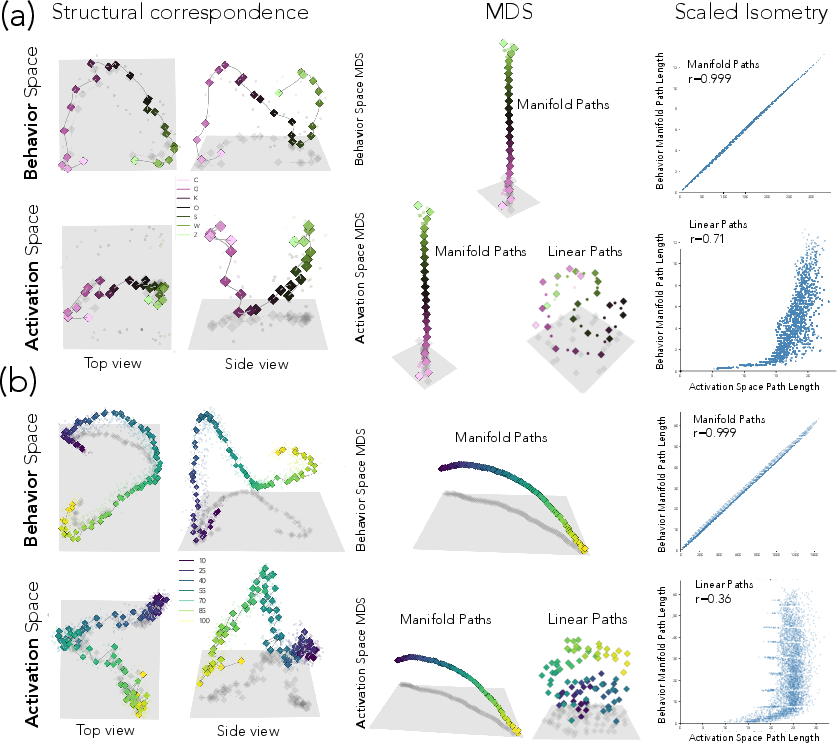
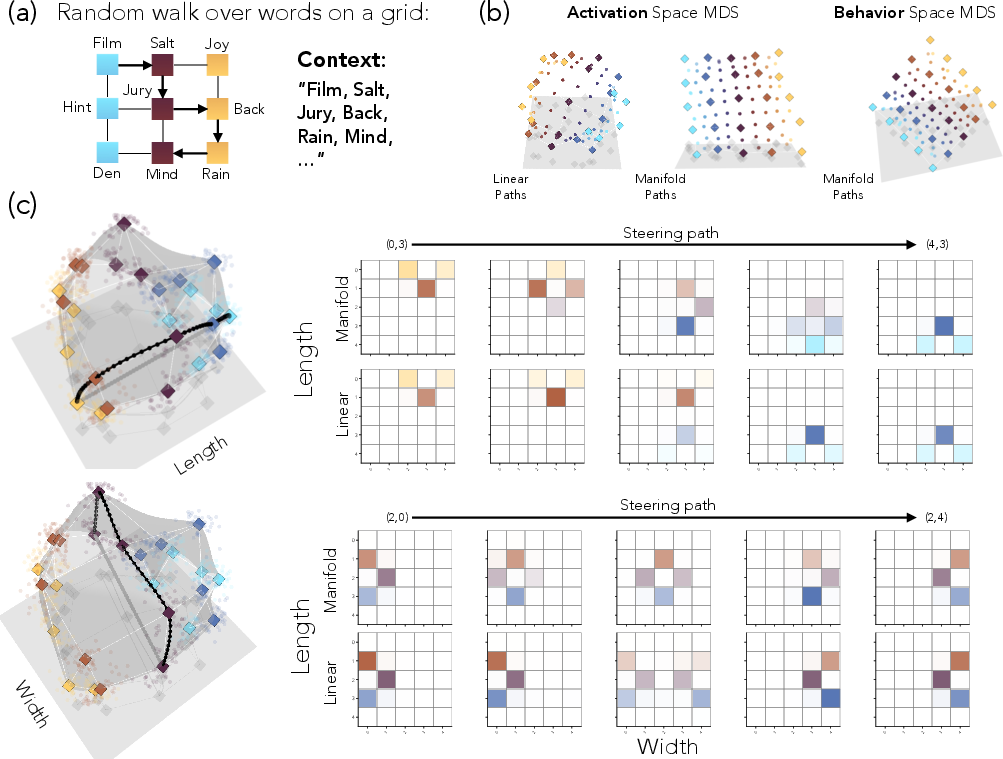
- In-context learned graphs:
- A 2D grid and a cylinder where the model learns structure from examples
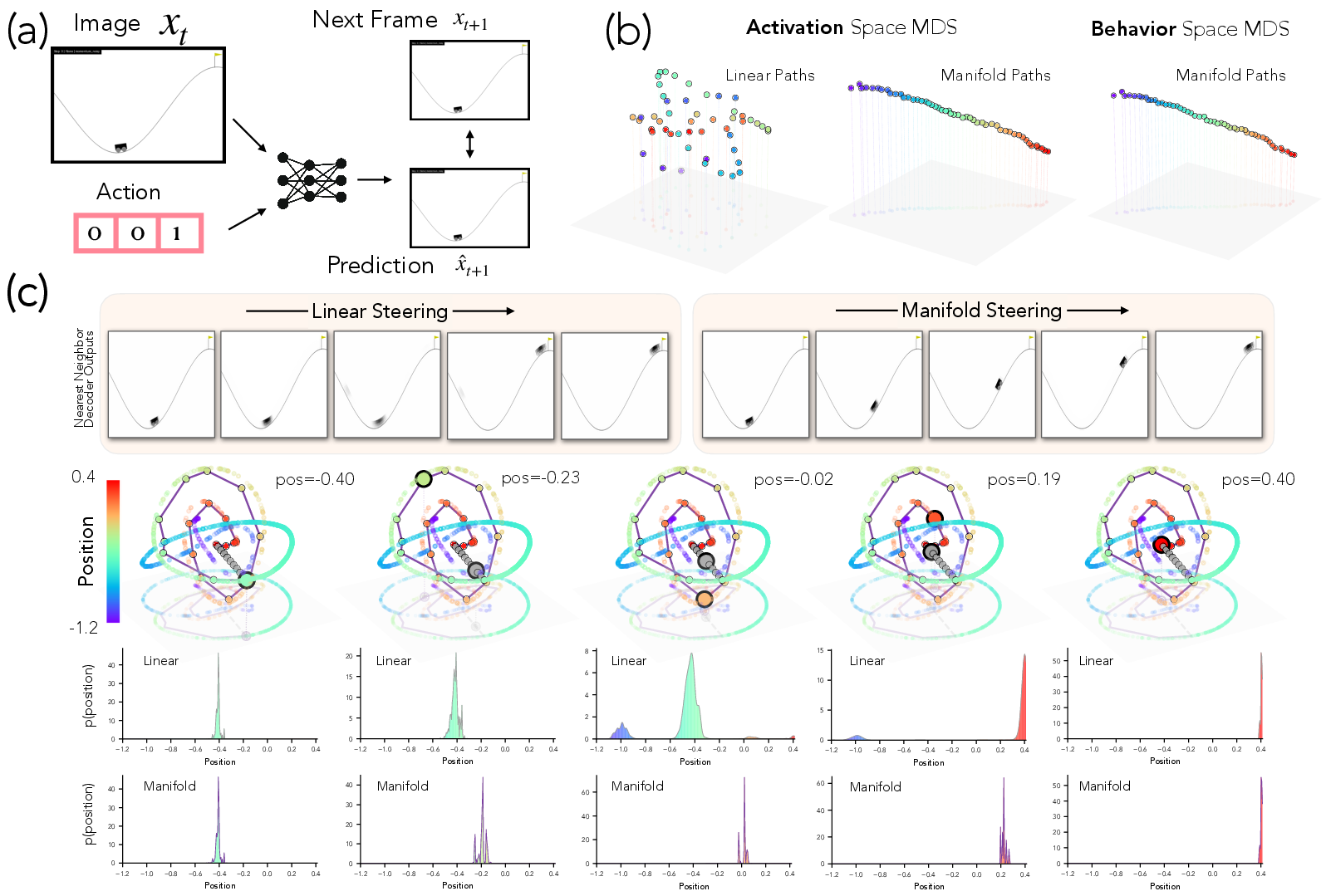
- Visual world model:
- A “mountain car” environment where a model predicts the next video frame as a car moves on hills
What did they find?
- The shapes match (almost isometric): the distances along the activation manifold closely match distances along the behavior manifold. That means the “shape” of thinking and the “shape” of output are the same, just in different places.
- Manifold steering gives smooth, ordered changes:
- Example: If you steer from Monday to Friday along the manifold, probability flows through Tuesday → Wednesday → Thursday → Friday.
- Linear steering “teleports”: probability jumps from Monday toward Friday with odd in-betweens (including unrelated tokens), producing unnatural outputs.
- More natural outputs:
- Manifold steering stays near the model’s natural behaviors (low “off-road” energy), while linear steering drifts far away (high energy).
- Reverse direction confirms the link:
- When they choose a smooth output path first and optimize activations to produce it, the best activation path bends to follow the activation manifold’s shape. This is strong causal evidence that the two manifolds are the same underlying structure.
- Works in multiple dimensions and gives factored control:
- On 2D grids learned in context, the activation and behavior manifolds both recover the grid’s layout.
- You can steer horizontally without disturbing vertical position (and vice versa). That’s clean, independent control—something straight-line steering fails to do.
- Generalizes to vision:
- In the mountain car video model, manifold steering moves the car smoothly along the hill in predicted frames.
- Linear steering creates blurry, confusing in-between frames (like the model is unsure where the car is), because it cuts across off-road regions.
Why is this important?
- Steering is about geometry, not just direction:
- The usual method pushes in a straight line and often breaks fluency or causes weird outputs.
- This work reframes steering as choosing the right geometry—the model’s natural roads—so that interventions are smooth and realistic.
- Better control, fewer side effects:
- Manifold steering changes behavior in predictable, stable ways and avoids “teleportation.”
- In multi-step reasoning or multi-dimensional concepts, it allows precise changes without messing up other parts.
- Broad impact:
- Safer, more reliable model control for tasks like style changes, personas, reasoning steps, or planning.
- Clearer interpretability: the manifolds give a compact picture of how a model organizes concepts.
- Cross-domain usefulness: it works in language, learned graph structures, and visual world models.
Takeaway
The model’s internal representations and its outputs share the same underlying geometry. If you respect that geometry—by steering along the model’s natural manifolds—you get behavior that looks and feels natural. This turns the core problem of controlling models from “find the right direction” into “find and follow the right shape.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues, uncertainties, and actionable open questions raised by the paper.
- Generalization across models: Does the observed representation–behavior isometry and the efficacy of manifold steering hold across diverse LLM families, sizes, tokenizer schemes, and non-transformer architectures?
- Layer dependence: How stable are the fitted activation/behavior manifolds and isometry relationships across layers, heads, and token positions; which layers are optimal for geometry-aware steering?
- Task breadth: Do these findings extend from simple cyclic/sequential or synthetic ICL graph tasks to richer, compositional, and semantically complex real-world tasks (e.g., multi-hop reasoning, code, tool use)?
- Behavior quality beyond concept tokens: Does manifold steering preserve full-text fluency, coherence, and usefulness (beyond distributions over concept tokens), as measured by perplexity, human evaluation, and task success?
- Off-concept “other” bucket: How much does collapsing all non-concept tokens into a single “other” class distort behavior-space geometry and the naturalness metric; are there principled alternatives?
- Metric choice in behavior space: How sensitive are results to the use of Hellinger vs Fisher–Rao or KL-based metrics; which metric best reflects a model’s notion of behavioral similarity?
- Manifold fitting sensitivity: How robust are results to PCA dimension choice, centroid construction, smoothing strength, spline/TPS hyperparameters, and sampling density; what are principled model selection/validation criteria?
- Manifold dimensionality: When conceptual geometries are higher-dimensional or have nontrivial topology (e.g., torus, tree, manifold with boundaries), how should manifolds be fit and validated?
- Isometry rigor: Beyond high correlations and MDS visuals, can the isometry be established with formal tests (e.g., Procrustes alignment of local metric tensors, sectional curvature comparisons, local distortion bounds)?
- Local vs global isometry: Are representation–behavior correspondences locally isometric but globally distorted; what are the limits of the scaled-isometry claim as paths traverse longer geodesic distances?
- Causal identification: Do interventions satisfy formal path-specific causal criteria (e.g., controlled direct effects); can we disentangle mediation through the targeted subspace from confounded pathways?
- Intervention realism: Does overwriting activations create states unattainable by natural inputs; how do results change with weaker, distributed interventions (e.g., low-rank or feature-wise modulation) or circuit-constrained patching?
- Stability under distribution shift: Do manifold paths remain natural under OOD prompts, adversarial contexts, or domain shifts; how fragile is geometry-aware steering to context variability?
- Computational scalability: What are the costs and practical algorithms for estimating densities, geodesics, and pullback metrics in high-dimensional spaces and at inference-time?
- Energy calibration: How should α, β (density geometry) and ε (pullback regularizer) be set or learned; do energy-based naturalness scores meaningfully predict downstream quality and safety across tasks?
- Learning F and its Jacobian: Can the activation-to-behavior map F and its Jacobian be estimated reliably (e.g., via local probes or Fisher information) to enable principled pullback metrics without expensive optimization?
- Optimization pitfalls: For pullback paths, how prevalent are nonconvexity, local minima, and sensitivity to initialization; can regularizers or constraints improve identifiability and robustness?
- Multi-concept entanglement: In real tasks where concepts interact (hierarchies, compositionality), do intrinsic coordinates still factor; when do steering axes interfere, and how can interference be mitigated?
- Compositional control: Do manifold geodesics compose (e.g., path concatenation, commutativity across axes) in multi-dimensional conceptual spaces; what operators provide predictable composition?
- Temporal dynamics in recurrent models: In world models, how does steering state/hidden dynamics (vs encoder latents) affect long-horizon rollouts, compounding error, and control stability in closed loop?
- From representation to policy: In the visual world model, does manifold steering improve control performance (e.g., sample efficiency or success rate) when embedded in an RL agent?
- Ambiguity and multi-modality: How does behavior geometry behave under inherently ambiguous or multi-modal outputs; do manifolds branch, and how should geodesics be defined through branching regions?
- Topology mismatches: What happens when activation-space geometry has different topology than behavior-space geometry (e.g., holes, boundaries); can the method detect and handle such mismatches?
- Safety and alignment tasks: Can geometry-aware steering improve robustness on non-toy alignment goals (harmlessness, bias mitigation, jailbreak resistance) versus stronger baselines (contrastive, RL-based, or safety-tuned methods)?
- Comparison to advanced baselines: How does manifold steering compare to state-of-the-art steering approaches (e.g., SAE-based features, contrastive decoding/activation methods, causal tracing/patching) on shared benchmarks?
- Data requirements: How many labeled concept instances are needed to fit reliable manifolds; can unsupervised or weakly-supervised methods discover geometry without explicit concept labels?
- Online/adaptive steering: Can geometry and geodesics be updated on-the-fly for new concepts or domains; can steering be learned end-to-end to track nonstationary or user-specific conceptual spaces?
- Theoretical conditions: Under what training data and architectural conditions should representation and behavior manifolds be approximately isometric; can we prove sufficiency/necessity results?
- Invariance and reparameterization: Are learned geometries invariant to reparameterizations (e.g., weight rescaling, layer norm shifts); how do such transformations affect estimated densities and geodesics?
- Robust evaluation protocols: What standardized procedures (cross-validation, bootstrapping, ablations) should be used to quantify uncertainty in manifold fits, geodesic distances, and naturalness metrics?
- Failure modes characterization: When does manifold steering fail (e.g., sparse data, weak concept salience, heavy polysemy), and can diagnostics predict failure before deployment?
- Practical deployment: What are the latency and memory overheads for real-time steering; can approximate geodesics or cached charts provide low-cost control at inference time?
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings can be used today, with proposed tools/workflows and key assumptions that affect feasibility.
- Manifold-based activation steering for safer, more fluent LLM control — sectors: software, content moderation, customer support, education, finance, healthcare, daily life
- Action: Replace linear/additive activation steering with manifold steering when controlling tone, persona, safety modes, verbosity, reading level, or domain style (e.g., “formal ↔ informal”, “concise ↔ detailed”, “lay ↔ clinician”).
- Why it works: Steering along the activation manifold produces “natural” output trajectories (low Bhattacharyya energy) and avoids off-manifold “teleportation,” reducing fluency loss and unstable side effects.
- Tools/workflows:
- Fit activation and behavior manifolds for specific control axes using the authors’ approach (PCA + cubic/Thin-Plate splines; Hellinger-space fitting for output distributions).
- Add a “geometry-aware intervention” module to existing activation-steering pipelines.
- Add an “energy-based naturalness” monitor to flag off-manifold behavior during steering.
- Assumptions/dependencies: White-box access to model activations; sufficient in-distribution data to fit reliable manifolds for the desired control axes; stability of manifolds across prompts and minor domain shifts.
- Factored, multi-attribute control panels for LLMs — sectors: software, marketing/creative, education, daily life
- Action: Use 2D (or higher-D) activation manifolds to create independent “knobs” (e.g., sentiment vs. formality; technical depth vs. length) that allow users to traverse a conceptual grid smoothly.
- Why it works: The paper’s grid/cylinder experiments show that intrinsic manifold coordinates align with conceptual dimensions and afford independent control.
- Tools/workflows:
- “Factored Control Panel” UI binding each intrinsic coordinate to a slider/joystick.
- Manifold-aware inference middleware that interpolates along geodesics in intrinsic coordinates (not in raw activation space).
- Assumptions/dependencies: Clear separation of dimensions in the learned manifold; robust thin-plate spline fitting; task contexts where multi-attribute structure is present or can be induced via in-context learning.
- Geometry-aware evaluation of steering quality — sectors: software, safety/assurance, policy compliance
- Action: Add two metrics to steering evaluations: (1) cumulative Bhattacharyya energy-to-manifold as a “naturalness” score; (2) “teleportation index” measuring non-adjacent probability jumps across concepts.
- Why it works: The paper shows lower cumulative energy and reduced teleportation for manifold steering, correlating with more human-like, stable transitions.
- Tools/workflows:
- Batch evaluation of steering trajectories vs. a behavior manifold fitted in Hellinger space.
- Dashboards comparing linear vs. manifold steering on internal benchmarks.
- Assumptions/dependencies: Access to samples for fitting behavior manifolds; careful selection of concept tokens and “other” class; agreement on task-relevant concepts.
- Model editing and fine-tuning constraints that “stay on manifold” — sectors: software, enterprise ML platforms
- Action: During post-training (e.g., PEFT/RLHF), add penalties for off-manifold activations/outputs and prefer updates that preserve geometry (geodesic-consistent moves).
- Why it works: Encourages updates that do not break the representation–behavior isometry, preserving fluency and predictability.
- Tools/workflows:
- Add geometry-aware regularizers (e.g., energy penalties, manifold distance penalties) to training loops.
- Early stopping or checkpoint selection based on manifold alignment metrics.
- Assumptions/dependencies: Reliable, task-specific manifold estimates; compute overhead tolerance for geometry terms; white-box training access.
- World-model nudging via manifold steering — sectors: robotics, simulation, gaming, AR/VR prototyping
- Action: For simple vision world models (e.g., autonomous simulator prototypes), steer latent states along position/pose manifolds to test, visualize, and correct belief trajectories (e.g., smooth location adjustments instead of pixel-space hacks).
- Why it works: In Mountain Car, manifold steering in latent space yields coherent, smooth, “on-trajectory” predictions; linear steering produces blurred or ambiguous beliefs.
- Tools/workflows:
- Fit latent manifolds over state variables (e.g., position bins) and use manifold geodesics to nudge predictions or visualize reachable states.
- Integrate with planners to produce “concept-space” waypoints rather than raw action tweaks.
- Assumptions/dependencies: Latent factors with clear geometry; robust state coverage; white-box latent access.
- Interpretability and debugging via “manifold explorer” — sectors: academia, enterprise ML, safety assurance
- Action: Provide an internal tool to:
- Fit/visualize activation and behavior manifolds (M_h, M_y).
- Compare geodesic vs. Euclidean distances and inspect isometry quality.
- Run pullback optimization to validate representation–behavior alignment.
- Why it works: The paper shows scaled isometry and bidirectional consistency; visual checks expose warped or brittle regions.
- Tools/workflows:
- “Manifold Explorer” SDK: PCA views, spline fitting, Hellinger mappings, MDS plots, energy overlays.
- Assumptions/dependencies: Engineering time to integrate; task-specific manifold definitions.
- Curriculum and prompt design that traverse concept manifolds — sectors: education, L&D, product UX
- Action: Sequence prompts/examples along manifold geodesics (e.g., gradually increasing reading level, age concepts, or temporal offsets) to produce smooth learning/evaluation curves.
- Why it works: Geodesic paths mirror models’ natural transitions, reducing abrupt failures and eliciting more predictable behaviors.
- Tools/workflows:
- Prompt generators that follow fitted manifold coordinates.
- Assumptions/dependencies: Identified concept axes; stable manifolds across user populations.
- Policy-facing evaluations for off-manifold risk — sectors: policy, compliance, safety audits
- Action: Include “on-manifold steering” and “naturalness energy” as part of model governance reports; flag any interventions or modes that induce high off-manifold energy.
- Why it works: Provides measurable evidence that control mechanisms keep outputs in natural, likely regions, reducing unexpected behavior.
- Tools/workflows:
- Lightweight audit scripts to compute distances to M_y for standard steering operations.
- Assumptions/dependencies: Agreement on audit tasks and concept sets; willingness to disclose geometry metrics.
Long-Term Applications
These opportunities require further research, scaling, or infrastructure maturity.
- General-purpose, plug-and-play manifold steering across open-ended tasks — sectors: software, foundation models
- Vision: Auto-discover and maintain a library of manifolds for thousands of latent concepts (style, stance, specificity, domains) that update as models evolve.
- Requirements:
- Scalable, online manifold discovery and tracking without manual concept curation.
- Robustness under domain shift and adversarial prompts.
- Black-box approximations (e.g., behavioral pullback via finite differences) when activations are hidden.
- Dependencies/risks: Dynamic models invalidate manifolds; identifying concepts without leaking sensitive or biased structure.
- Geometry-aware control stacks for robotics and embodied AI — sectors: robotics, autonomous systems, logistics
- Vision: Plan in conceptual manifolds (pose, affordances, semantics) and execute via geodesic controllers that keep internal beliefs on-manifold, improving stability and safety.
- Requirements:
- Learning rich, multi-factor manifolds from multi-modal world models.
- Riemannian MPC/planning with constraints derived from G_E/G_F metrics.
- Dependencies/risks: Real-time computation of geodesics; calibration between learned geometry and physical safety guarantees.
- Training objectives that explicitly shape representation–behavior isometry — sectors: academia, software platforms
- Vision: New pretraining/fine-tuning losses that enforce isometry between M_h and M_y for important conceptual spaces, producing models that are easier to steer safely.
- Requirements:
- Information-geometric regularizers (Hellinger/Amari metrics); contrastive terms discouraging off-manifold collapse.
- Benchmarks to quantify “geometry quality” as a first-class model property.
- Dependencies/risks: Compute overhead; risk of over-regularization; balancing generalization vs. geometric rigidity.
- Standardization and governance around geometry-aware steering — sectors: policy, standards bodies
- Vision: Best-practice standards that recommend on-manifold steering for high-stakes deployments and require reporting of off-manifold risks in model cards.
- Requirements:
- Shared test suites for “naturalness energy,” teleportation, and factored control.
- Sector-specific guidance (e.g., healthcare summarization dials, finance narrative neutrality).
- Dependencies/risks: Cross-organization coordination; potential for metrics gaming.
- Factored control marketplaces and UX paradigms — sectors: productivity software, creativity tools, education
- Vision: Users compose “control packs” (e.g., sentiment, formality, domain depth, narrative arc) with guaranteed independence via manifold coordinates; creators sell/share verified packs.
- Requirements:
- Certification that control dimensions are approximately orthogonal on M_h/M_y.
- Tooling to preview and validate geodesic trajectories before deployment.
- Dependencies/risks: Drift breaks independence; user confusion if controls interact subtly.
- Geometry-driven model editing and belief revision — sectors: enterprise ML, safety
- Vision: Edit knowledge along concept manifolds (e.g., time-sensitive facts, regulatory changes) using geodesic edits that preserve local structure and avoid collateral damage.
- Requirements:
- Local Riemannian solvers for minimal edits under G_E/G_F while maintaining performance elsewhere.
- Dependencies/risks: Identifying the right manifold neighborhood; detecting and mitigating downstream side effects.
- Cross-modal geometry unification — sectors: multimodal assistants, XR, media generation
- Vision: Shared conceptual manifolds spanning text, audio, and vision (e.g., emotion, formality, tempo, camera motion), enabling synchronized, factored control across modalities.
- Requirements:
- Learning and aligning manifolds across encoders/decoders; pullback metrics for multi-modal Jacobians.
- Dependencies/risks: Alignment brittleness; compute cost for multi-modal pullbacks.
- Black-box geometry estimation and secure deployment — sectors: API-based AI services
- Vision: Estimate behavior manifolds and approximate pullback geometry from outputs alone (query-efficient), enabling safe control without access to internals.
- Requirements:
- Local surrogate modeling of F and its Jacobian; adaptive sampling; uncertainty quantification.
- Dependencies/risks: Query budgets; reliability under adversarial or rare regimes.
- Bias detection and mitigation via geometry — sectors: policy, DEI, compliance
- Vision: Use manifold topology/curvature to detect biased conceptual organization (e.g., skewed neighborhoods) and design corrections that restore fair geometry.
- Requirements:
- Diagnostics relating curvature/density anomalies to data biases; geometry-aware debiasing operations.
- Dependencies/risks: Defining fairness in geometric terms; avoiding performance regressions.
Notes on global assumptions and dependencies across applications:
- Existence and stability of meaningful activation and behavior manifolds for the target concepts.
- Access to internal activations (preferable) or reliable black-box approximations via behavioral pullbacks.
- Adequate data to fit manifolds; careful token set design (including the “other” class); appropriate layer selection.
- Compute overhead for manifold fitting, geodesic interpolation, Jacobian estimation, and energy monitoring.
- Security and safety: geometry reflects training data and may encode biases; off-manifold detection should be combined with broader alignment and guardrail strategies.
Glossary
- activation manifold: A smooth, low-dimensional surface fitted to a model’s natural internal activations that captures the intrinsic geometry of representations. "we first fit an activation manifold to representations"
- activation space: The vector space of neural activations at a chosen layer, treated as a geometric space for defining paths and metrics. "assume a Euclidean geometry for activation space"
- approximate isometry: A near distance-preserving correspondence (up to scale) between two geometric spaces or manifolds. "These results demonstrate an approximate isometry between the activation and behavior space manifolds."
- behavior manifold: A smooth, low-dimensional surface fitted to natural output distributions capturing the intrinsic geometry of behavior. "a behavior manifold to output probability distributions."
- behavior space: The space of output probability distributions (typically the probability simplex) over relevant concepts. "induce paths in behavior space"
- Bhattacharyya distance: A divergence between probability distributions defined via the inner product of their square roots; used here to measure closeness to the behavior manifold. "is the Bhattacharyya distance to the nearest point on "
- cubic splines: Smooth 1D interpolating curves used to fit manifolds through centroid sequences in reduced activation or behavior spaces. "fit cubic splines \citep{reinsch1967smoothing} through the centroids"
- density geometry: A metric on activation space that rescales distances by local activation density so that geodesics follow high-density (on-manifold) regions. "Density geometry: a density-based metric whose geodesics follow the intrinsic geometry of a fitted activation manifold"
- diff-in-means steering: An activation intervention baseline that adds a difference vector between class-mean activations; equivalent to linear steering. "Linear steering (also known as `diff-in-means steering')~\citep{bau2018identifyingcontrollingimportantneurons, subramani-etal-2022-extracting, turner2023activation}"
- energy function: A scalar potential where lower values indicate more plausible or “natural” states, often proportional to negative log-likelihood. "Energy functions have a long history in machine learning as a way to measure plausibility under a model"
- Euclidean geometry: The standard flat geometry assuming straight-line paths and uniform metric; commonly assumed by linear steering. "linear steering---which assumes a Euclidean geometry---cuts through off-manifold regions"
- factored control: The ability to independently steer along different latent dimensions of a learned conceptual space without cross-interference. "Manifold steering enables factored control in multi-dimensional conceptual spaces."
- Gated Recurrent Unit (GRU): A recurrent neural network cell with gating mechanisms for sequence modeling. "Gated Recurrent Unit~(GRU; \citealt{cho2014learning})"
- geodesic: The shortest path under a given metric; on manifolds, these are curves that locally minimize path length. "a geodesic is defined as the path of minimum length between two endpoints"
- geodesic distance: The length of the shortest path along a manifold according to its metric. "We compute geodesic distance on using cumulative Euclidean distance between points along a geodesic path"
- Hellinger distance: A metric between probability distributions defined by the Euclidean distance between their square roots. "the Hellinger distance between distributions becomes an ordinary Euclidean distance"
- Hellinger metric: The Riemannian metric on probability simplices induced by the Hellinger geometry. "a chosen geometry on (e.g., the induced Hellinger metric used in our experiments)"
- Hellinger space: The space obtained by mapping probabilities via the elementwise square-root transform, linearizing the geometry of the simplex. "map each centroid from the probability simplex onto Hellinger space via"
- in-context learning of representations (ICLR): A task setup where LMs learn latent graph structures from contextual token sequences and reflect them in their representations. "using \citet{park2025iclr}'s in-context learning of representations (ICLR) task."
- Jacobian: The matrix of partial derivatives of a mapping; here, of the activation-to-behavior map, used to pull back behavior-space geometry. "through the Jacobian of the map from activation space to behavior space "
- L-BFGS: A limited-memory quasi-Newton optimization algorithm used for smooth, high-dimensional optimization. "optimize via L-BFGS for a path in activation space"
- linear representation hypothesis (LRH): The hypothesis that neural activations decompose into approximately orthogonal directions encoding atomic concepts. "motivated by the linear representation hypothesis (LRH)"
- linear steering: Steering by straight-line interpolation or additive vectors in activation space under a flat metric. "Euclidean: the standard approach of linear steering assumes a flat geometry and interventions follow a straight line."
- manifold steering: Steering by interpolating in intrinsic coordinates of the activation manifold so the path stays on-manifold. "we find that steering along , which we term manifold steering, yields behavioral trajectories"
- multidimensional scaling (MDS): A technique that embeds items into a low-dimensional space to best preserve given pairwise distances. "via a multidimensional scaling (MDS) embedding"
- open probability simplex: The set of strictly positive probability vectors that sum to one, excluding boundary faces. "which is the open probability simplex"
- PCA (Principal Component Analysis): A linear dimensionality reduction method that projects data onto directions of maximal variance. "we reduce activation vectors to 64 dimensions via PCA"
- pullback: Transporting geometry from one space to another via a mapping; here, finding activation paths whose induced behaviors follow a target behavior manifold. "We call the resulting path in activation space the pullback."
- pullback geometry: The metric on activation space obtained by pulling back a behavior-space metric through the activation-to-output map. "Pullback geometry: a behavior-aware metric obtained by ``pulling back'' behavior-space geometry into activation space"
- Riemannian isometry: A distance-preserving mapping between Riemannian manifolds (possibly up to scale); used to describe alignment of representation and behavior geometries. "related by an approximate Riemannian isometry."
- Riemannian metric: A smoothly varying inner product on tangent spaces that defines lengths and angles on a manifold. "Consider a Riemannian metric"
- thin plate splines (TPS): Smooth 2D interpolants that minimize bending energy; used to fit two-dimensional activation/behavior manifolds. "via thin plate splines (TPS; \citealt{ogsplines, thinplatesplines})"
- world model: A learned model that predicts future observations (and sometimes rewards/states) from past observations and actions. "learned world models that predict future observations from past frames and actions are central to model-based reinforcement learning"
Collections
Sign up for free to add this paper to one or more collections.

