- The paper demonstrates that LLM reasoning unfolds in distinct, step-specific trajectories, with late-stage divergence predicting correctness (ROC–AUC up to 0.87).
- The paper employs chain-of-thought prompting and linear probes to reveal that activation separability increases with depth, achieving near-ceiling accuracy (≥0.99) for early steps.
- The paper shows that targeted inference-time steering based on trajectory deviations can correct errors and modulate reasoning length with minimal accuracy loss (~1%).
Geometric Trajectory Analysis of LLM Reasoning: Structure, Correctness, and Control
Introduction and Motivation
"LLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals" (2604.05655) presents a geometric characterization of multi-step reasoning in LLMs, focusing on how reasoning steps form structured trajectories through the model’s internal state space. The study investigates three main questions: (1) Do reasoning steps occupy distinct regions in representation space that can be robustly identified? (2) Does correctness manifest as systematic differences in trajectory geometry, enabling mid-reasoning correctness signals? (3) Can these geometric insights be exploited for fine-grained inference-time control, including correction of deviating trajectories and reasoning length modulation?
Step-Specific Geometry in Representation Space
The study employs chain-of-thought (CoT) prompting on mathematical reasoning datasets (GSM8K, MATH-500) using Llama 3.1 8B variants (Base, Instruct, R1-Distill). Step-aligned activations are extracted from all decoder layers at each pre-Step marker, thereby mapping the sequential reasoning process onto a sequence of vectors in hidden state space.
Step-specific regions are highly linearly separable, especially at deeper layers; early steps become separable from shallow layers, while separation for later steps emerges progressively with depth. This behavior is consistent across base, instruction-tuned, and reasoning-distilled models, demonstrating an inherent alignment of LLM representation geometry with sequential reasoning steps.
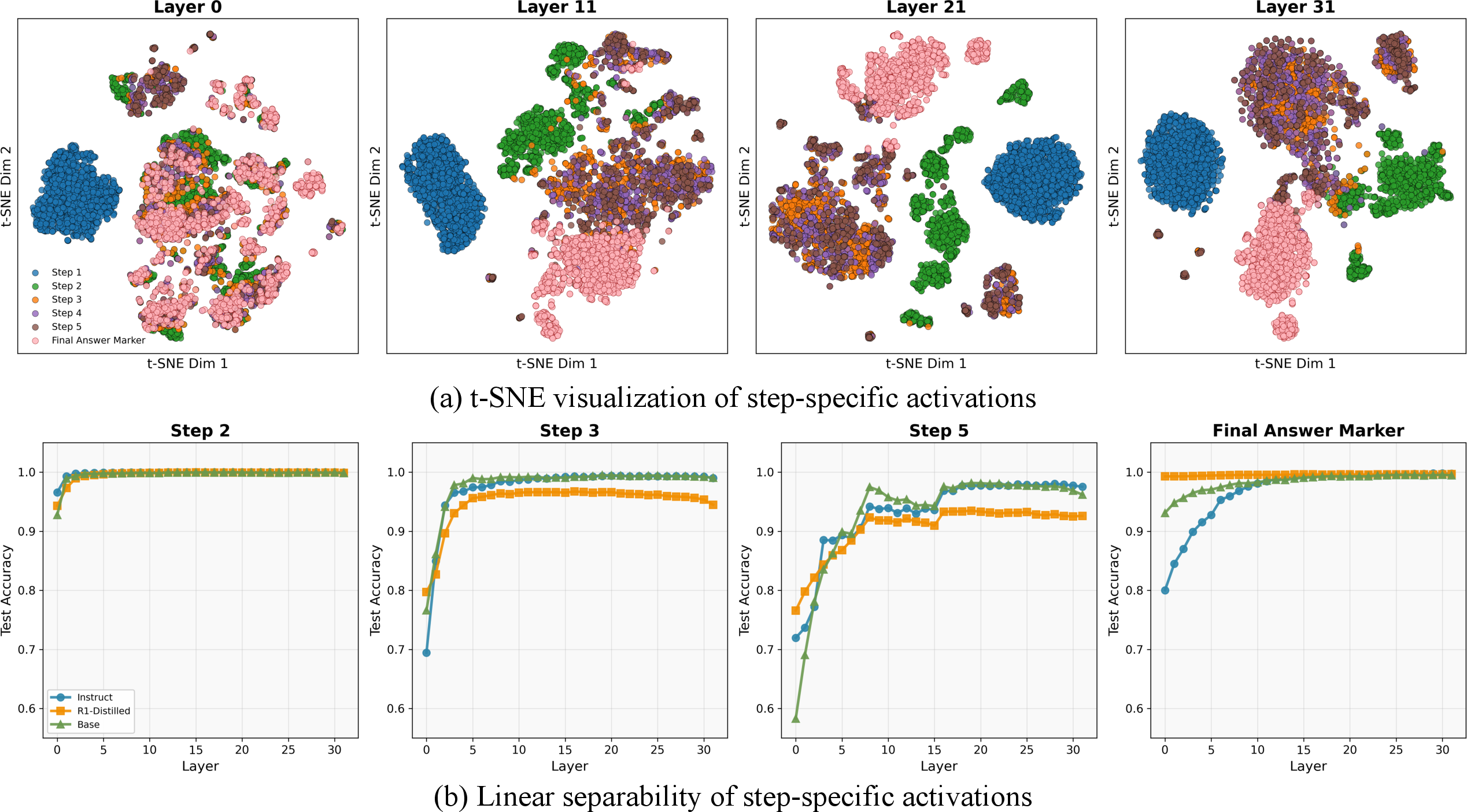
Figure 1: t-SNE projection of step-preceding activations (left) and linear probe step prediction accuracy (right) across layers show increasing separation of steps and growing linear probe accuracy with depth.
Probes trained on step-specific activations yielded near-ceiling accuracy (≥0.99) for early steps, especially Step 1, across all models and layers. For Steps 3–5, accuracy increases with depth, indicating that intermediate and late reasoning steps are encoded in more abstract subspaces. Notably, final answer markers and early step activations are exceptionally distinct, suggesting a unique geometric organization at reasoning endpoints.
Step-specific geometry persists under cross-model and cross-task generalization, e.g., linear probes trained on one training regime or dataset transfer robustly to others, indicating that representation geometry reflects reasoning progress, not surface token artifacts.
Trajectory Geometry and Correctness
To analyze correctness, activation trajectories are grouped by the final answer's correctness. Early step transitions are nearly invariant, with representation movement from Step 1 to Step 2 (and to Step 3) similar for both correct and incorrect solutions. However, at later steps, the trajectories diverge sharply, with incorrect trajectories showing statistically significant differences in distance measures (both Euclidean and cosine) compared to correct ones. The divergence intensifies at the transition to the answer marker.
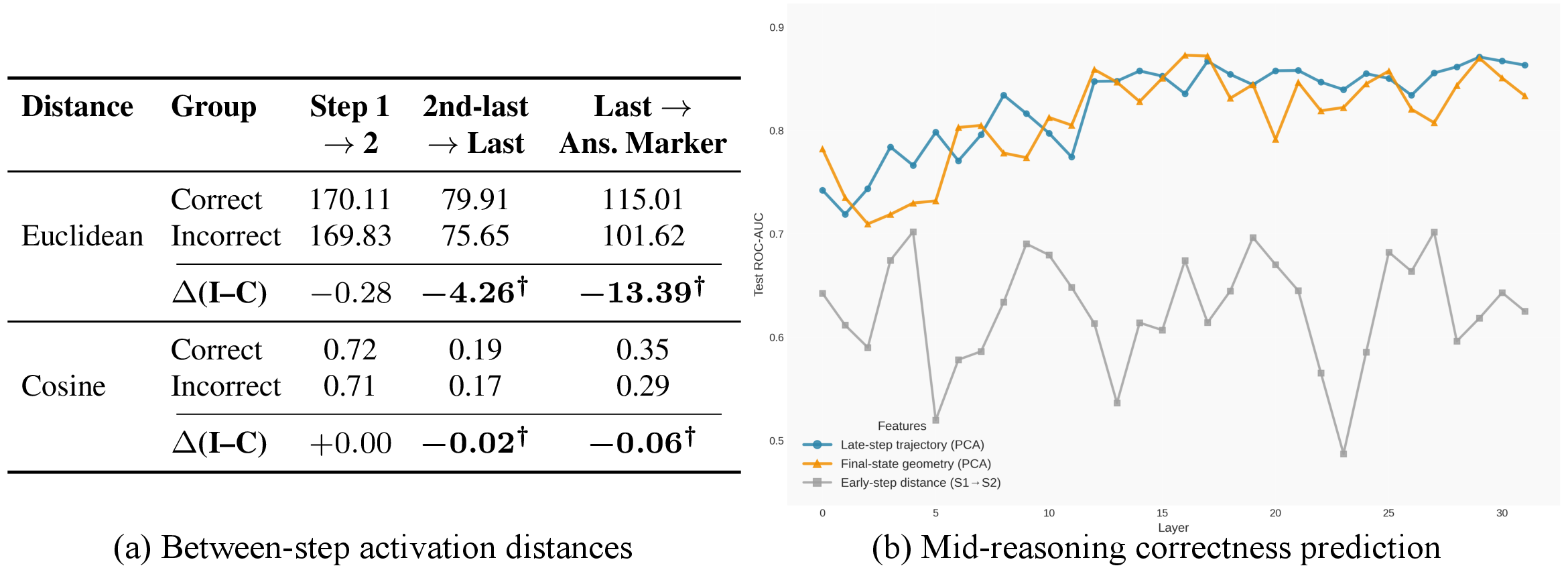
Figure 2: Late-stage divergence between correct and incorrect trajectories, and ROC–AUC as a function of layer and trajectory segment for mid-reasoning correctness prediction.
By training logistic regression classifiers on late-step trajectory features, the authors demonstrate mid-reasoning correctness signals: ROC–AUC up to 0.87 for predicting correctness prior to answer emission. Early-step features, in contrast, yield poor discriminative power (AUC ≈ 0.63). Trajectory-based correctness signals outperform both step-count and logit-level baselines. This suggests that the process—rather than the endpoint or length—captures essential signals about reasoning validity.
Error-Targeted Inference-Time Steering
The findings around trajectory divergence enable the design of error-targeted inference-time interventions. Traditional test-time scaling methods (e.g., injecting "Wait" or "Check" tokens) frequently degrade performance when applied unconditionally, especially as they may perturb correct reasoning unnecessarily, reflected in accuracy drops as large as 36%. Instead, by gating these interventions using mid-reasoning correctness predictors, interventions are selectively applied to only 12% of cases, converting substantial unconditional accuracy losses to positive net gains (e.g., +35.4% relative to always-on interventions).
In addition to token-level scaling, the paper explores trajectory-based activation steering, leveraging step-wise statistics of correct trajectories to design low-rank steering operations. When reasoning deviates beyond a learned threshold from the "ideal" trajectory, localized updates nudge activations toward correct behavior.
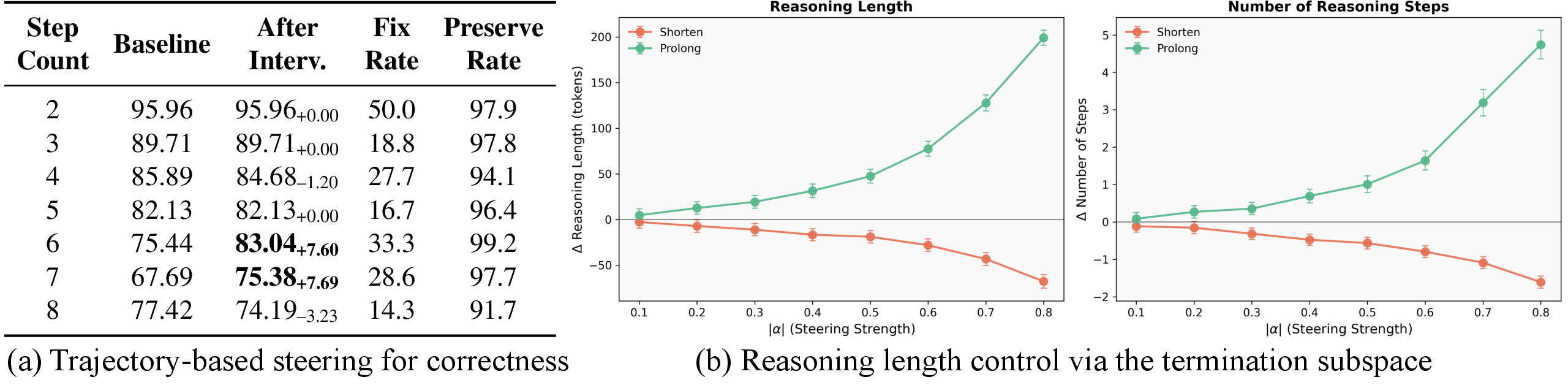
Figure 3: Correctness steering stratified by step count (left), and reasoning length modulation via low-rank steering as a function of intervention strength (right).
For complex, long-chain problems, accuracy improvements of 7–8% are achieved for 6- and 7-step problems, with over 97% preservation rate for originally correct trajectories. For short, stable reasoning, steering yields near-zero change, aligning with minimal early-step divergence between correct and incorrect solutions.
Modulation of Reasoning Length
The identified termination-related subspace offers a smooth geometric axis for reasoning length control. By modulating the projection of hidden activations toward or away from this subspace, the model’s propensity to terminate reasoning can be gradually adjusted. For steering strengths ∣α∣≤0.4, reasoning step count can be monotonically increased or decreased with minimal accuracy change (≈1%) and rare behavioral collapse.
Structural properties of the step-indexed geometry transfer robustly across mathematical tasks (GSM8K, MATH-500) and general-knowledge settings (MMLU), as well as in freeform CoT generations with no explicit formatting. However, correctness predictors are more dataset-sensitive; while structure generalizes, per-task calibration remains necessary for effective correctness prediction.
Theoretical and Practical Implications
This geometric characterization advances mechanistic interpretability at the trajectory level, opening avenues for:
- Automated failure detection and targeted correction: Mid-reasoning signals offer real-time monitoring and adaptive intervention.
- Reasoning process auditing: Step-aligned subspaces provide a natural lens for analyzing faithfulness and reasoning drift.
- Length and termination control: Users or downstream systems can modulate depth and confidence in model reasoning without retraining.
- New training objectives: Auxiliary losses may exploit geometric regularities to reduce spurious reasoning or enhance step alignment.
- Scalability to larger models and domains: The geometric abstraction is likely to apply to more expressive LLMs and outside mathematics, but further analysis is required.
Conclusion
This work establishes that multi-step reasoning in LLMs unfolds as structured, step-specific trajectories in representation space, with late-stage geometric divergence encoding actionable correctness signals. These trajectories are accessible to linear probes, enable robust transfer across training regimes and tasks, and support causally effective, efficient, and error-targeted interventions—including both correction and fine-grained control of reasoning length. Future developments may incorporate these geometric foundations into both the interpretability toolkit and the design of next-generation LLM control and training paradigms.