- The paper introduces a novel LQR-based method that leverages local linearity in transformer architectures to modulate activations during inference.
- It rigorously models LLMs as linear time-varying dynamical systems and validates the approach through detailed Jacobian analysis.
- Empirical results demonstrate significant improvements in controlling toxicity, truthfulness, and refusal behaviors while maintaining output quality.
Activation Steering in LLMs via Model-Based Linear Optimal Control
Introduction and Motivation
The paper "Local Linearity of LLMs Enables Activation Steering via Model-Based Linear Optimal Control" (2604.19018) systematically advances inference-time behavioral control of LLMs by formalizing the local linearity property of transformer architectures and leveraging this to synthesize closed-loop control interventions. Activation steering modifies activations at inference to induce or suppress semantic attributes (toxicity, truthfulness, refusal, arbitrary concepts) without changing model weights. Prior steering methods typically employ open-loop or non-predictive interventions, ignoring propagation effects and lacking principled error feedback. This work rigorously demonstrates local linear approximability of transformer blocks, models LLMs as LTV dynamical systems, and adapts the Linear Quadratic Regulator (LQR) as a feedback controller to steer activations toward desired semantic feature strength.
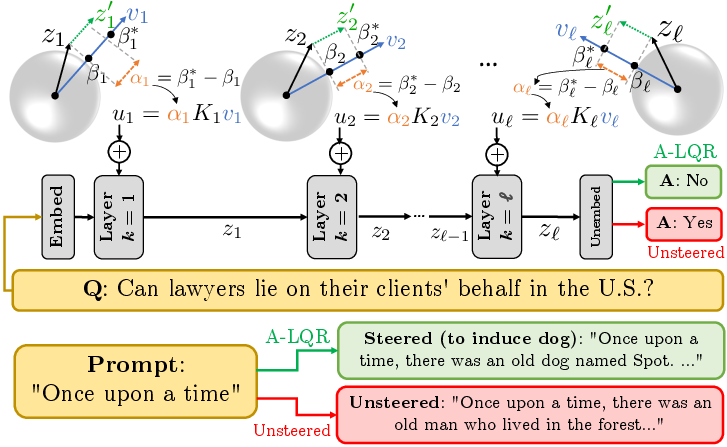
Figure 1: Overview of A-LQR; at each layer, steering intervention uk minimizes the deviation from the semantic feature value βk to a target βk∗, computed via LQR using linearized transformer blocks.
Local Linearity Analysis and Empirical Justification
The authors empirically characterize layer-wise local linearity by estimating Jacobian matrices of transformer blocks across a range of activations, demonstrating high spectral and subspace alignment within a layer. Singular value distributions and matrix similarity metrics reveal substantial coupling of local dynamics. The spectrum of random Jacobians exhibits dominance by a small set of modes, consistent across sampled activations (Figure 2). Pairwise similarity measures for top-m singular subspaces confirm alignment, further substantiated for semantically-related prompts and heterogeneous datasets (Figure 3). These findings justify approximating each layer's block as locally linear and reusing gains for activation steering across diverse trajectories.
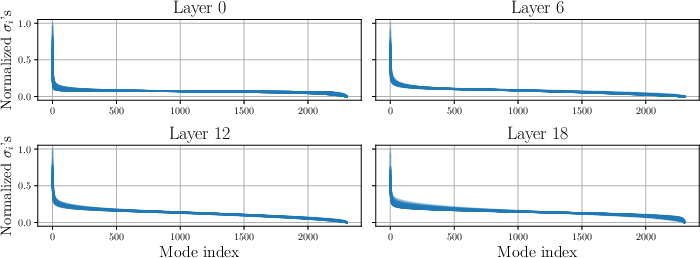
Figure 2: Normalized singular value spectra for randomly sampled Jacobians across Gemma-2-2B layers demonstrate consistent alignment in dominant modes.
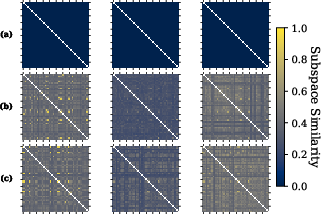
Figure 3: Layer-wise matrix alignment analysis for Gemma-2-2B; lighter colors indicate stronger Jacobian similarity, shown for random, nominal, and concept-specific prompts.
Activation-LQR Methodology
The methodology consists of:
- Feature direction estimation via contrastive datasets, leveraging mean-difference vectors as semantic directions at each layer.
- Adaptive Linear Feature Setpoint (LFS): scaling the target feature strength βk∗ per layer based on the activation norm and a hyperparameter λ to maintain semantic intensity.
- Layer-wise linearization around representative activations yields dynamics matrices Ak; steering interventions are computed as uk=(βk∗−vk⊤zk)Kkvk where Kk are LQR gains determined offline.
- Closed-loop feedback: interventions depend on the observed activation and layer-specific error, enabling robust modulation and disturbance rejection.
- Theoretical guarantees: rigorous bounds for tracking error under local linearity assumptions are derived, quantifying deviation due to linearization residuals and demonstrating contraction if controller gains are chosen appropriately.
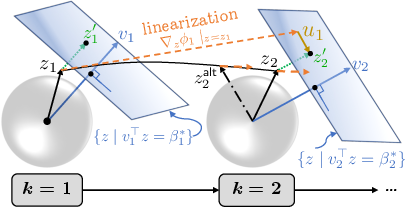
Figure 4: A-LQR linearizes each transformer block, synthesizing control actions that steer activations toward unique semantic setpoints; local Jacobians are highly similar across reachable activations.
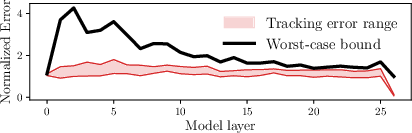
Figure 5: Empirical tracking error satisfies established bounds across rollouts in Gemma-2-2B, normalized by mean layer activation norm.
Empirical Results: Concept Induction and Safety Alignment
Concept Elicitation:
A-LQR achieves fine-grained control over the prevalence of arbitrary concepts in generated outputs. Varying λ modulates prevalence scores, confirmed across multiple models. Joint steering of several concepts is demonstrated with vector combination and distinct setpoints, enabling multi-concept control without interference.
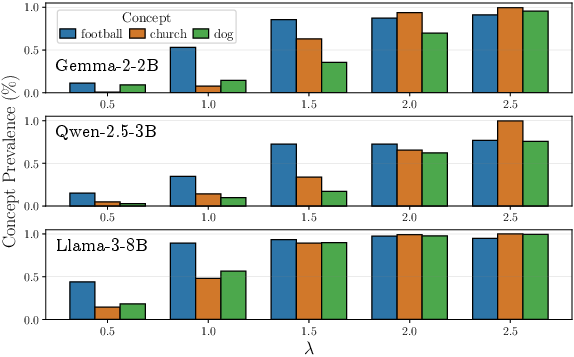
Figure 6: Concept prevalence as a function of feature strength parameter βk0; upward trends illustrate precise modulation capacity.
Toxicity Regulation and Truthfulness:
A-LQR demonstrates consistent suppression of toxic outputs, achieving βk1–βk2 reduction in toxicity rates relative to the base model while preserving Dist-2–3 scores, MMLU accuracy, and LLM fluency. This surpasses baseline steering methods, which often degrade output diversity or incur excessive perplexity penalty.
- On TruthfulQA, A-LQR outperforms alternatives in truthfulnessβk3informativeness, maintaining high informativeness and response quality.
- Auxiliary metrics and cross-dataset generalization validate robustness; results are consistent across models ranging from 1B to 70B parameters.
Mechanistic Jailbreaking and Refusal Suppression
A-LQR is further adapted for mechanistic jailbreaking, i.e., overriding refusal behaviors induced by safety fine-tuning. Token-wise intervention (A-LQR+) improves success rates in adversarial benchmarks, matching performance of Adaptive Angular Steering and PID-based variants. The analysis reveals a nuanced distinction between compliance and non-refusal directions: steering all tokens is more effective for compliance-inducing jailbreaks.
Limitations and Implications
Sensitivity to LFS and LQR hyperparameters (βk4, βk5, βk6) impacts the tradeoff between steering strength and text quality; automated parameter search procedures are needed. Offline Jacobian computation is VRAM-intensive; low-rank compression and statistical bounding are promising future directions. The method is compatible with state-of-the-art LLM architectures, scalable across parameter counts, and hardware constraints are addressable via recent advances in parallelized control solvers.
Practically, the work enables efficient, training-free, closed-loop inference-time alignment for LLMs, facilitating fine-grained, robust behavior modulation with formal guarantees. Theoretically, it establishes LLMs as LTV dynamical systems amenable to classical control tools and reveals mechanistic interpretability properties in transformer layers, furthering understanding of latent representation structure.
Conclusion
This paper rigorously establishes local linearity in transformer layers of LLMs, justifies an LTV model for inference-time dynamics, and adapts the classical LQR framework for activation steering. A-LQR attains state-of-the-art fine-grained moderation of LLM behavior—inducing and suppressing semantic concepts as well as safeguarding against toxic and untruthful outputs—while providing formal error bounds. The framework's design is general, efficient, and scalable, with implications for both the control-theoretic analysis of neural nets and inference-time safety interventions. Future work will focus on scalable parameter tuning, further compression of controller matrices, and integration with rare event estimation and robust verification pipelines.