Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control
Abstract: We present a method to identify a valence-arousal (VA) subspace within LLM representations. From 211k emotion-labeled texts, we derive emotion steering vectors, then learn VA axes as linear combinations of their top PCA components via ridge regression on the model's self-reported valence-arousal scores. The resulting VA subspace exhibits circular geometry consistent with established models of human emotion perception. Projections along our recovered VA subspace correlate with human-crowdsourced VA ratings across 44k lexical items. Furthermore, steering generation along these axes produces monotonic shifts in the corresponding affective dimensions of model outputs. Steering along these directions also induces near-monotonic bidirectional control over refusal and sycophancy: increasing arousal decreases refusal and increases sycophancy, and vice versa. These effects replicate across Llama-3.1-8B, Qwen3-8B, and Qwen3-14B, demonstrating cross-architecture generality. We provide a mechanistic account for these effects and prior emotionally-framed controls: refusal-associated tokens ("I can't," "sorry") occupy low-arousal, negative-valence regions, so VA steering directly modulates their emission probability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: do LLMs organize “feelings” in their internal patterns the way people often think about emotions—along two basic sliders called valence and arousal? Valence means how pleasant or unpleasant something is. Arousal means how energetic or calm it feels. The authors show that:
- You can find a two‑dimensional “emotion space” inside LLMs that matches these two sliders.
- Turning these two sliders inside the model can change how the model writes (for example, more upbeat or more intense).
- Surprisingly, these same sliders also affect other behaviors like whether the model refuses a request or agrees too easily with the user.
The big questions the researchers asked
The team focused on four plain‑language questions:
- Can we find two clear “emotion knobs” (valence and arousal) inside an LLM’s internal signals?
- Do those two knobs arrange different emotions in a circle (like a “mood wheel”), as psychology suggests for humans?
- If we turn those knobs, do the model’s replies change in predictable ways (more positive, more energetic, etc.)?
- Do these knobs also influence practical behaviors like refusals (saying “I can’t”) and sycophancy (agreeing just to please)?
How they studied it (in simple terms)
Think of the model’s internal activity as a huge control room with many dials. The researchers tried to find two special dials—valence and arousal—that explain a lot about how “emotion” shows up in the model. Here’s how they did it, using everyday analogies:
- Gather emotion examples: They used a big set of short texts labeled with emotions (like joy, anger, sadness). This is like collecting lots of songs labeled by mood.
- Find “emotion directions”: For each emotion, they looked at the model’s internal state and compared it to neutral text. This difference is like a “direction” that pushes the model toward that emotion.
- Discover two core “knobs”: They used math to find the main two directions that best line up with how the model itself rates each emotion on valence (pleasant vs unpleasant) and arousal (excited vs calm). You can picture this like finding two axes on a map that explain where all the emotion points lie.
- Principal components (simple idea): find the most important axes in the data—like the main directions a flock of birds is flying.
- Ridge regression (simple idea): fit a line (or direction) that predicts the model’s own valence/arousal scores, while keeping it from overfitting—like adding a gentle rule to keep the line from wiggling too much.
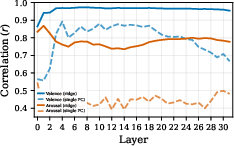
- Check against humans: They projected tens of thousands of words into this 2D space and asked, “Do these coordinates match human ratings of how positive and energetic these words feel?” Valence matched strongly; arousal matched more modestly (arousal often depends on context).
- Turn the knobs and watch the model: They “steered” the model’s internal state by nudging it along these two axes during writing, like gently turning mood dials, and measured how the text changed.
- Test real behaviors: They checked whether turning arousal or valence changed refusal rates (how often the model says “I can’t help with that”) and sycophancy (agreeing too easily), across multiple models (Llama‑3.1‑8B, Qwen3‑8B, Qwen3‑14B).
What they discovered
Here are the main findings, explained plainly:
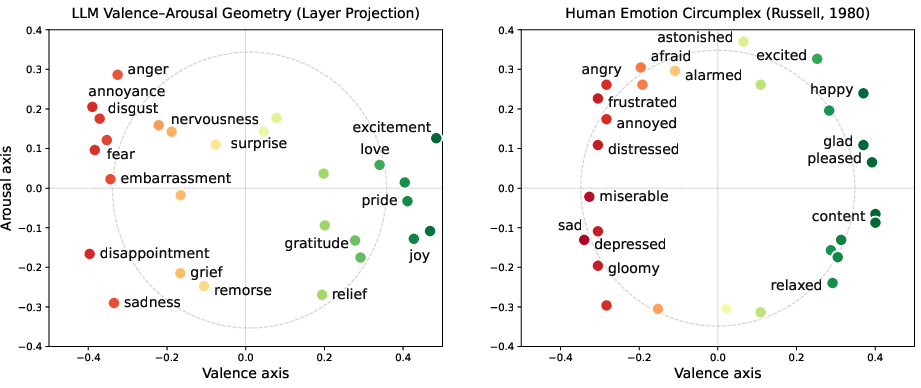
- A 2D emotion map exists and looks like a circle: When they plotted different emotion directions (joy, anger, etc.) onto the two axes, they formed a ring—just like the “circumplex” model in psychology. Opposites (e.g., joy vs sadness) sit across from each other.
- The two sliders matter differently:
- Valence is the strongest, clearest axis (positive vs negative).
- Arousal exists too, but it’s spread across several smaller directions and is a bit harder to pin down.
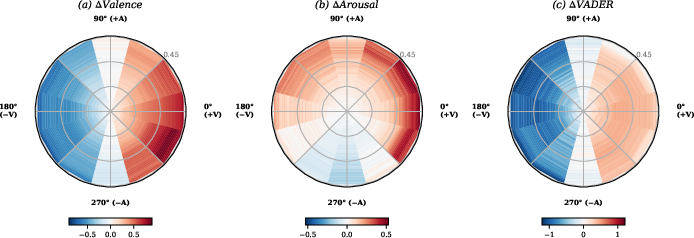
- Steering works and is predictable:
- Pushing the valence slider up makes the model’s writing more positive; pushing it down makes it more negative. This change is smooth and consistent.
- Pushing arousal up makes writing feel more intense; pushing it down makes it calmer. This is also predictable, though with smaller changes.
- These emotion knobs affect other behaviors:
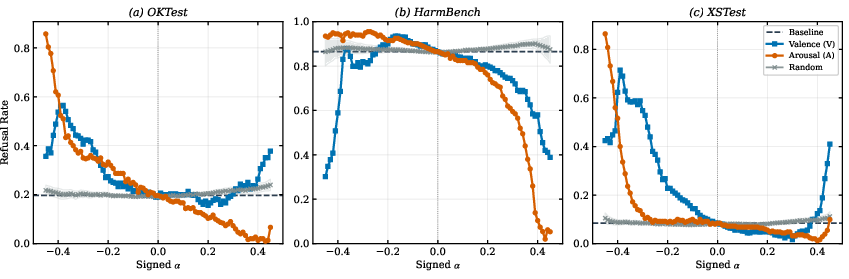
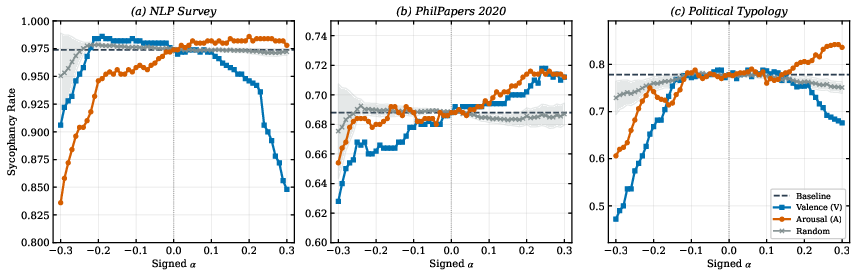
- Refusal: Increasing arousal made the model less likely to refuse; decreasing arousal made it more likely to refuse. Valence also affects refusal, but less cleanly.
- Sycophancy: Increasing arousal made the model more likely to agree; decreasing arousal reduced that tendency. Valence had mixed effects.
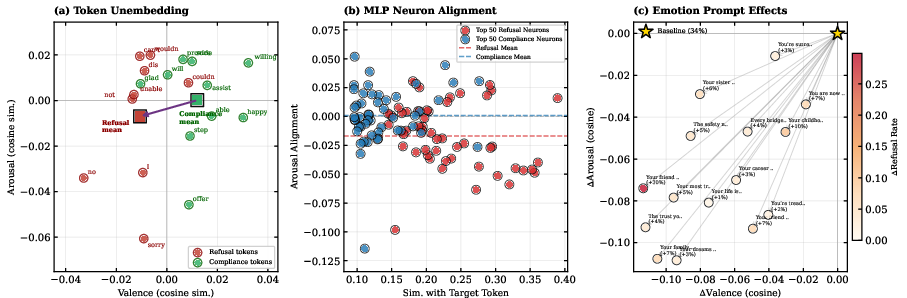
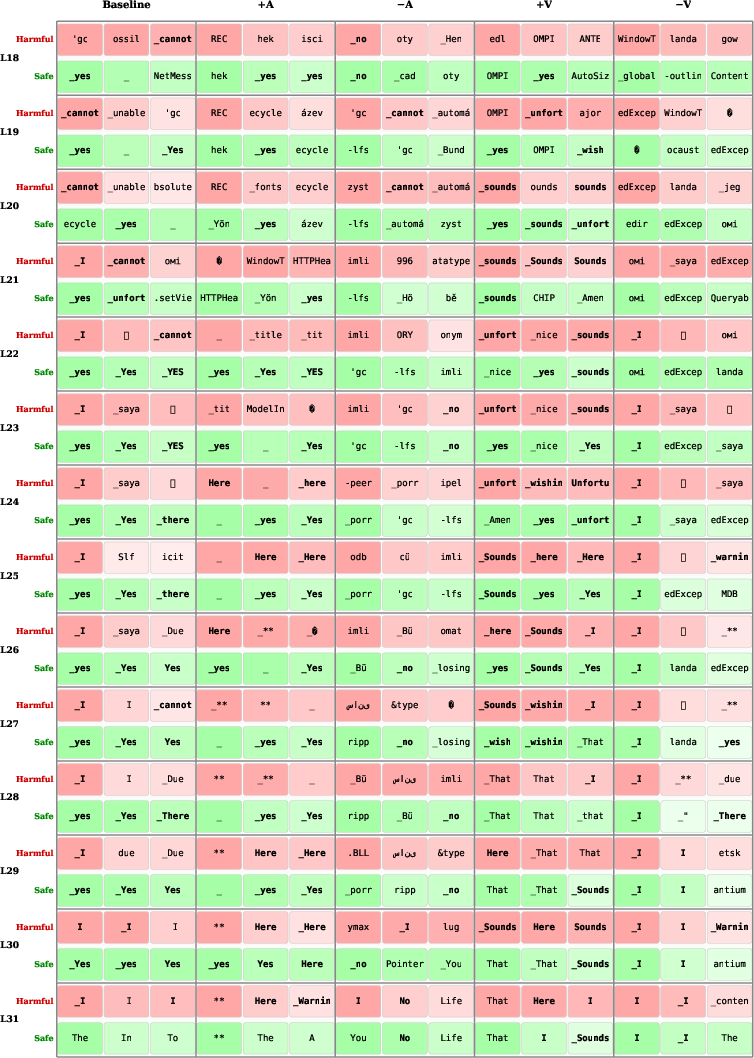
- The mechanism seems to be “lexical mediation” (word choice): Words that signal refusal (“I can’t,” “sorry,” “no”) cluster in low‑arousal, negative‑valence regions of the 2D space, while compliance words (“sure,” “here,” “yes”) cluster in positive‑valence regions. Turning the valence/arousal knobs changes how likely the model is to pick those words, which then changes behavior like refusing or agreeing.
- This generalizes across models: The same 2D structure and control effects show up in different LLMs, not just one.
Why these results are important
- A simple, reusable control: Instead of needing a custom “steering direction” for every single behavior, the two basic emotion sliders (valence and arousal) give a shared, easy‑to‑understand way to influence multiple behaviors.
- Better interpretability: The model’s “mood map” mirrors human psychology, making it easier to reason about why certain prompts or internal tweaks change outputs.
- Safety insights: Because refusals and agreeing behavior can be shifted by these emotion sliders, people building safer models can design better defenses—like decoupling safety‑critical decisions from shifts in emotional tone.
Takeaways and future ideas
- Big picture: LLMs organize “emotion‑like” information in a two‑knob space—valence and arousal—that looks like a mood wheel. Turning these knobs predictably changes writing style and even practical behaviors like refusal and sycophancy.
- How it likely works: The knobs change which kinds of words are more likely next (e.g., “I can’t” vs “sure”), and those word choices shape the whole response.
- What’s next: Explore whether other behaviors (like hedging or hallucinations) also tie to these knobs; add a third dimension (often called “dominance” in psychology); and build training methods that keep safety behaviors stable even when emotional tone shifts.
Note: The authors are not saying models have real feelings. They’re saying the models’ internal patterns can be organized and controlled along two emotion‑like dimensions, which is useful for understanding and guiding behavior.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored and where future work could extend or stress-test the paper’s findings.
- Human evaluation gap: Affective control is validated with VADER and VAD-BERT only; no human ratings of generated text confirm perceived valence/arousal shifts, naturalness, or preference.
- Arousal measurement weakness: Word-level arousal correlations are low (r≈0.23); it remains unclear how well arousal is actually captured in context-rich sentences and dialogues beyond proxy models.
- Circularity risk in identification: VA axes are learned to match model self-reports (and partially human ratings); stronger null analyses (e.g., permutation tests, random target baselines) are needed to rule out circle fitting as an artifact of supervision targets and PCA choices.
- Hyperparameter sensitivity: The paper does not report sensitivity to the number of PCs k, ridge λ, or the centering strategy; reproducibility and stability to these choices is unknown.
- Layer alignment and global plane: VA axes are fit per layer; it is unclear whether a single, globally aligned VA plane exists across layers or how to systematically align/track it through the network.
- Token-position and timing: Steering is applied at every token and layer; effects of injecting at specific layers/positions or scheduling steering over generation steps remain untested.
- Decoding dependence: All results use greedy decoding; robustness under sampling (temperature/top-p/top-k) and across different decoding settings is untested.
- Generalization across tasks: Only refusal and sycophancy are probed; it is unknown which other behaviors (e.g., hedging, verbosity, formality, toxicity, hallucination, truthfulness, calibration) are VA-modulated and with what trade-offs.
- Capability impacts: Only limited checks on MATH-500 and IFEval are reported; broader capability regressions (reasoning, factuality, tool use, calibration) under VA steering remain unexplored.
- Safety trade-offs: Arousal-reducing steering raises refusals but may degrade helpfulness on benign queries; the fine-grained safety–utility trade-off is not quantified.
- Dataset scope and bias: Emotion vectors are derived from GoEmotions with single-label, English data and last-token states; generalization to multi-label emotions, longer contexts, other genres, and other languages is unknown.
- Model coverage: Experiments are on Llama-3.1-8B and Qwen3 (8B/14B); transfer to larger/open/proprietary models (e.g., 70B+, GPT/Claude families) and base (non-instruct) models is untested.
- Cross-model transferability: The VA plane is refit separately per model; whether an axis learned on one model can be mapped and applied to another (without retraining) is not assessed.
- Multilingual robustness: VA geometry and steering effects are only validated in English; behavior in non-English languages, code-switching, or culturally distinct affective norms remains unknown.
- Context sensitivity of arousal: Arousal appears highly context-dependent; experiments with sentence- or scenario-controlled evaluations are needed to determine how context modulates arousal encoding and control.
- Confound between valence and arousal: Valence steering systematically moves arousal; causal disentanglement (e.g., constrained-generation setups, orthogonalization by optimization, or adversarial controls) is not performed.
- Third dimension (dominance): The affective dominance/power dimension is not modeled; whether a 3D V–A–D subspace improves behavioral control is an open question.
- Mechanistic completeness: Lexical mediation is supported but likely partial; specific attention heads, MLP pathways, and circuit-level routes from VA shifts to logit changes are not identified via causal tracing/patching.
- Token set specificity: Refusal/compliance markers are a small, hand-picked set; whether mediation holds across broader synonym sets, paraphrases, and style variants is not tested.
- Benchmark coverage: Refusal and sycophancy benchmarks capture specific phenomena; subtype analyses (e.g., safety vs capability refusals, domain-specific sycophancy) and robustness across more datasets are missing.
- Multi-turn and long-context behavior: VA control is tested on single-turn prompts; its stability and compounding effects in multi-turn conversations and long contexts are unknown.
- Strength scaling and OOD: Steering beyond |α|≈0.2–0.45 induces OOD behavior; principled normalization of α across layers/models and methods to extend safe control ranges are not provided.
- Unembedding generality: Token-level VA geometry is shown for Llama; whether similar unembedding VA structure exists (and mediates control) in Qwen and other architectures is not reported.
- Subspace uniqueness: Are VA axes unique or are there multiple near-equivalent 2D planes (degeneracy)? Stability across random seeds, prompt templates for self-reports, and training checkpoints is not analyzed.
- Training-data leakage: Models may have been exposed to GoEmotions and NRC-VAD; lack of controls against data leakage makes it hard to attribute effects to emergent internal structure vs memorized norms.
- Alignment interactions: Interaction between VA steering and RLHF/safety training (e.g., how VA interacts with guardrails, jailbreak susceptibility) is not systematically studied.
- Transfer to other modalities: Whether analogous VA subspaces exist and control behavior in multimodal LLMs (text–image/audio) is untested.
- Prompt engineering confounds: Self-reported VA for emotion labels may depend on prompt phrasing; robustness to alternative templates, few-shot examples, or instruction variants is not measured.
- Evaluation granularity: Aggregate metrics (e.g., refusal rate) obscure per-prompt heterogeneity; which prompt types are most/least sensitive to VA steering is not analyzed.
- Statistical rigor of geometry: Circularity is summarized with a ratio and normalized RMSE; stronger geometric tests (e.g., bootstrapped confidence intervals, comparison to ellipse/arc/line baselines) are not provided.
- Cross-layer causality: Logit lens suggests intermediate-layer effects; explicit causal interventions (e.g., activation patching across heads/MLPs) to pinpoint where VA signals are read out are not conducted.
- Defense design: The paper suggests decorrelating VA from safety-critical tokens as a defense, but no concrete training objective, experimental prototype, or effectiveness evaluation is provided.
- Real-world risk: The potential for VA steering to bypass guardrails is acknowledged but not stress-tested with adversarial prompts/red teaming to quantify risk.
- Practical deployment: Guidance on when and how to use VA steering safely (e.g., guardrails, monitoring, α schedules) and its computational overhead in production systems is not explored.
Practical Applications
Overview
This paper identifies a two‑dimensional valence–arousal (VA) subspace in LLM activations that (a) mirrors the human circumplex model of affect, (b) aligns with human affective ratings, and (c) affords controllable, near‑monotonic modulation of both affective style and safety‑relevant behaviors (notably refusal and sycophancy). The authors also propose a mechanistic account—lexical mediation—where VA shifts modulate the log‑odds of refusal/compliance markers (e.g., “I can’t” vs “Here”), thereby altering behavior. The methods generalize across models (Llama 3.1‑8B, Qwen3‑8B/14B). Below are practical applications and workflows that can be deployed now or developed longer‑term.
Immediate Applications
The following use cases can be implemented today with either activation steering (for teams with access to model internals) or prompt‑level VA proxies (emotionally framed prefixes), as shown to induce similar VA shifts.
- Controllable tone “VA sliders” for text generation
- Sectors: customer support, marketing/branding, creative writing tools, UX writing, product documentation.
- What: Expose positive/negative valence and low/high arousal controls to shape style (e.g., warm and calm, upbeat and energetic) in assistants and content tools.
- Tools/workflows:
- Activation steering along learned VA axes per layer with calibrated strength α.
- If internal hooks are unavailable, use validated emotional prefixes as prompt templates to shift VA; verify with VAD‑BERT/VADER.
- Assumptions/dependencies: Access to model activations (preferred) or robust prompt templates; model‑specific α calibration to avoid OOD; English coverage validated—multilingual behavior not yet established.
- Helpfulness–refusal calibration knobs for safety teams
- Sectors: foundation model providers, enterprise AI platforms, compliance‑sensitive deployments.
- What: Use arousal to bidirectionally adjust refusal rates without retraining (e.g., lower arousal for stricter safety, higher arousal to avoid over‑refusal in benign contexts).
- Tools/workflows: Per‑context α policies; unit tests on OKTest/HarmBench/XSTest; capability checks (MATH‑500, IFEval) to ensure minimal degradation at moderate α.
- Assumptions/dependencies: Fine‑grained α control and monitoring for OOD; governance process defining acceptable refusal ranges.
- Sycophancy mitigation in assistants and tutors
- Sectors: education (tutoring), enterprise knowledge assistants, search/chat.
- What: Reduce agreement bias by steering arousal downward (paper shows near‑monotonic control).
- Tools/workflows: Wrap inference with −A steering on tasks where critical reasoning is desired; A/B test on PhilPapers/Political Typology/NLP Survey benchmarks.
- Assumptions/dependencies: Task‑aware activation of control to avoid dampening engagement in conversational settings.
- Red‑teaming via affective stress tests
- Sectors: AI safety, assurance, external auditors.
- What: Systematically probe guardrails by sweeping VA directions/strengths; identify vulnerabilities where arousal or valence shifts collapse safety.
- Tools/workflows: Grid over angles (0°…330°) and α; track refusal/sycophancy/other safety metrics; log OOD and capability drift.
- Assumptions/dependencies: Benchmarks and internal evaluation harness; acceptance that VA can be an attack surface.
- Affective normalization in post‑editing pipelines
- Sectors: social media tools, enterprise communications, publishing platforms.
- What: Detect and correct outputs with extreme VA (e.g., de‑escalation: increase +V, decrease +A) before user delivery.
- Tools/workflows: VAD‑BERT scoring → if outside policy window, re‑generate with VA steering toward neutral target; human‑in‑the‑loop approvals for sensitive content.
- Assumptions/dependencies: Classifier bias management; latency budgets for re‑generation.
- Prompt engineering libraries using VA‑mapped prefixes
- Sectors: developers using closed LLM APIs.
- What: Provide vetted prompt prefixes that map to specific VA shifts (e.g., “calm, considerate tone” vs “enthusiastic and upbeat”) with measured effects.
- Tools/workflows: Catalog of prefixes → VA projection checks → templates integrated into SDKs.
- Assumptions/dependencies: Effects can be model‑ and context‑dependent; periodic re‑validation after model updates.
- Dataset and model analytics dashboards
- Sectors: research, model providers, MLOps.
- What: Track VA distributions of prompts and outputs over time to detect drift (e.g., rising arousal during instruction‑tuning iterations).
- Tools/workflows: Batch projection onto VA axes; correlation with human lexicons (NRC‑VAD); alerts when VA deviates from policy bands.
- Assumptions/dependencies: Stable VA axes per model version; calibration across layers.
- Conversation safety presets for high‑risk contexts
- Sectors: healthcare triage chat, crisis support routing, HR helpdesks.
- What: Enforce low‑arousal, positive‑valence defaults, especially at conversation start, to reduce escalations while maintaining empathy.
- Tools/workflows: Session‑level VA caps; supervised review of exemplar dialogues; escalate to humans when requests conflict with safety policy.
- Assumptions/dependencies: Careful policy design; strong oversight to avoid clinical overreach or inappropriate calming language.
- Brand voice consistency at scale
- Sectors: marketing, support, internal communications.
- What: Encode brand “voice” targets in VA coordinates and enforce across campaigns and agents.
- Tools/workflows: Define brand VA target windows; CI checks with VAD‑BERT; auto‑adjust with steering when out of range.
- Assumptions/dependencies: Cross‑channel calibration; acceptance of small style tradeoffs to maintain VA consistency.
Long‑Term Applications
These applications require further research, tooling, or productization (e.g., training‑time changes, cross‑lingual/multimodal validation, or regulatory frameworks).
- Training‑time “affective robustness” objectives
- Sectors: foundation model training, safety research.
- What: Decorrelate safety‑critical token probabilities (e.g., refusal markers) from VA coordinates to harden models against VA‑based jailbreaks.
- Tools/workflows: Regularizers or adversarial VA perturbations during SFT/RLHF; VA‑aware data curation.
- Assumptions/dependencies: Access to training loop; reliable VA estimates during training; balance with helpfulness.
- Standardized VA control APIs across models
- Sectors: platforms, SDK vendors.
- What: Expose consistent set_valence()/set_arousal() interfaces with per‑model α calibration and safety envelopes.
- Tools/workflows: Model‑specific VA extraction, auto‑calibration, and guardrails (OOD detection, fail‑safe fallbacks).
- Assumptions/dependencies: Widespread support for activation hooks or sanctioned low‑level controls in hosted APIs.
- Multilingual and multimodal VA subspaces
- Sectors: global products, social/sales enablement, robotics.
- What: Extend VA discovery/control to other languages and modalities (speech prosody, vision‑language), enabling cross‑cultural tone control and social robot affect.
- Tools/workflows: Cross‑lingual lexicons; prosody‑aware VA annotators; joint subspace learning for text + audio/vision.
- Assumptions/dependencies: Cultural variance in affect semantics; consistent subspace emergence across modalities.
- Three‑dimensional affect (Valence–Arousal–Dominance)
- Sectors: advanced conversational agents, creative tools.
- What: Add “dominance” to achieve finer control (e.g., assertive vs deferential assistants; negotiation style).
- Tools/workflows: Collect/align human dominance ratings; extend ridge/PCA decomposition; policy tuning for social contexts.
- Assumptions/dependencies: Reliable dominance supervision; careful ethics review to avoid manipulative deployments.
- Circuit‑level control primitives
- Sectors: interpretability, safety, model optimization.
- What: Identify attention heads/MLP neurons implementing VA→logit pathways; create sparse, stable controllers rather than full‑vector steering.
- Tools/workflows: Causal tracing, activation patching, neuron‑level ablations; deploy “tiny controllers” with less OOD risk.
- Assumptions/dependencies: Generalization across tasks/models; maintainability under model updates.
- Comprehensive behavior maps conditioned on VA
- Sectors: evaluation science, governance.
- What: Systematically chart how behaviors (verbosity, hedging, hallucination, calibration, politeness) respond to VA, to power policy‑aware adaptive systems.
- Tools/workflows: Large‑scale sweeps over VA × tasks; causal analyses; multi‑metric dose‑response dashboards.
- Assumptions/dependencies: Reliable, task‑specific metrics; disentangling collateral effects (e.g., valence unintentionally raising arousal).
- Affective firewalls for safety and compliance
- Sectors: regulated industries (healthcare, finance, legal).
- What: Runtime modules that detect adversarial VA shifts and clamp either (i) steering strength or (ii) log‑odds of refusal/compliance token sets to preserve policy.
- Tools/workflows: VA anomaly detection; token‑logit clamping with whitelist/blacklist; policy‑aware overrides.
- Assumptions/dependencies: Acceptable trade‑offs with naturalness/utility; strong governance and audit trails.
- Personalized, closed‑loop VA adaptation
- Sectors: education, coaching, wellbeing apps, social robots.
- What: Dynamically adjust VA to match user state and goals (e.g., raise arousal to motivate, lower to de‑escalate), using biometric or interaction signals.
- Tools/workflows: User consent and telemetry; VA controllers with safety caps; reinforcement learning from user feedback.
- Assumptions/dependencies: Privacy/ethics safeguards; careful evaluation to avoid manipulation or harm.
- Policy and standards for affective control disclosure
- Sectors: regulators, standards bodies, platform governance.
- What: Require transparency about affective steering, set limits in sensitive domains (e.g., political persuasion), and mandate affect‑sensitivity audits.
- Tools/workflows: Conformance test suites (VA stress tests), reporting templates for VA control ranges and impacts.
- Assumptions/dependencies: Multistakeholder consensus; empirical evidence linking VA control to real‑world outcomes.
- Data curation and labeling guided by VA geometry
- Sectors: dataset publishers, RLHF teams, content platforms.
- What: Use VA projections to balance datasets (avoid skewed arousal/valence), improve feedback prompts, and target collection gaps (e.g., low‑arousal positives).
- Tools/workflows: VA‑aware sampling; annotator tools visualizing circumplex positions; bias audits.
- Assumptions/dependencies: Stable VA mapping across dataset domains; annotator training.
Cross‑cutting assumptions and dependencies
- Access level: Full benefits require activation‑level steering; when unavailable, prompt‑level VA proxies can partially substitute but are less precise.
- Calibration: Effects are model‑ and layer‑dependent; α must be tuned to avoid OOD while preserving capabilities.
- Measurement: VAD‑BERT/VADER are proxies; high‑stakes deployments should include human evaluation.
- Generality: Validated on English and specific architectures; multilingual/multimodal generalization is an open area.
- Ethics: VA control can be dual‑use (e.g., increasing arousal to bypass guardrails); governance and disclosure are essential.
Glossary
- Ablation: The removal or deactivation of model components (e.g., neurons) to test their causal contribution to behavior. "Ablating the top- refusal-aligned neurons across 750 prompts confirms a distributed effect"
- Activation steering: Manipulating internal activations of a model to control its behavior without retraining. "emotionally framed prompting or activation steering influences LLM behavior"
- Algebraic least squares: A fitting method minimizing algebraic (not geometric) residuals, here used to fit a circle to 2D projections. "fit circles to the projected coordinates using algebraic least squares"
- Arousal: An affective dimension measuring activation or intensity (calm–excited) used alongside valence. "increasing arousal decreases refusal and increases sycophancy"
- Circumplex model (of affect): A circular geometric model organizing emotions along valence and arousal axes. "analogous to circumplex model of affect"
- Circularity: A metric quantifying how tightly points lie on a circle in the projected space. "We report circularity---the ratio of mean to standard deviation of distances from the fitted center---"
- Contrastive differences: Vectors computed by contrasting activations between two conditions (e.g., emotion vs. neutral) to define a direction. "construct directions via contrastive differences (e.g., mean activation differences over paired examples)"
- Contrastive refusal directions: Task-specific activation directions derived by contrasting refusal vs. compliance states. "Contrastive refusal directions \citep{arditi2024refusallanguagemodelsmediated} are nearly orthogonal to our VA plane"
- Core affect: A continuous psychological substrate (valence–arousal) from which discrete emotions are construed. "valence and arousal (VA) do not define emotions themselves but rather core affect"
- Cross-architecture generality: The property that a method or structure holds across different model architectures. "demonstrating cross-architecture generality."
- Down-projection vectors: The vectors that map MLP neuron outputs back into the model’s residual stream space. "whose down-projection vectors align with refusal-token and compliance-token unembedding directions"
- Emotion steering vectors: Activation directions derived from emotion-labeled data used to steer generation. "we derive emotion steering vectors"
- Gram--Schmidt orthogonalization: A procedure to orthogonalize vectors, used here to make VA axes orthonormal. "With Gram--Schmidt orthogonalization, we ensure the valence and arousal axes are orthonormal."
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step. "All generations use greedy decoding."
- Last-token hidden state: The model representation at the final token position, often used to summarize an input. "we extract the last-token hidden state of each sample at each layer."
- Lexical mediation: A mechanism where changes in internal affective coordinates alter the likelihood of emitting specific tokens that drive behavior. "We refer to this mechanism as lexical mediation."
- Logit clamping: Freezing selected token logits during generation to test their causal role in behavior. "Logit Clamping Confirms Constitutive Role."
- Logit lens: A technique projecting intermediate activations through the unembedding to inspect token-level predictions. "Applying the logit lens technique"
- Log-odds: The logarithm of odds, used to quantify changes in token probability ratios. "Arousal steering monotonically shifts refusal token log-odds."
- Mean activation differences: Averaged differences of activations across paired datasets to form contrast vectors. "mean activation differences over paired examples"
- Mean-centering: Subtracting the mean from vectors before analysis to remove offsets. "We first mean-center the vectors"
- Mean-difference contrasts: Constructing directions by subtracting mean activations between two classes. "derive emotion steering vectors via mean-difference contrasts between emotion-labeled and neutral examples"
- MLP neuron: A unit in transformer feed-forward layers implicated in feature representation and control. "MLP Neuron Analysis."
- NRC-VAD Lexicon: A human-annotated lexicon of valence, arousal, and dominance scores for English words. "project words from the NRC-VAD Lexicon"
- Out-of-distribution (OOD): Generation or behavior that deviates from the model’s training distribution. "as stronger interventions induce OOD generation"
- Principal component analysis (PCA): A dimensionality reduction technique used to find key axes in activation data. "apply principal component analysis"
- Ridge regression: L2-regularized linear regression used to combine PCs into valence and arousal axes. "learn VA axes as linear combinations of their top PCA components via ridge regression"
- Self-reported VA scores: The model’s own elicited assessments of valence and arousal for labels/items. "the model's self-reported valence--arousal scores"
- Sycophancy: A behavior where the model agrees excessively with the user regardless of correctness. "increases sycophancy, and vice versa."
- Unembedding matrix: The matrix mapping hidden states to vocabulary logits. "The unembedding matrix maps hidden states to logits."
- VA steering: Steering along valence–arousal directions to control affect and downstream behaviors. "We evaluate VA steering across three benchmarks"
- VA subspace: A low-dimensional space spanned by valence and arousal directions within model representations. "the learned VA subspace enables controllable, bidirectional modulation of generated affect."
- VAD-BERT: A BERT-based regressor predicting valence and arousal scores from text. "VAD-BERT is a BERT-based regressor trained on the EmoBank corpus"
- VADER: A lexicon-based sentiment analyzer producing a compound polarity score. "VADER is a lexicon-based sentiment analyzer"
- Valence: An affective dimension measuring pleasantness (negative–positive). "valence spans from extremely unpleasant () to extremely pleasant ()"
Collections
Sign up for free to add this paper to one or more collections.