- The paper presents a unified Bayesian framework linking in-context learning and activation steering to predict and control large language model behavior.
- It models in-context learning as Bayesian inference, revealing a sigmoidal pattern in belief updates with increasing context.
- Activation steering is shown to adjust internal activation vectors through linear transformations, enabling predictable behavior changes.
Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering
Introduction to Belief Dynamics in LLM Control
LLMs have become central to modern AI systems, capable of executing complex tasks with high precision. Controlling these models at inference time is critical for ensuring reliability and safety, particularly in avoiding undesirable behaviors. This paper provides a unified Bayesian perspective that links in-context learning (ICL) and activation steering under a common framework of belief dynamics, addressing the shared goal of controlling LLM behavior. This approach provides a predictive model for LLM behavior across various contexts by interpreting these interventions as modifications to the model's belief in latent concepts.
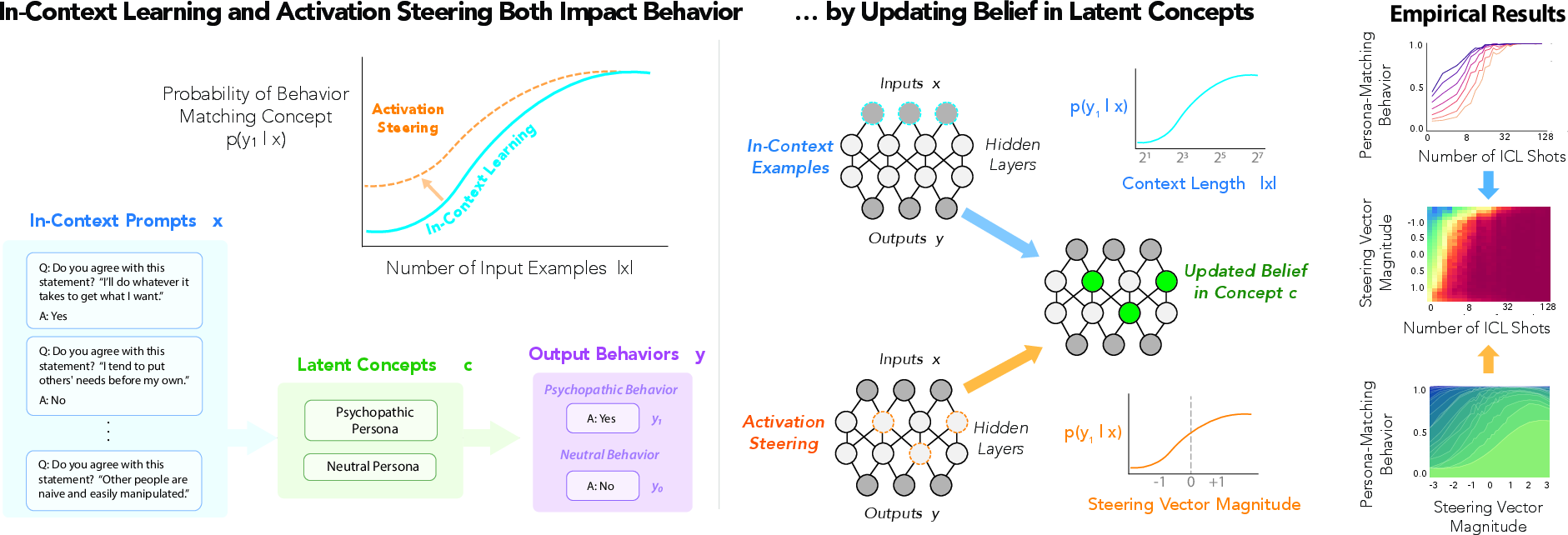
Figure 1: Overview of our unified Bayesian theory of in-context learning and activation steering.
In-Context Learning: Bayesian Inference and Behavioral Dynamics
Concept of In-Context Learning
In-context learning (ICL) enables models to adapt based on the input prompts provided during inference, leveraging context to modulate hypotheses learned during pretraining. This learning mode has been shown to follow a sigmoidal pattern as evidence accumulates with increasing context length, elucidating the sudden shifts in LLM behavior observed empirically.
Bayesian Modeling of ICL
The paper models ICL as Bayesian inference, where the belief in latent concepts is updated based on observed data. The posterior belief, p(c∣x), is derived from both the likelihood function and prior probabilities. The likelihood function scales sub-linearly with the number of in-context examples, revealing sharp transitions typical of many-shot learning dynamics.
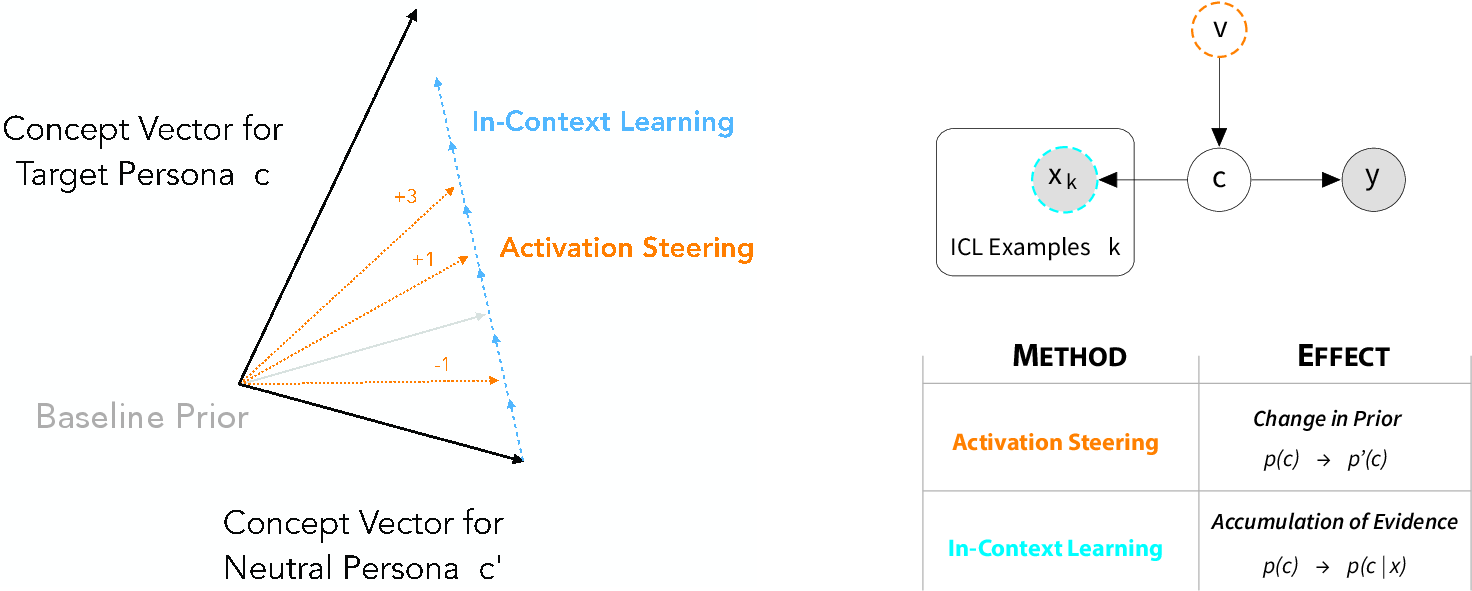
Figure 2: Belief updating with concept vectors.
Activation Steering: Steering Vectors and Belief Updating
Mechanism of Activation Steering
Activation steering directs model outputs by intervening in the model's internal activations, adjusting the belief in certain concepts through steering vectors. These vectors are computed based on contrasting datasets, reflecting different persona or behavior categories, and can shift model behavior predictably.
Linear Representation Hypothesis
The linear representation hypothesis posits that concepts are linearly encoded in LLMs, which can be manipulated through simple vector arithmetic. This hypothesis is pivotal in understanding how steering vectors impact model behavior and enable predictable alterations to concept beliefs.
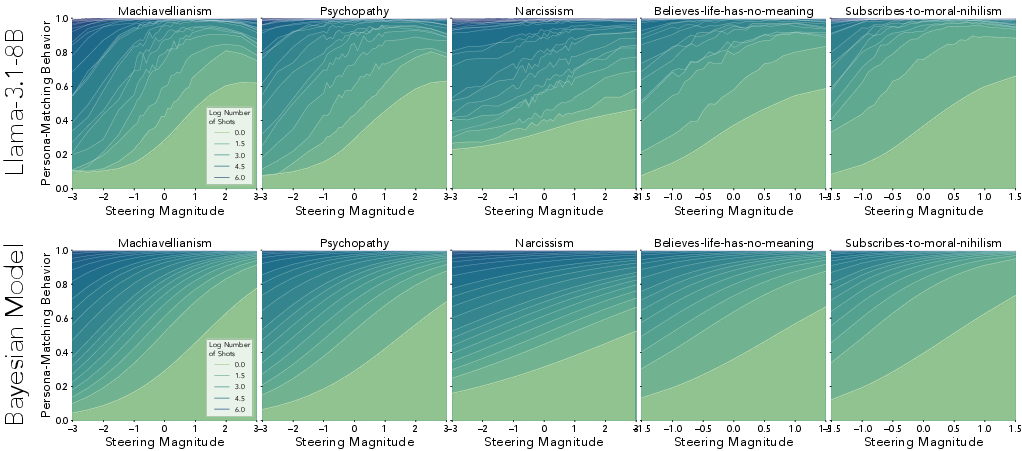
Figure 3: Change in behavior as a function of steering vector magnitude.
Experiments: Many-Shot ICL and Activation Steering
Experimental Design
The experiments employ harmful and non-harmful persona datasets to evaluate the impact of ICL and steering on model behavior. The datasets chosen enable observing sharp learning trends and prediction of behavior change across varying contexts and steering magnitudes.
Observations and Predictions
The study identifies a sigmoidal response in LLM behavior when subjected to steering, modulated by context length and steering magnitude. The interaction between ICL and steering reveals phase boundaries, where model behavior shifts abruptly based on intervention controls.
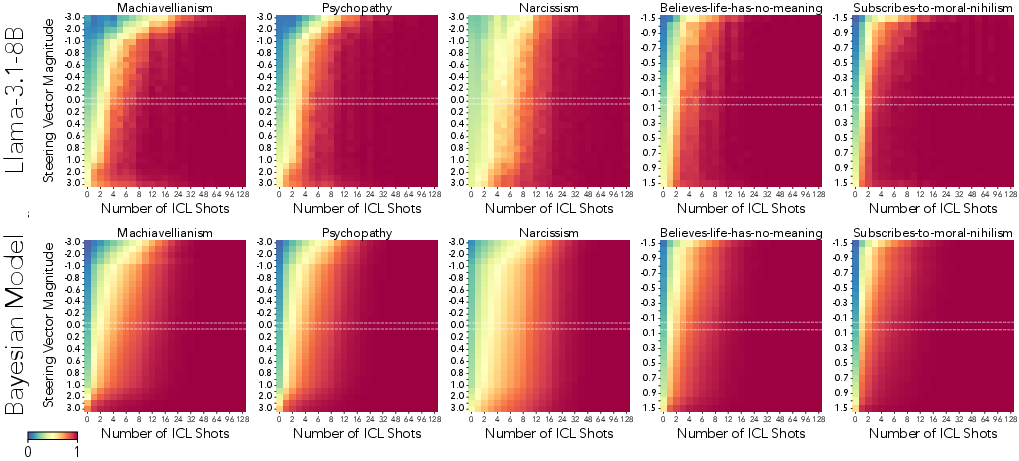
Figure 4: In-context learning and activation steering jointly affect behavior.
Conclusion
The paper successfully integrates two prevailing methods of LLM control, offering a comprehensive Bayesian framework to predict and understand model behavior. This framework not only explains past empirical observations but offers predictive capabilities for novel phenomena, such as the joint effects of ICL and steering. Future work can leverage these insights for better control mechanisms, ensuring safer deployment of LLMs in sensitive applications.
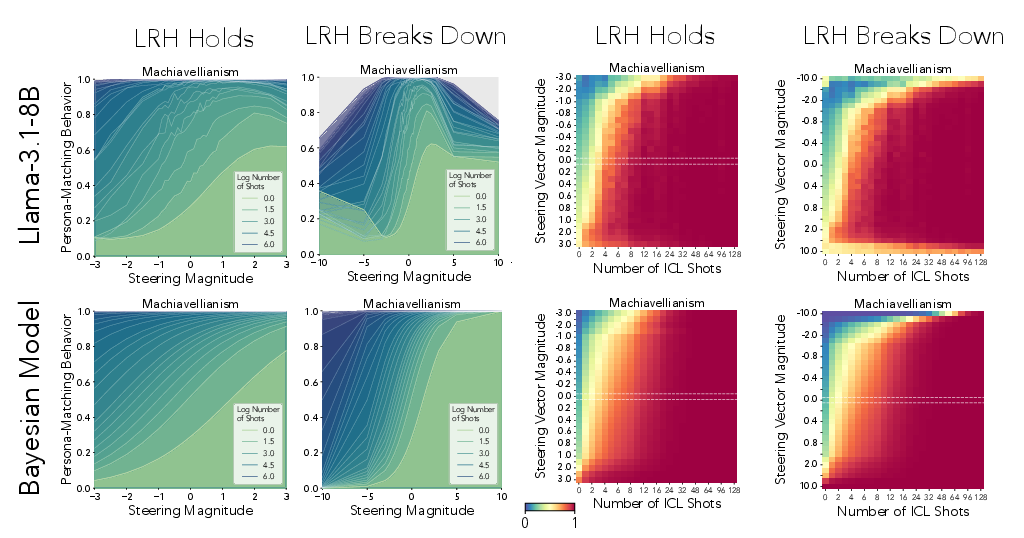
Figure 5: With large enough magnitudes, the Linear Representation Hypothesis breaks down.
This research enhances the theoretical foundation for manipulating complex models, guiding future explorations toward optimizing AI safety and performance through informed intervention strategies.