- The paper shows that function vectors (FVs) can effectively steer model behavior even when the logit lens fails to decode the intended outputs.
- It employs extensive cross-template and cross-architecture experiments across 12 tasks and 6 models, revealing template-invariant, additive effects.
- The study uncovers that FVs encode computational instructions rather than direct answer representations, challenging standard interpretability approaches.
Steerable but Not Decodable: Function Vectors Operate Beyond the Logit Lens
Introduction and Context
The paper "Steerable but Not Decodable: Function Vectors Operate Beyond the Logit Lens" (2604.02608) presents a comprehensive evaluation of Function Vectors (FVs) as tools for activation steering in LLMs. FVs, defined as mean-difference directions taken from in-context learning (ICL) demonstrations, are added to a model’s residual stream, thereby aiming to induce specific behaviors without retraining or fine-tuning the model parameters. The central innovation of this work is the systematic, cross-template, and cross-architecture analysis of when and how FVs are effective, and a direct confrontation with the intuition—stemming from the linear representation hypothesis—that effective FVs should be interpretable (or at least decodable) by the model’s output head at some point in the computation.
Experimental Design
The study spans 12 discrete tasks across five computational categories, employing 6 models from 3 prominent LLM families (Llama-3.1-8B, Gemma-2-9B, Mistral-7B-v0.3, with both base and instruction-tuned variants), and evaluating FV transfer across 8 templated prompt formulations per task. This yields a matrix of over 4,000 cross-template transfer cases. For each task, the FV is extracted via the mean difference between the residual activations for positive (ICL-consistent) and negative (ICL-inconsistent) demonstrations, then injected at variable layers and magnitudes during inference.
The analysis benchmarks IID (in-distribution) template performance versus OOD (cross-template), probes the alignment between geometric similarity and steering efficacy, and—crucially—interrogates the representational decodability of FV-perturbed activations via two approaches: (1) the zero-parameter logit lens (layer-wise projection onto the model’s final unembedding), and (2) direct FV vocabulary-space projection.
Main Empirical Findings
Steerability-Decodability Dissociation
Contrary to the initial hypothesis, the major empirical result is that FV steering succeeds in many cases where the logit lens fails completely to decode the correct answer at any layer. The previously assumed implication—that failed FV steering would correspond to an absence of decodable task-relevant information—does not hold. Instead, a universal gap emerges: for every task and model, FV steering accuracy consistently matches or exceeds logit lens accuracy at all tested layers, often by large margins (max observed steerability-decoding gap: −0.91).
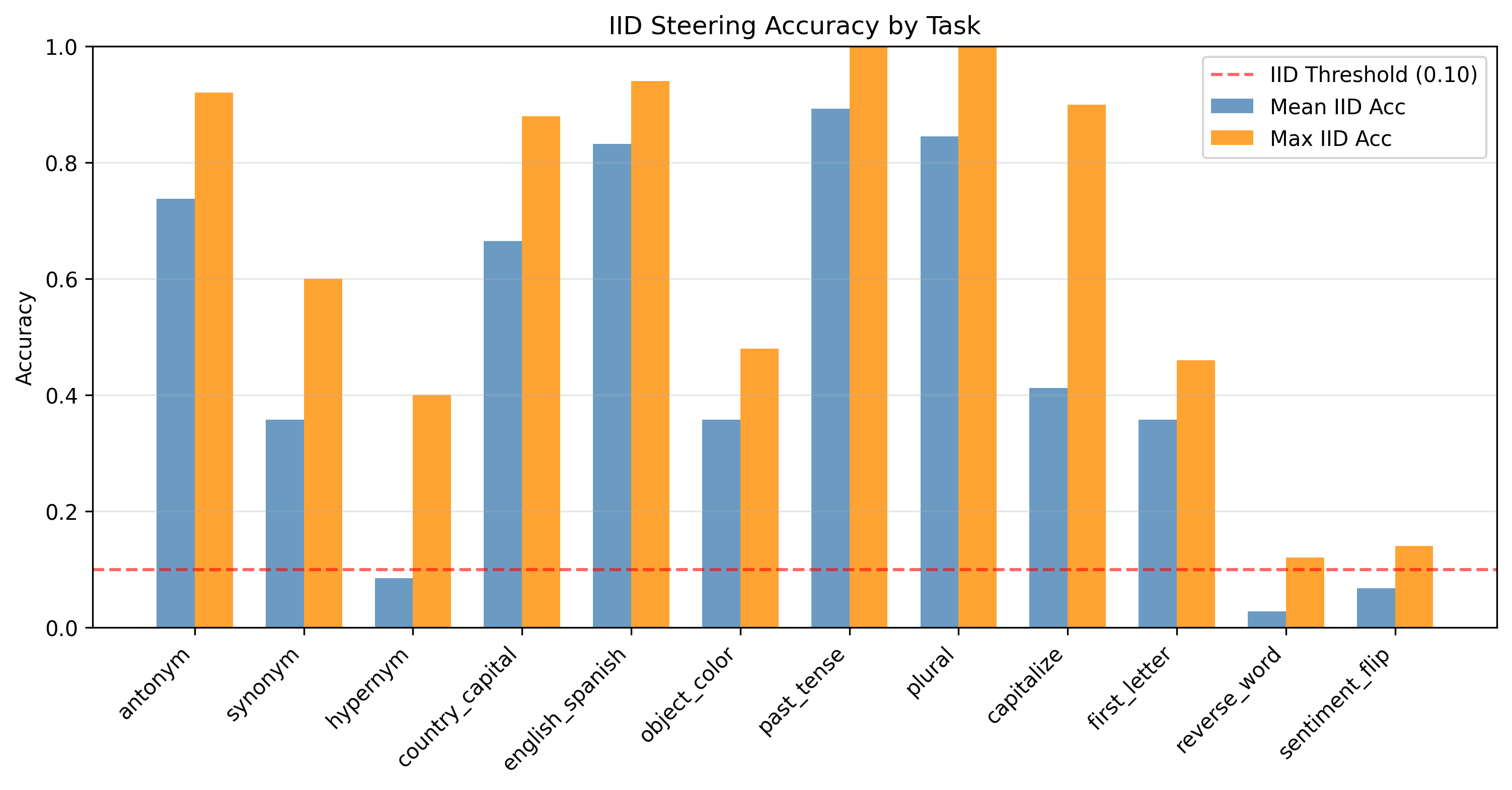
Figure 1: IID steering accuracy across all 12 tasks for Llama-3.1-8B Base. The horizontal dashed line marks the IID threshold (τ=0.10). Morphological tasks dramatically exceed predictions. Character-level capitalize and first_letter succeed (falsifying negative-control predictions), while only reverse_word and sentiment_flip consistently fail.
This pattern holds across all three major LLM families, with only three out of 72 model-task combinations showing the opposite "decodable without steerable" result (all specific to Mistral).
Additivity, Template-Invariance, and Geometry
FV-steered outputs are either additive or neutral relative to the model’s baseline capability: steering never destructively interferes with model computation. Moreover, transfer between templates (OOD transfer) shows minimal degradation compared to IID steering for most tasks—underscoring the template-invariant nature of FV-induced interventions.
Cross-template transfer correlation with geometric alignment (cosine similarity of FVs) is negligible after controlling for task identity. The paper’s large-scale analysis dissolves the negative cosine-transfer correlation previously reported at smaller scale, demonstrating that geometric similarity is not a functional predictor of steering success.
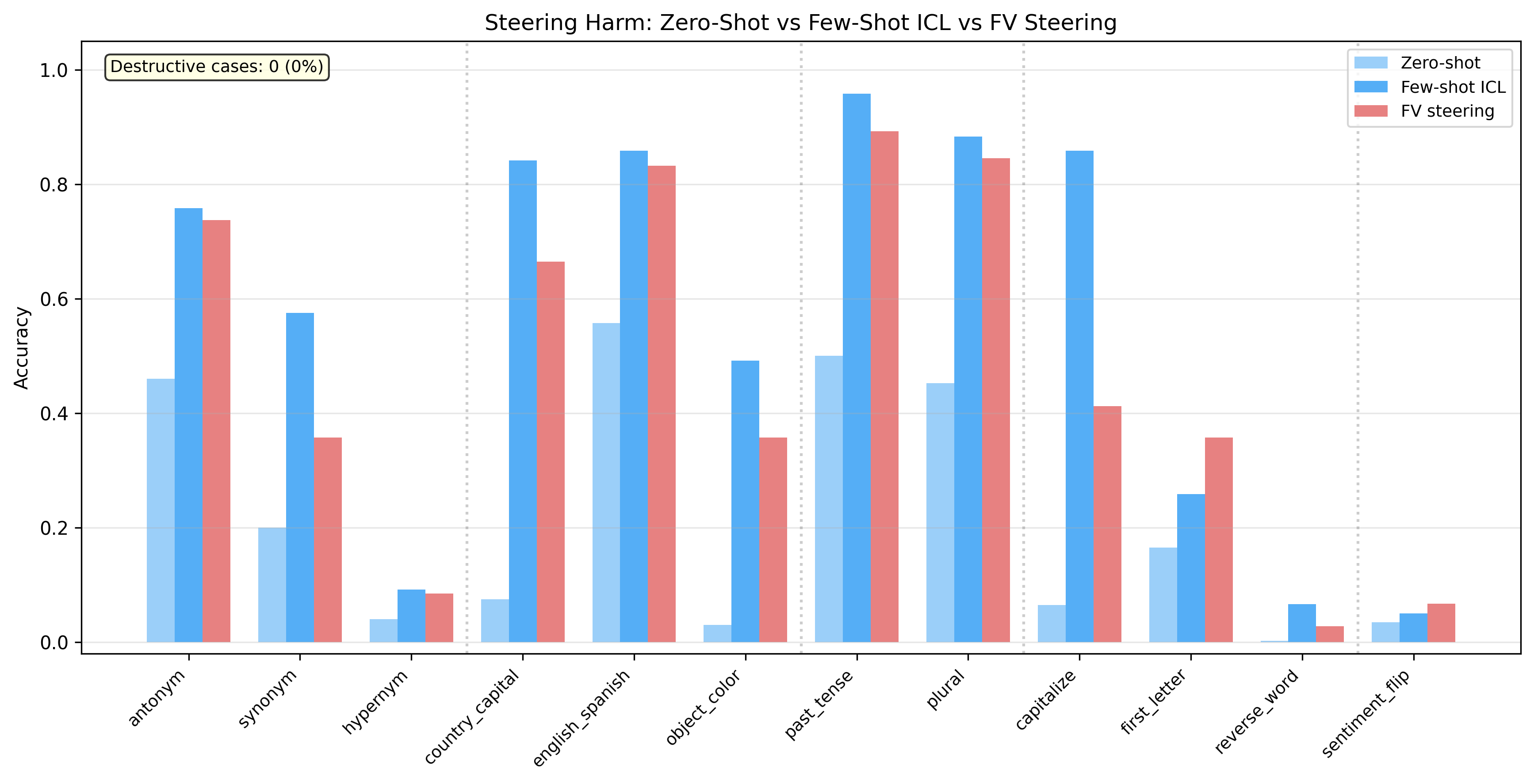
Figure 2: Zero-shot vs.\ few-shot ICL vs.\ FV-steered accuracy for Llama-3.1-8B Base. FV steering is consistently additive or neutral---it never catastrophically interferes with the model's existing computation. For most tasks, FV steering matches or approaches few-shot ICL accuracy.
FV Vocabulary Projection and Computational Instruction
A central claim of the paper is that FVs encode computational instructions—that is, they induce a trajectory through the network’s computation graph, rather than merely shoving the residual stream toward a direction in vocabulary space. This is bolstered by FV vocabulary projections, which show that FVs with high (>0.90) steering accuracy still project to incoherent, largely irrelevant token distributions, except for first_letter, which partially projects to single-character tokens but not the correct answer tokens. Thus, FVs are not answer directions from the perspective of the model's unembedding.
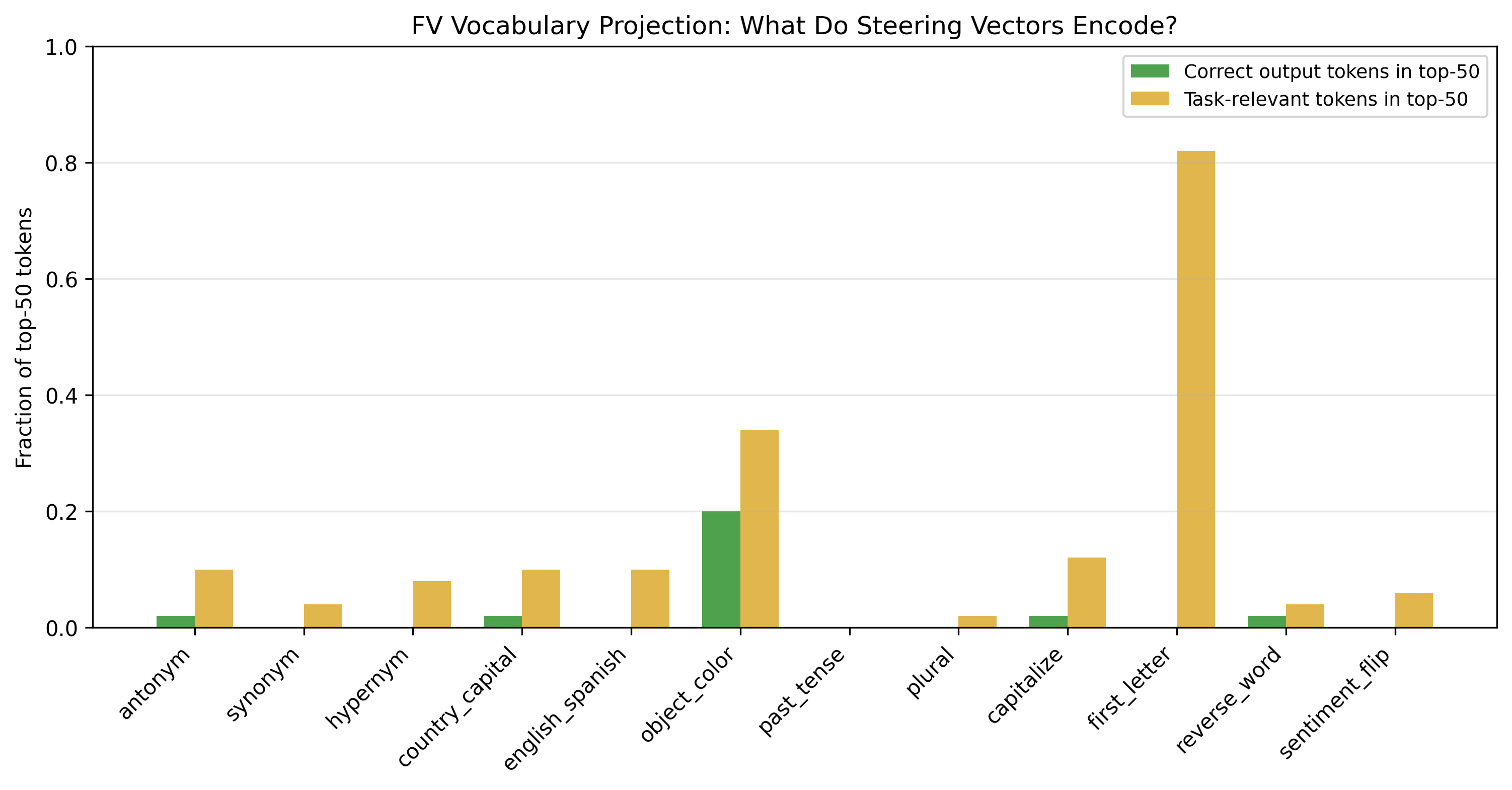
Figure 3: FV vocabulary projection results for Llama-3.1-8B Base. The near-universal incoherence of FV vocabulary projections, even for highly effective FVs (>0.90 steering accuracy), demonstrates that FVs encode computational instructions rather than answer directions. The partial exception is first_letter (task-relevant fraction ∼0.82): the FV projects to single-character tokens, though not to the correct specific letters.
Layerwise Effects and Model Family Mechanisms
The optimal injection layers for FV steering are early (L2–L8), while the logit lens only begins to decode correct answers at late layers (L28–L32). This layerwise dissociation strongly supports the notion that FV steering catalyzes the execution of internal processes rather than immediately cracking open a latent answer representation.
Moreover, post-steering logit lens analysis reveals a mechanistic bifurcation: Mistral FVs tend to write the answer directly into the logit lens space (producing dramatic jumps in decodability post-intervention), while Llama/Gemma FVs produce the behavioral effect without leaving a trace in the unembedding-aligned subspace, hinting at a duality between representational (Mistral) and modulatory (Llama/Gemma) steering modes.
Theoretical and Practical Implications
The findings decisively challenge the linear representation hypothesis as a universal explanation for successful activation steering. Specifically, the decodability and steerability of internal activations are shown to be separable: additive interventions can reliably induce complex behavioral changes in LLMs via subspaces and computational trajectories not linearly decodable by the output head at any stage. This disconnect implies FVs fundamentally manipulate the model’s propensity to enact certain computations, rather than merely biasing output token likelihoods—a notion that undermines the interpretability of such interventions by standard tools like the logit lens or vocabulary-space projection.
From a safety perspective, the steerability-without-decodability result implies that conventional monitoring and post hoc analysis relying on vocabulary projection or layerwise probing may systematically miss stealth behavioral interventions. Such “invisible” interventions highlight the necessity of behavior-centric, black-box evaluation methods for verifying and validating activation additions in LLM deployments.
Limitations and Future Directions
The study is limited to medium-scale (7–9B parameter) models; generalization to 70B+ or multimodal architectures remains untested. Only the mean-difference FV extraction method is assessed; there may exist alternative steering vector derivation protocols that interact differently with model representations. The logit lens approach is intentionally parameter-free—relaxing this constraint (e.g., via per-layer affine transformations as in the tuned lens) could revisit the issue of probe complexity and spurious decoding. Open-domain generation tasks, where correct answers are not single tokens, remain unexplored.
Conclusion
This work establishes, at scale and across architectures, that function vectors can robustly induce template-invariant, stepwise-behavioral changes in LLMs through non-decodable internal subspaces. Steering success and decodability, as inferred by the model’s own unembedding, are systematically decoupled, often with steering far outpacing decodability. This compels a revision of representation-centric theories of activation steering, foregrounds the distinction between computational instruction and answer representation, and mandates behavioral validation for safety-critical LLM deployments. The study also delineates divergent mechanisms between major transformer families, inviting further research on the mechanistic underpinnings and broader applicability of activation steering techniques.

