- The paper introduces ARIS, a system for automating research with adversarial multi-agent collaboration to enhance the reliability of long-horizon workflows.
- It details a modular architecture with over 65 skills and a three-layer pipeline covering idea generation, experiment execution, and rigorous auditing.
- Empirical results demonstrate improved review scores (from 5.0 to 7.5), while also highlighting limitations like reviewer bias and the lack of formal correctness guarantees.
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Introduction
"ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration" (2605.03042) presents a comprehensive architecture and methodology for automating the end-to-end scientific research workflow by orchestrating heterogeneous LLMs in adversarial, reviewer-executor interactions. The central claim is that single-agent, long-horizon research workflows are inherently unreliable, and that plausible but unsupported scientific claims are a more significant hazard than overt failure. To mitigate these risks, ARIS introduces a multi-layered research harness emphasizing modular execution, persistent research memory, and a rigorous, independently operated assurance stack.
System Architecture and Design Principles
ARIS implements a three-layer architecture: execution, orchestration, and assurance. The execution layer exposes over 65 modular Markdown-defined "skills," facilitating platform-agnostic research capabilities ranging from literature review and ideation to experiment deployment and manuscript assembly. Integrated model bridges enable seamless calls to multiple LLM providers. The orchestration layer manages five end-to-end workflows: idea discovery, experiment bridge, auto-review, paper writing, and rebuttal. These workflows can be composed, recovered, or extended with minimal coupling.
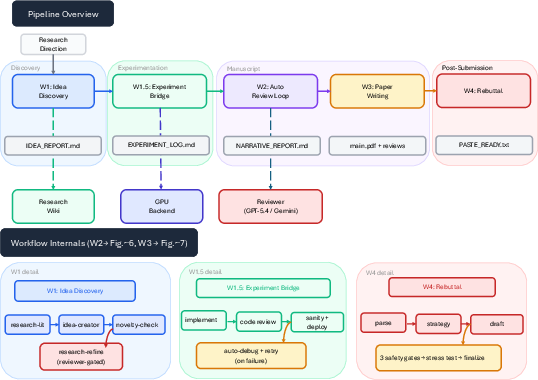
Figure 1: The ARIS workflow library demonstrates five interconnected workflows and their artifact contracts, annotated by research phase.
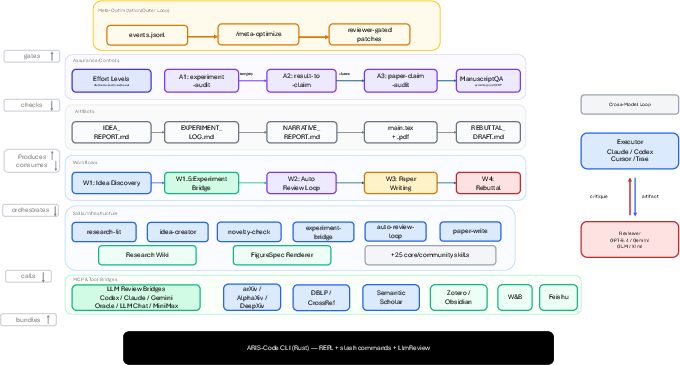
Figure 3: System topology showing the interaction and control flow between meta-optimization, assurance, workflow, skills, and various LLM bridge subsystems.
ARIS defaults to cross-family executor-reviewer pairings (e.g., Claude executor, GPT-based reviewer), under the hypothesis—supported by multi-agent debate studies—that heterogeneous LLM systems generate more independent and less correlated critiques than homogeneous self-refinement loops. Skills exchange versioned artifacts in lightweight, human-readable formats, improving transparency and reproducibility across sessions and platforms.
Cross-Model Adversarial Collaboration
The core mechanism of ARIS is the critique-to-action adversarial loop: an executor model generates an artifact, which is independently reviewed—and often challenged—by a reviewer from a different model family. This loop continues iteratively until either a review score threshold is met or a fixed number of rounds elapse. Reviewer access policies range from document-only to repository-level, and reviewers can operate with or without cross-round memory to control for bias or ensure progress.
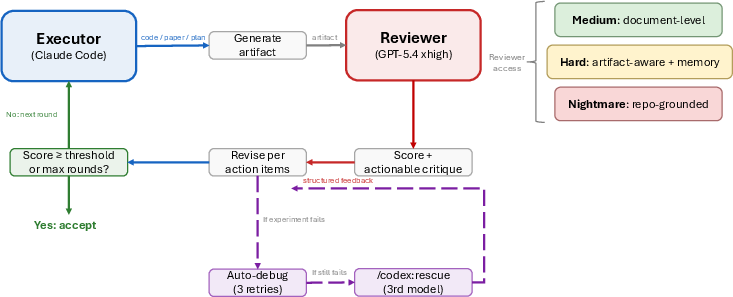
Figure 5: Cross-model adversarial collaboration: executor alternates with reviewer critique, revision requests, and convergence checks.
Reviewer independence is strictly enforced. The reviewer must directly access referenced artifacts to minimize bias propagation from the executor’s summarization. In case of experiment failures, automated remediation cascades are employed with escalation to tertiary diagnostic models as necessary.
Assurance Stack and Audit Cascade
A highlight of ARIS is its three-stage evidence-to-claim assurance cascade:
- Experiment-integrity audit: Reviewer inspects evaluation scripts and outputs for integrity failures, such as model-derived reference generation, self-normalized metrics, phantom results, dead-code inflation, and unjustified generalization.
- Result-to-claim mapping: Every experimental claim is mapped to evidence and assigned a status—supported, partially supported, or invalidated. Stage 1 audit statuses directly constrain allowable claim verdicts.
- Paper-claim audit: A zero-context, fresh-thread reviewer checks all quantitative claims in the manuscript against raw evidence, focusing on numerical mismatches, cherry-picking, misalignments, and scope overclaim.
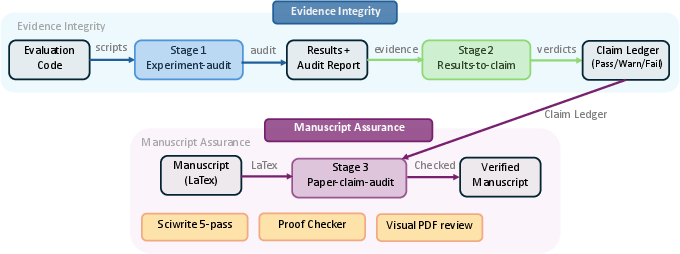
Figure 2: Assurance stack—evidence-to-claim audit cascade outlining three distinct, composable audit stages culminating in a final manuscript check.
Additionally, ARIS applies a five-pass scientific editing pipeline to manuscript drafts (clutter removal, active-voice enforcement, sentence structure, terminology consistency, and numerical consistency), proof-checker mechanisms for theorem verification, visual PDF reviews, and exhaustive citation audits (including claim-context verification, not just metadata consistency).
Persistent Memory and Workflow Recovery
A persistent research wiki records papers, ideas, experiments, and claim status—including negative outcomes—across sessions. This supports non-redundant, spiraling research trajectories, overcoming the statelessness issues prevalent in earlier agent frameworks.
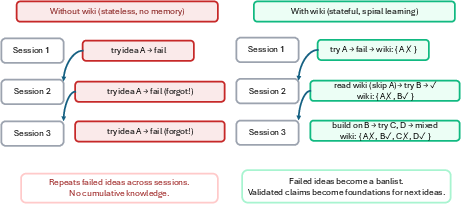
Figure 4: The research wiki prevents repetitive exploration of failed ideas, supporting spiral learning across multiple research cycles.
Workflow Orchestration
Workflows are constructed by chaining relevant skills, inducing a modular pipeline spanning ideation (literature survey, ideation, novelty checks), experimentation (experiment bridging, execution, result analysis), auto-review (revision loops), paper writing (planning, LaTeX drafting, proof checking, assurance), and rebuttal.
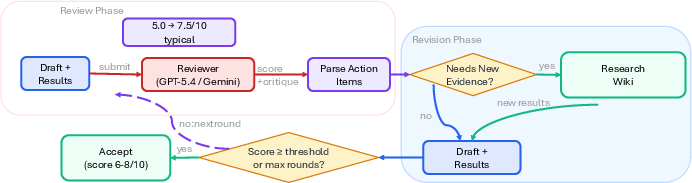
Figure 6: Auto Review Loop: cross-model reviewer scoring, action extraction, optional experimentation, revision, and convergence.
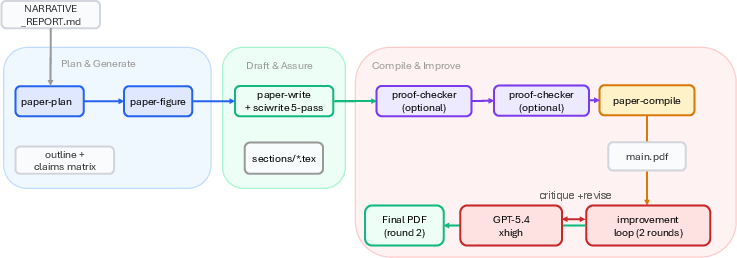
Figure 7: Paper Writing Pipeline: planning, generation, drafting with editing, claim auditing, compiling, assurance, and visual review.
Supporting infrastructure includes bridges for multiple LLMs, external tool APIs (citation, literature, experiment tracking), deterministic figure rendering for reproducibility, and a CLI based on a standalone binary for deployment flexibility. ARIS logs all workflow execution and reviewer-interaction traces, enabling automated meta-optimization routines that propose harness and prompt refinements—subject to external reviewer approval.
Empirical Results and Limitations
Empirical reporting documents overnight runs comprising four review-revision cycles, 20+ GPU experiments, and review-driven claim pruning, with review scores improved from 5.0 to 7.5/10. The system demonstrates the operational viability of adversarial review loops and artifact-state persistence in realistic research settings.
Boldly, the paper asserts that any long-term research task performed by a single agent should be treated as unreliable, thus establishing cross-model, adversarial collaboration as a minimal necessary condition for research automation. This is a stricter stance than prior work, which often tolerates single-agent or homogeneous review configurations.
Key limitations include the absence of causal, compute-matched benchmarking to isolate the contribution of cross-model review, persistent susceptibility to reviewer bias amplification within the review loop, and residual risks of undetected errors and hallucinations even after assurance passes. ARIS does not provide formal guarantees of research correctness, novelty, or soundness; its audit layers are advisory, not verifiable.
Implications and Future Directions
Practically, ARIS advances the state of autonomous research harnesses by emphasizing heterogeneous adversarial review, explicit assurance mechanisms, and modular, portable skill definitions. Theoretically, it frames research automation through the lens of adversarial bandit and game-theoretic control, shifting the focus from capability demonstration to rigorous error-detection and claim validation.
Potential future developments include integrating confidential, local reviewer models; formal benchmarks dissecting the impact of reviewer-executor family separation; and extending the ARIS assurance apparatus to downstream data curation and reward-model pipelines for LLM self-improvement. The architectural primitives—adversarial reviewer independence, audit cascades, and provenance-aware ledgers—may generalize to other long-horizon, high-stakes automation domains.
Conclusion
ARIS delivers a rigorously engineered harness for autonomous research workflows, centering cross-family adversarial collaboration and a structured assurance cascade as minimal requirements for credible, end-to-end research automation. Its architectural innovations—persistent memory, modular skills, and independent auditing—provide meaningful checks against plausible unsupported success, setting a higher baseline for both technical robustness and empirical transparency in future autonomous research systems. Despite persistent limitations and the need for controlled validation, its methodology and claims represent a substantive advance in the automation and assurance of scientific research workflows.

