- The paper presents evidence chain mining to optimize retrieval quality by reducing noise and explicitly linking relevant evidence for improved reasoning.
- It introduces a three-stage pipeline—candidate evidence space identification, prefix-tree constrained chain generation, and context filtering—to balance comprehensiveness and noise suppression.
- Empirical results on benchmarks like HotpotQA demonstrate up to 9.4% F1 improvement, significant token efficiency, and enhanced Recall Conversion Rates.
NeocorRAG: Evidence Chain-Driven Retrieval Quality Optimization for RAG
Background and Motivation
Retrieval-Augmented Generation (RAG) frameworks integrate IR with LLMs to mitigate hallucinations and enable up-to-date factual knowledge access. Conventional RAG approaches heavily optimize recall-based metrics (e.g., Recall@k, NDCG), yet empirical evidence demonstrates a non-trivial gap between high recall and downstream reasoning performance. As illustrated, methods that maximize Recall@5 often experience a monotonically decreasing Recall Conversion Rate (RCR), revealing the inadequacy of traditional recall metrics to capture retrieval quality and utility for reasoning (Figure 1).
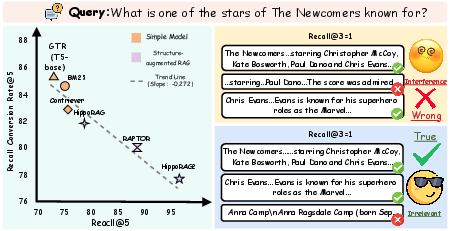
Figure 1: Improved Recall@5 is accompanied by decreased RCR, exemplifying that recall metrics inadequately measure retrieval quality for reasoning tasks.
Empirical evaluation on popular benchmarks, such as HotpotQA, shows incongruent gains between retrieval recall and QA F1 scores. For instance, HippoRAG2 attains a passage Recall@5 of 96.3% but only a QA F1 of 75.5%, evincing that the inclusion of irrelevant or misleading content impedes effective reasoning despite high nominal coverage.
Retrieval Quality: Optimization Criteria and Methodological Analysis
Recognizing deficiencies in recall-oriented retrieval, the paper formalizes three explicit criteria for retrieval quality optimization:
- Comprehensiveness: Ensuring broad coverage of both explicit and latent evidence supporting reasoning.
- Noise Suppression: Minimizing the inclusion of irrelevant or misleading text that could interfere with downstream reasoning.
- Evidence Visualization: Explicating hidden associations among retrieved entities, making implicit information actionable for LLMs.
Systematic analysis (Figure 2) reveals that existing methods bifurcate into structure-enhanced and reasoning-enhanced categories. Structure-enhanced approaches (e.g., HippoRAG, RAPTOR) achieve high recall and comprehensiveness but are susceptible to noise and lack evidence visualization. Reasoning-enhanced methods (e.g., Trace, RetroLLM, CoRAG) improve noise suppression and explicit evidence but often sacrifice context completeness. Neither paradigm jointly optimizes all criteria, resulting in a trade-off dilemma.
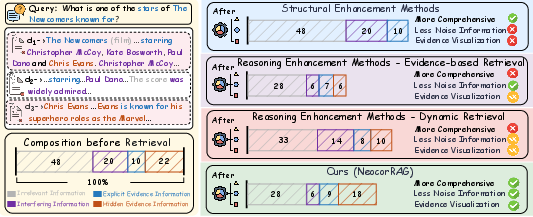
Figure 2: Comparative analysis of retrieval methods across optimization criteria, showing NeocorRAG achieves balanced optimization across comprehensiveness, noise suppression, and evidence visualization.
NeocorRAG Framework: Evidence Chain Mining and Retrieval Optimization
NeocorRAG introduces a three-stage, evidence chain-driven framework for holistic retrieval quality optimization (Figure 3):
- Candidate Evidence Space Identification: An activation-based path search algorithm traverses subgraphs of retrieved documents, starting from query-relevant entities to exhaustively mine potential evidence chains, scoring them by joint semantic similarity and confidence thresholds.
- Precise Evidence Chains Generation: The candidate chains are organized as a prefix tree, enabling constrained decoding within this space by an auxiliary LLM. The decoding process is strictly constrained by prefix tree membership, ensuring that only valid, highly-relevant evidence chains are generated.
- Retrieved Context Optimization: The evidence chains are used to filter noise from the initial retrieval set, retaining only documents containing supporting triples or those that form part of the evidence chains. The refined context offers minimal redundancy while maximizing actionable evidence for downstream LLMs.
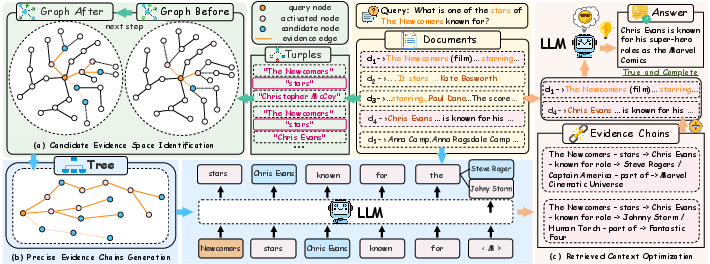
Figure 3: NeocorRAG's sequential evidence mining: candidate space identification, prefix-tree constrained evidence chain generation, and optimized context filtering.
This pipeline leverages generative reasoning to transcend shallow surface-level retrieval, explicitly surfacing latent associative evidence and minimizing information leakage.
Comprehensive evaluation on four QA benchmarks (NQ, MuSiQue, 2WikiMultiHopQA, HotpotQA) demonstrates that NeocorRAG consistently outperforms strong baselines (HippoRAG2, Trace, CoRAG, RAPTOR) across model sizes (Llama-3.2-3B, Llama-3.3-70B):
- F1 score improvements: Up to 9.4 percentage points on HotpotQA over HippoRAG2, with up to 11.2% average gain over Trace on 70B models.
- RCR gains: Up to 9.6 percentage points improvement, validating that evidence chain optimization directly translates retrieval utility into reasoning effectiveness.
- Token efficiency: NeocorRAG reduces token usage to 20.1% of CoRAG and 2.94% of Trace, achieving substantial computational savings.
- Filtering efficacy: Evidence-chain-guided filtering halves the number of irrelevant documents while sustaining recall above 80%, far surpassing reasoning-enhanced filtering baselines.
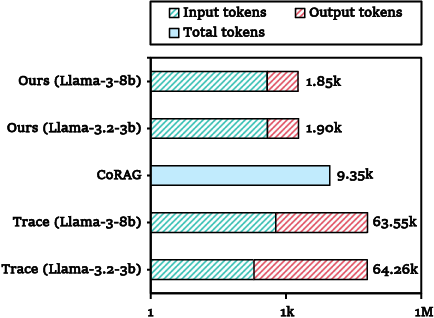
Figure 4: Token consumption for NeocorRAG and baselines, showcasing superior efficiency.
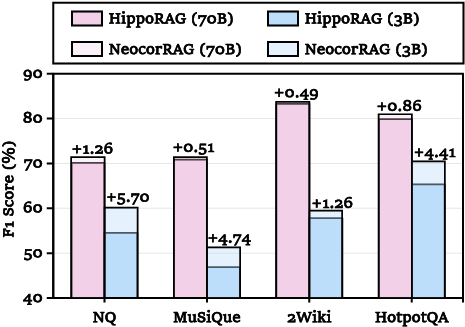
Figure 5: Performance benefit of evidence chain explication even with golden documents, isolating the effect of surfacing hidden evidence.
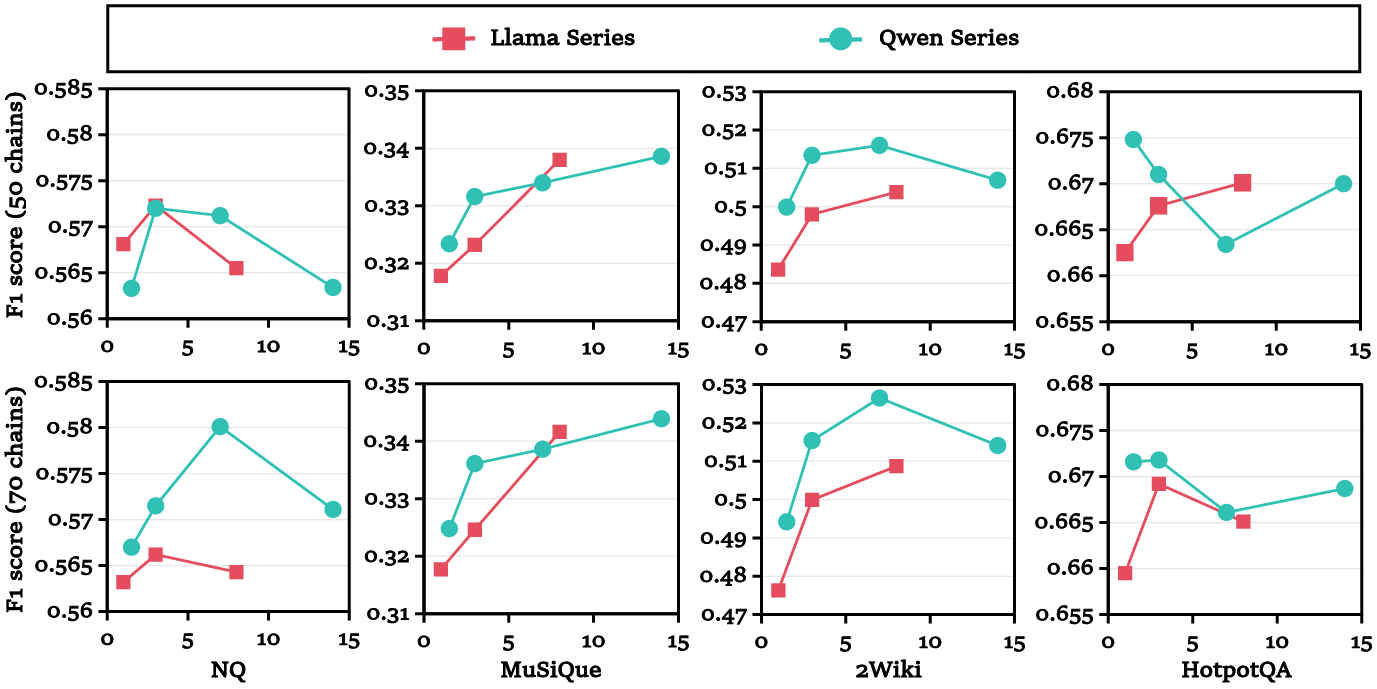
Figure 6: F1 score scaling with evidence chain count across backbone model families and sizes; lightweight models benefit most from explicit associative evidence.
Theoretical and Practical Implications
The evidence chain-centric paradigm presented by NeocorRAG offers several theoretical and practical implications:
- Retrieval quality is orthogonal to recall: Achieving high recall is necessary but not sufficient. Explicit optimization for evidence chains closes the recall-reasoning gap.
- Structured evidence mining complements parametric and non-parametric memory: Explicit evidence surfacing minimizes hallucinations and enables generalization across diverse QA tasks.
- Plug-and-play scalability: NeocorRAG is backbone-agnostic, requiring only lightweight auxiliary LLMs for evidence chain mining and supporting diverse model families without retriever-specific fine-tuning.
- Future directions: The evidence-chain approach can be extended to other knowledge-intensive tasks, incorporated into joint retrieval-generation pipelines (e.g., RetroLLM), and used for explainability in reasoning-centric NLP systems.
Conclusion
NeocorRAG establishes new criteria for retrieval quality in RAG systems by integrating evidence chain mining, constrained decoding, and evidence-guided filtering. The framework delivers SOTA QA and reasoning performance, robust efficiency, and plug-and-play applicability. The explicit surfacing and utilization of associative evidence chains bridge the gap between high recall retrieval and actionable reasoning utility, laying the foundation for future advances in retrieval-driven LLM reasoning (2604.27852).

