- The paper introduces a navigation-based framework that actively guides evidence retrieval via hierarchical knowledge trees.
- Methodology leverages LLM-guided segmentation, multi-step navigational retrieval, and a memory module to enhance QA performance.
- Empirical results show significant gains on benchmarks like NarrativeQA, validating the efficiency and scalability of NaviRAG.
NaviRAG: A Navigation-Based Framework for Retrieval-Augmented Generation
Background and Motivation
Retrieval-Augmented Generation (RAG) has become an established methodology for enhancing LLMs in knowledge-intensive tasks. Conventional approaches typically operate on flat retrieval paradigms, indexing documents into static text chunks and matching queries to these segments based on semantic similarity. However, these methods encounter major challenges in complex question answering that requires dynamic synthesis of evidence at multiple levels of granularity, conditional retrieval across different semantic regions, and sophisticated contextual integration. The inability of traditional RAG to flexibly navigate contextual dependencies and granularity constraints prevents effective evidence localization in long-chain reasoning scenarios.
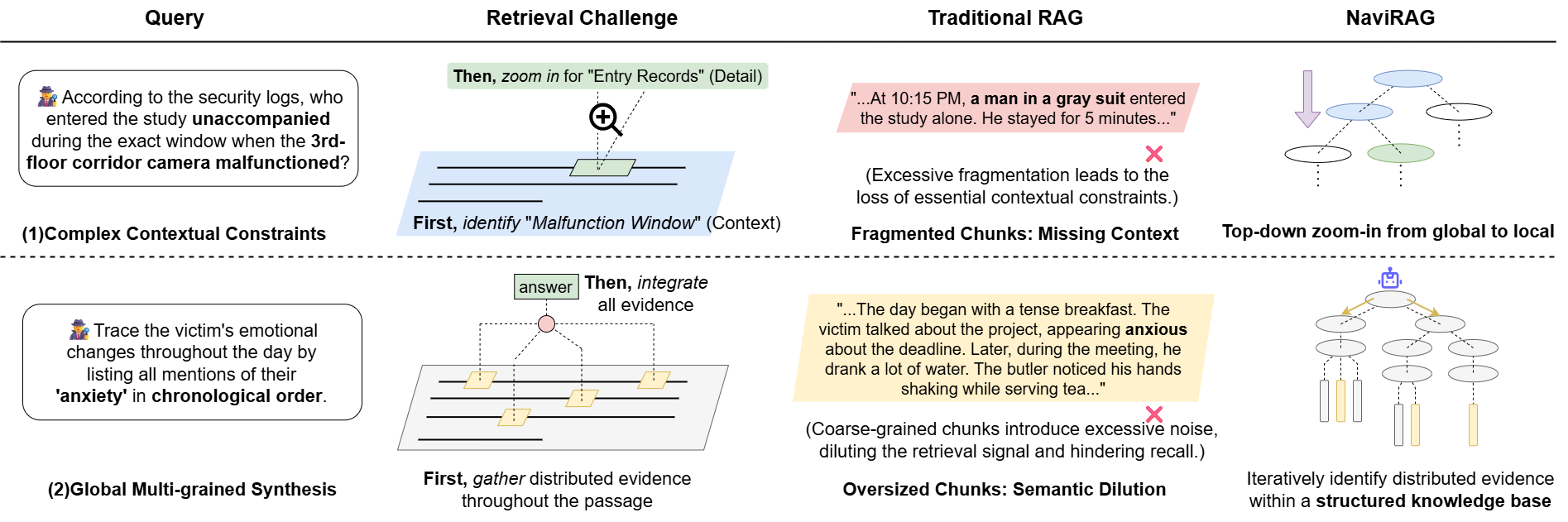
Figure 1: Two types of complex long-chain reasoning scenarios, each illustrated with example queries, retrieval challenges, RAG limitations, and how NaviRAG overcomes them.
NaviRAG addresses these gaps by shifting RAG from passive segment retrieval to active semantic navigation, introducing a framework for hierarchical knowledge organization and navigational retrieval. Theoretical inspiration is drawn from Information Foraging Theory, modeling evidence acquisition as a multi-stage, dynamic process guided by local information scent.
NaviRAG Framework and Algorithmic Structure
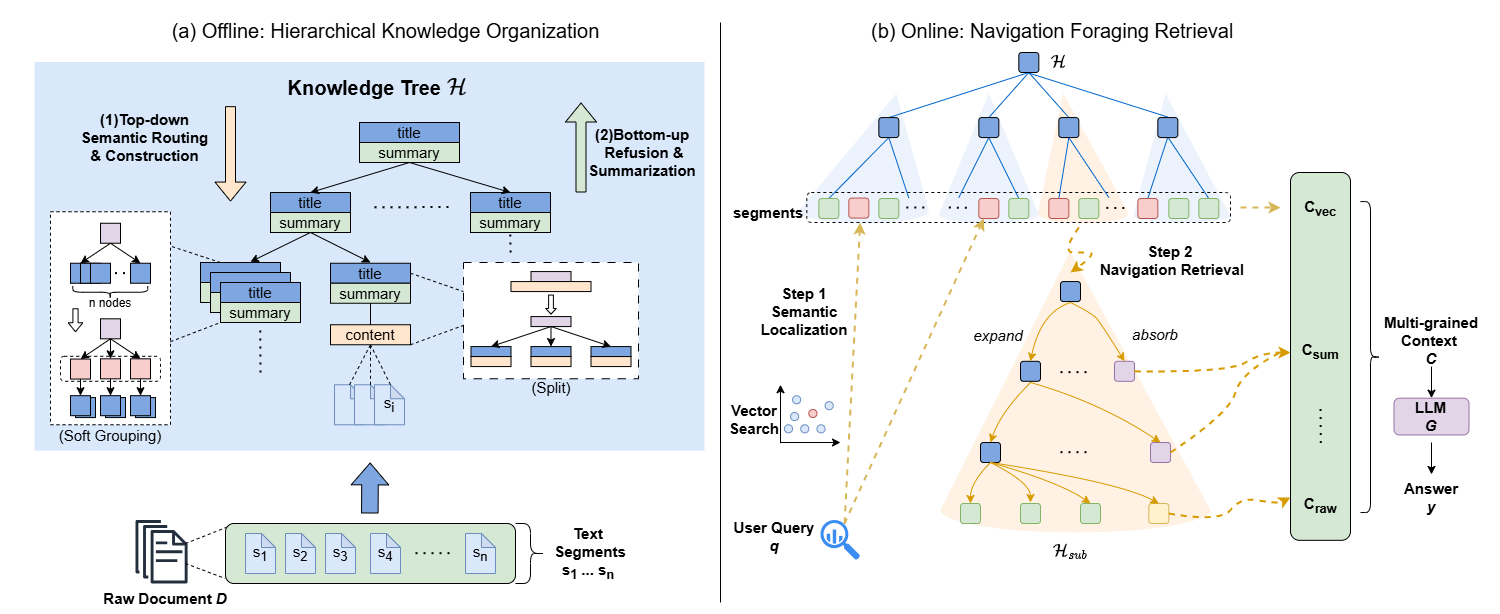
Figure 2: Framework of NaviRAG under a two-stage paradigm: offline hierarchical knowledge organization and online navigational retrieval.
Hierarchical Knowledge Organization
NaviRAG transforms each document into a "Knowledge Tree" via LLM-guided segmentation and structuring. Each node is characterized by a semantic title, content (either a set of child nodes or raw text), and a summary. The construction process combines top-down semantic routing (generating outlines and inserting text chunks) and bottom-up refusion with summarization, enforcing compactness through constraints on node assignment, semantic splitting, and structural grouping. The result is an operational hierarchical structure with continuous granularity and localized semantic subtrees.
Navigational Retrieval
During inference, given a query q, vector retrieval selects the most relevant text chunks, mapping them to knowledge tree nodes and initializing candidate semantic subtrees. NaviRAG then executes top-down, multi-step navigation within these subtrees: at each node, it decides whether to absorb summary information or explore child nodes based on query relevance. The process iteratively refines the context set across Cvec, Csum, and Craw, dynamically adapting retrieval depth to context sensitivity and evidence granularity.
Memory-Guided Navigation (Exploratory)
An optional memory mechanism augments navigational retrieval. During navigation, acquired context is written to transient memory, which conditions subsequent node selection. This enables global semantic state accumulation, facilitating cross-region evidence integration and avoiding redundant exploration. Memory is session-bound and non-persistent, serving only as an auxiliary retrieval signal.
Empirical Evaluation
Benchmarks and Baselines
NaviRAG is evaluated on complex reasoning QA benchmarks: NarrativeQA, LooGLE (short/long), LongBench-v2, and diverse domains (script, Wikipedia, legal, financial). Baseline comparisons encompass vanilla RAG (flat vector retrieval) and structure-enhanced RAG methods (GraphRAG, LightRAG, HippoRAG2). The evaluation employs uniform experimental settings (Qwen and LLaMA model families, bge-m3 embedding, consistent chunk sizes).
Results
NaviRAG delivers significant improvements in both retrieval recall and QA performance relative to all baselines. On NarrativeQA, NaviRAG achieves F1 scores up to 32.60 (LLaMA3.3-70B), outperforming vanilla and graph-based methods by margins exceeding 4-5 points. It consistently increases recall rates by ∼5% across scales. On LooGLE-long and LongBench-v2, NaviRAG excels in tasks demanding multi-evidence contextual reasoning, with the strongest gains realized in larger LLM configurations.
Performance improvements are most pronounced in complex long-chain scenarios—tasks requiring cross-segment evidence integration—while being muted in retrieval-focused local tasks. Ablation studies demonstrate that removal of either the navigation mechanism or hierarchical structure substantially reduces performance, validating the necessity of their synergy.
Efficiency
Inference efficiency is competitive: NaviRAG's latency and context utilization outperform most structure-enhanced baselines, remaining only behind lighter local methods. Under batch-wise hierarchical construction, knowledge base generation time also becomes comparable to the fastest alternatives. At top-k=3, NaviRAG matches or surpasses vanilla RAG performance achieved at much higher k (e.g., k=15), reflecting superior information efficiency.
Memory Module and Structural Preference
Memory-guided navigation yields incremental performance gains (e.g., +2-3 points on LooGLE-long Wikipedia), particularly in maintaining global semantic consistency across navigation steps. Case studies confirm that memory accumulation prevents redundant evidence aggregation and supports correct answer generation in event-counting queries.
NaviRAG shows stronger performance on documents with high semantic continuity (scripts) than modular, independently segmented texts (Wikipedia). Navigational mechanisms benefit from contextually dependent segment flow, while highly structured documents provide fewer gains absent explicit section-awareness.
Practical and Theoretical Implications
NaviRAG's paradigm introduces a fundamentally more flexible approach to retrieval in RAG systems, enabling LLMs to dynamically adjust retrieval granularity and navigate semantic constraints in complex reasoning tasks. This has direct consequences for real-world QA systems, document analysis, and LLM interpretability under long-context conditions.
Practically, the hierarchical-navigational model allows for scalable evidence localization, fine-tuned context selection, and improved generation quality without requiring costly global graph aggregation. The memory module, although lightweight and session-bound, points to promising avenues in state-aware retrieval and iterative context curation.
Theoretically, this work signals the necessity of moving beyond flat or static retrieval, framing evidence acquisition as a navigable, context-sensitive process. Further research may combine horizontal cross-node connection strategies, explicit document structure awareness, and persistent memory mechanisms to advance retrieval architectures.
Conclusion
NaviRAG offers a navigational retrieval-augmented generation framework that systematically structures knowledge for multi-stage, granular evidence localization. The empirical results demonstrate robust gains over conventional and structured RAG methods in complex reasoning scenarios. The hierarchical navigation paradigm, validated by ablation and efficiency analyses, lays a blueprint for future RAG systems to address long-context QA and adaptive retrieval, guiding both practical deployments and methodological advances in LLM-centric information systems (2604.12766).