- The paper introduces a novel five-agent LLM pipeline that uses sandboxed execution to verify and repair code modifications.
- It demonstrates a 40% bug resolution rate on SWE-bench Lite, outperforming single-agent and ReAct-based systems by 26–28 points.
- The study highlights role decomposition benefits and emphasizes execution feedback for improved sample efficiency and cost-performance.
AgentForge: Execution-Grounded Multi-Agent LLM Framework for Autonomous Software Engineering
AgentForge advances the paradigm of autonomous software engineering by leveraging execution-grounded feedback in a multi-agent LLM coordination framework. Large LMs, while effective at code generation, lack reliable mechanisms for verifying correctness, particularly in the context of repository-scale, multi-file reasoning demanded by real-world tasks. The AgentForge framework is constructed around an explicit five-agent pipeline—Planner, Coder, Tester, Debugger, Critic—combined with mandatory execution in a sandboxed Docker environment for every proposed code modification. Unlike prior systems that either simulate execution or make verification optional, AgentForge formalizes the engineering process as an MDP defined on repository states, where correctness is exclusively validated externally by program execution rather than proxy LM objectives.
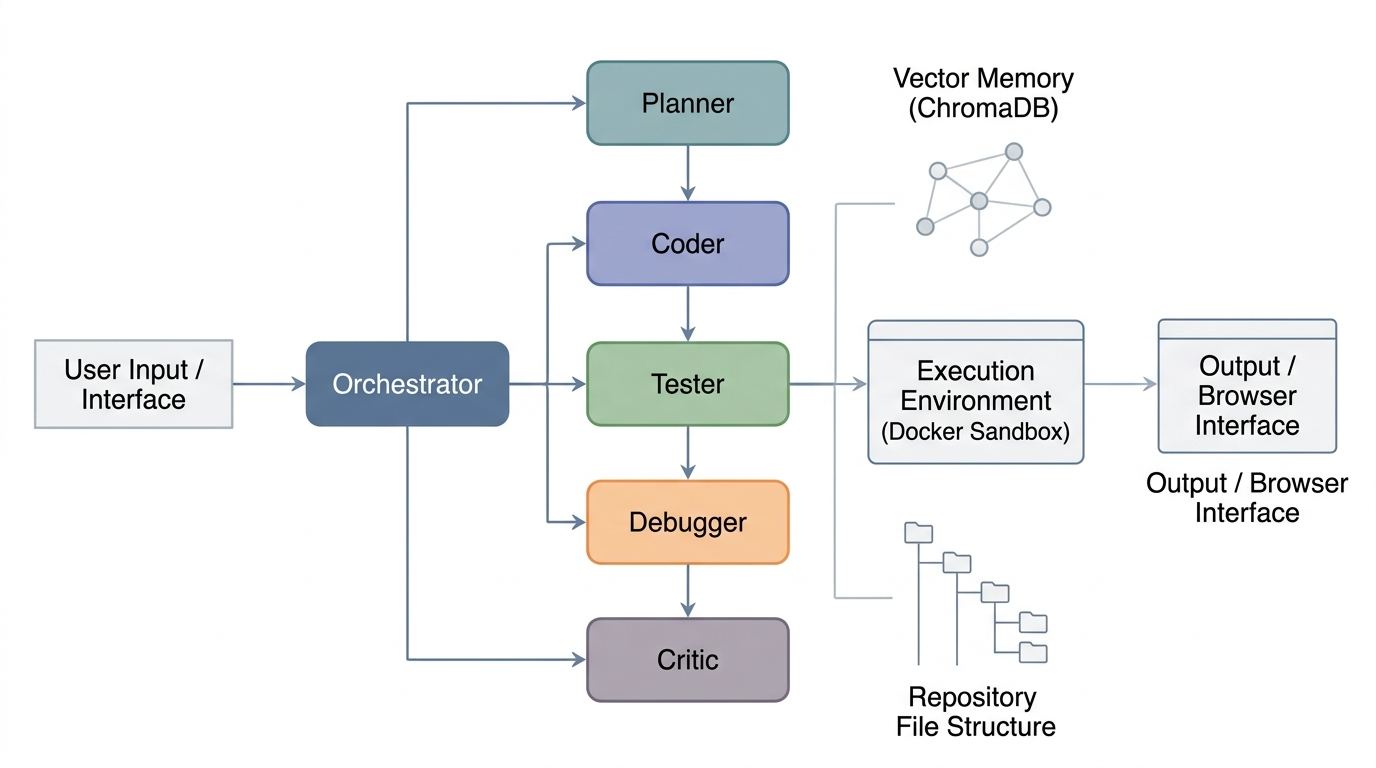
Figure 1: Overview of the AgentForge multi-agent coding framework, illustrating the sequential handover between specialized agents and the shared Vector Memory.
System Architecture
Agent Roles and Orchestration
Each role within AgentForge is mapped to a distinct LLM call with specialized prompts and contractual outputs:
- Planner: Synthesizes an execution plan based on the task, drawing context from both episodic memory and live repository embeddings.
- Coder: Generates either a minimal patch (via unified diff) or new code artifacts adhering to the plan.
- Tester: Produces targeted tests for both bug exposure (“fail to pass”) and regression avoidance (“pass to pass”).
- Debugger: Iteratively modifies failed code under the supervision of real execution traces, with retries bounded by a fixed budget.
- Critic: Delivers the terminal verdict, triggering either acceptance or rejection of the synthesized patch.
All agents interact with a vector store-based retrieval backend, supplying both historical (episodic) and current repository context on demand.
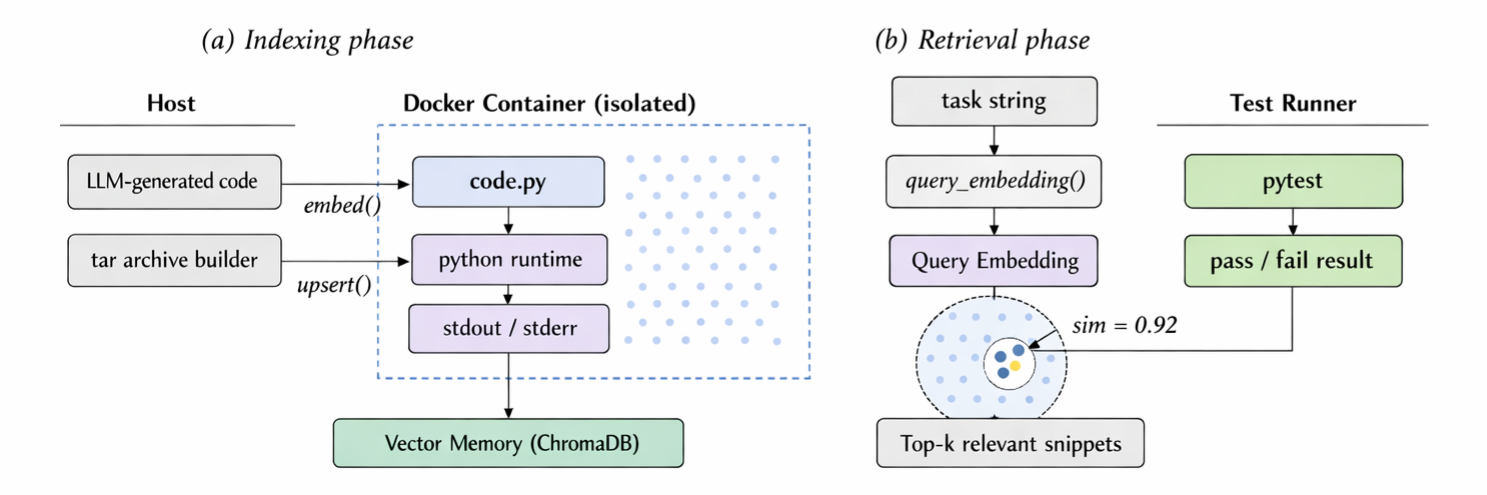
Figure 2: Retrieval-Augmented Generation (RAG) architecture: (a) Offline repository indexing; (b) Online semantic retrieval at inference.
Sandboxed Execution and Security Guarantees
Every code change is executed inside an isolated Docker container provisioned with a 512MB RAM cap, 0.5 CPU allocation, and complete network isolation. This strategy constrains program behavior, guarantees reproducibility, and prevents spurious model-induced feedback by ensuring that all results derive from faithful execution dynamics in a controlled environment.
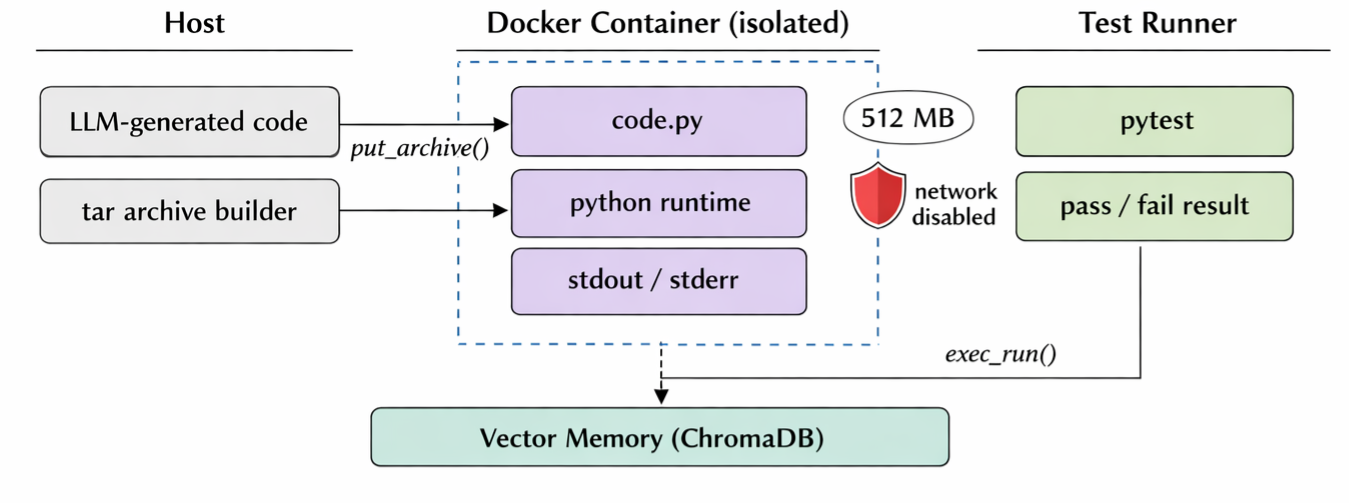
Figure 3: Isolated Docker sandbox execution environment.
Theoretical Framework and Design Claims
AgentForge’s methodological innovation stems from three explicit claims:
- Dominance of Execution Signal: Execution outcomes from sandboxed runs provide strictly stronger and lower-variance supervision for functional correctness compared with LM-internal heuristics (e.g., next-token likelihood).
- Error Propagation in Role Decomposition: While monolithic models accumulate errors via correlated generative chains, the division into specialized agents with constrained input space reduces both per-stage failure rate and temporal error correlation under mild independence assumptions.
- Sample/Token Efficiency: Diff-based editing restricts token generation to only the necessary lines, minimizing both semantic error surface and token budget compared to full-file regeneration for large files.
These claims are supported empirically by ablation and performance studies, and theoretically via formalization in MDP terms with explicit reward assignment grounded in test results.
Empirical Results
AgentForge is evaluated on the SWE-bench Lite benchmark (300 real-world GitHub bug-fixing tasks). Against strong baselines—single-agent GPT-4o, ReAct-based tool-using GPT-4o, and the published SWE-agent—AgentForge demonstrates a 40.0% resolution rate, yielding a substantial margin (+26–28 points) over all comparators. This is achieved under the strict constraint of mandatory sandboxed execution with three-step debug retries and without reliance on test-time sampling or scaling.
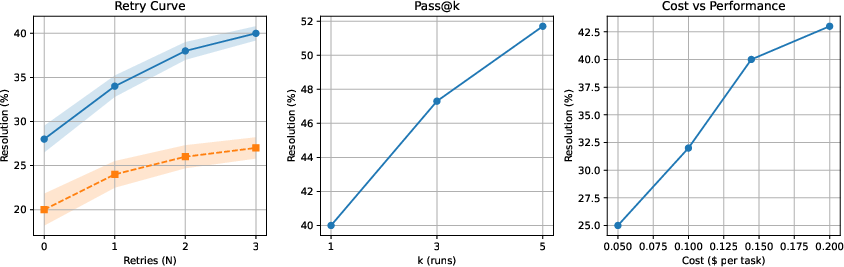
Figure 4: Performance of AgentForge across debug retries, majority voting, and cost-performance axes. Iterative repair provides gains up to N=2, and the overall system exhibits superior cost/sample efficiency.
The ablation study on the first 100 tasks highlights that decomposing plan-generation, test-generation, and debugging is essential: removing the Debugger or Tester yields the highest degradation, while removal of the Critic or Planner also substantially reduces performance.
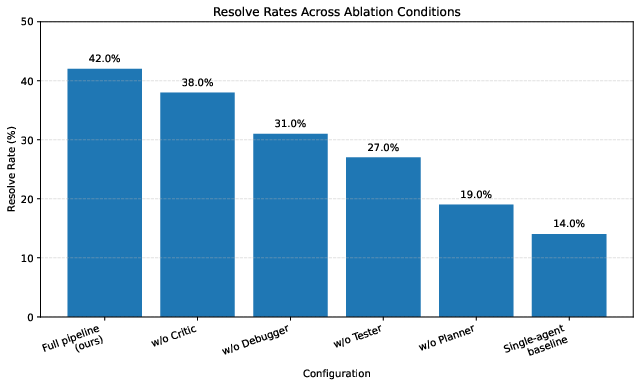
Figure 5: Resolve rates across ablation conditions. The Tester–Debugger loop provides the largest marginal contribution.
Error Analysis and Failure Modes
Direct analysis of failed tasks identifies three principal bottlenecks:
- Faulty Localization (40%): The Planner often localizes to the main file but ignores secondary dependencies or multi-file impacts, a limitation of repository-level reasoning.
- Ineffective Patch Generation (27%): Some fixes pass immediate tests but violate non-obvious invariants, with evidence that test cases generated by Tester sometimes lack robustness or generality.
- Cognitive Deadlocks (20%): The debug loop’s search space can stagnate, producing incremental edits to the same locus without adequate state diversification.
A minority of failures stem from environment/tooling constraints such as timeouts or patch application conflicts.
Practical Implications and Cost Analysis
AgentForge achieves higher correctness under a fixed execution and token budget compared to baselines, though at an increased absolute cost (~2.7x the single-agent approach). The improved sample efficiency highlights the practical value of role decomposition and execution feedback for real-world code repair. The framework is architected such that each stage can scale independently or utilize specialized, lighter models for selected agents under resource constraints.
Theoretical and Future Directions
The results suggest that improvements in grounding via execution and plan-based decomposition can yield higher marginal gains for repository-scale tasks than continued expansion of static model capacity. Specific future directions include:
- Enhancing multi-file planning and cross-file dependency reasoning via hierarchical retrieval and structural code analysis
- Improving regression test synthesis for more stringent patch validation
- Leveraging diversity-promoting strategies in debugging (e.g., population-based search or stochastic repair)
- Investigating memory persistence and hierarchical role specialization for scaling to larger codebases or continuous integration pipelines
Conclusion
AgentForge establishes a new standard for autonomous LLM-based software engineering, unifying execution-grounded verification with role-specialized agent orchestration. Quantitative results demonstrate robust gains in bug resolution across a challenging real-world benchmark. The study shows that the combination of enforced execution feedback, structured pipeline design, and semantic retrieval is more consequential for robust program repair than simply scaling monolithic LM capacity. The system’s open-source implementation provides a reproducible baseline for future architectural and memory/retrieval innovations in multi-agent, execution-grounded autonomous coding systems.