AEC-Bench: A Multimodal Benchmark for Agentic Systems in Architecture, Engineering, and Construction
Abstract: The AEC-Bench is a multimodal benchmark for evaluating agentic systems on real-world tasks in the Architecture, Engineering, and Construction (AEC) domain. The benchmark covers tasks requiring drawing understanding, cross-sheet reasoning, and construction project-level coordination. This report describes the benchmark motivation, dataset taxonomy, evaluation protocol, and baseline results across several domain-specific foundation model harnesses. We use AEC-Bench to identify consistent tools and harness design techniques that uniformly improve performance across foundation models in their own base harnesses, such as Claude Code and Codex. We openly release our benchmark dataset, agent harness, and evaluation code for full replicability at https://github.com/nomic-ai/aec-bench under an Apache 2 license.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
AEC‑Bench: A simple explanation for teens
What is this paper about?
This paper introduces AEC‑Bench, a big “test” for AI assistants that try to help with real construction work. AEC stands for Architecture, Engineering, and Construction. In this field, people use large sets of 2D drawings and documents (think: very detailed, very crowded maps of buildings) to plan and build things like bridges and offices. The authors built AEC‑Bench to see how well different AI “agents” can read these drawings, find the right info across many pages and files, and report what they discover.
What questions are the researchers asking?
Here are the main questions in simple terms:
- Can today’s coding-style AI agents (robot interns that can use tools and write small programs) handle real construction documents?
- Do special tools that break drawings into more structured, searchable pieces help these agents do better?
- Which kinds of tasks are easy or hard for AI agents: single‑page checks, multi‑page checks, or cross‑document checks?
- Where do these agents fail, and what tools or designs help fix those failures?
How did they do it?
Think of a construction project like a giant treasure hunt:
- Each drawing page is like a dense map with symbols, labels, and arrows pointing to other pages.
- The “agent” is a robot intern that can open files, search text, render images, run simple code, and then write a neat report of what it found.
What the team built:
- A benchmark (AEC‑Bench) with 196 small, realistic tasks grouped by how much context you need:
- Intra‑Sheet: tasks solvable from one page (e.g., “does this label match the thing it points to?”).
- Intra‑Drawing: tasks that require hopping across several pages in one drawing set (e.g., “does this reference number point to a real detail on another page?”).
- Intra‑Project: tasks across different document types (e.g., do the drawings and the written specs disagree?).
How tasks work:
- Each task gives the agent instructions and access to real project PDFs in a safe “sandbox.”
- The agent explores, uses tools (like turning PDFs into text or images), and outputs answers in a structured file (JSONL).
- An automatic checker (and domain experts) grade the final answers for correctness and completeness, giving a score from 0 to 100.
How the dataset was made:
- The team took real public construction PDFs and used a semi‑automated process to:
- Extract structured info (text locations, geometry, cross‑references).
- Carefully inject tiny, realistic “gotchas” (like a wrong reference number) without ruining the look.
- Verify the edits visually and with text checks to keep things realistic and fair.
What they compared:
- Two popular coding‑agent “harnesses” (think: the agent’s workbench that provides tools and rules)—similar to Claude Code and Codex.
- Two setups:
- H: just the base tools (command line, PDF utilities, etc.).
- H + Nomic: base tools plus special “parsing” and embeddings from Nomic that give more structured access to the drawings (where text is, how pages link, etc.).
- They measured how much the added structure helps.
What did they find, and why is it important?
Key takeaways:
- General coding agents transfer somewhat well: They can do a fair amount, especially when the job is mostly about searching and organizing information.
- Finding the right context is the biggest bottleneck: Agents often fail not because they can’t reason, but because they can’t find the correct page, detail, or file. When they do find it, they do much better.
- Structured parsing helps on “find‑it” tasks:
- With the extra structured tools, scores improved a lot on tasks like technical detail review, matching specs to drawings, and navigating to the right file/sheet/detail.
- But parsing doesn’t fix everything—visual grounding is still hard:
- Tasks that require precise visual understanding—like following arrows (leader lines) to the exact item on a busy drawing or checking that a note truly points to the right element—did not improve and sometimes got worse. It’s not enough to have text; the agent needs to understand spatial relationships in the drawing.
- Judgment-heavy tasks remain tough:
- Submittal review (checking if a contractor’s submitted product meets drawings and specs) stayed low across all models and setups. It requires professional judgment and careful prioritization, not just retrieval.
- Agents default to “code-first” habits:
- Most agents heavily used tools that turn PDFs into plain text (like pdftotext). This flattens the drawing’s spatial structure, losing important geometric context. Even when they rendered images, they rarely turned that visual info into precise, location-aware answers.
Why this matters:
- In real projects, delays and cost overruns often come from mismatched documents and missed details. An AI assistant that’s good at finding and cross-checking the right info could save time and money.
- The results show we need better tools that help agents keep and use the drawing’s spatial structure, not just the text.
What could this change in the future?
- Better AI assistants for AEC: With improved tools that understand both text and drawing layout, agents could help professionals catch mistakes earlier and coordinate teams more smoothly.
- Smarter system design: Success depends on how visual info, text, and tools are combined—not just having a powerful model. Domain‑aware orchestration (the way tools and steps are arranged) matters a lot.
- Stronger evaluations: Testing agents in realistic, workflow‑like settings gives a truer picture of what they can actually do on the job.
The benchmark, code, and tools are open-source (Apache 2 license), so others can reproduce results and build on this work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions the paper leaves open, organized to guide future research.
Dataset scope and representativeness
- Limited scale (196 instances) and document diversity; unclear how results generalize across larger projects, more sheets per set, and additional AEC disciplines and asset types.
- Injected/controlled defects may not reflect the full spectrum, frequency, and ambiguity of naturally occurring coordination issues; performance on “in-the-wild” errors remains unknown.
- No stratified analysis by discipline (architectural, structural, MEP, civil) or drawing type (plans, sections, details) to identify domain- or artifact-specific failure modes.
- Scanned vs. vector PDFs are not distinguished; the impact of OCR noise, rasterization quality, and vector availability on task performance is unquantified.
- Absence of a train/dev/test split or “challenge” sets (e.g., noisy scans, low-contrast annotations, dense callouts) to systematically probe robustness and difficulty.
Evaluation protocol and metrics
- Single-trial evaluation per instance; no variance estimates, confidence intervals, or statistical significance testing across runs or seeds.
- Deterministic, keyword/structure-based verifiers do not assess evidence localization, spatial grounding quality, or reasoning faithfulness; lack of metrics that require evidence pointers (e.g., bounding boxes, sheet coordinates) and justification.
- Judgment-heavy tasks (e.g., submittal review) are evaluated with static verifiers despite acknowledged subjectivity; no inter-rater reliability, human-in-the-loop assessment, or rubric-calibrated scoring.
- No precision/recall, calibration, or cost-of-errors analysis on multi-finding tasks where false positives are operationally harmful.
- Lack of human baselines (time, accuracy) to contextualize agent performance and difficulty calibration.
- No reporting on task-time, tokens, or compute/latency budgets; efficiency and cost-performance trade-offs remain unmeasured.
Agent/harness design and orchestration
- Only two coding-agent harness families (Codex, Claude Code) are evaluated; effects of alternative agent paradigms (e.g., ReAct, Planner-Executor, verifier-in-the-loop, multi-agent decomposition) are unknown.
- Agents defaulted to CLI-centric, pdftotext-driven strategies; it is unclear whether better tool affordances, prompting, or orchestration can shift behavior toward spatially grounded methods.
- No ablation on tool availability or instruction strategies to test if agents can be nudged to use structured tools (e.g., “read with regions,” geometric parsers) over linear text extraction.
- Outcome-only scoring obscures process-level failure analysis; lack of fine-grained trajectory evaluation (tool selection, exploration coverage, backtracking) limits insight into harness weaknesses.
Representation and perception for drawings
- Parsing benefits retrieval but not spatial grounding; the benchmark does not test or compare richer geometric/semantic representations (e.g., vector primitives, symbol libraries, topology graphs, CAD/BIM exports like DWG/IFC).
- No controlled study on image resolution, DPI, or rendering strategies and their effect on visual-spatial tasks (e.g., detecting leader lines, symbol associations).
- Absence of specialized perception modules (symbol detectors, line/leader/arrow parsers, OCR tuned for drawings); impact of integrating these is untested.
- Cross-sheet/link extraction is provided, but the completeness and error rates of parsed reference graphs (and their effect on tracing tasks) are not quantified.
Task design and coverage
- Narrow set of task families; many high-value AEC checks (e.g., dimension/scale consistency, units conversions, code compliance crosswalks, BOM/quantity takeoff alignment, change/version tracking) are not assessed.
- Intra-project tasks focus on text-centric sync; tasks requiring numerical reasoning with units, tolerances, and scale bars are underrepresented.
- No incremental/hierarchical tasks to test long-horizon exploration (e.g., “find, then verify, then summarize with evidence”) or curriculum effects.
Generalization, robustness, and transfer
- Generalization to proprietary or larger-scale enterprise project repositories (with deeper hierarchies, naming conventions, and nonstandard indexing) is untested.
- Cross-language/locale robustness (e.g., multilingual notes, region-specific symbols and codes) is not evaluated.
- Sensitivity to project metadata conventions (sheet naming, index styles, title block formats) is not analyzed.
Safety, reliability, and usability
- Over-generation and false positives are observed (e.g., submittal review), but there is no exploration of uncertainty estimation, abstention policies, or confidence-calibrated reporting to mitigate operational risk.
- No study of human-in-the-loop workflows (triage, verification, correction) or how agent outputs integrate with industry formats (e.g., BCF/issue trackers) and practitioner tooling.
- Lack of error taxonomies and actionable diagnostics that practitioners could use to trust or correct agent findings.
Reproducibility and fairness
- Results depend on proprietary foundation models; replicability across model updates or with open-source models is not addressed.
- The “H+Nomic” augmentation introduces domain-specific tools; fairness and comparability to alternative structured parsers or third-party toolchains are not investigated.
- Minor inconsistencies between narrative (expert grading) and practice (automated verifiers) create ambiguity about evaluation reproducibility and human oversight.
Open methodological questions
- What representations and toolchains most effectively couple retrieval with spatial grounding (e.g., hybrid vector-graph + image + text pipelines)?
- How should verifiers be designed to jointly assess correctness, evidence localization, and reasoning fidelity at scale?
- Which orchestration strategies best manage long-horizon document navigation (e.g., spatial memory, map-building, frontier exploration) and reduce compounding retrieval errors?
- Can domain-tuned training (e.g., instruction tuning on AEC tasks, RL with verifiers, retrieval-aware multimodal pretraining) materially improve grounding and judgment-heavy performance?
- How can benchmarks better reflect real coordination workflows, including iterative review cycles, uncertainty management, and graded severity/priority of findings?
Practical Applications
Below is an overview of practical applications that follow from AEC-Bench’s findings, methods, and tooling (e.g., Harbor harness, structured parsing via Nomic Parse/Embeddings). The items emphasize where the benchmark shows clear, deployable value (retrieval- and structure-heavy tasks) and where longer-term R&D is needed (spatial grounding and judgment-heavy tasks).
Immediate Applications
- Industry (AEC): Benchmark-driven vendor evaluation and procurement guardrails
- Use AEC-Bench as an acceptance test and SLA backbone in RFPs for AI document assistants, with task-category thresholds (e.g., drawing navigation and spec–drawing sync) derived from reported reward scores.
- Tools/workflows: Harbor harness; AEC-Bench dataset; automated verifiers; reproducible containers.
- Assumptions/dependencies: Access to representative project documents; ability to run containerized evaluations; acceptance by procurement teams.
- Industry (AEC) / Software: Retrieval-first document navigator for drawings
- Deploy an agent that reliably locates the correct file/sheet/detail given a query, where H+structured parsing showed near-perfect gains (e.g., drawing-navigation).
- Tools/workflows: Nomic Parse/Embeddings (or equivalent) to build cross-sheet indices; integration with Procore, Autodesk Construction Cloud, Bluebeam.
- Assumptions/dependencies: Indexing of all PDFs and sheet metadata; robust PDF parsing; permissions and APIs for DMS integration.
- Industry (AEC): Spec–drawing synchronization checker
- Automate detection of conflicts between specifications and drawings; parsing improved performance on this retrieval-sensitive task.
- Tools/workflows: Structured parsing pipelines for both specs and drawings; evidence-grounded JSON reports reviewed by engineers.
- Assumptions/dependencies: Consistent access to current spec books and drawings; policy for human-in-the-loop approval; traceability requirements.
- Industry (AEC): Sheet index and title block auditor
- Validate sheet index entries vs. title blocks for mismatches (high baseline performance suggests easy wins).
- Tools/workflows: Batch PDF text/layout extraction; scheduled audits with discrepancy dashboards.
- Assumptions/dependencies: Reliable OCR/layout extraction for title blocks; consistent title block formats.
- Industry (AEC): Cross-reference resolution scanner
- Identify broken or non-resolving cross-references across a drawing set (moderate performance; use with human review).
- Tools/workflows: Parse relationships between callouts and target details; flag suspect references for manual confirmation.
- Assumptions/dependencies: Correctly detected reference schema; tolerance for false positives and reviewer workflows.
- Academia / Software R&D: Harness- and tool-ablation research baseline
- Use AEC-Bench to study how representation and orchestration (e.g., structured parses vs. CLI-only) affect agent performance.
- Tools/workflows: Harbor harness; controlled tool-access experiments; shared leaderboards and reproducible code.
- Assumptions/dependencies: Compute resources; standard reporting of reward metrics by task.
- Education (AEC programs): Multimodal document literacy labs with auto-grading
- Train students and junior engineers on real review workflows (cross-sheet navigation, detail checks) using AEC-Bench tasks and verifiers.
- Tools/workflows: Classroom CI pipelines; automated feedback on JSON outputs; curated task subsets per course module.
- Assumptions/dependencies: Appropriately licensed documents; instructor capacity to curate tasks.
- Software Engineering (MLOps): CI/CD regression suites for AEC agents
- Run AEC-Bench nightly to detect regressions when updating models/tools; gate deployments on category-specific performance.
- Tools/workflows: Containerized tasks; reward thresholds; model/version tracking.
- Assumptions/dependencies: Stable compute budget; agreement on pass/fail criteria.
- Cross-domain (legal/healthcare/finance/manufacturing): Defect-injection evaluation pipelines
- Repurpose the semi-automated artifact-injection method to build realistic benchmarks for other document-heavy domains (e.g., contracts, IFUs, SOPs, P&IDs).
- Tools/workflows: Alignment-aware editing; before/after/diff validation; domain-expert curation.
- Assumptions/dependencies: Domain expertise; access to representative public documents; ethical/privacy constraints.
- Public Sector / Policy: Evidence-based auditing of vendor claims
- Agencies can independently verify AI assistant performance on public projects using an open, Apache-2.0 benchmark.
- Tools/workflows: Standardized evaluation protocol; reproducible code; transparent scorecards per task family.
- Assumptions/dependencies: Policy willingness to require open evaluations; reproducibility in agency environments.
Long-Term Applications
- Industry (AEC) / AI R&D: Spatially grounded drawing comprehension modules
- Develop VLM components that can trace leader lines, resolve symbols, and align text-to-geometry—addressing the benchmark’s core failure mode in note-callout accuracy and visually grounded tasks.
- Tools/workflows: New training datasets with symbol/leader annotations; region-level grounding; pixel-coordinate evidence outputs.
- Assumptions/dependencies: Large-scale curated data; novel perception models; evaluation protocols that check spatial grounding.
- Industry (AEC): End-to-end submittal review copilot with judgment modeling
- Build agents that triage submittals and produce evidence-backed findings consistent with professional standards—addressing low current performance and over-generation risks.
- Tools/workflows: Hierarchical reasoning with verifiers, policy templates, and human-in-the-loop adjudication; uncertainty calibration.
- Assumptions/dependencies: Improved long-horizon planning; domain-knowledge infusion; clear liability and governance frameworks.
- Industry (AEC): Real-time design review assistant during coordination sessions
- Live flag inconsistencies (cross-references, spec conflicts) as teams mark up drawings in Bluebeam/ACC; present linked evidence regions.
- Tools/workflows: Low-latency parsing and region retrieval; spatial memory across sheets; UI plugins for evidence overlays.
- Assumptions/dependencies: Plugin APIs; robust on-the-fly parsing; reliable grounding so as not to distract reviewers.
- Standards / Policy: Machine-readable AEC document requirements
- Encourage or mandate parsable, standardized title blocks, callout schemas, and cross-reference formats (e.g., via ISO 19650-aligned extensions) to enable reliable automation.
- Tools/workflows: Industry working groups; conformance tests; benchmark-aligned certification criteria.
- Assumptions/dependencies: Ecosystem adoption by designers/contractors; updates to authoring templates and QA processes.
- Software / Benchmarking: Evidence-grounded agent harness standards
- Require agents to cite coordinates/page regions for every claim; verifiers check both content and location to reduce hallucinations and ensure traceability.
- Tools/workflows: Harbor extensions to collect/certify evidence; UI for evidence replay; standardized JSON schemas for citations.
- Assumptions/dependencies: Model capabilities for fine-grained localization; acceptance by auditors/regulators.
- Industry (AEC) / CAD-BIM: Authoring-time QA in Revit/AutoCAD
- Plugins that continuously check detail titles, cross-references, and sheet indices inside the authoring environment, reducing downstream RFIs/change orders.
- Tools/workflows: Mappings between native models and publish-to-PDF; preflight checks; actionable fix suggestions.
- Assumptions/dependencies: Vendor SDKs/APIs; reliable linkage between model objects and published sheets.
- Cross-sector (Energy, Aerospace, Manufacturing): Multimodal agent benchmarks for technical drawings
- Extend AEC-Bench methodology to circuit diagrams, piping & instrumentation diagrams (P&IDs), aircraft maintenance manuals, grid schematics—where cross-document/spatial reasoning is critical.
- Tools/workflows: Domain-specific symbol libraries; task taxonomies paralleling intra-sheet/drawing/project scopes.
- Assumptions/dependencies: Access to public corpora; domain-expert curation; safety/regulatory buy-in.
- AI Infrastructure: Memory- and token-efficient multimodal retrieval stacks
- Build context-engineering layers that index documents into linkable regions, compress context, and retrieve evidence just-in-time—reflecting benchmark findings about retrieval as a bottleneck.
- Tools/workflows: Region-level embeddings; structured stores for text/layout/geometry; retrieval-aware planning.
- Assumptions/dependencies: Efficient multimodal vector stores; orchestration libraries that manage region provenance.
- Workforce Development: Credentialing for digital AEC coordination skills
- Create micro-credentials where trainees pass benchmarked tasks (e.g., navigation, reference tracing) with evidence-based reports.
- Tools/workflows: Proctored AEC-Bench subsets; dashboards for skill gaps; integration with professional development programs.
- Assumptions/dependencies: Industry acceptance; alignment with licensure/CPD frameworks.
- Insurance / Risk: Performance-based underwriting for AI-assisted workflows
- Use benchmark scores by task category to model risk impacts (e.g., likelihood of change orders due to coordination errors), influencing premiums and guarantees.
- Tools/workflows: Actuarial studies linking benchmark outcomes to project KPIs; third-party certifications.
- Assumptions/dependencies: Sufficient historical data; regulator approval; demonstrated correlation between scores and outcomes.
Notes on feasibility and dependencies common across applications:
- Retrieval-centric tasks are deployable now when coupled with structured parsing; spatial-grounding and high-judgment tasks need model advances and better evidence-verification loops.
- Success depends on high-quality PDF parsing (text + layout + references), access to complete project document sets, integration with existing DMS/CDEs, and clear human-in-the-loop protocols.
- For regulated uses, evidence traceability (page/region coordinates, before/after diffs) and auditability will be critical for adoption.
Glossary
- agentic systems: AI systems that can plan and act autonomously, often using tools and multi-step reasoning. "a multimodal benchmark for evaluating agentic systems on real-world tasks in the Architecture, Engineering, and Construction (AEC) domain."
- alignment-aware text editing: Editing that preserves positional alignment and layout when modifying document text. "using alignment-aware text editing that preserves visual fidelity."
- automated verifier: A programmatic grader that checks an agent’s final outputs against predefined criteria or answers. "Each instance is scored using a task-specific automated verifier against known ground truth."
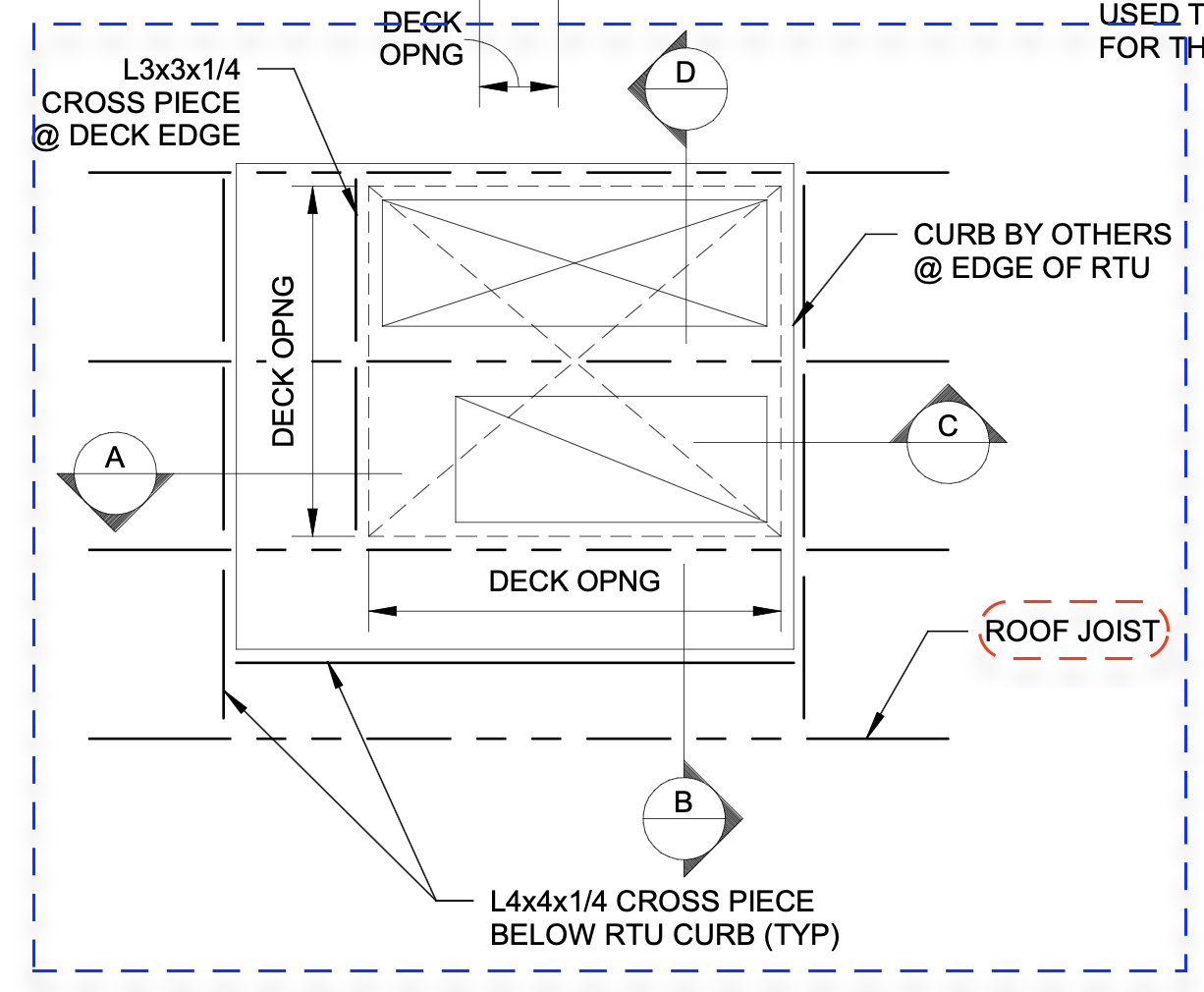
- callouts: Annotated labels with leader lines pointing to elements in a drawing to provide details or references. "A visually dense drawing sheet with tightly packed annotations, callouts, and linework typical of real construction coordination artifacts."
- coding-agent harnesses: Execution frameworks that let LLMs act as coding agents with tools (e.g., shell, code execution) to solve tasks. "Foundation models equipped with coding-agent harnesses demonstrate strong capabilities in software engineering workflows, where agents can search repositories, edit code, and verify outputs through tool use."
- cross-document coordination: Ensuring consistency and resolving conflicts across multiple documents within a project. "fail on visual grounding, exhaustive traversal, and cross-document coordination."
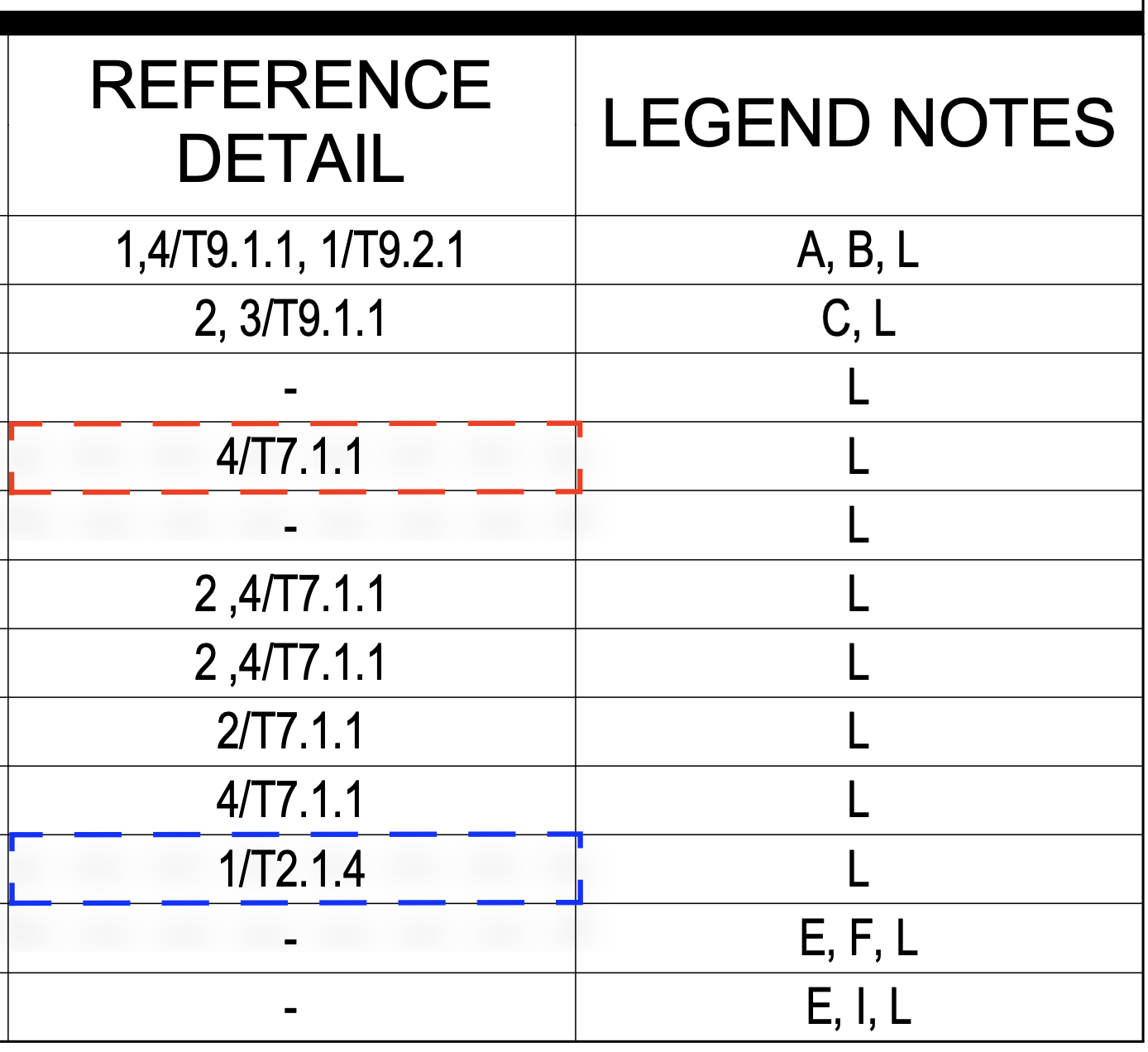
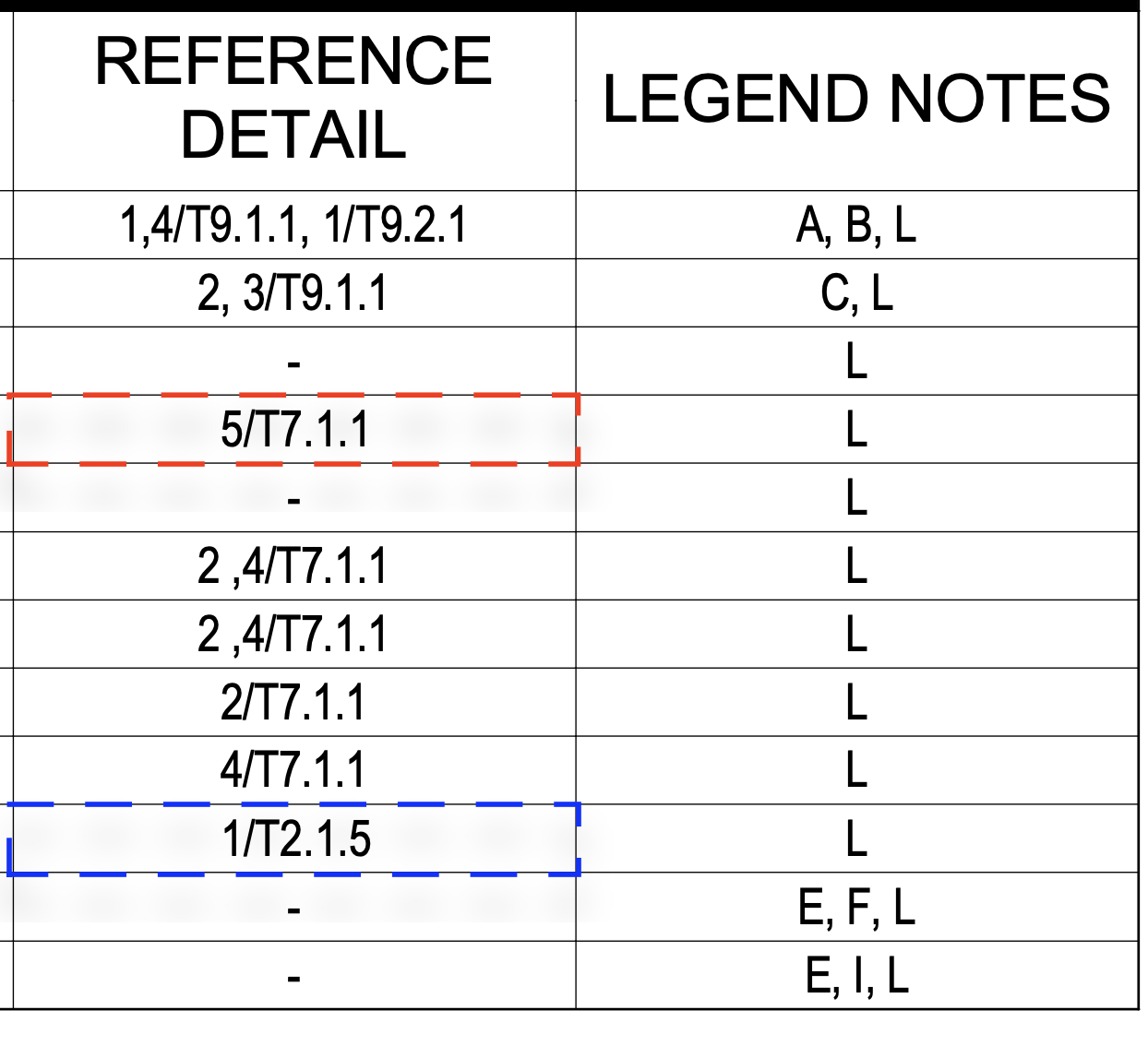
- cross-reference resolution: The process of verifying that references within drawings point to valid, correct targets. "For cross-reference resolution, the edits introduce subtle reference-number inconsistencies that require cross-sheet verification;"
- cross-sheet navigation: Moving between different sheets/pages of a drawing set to trace references and gather context. "including intra-sheet review, cross-sheet navigation, and project-level document alignment."
- cross-sheet references: Explicit links or pointers from one drawing sheet to elements on another sheet. "geometric regions, and cross-sheet references."
- detail titles: Titles labeling specific drawing details that should accurately describe the associated content. "verifying detail titles"
- drawing set: A multi-page collection of construction drawings that collectively define design intent and requirements. "In practical terms, a drawing set is a multi-page, multimodal instruction package in which meaning is conveyed through structured visual and textual elements such as plans, details, callouts, notes, and title blocks."
- drawing-navigation: A task type focused on locating the correct file, sheet, or detail in a drawing corpus. "Similar gains are observed for spec-drawing-sync +20.8% and drawing-navigation +18.75%,"
- execution primitives: Low-level, reliable operations provided by a system that agents can compose to perform tasks. "These systems rely on structured, verifiable environments and well-defined execution primitives, which enable reliable multi-step reasoning and self-correction."
- exhaustive traversal: Systematic, comprehensive exploration of documents or structures to ensure no relevant elements are missed. "fail on visual grounding, exhaustive traversal, and cross-document coordination."
- geometric reasoning: Interpreting and reasoning about shapes, spatial relationships, and geometry within visual documents. "vision-based tools lack the quality needed for reliable geometric reasoning."
- ground truth: The authoritative correct answers or annotations used to evaluate model outputs. "Each instance is scored using a task-specific automated verifier against known ground truth."
- Harbor harness: The execution framework used to run tasks and interface with agents via standardized tools and formats. "Tasks are defined using the Harbor task format and executed within the Harbor harness"
- Intra-Drawing: Tasks that require reasoning across multiple sheets within the same drawing set. "Intra-Drawing: Tasks that require reasoning across multiple sheets within the same drawing set."
- Intra-Project: Tasks that involve coordination across multiple documents (drawings, specifications, submittals). "Intra-Project: Tasks that involve multiple documents, such as drawings, specifications, and submittals."
- Intra-Sheet: Tasks solvable using information on a single sheet/page. "Intra-Sheet: Tasks that can be completed using a single sheet (one PDF page)."
- leader lines: Thin lines that connect callout text to the specific element being annotated in a drawing. "the model must trace leader lines and related geometry purely visually to correctly identify and report issues;"
- linework: The lines and graphical elements composing the visual structure of technical drawings. "A visually dense drawing sheet with tightly packed annotations, callouts, and linework typical of real construction coordination artifacts."
- Nomic Embeddings: Embedding models provided by Nomic to create structured representations for retrieval and analysis. "Nomic Parse and Nomic Embeddings"
- Nomic Parse: A parsing tool by Nomic that extracts structured elements (text, layout, references) from PDFs. "Nomic Parse and Nomic Embeddings"
- parse augmentation: Enhancing an agent setup by adding parsed, structured document representations to improve performance. "This side-by-side layout isolates the effect of parse augmentation while keeping the underlying harness fixed."
- pdftoppm: A command-line utility to rasterize PDF pages into images (PPM/PNG formats). "Codex agents also rely heavily on rasterization via pdftoppm (96% of runs), whereas Claude agents use it far less frequently (32% of runs)."
- pdftotext: A command-line utility that extracts text from PDFs, often losing spatial layout information. "Across all models, 77% of trajectories invoke pdftotext, indicating strong convergence toward a pdftotext extraction pipeline;"
- pixel-level differencing: Image comparison method that highlights exact pixel changes between two versions of a document. "pixel-level differencing (before, after, and diff)"
- project-level document alignment: Ensuring consistency and agreement across drawings, specifications, and related project documents. "including intra-sheet review, cross-sheet navigation, and project-level document alignment."
- rasterization: Converting vector-based PDF content into raster images for visual processing. "Codex agents also rely heavily on rasterization via pdftoppm"
- retrieval-sensitive tasks: Tasks where success is dominated by the ability to find the correct evidence before reasoning. "Under the H+\nomicN, we observe substantial average gains across models, specifically on retrieval-sensitive tasks."
- sheet index: The index listing of sheets in a drawing set, often cross-checked against titles and content. "Compare sheet index entries against title blocks for mismatches."
- specifications: Formal written documents detailing materials, standards, and requirements that complement drawings. "such as project specifications"
- structured representations: Parsed, schema-like data extracted from documents that preserve layout and relationships. "agents are provided with structured representations of drawings, including extracted text, layout elements, and reference relationships"
- submittals: Contractor-provided documents (e.g., product data, samples) for approval against project requirements. "Evaluate submittals for compliance with specs and drawings."
- symbol-centric understanding: The ability to recognize and interpret standard symbols and notations used in technical drawings. "still lack robust drawing literacy, especially for symbol-centric understanding."
- title blocks: Standardized sections on drawing sheets containing metadata like project name, sheet number, and author. "Compare sheet index entries against title blocks for mismatches."
- tool ablations: Systematic removal or variation of tools in experiments to measure their impact on performance. "We report results across tool ablations of our AEC agent harness."
- toolchain: A set of tools used in sequence to process documents into analyzable formats. "Our PDF toolchain breaks these multi-page documents into structured, machine-readable data"
- traceability: The ability to trace extracted or edited elements back to their original source locations. "We cache these artifacts with source coordinates for full traceability."
- visual grounding: Tying textual findings or references to the correct visual regions or elements in documents. "fail on visual grounding, exhaustive traversal, and cross-document coordination."
- visual-spatial grounding: Accurately mapping and reasoning about spatial relationships in visual documents to support precise localization. "On tasks that rely more heavily on visual-spatial grounding."
Collections
Sign up for free to add this paper to one or more collections.

