Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
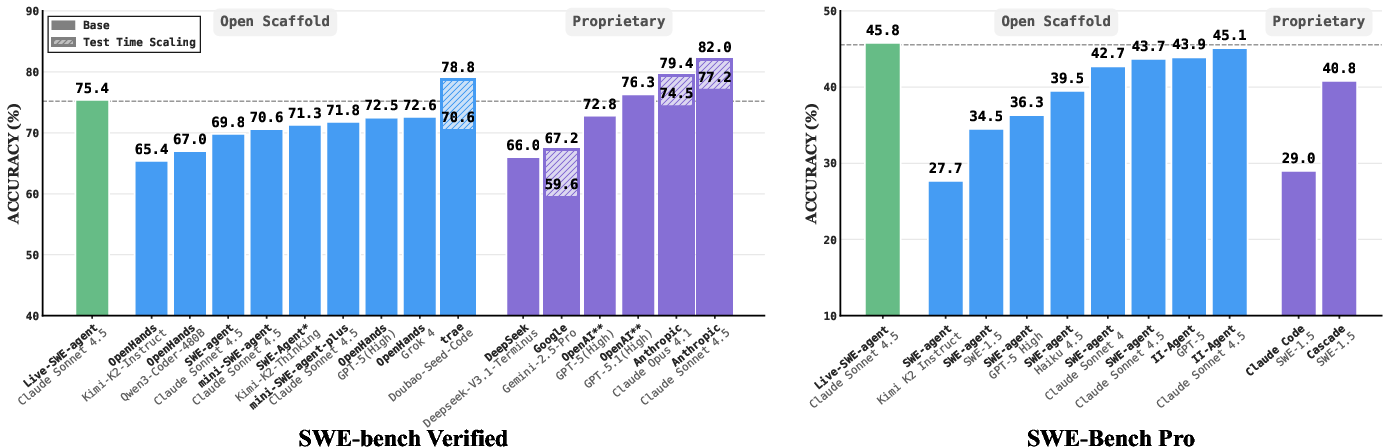
Abstract: LLMs are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-Gödel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Live-SWE-agent, a smart computer helper that fixes real-world coding problems. The special thing about it is that it can improve itself while it’s working. Instead of only using a fixed set of tools, it can create its own tools on the spot to solve the problem faster and better.
What questions does the paper try to answer?
To make the ideas clear, here are the main questions the researchers explore:
- Can a coding agent learn and improve itself during a task, not just before it?
- How do we let the agent decide when to build a new tool versus when to use an existing one?
- Does this “learn while working” approach beat other agents on well-known coding tests?
- Can this method stay simple, cheap, and work with different AI models?
How does Live-SWE-agent work?
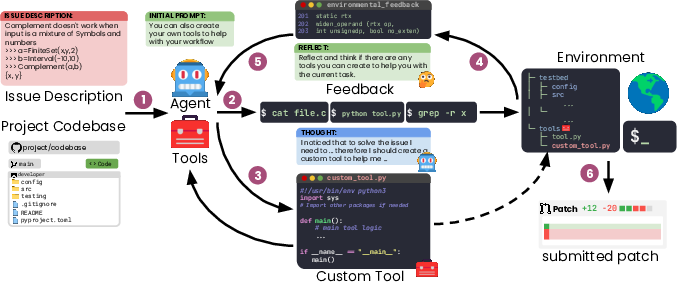
Think of a software agent as a “digital mechanic” working on a codebase. Most mechanics have a fixed toolbox. Live-SWE-agent starts with a very basic toolbox (just command-line tools, known as “bash commands”) and then, as it works, it can invent and add new tools to its toolbox.
Here’s the approach in everyday terms:
- Starting small: It begins with the simplest setup (only basic commands) so it’s lightweight and general.
- Two choices at each step: Every time it makes a move, it can either: 1) run a command to do something, or 2) create a new tool (a small script) that makes future steps easier.
- What is a “tool”? A tool is just a little program (a script) the agent writes and saves. For example, it might create:
- An editor tool that safely replaces text in a file and confirms it worked.
- A search tool that finds code patterns and shows helpful context without flooding the screen.
- A special analyzer for a unique file type (like MARC or Go source files) when the problem demands it.
- Reflection loop: After seeing the result of each step, the agent pauses and asks itself, “Would making or improving a tool help me here?” This quick self-check is like a coach whispering, “Is there a faster way?”
- No heavy training: Unlike some systems that spend lots of time and money training offline, Live-SWE-agent learns and adapts during the task itself. That keeps costs low and makes it work with different AI models.
Analogy: It’s like fixing a bike with a small starter kit, but if you discover a tricky bolt, you build a custom wrench right then and there—and keep using it for the rest of the repair.
What did the researchers find?
The team tested Live-SWE-agent on well-known benchmarks, which are collections of real coding issues used to measure performance:
- SWE-bench Verified (500 human-validated Python issues): Live-SWE-agent solved about 75.4% of the tasks. That’s better than previous open-source agents and close to the best commercial systems.
- SWE-Bench Pro (731 harder, more “enterprise-level” issues across multiple languages): Live-SWE-agent solved about 45.8%, which is the best reported open-source result at the time.
Why this matters:
- Better problem solving: Creating tools on the fly helps the agent solve more issues and sometimes reduces the number of steps needed.
- Low extra cost: It improves results without expensive offline training. Some older “self-improving” agents needed hundreds of hours or even tens of thousands of dollars’ worth of training runs.
- Adapts to the problem: The agent builds general tools (like edit/search) and also very specific tools tailored to unusual file formats or languages. That flexibility is key for real-world coding.
- Works across AI models: Stronger AI models benefit the most from this approach; weaker models can struggle to invent useful tools reliably. As AI models improve, Live-SWE-agent’s benefits grow.
Why is this important, and what could it lead to?
- Less manual design: Instead of engineers handcrafting giant toolboxes ahead of time, the agent builds exactly what it needs at the moment—saving effort and making systems more general.
- Better AI evaluation: This method tests both an AI’s ability to fix code and its ability to invent helpful tools. That gives a richer picture of how capable an AI really is.
- Broader uses: The same idea could help with writing tests, finding security bugs, analyzing binaries, or optimizing performance—domains where you often need very specialized tools.
- Future growth: The agent could learn to evolve not only its tools but also its overall strategy (its “scaffold”) and carry useful tools and skills from one task to the next. It could even be trained to self-evolve during learning, making future AI more adaptable and robust.
In short, Live-SWE-agent shows that letting an AI “craft its own tools while working” is a powerful, simple, and low-cost way to boost performance on real software problems.
Knowledge Gaps
Below is a concise, action-oriented list of knowledge gaps, limitations, and open questions the paper leaves unresolved.
- Quantify runtime overhead: report wall-clock latency, token usage, and step counts per issue, and isolate the marginal cost/benefit of tool synthesis versus baseline actions.
- Safety and sandboxing: design and evaluate permissioning, allowlists/denylists, resource limits, and syscall/network sandboxes for executing agent-generated scripts.
- Tool correctness validation: introduce pre-execution checks (unit tests, static analysis, schema/IO contracts) and measure how validation affects solve rates and failures.
- Failure-mode analysis: systematically characterize and mitigate loops, degenerately frequent tool creation, redundant/conflicting tools, and harmful edits.
- Reflection policy design: study sensitivity to reflection prompt wording, frequency, and triggers; compare static prompting to learned controllers or bandit-style gating.
- Lifecycle management of tools: specify and test policies for naming, versioning, modification, deprecation, and pruning within and across sessions.
- Cross-task retention: implement a persistent skill/tool library with retrieval and evaluate transfer, catastrophic forgetting, and overfitting across repositories.
- Generality across scaffolds: measure gains when starting from richer initial toolsets (e.g., editors/searchers) and quantify the marginal benefit of on-the-fly tools.
- Interplay with test-time scaling: evaluate whether multi-sampling, multi-patch search, and diversified trajectories complement on-the-fly tool synthesis.
- Controlled baselines: re-run competing agents under the same LLMs, budgets, and environments to remove confounds from different backends and costs.
- LLM robustness boundaries: extend LLM ablations beyond a 50-issue subset to full benchmarks and strong open-source models; identify capability thresholds where tool creation helps vs. harms.
- Broader evaluation: test on larger/heterogeneous codebases (monorepos), additional languages (Java/C/C++), OS variations, and SWE-bench-Live/PolyBench/Multi-SWE-bench.
- Cost accounting completeness: report compute/memory profiles and token breakdowns (prompt, reflection, tool code) in addition to dollar cost per issue.
- Repository isolation: assess side effects of generated tools on repo state and test infrastructure; adopt ephemeral worktrees, shadow copies, or container snapshots.
- Dependency management: define how generated tools declare and install dependencies (virtualenvs, lockfiles, offline constraints) and measure the reliability impact.
- Security and compliance: analyze risks of data exfiltration, secrets handling, license compliance of generated code, and introduce audit trails or policy checks.
- Tool discovery and selection: add retrieval/ranking over created tools (within-session and cross-session) to prevent “tool sprawl” and measure its effect on efficiency.
- Error handling and observability: standardize exit codes, structured outputs, telemetry, and logs for generated tools; study how this affects agent planning and debugging.
- Causal attribution: quantify which tool categories drive performance gains via ablations (disable/replace specific tool types) and report effect sizes.
- Cost–benefit gating: learn or estimate a decision policy that predicts when to create a tool versus issuing direct commands, optimizing for expected downstream gains.
- Beyond tools self-evolution: implement and evaluate online changes to prompts, planner/loop parameters, memory mechanisms, and environment interfaces.
- Persistence and sharing: define serialization, versioning, and governance for sharing tools across repos/teams while preventing specialization or degradation.
- Human oversight: test approval/review workflows for tool creation and modification; measure trade-offs between autonomy, safety, and performance.
- Reproducibility: release exact prompts, seeds, environment images, and evaluation scripts; report variance across runs and sensitivity to hyperparameters.
- Metrics beyond resolve rate: measure patch quality (maintainability, style), regression risk, and partial credit/functional coverage to capture nuanced improvements.
- Small-model pathways: devise lightweight policies (caps on tool creation, stricter validation, distilled controllers) to mitigate degradation on weaker LLMs.
- Reflection scheduling: study adaptive reflection frequency (event-triggered or uncertainty-based) to balance context/cost with benefits.
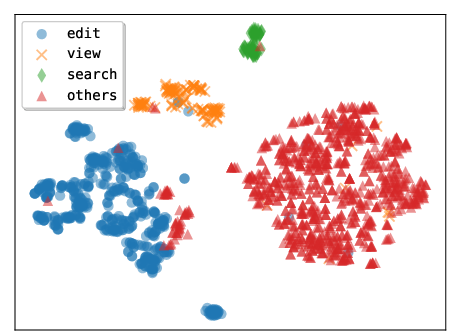
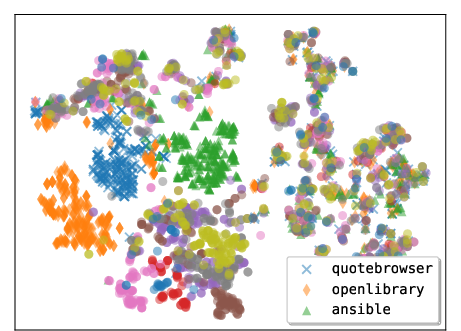
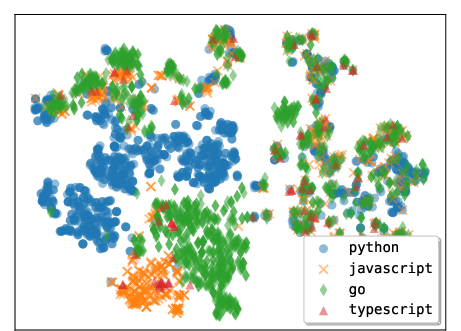
- Tool clustering rigor: replace qualitative t-SNE with quantitative clustering and correlate cluster membership with task characteristics and success rates.
- Build/toolchain complexity: evaluate performance on projects with heavy compilers, flakiness, and long builds; study caching and incremental builds for practicality.
- Real-world CI/code review integration: test end-to-end flows with PR creation, CI gates, reviewer feedback loops, and policy checks.
- Data contamination risk: assess proprietary LLM training contamination on SWE-bench-style tasks using controlled splits or contamination-aware models.
- Step-limit dynamics: analyze how tool creation affects step counts and hitting limits; adaptively tune limits or planning granularity.
- Fair comparisons to workflow systems: benchmark against Agentless/Moatless under identical LLMs and budgets to isolate the contribution of live tool synthesis.
- Guardrails for destructive commands: add formal policies or verifiers to prevent unsafe actions (e.g., rm -rf, chmod changes) and quantify prevented incidents.
Practical Applications
Overview
The paper introduces Live-SWE-agent, a minimal, runtime self-evolving software engineering agent that synthesizes and refines its own tools (as executable scripts) while solving real-world software issues. It achieves state-of-the-art open-source performance on SWE-bench Verified (75.4% solve rate without test-time scaling) and SWE-Bench Pro (45.8%). Its core innovation—on-the-fly tool creation with lightweight reflection—removes costly offline “self-improvement” and generalizes across LLMs, repositories, and languages.
Below are practical, real-world applications derived from the paper’s findings, categorized into immediate and long-term opportunities, with sector links, potential products/workflows, and key assumptions or dependencies.
Immediate Applications
These applications can be piloted or deployed now with strong LLMs, sandboxed environments, and integration into existing developer workflows.
- Software/DevOps: CI/CD auto-fixer for failing builds and issues
- Product/workflow: A GitHub/GitLab Action that triggers Live-SWE-agent on test failures, synthesizes repo-specific tools (search/edit/analyzers), proposes patches, opens PRs with diffs and test results for human review.
- Dependencies: Access to a strong LLM (e.g., Claude 4.5, GPT-5), reproducible tests, containerized sandbox with script execution, cost budget per task, VCS integration, audit logs.
- Enterprise Engineering: Internal “self-evolving” developer assistant
- Product/workflow: A bot that tailors tools to codebase idiosyncrasies (e.g., MARC or domain-specific file analyzers), supports root-cause analysis, rapid patching, and knowledge capture.
- Dependencies: Secure runtime with least privilege; change-management guardrails; access controls; observability of agent actions; alignment with enterprise coding standards.
- Open Source Maintenance: Issue triage and patch suggestions
- Product/workflow: Maintainer bot that reproduces issues, searches code, proposes fixes, and surfaces tailored tools for hard-to-inspect artifacts; can tag issues with confidence and open PRs.
- Dependencies: Clear issue descriptions, deterministic test harnesses, contributor license compliance, maintainer approval workflows.
- Developer Tools: IDE extensions for on-the-fly tool synthesis
- Product/workflow: VS Code/JetBrains plugin that lets the agent generate project-specific scripts (e.g., context-aware search, safe edit tools) to replace brittle multi-flag shell commands.
- Dependencies: Local sandboxed execution, policy for script persistence, telemetry to avoid privacy leakage, opt-in guardrails.
- AI Evaluation (Academia/Industry): Unified LLM benchmarking scaffold
- Product/workflow: Standardized evaluation harness that tests both issue-solving and tool-creation capabilities across models; reproducible tracks on SWE-bench Verified/Pro and internal corpora.
- Dependencies: Access to benchmarks and environments; standardized prompts; consistent cost budgets; seed control for reproducibility.
- Cost Reduction: Replace offline self-improving pipelines
- Product/workflow: Swap costly offline evolution (e.g., DGM/HGM pipelines) with Live-SWE-agent to deliver immediate performance gains at a fraction of cost, especially on verified issue sets.
- Dependencies: Reliable LLM backend; organizational acceptance of agent-in-the-loop instead of pretrained scaffolds; cost observability.
- Multilingual Development Support: Cross-language code analyzers
- Product/workflow: Agents synthesize lightweight analyzers for Go/TS/JS/Python to find identifiers, imports, and struct/function definitions for fast navigation and refactoring.
- Dependencies: Tolerance for heuristic parsers; not a substitute for full compilers; tests confirming analyzer accuracy on target repos.
- DevSecOps (low-hanging vulnerabilities): Rapid config/code hardening
- Product/workflow: Agent triages simple misconfigurations and code-level vulnerabilities (e.g., hardcoded secrets, unsafe defaults) and proposes patches; generates scanning tools tailored to the repo layout.
- Dependencies: Clear vulnerability reproduction; strict guardrails; security review gates; no binary-level or kernel-space actions.
- Data Engineering: Schema and ETL fix assistant
- Product/workflow: Agent synthesizes checks and validators (e.g., context-aware search over pipeline repos, schema diff tools) and proposes fixes for broken transformations.
- Dependencies: Access to sanitized data samples; privacy and compliance guardrails; staging environment; lineage/tracking.
- Education/Daily Life: Learning and local automation
- Product/workflow: Course labs where students explore agent tool creation; personal desktop tasks where the agent synthesizes scripts for batch file ops, log parsing, and small utilities.
- Dependencies: Safe local sandbox; curated tasks; limited permissions; model access.
Long-Term Applications
These require further research, scaling, or productization—often beyond tool creation to full scaffold self-evolution, persistent learning, and training-time integration.
- Skills/Tool Marketplace: Persistent, reusable “skill” library
- Product/workflow: A “Skills Store” that serializes effective tools discovered across tasks; agents load relevant skills on demand (e.g., repo-specific analyzers) and refine them.
- Dependencies: Versioning, provenance tracking, safety vetting, skill selection policies, license compliance.
- Full Scaffold Self-Evolution: Agent modifies prompts/workflows
- Product/workflow: Meta-agent that tunes its own loop (system prompt, action selection, feedback strategies) based on live outcomes; automatic schedule for tool creation vs. direct actions.
- Dependencies: Robust self-modification guardrails, automated A/B validation, rollback mechanisms, interpretability/audit trails.
- Training-Time Self-Evolution (AI Labs): Integrate into post-training
- Product/workflow: Models learn to synthesize and use tools during training (RL/CoT+tools), capturing richer signals and generalizing across scaffolds.
- Dependencies: Compute budgets; curated curricula; safe training environments; evaluation suites that test tool creation reliably.
- Enterprise Modernization: Large-scale codebase migration and optimization
- Product/workflow: Agents orchestrate profilers, tracers, and transformation tools (which they partly synthesize) to migrate frameworks, optimize performance, and reduce tech debt.
- Dependencies: Deep test coverage; performance baselines; production staging; SRE collaboration; extensive guardrails.
- Advanced Security: Binary analysis and patch pipelines
- Product/workflow: Agents compose decompilers and dynamic instrumentation—creating glue tools—for vulnerability discovery and remediation in complex binaries.
- Dependencies: Specialized toolchains; strict isolation; legal/regulatory compliance; expert review; high-performance compute.
- Robotics/Embedded: Domain-adaptive controllers and data tooling
- Product/workflow: Embodied agents generate task-specific data collection scripts, calibration tools, and simple controllers on the fly during experiments/simulation.
- Dependencies: Real-time constraints; sim-to-real safety; hardware APIs; rigorous testing; fail-safes.
- Governance/Policy: Standards for self-modifying AI in production
- Product/workflow: Policies for auditability of auto-created tools, change control, risk classification, and minimal-permission execution; procurement checklists leveraging the evaluation harness.
- Dependencies: Multi-stakeholder consensus; legal frameworks; secure logging; incident response plans; third-party certification.
- SaaS Platforms: “Self-evolving CI” offerings
- Product/workflow: Managed CI that automatically synthesizes repo-specific tools and patches; enterprise features for compliance, privacy, and observability.
- Dependencies: Enterprise trust; SOC2/ISO compliance; role-based access control; strong SLAs.
- Education/Research: Curricula and benchmarks on tool creation
- Product/workflow: Courses and lab suites focused on runtime tool synthesis, agent reflection, and evaluation; new benchmarks measuring tool utility, efficiency, and generalization.
- Dependencies: Open-source environments; standardized tasks; access to strong models; reproducible setups.
- Consumer OS Automation: Auto-Shortcuts/Auto-CLI
- Product/workflow: On-device agents that create bespoke utilities for repetitive tasks (file organization, reports, backups) with a secure approval flow.
- Dependencies: On-device models or private inference; permissions/sandboxing; UX for review and trust; energy/compute constraints.
Cross-cutting assumptions and dependencies
- Strong LLMs significantly improve outcomes; weaker models may fail to synthesize useful tools or get stuck (per ablations).
- Safe, sandboxed execution with strict permissions is mandatory to mitigate security risks of runtime tool creation.
- Deterministic test harnesses and reproducible environments increase success rates and confidence.
- Observability, audit logs, and human-in-the-loop review are critical for production adoption.
- Licensing, provenance, and compliance must cover synthesized tools and patches, especially in regulated domains.
Glossary
- Ablation: An experimental method that removes or alters components to assess their impact on performance. Example: "Our ablations and tooling analyses reveal that (1) custom tool creation materially improves effectiveness (higher solve rates) with minimal overhead"
- Action space: The set of operations an agent can take at any point; can be fixed or expanded. Example: "most existing agents have fixed designs and are limited in their static action space"
- Agent scaffold: The structural framework (prompts, tools, interfaces, workflows) that defines how an agent operates. Example: "it can be extremely challenging and costly to exhaust the entire agent scaffold design space."
- Agentic loop: The iterative decision–execution–feedback cycle an agent follows during problem-solving. Example: "Live-SWE-agent does not make any changes to the agentic loop, impose a particular workflow, or require any costly offline training."
- Context window: The maximum amount of text an LLM can consider at once. Example: "only showing the first 20 matches can be critically important to not drastically inflate the context window"
- Custom tool: A script the agent synthesizes and executes to extend its capabilities for the current task. Example: "we define a custom tool as a script that can be executed in the environment."
- Custom Tool Synthesis: The process by which the agent generates bespoke tools during runtime to aid problem-solving. Example: "Custom Tool Synthesis"
- Darwin-Gödel Machine (DGM): A prior self-improving software agent that evolves via costly offline procedures. Example: "including the Darwin-Gödel Machine (DGM)."
- Decompiler: A tool that translates binaries back into higher-level representations to aid analysis. Example: "we need binary analysis tools and decompilers."
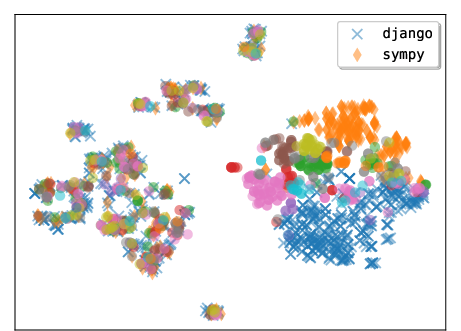
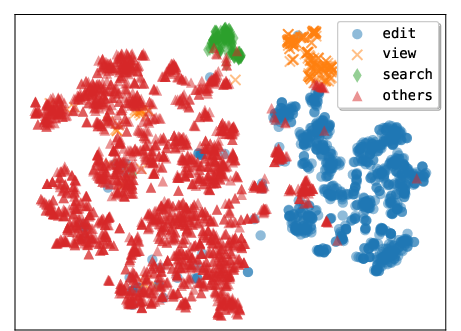
- Embedding: A vector representation of text or code used for similarity or visualization. Example: "We compute the embedding for each tool based on the tool body"
- Environmental feedback: The observable outputs (e.g., test results, command outputs) returned by the execution environment. Example: "directly provide the environmental feedback output to the agent"
- Huxley-Gödel Machine (HGM): A self-improving agent framework that performs offline evolution of scaffolds and strategies. Example: "Huxley-Gödel Machine (HGM)"
- LLM backend: The specific LLM used to power the agent’s reasoning and generation. Example: "benefits persist across different state-of-the-art LLM backends"
- MARC (Machine-Readable Cataloging) file: A standardized bibliographic data format used by libraries. Example: "MARC files, a file format for publication or text records"
- mini-SWE-agent: A minimal baseline agent that primarily uses bash tools. Example: "we implement Live-SWE-agent on top of the popular mini-SWE-agent \citep{yang2024sweagent} framework."
- Offline evolution: Improving an agent by modifying and validating its scaffold using precompiled benchmarks rather than during live runs. Example: "they rely heavily on offline evolution"
- Offline training: Costly pre-execution learning phases used to adapt an agent or model to benchmarks. Example: "such self-improving agents require costly offline training on known benchmarks"
- On-the-fly self-evolution: The agent’s ability to modify itself (e.g., by creating tools) during runtime while solving a task. Example: "performing practical self-evolution on-the-fly during runtime"
- Patch: A code change submitted to fix an issue. Example: "and sample one patch per issue."
- Profiler: A performance analysis tool to identify bottlenecks in software systems. Example: "To optimize a large complex system, we need to apply profilers and tracing tools."
- Reflection prompt: A targeted prompt that asks the agent to analyze its recent steps and decide whether to create or revise tools. Example: "A lightweight stepâ‘reflection prompt repeatedly asks the agent whether creating or revising a tool would accelerate progress"
- Resolve rate: The percentage of issues successfully solved by the agent. Example: "achieves 75.4\% resolve rate on Verified"
- Self-Improving Coding Agent (SICA): A prior framework for agents that evolve their strategies via offline improvement. Example: "Self-Improving Coding Agent (SICA)"
- Static analyzer: A tool that examines source code without executing it to extract structural or semantic information. Example: "a simple static analyzer for the Go programming language"
- SWE-agent: A software engineering agent framework equipped with specialized tools for repository tasks. Example: "SWE-agent \citep{yang2024sweagent}"
- SWE-bench Multilingual: A benchmark of software engineering tasks across multiple programming languages. Example: "SWE-bench Multilingual \citep{sbm}"
- SWE-bench Verified: A curated benchmark of 500 real-world issues verified by human annotators. Example: "SWE-bench Verified benchmark"
- SWE-Bench Pro: A more challenging benchmark capturing enterprise-level software issues across multiple repos and languages. Example: "SWE-Bench Pro \citep{deng2025swe}"
- Test-time scaling: Boosting performance by increasing inference-time resources (e.g., more samples or longer chains) rather than changing training. Example: "without test-time scaling"
- t-SNE: A dimensionality reduction method used to visualize high-dimensional embeddings. Example: "t-SNE visualization of tools generated by Claude 4.5 Sonnet"
- Trajectory: The sequence of states, actions, and observations an agent experiences while solving a task. Example: "reflect on its past trajectory to determine if it should create any tools"
Collections
Sign up for free to add this paper to one or more collections.