- The paper introduces FusionCIM, a hybrid operator-fusion architecture that minimizes data movement by integrating compute-in-memory with a QO-stationary dataflow for LLM inference.
- It achieves up to 3.85× energy reduction and 1.98× speedup by cutting off-chip memory access by nearly 59% and on-chip traffic by up to 71%.
- The approach incorporates pattern-aware softmax scheduling to drastically reduce nonlinear rescaling, ensuring robust performance under long-context workloads.
FusionCIM: Fusion-Driven Computing-in-Memory Architecture for Efficient LLM Inference
Introduction and Motivation
The persistent challenge in LLM inference is the high overhead due to computation intensity and memory bandwidth constraints, especially under long-context workloads. Conventional solutions leveraging GPUs/TPUs, despite rapid growth in compute density, are fundamentally limited by frequent off-chip DRAM access—predominantly for activations—leading to excessive energy consumption and inferior throughput. Compute-in-memory (CIM) architectures offer a viable route by colocating arithmetic operations within memory arrays, reducing weight-activation movement. However, extant CIM-based accelerators manifest bottlenecks in activation handling, inefficient on-chip memory access due to tiling and transposition, and excessive overhead from elementwise nonlinear softmax fusion.
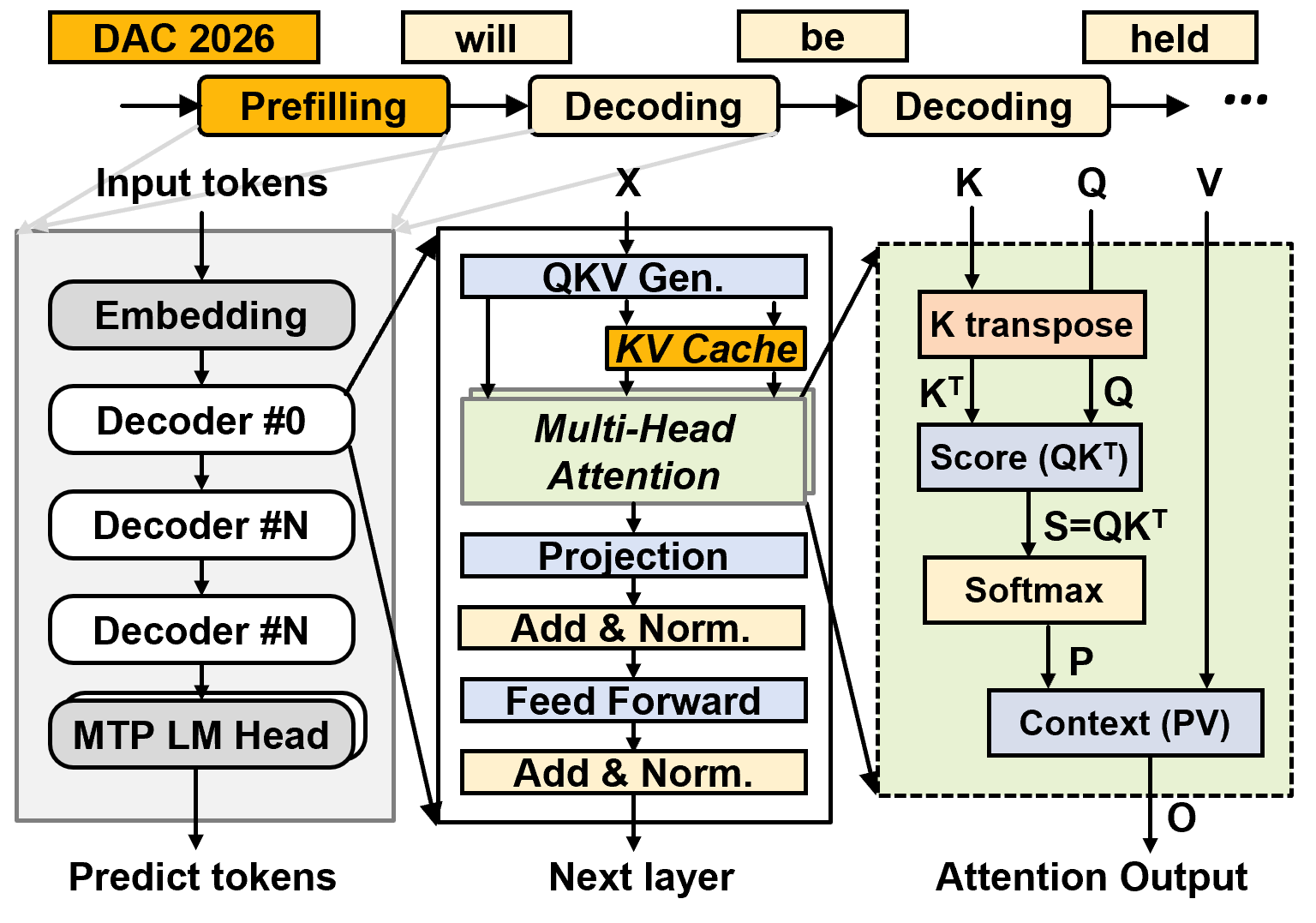
Figure 1: Model framework and inference in LLM, showcasing the fundamental flow of attention and feed-forward computation.
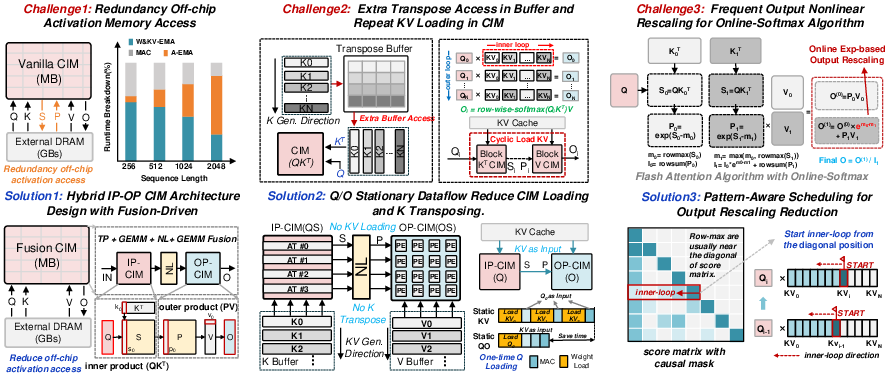
Figure 2: Three challenges in current CIM architectures for LLMs and the corresponding solutions embedded in FusionCIM.
This work presents FusionCIM, which overcomes the aforementioned limitations via a hybrid operator-fusion architecture, a QO-stationary dataflow strategy, and a pattern-aware softmax scheduling approach. These innovations jointly minimize redundant data movement, off-chip/on-chip access, and nonlinear fusion workload, providing substantial improvements in system energy and area efficiency for large-scale LLM applications.
FusionCIM Architecture
FusionCIM employs a hierarchical design comprised of a global buffer, a centralized scheduler, a DRAM memory controller, and multiple hybrid compute engines (HEs). Each HE integrates inner-product CIM (IP-CIM) and outer-product CIM (OP-CIM) macros, along with a lightweight, parallel softmax pipeline. This hybrid enables full operator fusion—GEMM, transposition, and softmax aggregation—directly within the memory array, thereby minimizing extraneous memory access patterns.
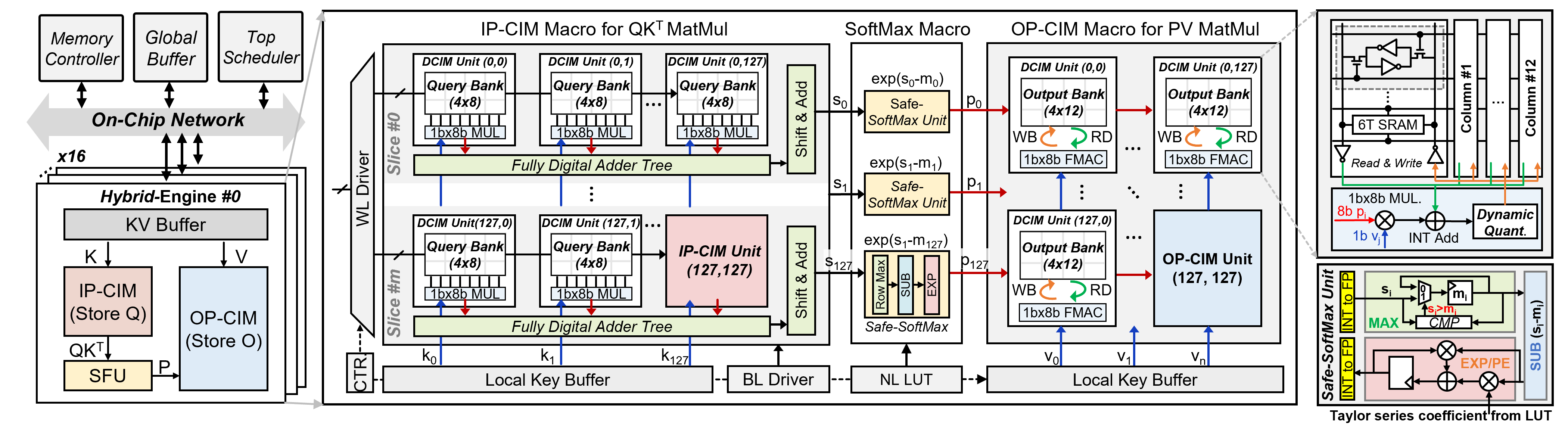
Figure 3: The overall architecture of FusionCIM, partitioned into multiple hybrid engines delivering efficient memory-compute fusion.
The IP-CIM macro is designated for QKT (attention score) computation with Q-stationary mapping, while the OP-CIM macro handles PV (context aggregation) through O-stationary mapping. Integration of a streamlined softmax engine allows real-time normalization within the attention pipeline, obviating the need for intermediate buffering or additional circuit resources for critical path arithmetic.
QO-Stationary Dataflow and Pipeline
Distinct from prior approaches that statically map KV pairs and repeatedly reload tiles with accompanying transposition, FusionCIM leverages a QO-stationary dataflow. Query and output activations are maintained in situ within the compute pipelines, enabling efficient, in-place transposition and maximizing data reuse. This mechanism drastically curtails repeated KV loading and associated high-energy write operations endemic to existing CIM paradigms.
Attention execution in each hybrid engine is orchestrated as a two-stage pipeline:
- At the vector level, K and V vectors are streamed in a staggered manner for successive QKT, softmax, and PV computation.
- Internally, a bit-serial pipeline processes each 8-bit vector element with cycle-aligned Taylor-expansion softmax, ensuring minimal throughput loss due to nonlinear units.
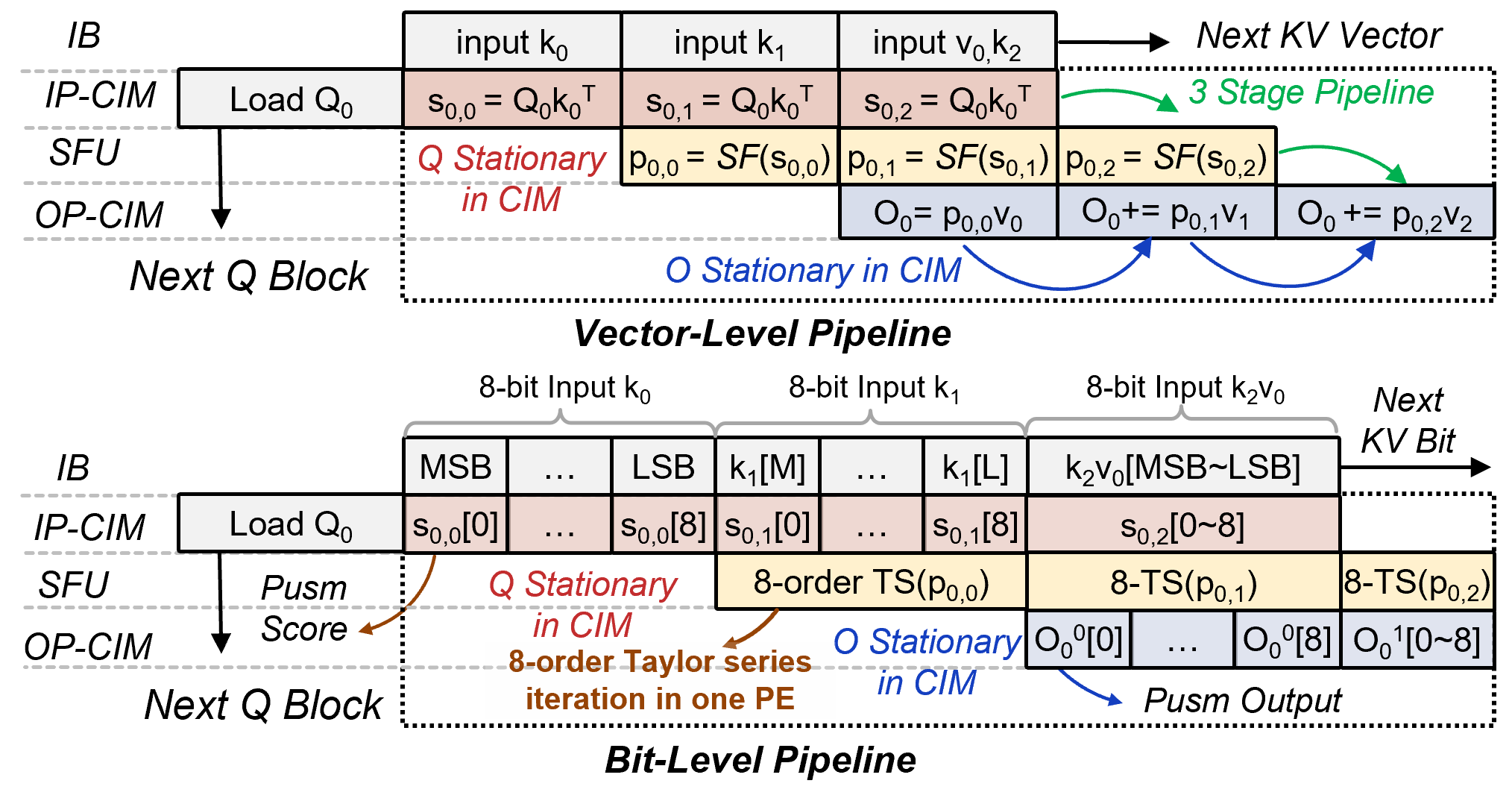
Figure 4: Two-level pipelined attention execution in FusionCIM, highlighting single Q loading and continuous data reuse.
Pattern-Aware Online Softmax Fusion
Standard online softmax introduces severe rescaling overheads, particularly with tile-wise scheduling that cannot anticipate score maxima until all tiles are processed. FusionCIM mitigates this by leveraging the empirical observation that attention score maxima tend to be diagonally distributed. Thus, the system implements a diagonal-first scheduling in both inter- and intra-tile scopes, identifying row maxima earlier and suppressing redundant output rescaling.
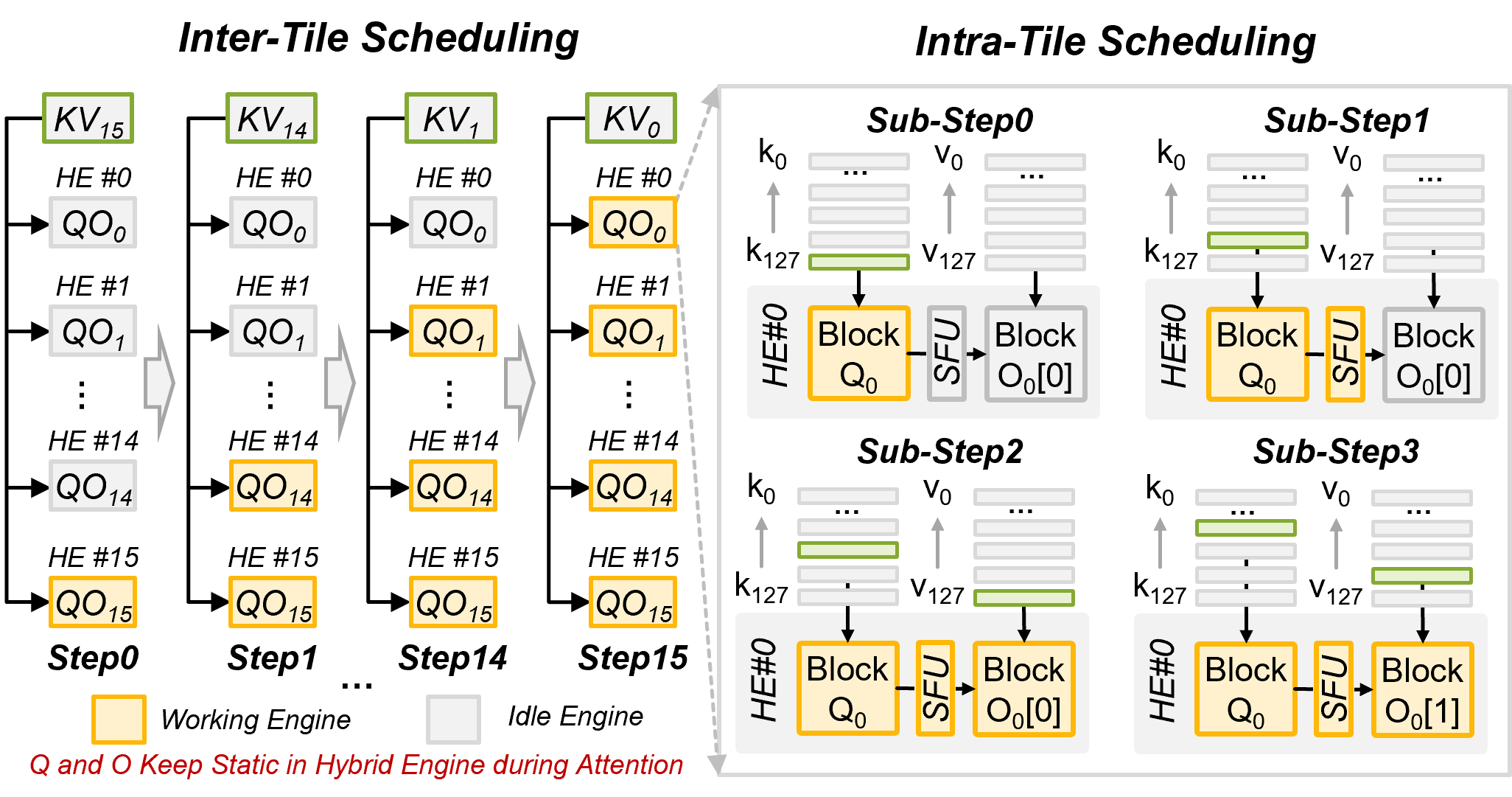
Figure 5: Inter- and intra-tile pattern-aware scheduling for online-softmax; the diagonal-first traversal reduces softmax rescaling overhead.
Empirical analysis demonstrates that this pattern-aware softmax approach can eliminate 58–61% of output rescalings for LLaMA3 with rotary encoding, and over 98% when combined with ALiBi positional encoding—delivering marked improvement in nonlinear latency and energy efficiency without loss in standard softmax fidelity.
Experimental Evaluation
Latency and Throughput
The comparative performance across baseline digital-CIM and prior pipeline CIM architectures establishes the efficacy of FusionCIM's operator-fusion and QO-stationary dataflow. Under representative LLM workloads (LLaMA3-8B, context up to 8K), FusionCIM achieves a speedup of up to 1.98× over monolithic-CIM and 21–40% over static-KV pipeline designs as the context length increases.
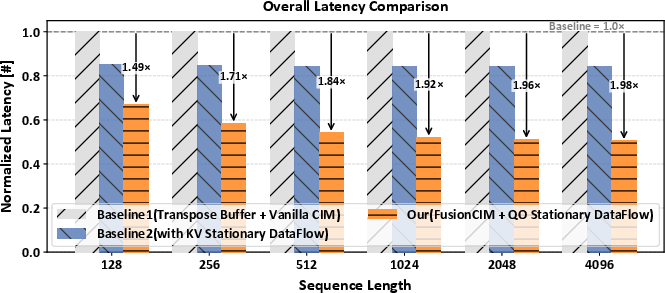
Figure 6: Normalized latency comparison—FusionCIM exhibits consistently lower latency across long-sequence inference tasks.
Energy and Memory Access
FusionCIM delivers 3.85× reduction in total energy consumption relative to conventional architectures at 4K sequence length, with the energy advantage amplifying for larger contexts due to dominant activation access cost.
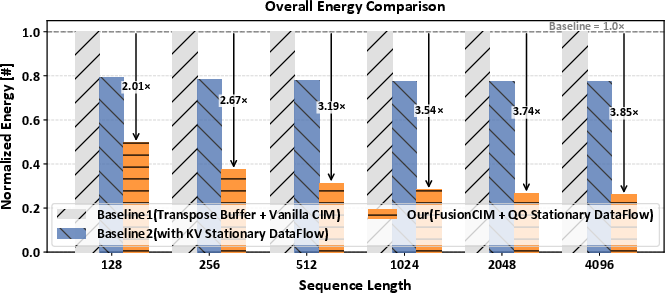
Figure 7: Normalized energy consumption across baselines, with FusionCIM's hybrid pipeline achieving maximal energy savings.
Off-chip memory access is reduced by up to 58.9% and on-chip traffic by up to 71% via QO-stationary scheduling and transposition-elimination mechanisms.
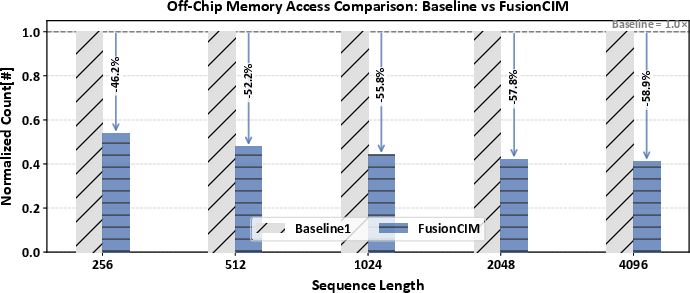
Figure 8: Normalized off-chip memory access—FusionCIM maintains significant reduction independent of sequence length growth.
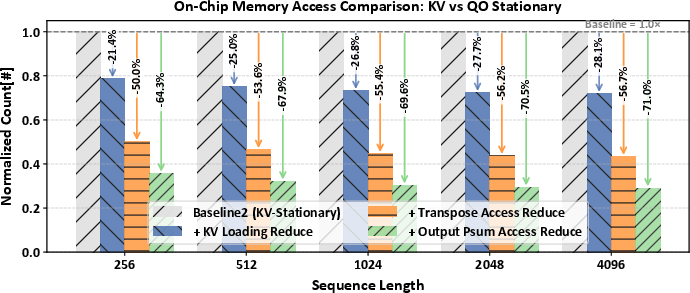
Figure 9: Normalized on-chip memory access and ablation studies demonstrating the contribution of each optimization within FusionCIM.
Nonlinear Rescaling Reduction
Implementing pattern-aware scheduling directly translates into substantial reductions in the number of required output rescaling operations for online softmax, robustly across various models and prompt structures.
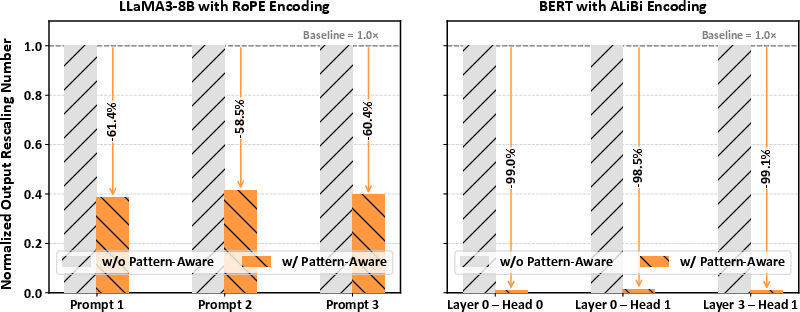
Figure 10: Normalized output rescaling number comparison showing substantial reduction under different network and prompt configurations.
System Efficiency
FusionCIM demonstrates 29.4 TOPS/W energy efficiency and 2.03 TOPS/mm2 area efficiency at system scale, surpassing prior solutions (P3ViT, TranCIM) by factors ranging from 1.26×–2.35× (energy) and 2.5×–9.2× (area). The architecture scales efficiently and exhibits manufacturability and deployability using mature 28 nm technology nodes.
Implications and Future Directions
FusionCIM advances the boundary of CIM-based LLM acceleration by resolving core activation and nonlinearity bottlenecks, enabling efficient, scalable inference for long-context transformer architectures. The integrated hybrid pipeline combined with a QO-stationary dataflow paves the way for further innovations in fusion-driven accelerator design—including dynamic tiling/adaptivity based on prompt and model structure, and seamless support for advanced attention mechanisms (e.g., grouped-query, multi-token decoding). Integration with further co-designed HW/SW scheduling and advanced positional encoding techniques offers a promising route toward ubiquitous, low-power edge deployment of LLMs.
Conclusion
FusionCIM systematically addresses data movement and on-chip resource constraints endemic to LLM inference through hybrid operator fusion, QO-stationary dataflow, and pattern-aware nonlinear scheduling. Empirical results demonstrate strong improvements—up to 3.85× in energy savings and 1.98× latency reduction—while maintaining high area and computational efficiency. The proposed architecture substantiates the viability of tightly coupled compute-memory fusion for future AI accelerators capable of sustaining next-generation LLM workloads.