- The paper presents TrilinearCIM, a DG-FeFET based architecture that eliminates runtime NVM reprogramming for in-memory trilinear multiplication in transformer models.
- It fuses attention computation into a single MAC stage, reducing data movement and achieving up to 46.6% energy savings and 20.4% latency reduction over bilinear CIM.
- The design nearly triples buffer reduction and improves NLP task accuracy while incurring a 37.3% area overhead, demonstrating practical energy and efficiency gains.
Introduction
Transformer models have redefined state-of-the-art in NLP and vision applications by exploiting self-attention mechanisms, but the quadratic complexity of attention and massive parameter counts incur significant energy and latency costs. Compute-in-Memory (CIM) architectures mitigate the data-movement bottleneck fundamental to von Neumann computing by leveraging analog memory cells for in-situ matrix-vector multiplications. However, standard two-operand CIM primitives are structurally mismatched to the three-operand interactions in attention, with dynamic operand generation forcing frequent non-volatile memory (NVM) reprogramming—a major throughput, energy, and endurance bottleneck for FeFET/ReRAM/PCM-based accelerators.
This work presents TrilinearCIM, a DG-FeFET-based CIM architecture that implements a true three-operand multiply-accumulate operation using a volatile back-gate modulation path. This eliminates runtime NVM reprogramming during attention computation and enables all attention steps to execute within the memory array using static, preprogrammed weights. Experimental evaluation with BERT-base (GLUE) and ViT-base (ImageNet, CIFAR) shows that TrilinearCIM achieves up to 46.6% energy reduction and 20.4% latency improvement versus the best conventional CIM baselines, at a controllable area overhead.
Trilinear Compute-in-Memory Primitive
The key innovation is the integration of a double-gate FeFET structure. The ferroelectric top gate encodes the stationary weight as conductance, while the back gate, isolated by a conventional dielectric, provides a third, volatile input—effectively implementing IDS=VDS⋅G0⋅(1+ηBGVBG). The second term realizes a first-order trilinear multiplication, where the inputs are distributed as row voltage (sequence/activations), column back-gate voltage (modulator), and non-volatile weight (stored in conductance). The design constrains G0 to a linear operating band to guarantee uniform back-gate modulation sensitivity, validated via experimental data calibration.
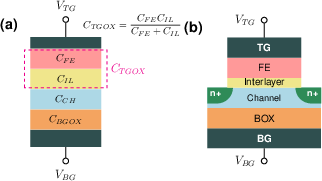
Figure 1: DG-FeFET device concept, with the top-gate storing weight and the back-gate providing a volatile modulation pathway.
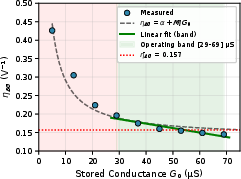
Figure 2: Back-gate modulation sensitivity ηBG as a function of programmed conductance, with the selected operating band ensuring reliable linearity and bounded error.
This trilinear primitive enables all attention stages—including token-tokent correlation (score), value aggregation, and query scaling—without dynamic NVM writes. Fixed weights are programmed at initialization, and runtime back-gate signals modulate conductance for dynamic operand application.
System Architecture and Dataflow
The proposed accelerator uses a scalable chip organization, hierarchically partitioned into tiles, processing elements, and DG-FeFET crossbar arrays, each supporting trilinear computations. A digital peripheral unit handles operations not amenable to analog compute (Softmax, LayerNorm, GELU).
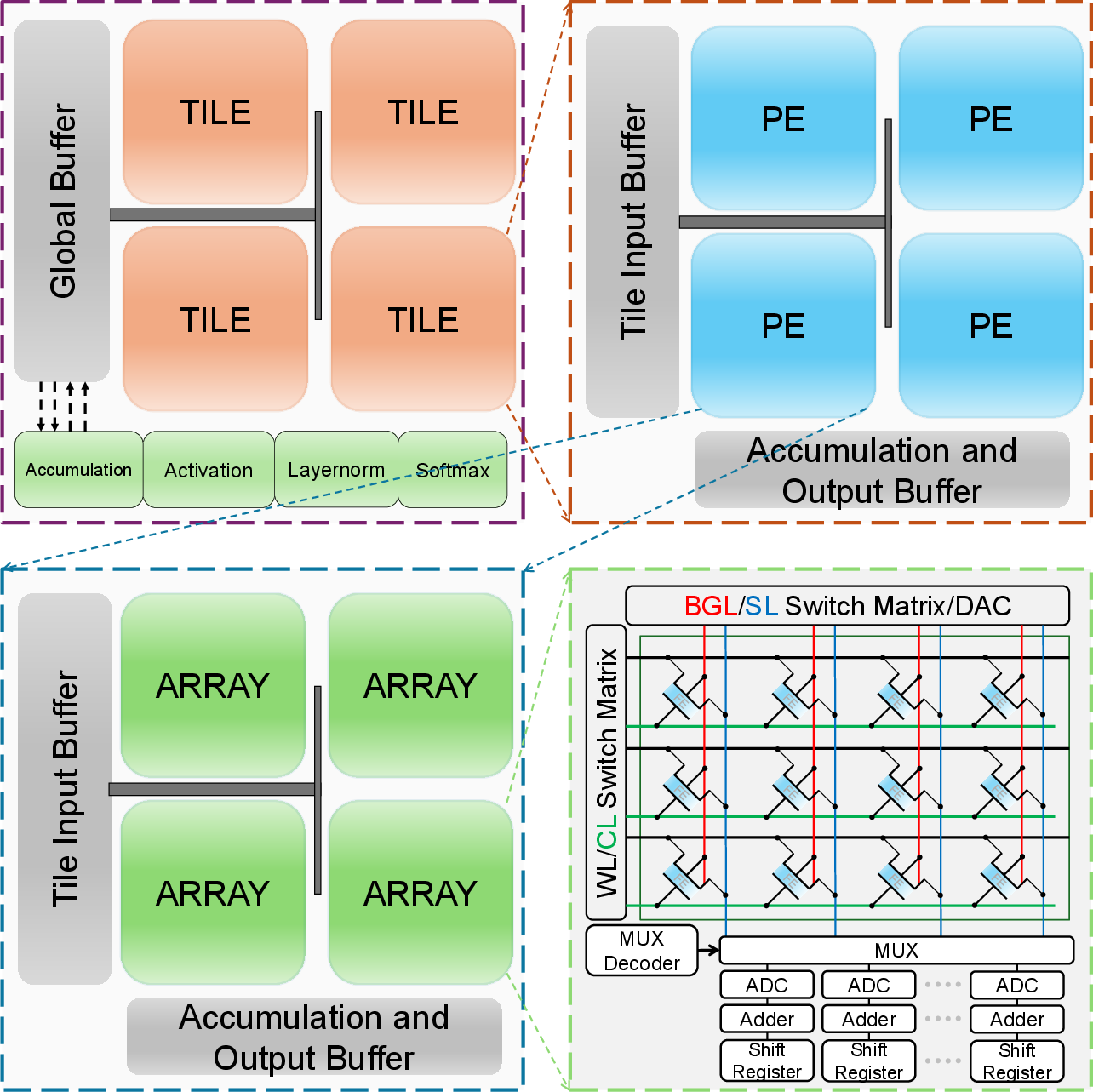
Figure 3: Hierarchical organization of the trilinear CIM accelerator, showing chip, tile, PE, and subarray organization.
The attention dataflow is compact: projections and subsequent matrix products are fused into trilinear MAC stages, reducing intermediate storage from three full-size tensors to one input sequence. This nearly 3× reduction in buffer requirements relieves DRAM/SRAM pressure.
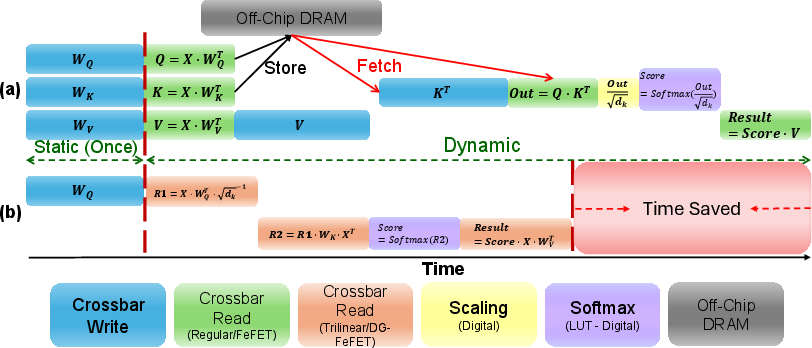
Figure 4: Dataflow comparison—trilinear attention eliminates DRAM transfer of Q/K/V projections, fusing data movement and compute into a single trilinear MAC path.
Trilinear configurations are adapted for each attention stage: during score synthesis, each column receives its own modulator, and results are aggregated accordingly. Stage-specific operand routing optimizes for parallelism and energy/latency trade-offs.
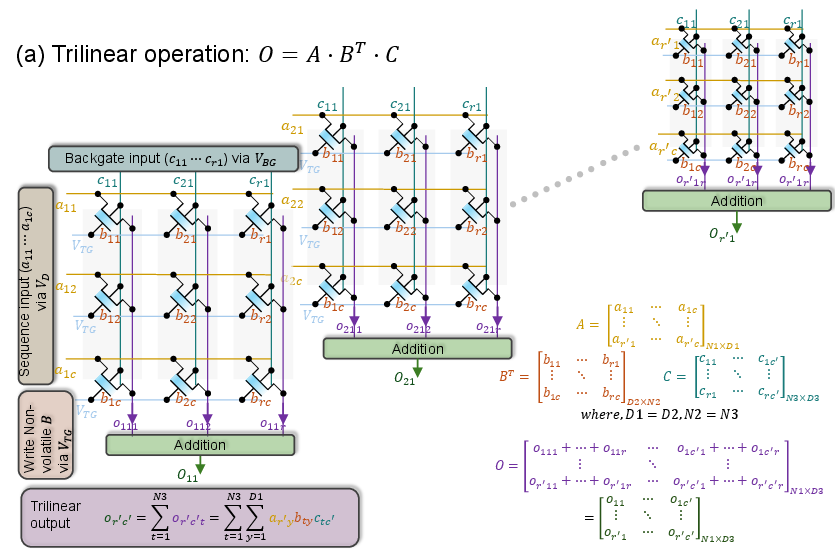
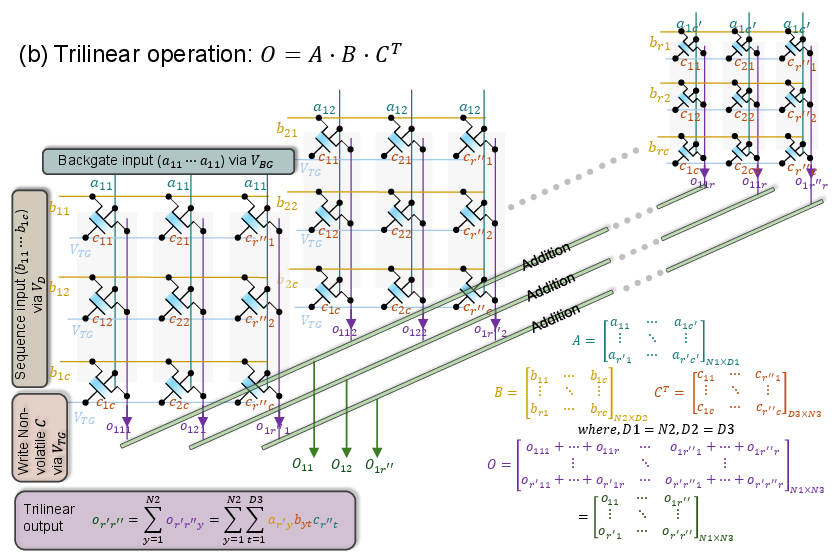
Figure 5: DG-FeFET crossbar for trilinear MAC; (a) modulator per column for O=A⋅BT⋅C, (b) uniform modulation for O=A⋅B⋅CT.
Experiments with BERT-base on GLUE reveal that trilinear CIM outperforms bilinear CIM on seven of nine tasks, with largest accuracy gains on QNLI (+3.74%), MNLI (+3.14%), and STS-B (+1.74%). Standard deviation is also lower, indicating improved stability by eliminating repeated mixed analog-digital conversion cycles.
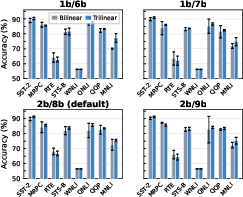
Figure 6: Per-task GLUE benchmark scores for bilinear and trilinear modes across varying cell/ADC configurations, with trilinear showing systematic accuracy and variance gains on most tasks.
For ViT-base on image benchmarks, trilinear accuracy lags due to the exacerbated impact of quantization error on vision attention distributions. Nonetheless, trilinear CIM delivers robust gains on NLP workloads.
Energy and latency results show that trilinear CIM consistently reduces per-inference energy (up to 46.6%) and latency (up to 20.4%) compared to bilinear CIM. Area overhead from per-column back-gate drivers and DACs is 37.3%, but compute density (TOPS/mm²) and energy-efficiency (TOPS/W) are improved or maintained at typical sequence lengths.
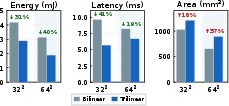
Figure 7: Sub-array size ablation quantifies the energy, latency, and area trade-offs between bilinear and trilinear CIM for practical configuration choices.
Ablation studies across sub-array size, cell/ADC precision, and sequence length confirm that the trilinear advantages are maintained as parameters are scaled, with 1b/6b precision and 32×32 sub-arrays offering particularly strong operating points for energy, area, and accuracy.
Implications and Future Directions
The architectural decoupling of weight storage from dynamic operand modulation by DG-FeFETs marks a significant step toward attention-friendly CIM. This eliminates one of the fundamental roadblocks—the NVM endurance/latency penalty—enabling direct mapping of arbitrary-length, all-to-all attention in a pure in-memory system without sacrificing the area and leakage advantages of FeFET NVM.
Practical implications include substantially lower energy footprint for sequence-processing and long-context workloads, improved lifetime reliability, and simpler data movement and buffering strategies in system-level designs. For vision transformers, future work must address quantization-induced accuracy gaps—potentially through hardware-aware fine-tuning, custom non-uniform DACs/back-gate coding, or selective digital fallback for peak attention values.
Device-level validation remains essential before deployment; full-array demonstrations must validate that the chosen operating band for G0 and back-gate uniformity is achievable at scale and under realistic process and noise conditions. Additional research into ultra-low-voltage, area-shared DAC implementations for back-gate driving could further reduce the area and static energy costs.
Conclusion
TrilinearCIM demonstrates the feasibility and system benefit of all-in-memory, write-free attention computation by exploiting the unique properties of DG-FeFETs. Through volatile back-gate modulation, it achieves true in-situ trilinear multiplication, enabling up to 46.6% energy savings and 20.4% latency reduction with accuracy improvements over standard bilinear CIM on key NLP tasks. The architecture forefronts a new category of non-von-Neumann accelerators equipped to support dynamic, multi-operand dataflows at scale and may serve as a foundation for future CIM research targeting advanced attention and sequence learning applications.

