- The paper introduces a systematic, post-layout framework for exploring dataflow in SRAM CIM accelerators by co-optimizing macro and array configurations.
- It employs cycle-accurate simulation and SPICE-based PPA evaluation to reveal vital performance-energy trade-offs, especially comparing systolic and broadcast interconnects.
- Practical case studies on LLM inference demonstrate that optimized macro-array co-design enhances compute density and scalability for both edge and cloud deployments.
AccelCIM: Systematic Dataflow Exploration for SRAM Compute-in-Memory Accelerator
Introduction and Motivation
SRAM-based Compute-in-Memory (CIM) technology has advanced neural network acceleration through the integration of MAC units directly within SRAM arrays, maximizing computational density and energy efficiency. However, SRAM CIM's inherent limited capacity introduces substantial data movement challenges for large-scale DNNs, especially LLMs requiring extensive on-/off-chip weight updates. Existing architectural explorations often neglect these bottlenecks by presuming that models fit entirely on-chip, thereby ignoring critical trade-offs in dataflow, macro arrangement, and physical design. "AccelCIM: Systematic Dataflow Exploration for SRAM Compute-in-Memory Accelerator" (2604.17692) addresses these gaps via a systematic dataflow exploration and rigorous post-layout evaluation, introducing a fully automated framework that co-optimizes spatial macro configurations and array-level dataflows to identify Pareto-optimal designs.
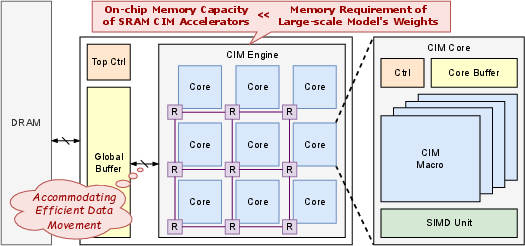
Figure 1: The design hierarchy of typical CIM accelerators. The limited capacity of SRAM CIM renders dataflow design critical to accommodate efficient data movement.
CIM Macro and Dataflow Design Space
The AccelCIM framework constructs a rich design space by jointly parameterizing the CIM macro specifications and macro array organizations (including dataflows and interconnection methods). Macro-level exploration spans parameters such as accumulation length (AL), local storage length (LSL), parallel channels (PC), pipeline level (PL), compute-I/O overlap (OL), and bitwidth choices. Array-level exploration encompasses row/column sizes, weight/output stationarity (WS/OS), and broadcast vs. systolic interconnects.
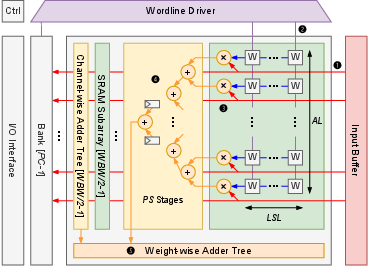
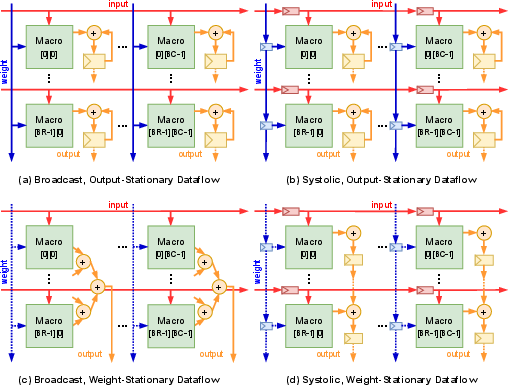
Figure 2: (Left) AccelCIM's design space table. (Middle) AccelCIM CIM macro template. (Right) Array-level dataflow options within AccelCIM.
Post-layout macro evaluation reveals a performance-energy trade-off as larger macros achieve superior energy efficiency (leveraging dense compute-memory integration) yet attain lower operational frequency due to extended critical paths. Additionally, enabling compute-I/O overlap reduces latency for weight updates but incurs a ~25–35% degradation in energy and area efficiency, especially in bandwidth-constrained configurations.
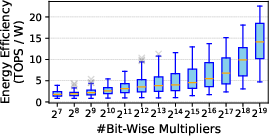
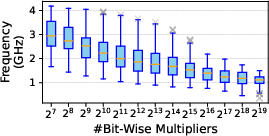
Figure 3: Distribution of CIM macro energy efficiency and frequency under different compute capacities.
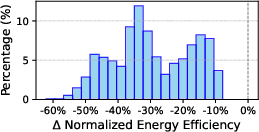
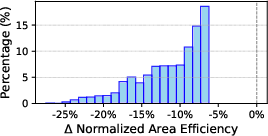
Figure 4: Histogram of CIM macro energy/area efficiency relative degradation when compute-I/O overlap is enabled.
Macro Array Generator and Rigorous PPA Evaluation
AccelCIM's macro array generator automates the creation of macro layouts, produces gate-level netlists, and completes digital floorplanning/routing using commercial tools, ensuring timing closure and compact placement. Timing and power are derived via SPICE simulation and integrated with cycle-accurate architectural modeling, yielding high-fidelity performance, power, and area (PPA) metrics.
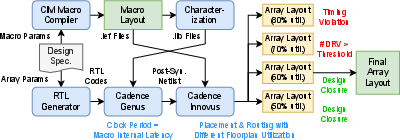
Figure 5: AccelCIM's macro array generator workflow detailing the macro-to-array design and evaluation.
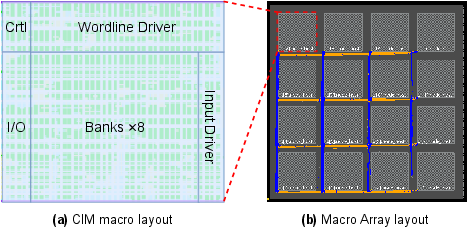
Figure 6: Example layouts from AccelCIM's macro array generator, illustrating spatial macro arrangements and routing resource constraints.
Dataflow Exploration and Experimental Results
The systematic exploration across macro size, array organization, and dataflow yields several observations:
- Systolic interconnects consistently demonstrate superior area efficiency, mitigating routing overhead compared to global broadcast links.
- Energy efficiency is dominated by macro-level design, with medium-sized macros balancing internal broadcast costs and peripheral logic overhead for optimal system-level trade-off.
- Compute-I/O overlap is beneficial to area efficiency for designs with high PC (parallel channels), but generally detrimental to energy efficiency.
- Accurate Pareto frontier identification requires joint timing- and cycle-aware simulation; neglecting frequency penalizes throughput estimation, as evidenced in WS-Systolic-NOL exploration.
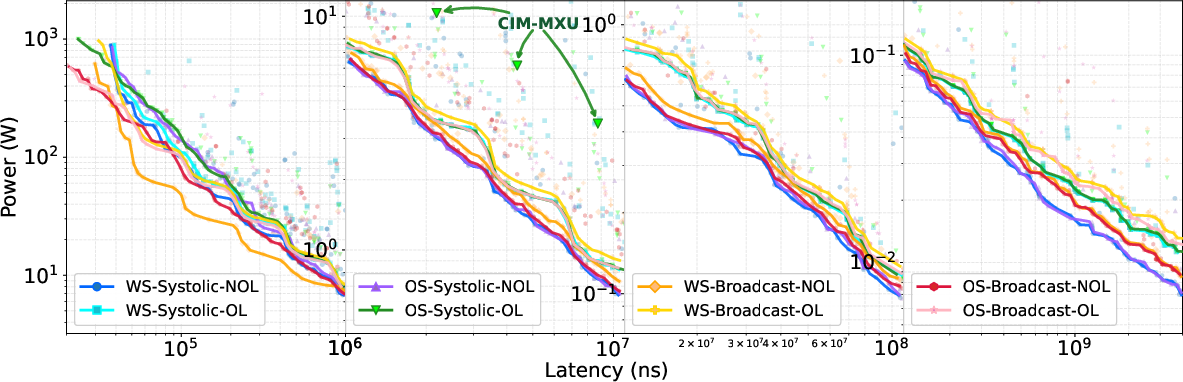
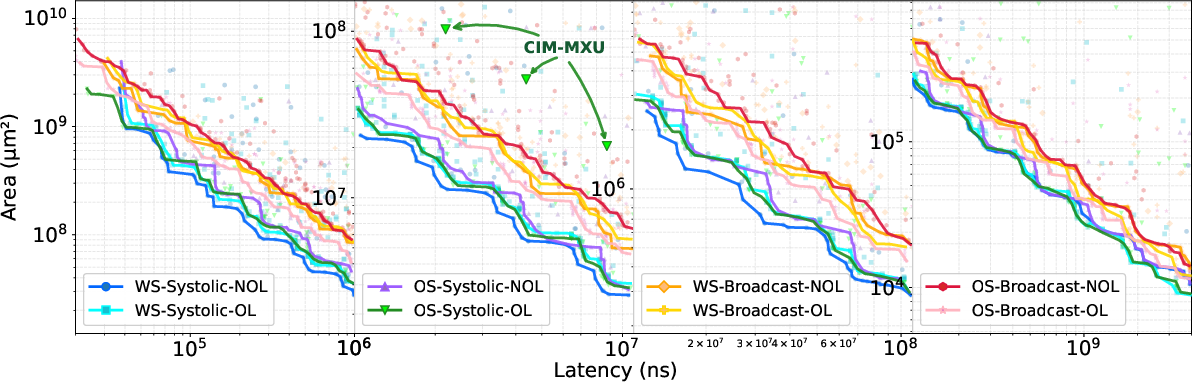
Figure 7: Performance and power Pareto frontiers across the AccelCIM dataflow space.
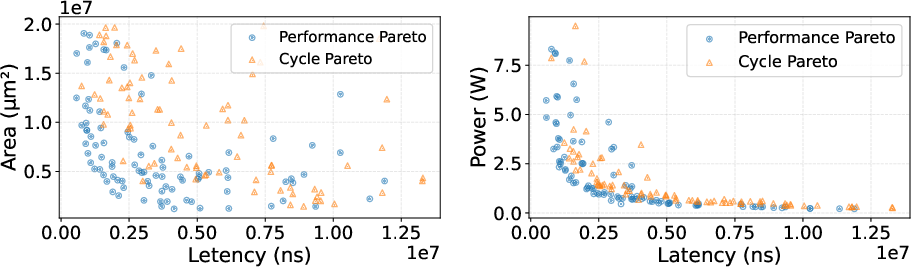
Figure 8: Comparison of cycle-oriented and performance-oriented design Pareto frontiers, showing impact of accurate frequency modeling.
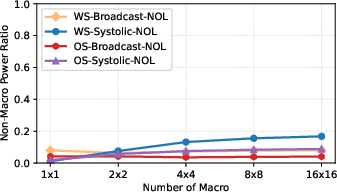
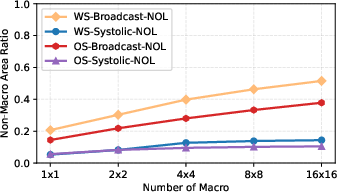
Figure 9: Power overhead attributed to array-level integration, highlighting the scalability of array organizations.
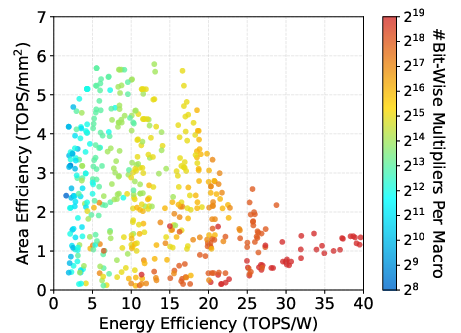
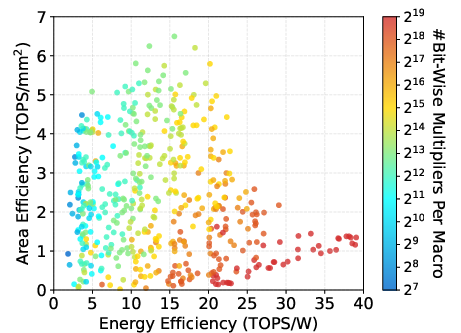
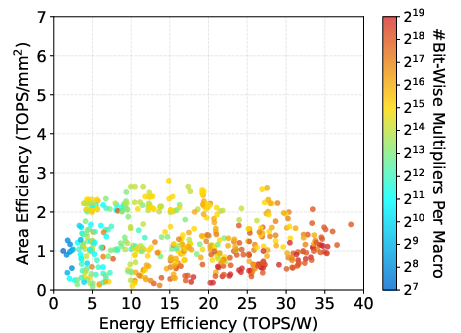
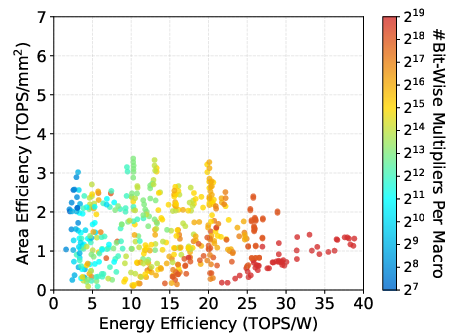
Figure 10: WS-Systolic dataflow energy/area efficiency plots demonstrating trade-offs across macro configurations.
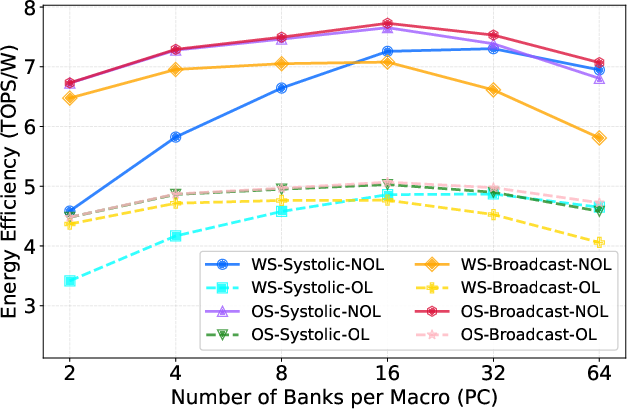
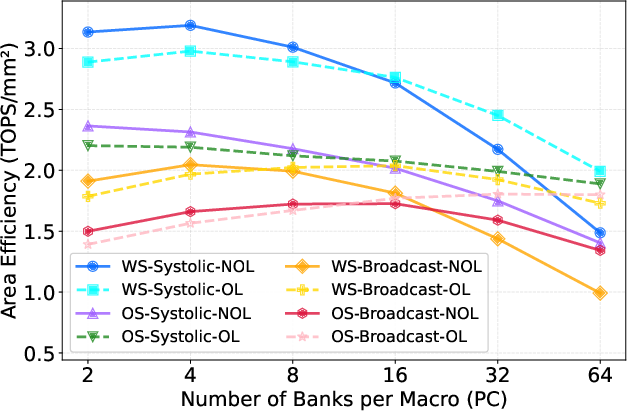
Figure 11: Impact of CIM macro supporting Compute-I/O overlap on energy and area efficiency.
Case Studies and Practical Implications
Case studies on LLM inference (Qwen3-0.6B, LLaMA-3-8B/70B, GPT-3-175B) reveal that optimal designs are highly context-dependent, varying by model structure, sequence length, and deployment constraints (edge vs. cloud). Edge deployments benefit from OS-Systolic-OL combined with moderate macro sizes, achieving minimized latency while maintaining reasonable area-power footprints. For large-scale processing (e.g., GPT-3 175B, long sequences), WS-Systolic-NOL becomes preferable due to lower per-core area and power, facilitating scalable multi-core arrays.
Notably, the optimal storage-compute ratio (LSL) is consistently low in compute-intensive settings, underscoring the primacy of computation density versus memory size. Macro-array co-design and fidelity in PPA evaluation are essential for achieving truly optimized CIM architecture—oversimplification in prior frameworks leads to sub-optimal hardware.
Theoretical and Practical Implications
The results of AccelCIM indicate several broader impacts:
- Physical-aware co-design is essential for SRAM CIM accelerator optimization, as architectural modeling alone fails to capture area, power, and frequency trade-offs.
- Dataflow choice (systolic vs. broadcast) strongly influences scalability; systolic architectures should be favored for large macro arrays due to locational routing constraints.
- Compute-I/O overlap must be selectively enabled based on bandwidth and macro size requirements, informed by empirical post-layout analysis.
- Optimization frameworks for DNN/HW co-design should integrate cycle-accurate simulation with post-layout evaluation to identify genuinely optimal Pareto points.
The adoption of AccelCIM's methodology facilitates efficient LLM inference on edge/cloud, informs DNN/hardware co-design strategies, and enables principled evaluations across full-stack accelerator design.
Conclusion
AccelCIM provides a systematic, physically accurate approach to SRAM CIM accelerator dataflow exploration. By simultaneously parameterizing macro and array-level configurations, enabling rigorous cycle-accurate and post-layout evaluation, it robustly reveals the impact of architectural and circuit-level trade-offs. The empirical results underscore the necessity of macro-array co-design and fidelity in PPA modeling, with systolic dataflow and medium macro sizing emerging as key factors for scalability and efficiency. Future developments will likely extend these insights to even larger model deployment, more sophisticated quantization/activation schemes, and heterogeneous memory architectures.