- The paper introduces a digital SRAM-based CIM macro with a novel LUT-based split softmax to accelerate self-attention while supporting INT8 quantization.
- The architecture leverages standard-cell synthesis for scalable design and flexible mapping across encoder, decoder, and encoder-decoder transformer models.
- Evaluation demonstrates a 33% latency reduction and energy efficiency up to 57.9 TOPS/W, optimizing performance for resource-constrained edge devices.
CIMple: Standard-cell SRAM-based CIM with LUT-based Split Softmax for Attention Acceleration
Overview and Motivation
The CIMple architecture addresses critical bottlenecks in deploying transformer-based LLMs on resource-constrained edge devices. As transformer models encapsulate large parameter sets and incur quadratic complexity in self-attention, data movement and nonlinear computations—particularly softmax—dominate energy and latency costs. Traditional Compute-in-Memory (CIM) schemes, especially analog variants, are limited in supporting both configurability and nonlinear operations, leading to a reliance on off-chip computation or separate processing cores for softmax, which undermines CIM’s inherent efficiency. CIMple introduces a fully digital, standard-cell SRAM-based CIM macro with a native LUT-based split softmax, providing efficient self-attention acceleration with support for INT8 quantization. Notably, CIMple's design leverages SRAM cells as standard cells, facilitating synthesis in current digital flows and easy porting to newer technology nodes.
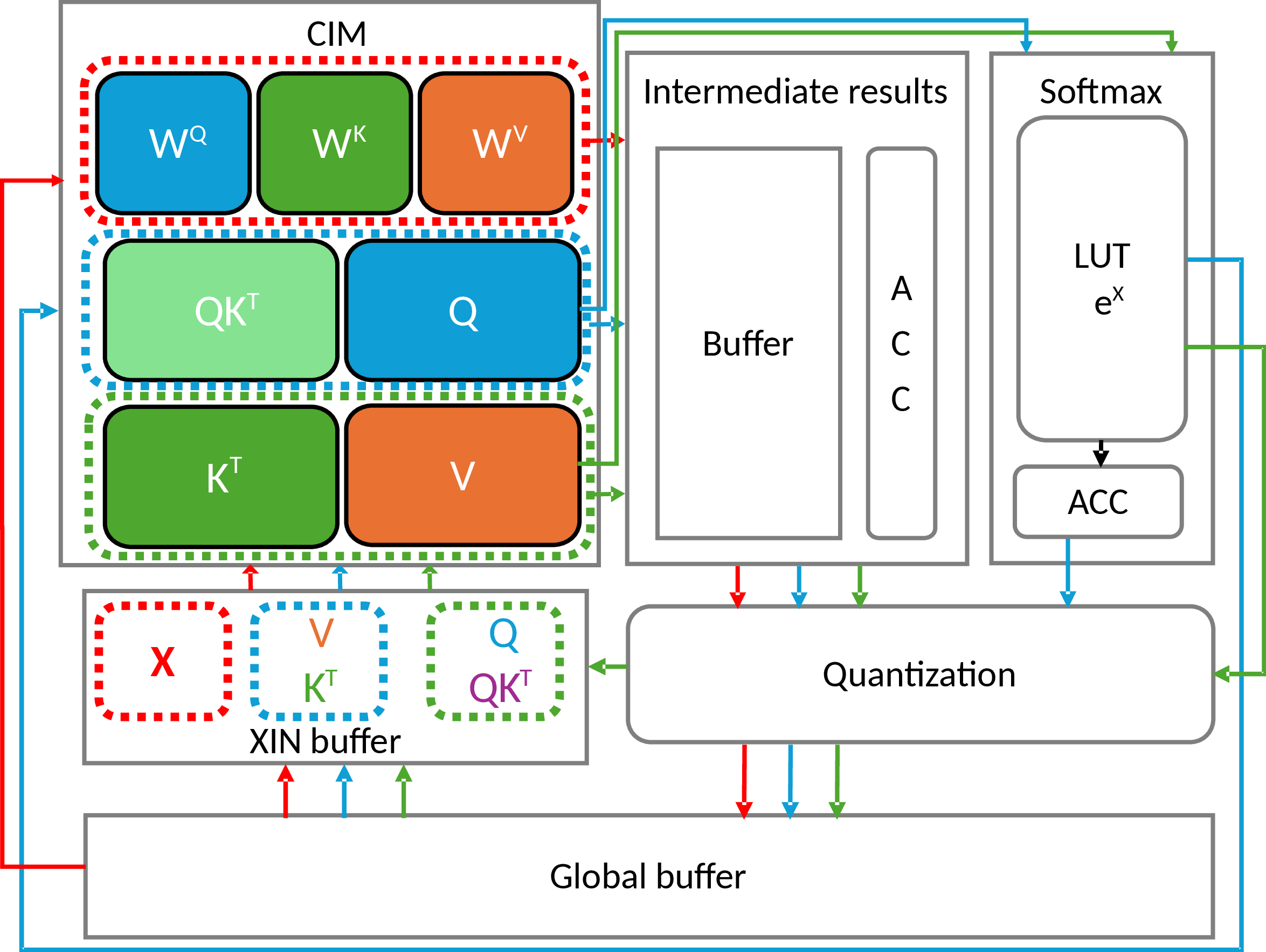
Figure 1: High-level view of the CIMple accelerator, highlighting the CIM core, LUT for softmax, quantization unit, intermediate and global buffers, and computation flow for diverse transformer mapping.
Architectural Innovations
CIMple’s core includes a dual-banked CIM macro (32kb), supporting 8-bit parallel weight feeding and efficient MAC operations. The design features an intermediate buffer, quantization unit narrowing from 32b to 8b, and tightly-coupled LUTs implementing a split fixed-point softmax function. The CIM uses 8-T SRAM bitcells with OAIs as both multipliers and selectors, yielding lower signaling overhead and allowing macro creation with high density and scalable placement.
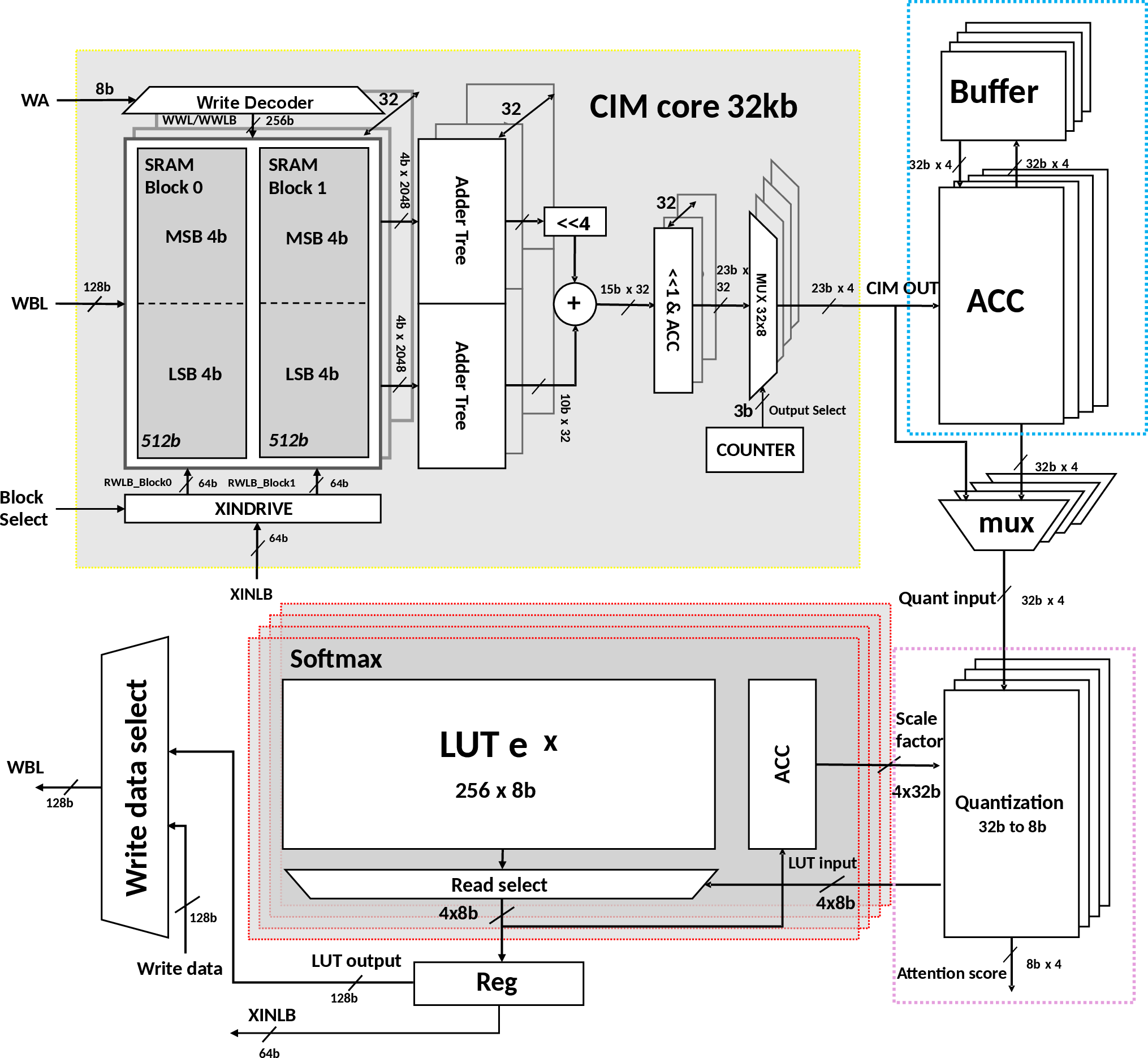
Figure 2: CIMple’s architecture with CIM core, buffer, quantization, and softmax LUT modules. The macro contains 32 partitions enabling scalability and parallelism.
The split softmax implementation approximates numerator and denominator calculations using one-dimensional full-precision LUTs, enabling pipelined activation-to-activation computation. This approach mitigates latency and eliminates floating-point datatype conversions inherent to traditional softmax computation. Local storage of Q and V in SRAM, streaming KT as input, and quantized matrix operations minimize memory accesses and intermediate data movement.
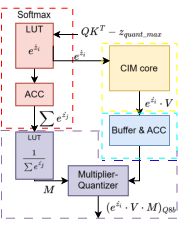
Figure 3: Diagram of the LUT-based split softmax, illustrating the separation of numerator and denominator computation, quantization, and integration with the CIM macro.
SRAM cells are synthesized as standard cells, facilitating a fully digital flow (RTL-to-GDSII) and enabling high area efficiency through distributed placement/routing. This removes manual macro layout and allows rapid porting to smaller nodes.
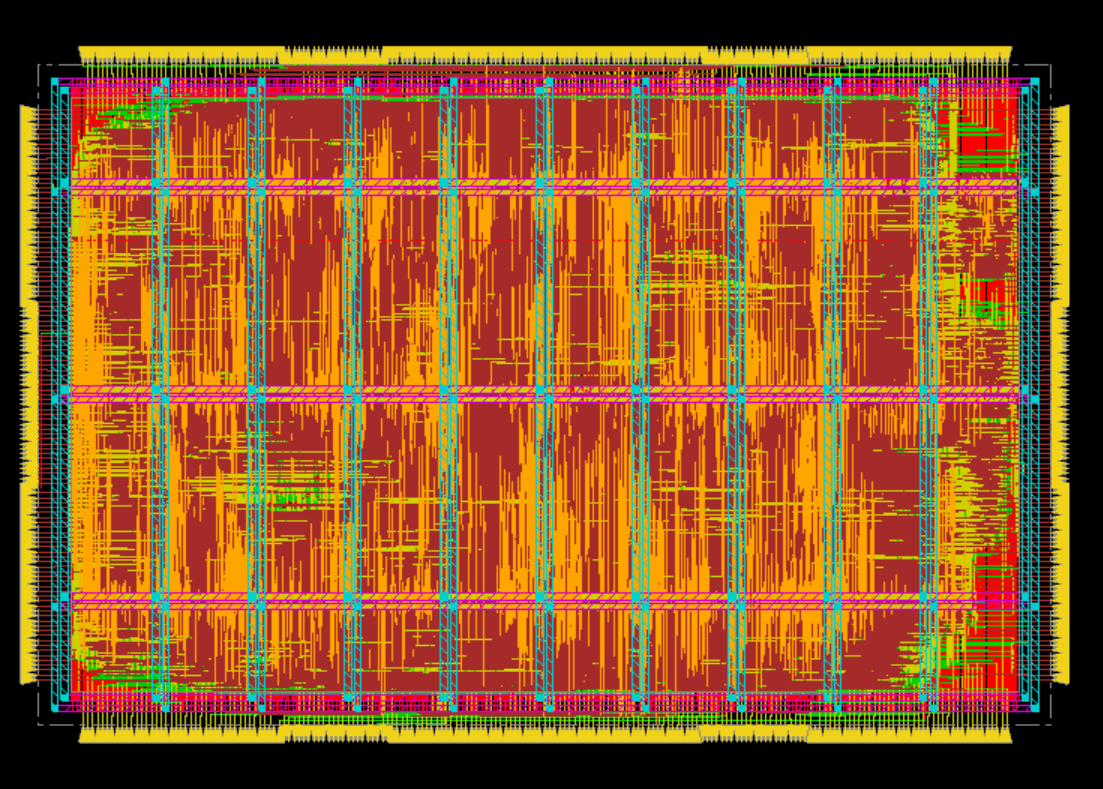
Figure 4: Physical layout of the CIMple accelerator, demonstrating distributed SRAM cell integration as standard cells in 28nm FD-SOI.
CIMple natively supports encoder-only, decoder-only, and encoder-decoder transformer mappings. Encoder-only computation exploits parallel token processing, buffering Q and V in local SRAM during attention scoring. Decoder-only computation handles autoregressive token inference, using intermediate cache for K and V, and sequential input tokens in the attention loop. Encoder-decoder models are accommodated via tiled buffer structures and repeated attention layers, with selective read/write paths in CIM and input buffers.
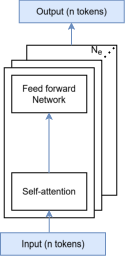
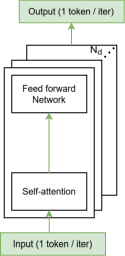
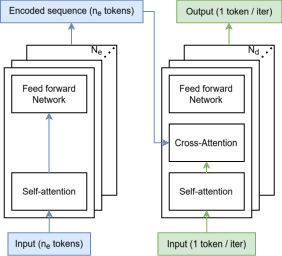
Figure 5: High-level schematic of transformer types—encoder-only, decoder-only, encoder-decoder—indicating parallel sequences and token mapping.
Numerical Results and Evaluation
CIMple achieves a peak energy efficiency of 26.1 TOPS/W at 0.85V and 417MHz, with area efficiency of 2.31 TOPS/mm2 at 1.2V and 770MHz (post-synthesis/layout). Excluding the global buffer, energy efficiency reaches 57.9 TOPS/W and area efficiency 2.71 TOPS/mm2. Power analysis indicates the CIM core consumes 94.7% of energy, predominantly in the adder tree, whereas the softmax LUT incurs minimal overhead (0.34%).
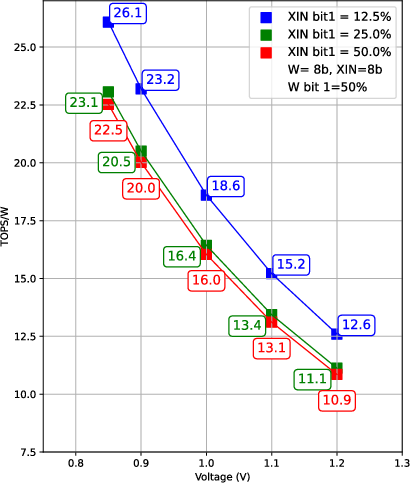
Figure 6: Energy efficiency (TOPS/W) versus activation sparsity and voltage scaling, demonstrating CIMple's benefits from sparse matrix operations with optimal voltage at 0.85V.
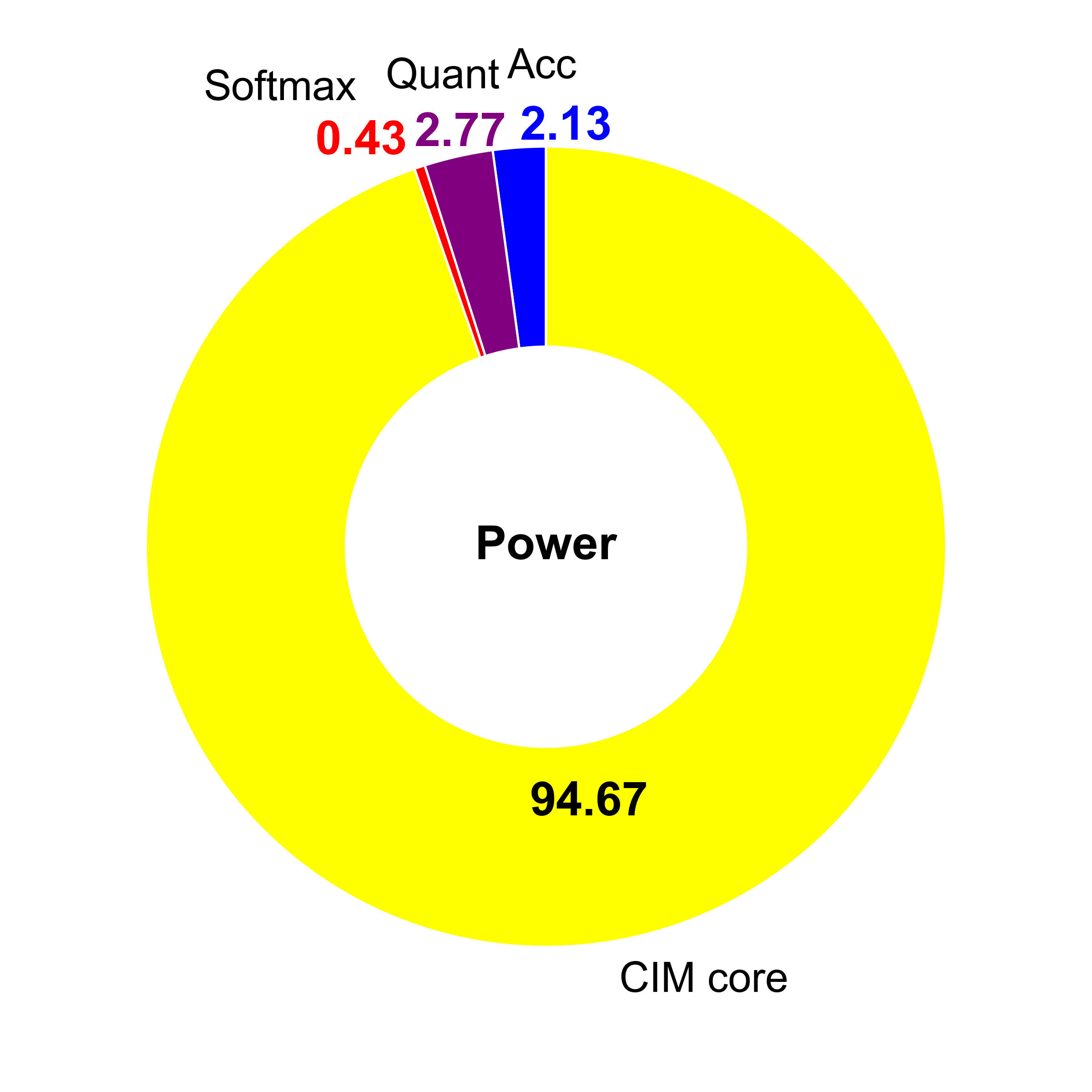
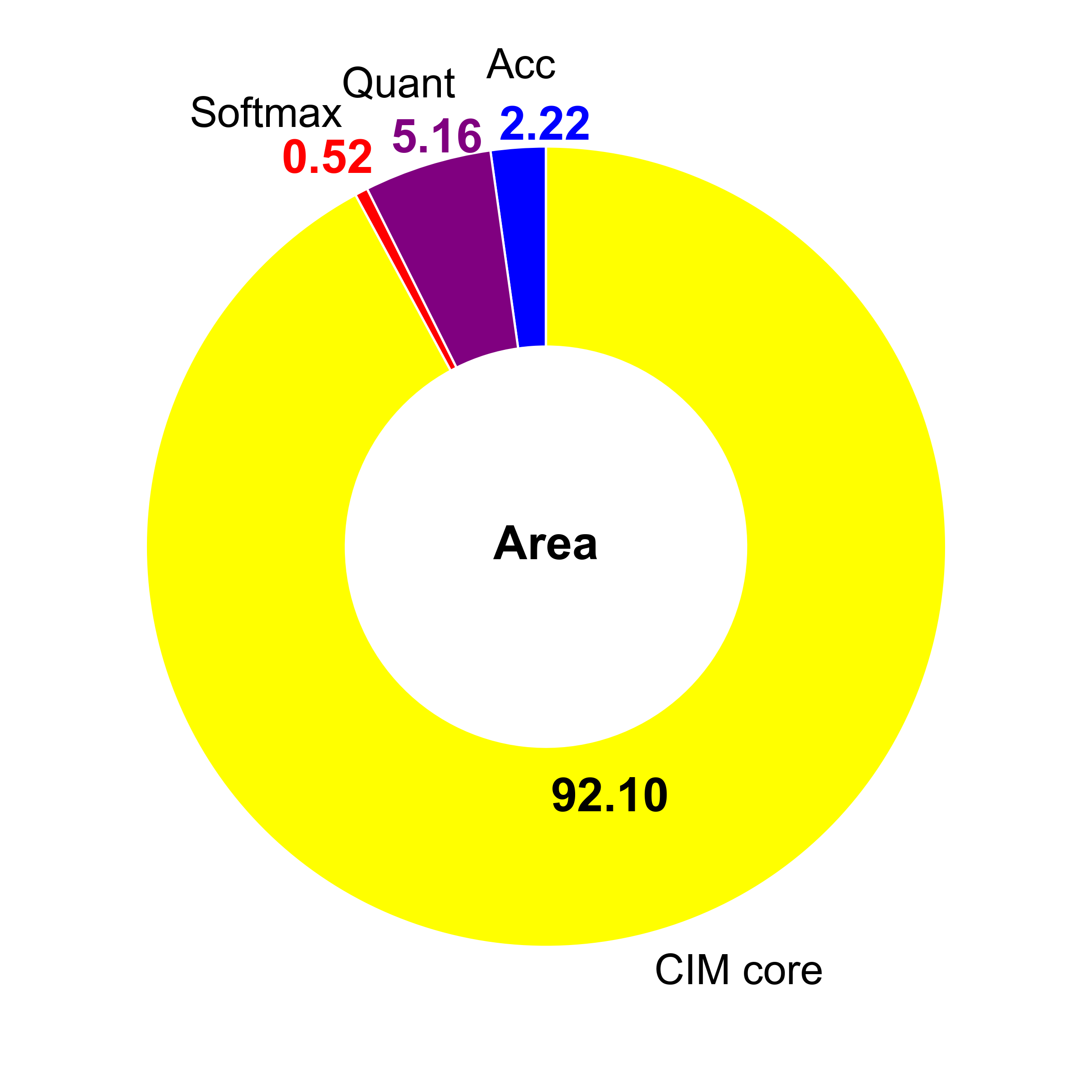
Figure 7: Power consumption and area breakdown of the CIMple accelerator, highlighting dominant contribution from the CIM core and SRAM bitcells.
Compared to contemporaneous CIM transformer accelerators, CIMple outperforms in area efficiency and offers robust configurability across transformer variants. While not achieving the maximum energy efficiency of sparse/exploiting designs (e.g., MultCIM, which leverages aggressive pruning techniques impacting accuracy), the CIMple architecture maintains accuracy and flexibility.
Latency and Accuracy Impacts of Split Softmax
The LUT-based split softmax yields a 33% reduction in activation-to-activation latency, enabled by earlier pipelining and avoidance of datatype conversions and three-pass input traversal characteristic of conventional softmax. Accuracy evaluation on a quantized TinyLlama transformer model (INT8) using the lm-evaluation-harness framework demonstrates minimal performance loss (≤0.6% across several tasks), with some tasks even exhibiting marginal improvement attributable to numerical stability enhancements in LUT-based softmax.
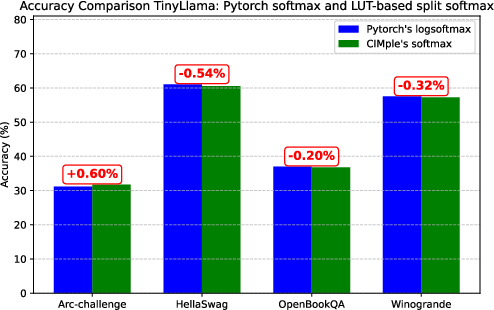
Figure 8: Accuracy comparison between baseline PyTorch LogSoftmax and CIMple’s LUT-based split softmax on language tasks, quantized to INT8.
CIMple’s full-precision LUTs ensure that observed accuracy drops originate strictly from the softmax approximation, not quantization error or architecture-induced mismatch.
Practical and Theoretical Implications
CIMple advances CIM-based transformer acceleration through:
- Enabling fully digital, configurable self-attention acceleration for INT8 transformers;
- Integrating nonlinear softmax within CIM, eliminating off-core computation and data movement;
- Achieving significant energy and area efficiency gains in a scalable, synthesis-friendly architecture;
- Providing robust mapping flexibility across transformer variants.
This positions CIMple as a practical solution for transferring transformer capabilities to edge devices with stringent compute, power, and area constraints. The theoretical implication is the feasibility of efficient, pipelined nonlinear computation in digital CIM, challenging the canonical requirement for analog computation or external processing units.
Future Directions
Further development should target end-to-end dataflow optimizations in full transformer pipelines, extending acceleration beyond self-attention to feedforward and token-generation modules. Enhanced accuracy may be achievable via application-specific LUT tuning and retraining. External memory access remains an energy bottleneck for large LLM inference; future work must optimize on-chip-external memory mapping to minimize data movement and maximize weight reuse.
Conclusion
CIMple demonstrates a standard-cell SRAM-based CIM architecture with integrated LUT-based split softmax, offering configurable, efficient acceleration for transformer self-attention layers on resource-constrained platforms. Its innovations facilitate area, energy, and latency gains without sacrificing accuracy or configurability, and its modular, digital flow enables rapid porting and scalability. CIMple stands as an instructive blueprint for future CIM-based AI accelerators, and its principles extend to broader classes of nonlinear neural computations.