- The paper introduces a dual-system architecture combining discrete macro-intents with continuous fine actions to bridge semantic reasoning and precise manipulation.
- It achieves a Libra Point at 10 coarse bins, balancing learning complexity and optimizing performance across simulation and real-world tasks.
- Empirical results on LIBERO benchmarks and AgiBot G1 validate superior accuracy (97.2% success) and robustness under perturbations.
Libra-VLA: Learning Equilibrium via Asynchronous Coarse-to-Fine Dual-System
Motivation and Action Generation Paradigms
Libra-VLA addresses the fundamental challenge of bridging semantic reasoning and precise actuation in Vision-Language-Action (VLA) models for generalist robotic manipulation. Conventional VLA strategies either discretize the action space into massive bins (Fig. 1a), leading to flat autoregressive generation that overloads the representational capacity, or adopt continuous diffusion (Fig. 1b) to directly synthesize motor signals but still require semantic grounding. Libra-VLA refines this conceptual landscape by proposing a hybrid action space (Fig. 1c): discrete coarse bins anchor macro-intents for semantic guidance, while continuous fine actions serve geometric precision, conforming to the intrinsic hierarchy of manipulation tasks.
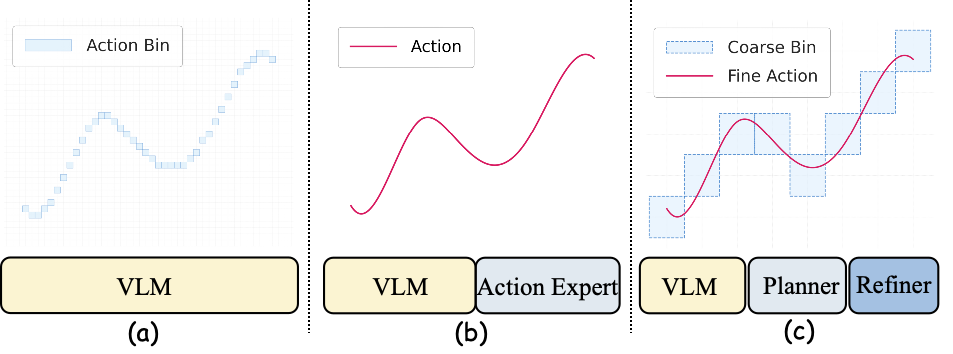
Figure 1: Paradigms for action generation: discrete bins, continuous diffusion, and Libra-VLA's hybrid coarse-to-fine structure.
Dual-System Architecture and Hierarchical Policy Decomposition
Libra-VLA introduces a modular dual-system architecture to distribute learning complexity. System 2 (Semantic Planner) employs a vision-language backbone (InternVL2.5-2B) with a Parallel Coarse-Action Head to predict discrete macro-directional tokens at low frequency. These coarse tokens are semantically aligned and serve as anchors for subsequent fine motor command synthesis. System 1 (Action Refiner) leverages a diffusion transformer and an independent high-resolution visual encoder (SigLIP) to conditionally generate continuous micro-pose alignments at high frequency, guided by the intent buffer. The asynchronous execution protocol amortizes expensive VLM computation across multiple steps, enabling real-time responsiveness with planning horizon expansion regulated by factor M.
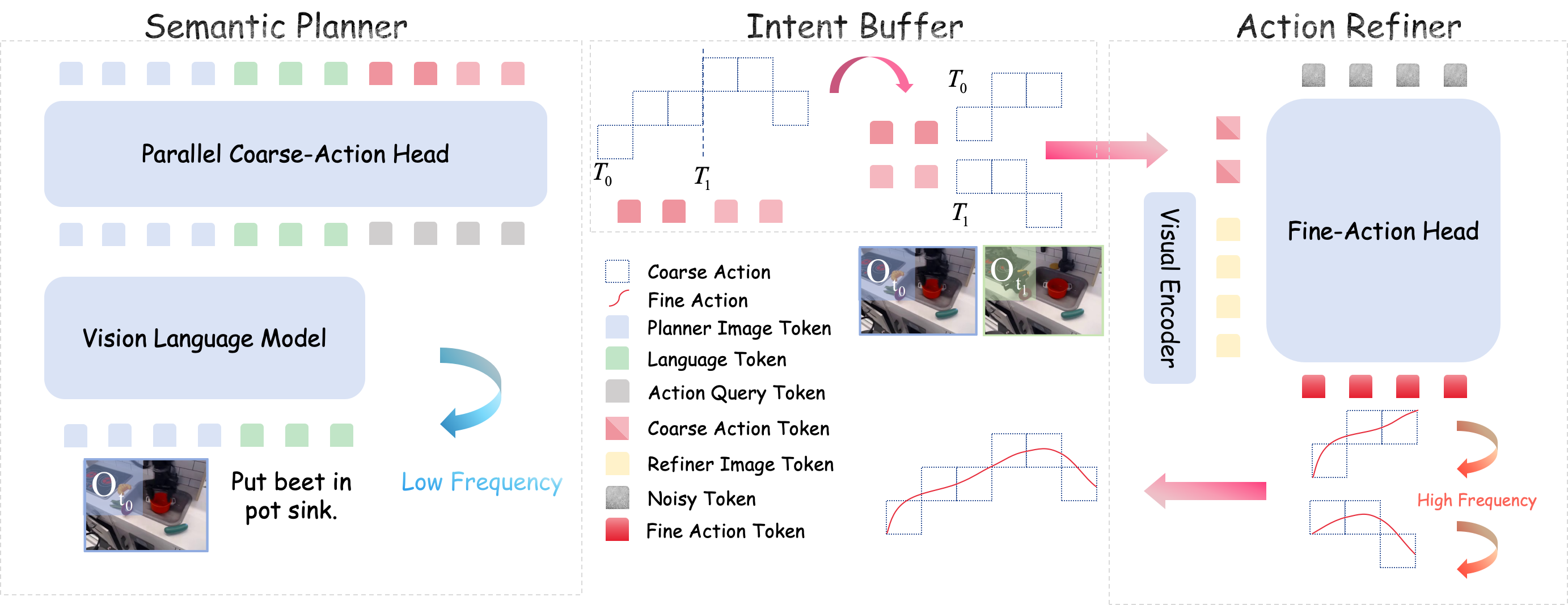
Figure 2: Libra-VLA architecture with decoupled Semantic Planner and Action Refiner bridged via asynchronous intent buffering.
Learning Complexity Equipartition and Granularity Equilibrium
A pivotal insight is the emergence of an inverted-U performance curve with respect to coarse action bin granularity N (Fig. 3). Excessively low N yields underinformative anchors, overburdening the Action Refiner. Large N renders macro-intent prediction intractable, causing cascading errors from planner to refiner. Empirically, the optimal equilibrium ("Libra Point") is found at N=10, where macro-intents are sufficiently expressive for geometric constraint without imposing excessive abstraction complexity.
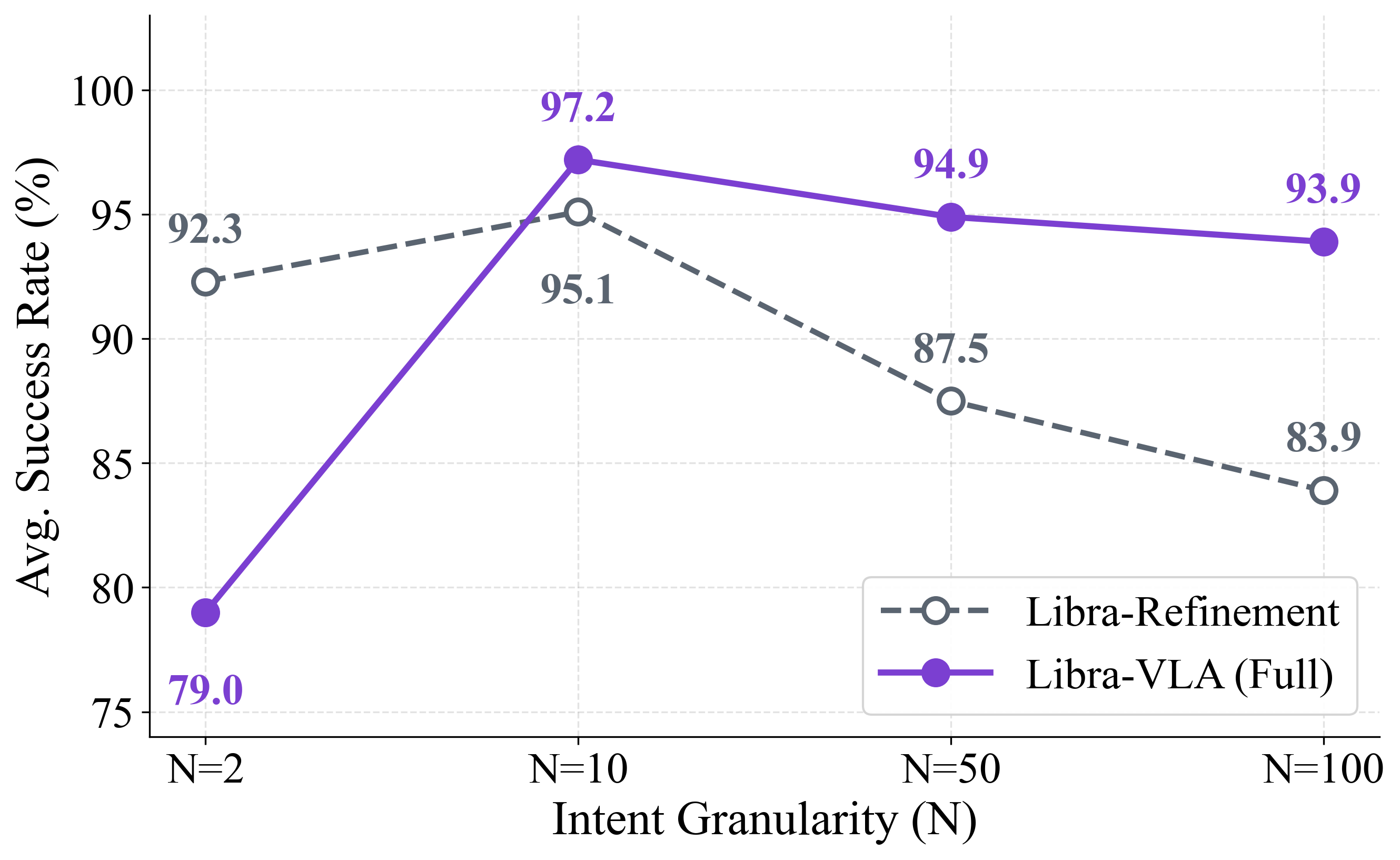
Figure 3: Inverted-U performance versus coarse bin size N, with equilibrium at N=10 for balanced learning.
LIBERO Benchmark
Libra-VLA achieves a state-of-the-art average success rate of 97.2% on LIBERO, surpassing both discrete and continuous action baselines, with dominant performance on object-centric precision and long-horizon planning suites. The architecture demonstrates robust macro-guidance and geometric fidelity, validating the coarse-to-fine paradigm.
LIBERO-Plus Robustness
On the LIBERO-Plus suite, which evaluates resilience to controlled real-world perturbations (camera, lighting, backgrounds, initial states, language variation, etc.), Libra-VLA attains superior robustness. Under zero-shot transfer, the model records 79.5% average success; with supervised finetuning, this increases to 82.3%, outperforming relevant baselines in nearly every perturbation category.
Ablation and Convergence Analysis
Ablation studies reveal that simply adding a visual encoder (Libra-VE) does not improve over monolithic baselines. Performance gains manifest only through hierarchical refinement and structural decoupling. Loss curves (Fig. 4, Fig. 5) corroborate faster convergence and lower continuous-action MSE in Libra-VLA, and intermediate rollout success rates show significant advantages at early training stages.
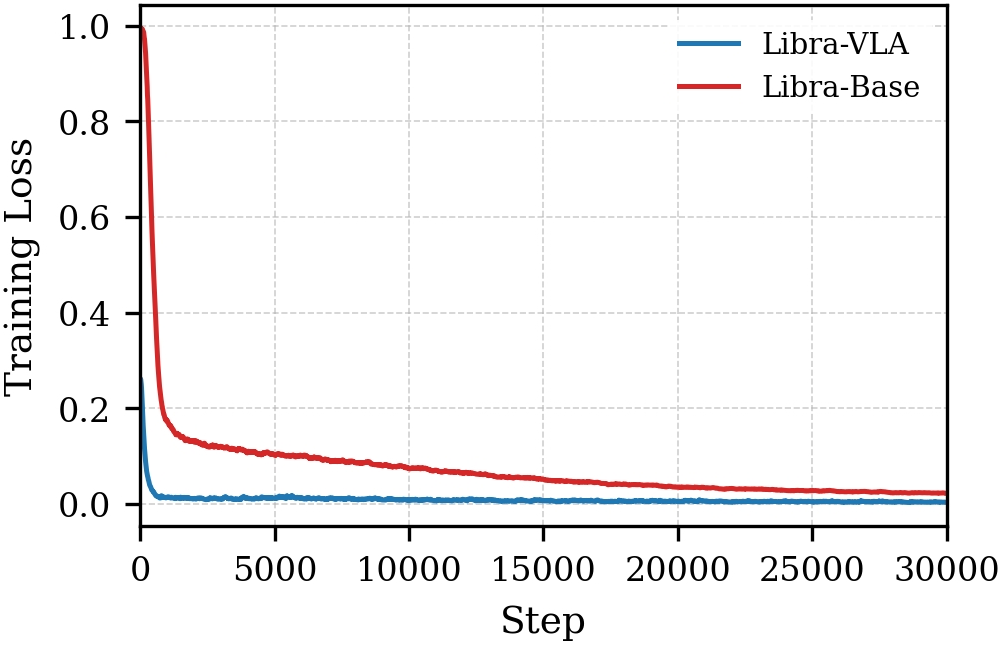
Figure 4: Training loss curves of Libra-VLA and Libra-Base models on LIBERO benchmark.
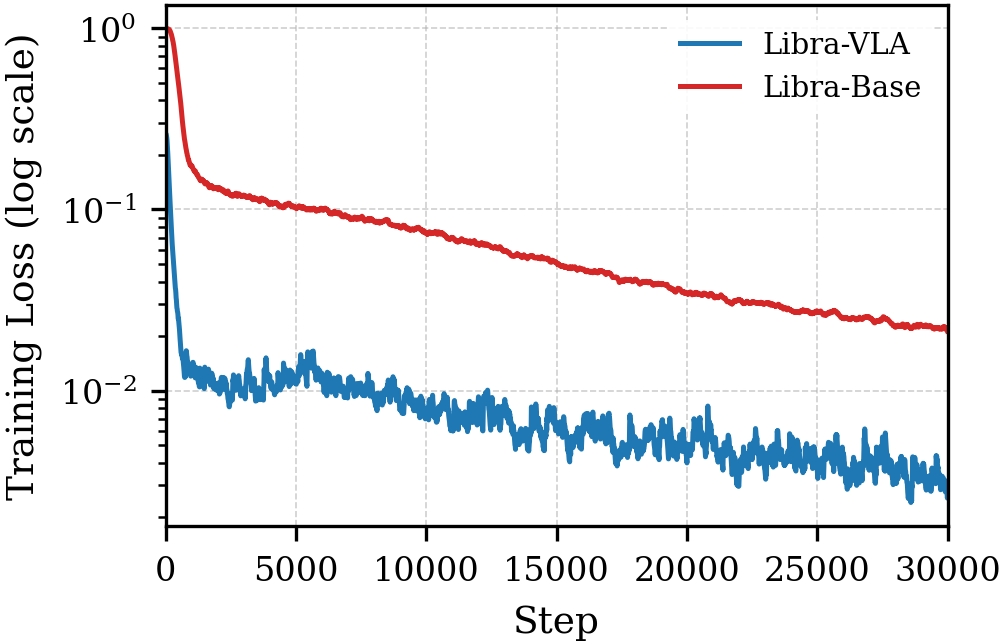
Figure 5: Log-scale visualization of training loss curves, highlighting rapid convergence of Libra-VLA.
Real-World Manipulation
Libra-VLA is validated on AgiBot G1 platform for long-horizon, spatially coherent tasks: "Wipe Stain", "Pour Water", and "Make Sandwich". The architecture achieves high single-task and average success rates across all tasks, demonstrating practical robustness and adaptability in physical settings.
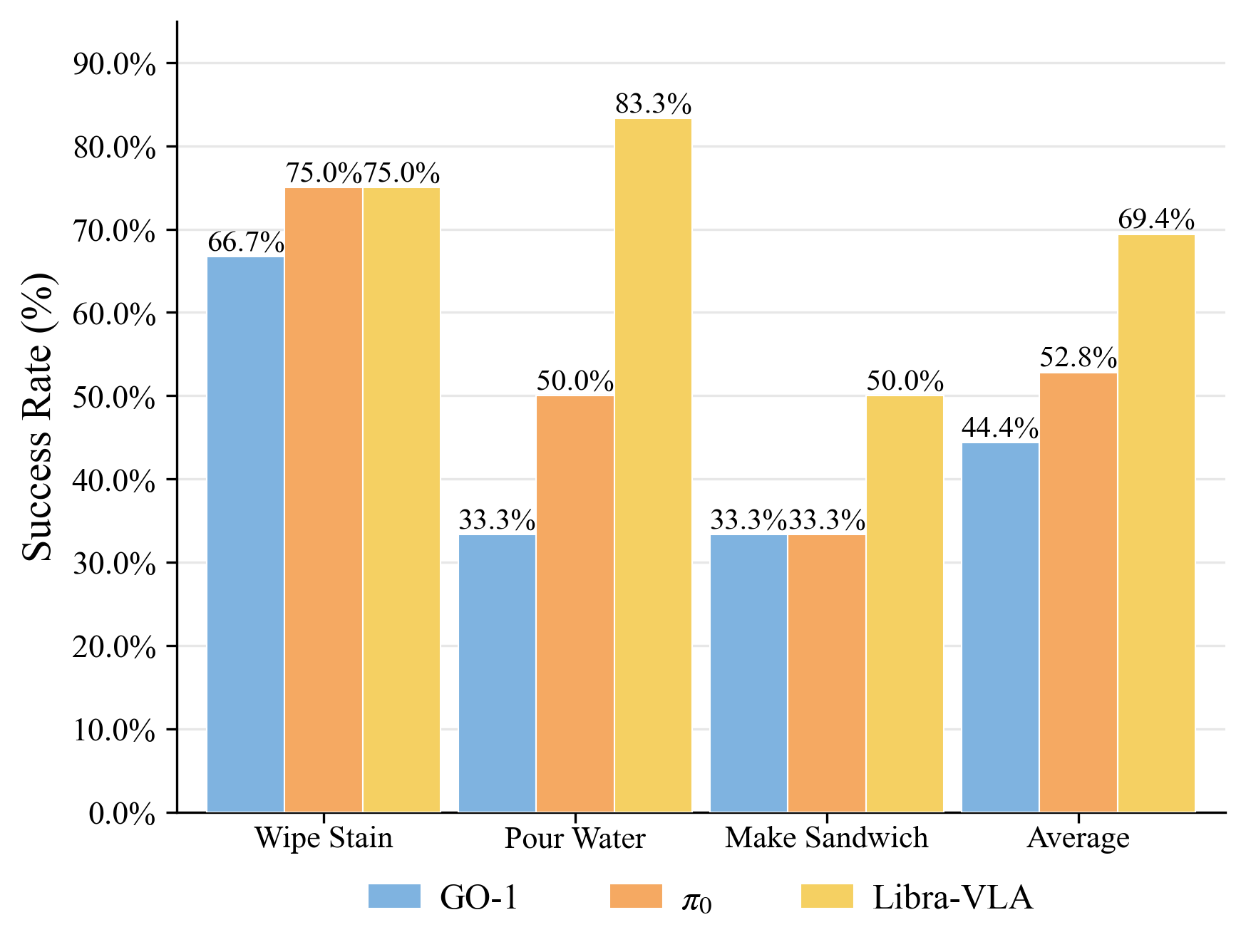
Figure 6: Real-world experiment results for Libra-VLA versus state-of-the-art baselines.

Figure 7: Visual illustrations of real-world tasks executed by Libra-VLA.
Theoretical and Practical Implications
Libra-VLA's coarse-to-fine hierarchical decoupling formalizes the learning complexity equipartition principle for mixed-modality policies. The explicit bridging via macro-intents reduces the representational burden on VLMs, yielding interpretable intra-modal communication and favorable optimization dynamics. Asynchronous execution further advances latency and real-time feasibility, critical for open-world manipulation. The methodology introduces a transparent information flow, sidestepping the opacity of latent-vector protocols that dominate prior dual-system architectures.
Practically, Libra-VLA sets new performance standards for generalist manipulation under distributional shifts and perturbations, extending the scalability and reliability of VLA pipelines. The structure generalizes to diverse robot platforms and tasks, with minimal dependence on large-scale robot-data pretraining.
Limitations and Future Directions
Performance marginally attenuates as asynchronous update frequency increases, highlighting the necessity for dynamic intent verification and real-time confidence estimation. Integrating such mechanisms will further enhance adaptability, especially under prolonged open-loop execution or in safety-critical environments. Extending the hierarchy to multi-level temporal abstraction, and incorporating explicit spatial or relational reasoning in planner-refiner interactions, could augment expressiveness and robustness. Bias inheritance from VLM pretraining and privacy considerations require careful mitigation as deployment expands to unconstrained domains.
Conclusion
Libra-VLA advances hierarchical VLA modeling by decomposing manipulation into interpretable macro- and micro-control, optimizing learning equilibrium via the hybrid action space. The dual-system asynchronous protocol delivers state-of-the-art accuracy, robustness, and efficiency in both simulation and real-world benchmarks, offering a scalable foundation for generalist embodied AI in open environments (2604.24921).