- The paper introduces a diffusion-based VLA model that leverages masked diffusion to generate structured robotic action sequences beyond the sequential limits of autoregressive models.
- It employs localized special-token classification and hierarchical decoding to boost training efficiency and accuracy, achieving 55.5% success on SimplerEnv and 58% on real-world tasks.
- Experimental evaluations on simulated and real-world benchmarks demonstrate that LLaDA-VLA significantly outperforms prior VLA baselines, setting new standards in robotic policy learning.
LLaDA-VLA: Vision-Language Diffusion Action Models
Introduction and Motivation
LLaDA-VLA introduces a novel paradigm for robotic policy learning by leveraging masked diffusion models (MDMs) in the vision-language-action (VLA) domain. Traditional VLA models predominantly utilize autoregressive models (ARMs), which generate action sequences token-by-token in a unidirectional manner. This sequential generation constrains efficiency and flexibility, particularly in complex multimodal robotic tasks. In contrast, MDMs enable parallel and iterative refinement of predictions, offering potential advantages in structured sequence generation. However, adapting diffusion-based vision-LLMs (d-VLMs) to robotic manipulation presents unique challenges, including a substantial domain gap and the need to model hierarchical dependencies in action sequences.
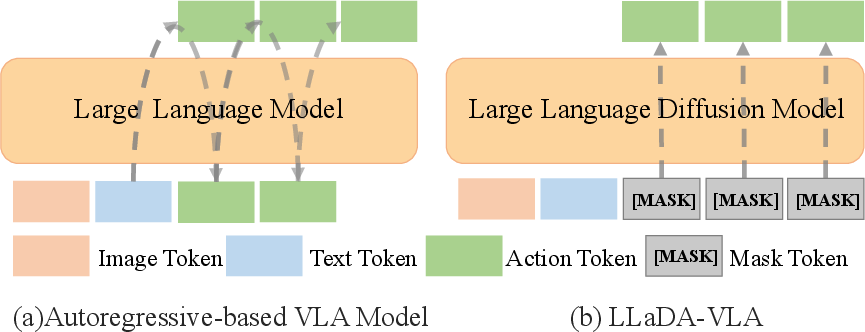
Figure 1: Comparison between Autoregressive-based VLA Model and LLaDA-VLA, highlighting the parallel and iterative decoding advantages of the diffusion-based approach.
Model Architecture and Key Innovations
LLaDA-VLA is constructed atop a pretrained d-VLM backbone (LLaDA), a vision encoder (SigLIP-2), and a projection module. The model ingests a language instruction and a front-view RGB image, extracting visual features and projecting them into the text token space. These concatenated tokens, along with masked tokens, are processed by the diffusion model to generate action sequences.
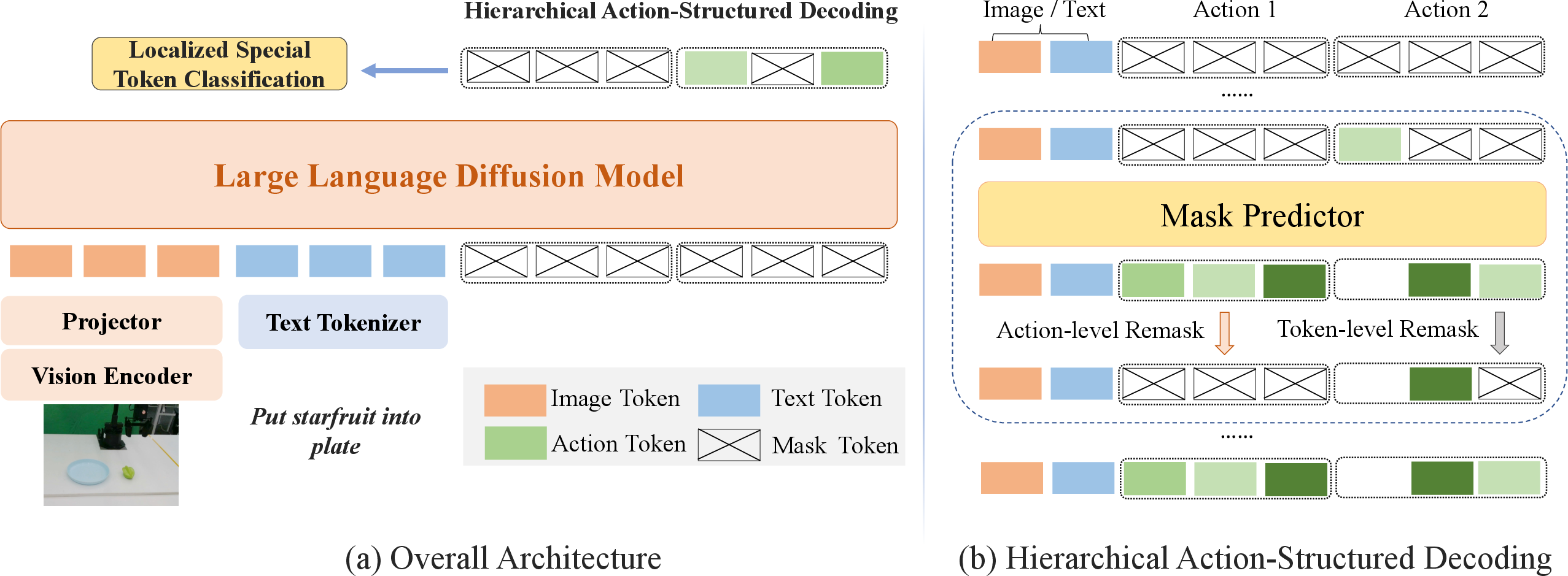
Figure 2: Overview of LLaDA-VLA architecture and the hierarchical action-structured decoding strategy for generating coherent action sequences.
Localized Special-Token Classification
A central innovation is the localized special-token classification strategy. Instead of classifying over the entire vocabulary, the model restricts prediction to a set of special action tokens representing discretized robot actions. This reduces adaptation difficulty and focuses learning on action-relevant tokens, improving both training efficiency and action generation accuracy. During training, only masked positions corresponding to action tokens are considered in the loss, and inference is performed exclusively over the special token subset.
Hierarchical Action-Structured Decoding
The second key contribution is the hierarchical action-structured decoding strategy. Standard diffusion decoding treats all tokens equally, neglecting the structured dependencies inherent in action sequences. LLaDA-VLA introduces a two-level hierarchy: first, actions within a chunk are ranked by aggregated confidence scores, and the most confident action is selected for partial preservation. Within this action, tokens are further ranked by confidence, and only high-confidence tokens are retained. This iterative, hierarchical remasking and prediction process ensures that both intra-action and inter-action dependencies are respected, resulting in more coherent and plausible action trajectories.
Experimental Results
LLaDA-VLA is evaluated on SimplerEnv, CALVIN, and real-world WidowX robot benchmarks. The model demonstrates state-of-the-art performance across all settings, with notable improvements over ARM-based and prior diffusion-based VLA baselines.
- On SimplerEnv, LLaDA-VLA achieves a 55.5% average success rate, outperforming OpenVLA by 50.9% and CogACT by 4.2 points.
- On CALVIN, LLaDA-VLA attains an average episode length of 4.01, a 0.74 improvement over OpenVLA, and superior success rates compared to GR1 and RoboFlamingo.
- On real-world tasks, LLaDA-VLA achieves a 58% average success rate, surpassing π0 and CogACT by 23% and 28%, respectively.
Ablation studies confirm the effectiveness of both the localized special-token classification and hierarchical decoding strategies, with each contributing substantial gains in episode length and success rate. The action chunk size is shown to impact performance, with moderate chunk sizes yielding optimal results.
Qualitative Analysis
LLaDA-VLA exhibits robust performance in both simulation and real-world environments. In CALVIN, the model successfully completes long-horizon, multi-step manipulation tasks.
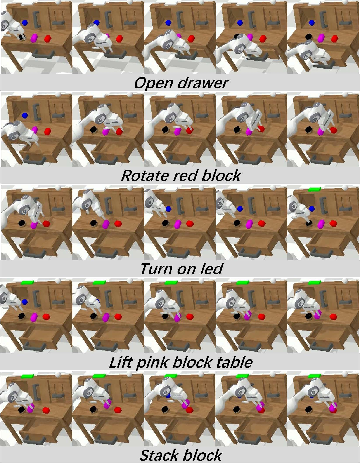
Figure 3: Qualitative results of LLaDA-VLA on CALVIN tasks, demonstrating successful multi-step manipulation.
In SimplerEnv, LLaDA-VLA reliably localizes and manipulates target objects.

Figure 4: Qualitative results of LLaDA-VLA on SimplerEnv tasks, showing precise object-level manipulation.
On real-world in-domain tasks, the robot executes actions with high reliability.

Figure 5: Qualitative results of LLaDA-VLA on real-world in-domain tasks, illustrating robust execution of seen tasks.
For out-of-domain generalization, LLaDA-VLA demonstrates the ability to manipulate unseen objects and containers, even in the presence of distractors.

Figure 6: Qualitative results of LLaDA-VLA on real-world out-of-domain tasks, highlighting generalization to novel scenarios.
Implications and Future Directions
The results establish diffusion-based VLA models as a viable and competitive alternative to autoregressive approaches for robotic manipulation. The localized special-token classification and hierarchical decoding strategies are critical for bridging the domain gap and modeling structured action dependencies. Practically, LLaDA-VLA enables more efficient and accurate policy learning, with strong generalization to unseen tasks and environments.
Theoretically, this work suggests that discrete diffusion models can be effectively adapted to structured sequence generation beyond language, with implications for other domains requiring hierarchical output modeling. Future research may explore scaling d-VLMs with larger datasets, integrating continuous control spaces, and extending hierarchical decoding to more complex action representations. Additionally, the parallel decoding capabilities of diffusion models may facilitate real-time deployment in robotics, especially when combined with hardware acceleration and adaptive caching strategies.
Conclusion
LLaDA-VLA represents a significant advancement in vision-language-action modeling for robotics, demonstrating that masked diffusion models, when equipped with localized classification and hierarchical decoding, can outperform autoregressive baselines in both simulation and real-world settings. The approach provides a robust foundation for further exploration of diffusion-based models in structured action generation and generalist robotic policy learning.