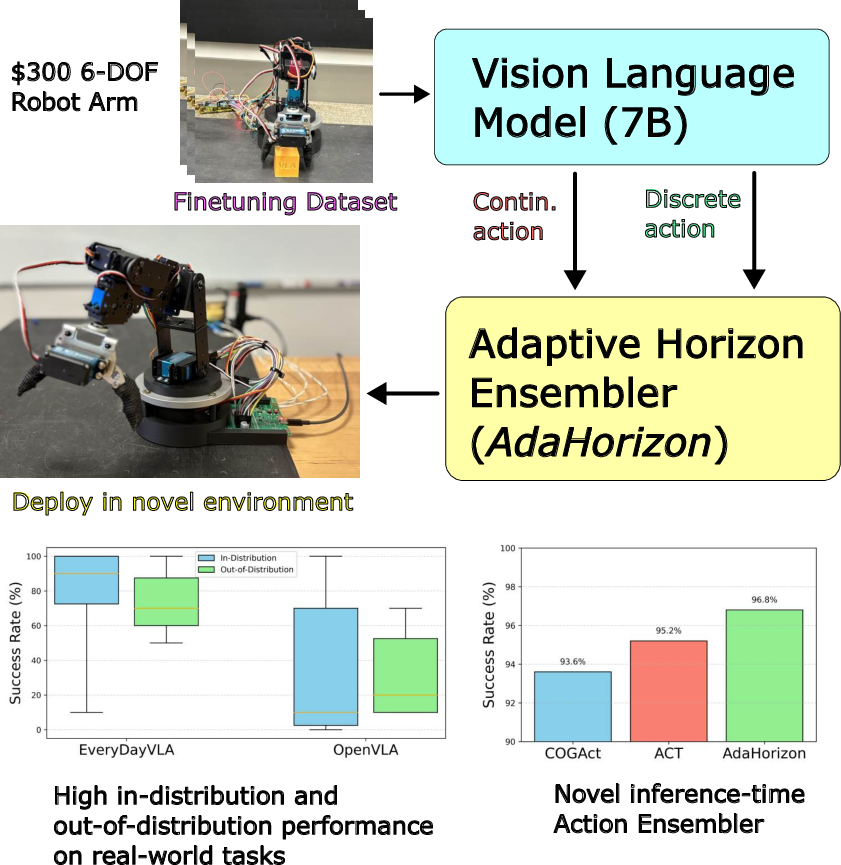
EveryDayVLA: A Vision-Language-Action Model for Affordable Robotic Manipulation
Abstract: While Vision-Language-Action (VLA) models map visual inputs and language instructions directly to robot actions, they often rely on costly hardware and struggle in novel or cluttered scenes. We introduce EverydayVLA, a 6-DOF manipulator that can be assembled for under $300, capable of modest payloads and workspace. A single unified model jointly outputs discrete and continuous actions, and our adaptive-horizon ensemble monitors motion uncertainty to trigger on-the-fly re-planning for safe, reliable operation. On LIBERO, EverydayVLA matches state-of-the-art success rates, and in real-world tests it outperforms prior methods by 49% in-distribution and 34.9% out-of-distribution. By combining a state-of-the-art VLA with cost-effective hardware, EverydayVLA democratizes access to a robotic foundation model and paves the way for economical use in homes and research labs alike. Experiment videos and details: https://everydayvla.github.io/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces EverydayVLA, a low-cost robot arm and a smart control system that lets the robot understand a camera image and a written instruction, then move to do tasks like picking up and placing objects. The key idea is to make powerful “see–read–act” robot technology more affordable and reliable, so more people can use it at home, in schools, and in research labs.
What the researchers wanted to achieve
The paper has three main goals:
- Build a capable robot arm you can assemble for around $300, instead of thousands of dollars.
- Create a single brain (a model) that looks at an image, reads a short instruction, and outputs the robot’s movements both as smooth motions and as step-by-step commands.
- Make the robot safer and more dependable by checking its own confidence during motion and quickly replanning if things look uncertain or risky.
How they did it (in simple terms)
Think of the robot as a student following instructions while watching a video of the scene.
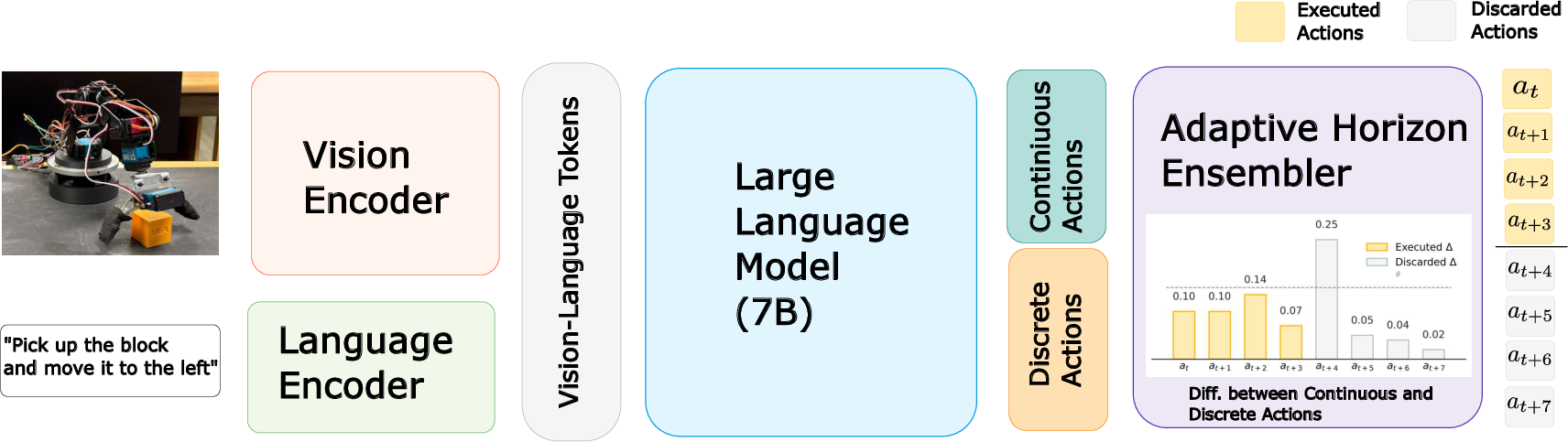
- The “Vision–Language–Action” model is the student’s brain. It looks at a camera image, reads the instruction (like “pick up the ball and place it to the left”), and decides what the robot’s “hand” should do next.
- Two ways of giving the robot moves:
- Discrete actions: like following a recipe step-by-step (“move forward 1 cm,” “turn 10 degrees,” “open gripper”). These are token-like, short instructions.
- Continuous actions: like drawing a smooth line to the target (“glide here while turning gradually”).
- Action chunks: instead of deciding one tiny move at a time, the model plans a small bundle of moves at once. This is faster, like writing down several steps before acting, rather than pausing after every single step.
- Adaptive Horizon (AdaHorizon): the robot watches how much its “step-by-step plan” and its “smooth plan” agree with each other. If the two disagree a lot, that’s a sign of uncertainty—maybe there’s clutter, a new object, or a person moving around. When that happens, the robot shortens the bundle of planned moves and replans sooner, which helps avoid mistakes and keeps things safe.
- Training the brain:
- The model uses a large vision-language backbone (Prismatic + Llama 2) so it understands both pictures and words.
- It’s trained to produce both discrete actions (using a “pick-the-right-token” loss) and continuous actions (using an L1 loss, which just means “make your predicted numbers close to the ground-truth numbers”).
- They collected their own dataset: 1,200 examples where a person controlled the robot (teleoperation), recording the camera video, the written instruction, and the robot hand’s positions. This teaches the model how to imitate good behavior.
- The hardware:
- A 6-DOF (Degrees of Freedom) arm—think six joints that can move to position and orient the robot’s hand.
- Built from off‑the‑shelf parts: hobby servo motors, a simple Arduino Uno, and a bit servo driver board. It reaches 38.2 cm from the base to the wrist, lifts up to 0.2 kg, and repeats positions within about 10 mm—that’s decent for everyday tasks at low cost.
Main findings and why they matter
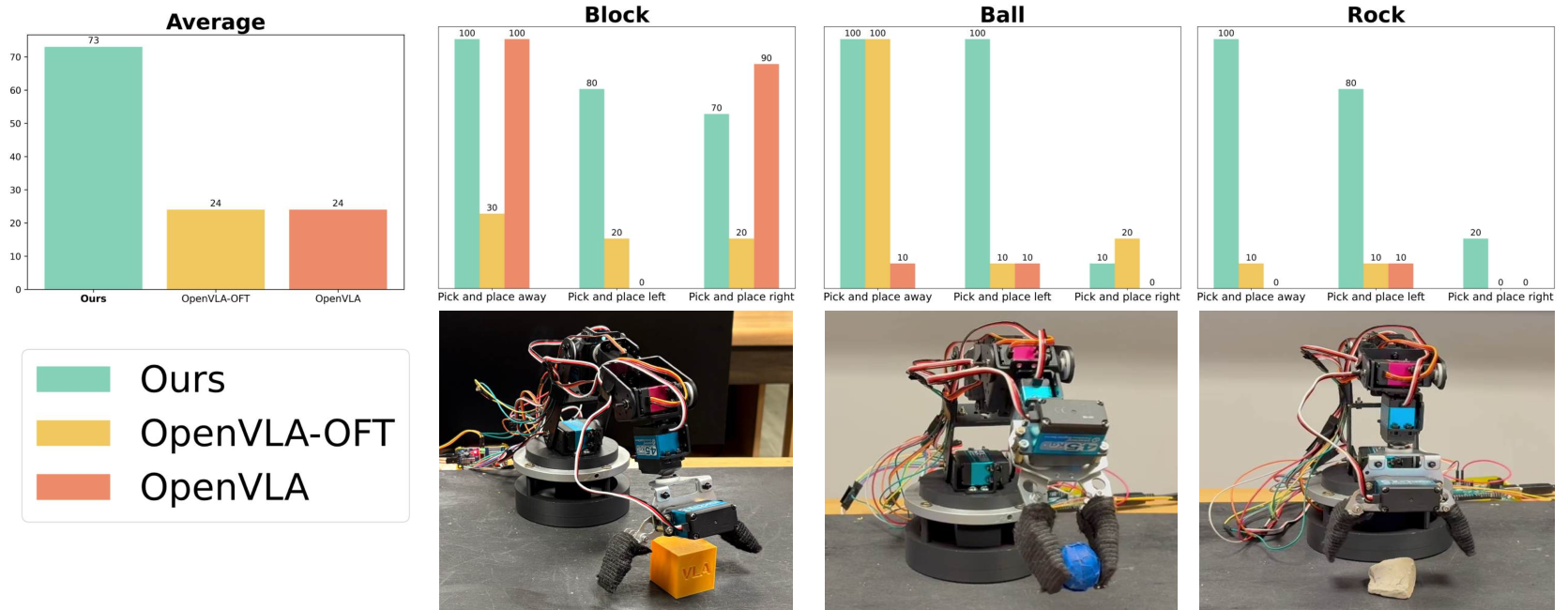
- Real-world success: On practical tests (like picking up blocks, balls, and rocks), EverydayVLA outperformed previous methods by about 49% on tasks similar to the training (“in-distribution”) and by about 34.9% on new, different tasks or scenes (“out-of-distribution”).
- Simulation benchmark: On the LIBERO robot simulation tests, EverydayVLA was competitive with top methods, and even won on one of the task groups (Spatial tasks).
- Speed: The system runs fast—up to around 108 actions per second (108 Hz)—so it can react quickly.
- Robustness: It handled cluttered tables (static distractors) and even people moving in the background (dynamic distractors) with relatively small performance drops. That means it’s less likely to get confused by messier, more realistic environments.
- Cost: The hardware costs around $312, which is much cheaper than most research robot arms. This lowers the barrier for classrooms and home projects.
These results show that combining an affordable robot arm with a clever control model that can self-check and replan makes real-world robot manipulation more reliable without needing fancy, expensive equipment.
What this means for the future
EverydayVLA helps “democratize” robotics. With cheaper hardware and a smart, adaptable model:
- Students, hobbyists, and small labs can experiment with advanced robot systems.
- Robots can better follow natural instructions and handle messy environments at home (like cleaning up a desk or organizing objects).
- Research can move faster because more people can test and improve these models.
There are still limits—the servos aren’t super precise, the arm’s durability needs more testing, and very fine, delicate movements are hard. In the future, the team plans to use higher-precision parts and collect more training examples to improve performance further. Even so, EverydayVLA is a promising step toward practical, affordable robot helpers that understand both what they see and what we say.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future work:
- End-to-end system latency on the real robot is unreported (camera capture + network streaming + perception + policy + IK + PWM actuation loop); only simulation-side inference rates are provided. What is the closed-loop control frequency, jitter, and worst-case latency on the deployed system?
- AdaHorizon’s key hyperparameters (difference thresholds, min_actions, chunk size K, hysteresis) lack sensitivity analyses and principled tuning guidance; how do these choices trade off success, stability, and safety across tasks and robots?
- The uncertainty proxy (mean absolute difference between continuous and discrete action chunks) is heuristic; how does it compare to calibrated uncertainty (e.g., ensembles, MC dropout, epistemic/aleatoric decomposition), per-dimension weighting, or learned disagreement metrics?
- No analysis of AdaHorizon failure modes (e.g., chattering/oscillation in horizon, delayed replans, premature truncation) or safeguards (hysteresis, smoothing, cooldown timers) to prevent instability.
- Discrete action design is under-specified: how were the 256 bins chosen, how are ranges normalized per DOF, and what is the quantization error vs task accuracy? What is the effect of varying bin count or nonuniform binning?
- Action chunk length K and minimum execution length selection are not justified; how do K and min_actions affect precision, responsiveness, and throughput across short vs long-horizon tasks?
- Orientation is represented with Euler angles; singularities and discontinuities are not addressed. Would alternative representations (quaternions, 6D continuous reps) improve stability and accuracy?
- The policy outputs relative EE deltas but the IK/trajectory generation stack is not detailed (velocity/acceleration limits, time-parameterization, smoothing, collision avoidance). How do these factors impact precision and safety?
- Collision avoidance, self-collision checks, and workspace/obstacle constraints are not modeled; how does the system prevent collisions in clutter and during long-horizon motion?
- Generalization to truly long-horizon, multi-step tasks is limited; the method underperforms SOTA on LIBERO-Goal and LIBERO-Long but lacks analysis of root causes (language grounding drift, compounding EE pose error, insufficient replanning cadence).
- Real-world evaluation focuses on simple tabletop pick-and-place; performance on contact-rich, deformable, tool-use, insertion, or tightly-toleranced tasks is not studied.
- Success criteria, sample sizes, trial counts, and statistical confidence (variance, CIs) are missing for real-world and OOD evaluations; robustness claims lack statistical rigor.
- The dataset (1,200 demos) is relatively small and built from parameterized trajectory primitives and templated language. How well does the model generalize to natural, diverse paraphrases, multi-constraint instructions, or compositional tasks?
- The dataset release details are unclear (license, splits, calibration files, teleop interfaces, instruction vocab, quality control). Can others reproduce the reported results and finetune fairly?
- Backbone inconsistencies: the paper claims Prismatic-7B (Llama 2) for VLM, yet also states finetuning OpenVLA-7B. Which backbone is used where, and how do different backbones impact performance and compute?
- Compute democratization gap: while hardware is low-cost, training relies on 1–2 A100s; inference hardware, memory footprint, and viability on edge devices (Jetson, NUC, CPU) are not reported. Are quantized or distilled models feasible without degrading performance?
- Camera setup relies on a monocular third-person RGB feed via smartphone streaming; camera intrinsics/extrinsics, calibration procedures, and robustness to viewpoint shifts, compression artifacts, motion blur, and lighting changes are not quantified.
- Depth sensing, multi-view, or active perception (camera motion) are not considered; how much would low-cost depth (e.g., RealSense) or stereo improve grasping and occlusion robustness?
- The gripper is binary (open/close); continuous aperture or force control is absent. How does this limit object diversity (thin, soft, heavy, slippery) and success rates on fine-grained tasks?
- Hardware repeatability (≤10 mm) lacks methodology: how was it measured (under load, across workspace, over time)? What are the contributions of servo backlash, PWM jitter, thermal drift, and supply voltage variation?
- Long-term mechanical reliability and maintenance are untested: servo wear, gear backlash growth, calibration drift, and power/thermal management during extended use remain open.
- Safety is minimally addressed: there is no description of E-stop, current/torque limiting, stall detection on the proposed arm, or human–robot interaction safeguards during dynamic distractors.
- Fairness of real-world baseline comparisons is unclear (retraining baselines on the same data, hyperparameters, controller integrations, horizon settings, and best-of-N evaluations). Can a standardized protocol be provided?
- IK feasibility and failure handling are not discussed; how does the system recover from unreachable targets, joint limits, or IK divergence, and does AdaHorizon help or hurt in these cases?
- OOD evaluation scope is narrow and loosely defined (what constitutes OOD tasks/environments?); more systematic taxonomies (lighting, background, viewpoint, object geometry/material, distractor motion patterns) and stress tests are needed.
- Energy consumption, peak current draw, PSU sizing, noise, and operating costs are not measured; these matter for home deployment.
- Open-source artifacts (CAD, BOM with vendors, firmware, calibration and assembly guides, test jigs) are not enumerated; without these, reproducibility and community adoption may be limited.
- No ablation on language conditioning method (e.g., FiLM vs alternatives) and its impact on grounding consistency in real-world settings.
- No comparison of AdaHorizon to model-predictive control/planning baselines or learned recovery policies for episodic replanning under uncertainty.
- The system does not report per-dimension error metrics (translation/orientation/gripper timing) or task-phase segmentation (reach, grasp, transport, release) to pinpoint where errors accumulate.
These points identify where documentation, analysis, and experimentation could be expanded to strengthen the paper’s claims and guide follow-on research.
Practical Applications
Immediate Applications
The paper’s low-cost hardware, collaborative VLA training, adaptive-horizon control, and streamlined data-collection pipeline enable practical deployments today across education, research, small-scale industry, and home use.
- Bold: Classroom and makerspace teaching kit for robot manipulation; Sector: education
- Use EverydayVLA’s $300 6-DOF arm, Arduino + PCA9685 control, and smartphone camera to teach vision-language robot control, IK, and dataset creation.
- Tools/workflows: BOM + printable parts, IKPy-based calibration, DroidCam streaming, LoRA fine-tuning on small task sets, standardized exercises (pick-and-place, drawer open/close).
- Assumptions/dependencies: Access to basic tools/3D printer, a consumer GPU or cloud GPU for fine-tuning; 10 mm repeatability and 0.2 kg payload fit curricular tasks; basic safety training.
- Bold: Budget research platform for VLA benchmarking and ablation; Sector: academia/software/robotics
- Replicate LIBERO-style experiments; test robustness with distractors; evaluate action-chunking and AdaHorizon against existing ensemblers.
- Tools/workflows: Prismatic-7B + Llama 2 backbone, LoRA fine-tuning scripts, AdaHorizon SDK-like module, RLDS/TFDS dataset export, OpenVLA-compatible code.
- Assumptions/dependencies: GPU access for training; reproducible setup; adherence to the provided pipeline for consistent metrics.
- Bold: Small-business light-duty automation (sorting, kitting, packaging of small items); Sector: industry/retail
- Deploy tabletop pick-and-place workflows for items under 0.2 kg (e.g., cosmetics, electronics accessories, gift boxes).
- Tools/workflows: Language templates for task specification (“pick up X, place left/right/away”), teleoperation for quick task adaptation, discrete action chunks with AdaHorizon to reduce misgrasp/replanning delays.
- Assumptions/dependencies: Task fits workspace and payload; tolerates ~10 mm precision; simple guards for human safety; on-premises GPU or cloud inference for reliable throughput.
- Bold: Home tabletop assistant for tidying and organizing; Sector: daily life/consumer robotics
- Voice/natural-language control to sort toys, move light objects, open/close drawers.
- Tools/workflows: Smartphone camera feed, prebuilt household instruction set, AdaHorizon thresholds tuned to reduce errors around clutter/dynamic distractors.
- Assumptions/dependencies: Non-medical, non-critical use; tasks within reach and payload; physical safety measures (enclosure, soft gripper), supervision recommended.
- Bold: Safety-aware motion execution module for existing robot controllers; Sector: software/robotics
- Integrate AdaHorizon’s uncertainty-based replanning into other VLA or policy stacks to reduce compounding errors and improve reliability with dynamic distractors.
- Tools/workflows: Drop-in “adaptive horizon” component that accepts continuous + discrete predictions and enforces minimum chunk lengths and thresholds.
- Assumptions/dependencies: Access to both discrete and continuous action heads or adapters; latency budget compatible with controller loop; threshold tuning per task.
- Bold: Rapid data-collection and fine-tuning workflow; Sector: academia/industry/software
- Use the teleoperation pipeline to create small, high-relevance datasets (video + language + poses) and fine-tune to site-specific tasks in days.
- Tools/workflows: Parameterized trajectory primitives, language templates, LoRA fine-tuning; export datasets in RLDS/TFDS for reuse.
- Assumptions/dependencies: Operator time for demonstrations; modest GPU resources; clear labeling of instructions; domain coverage of target tasks.
- Bold: Vision-language guided inspection and simple rework; Sector: manufacturing/QA
- Instruction-driven checks (e.g., “press button, move part to bin,” “place label here”) for small assemblies that tolerate 10 mm precision.
- Tools/workflows: Camera-based verification routines tied to discrete action chunks; on-the-fly replanning when disagreement rises.
- Assumptions/dependencies: Low precision acceptable; limited forces; basic fixturing for part presentation.
- Bold: STEM equity pilot programs and low-capex robotics adoption; Sector: policy/education
- Use EverydayVLA to expand hands-on robotics to underserved schools and community labs.
- Tools/workflows: Standardized kits, curricula, training modules; procurement guidelines for <$500 setups; shared datasets for cross-site learning.
- Assumptions/dependencies: Policy support for safety protocols and teacher training; minimal IT overhead; community support for maintenance.
Long-Term Applications
With further refinement in mechanical durability, precision, and on-device inference, EverydayVLA’s approach can scale to more demanding sectors and broader consumer deployment.
- Bold: Consumer-grade voice-controlled home assistant arm; Sector: consumer robotics
- Productize an under-$500 household manipulator for routine tasks (table clearing, small-item retrieval).
- Tools/products: Safety-certified enclosure, robust servos, tactile sensing, cloud/on-device VLA; companion app for task setup.
- Assumptions/dependencies: Mechanical redesign for durability; regulatory compliance and safety certification; improved gripper and precision.
- Bold: Micro-automation cells in warehouses and micro-fulfillment centers; Sector: logistics/warehousing
- Swarms of low-cost arms for bin sorting, return processing, and light kitting, coordinated via scheduling systems.
- Tools/workflows: Fleet management, task allocation via language specs, site-specific fine-tuning; AdaHorizon for safe high-throughput execution.
- Assumptions/dependencies: Higher payload/end-effector reliability; standardized fixtures; robust 24/7 operation; predictive maintenance.
- Bold: Hospital and clinic logistics assistants; Sector: healthcare
- Handle lightweight logistics (med kits, disposables) and prep tasks with language guidance.
- Tools/workflows: Sterility-compliant housings, safety wrappers, validated instruction libraries; clinician-in-the-loop overrides.
- Assumptions/dependencies: Medical regulatory approvals; improved precision, compliance, and fault tolerance; institutional IT integration.
- Bold: Agricultural micro-tasks (sorting small produce, seeding, labeling); Sector: agriculture
- Deploy low-cost arms for repetitive, lightweight tasks that benefit from language-conditioned flexibility.
- Tools/workflows: Domain-specific datasets (lighting, textures), ruggedized housings, grippers for delicate items.
- Assumptions/dependencies: Environmental hardening; task-specific end-effectors; robust generalization outdoors.
- Bold: Cross-site teleoperation data network and cloud fine-tuning service (“EveryDayVLA Hub”); Sector: software/robotics
- Crowdsource diverse manipulation datasets from distributed arms; run continuous LoRA fine-tuning with privacy controls.
- Tools/workflows: RLDS/TFDS-compatible pipelines, consent and anonymization tooling, model versioning, task marketplace.
- Assumptions/dependencies: Data governance, privacy compliance; scalable compute; cross-embodiment model alignment.
- Bold: Edge/on-device VLA inference on embedded SoCs; Sector: energy/software/robotics
- Distill/quantize models (e.g., towards TinyVLA-like footprints) to run locally on ARM/Jetson-class hardware, reducing cloud reliance and energy costs.
- Tools/workflows: Model compression, mixed-precision kernels, real-time camera pipelines; action-chunking optimized for edge latency.
- Assumptions/dependencies: Research in distillation and quantization for VLA; acceptable performance vs. cloud models.
- Bold: Bimanual and dexterous manipulation with improved mechatronics; Sector: robotics/industry
- Extend to two arms, higher-torque actuators, tactile sensing; leverage AdaHorizon for fine control and safe replanning.
- Tools/workflows: New kinematic chains, compliant wrists, better servos/gearboxes; richer datasets of dexterous tasks.
- Assumptions/dependencies: Hardware redesign and higher capex; significantly more expert demos; potential diffusion or flow methods for very fine control.
- Bold: Standards, safety, and liability frameworks for low-cost VLA robots; Sector: policy/regulation
- Create guidelines for deployment, operator training, dataset governance, and safe human-robot interaction with dynamic replanning.
- Tools/workflows: Certification checklists, threshold presets, audit trails for actions and overrides.
- Assumptions/dependencies: Multistakeholder coordination (manufacturers, schools, SMEs); empirical safety data; clear liability rules.
- Bold: Financing and procurement models for SMEs; Sector: finance/industry
- Micro-leasing and subscription bundles (hardware + cloud fine-tuning + support) to lower adoption barriers.
- Tools/workflows: ROI calculators based on throughput, error reduction via AdaHorizon, service-level agreements for uptime.
- Assumptions/dependencies: Demonstrated reliability and service ecosystem; transparent TCO; minimal IT complexity.
- Bold: National curricula and competitions using standardized low-cost VLA kits; Sector: education/policy
- Scale EverydayVLA into a shared educational platform with common tasks and benchmarks (e.g., mini-LIBERO challenges).
- Tools/workflows: Curriculum packs, educator training, shared leaderboards and datasets, integration with science fairs.
- Assumptions/dependencies: Funding, teacher support, maintenance logistics; accessible compute options (school GPUs or subsidized cloud).
Glossary
- 6-DOF: A robot with six independent degrees of freedom, enabling arbitrary 3D positioning and orientation. "We introduce EverydayVLA, a 6-DOF manipulator that can be assembled for \$300"
- Adaptive Horizon Ensembler (AdaHorizon): A module that adjusts how many future actions to execute based on model uncertainty to enable timely replanning. "our adaptive-horizon ensembler monitors motion uncertainty to trigger on-the-fly replanning"
- Action chunking: Grouping multiple future control steps into a single predicted block to reduce latency and improve throughput. "by leveraging action chunking and parallel decoding, enabling joint prediction of discrete and continuous action chunks."
- Action horizon: The number of future actions planned/executed before replanning is considered. "and dynamically adjust action horizons to trigger replanning under tight realâtime constraints."
- Autoregressive: A modeling approach that predicts the next output conditioned on previously generated outputs. "Autoregressive VLAs suffer due to iterative generation, leading to danger of compounding errors"
- Cross-embodiment datasets: Robot learning datasets collected across different robot bodies and platforms to improve generalization. "expansive crossâembodiment datasets"
- Cross-entropy loss: A standard classification loss used to train discrete predictions by comparing predicted distributions to targets. "To supervise the discrete actions, we use cross-entropy loss:"
- Degrees of freedom (DOF): Independent controllable axes of motion of a robot. "workspace, degrees of freedom (DOF), payload capacity, speed, and repeatability."
- Diffusion-based VLAs: Vision-language-action models that generate continuous actions using diffusion processes. "diffusion-based VLAs suffer from long training times \cite{zhang2024improving} \cite{wang2023patch}, and multiple denoising steps."
- DINOv2: A self-supervised vision backbone used for robust visual feature extraction. "and DinoV2 \cite{oquab2023dinov2}"
- End-effector: The tool or gripper at the robot’s wrist that interacts with objects. "The action represents the endâeffector pose and is 7-DOF."
- Euler angles: A 3-parameter representation of 3D orientation using rotations about coordinate axes. "3-DOF for rotation (Euler angles):"
- FiLM-based: Using Feature-wise Linear Modulation layers to condition a vision backbone on text or other inputs. "its FiLMâbased language grounding \cite{perez2018film} can be inconsistent."
- Flow-matching: A generative modeling approach related to diffusion that learns continuous flows to map noise to data. "via diffusion and flowâmatching methods"
- I2C: A two-wire serial communication bus commonly used for connecting low-speed peripherals. "that communicates over I2C with an Arduino Uno."
- In-distribution: Data or tasks that match the training distribution encountered during model development. "49\% in-distribution and 34.9\% out-of-distribution."
- Inference throughput: The rate at which a model can produce action predictions, often measured in Hz. "Although diffusionâbased approaches can deliver higher inference throughput,"
- Inverse kinematics: Computing joint angles that achieve a desired end-effector pose. "We use IKPy \cite{Manceron_IKPy} for inverse kinematics to get robot joint angles."
- L1-regression objective: A training objective that minimizes the absolute error between predicted and true continuous values. "an L1-regression objective: the model generates entire action chunks in one forward pass,"
- LIBERO: A benchmark suite for evaluating robot manipulation and generalization. "On LIBERO, EverydayVLA matches state-of-the-art success rates,"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique for large models. "For finetuning, we use LoRA \cite{lora}"
- Mean absolute difference (MAD): An uncertainty metric computed as the average absolute difference between two predictions. "the mean absolute difference between the continuous and discrete action predictions,"
- Out-of-distribution (OOD): Data or tasks that differ significantly from the training distribution. "49\% in-distribution and 34.9\% out-of-distribution."
- Parallel decoding: Producing multiple outputs in one forward pass instead of step-by-step autoregression to reduce latency. "parallel decoding,"
- PCA9685: A 16-channel, 12-bit PWM driver chip used to control many servos. "PCA9685 pulse with modulation (PWM) driver for 12-bit PWM control."
- PWM: Pulse-width modulation, a method to control servo position or motor power via duty cycle. "PCA9685 pulse with modulation (PWM) driver for 12-bit PWM control."
- Repeatability: The ability of a robot to return to a position with small variation across repeated motions. "achieves better than 10 mm repeatability"
- Replanning: Updating a planned action sequence based on new information or uncertainty during execution. "trigger on-the-fly replanning"
- SE(3): The Lie group of 3D rigid body transformations (rotation and translation). "The ground truth (GT) and the predicted action lie in ,"
- SigLIP: A vision-language pretraining method using a sigmoid loss for image–text alignment. "containing pretrained SigLIP \cite{zhai2023sigmoid}"
- Teleoperation: Controlling a robot manually to collect demonstrations or perform tasks remotely. "We streamline teleoperation to collect trajectories"
- Tokenization: Discretizing continuous trajectories into compact tokens for sequence modeling. "Tokenizationâbased methods like FAST convert continuous trajectories into compact tokens,"
- VisionâLanguageâAction (VLA): Models that map images and language instructions directly to robot actions. "VisionâLanguageâAction (VLA) models map visual inputs and language instructions directly to robot actions,"
- VisionâLLMs (VLMs): Models that jointly process images and text to enable multimodal understanding. "VisionâLLMs (VLMs) \cite{chen2022pali} preâtrained on massive webâscale datasets,"
- Workspace: The volume of space the robot’s end-effector can reach and operate within. "capable of modest payloads and workspaces."
Collections
Sign up for free to add this paper to one or more collections.

