Demystifying Reinforcement Learning in Agentic Reasoning
Abstract: Recently, the emergence of agentic RL has showcased that RL could also effectively improve the agentic reasoning ability of LLMs, yet the key design principles and optimal practices remain unclear. In this work, we conduct a comprehensive and systematic investigation to demystify reinforcement learning in agentic reasoning from three key perspectives: data, algorithm, and reasoning mode. We highlight our key insights: (i) Replacing stitched synthetic trajectories with real end-to-end tool-use trajectories yields a far stronger SFT initialization; high-diversity, model-aware datasets sustain exploration and markedly improve RL performance. (ii) Exploration-friendly techniques are crucial for agentic RL, such as clip higher, overlong reward shaping, and maintaining adequate policy entropy could improve the training efficiency. (iii) A deliberative strategy with fewer tool calls outperforms frequent tool calls or verbose self-reasoning, improving tool efficiency and final accuracy. Together, these simple practices consistently enhance agentic reasoning and training efficiency, achieving strong results on challenging benchmarks with smaller models, and establishing a practical baseline for future agentic RL research. Beyond these empirical insights, we further contribute a high-quality, real end-to-end agentic SFT dataset along with a high-quality RL dataset, and demonstrate the effectiveness of our insights in boosting the agentic reasoning ability of LLMs across four challenging benchmarks, including AIME2024/AIME2025, GPQA-Diamond, and LiveCodeBench-v6. With our recipes, 4B-sized models could also achieve superior agentic reasoning performance compared to 32B-sized models. Code and models: https://github.com/Gen-Verse/Open-AgentRL

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to “think and act” more like helpful agents. Instead of only writing answers, these agents can use external tools (like a calculator, code runner, or web search) while they think. The authors study how to train these tool-using agents with reinforcement learning (RL) so they become smarter, faster, and more reliable. They share simple recipes that work well and a small, strong model called DemyAgent-4B that beats much larger models on tough tests.
Key Objectives
The paper focuses on three big questions, explained in everyday terms:
- Data: What kind of training examples help an AI learn when and how to use tools?
- Algorithms: Which training tricks make RL stable, efficient, and effective for tool-using agents?
- Reasoning Mode: Is it better for an AI to call tools often, or to think more carefully and call tools less?
Methods and Approach
To answer these questions, the authors run careful comparisons and experiments. Here’s how:
- Training with Real vs. Synthetic Data:
- Real data means full, real-life “end-to-end” examples of the AI deciding when and why to use a tool, getting the tool’s result, checking it, and continuing.
- Synthetic data is “stitched together” by replacing parts of the AI’s thinking with tool outputs, which can miss the true flow of decisions.
- They fine-tune models on both and compare performance.
- Diverse and Model-Aware Datasets:
- Diverse dataset: includes problems from different areas (not just math) to prevent narrow thinking.
- Model-aware dataset: adjusts problem difficulty for the model’s skill level, so the model gets useful feedback instead of being stuck.
- RL Training Recipe (GRPO):
- They use a popular RL method called GRPO (a variant of PPO) and test practical tweaks:
- Clipping “higher”: like allowing a bigger “speed limit” on how much the model can change per update, to encourage exploration.
- Reward shaping: giving points not just for correct answers, but also for good behavior (like not making answers overly long).
- Loss granularity: training at the token level (every word matters) vs. sequence level (one big chunk). Token-level often helps stronger models learn faster and better.
- Key signals they track:
- Pass@k: If the model tries k different answers, how often is at least one correct? Think of it as “how many ideas do you try and does one work?”
- Average@k: The overall accuracy across k attempts—more about consistent quality, not just “one lucky try.”
- Entropy: How unpredictable or “adventurous” the model’s choices are. Higher entropy means it explores more options; too low means it gets stuck repeating itself.
- Reasoning Mode Analysis:
- They study whether agents do better by calling tools frequently with short thinking (“Reactive”), or by thinking carefully and calling tools less (“Deliberative”).
- They also test Long Chain-of-Thought (Long-CoT) models, which naturally write long, detailed reasoning, to see how they behave with tools.
Main Findings
Here are the main takeaways from the three perspectives:
1) Data: Real, Diverse, and Model-Aware Data Work Best
- Real end-to-end tool-use examples are much better than synthetic “stitched” ones. Real examples teach the agent:
- When to call a tool.
- Why it helps.
- How to check results and recover from mistakes.
- Diverse datasets keep the model’s “entropy” (willingness to explore) higher, which speeds up learning and prevents getting stuck.
- Model-aware datasets (matching problem difficulty to the model’s skill) give clearer feedback and help weaker models break through performance blocks.
2) Algorithms: Exploration-Friendly Training Improves Results
- Simple tweaks help a lot:
- Clip higher: allow slightly bigger updates so the model explores more early on.
- Overlong reward shaping: penalize overlong answers to keep reasoning focused and efficient.
- Token-level training often beats sequence-level for stronger models, improving speed and peak accuracy.
- Agentic RL can improve both pass@k and average@k together when done well (thanks to tool feedback), unlike conventional RL that often boosts pass@1 but hurts broader exploration.
- Entropy should be balanced:
- Too low: the model “freezes” and stops exploring.
- Too high: training becomes unstable.
- The best range depends on how strong the model is—weaker models benefit from more exploration headroom; stronger models need tighter control.
3) Reasoning Modes: Fewer, Smarter Tool Calls Win
- The best agents think more before calling tools, then make fewer, more accurate calls (Deliberative Mode). This leads to higher success rates and better performance.
- Calling tools often with shallow thinking (Reactive Mode) wastes time and fails more.
- Current Long-CoT models tend to avoid tools on thinking-heavy tasks and try to solve everything internally. With proper supervised fine-tuning (SFT) on tool-use data, they learn to call tools—but instruction-based models (without strong pre-baked long-thinking habits) are often easier to train and scale for agentic RL.
Bonus: Strong Results with a Small Model
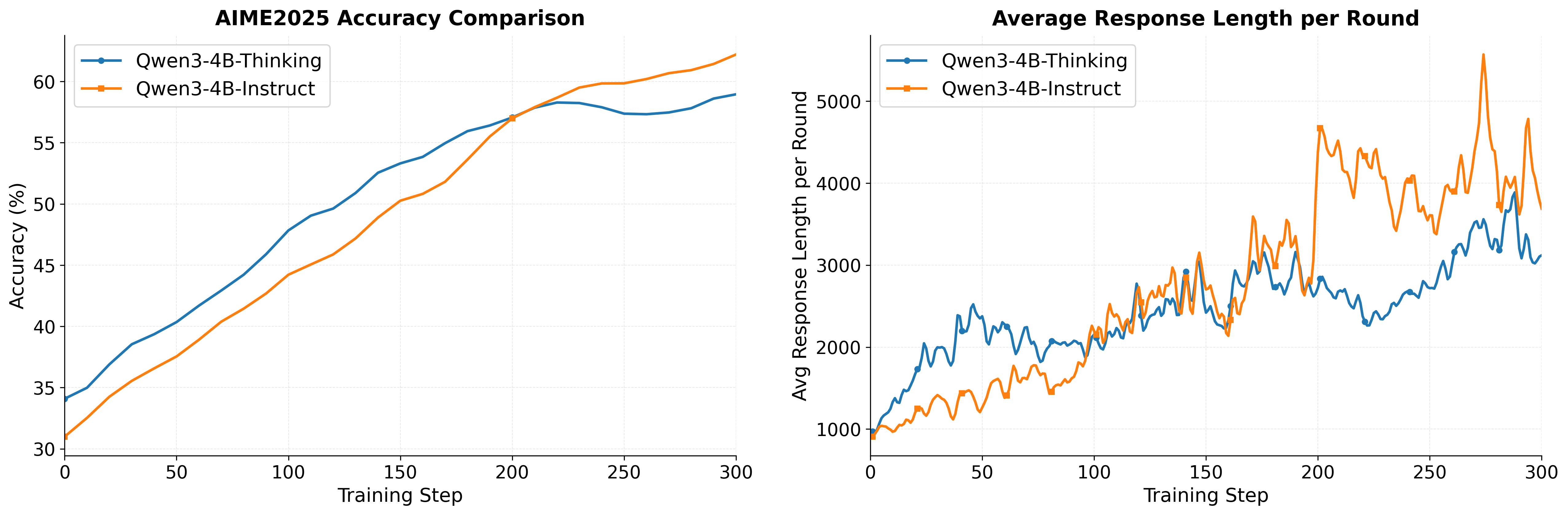
- Using these recipes, their 4-billion-parameter model (DemyAgent-4B) reaches or beats larger 14B/32B models on hard benchmarks like AIME2024/2025 (math), GPQA-Diamond (science), and LiveCodeBench-v6 (coding). That means smart training can matter more than model size.
Why This Is Important
- Better AI Helpers: Teaching models to reason carefully and use tools well can make them far more helpful for math, science, and coding tasks.
- Efficiency Over Size: A small, well-trained model can beat much larger ones, saving compute, cost, and energy.
- Clear, Practical Recipes: The paper gives simple, effective training tips and new datasets that others can use to build strong AI agents.
- Smarter Exploration: Maintaining balanced “adventurousness” (entropy) and using the right data lets models improve faster and more stably.
- Real-World Impact: From classroom math to programming tasks, agentic reasoning can make AI more accurate, efficient, and trustworthy.
In short, this work shows that the right data, simple RL tweaks, and a careful reasoning style can turn even smaller models into powerful tool-using agents that think better and get more done.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future research.
- [Data] Lack of contamination analysis: no systematic checks for overlap between the curated SFT/RL datasets and evaluation benchmarks (e.g., AIME-style items), nor a documented protocol for leakage avoidance and measurable contamination rates.
- [Data] Insufficient dataset documentation: unclear sources, licensing, annotation/verification procedures, and tool-execution environments for the “real end-to-end” trajectories; hinders reproducibility and bias assessment.
- [Data] Tool realism not characterized: no quantification of tool noise/failure/latency, non-determinism, or version drift; unclear how agent policies handle flaky tools or stale environments.
- [Data] Model-aware dataset selection risks: potential feedback loops (curriculum collapse) and narrowing of distribution coverage when filtering by current model competence; no safeguards or diagnostics for overfitting to “easy/medium/hard” bands tailored to the model.
- [Data] Diversity scope is underspecified: “diverse” RL dataset composition is not detailed (task types, tool types, domain proportions); no ablation on which diversity dimensions (domain, tool, reasoning pattern) drive entropy and performance.
- [Algorithm] Missing formal grounding: no theoretical analysis linking clipping bounds, entropy dynamics, and convergence/performance in agentic RL; open question how to derive principled schedules for clip/KL/entropy targets across model scales.
- [Algorithm] Limited algorithmic coverage: trajectory-level objectives, off-policy corrections (e.g., V-trace), replay buffers for tool-augmented trajectories, critic/value baselines, and adaptive KL schedules are not explored.
- [Algorithm] Reference-policy design is underexplored: effect of reference model choice (static vs updated), KL coefficient β scheduling, and reference refresh strategies on exploration and stability remains unstudied.
- [Algorithm] Group size and sampling: no ablation of GRPO group size G, rollout temperatures, or sampling strategies on pass@k-to-average@k conversion and entropy control in tool-augmented settings.
- [Algorithm] Reward formulation is ad hoc: the “out+tool” reward (with 0.1n bonus and clipping) lacks a principled cost/benefit model; need to study cost-aware multi-objective rewards that incorporate latency, API cost, tool reliability, and safety without incentivizing “tool abuse.”
- [Algorithm] Length shaping generality: overlong reward shaping hyperparameters (, $L_{\text{cache}$) are not stress-tested across tasks/tools; unknown impact on solution quality when solutions require legitimately long reasoning or delayed tool calls.
- [Algorithm] Entropy as a proxy: reliance on aggregate policy entropy lacks causal validation; need token- and state-conditional entropy analyses (pre- vs post-tool-call, decision points) and interventions to test causality.
- [Algorithm] Adaptive exploration control absent: no method for entropy-targeted or performance-aware adaptive clipping/KL schedules; open question how to auto-tune exploration budgets per model competency and training phase.
- [Algorithm] Credit assignment around tool calls: rewards are outcome-based; no fine-grained, call-level credit assignment to distinguish helpful vs harmful tool invocations within a trajectory.
- [Reasoning] Causality of “fewer calls is better” is unclear: stronger models both call fewer tools and perform better; need controlled interventions (fixed budgets, randomized tool availability/cost, matched trajectories) to establish causality vs correlation.
- [Reasoning] Task sensitivity: the “deliberative mode” advantage is shown mainly on math/coding/science; unclear whether it holds for knowledge-heavy, retrieval-centric, or multi-hop web tasks where frequent lightweight calls might help.
- [Reasoning] Tool orchestration not studied: no exploration of meta-control (e.g., a gating/controller module) to decide when to call tools vs think longer, or hierarchical policies/options for planning, calling, and verification.
- [Reasoning] Long-CoT integration remains fragile: beyond SFT initialization, there is no systematic method to resolve conflicts between internal long-form reasoning and external tool use (e.g., constraint regularization, mixture-of-policies, call-aware decoding, or thinking-to-calling distillation).
- [Evaluation] Limited robustness analysis: results lack multiple seeds, confidence intervals, and sensitivity to decoding hyperparameters (temperature/top-p), tool availability, and prompts; unclear stability and reproducibility.
- [Evaluation] Metric scope: average@k, pass@k, maj@k do not capture real-world costs (time, latency, API expenditure), safety, or tool reliability; open need for cost-sensitive and safety-aware evaluation metrics.
- [Evaluation] Generalization breadth: benchmarks mainly cover math, science QA, and code; untested on long-horizon, dynamic, or multi-modal agent tasks (web, robotics, multi-file codebases, toolchains with dependencies).
- [Safety] Safety and security are unaddressed: no discussion of sandboxing for code execution, prompt-injection and data-exfiltration attacks in search tools, or guardrails for unsafe tool use.
- [Compute] Compute/sample efficiency not quantified: wall-clock tokens, tool-call overhead, and compute-per-gain are not reported; no comparison to alternative recipes for efficiency at fixed budgets.
- [Reproducibility] Incomplete hyperparameter reporting and minor equation typos hinder exact replication; a formal recipe card (data splits, seeds, tool configs, rollout settings) is missing.
- [Open-method] Unified multi-domain reward scaling: when mixing tasks (math, code, science), reward magnitudes and verification fidelity differ; no normalization or calibration method to prevent task imbalance in multi-task agentic RL.
- [Open-method] Online/interactive data collection: the paper focuses on static datasets; it remains open how to safely and efficiently collect online trajectories with evolving tools and minimize distribution drift.
- [Open-method] Multi-agent or collaborative settings: unexplored potential of agents coordinating tool-use (planner-executor, verifier-coder) to reduce calls while improving reliability.
- [Open-method] Scaling laws for agentic RL: no systematic study of performance as a function of model size, dataset size/diversity, entropy targets, and clipping ranges to guide compute-optimal training.
Practical Applications
Immediate Applications
The paper’s findings can be operationalized today to improve agentic LLM training, deployment, and governance. Below is a concise set of use cases across sectors, each with suggested tools/workflows and feasibility notes.
- Software and developer tooling — Deliberative code agents with fewer tool calls
- What: Deploy code assistants that plan before acting, call the code interpreter less frequently but more accurately, and keep outputs within length budgets to reduce cost and latency while boosting correctness on coding tasks.
- Tools/products/workflows: DemyAgent-4B as a base; code interpreter; unit-test–based verifiers; overlong reward shaping to enforce token budgets; “Deliberate-Call” prompting policies; GRPO-TCR recipe (token-level loss, clip-higher, length shaping).
- Assumptions/dependencies: Access to execution sandboxes and test oracles; logging to compute tool-call success; privacy-safe storage of run traces.
- Enterprise knowledge work and customer support — Tool-savvy assistants with quality-over-quantity tool use
- What: Assistants that interleave internal reasoning with targeted CRM, search, or database queries; fewer external calls reduce latency, API bills, and failure modes.
- Tools/products/workflows: CRM/database connectors; RAG/search; internal verifiers for “success/failure” signals; entropy monitoring and clip tuning to maintain exploration without instability.
- Assumptions/dependencies: High-quality E2E logs for SFT; permissioned access to internal data; data compliance and redaction.
- Education — Tutoring and homework helpers that reason first, then call tools
- What: Math/science tutors that think through steps, then invoke calculators/solvers selectively; adaptive “model-aware” curricula tuned to the learner’s level.
- Tools/products/workflows: Calculator/CAS/WolframAlpha; item response logs to label difficulty (easy/medium/hard); model-aware sampling to avoid too-easy/too-hard items; pass@k vs average@k gap as a progress KPI.
- Assumptions/dependencies: Verifiable problems (e.g., with numeric answers); student data privacy; alignment with school policies.
- Data and RLOps — Practical training recipe and monitoring kit for agentic RL
- What: Adopt the paper’s “recipes” as standard operating procedure for training agentic LLMs.
- Tools/products/workflows:
- Data: Replace stitched synthetic tool traces with real end-to-end trajectories; curate diverse RL datasets; build model-aware datasets by filtering zero/100% accuracy items and matching difficulty histograms to model capacity.
- Algorithm: GRPO-TCR (token-level loss, clip higher, overlong reward shaping); clip-upper-bound sweeps; entropy dashboard.
- Ops: Track pass@k, average@k, their gap, and policy entropy over time; early-stop on entropy collapse; increase clip_high for weaker models.
- Assumptions/dependencies: Access to open-source stack (Open-AgentRL), compute budget for PPO-style training, verifiers/reward functions for your domain.
- Cost and latency reduction — Governance knobs that cut waste
- What: Reduce overlong outputs and excessive API/tool calls via reward shaping and deliberation-first policies.
- Tools/products/workflows: Overlong reward shaping; per-tool success counters; tool-bonus clipping to prevent reward hacking; cost dashboards.
- Assumptions/dependencies: Clear max-token budgets; reliable success signals from tools; robust logging.
- Research and benchmarking — Reproducible baseline and datasets
- What: Use DemyAgent-4B and the released datasets as community baselines for agentic RL studies.
- Tools/products/workflows: HF model (DemyAgent-4B), Open-AgentRL repo; AIME/GPQA/LiveCodeBench suites; ablation templates (token vs sequence-level loss; clip settings; data diversity).
- Assumptions/dependencies: Benchmark licenses; compute for rollouts; consistent prompts and verification scripts.
- Public-sector and enterprise policy — Data and training governance patterns
- What: Codify data collection and training practices that favor real E2E trajectories, diversity, and model-aware sampling; require monitoring of the pass@k–average@k gap and entropy for stability.
- Tools/products/workflows: Policy templates for provenance of agentic logs; tooling to scrub PII; training audits that include entropy traces and clipping configs.
- Assumptions/dependencies: Legal frameworks for log collection; DPIA/PIA processes; secure logging infrastructure.
- Personal productivity — On-device or low-cost assistants
- What: 4B-parameter agents that can run locally or cheaply in the cloud to solve math, coding snippets, and research tasks with deliberate tool calls.
- Tools/products/workflows: Local code interpreter; browser/search plug-ins; energy-efficient runtimes for small LLMs; few-call policies to preserve battery/network.
- Assumptions/dependencies: Device memory and compute; offline-capable tools; sandboxing for safety.
Long-Term Applications
These ideas require additional research, domain-specific verification, safety validation, scaling, or integration with regulated systems.
- Healthcare — Decision-support agents that judiciously invoke clinical tools
- What: Agents that reason through cases and selectively query EHRs, guidelines, or medical calculators; fewer, higher-precision tool invocations for safety and traceability.
- Tools/products/workflows: EHR connectors (FHIR), medical calculator APIs, formal verifiers (guideline compliance checkers), audit trails.
- Assumptions/dependencies: Regulatory approvals, bias and safety evaluation, domain reward functions beyond accuracy (e.g., patient risk), robust tool success signals.
- Autonomous science — Lab copilots that plan then act via instruments/simulators
- What: Agents that deliberate, then call lab equipment APIs or simulation tools to explore hypotheses efficiently.
- Tools/products/workflows: ELN/LIMS integrations, simulator APIs with verifiable outputs, model-aware curricula that stage from easy to hard experiments, entropy-bound controllers for stability.
- Assumptions/dependencies: High-fidelity simulators/ground-truth checks, lab safety constraints, provenance tracking, extensive E2E trace datasets.
- Robotics and operations — Fewer-but-better action calls in embodied agents
- What: Treat tool calls as actuator/planner invocations; encourage deliberation to reduce action flapping and energy use.
- Tools/products/workflows: Planner APIs, safety supervisors, overlong reward shaping for time/energy budgets, entropy targets for exploration without instability.
- Assumptions/dependencies: Real-world reward design (task success, safety margins), sim-to-real robustness, reliable state estimation.
- Energy and infrastructure — Agentic controllers for grid/plant ops
- What: Agents that call simulators/optimizers (SCADA, EMS) sparingly, focusing on high-value interventions.
- Tools/products/workflows: Physics-informed verifiers; model-aware datasets matched to plant complexity; pass@k–average@k gap as a stability KPI for control policies.
- Assumptions/dependencies: Safety-critical verification, regulatory acceptance, high-reliability tool APIs.
- Finance — High-precision, low-latency analysis with controlled exploration
- What: Agents that think first, then query market data or compliance tools selectively; clip/entropy tuning to prevent over-exploration.
- Tools/products/workflows: Market-data APIs, compliance rule engines, reward functions that penalize overlong reports and unnecessary calls, cost-aware training.
- Assumptions/dependencies: Strict auditability, adversarial robustness, domain-specific correctness checks.
- Education at scale — Adaptive curricula via model-aware sampling
- What: LMS-integrated builders that continuously calibrate problem difficulty to a student’s evolving “ability histogram,” accelerating learning.
- Tools/products/workflows: Difficulty labeling via multi-try correctness, tailored sampling policies, pass@k–average@k gap as a mastery indicator.
- Assumptions/dependencies: Longitudinal validations of learning gains, equity considerations, privacy safeguards.
- Multi-agent systems — Coordination via exploration–exploitation metrics
- What: Use pass@k–average@k gaps and entropy profiles to allocate tasks, decide when to seek external tools, and reduce redundant calls across agents.
- Tools/products/workflows: Multi-agent orchestration frameworks; shared tool-call success ledgers; entropy-aware schedulers.
- Assumptions/dependencies: Inter-agent communication protocols, credit assignment for rewards, tool contention management.
- Standardization and audits — Agentic RL training and safety standards
- What: Formalize practices around real E2E data, diversity, model-aware datasets, clipping/entropy configs, and reward shaping as part of certification.
- Tools/products/workflows: Audit checklists; standardized telemetry schemas (entropy traces, clip params); benchmark suites for agentic tasks (math, code, search).
- Assumptions/dependencies: Cross-industry consensus; regulatory alignment; reproducible open benchmarks.
- Dataset and tooling ecosystems — Model-aware data services and tool APIs with reward hooks
- What: Marketplaces that deliver difficulty-labeled, verifier-backed datasets; tool vendors that expose standardized success/failure signals to power RL.
- Tools/products/workflows: Tool-Use Logger SDKs; verifiers-as-a-service; dataset curation pipelines aligned with the paper’s filtering and diversity recipes.
- Assumptions/dependencies: Incentives for providers; privacy-preserving logging; domain verifiers with high precision/recall.
- Long-CoT alignment pipeline — Convert long-reasoning models into competent tool users
- What: A productized pipeline that first SFTs Long-CoT models on end-to-end tool-use traces before RL, resolving over-reliance on internal reasoning.
- Tools/products/workflows: E2E tool-use SFT datasets; RL with GRPO-TCR; monitoring of tool-call rates to prevent collapse to zero calls.
- Assumptions/dependencies: Access to suitable Long-CoT bases; sufficient E2E traces; domain verifiers and tool adapters.
Notes on feasibility and transfer
- Transfer to new domains depends on available verifiers/reward functions (e.g., unit tests, calculators, compliance rules) and reliable tool success signals.
- Real, privacy-compliant end-to-end logs are foundational for SFT. Synthetic “stitched” traces degrade tool-use learning.
- Clip-high and entropy settings are model- and domain-dependent: weaker models typically need more exploration (higher clip upper bound), stronger models benefit from tighter bounds.
- Overlong reward shaping assumes known max-length budgets and helps contain cost/latency without harming accuracy.
- The pass@k–average@k gap is a practical KPI for training headroom: a large gap indicates exploitable exploration that can be converted into reliable performance.
Glossary
- Ability boundary: An estimate of the upper limit of a model’s problem-solving capability measured via pass@k. "pass@32 (ability boundary \citep{deng2025trial-error})"
- Advantage (normalized): The standardized advantage signal used in policy gradient updates across tokens or sequences. " is the normalized advantage across all tokens:"
- Agentic reasoning: A paradigm where LLMs integrate external tools within their reasoning process to solve tasks more effectively. "Effective agentic reasoning follows a quality-over-quantity principle:"
- Agentic RL: Reinforcement learning setup that trains agents to reason with and call external tools during multi-turn interactions. "A central question in agentic RL is how an agent should allocate its reasoning budget"
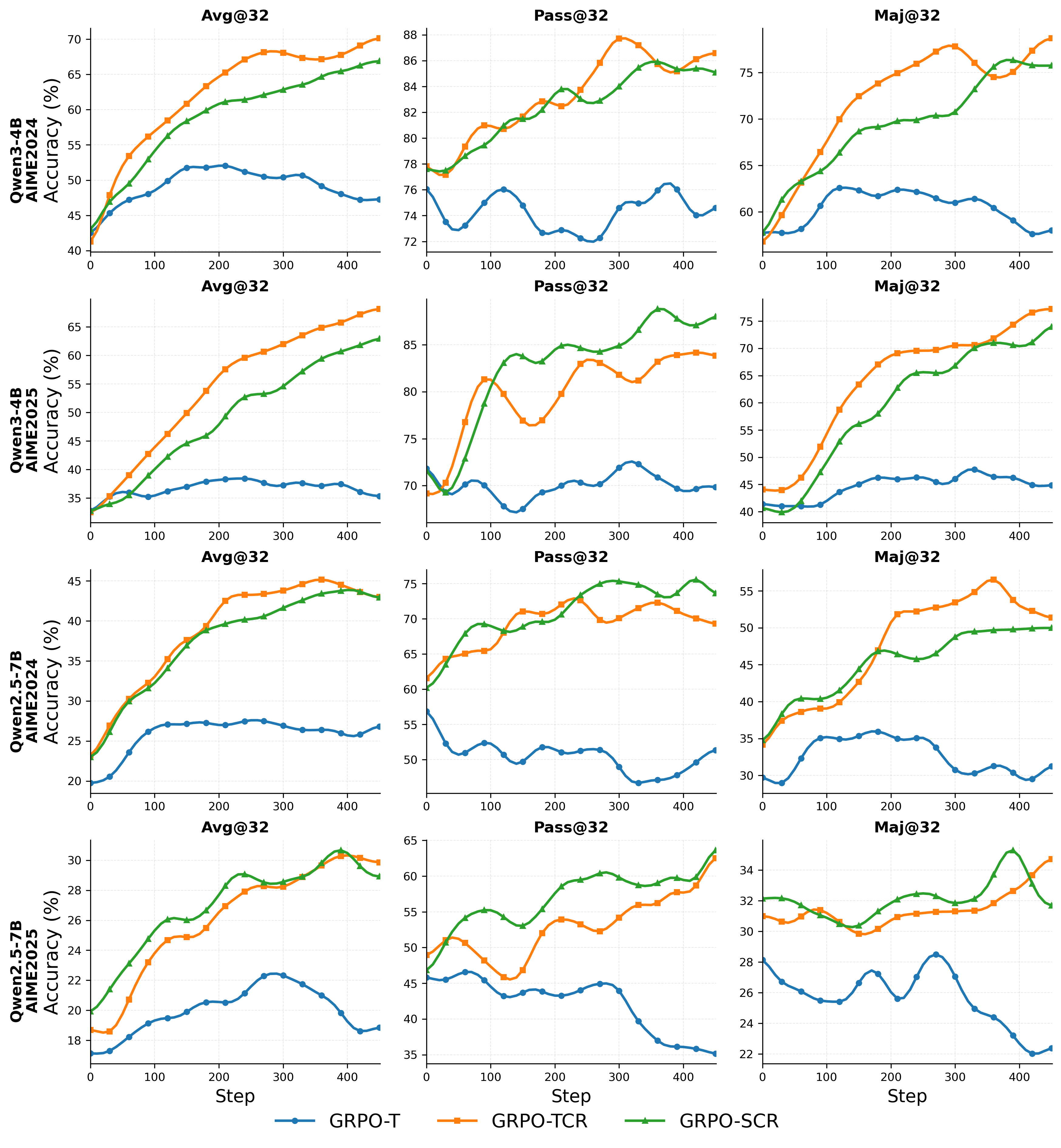
- Average@k: The average accuracy over k sampled attempts, reflecting overall performance under multiple rollouts. "We evaluate using average@32 (overall agent performance), pass@32 (ability boundary \citep{deng2025trial-error}), and maj@32 (performance stability)."
- Chain-of-thought (CoT): Explicit intermediate reasoning steps generated by the model to arrive at an answer. "encouraging the generation of effective chain-of-thought (CoT) trajectories."
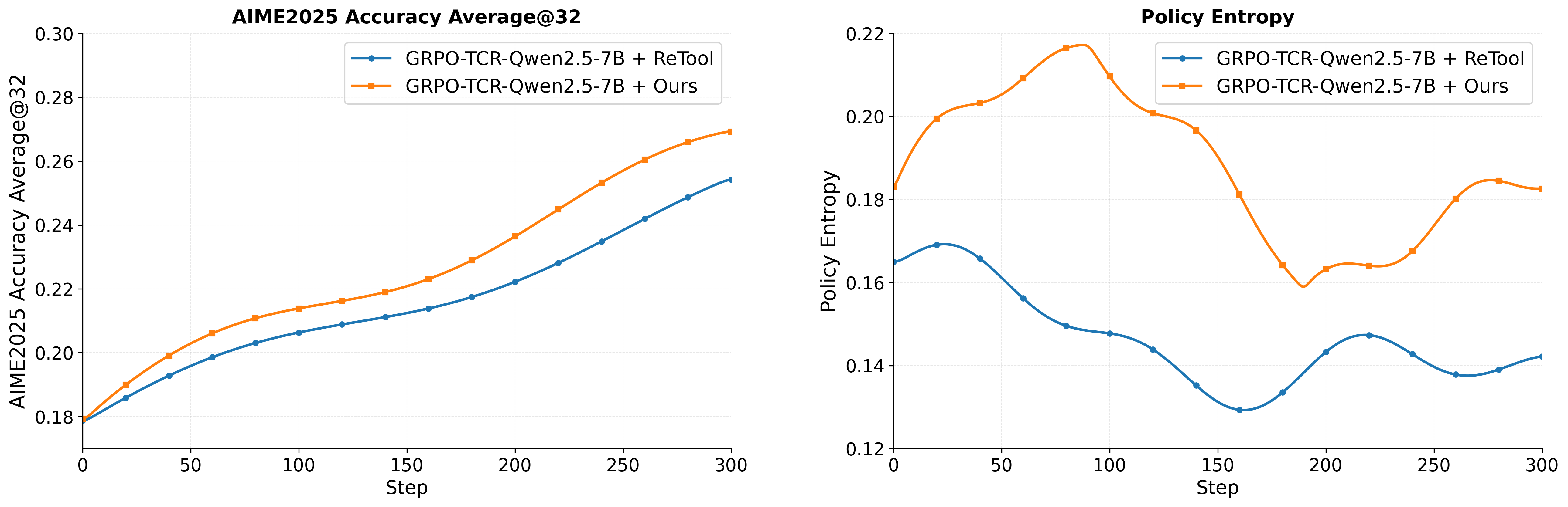
- Clip higher: Using a larger clipping range in PPO/GRPO to encourage exploration and prevent premature policy collapse. "such as clip higher, overlong reward shaping, and maintaining adequate policy entropy could improve the training efficiency."
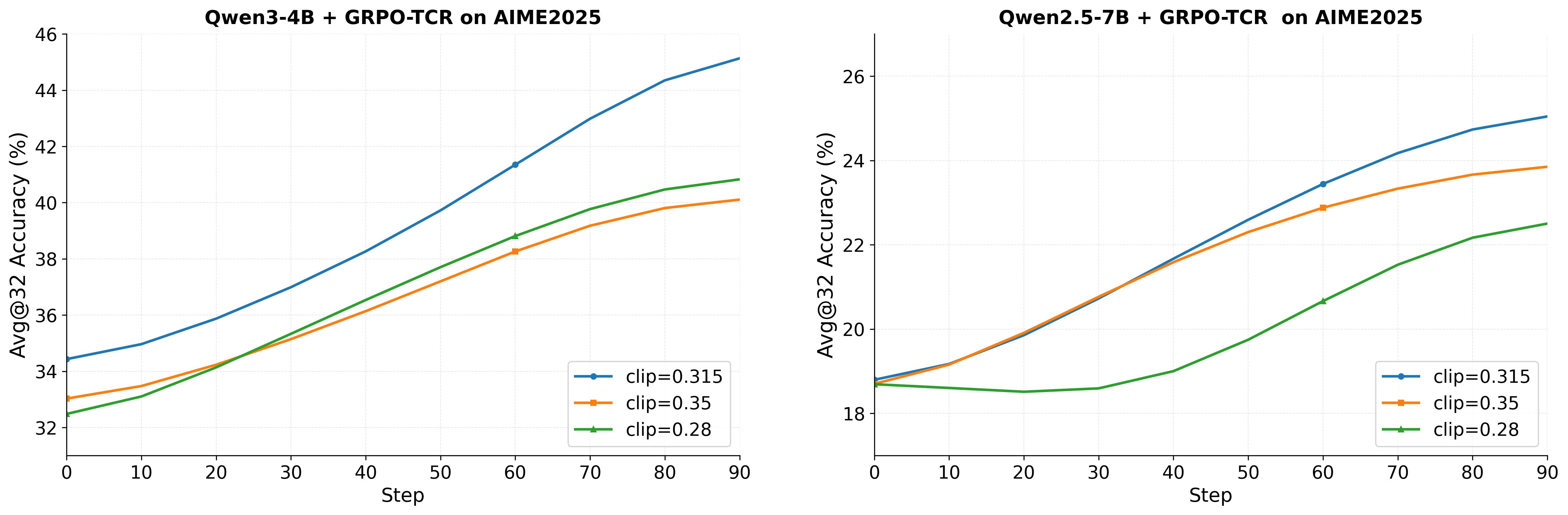
- Clip upper bound: The upper limit of the probability ratio clipping window that controls how far the policy can deviate from the reference. "we conduct experiments with different clip upper bounds, including 0.28,0.315,0.35"
- Clipping Strategy: The technique of constraining policy updates by clipping the importance ratio to stabilize training. "3) Clipping Strategy."
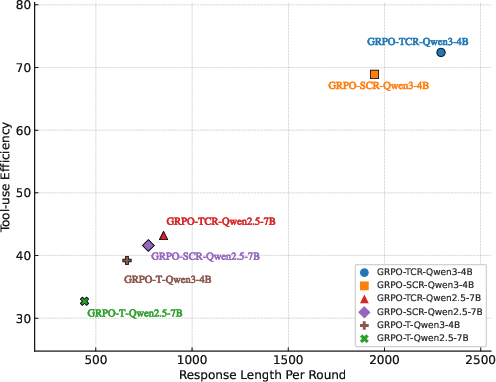
- Composite reward: A reward that combines multiple terms (e.g., outcome accuracy and tool-use efficiency). "We optimize a composite reward that sums an outcome term (solution accuracy) and a tool-use term (number of invocations), with the tool bonus clipped"
- Conservative clipping: A restrictive clipping configuration that tightly limits policy shifts and can suppress exploration. "or conservative clipping."
- Deliberative Mode: A reasoning strategy emphasizing longer internal thinking with fewer, more targeted tool calls. "Deliberative Mode (deliberate-think + fewer tool calls)."
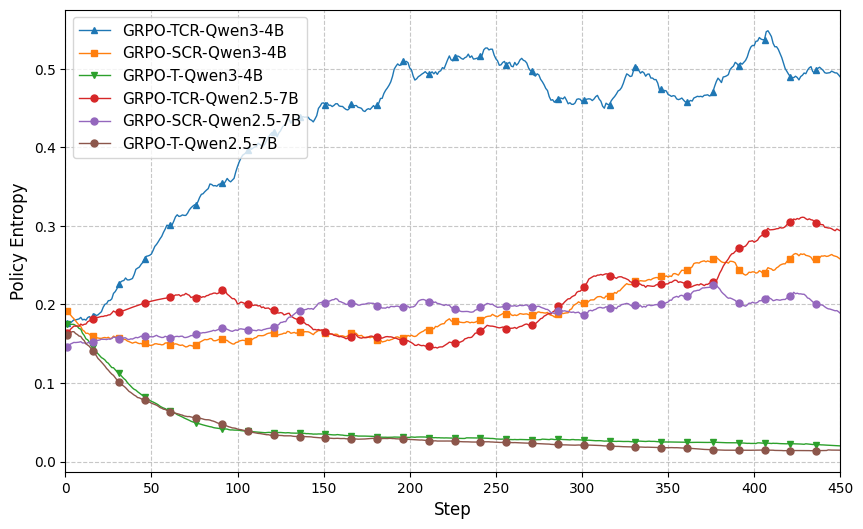
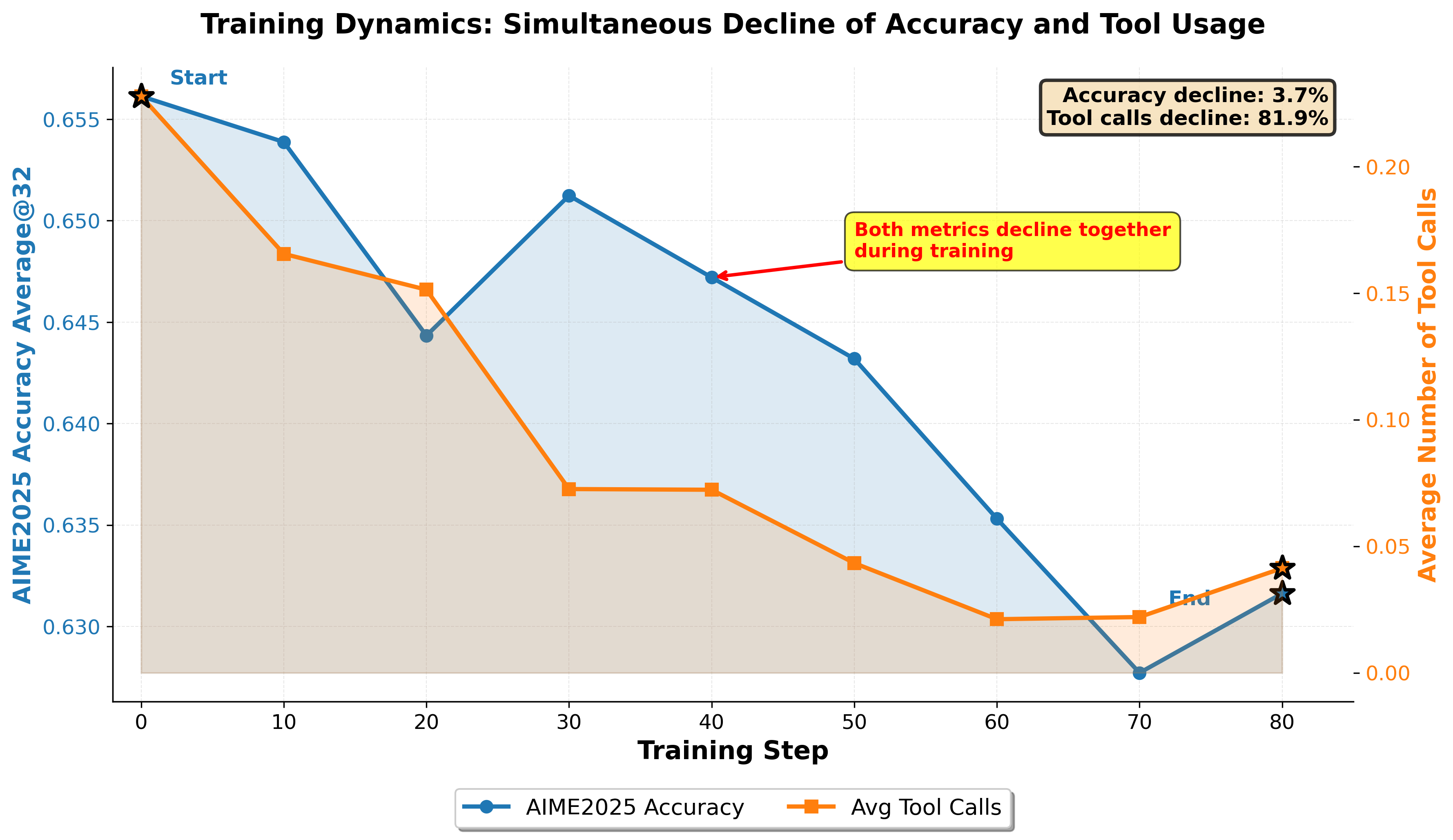
- Entropy collapse: Premature reduction of policy entropy leading to reduced exploration and potential suboptimal convergence. "GRPO-T exhibits an early entropy collapse"
- Entropy spikes: Sudden increases in policy entropy, often after tool calls, indicating exploratory uncertainty. "ARPO \citep{dong2025arpo} observes entropy spikes after tool calls"
- Explorationâexploitation trade-off: The balance between seeking new strategies (exploration) and leveraging known good strategies (exploitation). "revealing how they capture the explorationâexploitation trade-off and highlight performance bottlenecks."
- GRPO: A PPO-style policy optimization algorithm variant used for training reasoning agents. "Here we utilize GRPO \citep{shao2024deepseekmath-grpo} as our baseline algorithm."
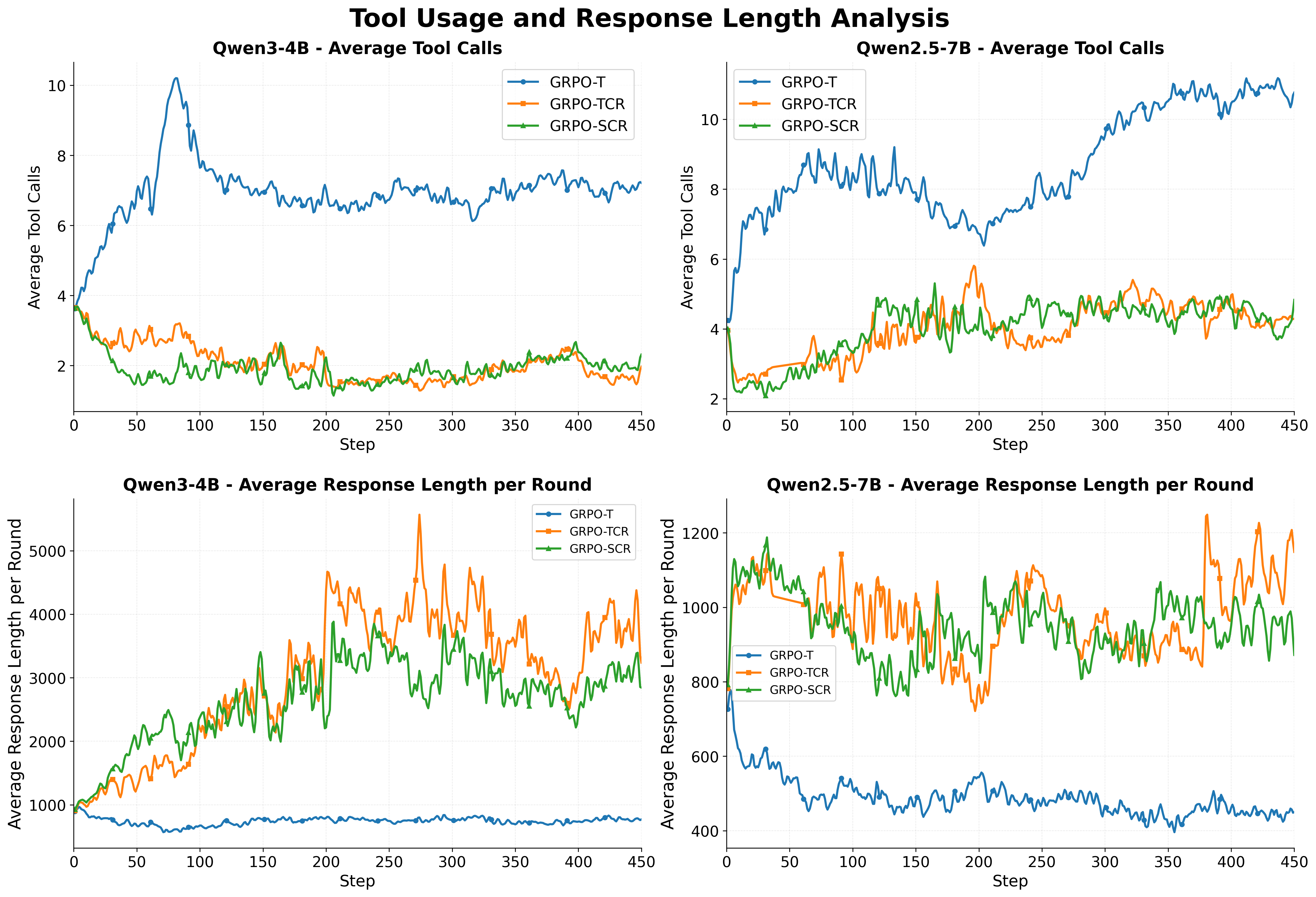
- GRPO-SCR: A training recipe using Sequence-level loss, Clip higher, and overlong Reward shaping with GRPO. "GRPO-SCR: We incorporate Sequence-level loss, Clip higher, overlong Reward shaping techniques with GRPO."
- GRPO-T: The baseline GRPO recipe variant used for comparison in experiments. "GRPO-T: we adhere to the implementation in \citep{shao2024deepseekmath-grpo}, and change the sample-level loss to token-level, and we take this recipe as our baseline."
- GRPO-TCR: A training recipe using Token-level loss, Clip higher, and overlong Reward shaping with GRPO. "GRPO-TCR: We incorporate Token-level loss, Clip higher and overlong Reward shaping techniques with GRPO."
- Importance ratio: The ratio of current policy probability to reference policy probability used in the clipped objective. " is the importance ratio related to the type of loss aggregation granularity"
- KL divergence: A measure of divergence between the current policy and a reference policy, used as a regularizer. "r_\phi and $\mathbb{D}_{\mathrm{KL}$ denote the reward function and KL divergence respectively."
- KL regularization: Penalizing deviation from a reference policy via a KL term to stabilize updates. "while others suppress it through strong KL regularization \citep{cheng2025reasoning}"
- Loss aggregation granularity: The level (token or sequence) at which losses are aggregated during optimization. "For loss aggregation granularity, we compare two kinds of loss"
- maj@k: A stability metric measuring consistency via majority voting across k samples. "and maj@32 (performance stability)."
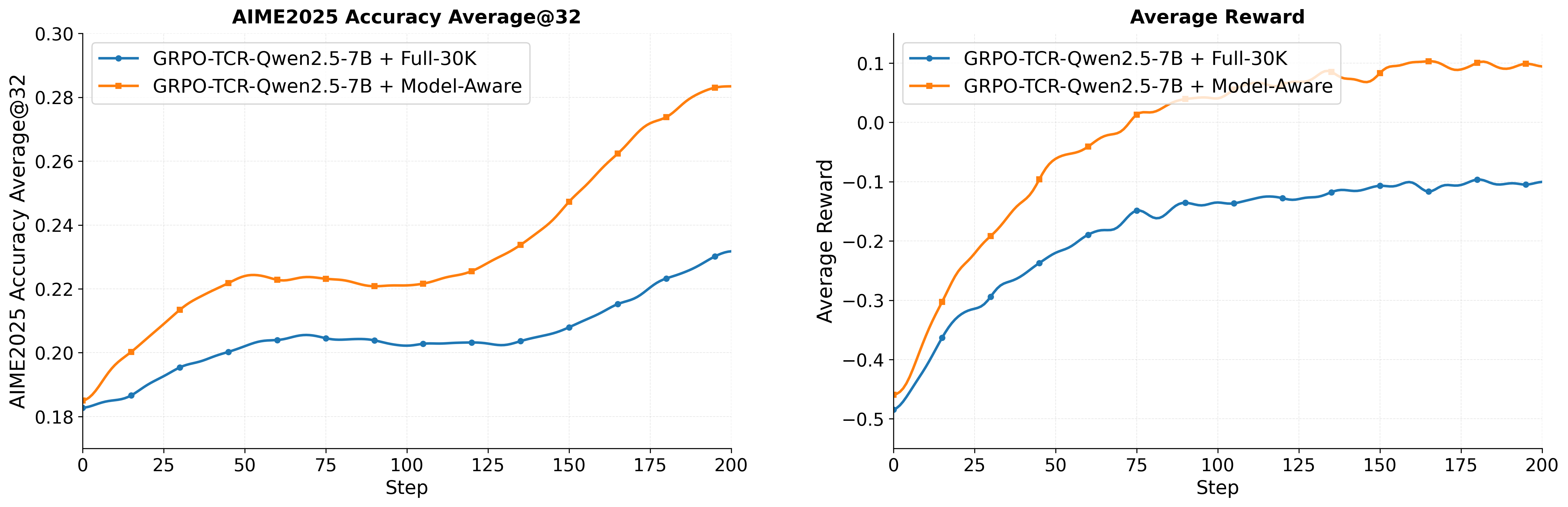
- Model-aware dataset: A training set curated to match task difficulty with the model’s current capability. "we construct a model-aware RL dataset that adapts the task distribution to the capacity of the model."
- On-policy rollout sampling: Collecting trajectories from the current policy during training, as opposed to off-policy data. "inefficient on-policy rollout sampling"
- Overlong reward shaping: A length-penalization scheme that discourages overly long outputs while preserving a smooth learning signal near limits. "overlong reward shaping gives zero reward when the output length is within a safe budget"
- Pass@k: The probability of solving a task at least once in k sampled attempts. "We evaluate using average@32 (overall agent performance), pass@32 (ability boundary \citep{deng2025trial-error}), and maj@32 (performance stability)."
- Policy entropy: The entropy of the policy’s action distribution, indicating exploration level. "maintaining adequate policy entropy could improve the training efficiency."
- Policy LLM: The trainable LLM that represents the acting policy in RL. "π_\theta$ represents the policy LLM"</li> <li><strong>Reactive Mode</strong>: A reasoning strategy characterized by short internal thinking and frequent tool calls. "Reactive Mode (short-think + frequent tool calls)"</li> <li><strong>Reference LLM</strong>: A fixed model used to anchor the current policy via a KL penalty. "π_{\mathrm{ref}$ is the reference LLM"
- Reward hacking: Exploiting imperfections in the reward function to achieve high reward without truly solving the task. "tool abuse reward hacking"
- Reward shaping: Modifying the reward function to guide learning efficiency or stability. "2) Reward Shaping,"
- Rollout distribution: The distribution over reasoning trajectories and outputs generated by the policy. "The rollout distribution factorizes as"
- Self-Contained Reasoning: A setting where the model solves tasks without external tools. "Self-Contained Reasoning"
- Sequence-level loss: An objective aggregated per sequence, often using sequence-level importance ratios. "and is the sequence-level loss"
- SFT (supervised fine-tuning): Fine-tuning a model on labeled data before RL. "Beyond pre-training and supervised fine-tuning (SFT) stages"
- Stitch-style data synthesis: Constructing trajectories by patching tool outputs into internal reasoning steps. "stitch-style data synthesis"
- Token-level loss: An objective aggregated per token, giving uniform per-token contributions to the update. "where is the token-level loss"
- Tool-call feedback: Information returned by external tools during the reasoning rollouts. "integrates tool-call feedback during reasoning."
- Tool-use trajectories: End-to-end sequences that include when, why, and how tools are invoked. "Replacing stitched synthetic trajectories with real end-to-end tool-use trajectories yields a far stronger SFT initialization"
- Trajectory verification: Post-hoc checking and filtering of collected trajectories for correctness/quality. "After trajectory verification, we discard the problems"
Collections
Sign up for free to add this paper to one or more collections.

