SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
Abstract: Equipping LLMs with complex, interleaved reasoning and tool-use capabilities has become a key focus in agentic AI research, especially with recent advances in reasoning-oriented (``thinking'') models. Such capabilities are key to unlocking a number of important applications. One such application is Deep Research (DR), which requires extensive search and reasoning over many sources. Our work in this paper focuses on the development of native Autonomous Single-Agent models for DR featuring minimal web crawling and Python tool integration. Unlike multi-agent systems, where agents take up pre-defined roles and are told what to do at each step in a static workflow, an autonomous single-agent determines its next action dynamically based on context, without manual directive. While prior work has proposed training recipes for base or instruction-tuned LLMs, we focus on continual reinforcement learning (RL) of reasoning-optimized models to further enhance agentic skills while preserving reasoning ability. Towards this end, we propose a simple RL recipe with entirely synthetic data, which we apply to various open-source LLMs. Our best variant SFR-DR-20B achieves up to 28.7% on Humanity's Last Exam benchmark. In addition, we conduct key analysis experiments to provide more insights into our methodologies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to teach a single AI “researcher” to think, plan, and use simple tools (like web search, webpage reading, and Python code) to answer tough questions. The authors build a training recipe that uses reinforcement learning (a way of learning from trial and error) so the AI can decide its own next steps—like a student doing research—without being told exactly what to do at each step.
What questions were they trying to answer?
The authors focused on a few simple questions:
- Can a single, self-directed AI agent do deep online research well using only a few basic tools?
- How can we train such an agent so it plans better, avoids getting stuck, and still thinks clearly?
- What training tricks keep long, multi-step research sessions stable and effective?
- Does this approach actually beat strong existing systems on hard benchmarks?
How did they build and train their research agent?
Think of the agent like a smart student doing a big project. It can:
- search the web,
- open and read a webpage,
- run short Python code snippets like a calculator.
It must decide, step by step, what to do next—search more, read a different section, write some code, or produce an answer.
The tools (kept simple on purpose)
- search_internet: Ask a search engine and get the top results.
- browse_page: Open a page and read a section of its text (as plain content—links are disabled to keep things controlled).
- code_interpreter: Run small, stateless Python programs (no internet, no installing packages).
Why so simple? If the tools do too much, the agent doesn’t learn real skills. If they’re just enough, the agent is challenged and learns to plan wisely.
Single agent vs multi-agent
- Single-agent: One model does everything—plans, searches, reads, codes, and answers. It chooses actions based on the situation.
- Multi-agent: Many models play separate roles (planner, coder, researcher, etc.) following a preset script.
The authors prefer single-agent training because it’s more flexible and can generalize better to new tasks. Later, such a strong single agent can even be used as a building block inside larger systems.
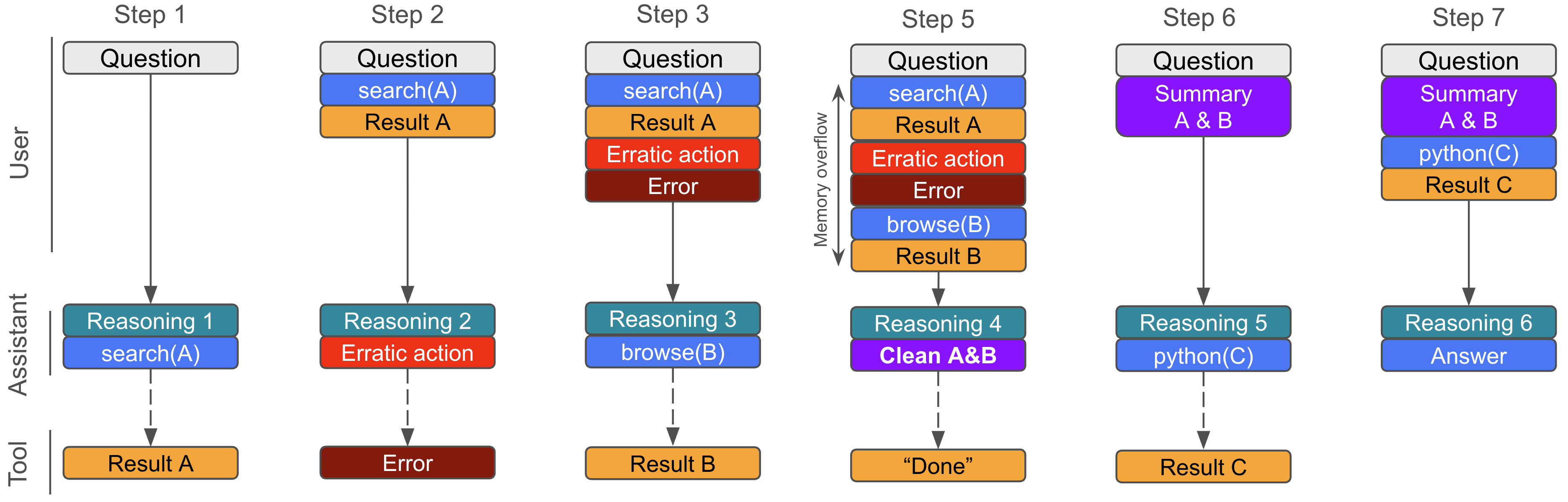
The agent’s workflow and “memory”
In normal chat, multi-step conversations can get long and messy. The authors found a better way for certain models: pack the whole history (previous searches, page snippets, code outputs) into one “context” for the next step. That keeps the model in a mode it’s best at: answering a single, context-rich prompt.
But the context can overflow. To fix this, they give the agent a clean_memory tool. When the history is too long, the agent summarizes and keeps only what’s important—like tidying a notebook so it doesn’t run out of pages.
They also add fault tolerance: if the AI formats a tool call wrong, the system tries to fix it or explains the error so the AI can retry.
How they created practice tasks (synthetic data)
They made their own challenging training data because many public datasets are now too easy for modern models. They built two kinds of tasks:
- Short answers: multi-step questions that require searching and connecting facts; also math and coding problems.
- Long reports: open-ended prompts where the agent must research and write a structured answer with citations.
They verified that these tasks are genuinely hard—even strong proprietary systems don’t get them all right.
How they taught it: reinforcement learning with smart stabilizers
Reinforcement learning (RL) is like practicing with feedback:
- The agent tries to solve a problem by taking actions (search, read, code).
- At the end, it gets a reward: good if the answer is correct or the report is high quality; bad if not.
- The model then updates itself to make better decisions next time.
Key ideas they used to keep training stable and effective:
- Length-normalized rewards: Long research runs create many action steps. Without care, the model can learn a bad habit: make many pointless tool calls to “dominate” the training signal. To prevent this, they scale the learning signal so long trajectories don’t unfairly overshadow shorter (but better) ones. This stops the model from spamming tools.
- Trajectory filtering: They throw out broken or low-quality attempts (like sessions that crashed or had invalid outputs) to keep learning on track.
- Partial rollouts: If the agent got partway through a problem, they reuse those midpoints as starting points. This gives the model more practice on tricky “in the middle” situations, not just from the beginning.
- Reward modeling: For short answers, a separate checker model decides if the final answer matches the ground truth. For long reports, the checker scores multiple aspects (factuality, writing, citation quality) and ranks the best one.
- Fair evaluation: They block the agent from visiting sites that might contain benchmark answers or spoilers, so it can’t cheat by reading posted solutions.
What did they find?
They trained three versions on top of strong open models:
- SFR-DR-8B (based on Qwen3-8B),
- SFR-DR-32B (based on QwQ-32B),
- SFR-DR-20B (based on gpt-oss-20b).
Main results (Pass@1, i.e., first try accuracy, text-only settings):
- FRAMES (fact-checking with browsing): up to 82.8% (SFR-DR-20B).
- GAIA (general assistant tasks with browsing): up to 66.0% (SFR-DR-20B).
- Humanity’s Last Exam (hard reasoning): 28.7% (SFR-DR-20B).
Why this matters:
- The 20B model, a single agent with simple tools, beats many open-source baselines and is competitive with some proprietary systems. It also strongly improves over its own base model (gpt-oss-20b).
- The approach works across different model families and sizes.
They also ran careful studies to understand what helped:
- Single-turn-style prompting (packing all context into the “user side”) often works better than standard back-and-forth chat for certain models. It boosted scores because those models were trained to excel at single-shot reasoning.
- Length-normalized RL stopped the model from doing silly things like endlessly repeating tool calls. Performance improved, and training became more stable.
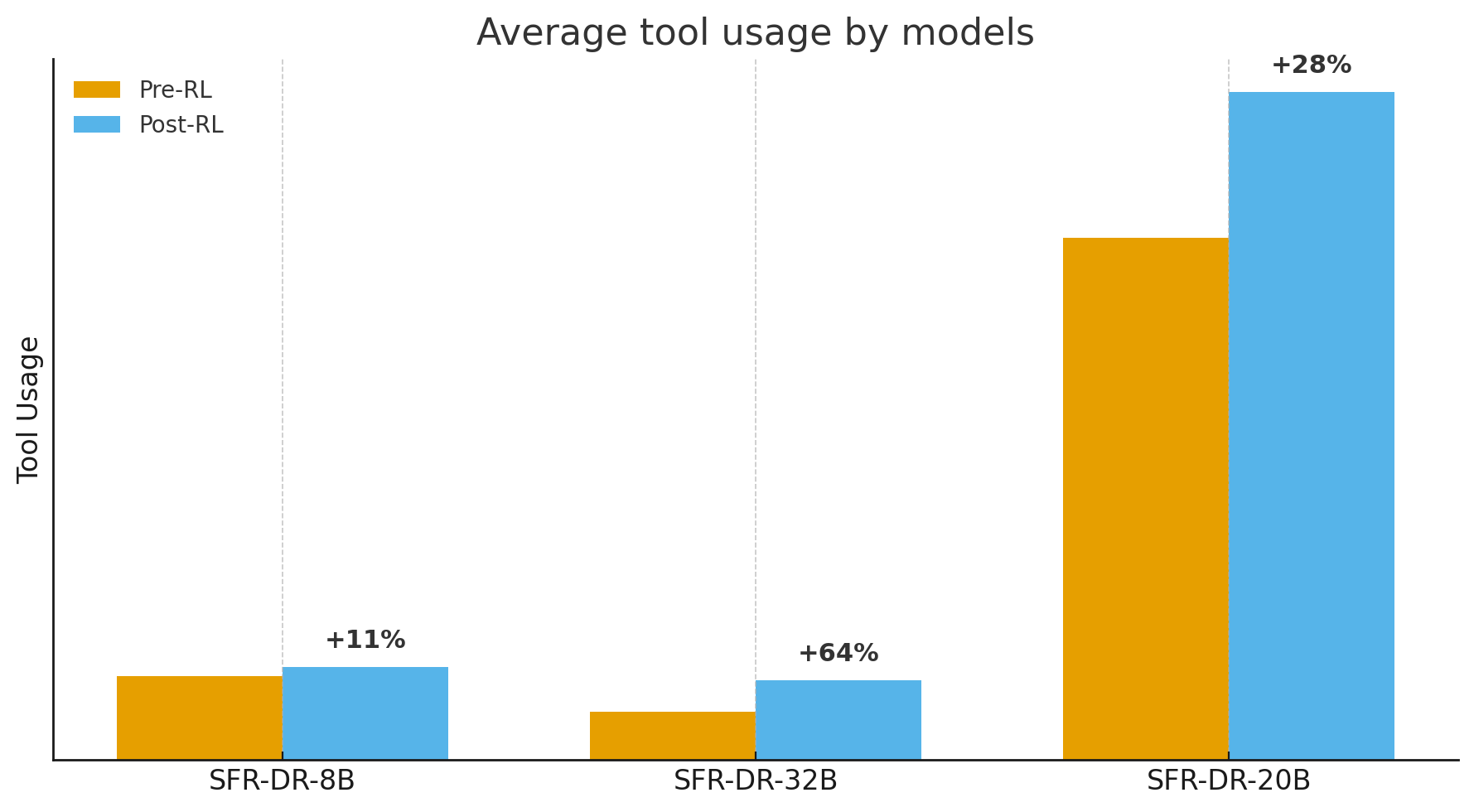
- More tool calls isn’t always better. It helps only when the calls are diverse and purposeful.
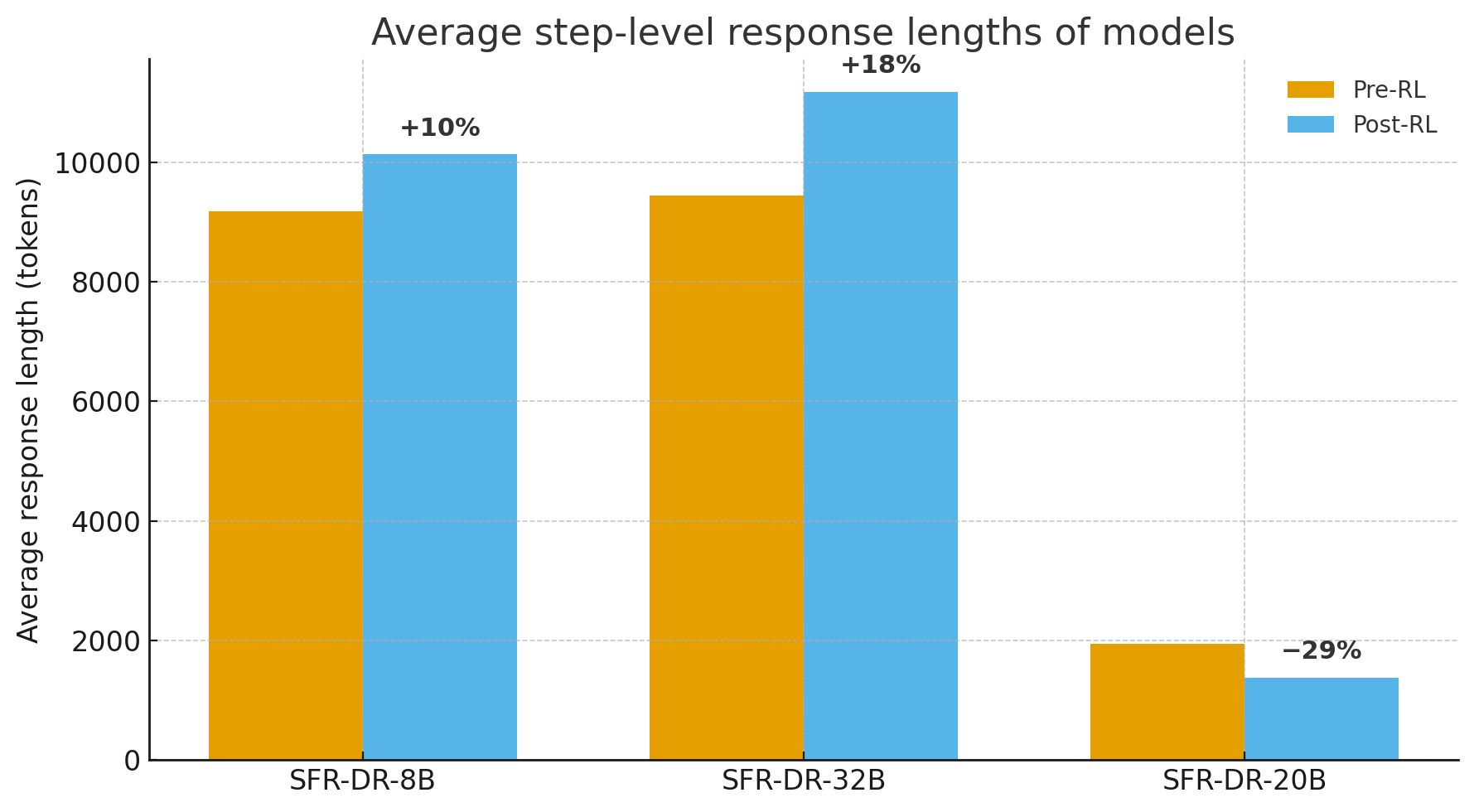
- The gpt-oss-20b agent learned to use tools more and write shorter, more efficient “thinking” text per step, which likely helped speed and reliability.
Why does this matter?
This work shows a practical, scalable path to train one AI to handle complex research tasks without relying on complicated multi-agent scripts. The agent learns to:
- plan its own steps,
- use just three simple tools effectively,
- manage its own memory,
- stay stable across long, multi-step sessions.
That’s useful for many real-world jobs: technical support, investigative research, writing reports with citations, data gathering, and solving scientific or math problems that require checking sources and running small calculations.
Key takeaways in plain words
- One smart AI “researcher” can learn to do deep web research with only search, read, and code tools.
- Training it with the right kind of reinforcement learning (especially length-normalized feedback) keeps it from getting stuck or spamming tools.
- Reformulating the conversation so the model always sees one rich, up-to-date “context” can make it think better step after step.
- The resulting agent is strong on tough benchmarks and beats many open systems of similar size.
- This approach is a solid foundation for future AI assistants that need to be reliable, explainable, and good at multi-step reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Data transparency and release: The synthetic dataset creation process (prompt templates, seed sources, topic coverage, difficulty calibration, filtering) is under-specified; it’s unclear whether data and generation code will be released to enable replication and benchmarking.
- Reward model specification: The verifier LLM(s) and prompts used for semantic-consistency and long-form grading are not fully detailed; the paper does not assess cross-verifier robustness, agreement, or sensitivity to the choice of judge.
- Reward misspecification risks: There is no analysis of reward hacking or exploitation (e.g., optimizing for the judge rather than true task success), nor adversarial tests to probe judge reliability and safety against gaming.
- Lack of human evaluation: No human ratings are reported for factuality, citation quality, and report quality, leaving uncertainty about alignment between LLM-judged scores and human judgments.
- Intermediate rewards and credit assignment: The method uses only terminal rewards with uniform per-step advantages; no exploration of intermediate rewards (e.g., page relevance, evidence extraction, plan quality) or step-dependent credit assignment is provided.
- Theoretical underpinnings of length normalization: Dividing the advantage by trajectory length stabilizes training empirically, but its effect on bias/variance and on tasks that inherently require long trajectories is not theoretically analyzed.
- Comparison to alternative RL objectives: There is no head-to-head evaluation against PPO with value functions, GAE, off-policy methods, or recent agentic RL algorithms with trajectory-level baselines and better credit assignment.
- Partial rollout reuse: Treating partial rollouts as independent initial states may introduce off-policy bias; no analysis of its statistical implications or comparison to continuing rollouts under the latest policy.
- Hyperparameter sensitivity: Key RL hyperparameters (group size G, clipping parameters, temperatures/top-p for exploration, trajectory filters, length penalties) are not systematically ablated for stability and performance sensitivity.
- Memory management efficacy: The clean_memory tool design is not evaluated for retention vs. forgetting trade-offs; no ablations on memory thresholds, summarization quality, or information-loss impact on downstream accuracy.
- Omitted CoTs across steps: The choice to discard earlier chain-of-thought tokens is not studied for potential loss of cross-step rationale continuity, auditability, and error propagation.
- Tool constraints vs. real-world generalization: Stripping hyperlinks and forbidding clickable browsing create a static, search-only environment; the paper does not test transfer to realistic, interactive browsers or dynamic sites (pagination, logins, JS-driven content).
- Stateless code execution: The interpreter’s statelessness and package restrictions limit multi-step coding workflows; there is no evaluation of how much this constraint caps agent performance or how stateful execution would change outcomes.
- Tool curriculum and diversity: The impact of adding/removing tools (e.g., clickable browsing, structured extraction, table processing, citation resolvers, PDF parsers) is not explored; a tool-ablation and tool-curriculum study is missing.
- Prompt-injection and web adversary robustness: The system’s resilience to prompt injection, malicious content, and adversarial pages is not evaluated or defended (e.g., content sanitization, isolation, instruction hierarchy).
- Safety and security audit: Beyond library restrictions in the code tool, security posture (filesystem sandboxing details, network isolation, rate limiting, safe browsing policies) is not audited or stress-tested.
- Contamination safeguards beyond blocklists: The blocklist approach may not catch all leakage; there is no measurement of residual contamination risk, nor verification that training data avoids benchmark leakage.
- Evaluation breadth and depth: Results are primarily Pass@1 on three benchmarks; missing are per-category breakdowns, error analyses, statistical significance, variance across seeds, and calibration of gains vs. compute.
- Cost, efficiency, and latency: There are no measurements of inference-time latency, GPU-hours, cost per query, or Pareto trade-offs between tool-call budget, token usage, and accuracy.
- Long-form report evaluation gap: While long-form report generation is part of training, there is no external benchmark or human study evaluating long-form performance and citation fidelity.
- Citation verification: “Citation quality” scoring is mentioned, but the method for checking citation correctness, auditable provenance, and link validity is not described or evaluated.
- Generalization claims: The claim that single-agents generalize better is not tested against out-of-distribution tasks, unseen tool APIs, or new web environments; transfer to multi-agent systems as sub-agents is asserted but not demonstrated.
- Scaling behavior: No model/data/compute scaling trends are reported (e.g., how performance grows with model size, RL steps, or synthetic data volume) to guide future resource allocation.
- Fairness of baseline comparisons: Re-running baselines with a blocklist may change their original settings; equivalence of tools, prompts, search APIs, and inference parameters is not guaranteed, complicating fairness.
- Multi-modal and non-text inputs: The approach is text-only; extension to images, tables, PDFs, or mixed modalities common in web research is untested.
- Stopping criteria and looping: The policy for deciding when to stop researching and answer is not explicitly modeled; beyond length-normalization and filtering, loop-avoidance strategies are not formalized or compared.
- Interpretability and auditability: Omitting prior CoTs reduces traceability of reasoning; no structured evidence graph or explicit retrieval-and-citation tracking is provided to support auditing.
- Ethical and legal considerations: Web crawling compliance (robots.txt, rate limits, TOS, copyright), data provenance, and attribution practices are not discussed.
- Infrastructure reproducibility: Details on caching policies, failure recovery configurations, and potential cache-induced leakage or bias across rollouts are not evaluated for reproducibility risks.
Practical Applications
Immediate Applications
Below are applications that can be deployed today using the paper’s single-agent scaffolding, minimal tool set (web search, static page browsing with sections, stateless Python), memory self-management, fault-tolerant parsing, and the length-normalized RL recipe. Each item includes suggested sectors and key dependencies.
- Autonomous research copilot for analysts
- What it does: Plans multi-step web research, triages sources, extracts facts, compiles concise answers with citations, and optionally runs quick computations in a sandbox.
- Sectors: finance, consulting, market intelligence, sales enablement.
- Potential products/workflows: “Analyst Desk” sidebar in BI/CRM; scheduled research briefs; competitor/product landscape summaries.
- Assumptions/dependencies: Reliable search API; compliant web scraping; content rights; caching; human-in-the-loop for high-stakes briefs.
- Literature review and evidence synthesis assistant
- What it does: Multi-hop retrieval over academic sources, synthesizes related work, produces structured summaries with citations and rubrics.
- Sectors: academia, pharma R&D, public health.
- Potential tools/workflows: “LitSurvey Pro” that tracks questions, sources, and grading rubrics; automated PRISMA-like checklist generation.
- Assumptions/dependencies: Access to scholarly search or institutional databases; citation verification; paywall handling; domain-specific blocklists to avoid contaminated content.
- Regulatory and policy monitoring digest
- What it does: Monitors official websites, captures updates, compares versions, and writes compliance digests with citations.
- Sectors: finance (AML/KYC), healthcare (HIPAA), energy, privacy (GDPR/CCPA).
- Potential products/workflows: “Compliance Watch” with scheduled digests; change impact summarization; internal wiki updates.
- Assumptions/dependencies: Allowed scraping; precise source tracking; human compliance review; auditable logs.
- Vendor and counterparty due diligence
- What it does: Conducts OSINT across trusted sites, compiles risk signals, summarizes litigation/regulatory actions, and outputs a structured risk memo.
- Sectors: procurement, enterprise risk, insurance.
- Potential tools/workflows: Risk memo generator with templated rubrics; red-flag trackers.
- Assumptions/dependencies: Source whitelists; reproducible browsing traces; fact-check checkpoints.
- Data journalism and fact-checking aide
- What it does: Multi-hop verification across credible sources; creates claims-and-evidence tables; sandboxed code for simple number checks.
- Sectors: media, NGOs.
- Potential tools/workflows: Fact-check queue; evidence collection workspace with cached pages; editorial export.
- Assumptions/dependencies: Editorial standards; provenance storage; manual review before publication.
- Customer support and technical issue synthesis
- What it does: Gathers information from docs/forums, correlates symptoms, proposes probable cause trees, and drafts user-facing responses with citations.
- Sectors: software, devices, cloud services.
- Potential tools/workflows: Tier-2 assistant; knowledge-gap reports; auto-backlog item creation.
- Assumptions/dependencies: Access to internal KB/forums; PII/PHI safeguards; sandboxed code interpreter for benign log snippets.
- Patent and prior-art search assistant
- What it does: Searches patents and publications, links claims to references, drafts novelty/overlap notes with citations.
- Sectors: legal IP, R&D.
- Potential tools/workflows: Prior-art memo templates; citation evidence bundles.
- Assumptions/dependencies: Patent databases access; careful legal review; accurate citation mapping.
- Threat intelligence and OSINT aggregation
- What it does: Finds indicators of compromise (IoCs) and reports from trusted feeds, compiles timelines, and annotates sources.
- Sectors: cybersecurity, incident response.
- Potential tools/workflows: Daily IoC brief; campaign summary builder.
- Assumptions/dependencies: Source whitelists; false-positive handling; secured environment.
- Teaching and study coach for research assignments
- What it does: Guides students through multi-source research, promotes source evaluation, and provides structured outlines with citations.
- Sectors: education.
- Potential tools/workflows: Classroom “research mentor” with rubrics and progress tracking; plagiarism-aware citation export.
- Assumptions/dependencies: Age-appropriate source filters; academic integrity policies; teacher oversight.
- Single-agent “deep research” sub-agent in multi-agent stacks
- What it does: Operates as a specialized research component in broader agentic workflows (planner–researcher–writer), simplifying orchestration.
- Sectors: software, enterprise automation.
- Potential tools/workflows: Drop-in “research node” with memory tools and fault-tolerant parsing; unified audit logs.
- Assumptions/dependencies: Clear interfaces; tool budget constraints; orchestration policies.
- Cost-efficient long-context management add-on
- What it does: Uses self-managed memory and clean_memory tooling to keep prompts within budget while preserving salient facts.
- Sectors: any LLM product with long-horizon tasks.
- Potential tools/workflows: Memory cleaner component for LangChain/LlamaIndex/SGLang pipelines.
- Assumptions/dependencies: Accurate salience selection; token accounting; regression tests to prevent information loss.
- RLVR training recipe for agent stability
- What it does: Applies length-normalized advantages and trajectory filtering to stabilize long-horizon agent training beyond web research.
- Sectors: software agents, workflow automation, computer-use agents.
- Potential tools/workflows: “Agent RL SDK” with group rollouts, partial rollout reuse, verifier scaffolds.
- Assumptions/dependencies: Compute and GPU orchestration (co-location/offloading as described); tuned verifiers; careful reward design.
- Governance and evaluation harness with contamination controls
- What it does: Enforces domain blocklists, logs tool traces, caches results, and conducts fair, repeatable evaluations.
- Sectors: MLOps, AI governance, benchmarking orgs.
- Potential tools/workflows: Standardized “clean browsing” harness; benchmark replay with cache and blocklist.
- Assumptions/dependencies: Maintained blocklists; up-to-date cache invalidation; reproducible seeds.
Long-Term Applications
These require further research, scaling, domain integrations, or stronger guarantees (factuality, safety, compliance) before broad deployment.
- Clinical guideline retrieval and evidence-linked summaries
- What it could do: Retrieve latest guidelines/trials, reconcile conflicts, and generate decision support notes with linked evidence.
- Sectors: healthcare.
- Potential products/workflows: “Evidence Companion” for clinicians with confidence scores and audit trails.
- Assumptions/dependencies: Regulated medical databases; clinical validation; strict hallucination control; liability frameworks.
- Legal research and draft memoranda with pinpoint citations
- What it could do: Traverse case law/statutes, build argument maps, and draft memos with precise citations and quote-level evidence.
- Sectors: legal.
- Potential tools/workflows: Motion/memo drafting assistant; Shepardizing checks; contradiction detection.
- Assumptions/dependencies: Access to premium legal corpora; verifiable citation matching; human attorney review.
- Autonomous compliance report generation with embedded analytics
- What it could do: Continuously monitor obligations, execute lightweight analytics in a secured sandbox, and draft regulator-ready reports.
- Sectors: finance, energy, telecom.
- Potential products/workflows: End-to-end “RegOps” agent with change detection and response drafting.
- Assumptions/dependencies: Statefulness beyond stateless code; secure data access; SOC-compliant audit; regulator acceptance.
- Scientific discovery and hypothesis generation assistant
- What it could do: Propose hypotheses from literature, design simple analyses, and run reproducible code to test preliminary claims.
- Sectors: academia, biotech, materials.
- Potential tools/workflows: Lab-note style agent; experiment suggestion and evidence map.
- Assumptions/dependencies: Expanded code runner (packages, datasets); reproducibility layers; lab HIL validation.
- Autonomous software research and diagnosis agent
- What it could do: Investigate issues via docs/forums, run constrained test scripts, and propose patches or workarounds.
- Sectors: software engineering, DevOps.
- Potential tools/workflows: Issue triage and RCA assistant; safe sandboxes; staged remediation plans.
- Assumptions/dependencies: Statefulness and richer tool access; rigorous safety and isolation; code-review gates.
- Corporate knowledge “deep RAG” with internal + external synthesis
- What it could do: Blend internal repositories with web sources, manage long-horizon contexts, and produce policy- or product-ready briefs.
- Sectors: enterprise knowledge management.
- Potential tools/workflows: Cross-silo research with access controls; lineage tracking; continuous updates.
- Assumptions/dependencies: Access controls, privacy guarantees; content governance; deduplication and staleness handling.
- National-security grade OSINT with multilingual and deception resistance
- What it could do: Aggregate global signals, handle cross-lingual sources, resist manipulation, and maintain robust provenance.
- Sectors: public sector, defense, crisis response.
- Potential tools/workflows: Incident fusion center assistants; adversarial monitoring.
- Assumptions/dependencies: Bias/propaganda detection; adversarial robustness; ethical and legal boundaries.
- Standards and audits for web-browsing AI agents
- What it could do: Establish RL-with-verifiable-reward (RLVR) audit trails, reproducible evaluation with blocklists, and trajectory-level accountability.
- Sectors: policy, standards bodies, regulators.
- Potential tools/workflows: Certification suite for browsing agents; standardized reward schemas; shared contamination protocols.
- Assumptions/dependencies: Sector consensus; third-party audit infrastructure; secure logging standards.
- On-prem, air-gapped deep-research agents
- What it could do: Run research over proprietary corpora with local tools and co-located inference/training for privacy-by-design deployments.
- Sectors: highly regulated industries (defense, healthcare, finance).
- Potential tools/workflows: On-prem SGLang-like stack; model offloading/orchestration; local verifiers.
- Assumptions/dependencies: Hardware capacity; licensed models; private search index; strict telemetry controls.
- Generalized agentic RL for long-horizon tool use (beyond web)
- What it could do: Port the length-normalized RL + trajectory filtering to computer-use agents, robotics task planners, and workflow automation.
- Sectors: robotics, enterprise automation, UI automation.
- Potential tools/workflows: Multi-step planners with verifiable subgoals; curriculum via synthetic tasks.
- Assumptions/dependencies: Verifiable reward design for new domains; safe tool controllers; sim-to-real gaps (for robotics).
Cross-cutting Assumptions and Dependencies
- Access and licensing: Availability of the trained checkpoints (e.g., SFR-DR-20B), and commercial licensing of base models (QwQ/Qwen/gpt-oss) where applicable.
- Tool constraints: Stateless Python limits complex analytics; browsing design (no link clicking) may require richer tools for some domains.
- Safety and accuracy: Hallucination risks persist; critical applications need human oversight, verifier ensembles, and strong provenance.
- Compliance: Respect robots.txt/ToS, copyright, privacy/PII constraints; domain-specific legal review.
- Infrastructure: GPUs for inference and RL; high-throughput serving (e.g., SGLang), caching, and robust fault tolerance as described.
- Evaluation and governance: Maintain contamination blocklists; store traceable tool logs; periodic red-teaming and regression tests.
Collections
Sign up for free to add this paper to one or more collections.