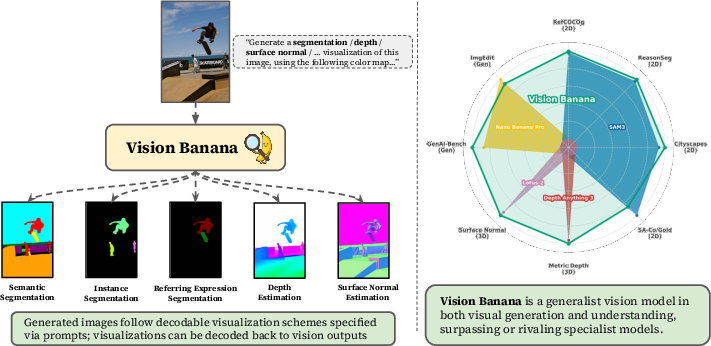
Image Generators are Generalist Vision Learners
Abstract: Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.


































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but big question: if a computer is great at making pictures, does that mean it also understands what’s in pictures? The authors show that the answer is yes. They take a powerful image generator and teach it, with a small amount of extra training, to “answer” vision questions by producing special images. This single model, called Vision Banana, ends up doing many different vision tasks really well—sometimes better than expert models—while still staying good at making and editing images.
What were they trying to find out?
The researchers wanted to test two ideas:
- Do image generators secretly learn a lot about the visual world when they learn to create images?
- If we give them a few instructions and examples, can they use that knowledge to solve many vision tasks (like finding objects, measuring depth, or understanding 3D shapes) without losing their image-creation skills?
How did they do it?
They started with a strong image generator called Nano Banana Pro. Then they did “instruction tuning,” which is like teaching the model to follow very clear instructions and output answers in a neat, checkable format.
Here’s the clever part: instead of asking the model to output numbers or labels directly, they asked it to generate RGB images that encode the answers. Think of it like turning every vision task into a “coloring” task:
- Semantic segmentation (label every pixel by category): “Color all cars blue, roads gray, trees green.” The model outputs a color-coded map; a simple script reads the colors back into labels.
- Instance segmentation (separate each object even if they are the same type): “Color each basketball in a different color.” Group nearby pixels with similar colors to get each object.
- Referring expression segmentation (find “the man in a pink T-shirt”): “Make the man in the pink T-shirt white, everything else black.” You get a precise mask for that description.
- Metric depth estimation (how far things are, in meters): “Paint a depth image using a special color scale where each color matches a specific distance.” Because the color mapping is reversible (like a legend on a map), the model’s image can be turned back into real distance values.
- Surface normals (the direction each surface is facing): “Use RGB to represent surface directions” (e.g., right/left, up/down, toward/away). This naturally fits into colors and can be read back.
To keep the model’s original image-making talent, they mixed a small amount of these labeled vision examples into its usual image training data, instead of retraining it from scratch. This light-touch training teaches format-following (how to “color” answers correctly) rather than relearning the world.
Key ideas in everyday terms:
- Instruction tuning = teaching the model to follow directions and fill in answers in a specific, easy-to-check format.
- Reframing tasks as images = turning different problems into color-by-number pictures so they can be checked and scored.
- Zero-shot = testing on datasets the model didn’t see during training (like being tested on new examples from new sources).
What did they find?
Vision Banana performed at or near the best-known levels on many tasks—using a single model and only light extra training—while staying good at image generation.
Highlights:
- 2D understanding (finding and labeling things in images):
- It beat or matched specialist models on several segmentation tasks, including outperforming the latest Segment Anything Model 3 (SAM 3) on some benchmarks.
- On “referring segmentation,” where the model must follow natural-language descriptions (like “the stretching cat”), it set new top scores in zero-shot settings.
- On instance segmentation, it was close to strong specialist models.
- 3D understanding:
- Metric depth estimation: On average, it beat Depth Anything 3 across multiple datasets, even without using camera information. It learned to estimate real-world distances from just a single image.
- Surface normals: It reached state-of-the-art or near state-of-the-art accuracy on indoor scenes and was competitive outdoors.
- Image generation:
- It kept its creative skills. In head-to-head comparisons, Vision Banana was about as good as its base model at text-to-image generation and image editing.
Why this matters:
- It shows that learning to make images also teaches the model a lot about how the visual world works.
- With a little guidance, that knowledge can be “unlocked” for many different tasks.
Why is this important?
- One model for many jobs: Instead of building and maintaining separate, specialized systems for each vision task, we can use one general model and just change the prompt.
- A unified interface: Treating “seeing” as “generating a special image” is simple and flexible—like how LLMs solve many tasks by generating text.
- Less extra training: Because the model already “knows” a lot from image generation, it only needs a small amount of task-specific examples to follow instructions and format answers correctly.
- A potential shift in how we build vision AI: This suggests that future “foundation models” for vision may start with image generation, then add small instruction steps to do almost any visual understanding task, from robotics perception to AR/VR to photo editing.
Takeaway
The paper shows that image generators are more than just artists—they’re learners. By asking them to “answer” vision questions with carefully designed images (that we can decode), the researchers turned a creator into a general-purpose vision expert. This could change how we build smart systems that both understand and create visual content.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper presents strong evidence that an image generator, instruction-tuned to emit RGB-formatted task outputs, can act as a generalist vision learner. However, several aspects remain underexplored or uncertain. The following list itemizes concrete gaps future work can address.
Data, training, and ablations
- Quantify the minimal instruction-tuning data required: no ablation is provided on the amount, diversity, and ratio (“very low ratio”) of task data mixed into the base generator’s training. Action: run controlled scaling studies varying task-data proportion, class diversity, and sampling strategies to map performance/forgetting curves.
- Impact of data provenance: instruction-tuning uses in-house web annotations and synthetic 3D data; reproducibility and potential bias/overlap with evaluation distributions are unclear. Action: replicate with fully public datasets and publish a de-duplicated training list to rule out leakage; compare performance using different synthetic engines and realism levels.
- Base-model dependency: only Nano Banana Pro is tested. Action: repeat the process on multiple generator families/architectures (e.g., diffusion, autoregressive, latent video) to assess generality and sensitivity to pretraining corpus/architecture.
Output parameterization and decoding
- Sensitivity to RGB-to-output decoding: segmentation depends on color thresholding/clustering; depth relies on an invertible color mapping; normals use direct RGB. Action: stress-test decoding under color noise, compression artifacts, gamma/tonemapping, and palette perturbations; report robustness curves and failure modes.
- Choice of depth bijection and hyperparameters: the power transform (fixed α = −3, c = 10/3) and cube-edge path are arbitrary design choices. Action: ablate alternative bijections (e.g., log-depth, disparity, learned palettes), different α/c, and quantify effects on near- vs far-range accuracy and error calibration.
- Uncertainty estimation: the RGB interface yields a point estimate without calibrated uncertainty. Action: add stochastic sampling, ensembles, or uncertainty-encoding channels (e.g., variance maps) and evaluate calibration (ECE, CRPS) on depth/normals/segmentation.
- Multi-output representation: current interface emits one RGB per task; panoptic or joint multi-task outputs require multiple passes or complex palettes. Action: explore multi-plane outputs (e.g., RGB stacks), tiling, or latent-coded channels that decode to multiple maps simultaneously.
Evaluation design and fairness
- Limited retention assessment of generative ability: only GenAI-Bench and ImgEdit win rates against the base model are reported. Action: broaden to diverse creative tasks (style transfer, long prompts, compositional constraints, photorealism/fidelity metrics, user studies) and quantify catastrophic forgetting across more axes.
- Reliance on external MLLMs for reasoning (e.g., Gemini 2.5 Pro in ReasonSeg): the contribution of the vision model vs the LLM is not disentangled. Action: evaluate with multiple MLLMs, ablate MLLM quality, and test pure-vision prompts to isolate each component’s impact.
- Runtime and efficiency are unreported: generating images for segmentation/depth likely incurs higher latency and cost than discriminative models, especially for instance segmentation done per-class. Action: benchmark throughput, latency, and memory vs specialist baselines across resolutions and batch sizes; analyze Pareto frontiers (accuracy vs cost).
- Zero-shot transfer boundaries: while benchmark train splits are excluded, web data may still overlap semantically or visually with test distributions. Action: perform strict de-duplication audits, “leave-one-domain-out” tests, and OOD robustness evaluations (synthetic-to-real shifts, rare categories, unusual viewpoints).
Task coverage and generalization
- Breadth beyond 2D segmentation and monocular depth/normals: many vision tasks remain unevaluated (e.g., object detection/bounding boxes, keypoints/pose, optical flow, dense matching, panoptic/instance segmentation at scale, 3D boxes, camera pose). Action: extend the RGB interface to these tasks (e.g., vector fields via two-channel color coding, box corners via color-coded landmarks) and benchmark against specialists.
- Video and temporal consistency: the work does not test video understanding/generation or temporal tasks (tracking, video depth/flow, consistent masks). Action: adapt the approach to video generators and assess temporal coherence, stability, and drift.
- Interactive conditioning: support for point/box/scribble prompts (as in SAM) or multi-modal constraints is not explored. Action: integrate visual prompts into the instruction interface and evaluate interactive segmentation/refinement.
- Multilingual and open-vocabulary robustness: qualitative examples show multilingual capability, but there is no systematic evaluation. Action: benchmark across languages, synonyms, and long-form queries with controlled prompt sets and measure segmentation grounding accuracy.
3D-specific questions
- Camera intrinsics and focal-length variability: the model claims metric depth without intrinsics, but robustness across cameras with different intrinsics is not quantified. Action: conduct controlled tests varying focal length, sensor size, distortion, and scene scale; compare to versions that condition on intrinsics to measure trade-offs.
- Absolute scale reliability and far-range performance: the “vibe test” checks one point; far distances and extreme scales are not rigorously assessed. Action: evaluate on datasets with precise ground-truth ranges (indoor/outdoor, near/far), and report error stratified by depth bins and object categories.
- Domain gap from synthetic-only depth training: despite strong results, failure cases near transparency, specularities, thin structures, and non-Lambertian surfaces are not analyzed. Action: curate challenge sets and error taxonomies; add targeted synthetic augmentations and measure gains.
2D segmentation-specific issues
- Instance segmentation via per-class passes: this is computationally expensive and scales poorly with many categories/instances; color-clustering may merge touching objects or split single objects with texture. Action: develop palette schemes or instance-aware encodings that enforce separability and test scalability to crowded scenes and panoptic settings.
- Prompt sensitivity and instruction-following: segmentation depends on exact color specifications and textual phrasing. Action: quantify robustness to prompt paraphrases, color synonyms/hex/RGB variants, and ambiguous instructions; build prompt suites with automatic perturbations.
Negative transfer and multi-task dynamics
- Cross-task interference/benefit is not characterized: does adding more tasks help or harm others? Action: run task-addition/removal ablations and measure transfer matrices; study parameter-efficient vs full fine-tuning and its effect on interference.
Reproducibility, transparency, and ethics
- Reproducibility barriers: key training details (data composition, hyperparameters, exact ratios, code) are not released. Action: provide full training recipes, palettes, decoding code, and seeds; or replicate with public resources.
- Bias and safety: no analysis of demographic, geographic, or content biases; no adversarial robustness tests. Action: audit segmentation and depth across demographics and regions; evaluate adversarial prompts/perturbations and color-illusion edge cases.
These gaps are actionable through targeted ablations, broader task coverage, controlled evaluations, and expanded reporting. Addressing them will clarify the generality, robustness, and practicality of reframing vision as image generation.
Practical Applications
Immediate Applications
The following applications leverage the paper’s demonstrated capabilities—reframing perception tasks as RGB image generation, lightweight instruction-tuning, and zero-/few-shot performance across 2D and 3D tasks—using today’s infrastructure and workflows.
- Promptable selection and masking in creative tools
- Sectors: software, media/entertainment, e-commerce
- What it enables: Text-conditioned semantic, instance, and referring-expression segmentation (“select the stretching cat,” “segment all price tags”) to create accurate masks without manual polygon tools.
- Tools/products/workflows:
- “Prompt-to-Mask” SDK or Photoshop/Figma/GIMP plug-ins that output an RGB mask image decodable to layers.
- Batch background removal and compositing pipelines for product imagery.
- Assumptions/dependencies:
- The model adheres to the instructed color format; robust decoding thresholds are in place.
- Instance segmentation currently uses per-class inference and may be slower for multi-class scenes.
- Zero-shot product content pipelines
- Sectors: retail/e-commerce, advertising
- What it enables: Automatic object cutouts, brand/attribute highlighting, multi-language grounding (e.g., “segment the logo,” “segment vegan items”), and consistent stylistic edits while preserving base generation quality.
- Tools/products/workflows: Automated listing image pipeline that runs segmentation and selective edits server-side.
- Assumptions/dependencies: Domain shift (studio shots vs. web images) may require light adaptation or QA.
- Monocular depth for relighting, AR occlusion, and bokeh
- Sectors: AR/VR, mobile photography, creative tools
- What it enables: Single-image metric depth and surface normals to support occlusion-aware AR effects, scene relighting, portrait/bokeh, and background replacement.
- Tools/products/workflows:
- “Depth-as-an-Image” microservice that returns invertible false-color depth maps and RGB-encoded normals.
- Compositing nodes in Nuke/After Effects/DaVinci Resolve that consume decodable depth/normal images.
- Assumptions/dependencies:
- Compute cost may push usage to server or desktop GPU rather than mobile on-device.
- For ground-truth 3D reconstruction downstream, camera intrinsics are still needed even though inference can be intrinsic-free.
- Rapid robotics prototyping with zero-shot perception
- Sectors: robotics, warehousing, academic labs
- What it enables: Grasping/placement pipelines using text-conditioned segmentation (e.g., “pick the ‘red box’”); metric depth for grasp planning; surface normals for contact reasoning—without specialized sensor setups.
- Tools/products/workflows:
- “Promptable Perception Node” for ROS2 that returns masks/depth/normal images from a single camera feed.
- Low-intrinsics environments or quick lab setups (no camera calibration step for depth inference).
- Assumptions/dependencies:
- Safety-critical robotics still requires calibration and uncertainty estimation; domain-specific evaluation is necessary.
- Real-time constraints may require distillation or model compression.
- Pseudo-label generation for dataset bootstrapping
- Sectors: academia, ML tooling, applied CV teams
- What it enables: High-quality pseudo-labels for segmentation, metric depth, and normals to reduce annotation costs and seed task-specific fine-tuning.
- Tools/products/workflows:
- Semi-supervised training pipelines that decode RGB outputs back to labels for training discriminative models.
- Assumptions/dependencies:
- Label noise management is needed; bias in synthetic 3D training data may affect domain fidelity.
- Visual QA and moderation aids
- Sectors: platform integrity, safety, enterprise compliance
- What it enables: Text-driven localization (e.g., “mask weapons,” “highlight alcohol”), region-of-interest extraction for downstream review or classifiers.
- Tools/products/workflows:
- Reviewer tooling that overlays decodable masks for flagged regions.
- Assumptions/dependencies:
- Requires careful prompt design and human-in-the-loop; domain-specific fine-tuning advisable to reduce false positives.
- UI/Document automation
- Sectors: software testing, RPA, enterprise IT
- What it enables: Identify and mask UI elements or text regions via prompts (“select the OK button,” “highlight bilingual headings”) to drive automated testing or redaction workflows.
- Tools/products/workflows:
- “Screen-to-Mask” service for test automation frameworks.
- Assumptions/dependencies:
- Generalization to diverse UI skins and fonts may require small, targeted instruction-tuning.
- Teaching and benchmarking with a unified interface
- Sectors: education, research
- What it enables: Courses and labs demonstrating how multiple vision tasks can be unified through RGB generation and invertible mappings; standardized, prompt-driven evaluation harnesses.
- Tools/products/workflows:
- Open-source examples of decodable color maps and prompts for segmentation, depth, normals.
- Assumptions/dependencies:
- Access to a suitable base generator or public checkpoint with legal/ethical training pedigree.
Long-Term Applications
These applications are feasible but depend on further research, scaling, standardization, or domain adaptation (e.g., efficiency, safety, robustness, or specialized datasets).
- Unified perception backbones for autonomous systems
- Sectors: autonomous driving, drones, industrial robotics
- What it could enable: A single, promptable perception stack delivering segmentation, depth, normals, and scene grounding without architecture changes—simplifying maintenance and sensor configurations.
- Tools/products/workflows:
- “Generalist Vision API” deployed on-vehicle with task prompts; dynamic task switching based on mission needs.
- Assumptions/dependencies:
- Requires rigorous calibration, uncertainty quantification, safety validation, and efficient on-device inference.
- Real-time, on-device AR with generalist perception
- Sectors: AR/VR, mobile
- What it could enable: On-device, low-latency depth and segmentation for occlusion, persistent anchors, and scene understanding—using a single generalist model.
- Tools/products/workflows:
- Quantized/distilled variants; hardware acceleration pipelines (NPU/GPU).
- Assumptions/dependencies:
- Significant model compression and power/latency optimizations; thermal budgets and privacy constraints.
- 3D reconstruction and scene editing from single images
- Sectors: gaming, VFX, AEC, digital twins
- What it could enable: From 2D photos to metric proxy geometry and normal maps enabling relighting, consistency checks, and coarse mesh extraction for editing or simulation.
- Tools/products/workflows:
- “Single-Image to 3D Proxy” services integrated into DCCs (Blender, Unreal, Unity).
- Assumptions/dependencies:
- Accuracy for professional-grade metrology or CAD remains a challenge; camera intrinsics/extrinsics improve fidelity.
- Industrial metrology and inspection
- Sectors: manufacturing, construction
- What it could enable: Rough metric measurements, defect highlighting, and texture/normal-based surface analysis using existing monocular cameras.
- Tools/products/workflows:
- QA stations or mobile apps for measurements where tolerances are moderate.
- Assumptions/dependencies:
- Tight tolerances and compliance require calibrated setups and extensive domain adaptation.
- Medical imaging and scientific domains
- Sectors: healthcare, scientific research
- What it could enable: Promptable segmentation or structural estimation in medical images (e.g., MRI/CT) via a unified generative interface.
- Tools/products/workflows:
- Task-specific instruction-tuning with curated, consented datasets; regulatory-grade validation workflows.
- Assumptions/dependencies:
- Current model is trained on natural images; medical application requires domain training, explainability, and regulatory approval.
- Generalist video understanding/generation with decodable outputs
- Sectors: surveillance, media, robotics
- What it could enable: Extending the RGB-as-interface idea to video for optical flow, depth, motion segmentation, material/illumination estimation—all decodable from generated frames.
- Tools/products/workflows:
- Video instruction-tuning pipelines with invertible spatiotemporal encodings.
- Assumptions/dependencies:
- Robust, low-noise encodings for time; compute and memory scaling for long sequences.
- Multimodal agents that reason and act visually
- Sectors: enterprise automation, digital assistants, robotics
- What it could enable: Agents that combine LLM reasoning with generalist vision outputs—e.g., chain-of-thought reasoning to decide “what to segment” or “what to measure,” then executing visual actions via decodable images.
- Tools/products/workflows:
- Reasoning+perception stacks (LLM + Vision Banana-like model) with tool-use policies.
- Assumptions/dependencies:
- Reliability of prompts and adherence to output formats; safeguards to prevent cascading errors.
- Standardization of decodable RGB interfaces for vision tasks
- Sectors: software standards, open-source ecosystems
- What it could enable: Community-agreed color encodings for depth, normals, segmentation across toolchains—making models interoperable via “image-in, image-out” contracts.
- Tools/products/workflows:
- Specs and libraries for invertible mappings (e.g., power-transformed depth-to-RGB, normal-to-RGB conventions).
- Assumptions/dependencies:
- Consensus-building across vendors; backward compatibility and robustness to quantization/compression.
- Data-efficient, instruction-tuned foundation models for vision
- Sectors: academia, platform AI providers
- What it could enable: Replace task-specific discriminative pretraining with generative pretraining plus light instruction-tuning to unlock task behavior—reducing annotation needs and fragmentation.
- Tools/products/workflows:
- Training pipelines that mix small, invertible task datasets at low ratios into generative mixtures.
- Assumptions/dependencies:
- Access to large, legally compliant generative pretraining data and compute; reproducible, open benchmarks.
- Cross-domain deployment toolkits
- Sectors: defense, agriculture, marine, space
- What it could enable: Fast adaptation of a single generalist model to niche domains (e.g., crops, marine life) using small instruction-tuning sets and prompt libraries.
- Tools/products/workflows:
- Domain packs with curated prompts, color encodings, and adapters.
- Assumptions/dependencies:
- Out-of-distribution robustness; governance around sensitive domains and misuse prevention.
Key Cross-Cutting Assumptions and Dependencies
- Base model availability and licensing: The approach depends on access to a strong image generator (e.g., Nano Banana Pro or equivalent) and permissive use rights.
- Output-format adherence: Success relies on the model’s ability to follow prompts precisely and emit decodable RGB outputs; robust parsing and validation are required.
- Compute and latency: Generative models are typically heavier than specialist discriminative models; practical deployments may need distillation, pruning, or hardware acceleration.
- Domain shift and safety: Zero-shot performance is strong on standard benchmarks but may degrade in specialized domains; safety-critical use demands calibration, confidence estimation, and rigorous evaluation.
- Synthetic-to-real transfer: 3D tasks used synthetic data for instruction-tuning; additional real-domain tuning may be needed for high-precision applications.
- Multimodal dependencies: Some best results (e.g., ReasonSeg) leverage an MLLM for reasoning; system performance can depend on this external component.
Glossary
- Absolute Relative Error (AbsRel): A depth estimation error metric that averages the absolute difference between predicted and ground-truth depth normalized by ground-truth. Example: "achieving a 20\% lower absolute relative error (AbsRel) compared to MoGe-2"
- Auto-encoding: A self-supervised learning paradigm where models reconstruct inputs from compressed representations to learn features. Example: "auto-encoding \citep{he2022masked_mae,bao2021beit,chen2024deconstructing_dae}"
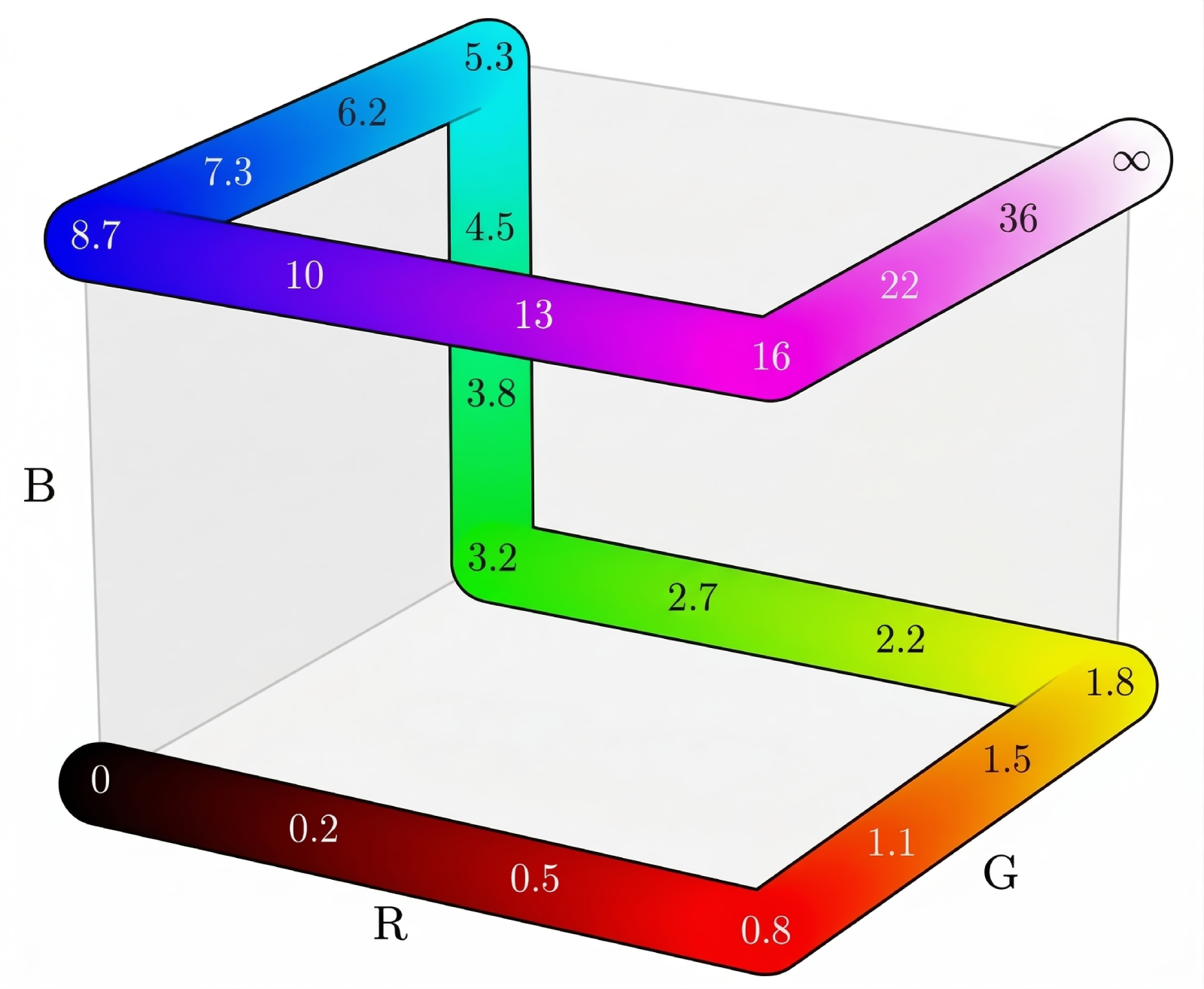
- Bijection: A one-to-one and onto mapping that can be inverted uniquely. Example: "their composition forms a bijection between metric depth in and RGB space in ."
- Bootstrapping: A self-supervised approach where a model trains by predicting targets derived from itself or augmented views without labels. Example: "bootstrapping \citep{caron2021emerging_dinov1,grill2020bootstrap_byol}"
- Camera extrinsics: Parameters describing the camera’s pose (rotation and translation) relative to the world. Example: "without relying on camera parameters (neither intrinsics nor extrinsics) during both training or inference."
- Camera intrinsics: Parameters defining the camera’s internal geometry (e.g., focal length, principal point) used to map 3D rays to image pixels. Example: "Most recent SOTA methods rely on camera intrinsics during training, inference, or both"
- cIoU: A task-specific variant of Intersection-over-Union used in referring segmentation benchmarks. Example: "it achieves a cIoU of $0.738$ on RefCOCOg UMD"
- Contrastive learning: A representation learning method that pulls together similar pairs and pushes apart dissimilar pairs. Example: "contrastive learning \citep{simclr,he2020momentum_moco,chen2020improved_moco2,zhai2023siglip1,tschannen2025siglip2,radford2021learning_clip}"
- Decodable visualization schemes: Output formats (e.g., specific RGB encodings) designed so generated images can be deterministically converted back to task outputs. Example: "Such instruction prompts and decodable visualization schemes are designed to bridge and calibrate the visual generations to formats where measurable metrics for benchmarking can be applied."
- Disparity: The inverse depth-like quantity used in stereo/monocular benchmarks, often more emphasized for near-field accuracy. Example: "stereo/monodepth benchmarks usually measure accuracy terms of disparity or relative/log-depth"
- Discriminative learning: Training that directly maps inputs to labels/decisions (e.g., classifiers), as opposed to generative modeling. Example: "they include supervised discriminative learning"
- Emergent capabilities: Abilities that arise from large-scale pretraining which were not explicitly supervised. Example: "developed emergent capabilities of language understanding and reasoning from generative pretraining."
- False-color visualization: Mapping scalar values (e.g., depth) to RGB colors to visualize and later invert to recover the scalar. Example: "we instruct the model to output a carefully constructed false-color visualization of depth values."
- Foundational Vision Models: General-purpose vision models pretrained at scale to support a wide range of tasks. Example: "Foundational Vision Models for both generation and understanding."
- Generative pretraining: Pretraining a model to generate data (e.g., text or images) so it learns general representations. Example: "generative pretraining \citep{brown2020language_gpt3,chowdhery2023palm} is performed to produce base models, often referred to as LLMs,"
- Generative priors: Inductive biases and knowledge acquired during generative training that guide outputs even on new tasks. Example: "ensuring that our vision task alignment does not degrade the model's original generative priors."
- Geometric priors: Learned assumptions about 3D structure (e.g., typical scales, shapes) that help infer geometry from images. Example: "By leveraging the immense geometric priors embedded in its foundation model"
- gIoU: Generalized Intersection-over-Union metric variant often used for segmentation/localization evaluation. Example: "ReasonSeg val (gIoU )"
- Hilbert curve (3D Hilbert curve): A space-filling curve; here, a 3D variant guides a color traversal used for invertible depth-to-RGB mapping. Example: "similarly to the first iteration of a 3D Hilbert curve."
- Instruction-tuning: Fine-tuning a generative model to follow task instructions and produce outputs in specified formats. Example: "we position a visual generative model as a ``base'' model and perform instruction-tuning to align the model to produce visual output in desired formats"
- Instance segmentation: Segmenting individual object instances within the same class into separate masks. Example: "Unlike semantic segmentation, instance segmentation requires the model to distinguish between individual objects that belong to the same class."
- IoU (Intersection-over-Union): Overlap metric between predicted and ground-truth regions, defined as intersection divided by union. Example: "and an IoU of $0.793$ on ReasonSeg"
- mIoU (mean IoU): The average IoU across classes, commonly used in semantic segmentation evaluation. Example: "Vision Banana surpasses SAM 3 by $4.7$ points in mIoU"
- Mode-seeking (in generative modeling): Tendency of generative models to produce outputs near high-density regions of the learned data distribution. Example: "the mode-seeking nature of generative modeling naturally resolves training target ambiguities"
- Monocular metric depth estimation: Predicting absolute (metric) depth from a single RGB image without multi-view cues. Example: "We evaluate this capability on two classical tasks: monocular metric depth estimation and surface normal estimation."
- Multimodal LLMs: LLMs that process and reason over multiple modalities (e.g., text and images). Example: "On ReasonSeg, methods are paired with multimodal LLMs for reasoning."
- Open vocabulary (model): A model that can handle categories specified via free-form text, beyond a fixed label set. Example: "Vision Banana surpasses SAM 3 by $4.7$ points in mIoU and is the best open vocabulary model"
- Parallax cues: Depth cues arising from viewpoint changes across multiple images, absent in single-view (monocular) settings. Example: "due to the absence of parallax cues available in multi-view setups"
- Per-pixel supervised regression: Training setup where a continuous value is predicted for every pixel with supervised targets. Example: "framed depth estimation as a dense per-pixel supervised regression problem"
- Piecewise-linear function: A function composed of linear segments; used here for color interpolation along RGB cube edges. Example: "interpolate along a piecewise-linear function that follows the edges of the RGB cube"
- Point clouds (3D point clouds): Sets of 3D points representing surfaces in space, often reconstructed from depth and camera parameters. Example: "When these 2D predictions are unprojected into 3D point clouds"
- Power transform: A parametric transformation that warps values (e.g., depths) nonlinearly to emphasize certain ranges. Example: "applying the power transform of \citet{barron2025power}"
- Referring expression segmentation: Segmenting regions described by free-form natural language expressions. Example: "Unlike traditional fixed-class segmentation, referring expression segmentation is based on free-form text queries."
- Right-handed coordinate system: A 3D coordinate convention where axes follow the right-hand rule; here, (+x right, +y up, +z out of the image). Example: "using the standard right-handed coordinate system (+x right, +y up, +z pointing out of the image plane)."
- Semantic segmentation: Assigning a class label to every pixel, without distinguishing instances. Example: "Historically, the task ``semantic segmentation'' is to classify each pixel into one of the predefined categories"
- SOTA (state-of-the-art): The best reported performance achieved by any method on a given benchmark. Example: "Vision Banana achieves SOTA-level results across a broad range of visual understanding tasks"
- Surface normal estimation: Predicting the 3D orientation (unit normal vector) of surfaces at each pixel. Example: "Surface normal estimation represents another critical vision task."
- Unprojected (to unproject): Mapping image pixels with depth back into 3D coordinates using camera geometry. Example: "When these 2D predictions are unprojected into 3D point clouds"
- Zero-shot transfer: Evaluating a model on tasks/datasets it was not trained on, without task-specific fine-tuning. Example: "We denote them as ``Zero-Shot Transfer'' in the table."
- Zero-shot visual understanding: The ability of a model trained generatively to interpret new visual tasks without explicit supervision for those tasks. Example: "image and video generators exhibit zero-shot visual understanding behaviors"
Collections
Sign up for free to add this paper to one or more collections.