Generalized Decoding for Pixel, Image, and Language
Abstract: We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
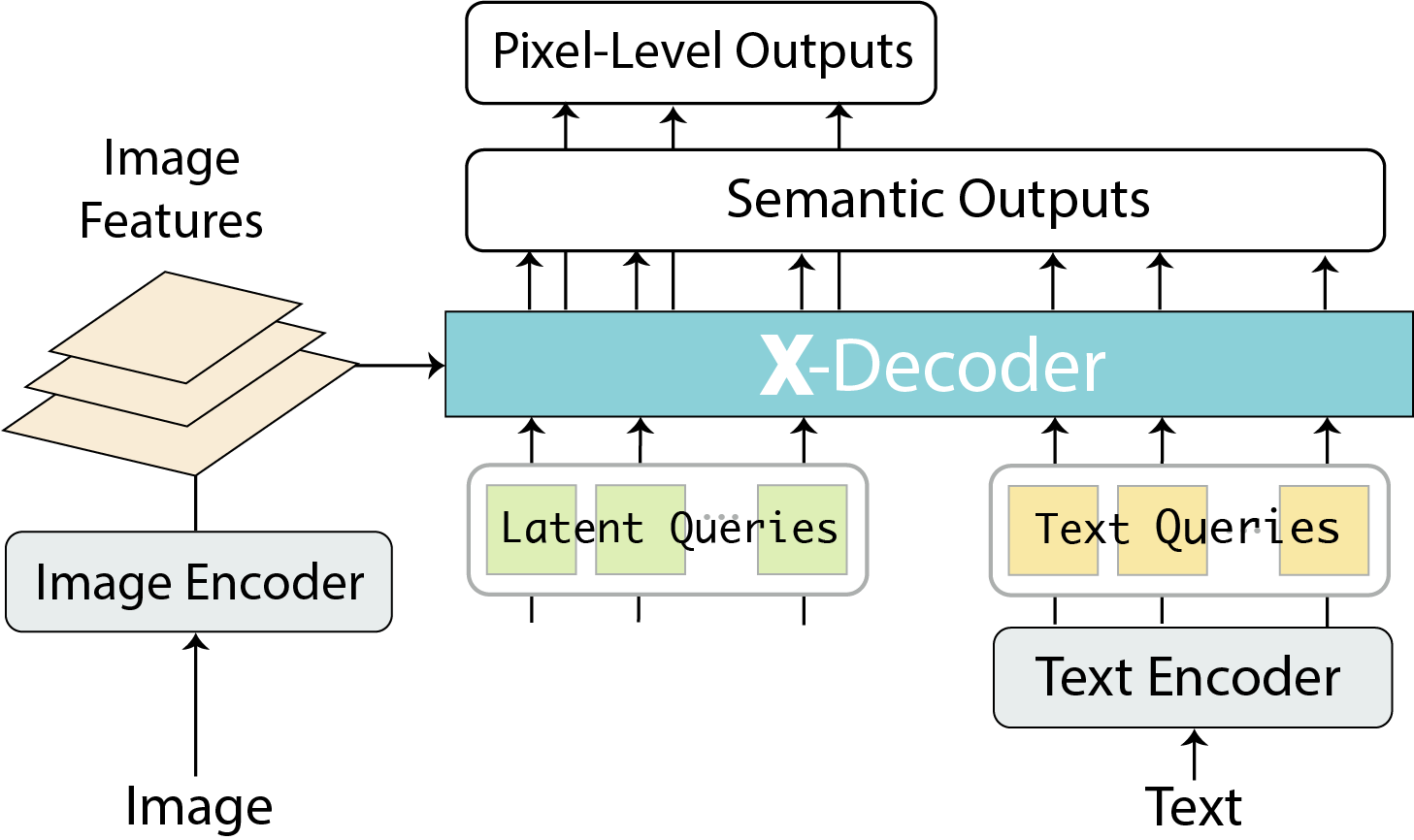

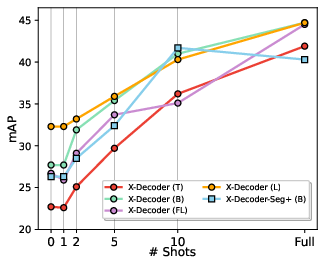
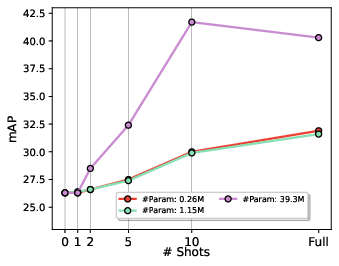
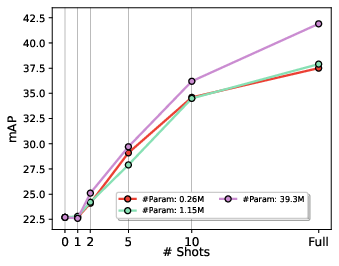
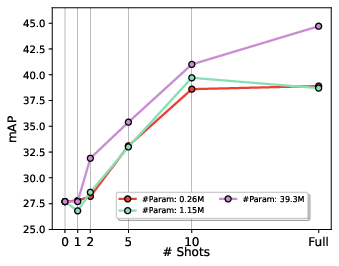
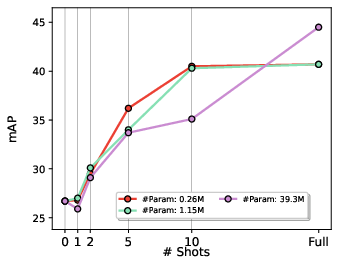
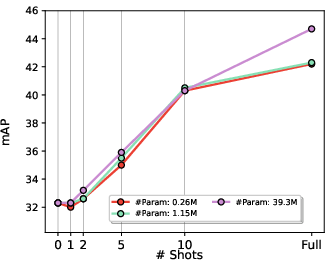
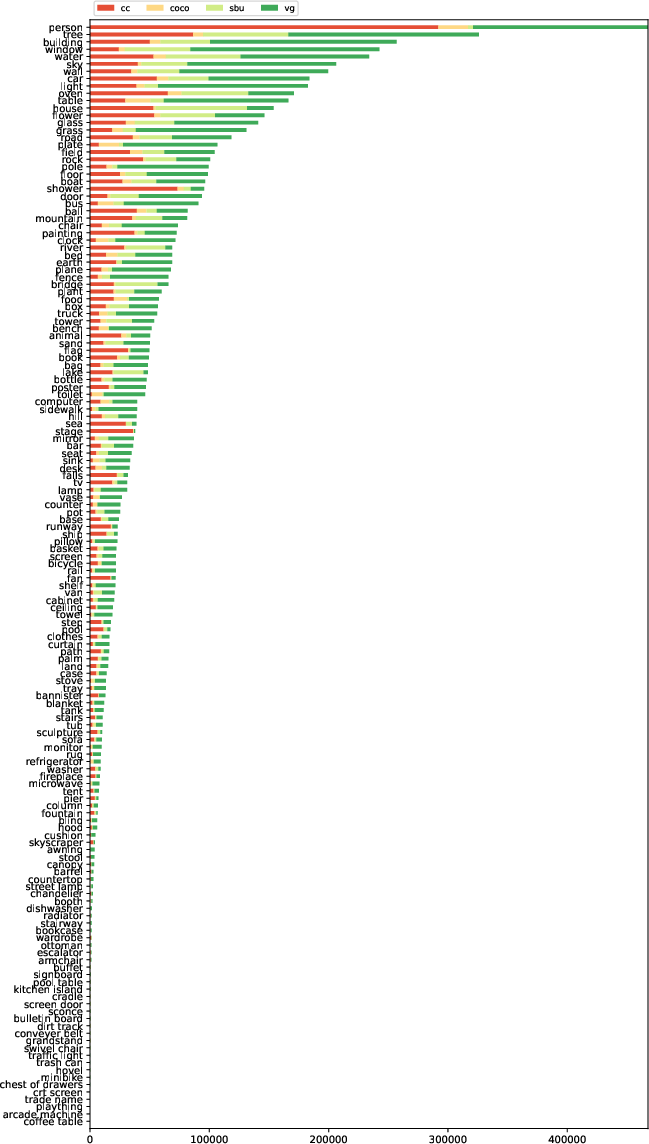

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces X-Decoder, a single smart model that can both “color in” parts of an image at the pixel level (segmentation) and also understand and generate language (like captions). Instead of building separate models for each task, X-Decoder is designed to handle many vision and vision-language jobs with one shared system.
Key Questions the Paper Tries to Answer
- Can we build one model that understands images at different scales—from whole-image summaries (like captions), to specific objects (like detection), down to individual pixels (like segmentation)?
- Can this model use language (words and phrases) to guide what it looks for in pictures—for example, “find the small red backpack”—even if it’s never seen that exact phrase before?
- Can learning several related tasks together make the model better overall, rather than worse?
How the Researchers Approached It
Think of X-Decoder as a multi-tool with three main parts, working together:
The Encoders: Turning pictures and text into numbers
- An image encoder reads a picture and turns it into useful features—like a map of what’s where in the image.
- A text encoder reads words (like labels, phrases, or captions) and turns them into features too—so the model can compare image parts to language.
Analogy: The encoders are like translators that convert pictures and sentences into a shared “language” of numbers, so they can be compared and combined.
The Decoder: Answering different kinds of questions
The decoder takes in two kinds of “queries” (you can think of these as questions or prompts the model asks itself):
- Latent (non-semantic) queries: These are general-purpose prompts that help the model discover and outline meaningful regions in the image—like potential objects or stuff (sky, road).
- Text queries: These come from real words or phrases, like “cat,” “traffic light,” or “a man wearing a blue jacket.” They make the decoder language-aware.
Using these queries, the decoder can produce two kinds of answers:
- Pixel masks: Which exact pixels belong to a thing or region (like coloring in the dog).
- Language tokens: Words for captions or labels (like “a white dog running”).
By mixing and matching these queries and outputs, the same decoder can do different tasks:
- Generic segmentation (coloring all objects and stuff)
- Referring segmentation (find and color the region described by a phrase)
- Image–text retrieval (match images with the right caption)
- Image captioning (write a sentence about the image)
- Visual Question Answering (answer questions about the image)
Training: Learning many skills at once
The model is trained end-to-end on:
- A smaller set of images with pixel-level annotations (so it learns to color accurately).
- Millions of image–text pairs (so it learns rich connections between visuals and words).
- Referring segmentation examples (phrases linked to the exact region they describe).
Instead of making up “fake” labels (called pseudo-labeling), X-Decoder directly links what it sees to the words in real captions and phrases. This helps it learn a strong shared understanding of visuals and language.
Main Findings and Why They Matter
- One model, many tasks: X-Decoder handles all major types of image segmentation (semantic, instance, panoptic) and several vision–language tasks (retrieval, captioning, VQA) with the same set of parameters.
- Strong performance: It sets new state-of-the-art results on open-vocabulary segmentation and referring segmentation across multiple datasets, and performs competitively on captioning and retrieval.
- Works “zero-shot”: Because it connects image regions to words, it can often recognize or segment new categories it hasn’t explicitly been trained on, just by using text prompts.
- Flexible task combinations: It can do creative combos—like “referring captioning” (generate a caption about a specific region you point out with a phrase) and even help with image editing when paired with generative models like Stable Diffusion (e.g., “replace the sky with sunset clouds”).
- Efficient fine-tuning: You can adapt it to new tasks or domains without bolting on extra specialized parts.
Implications and Potential Impact
X-Decoder shows a practical path toward unified AI systems that understand images and language together at many levels—from the whole scene down to individual pixels. This could make it easier to:
- Build smarter photo search tools (ask for “the person riding a bike near a river” and get exact results).
- Assist in medical or scientific imaging (precisely highlight regions while using flexible, natural language).
- Improve creative and editing apps (target specific parts of an image using plain language).
- Develop more general-purpose AI models that learn better by sharing knowledge across tasks.
In short, by uniting pixel-precise vision with language understanding in one model, X-Decoder reduces the need for separate specialized tools and opens the door to more powerful, flexible, and user-friendly AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research:
- Quantify task composition benefits: The paper demonstrates “referring captioning” and image editing qualitatively but provides no quantitative evaluation, user studies, or standardized metrics to assess utility, accuracy, or controllability in these composed tasks.
- VQA output format and reasoning depth: The model uses only the last semantic output for VQA (non-causal), implying short-answer classification rather than generative multi-token answers; there is no analysis of performance on compositional reasoning, counting, or multi-step inference, nor of support for generative VQA.
- Multilingual generalization: The single text encoder appears trained on English-only corpora; there is no evaluation or design considerations for cross-lingual open-vocabulary segmentation, retrieval, captioning, or VQA, nor strategies for multilingual prompts.
- Prompt and template sensitivity: Mask-text matching relies on prompted concept names; the paper does not analyze sensitivity to prompt wording, template design, synonyms/polysemy, capitalization, or contextual descriptions, nor provide methods for prompt optimization or robustness.
- Deformable encoder claim: The authors avoid deformable encoders due to alleged poor open-vocabulary generalization, but provide no systematic ablations, diagnostics, or conditions under which deformable attention harms or helps; the underlying failure modes remain unknown.
- Fixed query budget and crowded scenes: With a fixed number of latent queries (m=100+1), the paper does not characterize behavior when the number of instances exceeds the query budget or in highly crowded/long-tail scenes; adaptive/dynamic query allocation is unexplored.
- Hand-crafted attention policies: The self-attention rules (e.g., last latent query for global representation, textual queries’ access patterns) are manually designed; the paper lacks ablations comparing learned gating or policy search, and does not assess the impact of these constraints across tasks.
- Data mixture and loss balancing: The end-to-end pretraining mixes segmentation and image-text pairs with balanced sampling and four losses, but there is no sensitivity analysis of sampling ratios, loss weights, curriculum schedules, or alternative multi-task optimization strategies (e.g., uncertainty weighting).
- Region–caption alignment reliability: The claim of learning “without pseudo-labeling” hinges on mapping predicted segmentation proposals to caption content on the fly; the paper does not measure alignment accuracy, ambiguous caption handling (multi-object mentions), or negative pair mining to avoid spurious associations.
- Background and “stuff” concepts: Treating “background” as a textual concept for mask classification is underspecified; the paper does not discuss how “stuff” categories and unnameable regions are handled in open-vocabulary settings, nor strategies for segmenting unlabeled/background content.
- Resolution mismatch effects: Pretraining uses 1024 px for segmentation and 224 px for image–text pairs; the impact of this resolution mismatch on learned representations, small-object performance, and cross-task transfer is not analyzed.
- Domain robustness: Evaluation is limited to standard natural-image benchmarks; there is no assessment on out-of-domain settings (e.g., medical, satellite, nighttime driving, adverse weather), nor robustness to occlusion, noise, heavy compression, or adversarial perturbations.
- Efficiency and scalability: Training/inference compute, memory footprint, latency, and throughput are not reported; there is no comparison of efficiency versus specialist baselines, nor analysis of how model size (T/B/L) impacts task trade-offs.
- Bias, fairness, and safety: The 4M image–text corpora are known to contain societal biases; the paper does not address bias auditing, fairness across demographics, harmful caption generation, or safety risks of segmentation-conditioned image editing.
- Continual and incremental learning: The framework does not include strategies for adding new vocabulary/concepts or tasks without catastrophic forgetting, nor mechanisms for online adaptation or updating text/visual encoders post-deployment.
- Coverage of region-level tasks: While the architecture should support phrase grounding and open-vocabulary detection, the paper does not evaluate these tasks nor detail what adaptations are needed to match specialist performance.
- Self-/weakly-supervised pixel learning: The claim of “no pseudo-labels” leaves unexplored whether self-supervised or weakly-supervised pixel-level objectives (e.g., mask consistency, contrastive region learning) could further improve open-vocabulary segmentation.
- Joint training with generative models: Image editing is shown via external diffusion models, but there is no exploration of end-to-end joint training or alignment between X-Decoder masks/semantics and generative controls (e.g., attention, conditioning tokens).
- Hyperparameter ablations: The paper lacks systematic ablations on number of decoder layers, latent/text query counts, feature dimension d, and attention depth, making it unclear which components are most critical to performance.
- Failure-mode analysis: There is no detailed analysis of where mask–text matching fails—e.g., synonyms, polysemy, pronouns, compositional phrases, relational descriptions (“left of,” “holding”), numerals/counts, or attribute binding errors.
- Video and temporal tasks: The approach is not evaluated on video segmentation, video captioning, or temporal VQA; extensions to temporal coherence and memory across frames remain unexplored.
- Thing vs. stuff in open-vocab panoptic: The method’s performance across “thing” and “stuff” categories in open-vocabulary panoptic segmentation is not dissected, nor strategies to handle labeling ambiguities and class granularity.
- Hungarian matching implications: The use of Hungarian matching for mask assignment is not analyzed for stability and optimality across tasks, especially in open-vocabulary settings with variable instance counts and overlapping masks.
- Reproducibility and data availability: Visual and text encoders are pretrained on Florence/UniCL and DaViT/Focal backbones; the paper does not clarify whether all pretraining data and checkpoints are publicly accessible or provide alternatives to reproduce results without proprietary assets.
- Trade-off characterization: There is no explicit analysis of the accuracy trade-offs between open-vocabulary generalization and closed-set performance, nor guidance for practitioners on choosing training mixtures to meet application-specific needs.
- Image representation for retrieval: Using the last latent query as the global image representation is an ad hoc design; alternatives (e.g., learned pooling over queries, region-aware retrieval embeddings) are not compared.
- Vocabulary coverage and OOV handling: Open-vocabulary segmentation assumes concept names exist in the text encoder’s vocabulary; there is no mechanism for truly novel OOV concepts, rare words, or subword composition, nor evaluation of coverage gaps.
Practical Applications
Immediate Applications
The following applications can be deployed with available pre-trained models and code, or with minimal finetuning. Each bullet specifies sector(s), what is enabled, potential tools/products/workflows, and key assumptions/dependencies.
- Open-vocabulary, language-guided image editing and compositing (software, creative industries)
- Enables: Precisely segment any user-specified concept via text (e.g., “make the foreground person’s jacket red”), then edit, inpaint, or replace regions.
- Tools/products/workflows: Photoshop/GIMP/Figma plugins; web UIs combining X-Decoder with Stable Diffusion or other diffusion/inpainting backends; “smart brush” selection tools powered by referring segmentation.
- Assumptions/dependencies: Requires integration with a generative model; quality depends on text encoder vocabulary and diffusion model; GPU for interactive latency.
- Interactive selection tools for photo/video post-processing (software, consumer apps)
- Enables: Click-and-phrase selection (e.g., “the nearest tree,” “the cloudy sky”), mask refinement, and per-region adjustments without manual lassoing.
- Tools/products/workflows: Mobile photo apps; desktop editors with language-conditioned segmentation and panoptic masks; batch background removal for product photos.
- Assumptions/dependencies: Real-time performance requires model optimization (quantization/distillation) or server offloading; domain shift may require finetuning for specific camera/video content.
- Asset tagging, retrieval, and description for media libraries (media, DAM/MAM systems, e-commerce)
- Enables: Open-vocabulary segmentation for fine-grained tags; text-to-image retrieval; automatic captions and per-region referring captions.
- Tools/products/workflows: Digital asset management pipelines; catalog enrichment; “search by description” for product databases; auto-tagging of stock images.
- Assumptions/dependencies: Tag quality varies with domain; better performance with short, well-phrased prompts; storage for per-image masks and embeddings.
- Product listing enhancement and search (e-commerce)
- Enables: Background removal; uniform staging; attribute-focused crops; open-vocabulary search (“blue ceramic mug with gold handle”).
- Tools/products/workflows: Listing automation; marketplace moderation (detect restricted items with text prompts); storefront search with retrieval.
- Assumptions/dependencies: Needs prompt engineering for attributes; careful governance to avoid biased/non-compliant outputs; possible finetuning on brand/product domains.
- Rapid dataset bootstrapping and auto-annotation (academia, software, robotics)
- Enables: Open-vocabulary pseudo-labels/masks to reduce hand annotation; fast class expansion without designing new heads.
- Tools/products/workflows: Labeling tools that propose masks given text labels; human-in-the-loop QA; curriculum learning across segmentation and captioning.
- Assumptions/dependencies: Zero-shot masks may need manual correction; domain shift mitigation (few-shot finetuning) improves precision.
- Accessibility: on-device or cloud captioning with region-level grounding (public sector, assistive tech)
- Enables: Image captions plus referring segmentation for “what’s where” explanations; answer region-specific questions (VQA finetuning).
- Tools/products/workflows: Assistive camera apps; browser plugins providing descriptive overlays.
- Assumptions/dependencies: Safety/accuracy guardrails for sensitive content; multilingual support depends on text encoder.
- Compliance and privacy redaction (policy, enterprise IT, legal)
- Enables: Language-prompted detection and masking of PII-like regions (“license plate,” “passport ID,” “face of a minor”) across varied imagery without fixed label sets.
- Tools/products/workflows: Document/photo pipelines that auto-blur or remove sensitive regions before storage/sharing.
- Assumptions/dependencies: Requires rigorously curated prompt lists; QA to reduce false negatives; potential regulatory review.
- Industrial visual QA and inspection support (manufacturing, quality control)
- Enables: Language-conditioned segmentation to highlight defects or specific parts, even for newly defined categories.
- Tools/products/workflows: Operator-assist UIs; spot-checking stations with open-vocabulary prompts; anomaly region proposals for downstream algorithms.
- Assumptions/dependencies: Domain adaptation (few-shot finetuning) often required; controlled lighting improves reliability.
- Visual analytics and reporting (business intelligence, marketing)
- Enables: Automatic region summaries for campaign assets; detection of brand elements and layout regions.
- Tools/products/workflows: Dashboards that tokenize scenes into brand assets; compliance checks for logo placement.
- Assumptions/dependencies: Requires curated prompts and potentially style-specific finetuning.
- Generalist perception API for research and prototyping (academia, startups)
- Enables: One model for semantic/instance/panoptic segmentation, referring segmentation, retrieval, captioning, VQA (finetuning), and novel task compositions.
- Tools/products/workflows: Unified inference service; evaluation harnesses for multi-task zero-shot transfer; rapid ablation studies across granularities.
- Assumptions/dependencies: GPU resources; governance for data licensing and model weights; consistent prompt templates for stability.
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, optimization, or regulatory validation before broad deployment.
- Open-world perception stacks for autonomous systems (robotics, autonomous driving)
- Enables: Open-vocabulary panoptic perception, language-conditioned attention (e.g., “track the nearest bicyclist”), and dynamic class updates without re-architecting.
- Tools/products/workflows: On-vehicle perception modules integrating X-Decoder-style decoders; operator-issued natural-language tasks for robots.
- Assumptions/dependencies: Real-time constraints (latency, power) on edge hardware; robust performance under motion blur, weather, adversarial scenes; safety certification.
- Clinical and biomedical segmentation with language guidance (healthcare)
- Enables: Queryable segmentation for rare or emergent anatomical/pathological concepts; text-guided region-of-interest proposals to assist radiology/pathology.
- Tools/products/workflows: PACS-integrated viewers; pathology slide triage; semi-automated measurement and reporting.
- Assumptions/dependencies: Extensive domain-specific finetuning; dataset curation and bias assessment; rigorous clinical validation and regulatory approval (e.g., FDA/CE).
- City-scale scene understanding and planning (public sector, geospatial, energy)
- Enables: Open-vocabulary segmentation of urban assets (“new bike lanes,” “damaged road markings”), satellite/aerial analysis with language prompts.
- Tools/products/workflows: Municipal asset inventories; change detection; infrastructure monitoring; energy grid asset inspection.
- Assumptions/dependencies: Domain shift to overhead imagery; multi-spectral inputs; calibration across seasons/sensors; integration with GIS systems.
- Privacy-first, on-device multimodal assistants (consumer devices)
- Enables: Localized captioning, region grounding, and selective redaction/editing in camera workflows; AR assistants that follow language instructions.
- Tools/products/workflows: On-device compressed X-Decoder variants; privacy-preserving inference; low-latency AR overlays.
- Assumptions/dependencies: Model compression (pruning, distillation, quantization) without severe degradation; hardware acceleration; energy constraints.
- Automated content moderation with nuanced grounding (platforms, policy)
- Enables: Open-vocabulary segmentation to identify policy-relevant regions (e.g., “brand logo misuse,” “graphic content”) with explainable region masks.
- Tools/products/workflows: Moderation queues with grounded evidence; triage systems that surface masked regions for human review.
- Assumptions/dependencies: High-stakes false positive/negative costs; fairness auditing; ongoing policy-prompt updates; potential adversarial exploitation.
- Multimodal creative co-pilots for localized generation (creative industries, gaming)
- Enables: Region-aware text-to-image generation and editing (e.g., “turn the middle building into art deco style”), scene re-captioning, and storyboard prototyping.
- Tools/products/workflows: 3D/game engines integrating language-to-mask-to-texture workflows; video editors with language-driven tracking and edits.
- Assumptions/dependencies: Tight coupling with high-fidelity generative models; temporal consistency for video; rights management and watermarking.
- Fine-grained document and chart understanding via pixel-language decoding (finance, enterprise analytics)
- Enables: Segmentation of visual elements in documents/charts coupled with text prompts (e.g., “select the legend,” “mask the pie slice labeled ‘Q3’”).
- Tools/products/workflows: Report automation; compliance redaction; semantic cut-and-paste from complex layouts.
- Assumptions/dependencies: Domain adaptation to document imagery; OCR integration; layout-aware training; legal constraints on automated edits.
- Lifelong, open-world model updating with minimal labels (MLOps)
- Enables: Continual addition of new visual concepts via text prompts and sparse labels; cross-task knowledge sharing to reduce annotation needs.
- Tools/products/workflows: Active learning loops; prompt libraries; evaluation suites for catastrophic forgetting and open-set robustness.
- Assumptions/dependencies: Stable continual learning methods; versioning and rollback strategies; monitoring for drift.
- Safety-critical hazard detection and explainability (industrial safety, insurance)
- Enables: Open-vocabulary masking of hazards (e.g., “uncovered machinery,” “no safety helmet”), with spatial grounding for audit trails.
- Tools/products/workflows: Site monitoring solutions; insurer risk assessment tools with region-level evidence.
- Assumptions/dependencies: High recall requirements; tailored prompts and finetuning per site; strict human-in-the-loop verification.
- Cross-lingual, culturally-aware multimodal assistants (education, global platforms)
- Enables: Multi-language prompts for segmentation/captioning; localization of region mentions with culturally appropriate descriptions.
- Tools/products/workflows: Education apps; museum guides; cross-cultural media localization.
- Assumptions/dependencies: Multilingual text encoders and training data; cultural bias assessment; robust translation for technical terms.
Notes on general dependencies
- Data and compute: Training and high-quality inference typically require GPUs; performance scales with pretraining corpora (image-text pairs and segmentation data).
- Prompting: Results are sensitive to phrasing; standardized prompt templates improve stability; domain-specific lexicons often help.
- Domain shift: Zero-shot works well but still benefits from few-shot finetuning in specialized domains (medical, aerial, industrial).
- Safety and governance: Open-vocabulary capabilities can inadvertently surface sensitive concepts; incorporate filters, auditing, and human oversight where needed.
- Licensing and IP: Ensure compliance with model and dataset licenses; consider watermarking for generative integrations.
Glossary
- ADE20K: A large-scale scene parsing benchmark dataset commonly used for evaluating semantic segmentation models. "MaskCLIP~\cite{ding2022open} proposed to tackle open-vocabulary panoptic and semantic segmentation by leveraging CLIP, and achieved SoTA performance on ADE20K~\cite{zhou2017scene} and PASCAL~\cite{mottaghi2014role,everingham2011pascal}."
- ALIGN: A large-scale vision-language contrastive pretraining model used as a foundation for transferring semantic knowledge. "To support open vocabulary recognition, a number of works study how to transfer or distill rich semantic knowledge from image-level vision-language foundation models such as CLIP~\cite{radford2021learning} and ALIGN~\cite{jia2021scaling} to specialist models~\cite{ghiasi2021open,ding2022open,rao2022denseclip}."
- Bidirectional cross-entropy loss: A loss applied in both image-to-text and text-to-image directions for contrastive retrieval training. "and compute the bidirectional cross-entropy loss:"
- Binary cross-entropy loss: A per-pixel loss used to supervise predicted masks against ground-truth labels. "we follow~\cite{cheng2022masked} to use binary cross-entropy loss and dice loss to compute the loss for masks."
- Causal masking: A decoding strategy that prevents each generated token from attending to future tokens, typical in autoregressive captioning. "The caption prediction follows a causal masking strategy while VQA does not."
- Contrastive loss: An objective that pulls matched image-text pairs together and pushes mismatched pairs apart in embedding space. "we compute the language-image contrastive loss as~\cite{radford2021learning}."
- Deformable encoder: A transformer encoder variant using deformable attention to handle multi-scale features; sometimes avoided for open-vocabulary generalization. "However, we do not adopt a deformable encoder as it does not generalize well to open-vocabulary settings (see in Appendix)."
- Dice loss: An overlap-based loss function commonly used for segmentation to improve mask quality. "we follow~\cite{cheng2022masked} to use binary cross-entropy loss and dice loss to compute the loss for masks."
- Encoder-decoder architecture: A neural design where an encoder extracts representations and a decoder produces task-specific outputs. "Mask2Former~\cite{cheng2022masked} proposed to address all three tasks with a unified encoder-decoder architecture."
- End-to-end pretraining: Jointly training all components and tasks in a single optimization pipeline without intermediate supervision stages. "we propose an end-to-end pretraining method to learn from all granularities of supervision."
- Foundation models: Large pretrained models (often on web-scale data) that provide transferable representations across tasks. "DenseCLIP~\cite{rao2022denseclip} demonstrated the superiority of foundation models in finetuning settings compared with supervised models."
- Hungarian matching: An assignment algorithm used to match predicted masks/queries to ground-truth targets optimally. "we use Hungarian matching~\cite{carion2020end,cheng2022masked} to find the matched entries of first outputs to ground-truth annotations."
- Image captioning: Generating descriptive natural language sentences for an image. "image captioning~\cite{chen2015microsoftcoco}"
- Image-text retrieval: Retrieving images or texts based on cross-modal similarity between image and text embeddings. "image-text retrieval, and image captioning"
- Instance segmentation: Assigning a distinct mask to each object instance in an image. "instance segmentation groups pixels of the same semantic meaning into object instances."
- Latent queries: Learnable, non-semantic query embeddings used by the decoder to propose masks or global representations. "the non-semantic or latent queries {}"
- Mask2Former: A transformer-based segmentation framework unifying semantic, instance, and panoptic segmentation with mask-based decoding. "Mask2Former~\cite{cheng2022masked} proposed to address all three tasks with a unified encoder-decoder architecture."
- Multi-task learning: Training a single model on multiple tasks simultaneously to leverage shared representations. "through multi-task learning~\cite{hu2021unit,gupta2022towards}"
- Open-vocabulary: The ability to recognize or segment categories not seen during supervised training by leveraging text embeddings. "our X-Decoder supports a diversity of tasks in a zero-shot and open-vocabulary manner."
- Open-world generalization: Robust performance in settings with unseen categories or distributions beyond the closed training set. "limited support for open-world generalization."
- Panoptic segmentation: A task unifying semantic and instance segmentation by assigning every pixel either to a stuff class or a thing instance. "panoptic segmentation~\cite{kirillov2019panoptic}"
- Phrase grounding: Localizing regions in an image corresponding to natural language phrases. "phrase grounding~\cite{plummer2015flickr30k}"
- Pseudo-labeling: Generating synthetic labels (often from another model) to supervise training without ground-truth annotations. "without any pseudo-labeling."
- Query-based approaches: Methods that represent potential objects/regions as a set of learnable queries processed by a transformer decoder. "and to the recent query-based approaches~\cite{dong2021solq,zou2022end}."
- Referring segmentation: Segmenting the region in an image described by a natural-language expression. "Referring Segmentation by nature is open-vocabulary in that it does not presume a fixed number of phrases in the training and inference times."
- Self-attention mechanism: An attention operation where tokens attend to each other to aggregate contextual information. "we specifically design the self-attention mechanism to prompt the synergy of tasks"
- Semantic segmentation: Assigning a semantic class label to every pixel in an image. "Semantic segmentation cares about the per-pixel semantic within an image~\cite{long2015fully, chen2017rethinking, chen2022vision}"
- Sequential decoding: Reformulating diverse tasks as sequences to be generated by a single decoder. "sequential decoding \cite{wang2022ofa,yang2022unitab,chen2022unified, lu2022unified}"
- Stable Diffusion: A text-to-image latent diffusion model often used for image generation and editing. "Stable Diffusion~\cite{rombach2022high}"
- Text encoder: The component that converts input text into embeddings used by the decoder. "we use the text encoder to encode a textual query "
- Token-level semantics: Semantic outputs represented at the granularity of discrete language tokens (words/subwords). "it predicts two types of outputs: pixel-level masks and token-level semantics"
- Vision backbone: The base visual feature extractor (e.g., CNN or transformer) used before the decoder. "X-Decoder is built on top of a vision backbone and a transformer encoder for extracting multi-scale image features"
- Vision-language (VL): Tasks or models that jointly process visual and textual modalities. "vision-language (VL) tasks"
- Visual question answering (VQA): Answering natural-language questions about an image. "visual question answering (VQA)~\cite{antol2015vqa}"
- Zero-shot: Evaluating or applying a model to categories or tasks without task-specific supervised training. "zero-shot and finetuning settings."
Collections
Sign up for free to add this paper to one or more collections.

