Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Abstract: Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Tuna-2, a new kind of AI model that can both understand images (answer questions, read text in pictures, reason about diagrams) and create images (draw from text, edit photos). The big idea is that Tuna-2 works directly with raw image pixels instead of using separate “vision encoders” (special helper networks) to pre-process images. The authors show that this simpler, end‑to‑end design can match or beat more complicated models on many tasks.
What questions were they trying to answer?
The researchers asked:
- Do we really need pretrained vision encoders to build a strong model that both understands and generates images?
- If we skip encoders and learn straight from pixels, can one unified model do both jobs well?
- Can this simpler approach help the model notice tiny, fine‑grained details (like small objects, small text, or exact counts) better than encoder‑based systems?
- How should we train such a model so it stays stable and learns useful visual features?
How did they build and train Tuna-2?
To make this clear, think of images as puzzles and the model as a student learning to both describe puzzles and create new ones.
From encoders to pixel embeddings
- Traditional models use “encoders,” like translators that convert an image into a special language before the main model sees it. They often also compress images with a VAE (a kind of smart zipper for images).
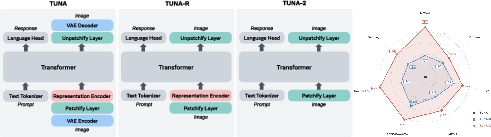
- The authors built three versions to compare:
- Tuna (older): used both a VAE and a representation encoder.
- Tuna‑R (intermediate): removed the VAE but kept a representation encoder.
- Tuna‑2 (new): removed all vision encoders. It just cuts the image into small patches (like tiles), turns those into numbers (patch embeddings), and feeds them straight into a single Transformer (the same type of model used for text).
- Analogy: Instead of asking a translator to summarize a picture first, Tuna‑2 lets the main model look at the picture tiles directly, like reading a comic strip panel by panel.
How the model makes images (generation)
- Tuna‑2 learns image generation in pixel space by practicing “cleaning up” images that have noise added to them.
- Imagine starting with a noisy, speckled version of an image and teaching the model to predict the clean version step by step. This process (called flow matching) is like learning to restore a blurry photo to sharpness by repeatedly making small, careful fixes.
Hide‑and‑seek training (masking)
- Learning from pixels is hard because there’s a lot of information. To help, the authors add a “hide‑and‑seek” trick:
- During training, they randomly hide some image patches and replace them with a special [MASK] token.
- For understanding tasks: the model must answer questions even with parts hidden, so it learns to reason from what it can see.
- For generation tasks: the model must reconstruct both hidden and visible parts, which makes it better at filling in missing details.
- Analogy: It’s like practicing with a jigsaw puzzle where some pieces are covered—you get better at guessing what’s missing from the pieces you do see.
Training steps
- Stage 1: Joint pretraining on image captioning (describe images) and text‑to‑image generation (draw from descriptions), plus some text-only data to keep language skills strong.
- Stage 2: Supervised fine‑tuning on:
- Instruction-following with images (how to respond to complex prompts)
- Image editing (change style, add/remove objects, adjust backgrounds)
- High‑quality image generation
- For Tuna‑R (which still used an encoder), they did a short extra alignment step to connect the encoder to the main model. Tuna‑2 didn’t need that.
What did they find?
Here are the key takeaways in plain language:
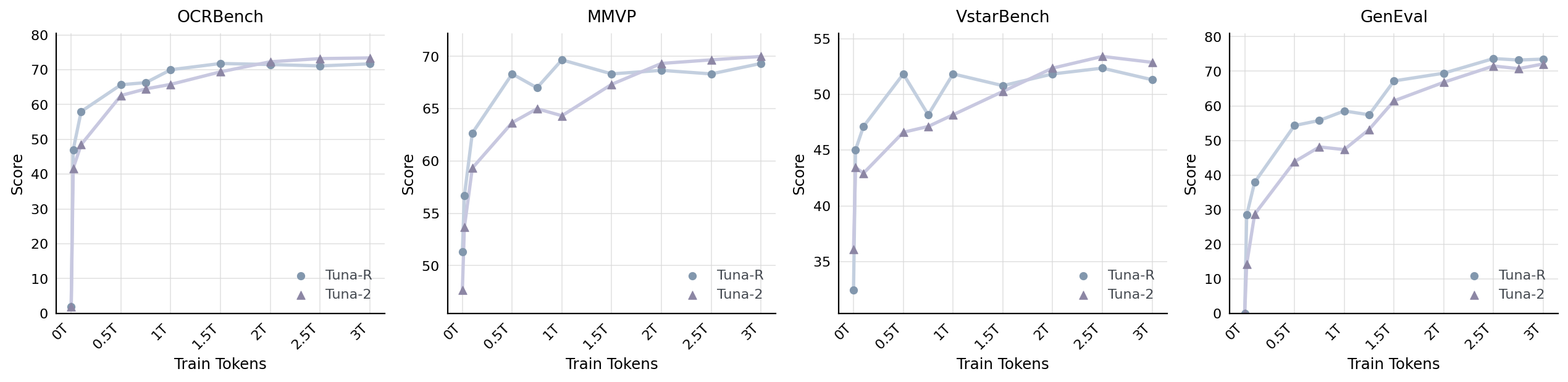
- Tuna‑2 understands images extremely well:
- It reached state‑of‑the‑art performance among similar‑sized models on many image understanding tests (like QA about real-world photos, charts, and diagrams).
- It is especially strong on “pixel‑centric” tasks that need fine detail, such as reading tiny text (OCR), counting small objects, and precise visual reasoning. Working directly with pixels helps here.
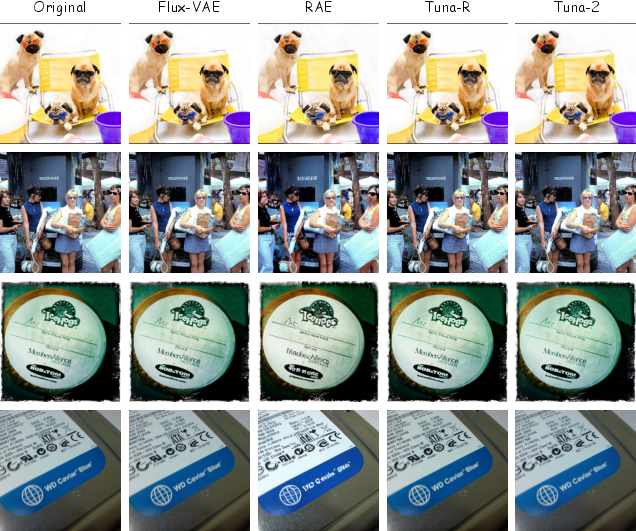
- Tuna‑2 generates images competitively:
- Even without a VAE, Tuna‑2 creates high‑quality images from text and does image editing well.
- On some generation benchmarks, Tuna‑R (which kept the representation encoder) was slightly ahead, especially early in training, likely because the encoder provided helpful starting knowledge. But Tuna‑2 stayed very competitive and produced more diverse images in side‑by‑side tests judged by strong LLMs.
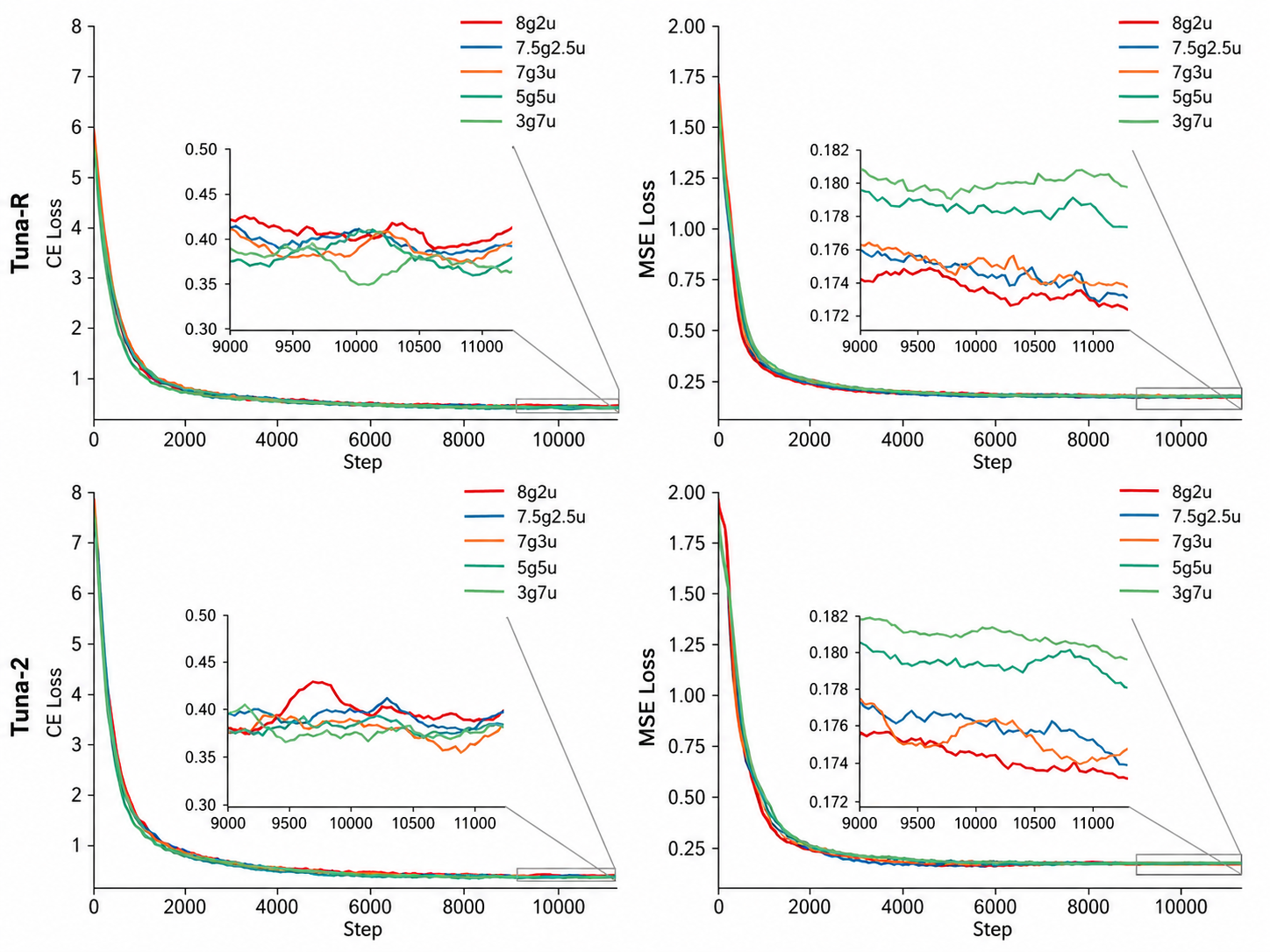
- Training dynamics:
- Early on, Tuna‑R learns faster (thanks to the encoder). With more training, Tuna‑2 catches up and often surpasses it on understanding tasks.
- A data mix of roughly 70% generation and 30% understanding during pretraining balanced both skills best.
- The hide‑and‑seek (masking) trick improved both understanding and generation, especially for Tuna‑2.
- Attention and robustness:
- Visualization showed Tuna‑2 focuses its “attention” more precisely on the right image regions for words in the prompt, and it’s less fooled by misleading text or distracting visuals.
Why this is important:
- It shows you don’t need complex, separate vision encoders to get top performance. A single, simpler model that learns directly from pixels can do both understanding and generation very well.
- It’s particularly good for tasks that need careful, fine‑grained perception.
Why does this matter?
- Simpler and more scalable: Removing encoders makes the system cleaner—one unified model that can be trained end‑to‑end. That can make development faster and easier to scale.
- Better at details: Pixel‑level learning helps with tasks needing sharp eyes—like reading small text, counting objects, and spotting tiny differences—useful for education, accessibility tools, scientific images, and more.
- Strong all‑rounder: Tuna‑2 shows that a single model can handle both “seeing” and “drawing” well without special modules, which could inspire new, unified AI systems for multimedia tasks.
- Future potential: As we train longer on larger, more diverse data, encoder‑free models like Tuna‑2 may keep improving, possibly overtaking encoder‑based methods in both understanding and generation.
In short: Tuna‑2 proves that “pixel embeddings” (working directly from image tiles) can beat or match traditional vision encoders for multimodal AI. It’s simpler, strong at fine detail, and competitive at making images—pointing to a promising, end‑to‑end path for future AI that sees and creates.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable items for future research.
- Compute, memory, and efficiency: Quantify and compare training/inference FLOPs, GPU memory, throughput, latency, and cost of pixel-space Tuna-2 vs latent-space and encoder-based baselines at matched resolution, batch size, and quality.
- Resolution and aspect ratio scaling: Characterize how Tuna-2 scales to higher resolutions and variable aspect ratios (beyond 512 px), including memory-efficient attention, multi-scale patching, and tiled/streamed inference.
- Video capability: The model claims unified handling of image and video tokens but provides no video training or evaluation; assess video understanding, generation, and editing performance and efficiency.
- Early-phase convergence: Develop strategies to close Tuna-2’s slower early-stage convergence vs Tuna-R (e.g., curriculum learning, masked warmup schedules, bootstrapping from SSL objectives, distillation from encoders).
- Masking objective design: Systematically ablate mask ratios, schedules, block vs random masks, token-sharing strategies, and where/when to apply masking (per-layer, per-task) to understand why/when it helps most.
- Data mixture scheduling: Replace the static 7:3 generation-to-understanding ratio with adaptive mixture policies (e.g., curriculum, uncertainty-based sampling, gradient conflict-aware mixing) and measure their effects.
- Text-only data impact: Quantify the contribution of text-only corpora (20% Nemotron) to multimodal performance, including ablations on proportion, domain, and instruction-tuning quality.
- Generalization and robustness: Evaluate robustness to distribution shift and corruptions (e.g., ImageNet-C/P), occlusion, compression, adversarial perturbations, out-of-domain scenes, and long-tail categories.
- Fine-grained localization tasks: Test segmentation, detection, referring expression grounding, and keypoint/pose to verify claims about pixel-level advantages for fine-grained perception.
- Multilingual and OCR breadth: Assess cross-lingual OCR (non-Latin scripts), multilingual VQA/ChartQA/DocVQA, and text rendering/reading fidelity in generation/editing.
- Safety and misuse: Analyze safety alignment (toxic/NSFW generation, deepfake risks), watermarking, provenance, and content filtering; report safety metrics and mitigation mechanisms for pixel-space models.
- Hallucinations and faithfulness: Measure visual and textual hallucinations (e.g., POPE, MMHal-Bench), causal grounding, and consistency under counterfactual prompts.
- Human evaluation rigor: Supplement LLM-judge results with blinded human studies; publish prompts, rating rubrics, inter-rater reliability, and tie-breaking procedures.
- Benchmark coverage and comparability: Report standard generation metrics on public datasets (e.g., FID/IS/KID on COCO/LAION subsets) and release all evaluation prompts/seed settings for exact reproducibility.
- Reproducibility and openness: Specify licensing, curation, deduplication, and filtering of the 550M in-house pairs; release code, configs, and (where possible) models/datasets or provide a reproducible recipe with public alternatives.
- Encoder choice breadth: Compare Tuna-R with a wider set of representation encoders (e.g., EVA-CLIP, DINOv2, SigLIP variants, strong ViT-G models) to isolate the role of encoder priors in generation vs understanding.
- Architectural ablations: Study alternatives to simple patch embeddings (e.g., hybrid conv+patchify, hierarchical tokens, local–global attention, learned downsampling) and positional schemes (RoPE vs 2D biases).
- Inference solvers and schedules: Compare Euler vs higher-order or learned solvers, different rectified-flow schedules, and step–quality trade-offs for pixel-space flow matching.
- Guidance and controllability: Explore classifier-free guidance, textual/image-conditioned guidance strength tuning, ControlNet-like controls, and region-level conditioning for improved editing fidelity.
- Persistent editing gap: Diagnose why Tuna-2 trails Tuna/Tuna-R on ImgEdit; test localized conditioning, attention control, and hybrid latent–pixel workflows to close the gap.
- Multi-image/multi-turn reasoning: Evaluate multi-image inputs, long-context sequences, and iterative understand–generate loops (agentic workflows) to stress unified reasoning and memory.
- Compositional generalization: Test hard compositional tasks (multi-attribute, multi-object relations, counterfactuals) under systematic splits (e.g., Winoground-style, compositional templates) for both understanding and generation.
- Scaling laws: Provide explicit scaling curves vs data, parameters, and compute for Tuna-2 and Tuna-R, including sample efficiency, loss–accuracy predictability, and asymptotic gaps.
- Training stability: Report instabilities (loss spikes, divergence), gradient norms, and mitigation strategies (loss balancing, gradient surgery, optimizers, weight decay schedules).
- Token budget constraints: Analyze the 16k-token cap’s impact on high-res inputs and multi-image contexts; investigate sparse attention, token pruning/merging, and learned token compression.
- Distillation and hybridization: Test whether distilling from encoder-based models (or latent-space generators) accelerates Tuna-2 training and narrows generation/editing gaps without sacrificing fine-grained understanding.
- Downstream task transfer: Measure zero/few-shot transfer to specialized tasks (medical, remote sensing, scientific figures) and to 3D/geometry reasoning (depth, normals, multi-view).
- LLM backbone dependence: Disentangle the effect of using a pretrained instruction-tuned LLM decoder; compare to training-from-scratch backbones, different sizes (13B/34B/70B), and frozen vs unfrozen LLMs.
- Attention alignment quantification: Complement qualitative maps with quantitative localization metrics (pointing game, Grad-CAM IoU vs RefCOCO boxes, referring expression accuracy).
- Legal/ethical data risks: Audit training data for copyrighted or sensitive content, summarize consent/provenance practices, and evaluate compliance with jurisdictional requirements.
Practical Applications
Immediate Applications
The paper’s encoder-free, pixel-space unified multimodal model (Tuna-2) and its training insights can be adopted today in several production and research settings. Below are concrete use cases, linked to sectors, with suggested tools/workflows and key dependencies.
- Industry – Fine-grained visual QA and OCR-heavy pipelines
- Sectors: finance, logistics, public sector, legal
- Use cases:
- Automated document and ID processing: improved OCRBench-style performance for small text, stamps, signatures, and dense tables.
- Chart and diagram understanding: ChartQA/AI2D capabilities for extracting series, labels, and relations from business reports and scientific figures.
- Tools/workflows:
- Replace CLIP+VAE stacks with a single-decoder Tuna-2 inference service for VQA+OCR+chart parsing.
- Introduce a pixel-centric “microtext” route in intake workflows for forms and invoices.
- Assumptions/dependencies:
- Requires access to released Tuna-2 weights or replication.
- GPU memory budget for long visual-token sequences; throughput tuning for SLAs.
- Domain fine-tuning for specific document layouts and languages; PII and compliance controls.
- Creative tools – Instruction-guided editing and diverse image generation
- Sectors: advertising, media, e-commerce, product design
- Use cases:
- Prompt-based image editing (add/adjust/replace/remove/stylize), with strong diversity preferences in LLM-judge evaluations.
- Rapid variant generation for campaigns (colorways, backgrounds, compositions).
- Tools/workflows:
- Integrate Tuna-2’s pixel-space flow generator as a plugin in creative suites; expose “edit-by-instruction” and “diversify” APIs.
- Guardrails for brand safety and prohibited content.
- Assumptions/dependencies:
- Slightly behind encoder-based variants in some fine-grained edits; human-in-the-loop review recommended.
- Content moderation and watermarking are needed for safe deployment.
- Retail/e-commerce – Product understanding and synthetic assets
- Sectors: retail, marketplaces
- Use cases:
- Attribute extraction (color, count, placement) and QA for catalog images.
- Generating product images, backgrounds, and lifestyle composites from text.
- Tools/workflows:
- Unified pipeline (single model) for both attribute parsing and asset generation, reducing integration complexity.
- Batch diversification for A/B testing of visuals.
- Assumptions/dependencies:
- Product-specific fine-tuning boosts attribute accuracy.
- Rights management for generated content; prompt filtering.
- Manufacturing & inspection – Pixel-level perception for tiny defects
- Sectors: electronics, automotive, pharma packaging
- Use cases:
- Fine-grained detection/counting (CountBench-style) and visual reasoning over small regions that latent encoders may miss.
- Tools/workflows:
- Offline/nearline QA (not real-time) with encoder-free Tuna-2 for better sensitivity to subtle anomalies.
- “Explain-why” VQA interfaces for inspector review.
- Assumptions/dependencies:
- Domain data and labeling required; latency likely too high for high-FPS inline inspection without compression/distillation.
- Safety-critical decisions require formal validation.
- Education and knowledge platforms – Visual tutors and assessment
- Sectors: education, corporate training, science communication
- Use cases:
- Diagram/figure Q&A, chart reading, and step-by-step reasoning (AI2D/ChartQA/MMVP).
- Generating illustrative diagrams and variations aligned with prompts.
- Tools/workflows:
- Tutor bots that both explain diagrams and create new ones for exercises.
- Instructor dashboards that auto-grade chart/diagram questions.
- Assumptions/dependencies:
- Hallucination management (answer verification); content appropriateness filters.
- Software and UI agents – Screen reading and mockup generation
- Sectors: software engineering, QA, product management
- Use cases:
- Pixel-level GUI parsing for test automation and bug triage.
- Generate mockups from textual specs for early-stage ideation.
- Tools/workflows:
- One-model architecture reduces maintenance vs. CLIP+VAE-based stacks.
- Adopt 7:3 (generation:understanding) data mixture and masking-based feature learning during custom pretraining to improve robustness.
- Assumptions/dependencies:
- Requires calibration on real GUI elements and iconography.
- Privacy/security for screen captures.
- Research and teaching – Strong baseline and training practices
- Sectors: academia, applied AI labs
- Use cases:
- Studying end-to-end pixel-space representation learning without encoder biases.
- Reusing the paper’s findings: masking-based feature learning and 7:3 data ratio for balanced generation/understanding.
- Tools/workflows:
- Reproducible training scripts with masked patch prediction and flow matching (x-prediction, v-loss).
- Attention-map analysis for cross-modal alignment diagnostics.
- Assumptions/dependencies:
- Compute costs for pixel-space training and long contexts; mixed-precision and sequence-chunking recommended.
- Evaluation and governance – Pixel-centric benchmark adoption
- Sectors: ML evaluation providers, enterprise ML governance
- Use cases:
- Incorporate V*, CountBench, VisuLogic into internal model scorecards to capture fine-grained perception performance.
- Tools/workflows:
- Update evaluation suites and red-team protocols to include small-object and counterintuitive cases (to detect language-prior bias).
- Assumptions/dependencies:
- Access to benchmark datasets and consistent scoring pipelines.
Long-Term Applications
These opportunities require further research, scaling, optimization, or regulatory clearance before broad deployment.
- Healthcare diagnostics and biomedical imaging
- Sectors: healthcare, life sciences
- Use cases:
- Fine-grained detection in radiology/dermatology/pathology; robust chart/figure Q&A for literature mining.
- Generating realistic synthetic images to augment rare-condition datasets.
- Dependencies/assumptions:
- Extensive domain-specific fine-tuning; rigorous validation; FDA/CE approvals.
- Privacy-preserving training; bias and robustness audits.
- Robotics and real-time embodied AI
- Sectors: robotics, warehousing, assistive tech
- Use cases:
- Encoder-free perception for precise, small-object reasoning and language-guided manipulation.
- On-device pixel-space inference for low-latency perception-action loops.
- Dependencies/assumptions:
- Model compression/distillation and custom kernels to meet latency/energy budgets.
- Integration with control stacks; reliable failure handling.
- Autonomous systems and ADAS
- Sectors: automotive, drones
- Use cases:
- Fine-grained visual understanding under adverse conditions; multi-object reasoning and counting.
- Unified perception+reasoning for scene interpretation and driver monitoring.
- Dependencies/assumptions:
- Extension to video tokens and temporal consistency; safety certification and extreme stress testing.
- Unified video understanding and generation
- Sectors: media, simulation, education
- Use cases:
- Pixel-space video captioning, QA, and instruction-following plus text-to-video and video editing in one model.
- Dependencies/assumptions:
- Scalable training on long video sequences; efficient tokenization and memory management; improved solvers for flow in pixel space.
- Enterprise multimodal agents (RPA) that see, reason, and generate
- Sectors: back-office automation, customer support, IT ops
- Use cases:
- End-to-end agents that read screens, interpret charts, process documents, and generate visuals (reports, diagrams) contextually.
- Dependencies/assumptions:
- Tool-use integration (browsers, spreadsheets, CAD); guardrails and audit trails; enterprise-grade latency and reliability.
- High-fidelity synthetic data engines for vision training
- Sectors: automotive, retail, robotics, manufacturing
- Use cases:
- Pixel-space generators producing diverse, fine-detail synthetic scenes for training and robustness testing.
- Dependencies/assumptions:
- Domain adaptation for photorealism and label fidelity; scalable data generation pipelines; evaluation against real-world benchmarks.
- Public-sector procurement and standards for fine-grained perception
- Sectors: government, standards bodies
- Use cases:
- Setting minimum performance thresholds on pixel-centric benchmarks for safety-critical deployments (e.g., inspection, forensics).
- Dependencies/assumptions:
- Consensus on benchmark coverage, fairness metrics, and auditing methodologies; periodic re-certification processes.
- On-device creative and AR/VR assistants
- Sectors: consumer devices, gaming, design
- Use cases:
- Interactive agents that understand complex scenes and generate/edit visuals in mixed reality, guided by voice/text.
- Dependencies/assumptions:
- Aggressive model compression and hardware acceleration; privacy-preserving on-device inference; UX and safety design.
- Secure and responsible deployment frameworks for pixel-space generators
- Sectors: platforms, regulators, IP holders
- Use cases:
- Watermarking, provenance tracking, and content moderation tailored to pixel-space flow models.
- Dependencies/assumptions:
- Standards for provenance; interoperable watermark detectors; legal frameworks for generative content.
Notes on Feasibility and Cross-Cutting Dependencies
- Compute and memory: Pixel-space tokenization increases sequence length and cost; efficient attention, KV-caching, and distillation are often required for production latency.
- Data scale and quality: Reported performance relies on hundreds of millions of image-text pairs plus SFT; domain-specific applications need curated, compliant datasets.
- Safety and governance: Stronger fine-grained perception can amplify privacy and misuse risks (e.g., reading small text). Content filters, red-teaming, and watermarking are necessary.
- Training best practices from the paper:
- Data mixture: Approximately 7:3 generation-to-understanding sampling improved balance between tasks.
- Masking-based feature learning: Improves robustness (especially for encoder-free variants); apply in later training phases.
- Architecture simplification trade-offs: Removing pretrained encoders reduces integration complexity and representation mismatch, but can slow early-stage convergence and may modestly lag in certain editing/generation subtasks without additional tuning.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates for more stable training. "with the AdamW optimizer"
- Autoregressive text generation: Generating text token-by-token conditioned on previous tokens. "including a language modelling head for autoregressive text generation"
- CLIP: A contrastive vision–LLM commonly used as a pretrained representation encoder. "representation encoders such as CLIP"
- Connector layer: A learned module that maps vision-encoder outputs into the LLM token space. "a connector layer between the representation encoder and the LLM decoder"
- Cross-entropy loss (CE): A standard classification loss used here to train language modeling. "cross entropy loss (CE)"
- Cross-modal alignment: The correspondence between textual concepts and the relevant image regions or tokens. "cross-modal alignment capabilities"
- Denoised image: The reconstructed clean image predicted at a later time step in a generative process. "predict the denoised image"
- Encoder-free: An architecture that removes pretrained vision encoders and processes pixels directly with the LLM. "encoder-free UMM"
- Euler solver: A first‑order numerical integrator used to step along the generative trajectory in flow matching. "we employ the Euler solver"
- Flow matching: A transport-based generative modeling approach that learns velocities mapping noise to data. "pixel-space flow matching"
- Flow matching head: The output head that predicts flow/velocity for image generation. "a flow matching head for image generation"
- Inductive biases: Built-in assumptions of a model (e.g., fixed resolution) that influence learning and performance. "built-in inductive biases"
- Joint vision-language modeling: Training that processes image and text tokens together in a shared backbone. "LLM decoder for joint vision-language modeling"
- KL- or VQ-regularized VAEs: VAEs whose latent spaces are regularized by KL divergence or vector quantization to stabilize training. "KL- or VQ-regularized VAEs"
- Language modelling head: The output layer that performs next-token prediction for text generation. "a language modelling head"
- Latent diffusion: Diffusion modeling performed in a compressed latent space rather than pixel space. "latent diffusion architecture"
- Latent space: A compact, encoded representation space used for modeling or generation. "latent-space approaches"
- Learnable mask token: A trainable token that replaces masked image patches to encourage robust feature learning. "learnable mask token"
- Linear schedule: A time schedule where the interpolation coefficient increases linearly during rectified flow. "its linear schedule"
- LLM decoder: The decoder-only LLM that consumes both text and visual tokens to produce outputs. "LLM decoder"
- Masking-based visual feature learning: A training scheme that masks image patches to regularize and strengthen visual representations. "masking-based visual feature learning scheme"
- Mean squared error (MSE): A regression loss used here for the flow matching objective during training. "MSE"
- Monolithic architecture: A single unified transformer that processes both vision and language without separate encoders. "monolithic, encoder-free architectures"
- Patch embedding layers: Simple modules that split images into patches and embed them as tokens for the transformer. "simple patch embedding layers"
- Pixel embeddings: Token representations derived directly from raw pixels (e.g., patch embeddings) rather than latent codes. "Tuna-2 using pixel embeddings outperforms"
- Pixel-space diffusion models: Diffusion or flow models that operate directly on pixels instead of latent codes. "pixel-space diffusion models"
- Pixel-space image generation: Generating images directly in pixel space without a latent-space VAE. "pixel-space image generation"
- Pixel-space UMM: A unified multimodal model that represents and generates images directly in pixel space. "a pixel-space UMM"
- Pretrained representation encoder: A vision backbone trained beforehand to extract semantic features from images. "a pretrained representation encoder"
- PSNR: Peak Signal-to-Noise Ratio, a reconstruction quality metric; higher is better. "PSNR"
- Rectified flow: A flow-matching formulation that uses straight-line paths between noise and data for sampling and training. "we employ rectified flow"
- Representation encoder: A vision model that converts images into visual tokens for an LLM. "representation encoder"
- Representation mismatch: A gap between the visual features used for understanding and those used for generation. "the representation mismatch"
- rFID: Reconstruction Fréchet Inception Distance, measuring realism of reconstructions; lower is better. "rFID"
- Semantic priors: Preexisting semantic knowledge in pretrained encoders that can aid downstream tasks. "the semantic priors provided by the representation encoder"
- Single transformer decoder: A design that uses only one decoder to process both image and language tokens. "using only a single transformer decoder"
- SSIM: Structural Similarity Index Measure, a perceptual similarity metric for image reconstruction. "SSIM"
- Supervised fine-tuning (SFT): A training stage that refines a pretrained model on labeled examples with a lower learning rate. "supervised fine-tuning (SFT)"
- Unified multimodal models (UMMs): Models that jointly support multimodal understanding and generation within one framework. "native unified multimodal models (UMMs)"
- VAE: Variational Autoencoder, a latent-variable model used to compress and reconstruct images. "remove the VAE model"
- Velocity term: The predicted velocity vector in flow matching that transports noisy samples toward data. "velocity term "
- Vision encoder: A module that extracts visual features from images before fusion with language. "vision encoder"
- Vision-language modeling: Learning representations that jointly integrate visual and textual signals. "vision-language modeling"
- Visual tokens: Discrete tokens representing image patches/features input to the LLM. "visual tokens"
- VQ-VAE: A VAE variant that uses vector quantization for discrete latent codes. "VQ-VAE"
- -loss: A training objective that regresses the velocity in flow matching. "the -prediction and -loss paradigm"
- -prediction: A training target that directly predicts the clean image from a noisy input in flow matching. "the -prediction and -loss paradigm"
Collections
Sign up for free to add this paper to one or more collections.