Video models are zero-shot learners and reasoners
Abstract: The remarkable zero-shot capabilities of LLMs have propelled natural language processing from task-specific models to unified, generalist foundation models. This transformation emerged from simple primitives: large, generative models trained on web-scale data. Curiously, the same primitives apply to today's generative video models. Could video models be on a trajectory towards general-purpose vision understanding, much like LLMs developed general-purpose language understanding? We demonstrate that Veo 3 can solve a broad variety of tasks it wasn't explicitly trained for: segmenting objects, detecting edges, editing images, understanding physical properties, recognizing object affordances, simulating tool use, and more. These abilities to perceive, model, and manipulate the visual world enable early forms of visual reasoning like maze and symmetry solving. Veo's emergent zero-shot capabilities indicate that video models are on a path to becoming unified, generalist vision foundation models.



























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: Can modern video-generating AI models become the “one model that does it all” for vision, like LLMs did for text? The authors test Google DeepMind’s video model, Veo 3, and show that it can do many visual tasks it wasn’t specially trained for, just by giving it an image and a written instruction. They argue this is a sign that video models are becoming general-purpose “foundation models” for seeing and reasoning.
Objectives
The paper has three simple goals:
- Show that Veo 3 can handle lots of different vision tasks without extra training (“zero-shot”), from basic seeing to advanced problem solving.
- Check whether Veo 3 can not only “see” but also “model” the world (like understanding physics), “manipulate” images (like editing), and “reason” over space and time (like solving mazes).
- Compare Veo 3 to the older Veo 2 and to specialized image models to see how fast video models are improving.
Methods (explained simply)
The approach is intentionally straightforward: the researchers “prompt” the video model.
- They give the model:
- An input image (used as the first frame of the video).
- A text instruction (what to do with the image).
- The model generates an 8-second video (720p, 24 frames per second) showing its step-by-step attempt to follow the instruction.
Why is this a big deal? In language AI, “prompting” replaced the need to retrain models for every task. The authors test if the same idea works for vision tasks with video models.
Key terms in plain language:
- Zero-shot: Solving a task the model was never specifically trained for, just by reading instructions.
- Foundation model: One powerful model that can do many different tasks.
- Chain-of-frames (CoF): Like “chain-of-thought” in LLMs, but in video. The model solves problems by changing the image frame-by-frame over time.
- “Best frame” vs “last frame”: Sometimes the model solves a task mid-video and then keeps animating. So the authors measure performance at the best frame (the peak moment) and at the last frame (the final state).
- pass@k: If you let the model try k times, how often does it succeed?
They evaluated:
- 62 tasks qualitatively (by watching videos and judging success).
- 7 tasks quantitatively (with clear, automatic scoring), including edge detection, segmentation, object extraction, image editing, maze solving, symmetry completion, and visual analogies.
Note: The API uses a “prompt rewriter” (an LLM that may refine instructions). The authors treated the whole system as one black box but also checked that a standalone LLM couldn’t reliably solve certain visual reasoning tasks from the image alone.
Main Findings
The results are organized into four levels of ability, each building on the previous:
Perception (seeing what’s in the image)
Veo 3 can:
- Detect edges and segment objects (outline and separate different things).
- Improve low-quality images (deblurring, denoising, low-light enhancement, super-resolution).
- Handle harder visual tasks like visual search and interpreting ambiguous images.
Why it matters: These are classic computer vision tasks usually handled by specialized models. Doing them “zero-shot” by prompting is impressive.
Modeling (understanding how the world works)
Veo 3 shows signs of “intuitive physics”:
- It reflects real-world properties like buoyancy (things float or sink), air resistance (how objects fall), and optics (reflection/refraction, color mixing).
- It keeps track of what’s in the scene over time (world-state memory).
- It recognizes patterns and categories, and can generate variations.
Why it matters: Modeling is more than seeing—it’s knowing the rules behind what you see, which is essential for prediction and planning.
Manipulation (meaningfully changing the scene)
Veo 3 can:
- Edit images based on instructions: background removal, inpainting/outpainting, colorization, style transfer, pose changes, view synthesis, and smooth object transformations.
- Simulate plausible object interactions (like dexterous hand movements) and use visual instructions to demonstrate tasks.
Why it matters: This shows the model understands 3D relationships and can maintain visual consistency when editing—key for future image/video editors.
Reasoning (solving step-by-step problems in space and time)
Veo 3 can:
- Solve mazes and simple navigation tasks by moving objects correctly without crossing walls.
- Reflect patterns to complete symmetry challenges.
- Do visual sequences and some analogies (e.g., “A is to B as C is to ?”).
- Use tools and solve simple puzzles.
Why it matters: Reasoning in vision means planning and applying rules over a sequence of frames. The “chain-of-frames” behavior suggests video models can develop step-by-step visual problem solving.
Quantitative highlights
- Edge detection: Veo 3 performs strongly for a zero-shot model (though still behind specialized state-of-the-art).
- Segmentation: Veo 3’s best-frame performance is comparable to a modern image editing model for easy scenes.
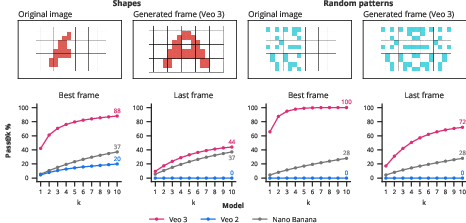
- Object extraction: A big jump from Veo 2 to Veo 3, reaching over 90% pass@10 on a simple dataset.
- Image editing: Veo 3 preserves details well but can add unintended animations; with better controls, it could become a powerful 3D-aware editor.
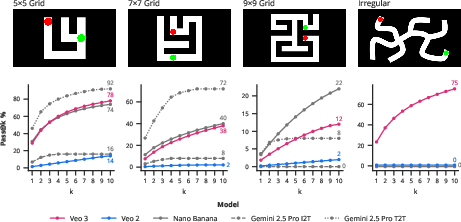
- Maze solving: Veo 3 greatly outperforms Veo 2 and benefits from multiple attempts; visual step-by-step solving has advantages over pure text approaches.
- Visual symmetry: Veo 3 beats Veo 2 and a reference image model, but results depend a lot on prompt wording.
- Visual analogies: Veo 3 succeeds on some transformations (like color, resize), but struggles with reflect/rotate, showing specific biases.
Overall trend: Veo 3 is much better than Veo 2 across tasks, suggesting rapid progress in video model capabilities.
Why This Is Important
- It signals a shift in vision AI similar to what happened in language AI: moving from many separate, specialized models to one general model you can prompt for almost any task.
- Video models operate in both space and time, letting them “think visually” through sequences—useful for planning, editing, and simulation.
- While not perfect yet, performance is improving quickly. As costs drop and controls improve, general video models may replace many task-specific vision tools.
Implications and Impact
- In the near future, designers, filmmakers, scientists, and robots could use a single video model to see, edit, simulate, and reason about visual scenes—just by describing what they want.
- Education and creativity tools could become more interactive: “Show me how to solve this maze,” or “Turn this sketch into a realistic scene,” handled by one model.
- Research and robotics might benefit from models that understand physics and plan visually.
- Like early LLMs, today’s video models are “jack of many trades, master of few,” but the rapid improvement from Veo 2 to Veo 3 suggests they’re on track to become the standard foundation for machine vision.
In short: The paper provides early but convincing evidence that video models can learn and reason without task-specific training. If this trend continues, they could become the universal engine for seeing and solving visual problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and can guide future research:
- Attribution of capability: The Vertex AI “prompt rewriter” (LLM) is active; the paper treats the rewriter+video model as a black box and does not quantify how much task success derives from the LLM vs. the video model. Ablations with the rewriter disabled, alternative rewriters, and controlled comparisons are needed.
- Quantitative coverage of “modeling” (intuitive physics) is missing: Despite extensive qualitative claims, there is no systematic, quantitative benchmarking on established physics datasets (e.g., IntPhys, Physion, Physion++); this prevents assessing true competence vs. surface plausibility.
- Dataset selection bias: Several evaluations use small, curated, or custom datasets (e.g., “easy” LVIS subset, custom animals, custom symmetry and analogy splits). Broader, harder, and standardized datasets are needed to avoid cherry-picking and to measure generalization.
- Success criteria and evaluation objectivity: Many tasks rely on author judgment or limited human ratings. Public, objective validators and ground-truth annotations for all evaluated tasks (including the 62 qualitative ones) should be released for reproducibility.
- “Best frame” vs. “last frame” oracle: Reporting “best frame” requires oracle selection; practical systems cannot choose post hoc. Develop automatic stopping/success detectors, evaluate consistency across frames, and report pass@k for predetermined frames or full trajectories.
- Prompt sensitivity and robustness: Performance varies greatly with phrasing, background color, and visual initialization. Systematic studies across prompts, languages, sampling parameters, and initial frames (including reporting temperature/decoding settings) are required to measure robustness.
- Editing control and unintended changes: The model often introduces camera motion and animation when asked to edit static images. Methods to constrain dynamics (e.g., freeze camera, spatial masks, motion suppression controls) and metrics to quantify locality and unintended edits are needed.
- Baseline breadth and fairness: Comparisons involve a narrow set of baselines (e.g., Nano Banana, SAMv2, Gemini). Broader, matched baselines across image/video editors and segmentation/detection models—including identical input formats and constraints—would yield fairer assessments.
- Constraint adherence and OOD generalization: Irregular mazes cause failures; illegal moves occur. Investigate decoding strategies (constraint-aware sampling), training augmentations, and verifiers that enforce legality, and test generalization to procedurally generated OOD structures.
- Systematic bias in visual analogies: Veo 3 performs below chance on rotation/reflection analogies. Analyze error modes, invariance/equivariance gaps, and training data biases; explore architectural inductive biases (e.g., group-equivariant layers) or augmentation regimes to fix these failures.
- Scaling and efficiency: The paper does not quantify how performance scales with video length, resolution, FPS, or inference cost/latency. Establish scaling laws (model/data size vs. zero-shot capability), cost–accuracy trade-offs, and energy/throughput metrics.
- Chain-of-frames (CoF) reasoning evidence: The CoF claim lacks controlled proofs that intermediate frames embody causal planning rather than pattern completion. Design tasks requiring explicit intermediate subgoals, measure plan consistency, and test frame interventions to validate causal dependence.
- Training data transparency and contamination: Web-scale training could include mazes, puzzles, and editing exemplars. Audit data sources and use held-out, procedurally generated benchmarks to rule out memorization; report contamination checks.
- Long-horizon memory and occlusion: Working memory is shown qualitatively over short, 8-second clips. Quantify state tracking, object permanence, occlusion handling, and memory decay for longer horizons and complex scenes.
- Robustness stress testing: Beyond basic denoising, robustness to occlusions, clutter, adversarial perturbations, viewpoint/illumination changes, and compression artifacts is under-tested. Build stress-test suites and report failure modes and rates.
- Embodiment and real-world control: Dexterous manipulation and robot navigation are simulated. Investigate how video-generated plans can be converted into executable policies for real robots (sim-to-real), including safety, latency, and reliability.
- Safety, ethics, and misuse: Powerful zero-shot editing/manipulation capabilities raise risks (e.g., deceptive media). Develop watermarking, edit provenance, misuse detection, and policy guidelines; quantify false positives/negatives in safety filters.
- Automatic verifiers and self-correction: Aside from maze checks, most tasks lack automatic validators. Create verifiers (physics constraints, mask quality, color symmetry) and integrate self-verification/self-correction to improve pass@1 without excessive sampling.
- Inference-time scaling strategies: Pass@10 improves markedly over pass@1, but self-consistency, rejection sampling, and verifier-guided decoding are not explored. Evaluate these methods for video generation and quantify their gains vs. compute costs.
- Multimodal instruction generality: Performance under multilingual prompts, speech inputs, or image-only conditioning (no text) is unstudied. Measure instruction following across modalities and languages.
- Reproducibility and version drift: Veo 3 is a “preview” model and the prompt rewriter may evolve. Publish exact configs (model IDs, rewriter on/off, decoding params), random seeds, full prompts, and release generated videos/datasets to enable faithful replication.
- Cost–accuracy adoption analysis: The claim that video models will replace bespoke CV models lacks Pareto analyses. Provide application-level benchmarks comparing accuracy, latency, cost, and reliability vs. specialized models.
- Failure-case taxonomy and root-cause analysis: Appendix failures are anecdotal; there’s no systematic error taxonomy (geometry/physics/semantics/planning) or attribution to components (data, architecture, decoding). Build diagnostic suites and ablate to identify causes.
- Green-screen bias in segmentation: Performance improves with green backgrounds, suggesting training-data biases. Test across varied backgrounds and chroma keys; quantify sensitivity and develop de-biasing strategies.
- Sampling and randomness disclosure: The paper leverages multiple attempts but doesn’t detail sampling temperatures, seeds, or stochasticity controls. Standardize and report these to interpret pass@k and variance.
- Stop-on-success behavior: The model keeps animating after solving tasks, degrading last-frame performance. Introduce and evaluate stop tokens, success triggers, or goal-conditioned termination to align generation with task completion.
- Generalization beyond 720p/8s: All generations are 720p, 24 FPS, 8 seconds. Evaluate if longer videos, higher resolutions, or different aspect ratios improve or degrade perception, manipulation, and reasoning.
- Tool use integration: Tool-use is shown qualitatively; no framework evaluates how external tools (planners, solvers, verifiers) can be orchestrated with video models. Develop modular pipelines and measure end-to-end gains.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the paper’s demonstrated zero-shot perception, modeling, manipulation, and early visual reasoning capabilities. Each item includes sector links and practical tools/workflows, along with assumptions or dependencies that affect feasibility.
- Zero-shot visual preprocessing and enhancement for creative pipelines (software, media/entertainment, e-commerce)
- Tools/products/workflows: API-driven modules for superresolution, denoising, low-light enhancement, edge maps, class-agnostic segmentation, background removal; plug-ins for Photoshop/Blender/Figma; batch “best-frame” selection and auto-verification scripts
- Assumptions/dependencies: Prompt engineering quality; pass@k strategy with automatic verifiers; cost/latency acceptable for batch workflows; control over unintended animation (prefer last-frame evaluation); green-screen prompts outperform white in segmentation
- 3D-aware image editing and view synthesis at the edge of production (media/advertising, design, social)
- Tools/products/workflows: “One-model” edit assistants for style transfer, colorization, in/outpainting, text manipulation, reposing, transfiguration; automated LinkedIn headshot enhancer; brand-constrained prompt templates and QA gates
- Assumptions/dependencies: Need guardrails to prevent unintended motion/camera changes; multiple attempts with best-frame pickers; human-in-the-loop review; current fidelity comparable to strong image editors on many tasks but not yet SOTA on all
- E-commerce product imagery automation (retail/e-commerce)
- Tools/products/workflows: Background removal and “line-up” object extraction; consistent white/green-screen cataloging; automatic mask generation for colorways; 360° product view synthesis via prompt sets
- Assumptions/dependencies: Stable lighting/style prompting; verification of counts via connected-component checks; brand compliance; pass@k workflows to reach high reliability
- Synthetic data generation for computer vision training (software, robotics, manufacturing)
- Tools/products/workflows: “Dataset factory” that batch-generates scenes with accurate edges/segmentation for pretraining/augmentation; prompt catalogs for diversity; label extraction pipelines from generated frames
- Assumptions/dependencies: Label correctness validated by auto-verifiers; domain gap management (web-scale generative outputs vs. target domain); licensing/compliance for synthetic media
- Visual inspection assistant for presence/absence, counting, and simple QC (manufacturing, logistics)
- Tools/products/workflows: Zero-shot instance extraction and counting (animals dataset analogue → parts/items); rule-based post-checkers; exception queues for human review
- Assumptions/dependencies: Domain imaging conditions are controlled (illumination, perspective); last-frame stability; on-prem or private cloud acceptable; not real-time critical yet
- Robotics research prototyping with chain-of-frames trajectories (robotics, academia)
- Tools/products/workflows: Generate path plans in constrained environments (maze analogs), tool-use demonstrations, affordance highlighting; extract 2D trajectories from frames for imitation-learning pretraining
- Assumptions/dependencies: Mapping 2D video trajectories to robot kinematics; physics plausibility not guaranteed; requires conversion to executable policies; LLM prompt rewriter may contribute reasoning—black-box assumptions
- Physics explainers and visual tutoring content (education)
- Tools/products/workflows: Prompted demonstrations of buoyancy, air resistance, optics, color mixing, “Visual Jenga” object-dependency sequences; classroom-ready clips with guided narration
- Assumptions/dependencies: Scientific correctness monitored by educators; curated prompt templates; QA for edge cases; minimal dependence on implicit LLM reasoning for correctness
- Rapid prototyping of UX/documentation animations (software/product design)
- Tools/products/workflows: Auto-generated micro-animations that illustrate flows (graph traversal, visual BFS, sorting, shape-fitting); design documentation library with short clips
- Assumptions/dependencies: Narrative clarity depends on prompt specificity; post-selection of best frames; avoid over-animation via constraints
- Accessibility image aids (consumer/daily life)
- Tools/products/workflows: Mobile app to improve low-light/noisy images, enhance edges/contrast; simple background cleaning for personal photos
- Assumptions/dependencies: Privacy-preserving local or private-cloud inference; cost constraints; disable unintended motion
- Benchmarking and method research for CoF reasoning (academia)
- Tools/products/workflows: Reproducible evaluation harness for edge/segmentation/editing/maze/symmetry/analogy; prompt-sensitivity sweeps; pass@k scaling curves; external verifiers
- Assumptions/dependencies: Access to Veo-like APIs; clear separation of LLM prompt rewriter vs. video model where needed; standardized reporting of best vs. last-frame metrics
Long-Term Applications
These applications require further research, scaling, controllability, or domain adaptation before broad deployment. Each item specifies sectors, plausible tools/products, and key dependencies.
- Unified, general-purpose vision foundation platforms replacing many bespoke CV models (software across sectors)
- Tools/products/workflows: “VisionOps” platforms integrating perception→modeling→manipulation→reasoning in one API; instruction tuning, RLHF, verifier-chains; enterprise-grade prompt libraries
- Assumptions/dependencies: Significant cost reductions; reliability on par with SOTA for critical tasks; robust prompt controls; governance and audit trails
- Video-model–based planners for autonomous robotics (robotics, manufacturing, logistics)
- Tools/products/workflows: CoF-to-actions planning layer that reasons spatially/temporally; coupling with simulator/real-time control; closed-loop verification (safety checkers)
- Assumptions/dependencies: Real-time inference; physics fidelity; sim-to-real transfer; safety certification; tight integration with robot kinematics and sensors
- All-in-one, 3D-aware video editing suites (media/entertainment)
- Tools/products/workflows: Unified editor for precise multi-step edits with controllable animation, scene composition, reposing, style transfer; timeline-aware “edit verifiers”
- Assumptions/dependencies: Fine-grained control over camera/object motion; multi-turn edit consistency; watermarking/rights management
- Clinical imaging augmentation and planning (healthcare)
- Tools/products/workflows: Segmentation/enhancement for radiology/endoscopy; visual reasoning for surgical path previews and tool-use planning; QA via clinical verifiers
- Assumptions/dependencies: Domain-specific training and validation; regulatory approval (e.g., FDA/CE); interpretability; strict data governance and bias/fairness checks
- Facility/layout planning and logistics visualization (construction/operations, energy, retail)
- Tools/products/workflows: CoF-based planners that propose feasible paths/layouts (e.g., “piano-mover” analogs, warehouse aisle planning); integration with CAD/BIM and digital twins
- Assumptions/dependencies: Accurate constraints ingestion; multi-modal inputs (text, CAD, sensor data); rigorous physical feasibility checks and cost models
- Interactive visual STEM tutors (education)
- Tools/products/workflows: Tutors that generate step-by-step visual reasoning sequences for geometry, physics, logic puzzles; student-adaptive prompting
- Assumptions/dependencies: Verified correctness; pedagogical alignment; guardrails against misleading animations; offline/on-device inference options
- Policy and standards for generalist visual models and synthetic media (policy, public sector)
- Tools/products/workflows: Government benchmarking suites for generalist models; procurement guidelines emphasizing pass@k, verifier use, prompt transparency; synthetic media labeling policies
- Assumptions/dependencies: Cross-agency collaboration; transparency from vendors (prompt rewriter disclosures); watermarking standards; auditing frameworks
- Visual inspection at scale with autonomous drones/robots (energy, infrastructure)
- Tools/products/workflows: Real-time detection/segmentation over complex assets (grids, pipelines); anomaly triage with CoF reasoning for spatiotemporal patterns; maintenance planning clips
- Assumptions/dependencies: On-device acceleration; ruggedized hardware; robust domain adaptation; safety and compliance
- Financial/retail visual analytics (finance, retail)
- Tools/products/workflows: Store-traffic flow mapping (maze-to-navigation analogs); planogram compliance via segmentation; visual anomaly detection in branches/ATMs
- Assumptions/dependencies: Privacy/security policies; integration with operational systems; high reliability via pass@k + verifiers; cost control for continuous monitoring
- Safety-focused verifier-chains for visual reasoning (software safety across sectors)
- Tools/products/workflows: External checkers that validate each frame’s legality (e.g., maze crossing rules), correctness of edits, geometry constraints; automatic retry/repair loops
- Assumptions/dependencies: Standardized metrics and checkers; acceptance of inference-time scaling (multiple attempts); system-level orchestration to combine generation + verification
Notes on common assumptions and dependencies across applications:
- Prompt sensitivity: Performance varies significantly by prompt wording and visual setup; expect prompt catalogs, guardrails, and best practices.
- Multiple attempts (pass@k) and auto-verification: Reliability improves with retries and programmatic checkers; build this into production pipelines.
- Best-frame vs. last-frame: Prefer predetermined frames (e.g., last) for automation, but incorporate best-frame selection to raise quality.
- Cost/latency and access: Current video generation is pricier than task-specific models; trends indicate rapid cost declines, but budgeting and batching strategies are important now.
- Model composition: Vertex AI’s prompt rewriter may contribute to solutions in some tasks; disclose and, where needed, isolate LLM vs. video-model contributions.
- Domain adaptation and governance: For regulated or high-stakes domains (healthcare, infrastructure), expect domain-specific tuning, auditability, and compliance frameworks.
Glossary
- Additive/Subtractive Color Mixing: Methods of combining or removing light to produce colors; additive mixing uses light sources, subtractive mixing uses pigments or filters. "and additive/subtractive color mixing"
- BIPEDv2: A benchmark dataset for edge detection used to evaluate models on natural images. "Edge detection on all 50 test images from BIPEDv2"
- Chain-of-frames (CoF): A reasoning paradigm where a video model applies step-by-step changes over time and space via frame-by-frame generation. "chain-of-frames (CoF)"
- Chain-of-thought (CoT): A prompting technique that encourages models to generate intermediate reasoning steps to solve problems. "chain-of-thought enabled models to tackle reasoning problems"
- Class-agnostic instance segmentation: Segmentation of all distinct objects in an image without specifying categories. "Class-agnostic instance segmentation on a subset of 50 easy images (1-3 large objects) from LVIS"
- Conjunctive search: A perceptual task requiring identification of targets defined by a conjunction of features (e.g., color and shape), related to the binding problem. "conjunctive search"
- Denoising: The process of removing noise from images or video, often a core objective in diffusion models. "denoising"
- Emu-edit: A dataset for evaluating image editing capabilities guided by text instructions. "Emu-edit"
- Few-shot in-context learning: Learning to perform a task from a handful of examples provided in the prompt, without parameter updates. "few-shot in-context learning"
- Generative objective: Training objective that requires models to generate continuations (e.g., text or video) rather than classify or regress. "large-scale training with a generative objective (text/video continuation)"
- Inpainting: Filling in missing or masked regions of an image with plausible content. "inpainting"
- Intuitive physics: The learned ability of models to predict and reason about physical properties and dynamics without explicit physics equations. "investigated and quantified intuitive physics in deep models"
- KiVA: A benchmark for visual analogies that tests understanding of transformations and relations between objects. "from KiVA"
- LLM-based prompt rewriter: An automated system that reformulates user prompts using a LLM before passing them to the generator. "an LLM-based prompt rewriter"
- LVIS: A large-scale dataset for instance segmentation with long-tail object categories. "from LVIS"
- mIoU: Mean Intersection over Union; an evaluation metric averaging IoU across classes or instances for segmentation accuracy. "mean Intersection over Union (mIoU)"
- Nano Banana: A state-of-the-art image editing model used as a reference baseline. "state-of-the-art image editing model Nano Banana"
- Object affordances: The action possibilities that an object offers based on its properties and context. "recognizing object affordances"
- OIS: Optimal Image Scale; an edge-detection metric measuring best performance per image across thresholds. "measured by OIS"
- Omniglot: A dataset of handwritten characters used to study pattern recognition and compositionality. "inspired by the Omniglot dataset"
- Outpainting: Extending an image beyond its original borders by synthesizing new, coherent content. "outpainting"
- Pass@k: The probability that at least one of k independent attempts succeeds; used to aggregate performance over multiple generations. "0.77 pass@10"
- Prompt engineering: Crafting and tuning textual and visual prompts to elicit desired model behavior. "prompt engineering---including the visual prompt a.k.a. starting frame---is as important for visual tasks as it is for LLMs"
- SAMv2: A bespoke promptable segmentation model (Segment Anything v2) specialized for segmenting objects. "SAMv2"
- Super-resolution: Enhancing the resolution of an image to reveal finer details. "super-resolution"
- Vertex AI: Google Cloud’s platform offering APIs for generative models, including video generation. "Google Cloud's Vertex AI API"
- Visual analogies: Tasks requiring completion of relationships (e.g., A:B::C:?); assess understanding of transformations and relations. "Visual analogies test a model's ability to understand transformations and relationships between objects"
- Visual Jenga: A benchmark that tests understanding of object dependencies via counterfactual inpainting and removal. "Visual Jenga task"
- Visual reasoning: The capacity to plan and apply logical operations across spatial and temporal visual information. "visual reasoning"
- Visual symmetry: Pattern completion and reflection tasks assessing spatial reasoning and symmetry understanding. "Visual symmetry."
- Zero-shot learning: Solving tasks without prior task-specific training, relying solely on instructions or prompts. "Zero-shot learning here means that prompting a model with a task instruction replaces the need for fine-tuning or adding task-specific inference heads."
Collections
Sign up for free to add this paper to one or more collections.