Let ViT Speak: Generative Language-Image Pre-training
Abstract: In this paper, we present \textbf{Gen}erative \textbf{L}anguage-\textbf{I}mage \textbf{P}re-training (GenLIP), a minimalist generative pretraining framework for Vision Transformers (ViTs) designed for multimodal LLMs (MLLMs). To better align vision encoders with the autoregressive nature of LLMs, GenLIP trains a ViT to predict language tokens directly from visual tokens using a standard language modeling objective, without contrastive batch construction or an additional text decoder. This design offers three key advantages: (1) \textbf{Simplicity}: a single transformer jointly models visual and textual tokens; (2) \textbf{Scalability}: it scales effectively with both data and model size; and (3) \textbf{Performance}: it achieves competitive or superior results across diverse multimodal benchmarks. Trained on 8B samples from Recap-DataComp-1B, GenLIP matches or surpasses strong baselines despite using substantially less pretraining data. After continued pretraining on multi-resolution images at native aspect ratios, GenLIP further improves on detail-sensitive tasks such as OCR and chart understanding, making it a strong foundation for vision encoders in MLLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Let ViT Speak: Explaining “Generative Language-Image Pre-training (GenLIP)” for a 14-year-old
What is this paper about?
This paper introduces a simple way to teach a computer “vision system” to describe images using words. The system is built on a Vision Transformer (ViT), which you can think of as very smart “eyes” that look at an image piece by piece. The big idea is to let these “eyes” directly learn to talk—no extra talking module needed—so the whole model learns to turn pictures into text naturally.
What questions are the researchers trying to answer?
The authors focused on three main questions:
- Can we train a vision model to produce words directly from images (like writing a caption), instead of using complicated extra parts?
- Will this simpler design still work well, especially for tricky tasks like reading text in images (OCR) or understanding charts?
- Does this approach scale well—meaning, does it keep getting better when we use more data and bigger models?
How did they do it? (Methods in simple terms)
They use a Vision Transformer (ViT) and train it to describe images using a single, language-style learning rule. Here’s how it works in everyday language:
- Images as puzzle pieces: Each image is cut into small square patches (like pixels grouped into tiles). These patches become “tokens,” which are like Lego bricks the model can process.
- Words as tokens: The caption (the sentence describing the image) is also split into tokens (small chunks of words).
- One big line of tokens: The model reads the image tokens first, then the text tokens—so the format is [image pieces, then words].
- One simple goal: Predict the next word. The model learns to write the caption one word at a time, using what it “saw” in the image and what it has already written. This is called “autoregressive language modeling”—like writing a sentence word by word without looking ahead.
- Special attention rule (Prefix-LM):
- Image tokens can look at each other freely (to understand the whole picture).
- Text tokens can only look backward (to avoid cheating by looking at future words).
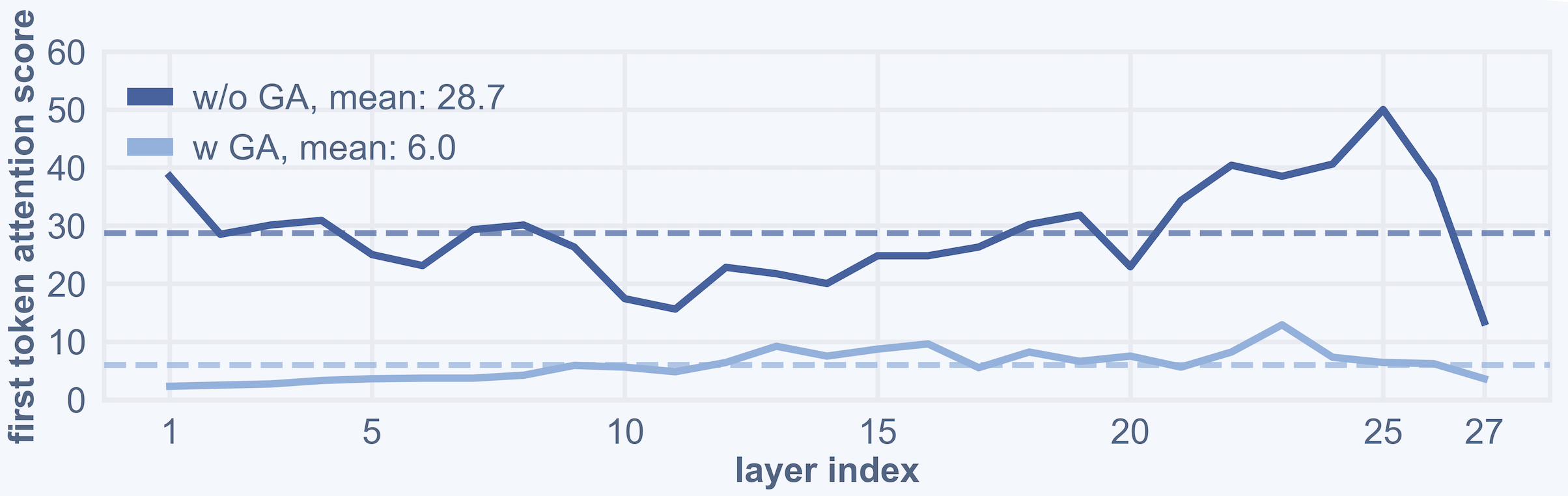
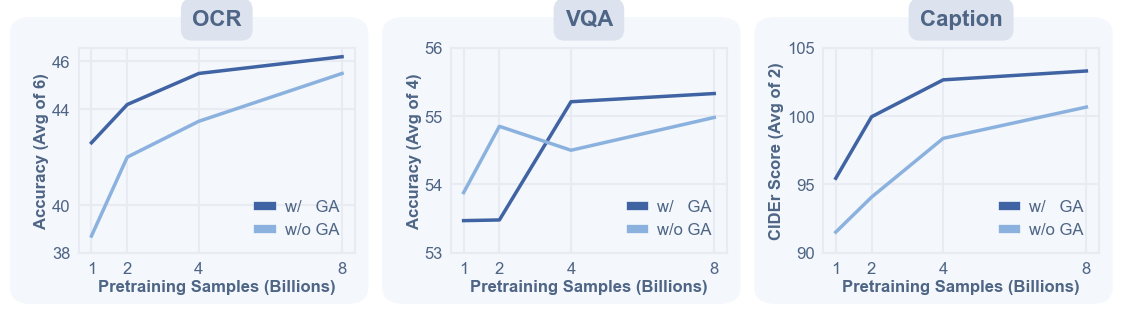
- Fixing a common problem (Gated Attention): Sometimes, the model over-attends to the very first token and ignores the rest—like a student who only listens to the first clue and stops paying attention. The authors add a small “gate” (a learned control) that balances attention across tokens so the model uses more of the image, not just one part.
- Two-stage training:
- Stage 1: Train on a huge set of 8 billion image–caption examples at a fixed size (224×224).
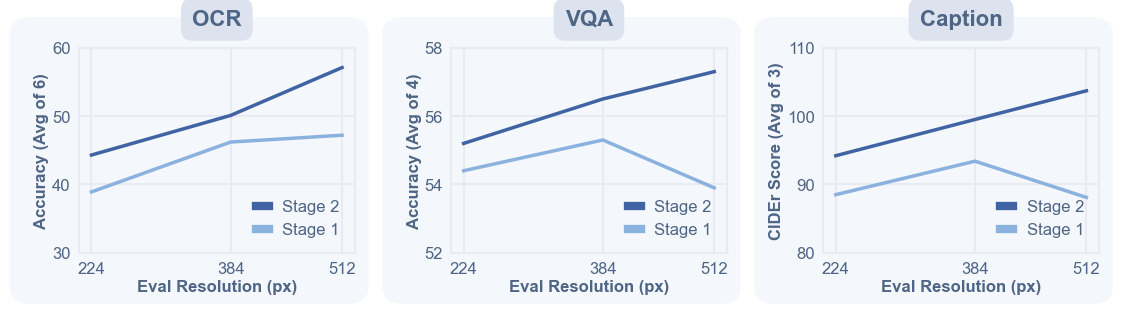
- Stage 2: Fine-tune on higher-quality, longer captions with images kept in their original shapes/sizes (not forced into a square). This helps with details—like reading small text (OCR) and understanding charts.
When they use this ViT as a “vision encoder” for bigger multimodal systems (models that use both images and text), they keep the visual parts and throw away the text generator head, passing the visual features to a LLM.
What did they find, and why does it matter?
The main results show that this simple approach works really well:
- Strong performance with less data: Trained on 8B samples, their model matches or beats big-name systems (like CLIP, SigLIP, and SigLIP2) that were trained on much more data.
- Especially good at reading and details: It does great on tasks like OCR (reading text in images), document understanding, and chart comprehension—areas that need careful attention to fine details.
- Scales well: As they increase the amount of data and the model size, performance keeps improving predictably.
- Simpler and faster to train: No need for two separate towers or an extra text decoder. This makes the system easier to build and potentially cheaper to train.
- Better fit for multimodal LLMs: Because it learns to predict words directly from images, it matches how LLMs already work (predicting next tokens). That makes the parts fit together more naturally.
In short, the model proves that “letting the ViT speak”—having one transformer handle both vision and language tokens and learning to write captions—can be both simple and powerful.
Why is this important for the future?
This research suggests a cleaner path to building strong vision components for AI systems that understand both images and text (like AI assistants that can look at your photo and answer questions). The impacts include:
- Easier building blocks for multimodal AI: Simpler design means fewer moving parts and fewer things to tune.
- Better document and data understanding: Strong gains in OCR and charts mean better tools for reading documents, forms, receipts, slides, and infographics.
- More efficient training: Good results with less data mean researchers and companies may spend less time and money to reach high performance.
- A strong foundation for future AI: These vision encoders can plug into many different multimodal systems and tasks.
Overall, the paper shows that sometimes, the most effective solution is the simplest one—just teach the “eyes” to speak directly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Data contamination and de-duplication: No decontamination against evaluation sets or near-duplicate removal is reported for Recap-DataComp-1B or stage-2 data; quantify leakage risk and re-run with rigorous decontamination.
- Dataset composition sensitivity: Lacks controlled ablations on caption quality, domain mix, and long-caption proportion; measure how each factor (caption noise, document-heavy fraction, web domain balance) drives gains.
- Multilingual coverage: Training and evaluation are English-centric; evaluate and/or pretrain on multilingual captions and non-Latin scripts for OCR/VQA (e.g., Japanese/Arabic) and report cross-lingual transfer.
- Scaling beyond 8B samples: Only up to 8B samples and ~1.1B parameters are tested; extend scaling curves (data and model) with compute-optimal analysis and quantify diminishing returns.
- Compute/efficiency reporting: No wall-clock time, FLOPs, memory, or throughput comparisons vs contrastive and encoder–decoder baselines; provide cost–quality trade-offs, especially with 16k-token packing and AnyRes.
- Gated attention ablations: The gating mechanism is introduced without systematic study; ablate gate placement, initialization, per-layer strength, alternatives (e.g., attention masking, CLS removal, entropy regularization), and quantify attention-sink mitigation.
- Prefix-LM masking choice: No comparison to other attention masking regimes (full bidirectional, fully causal, segmented masks); isolate how prefix-LM contributes to performance.
- Positional encoding choices: MRoPE is adopted without ablation versus absolute/relative 2D encodings or learned ViT position embeddings; test sensitivity at AnyRes and high token counts.
- Feature readout location: Only last-LN vision features are used; compare pooling strategies (mean/CLS), intermediate-layer readouts, learnable query resamplers, or token selection for LLM input.
- Connector design constraints: A 2-layer MLP projector is the sole connector; benchmark against cross-attention adapters, Perceiver resamplers, token compression/pruning, and MoE connectors for quality–latency trade-offs.
- Token budget trade-offs: AnyRes caps patches at [16, 1024]; characterize accuracy–latency curves as a function of token count and test higher caps for high-resolution documents.
- Stage-2 factor disentanglement: The second stage combines higher resolution, native aspect ratios, and long captions; perform controlled ablations to separate the effects of each component.
- Retrieval capability: No image–text retrieval (Recall@K) results; evaluate retrieval or propose an efficient retrieval head compatible with single-tower generative pretraining.
- Classification and linear probing: The paper mentions linear-probe issues pre-gating but omits post-gating ImageNet linear-probe and zero-shot classification; add standardized classification evaluations.
- Dense and grounded vision tasks: No results on detection/segmentation/grounding (e.g., COCO-Det, ADE20K, RefCOCO); test region-level understanding and localization performance.
- Robustness, safety, and privacy: Absent evaluation for OOD robustness, adversarial perturbations, occlusions, demographic bias, memorization/privacy risks (especially with OCR of sensitive content), and toxicity; add targeted suites and audits.
- Hallucination and faithfulness: Limited faithfulness analysis; include dedicated hallucination metrics (e.g., CHAIR, POPE in frozen setting) and qualitative audits for object/text hallucinations.
- Multi-image and long-context reasoning: Architecture and evaluations focus on single images; test multi-image VQA, interleaved document pages, and extremely long sequences near the 16k limit.
- Video and temporal modeling: No extension to video; evaluate temporal tokens, attention design for time, and pretraining on video–caption corpora.
- Objective design space: Only next-token prediction on text is used; explore complementary objectives (masked image modeling, region–word alignment, language-only LM warmup) and their interactions with the minimalist design.
- Instructional pretraining: Pretraining uses captions only; test whether adding conversational multimodal pretraining reduces SFT needs or improves instruction following and reasoning.
- Benchmark coverage and comparators: Some strong encoders (e.g., EVA-CLIP, DINOv2-Register, ALIGN variants) are absent; broaden head-to-head comparisons under identical token budgets, connectors, and LLMs.
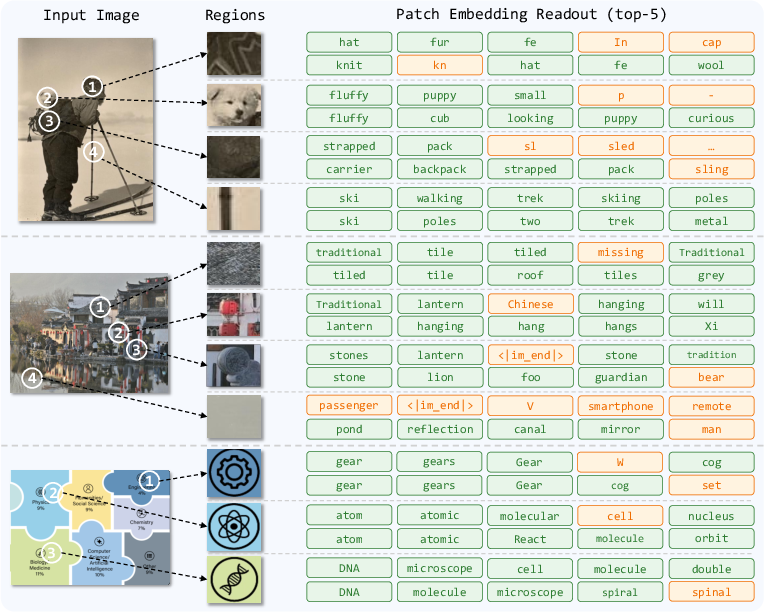
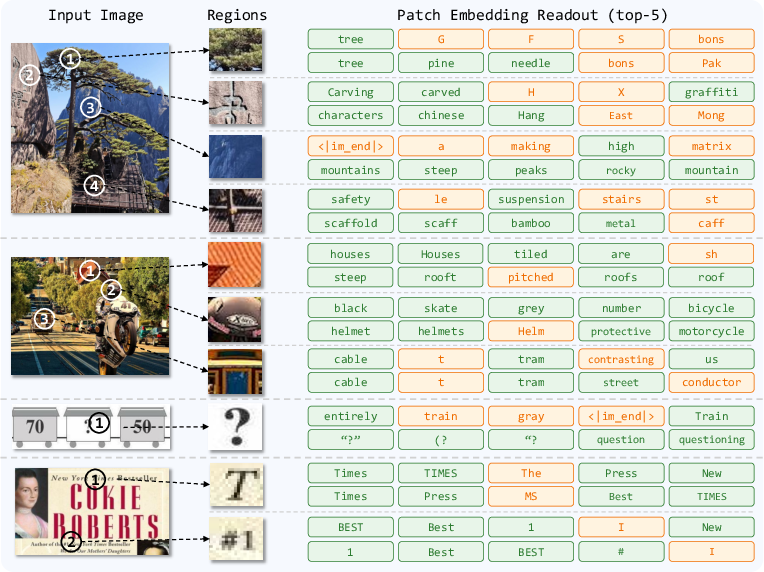
- Interpretability at scale: Patch-semantics readout is qualitative; develop quantitative probes for token–region alignment, spatial specificity, and causal impact of visual tokens on generated text.
- Deployment practicality: AnyRes with long sequences can be costly; investigate token pruning/compression, dynamic routing, or early-exit strategies to reduce inference latency without degrading accuracy.
- Reproducibility and release: Clarify model/checkpoint availability, exact hardware budgets, and training scripts; report energy footprint to support reproducibility and environmental assessment.
Practical Applications
Immediate Applications
- Drop-in vision encoder upgrade for existing MLLMs
- Sectors: software, cloud AI, platform ML teams
- What: Replace CLIP/SigLIP encoders in LLaVA-/QwenVL-like stacks with GenLIP to boost document/OCR, chart/diagram, and captioning performance without changing downstream LLMs
- Tools/workflows: 2-layer MLP projector alignment; frozen-encoder fine-tuning workflows (e.g., LLaVA OneVision-style SFT); any-resolution preprocessing with native aspect ratios
- Assumptions/dependencies: Availability of GenLIP checkpoints and license; projector re-training; serving infrastructure that supports variable token counts
- Document AI for forms, invoices, and receipts
- Sectors: finance, insurance, logistics, government, healthcare admin
- What: Higher-accuracy key information extraction and Q&A over scanned/photographed documents using improved OCR-centric visual features
- Tools/workflows: Document VQA pipelines; RPA bots; retrieval-augmented generation (RAG) over extracted fields; validation UIs
- Assumptions/dependencies: Domain fine-tuning for layouts/tables; privacy/compliance controls; multilingual data if non-English documents are expected
- Chart and infographic assistants
- Sectors: business intelligence, analytics, publishing, education
- What: Explain charts, answer questions, and summarize dashboards or scientific figures (improved performance on ChartQA/AI2D/InfoVQA)
- Tools/workflows: Plugins for Tableau/Power BI; scholarly PDF/figure assistants; enterprise analytics copilots
- Assumptions/dependencies: Access to high-quality chart screenshots/figures; handling of multi-visual inputs (multiple panels) as separate images or with light pipeline changes
- Accessibility: image-to-speech and screen-reading
- Sectors: consumer accessibility, public sector
- What: Read scene text, signage, menus, and describe images more faithfully; augment screen readers with better on-screen text understanding
- Tools/workflows: Mobile apps or browser extensions; server-backed captioning APIs with any-res images; on-device So/16 variants for lower latency
- Assumptions/dependencies: Latency/compute constraints on devices; robustness under low-light or motion blur; multilingual OCR needs additional data
- Screenshot/UI understanding for QA, agents, and RPA
- Sectors: software engineering, test automation, enterprise RPA
- What: Read UI labels/states from screenshots to drive test assertions, GUI navigation, and agentic tool selection
- Tools/workflows: Screenshot-to-text pipelines; UI state extraction for no-code bots; integration with action selection LLMs
- Assumptions/dependencies: Domain fine-tuning on specific OS/app UIs; guardrails for hallucinations; resolution variability handled via any-res path
- Content platforms: alt-text generation and policy moderation
- Sectors: social media, e-commerce, marketplaces
- What: Generate richer alt-text for accessibility/SEO and detect/flag policy-violating text appearing in images
- Tools/workflows: Batch captioning services; moderation filters for embedded text; human-in-the-loop review interfaces
- Assumptions/dependencies: Consistent quality control; configurable safety taxonomies; potential biases from web caption pretraining
- Enterprise search and knowledge indexing
- Sectors: enterprise IT, knowledge management
- What: Index scanned documents and images by GenLIP-derived captions and entities to improve multimodal search and RAG
- Tools/workflows: Caption/entity extraction + vector indexing; deduplication and doc linking; evaluator dashboards
- Assumptions/dependencies: Hallucination mitigation (e.g., confidence scoring, cross-checking); PII handling; multilingual coverage
- Data annotation acceleration and weak supervision
- Sectors: ML data operations, labeling services
- What: Auto-captions for rapid triage and preliminary labels; patch-semantics readout to suggest region-level tags for curators
- Tools/workflows: Labeling UIs showing top token predictions per region; active learning loops; QC pipelines
- Assumptions/dependencies: Patch-to-token alignments are emergent and imperfect; requires human oversight and calibration
- Training stability and cost reduction for internal multimodal pretraining
- Sectors: AI infrastructure, research labs
- What: Adopt gated attention to mitigate attention sink and use packing + flex-attention for efficient Prefix-LM training
- Tools/workflows: PyTorch flex-attention; gated attention layer plug-in; standardized any-res loaders with token budgets
- Assumptions/dependencies: Engineering effort to retrofit training stacks; PyTorch version support; monitoring for convergence/spikes
- Industrial reading (meters, panels, labels)
- Sectors: energy, manufacturing, utilities
- What: Read digital displays, labels, and safety signage from camera feeds for monitoring and safety checks
- Tools/workflows: Edge inference with So/16; periodic capture and alerting dashboards
- Assumptions/dependencies: Environmental variability (glare, distance) and domain-specific fine-tuning; integration with OT/SCADA
Long-Term Applications
- Multilingual document and scene-text understanding
- Sectors: global enterprise, public services, travel
- What: Extend GenLIP with multilingual tokenizers/data for robust non-Latin OCR and mixed-script documents
- Tools/workflows: Continued pretraining with multilingual captions; tokenizer expansion; cross-script evaluation suites
- Assumptions/dependencies: Availability of large-scale multilingual image–text corpora; careful handling of language-specific typography
- End-to-end, lighter multimodal stacks and on-device assistants
- Sectors: mobile/AR, consumer AI
- What: Compress/scale So/16 variants for edge devices to enable real-time AR captioning and text-reading assistants
- Tools/workflows: Knowledge distillation from g/16; quantization/pruning; optimized any-res inference kernels
- Assumptions/dependencies: Tight latency/memory budgets; battery/thermal constraints; privacy-by-design for on-device processing
- Advanced document agents (multi-page, structured extraction, reasoning)
- Sectors: legal, finance, healthcare, government
- What: Agents that navigate long, multi-page documents, extract structured data, and reason over charts/diagrams within the same workflow
- Tools/workflows: Pagination-aware chunking; memory and tool-use with retrieval; layout-aware adapters
- Assumptions/dependencies: Training data for multi-page layouts; evaluation standards; integration with knowledge bases
- Scientific and analytics copilots with chart-grounded reasoning
- Sectors: research, pharma, engineering, BI
- What: End-to-end pipelines that convert figures and tables into structured data, generate explanations, and check consistency with text
- Tools/workflows: Figure/table parsers connected to GenLIP encoders; structured extraction schemas; hypothesis checking with LLMs
- Assumptions/dependencies: Ground-truth figure annotations; domain ontologies; reliability auditing
- Vision-grounded explainability via patch-to-token rationales
- Sectors: regulated AI (finance/health), safety-critical systems
- What: Use patch-semantics readout for human-inspectable rationales linking visual regions to model outputs
- Tools/workflows: Saliency overlays; token-level attributions; audit trails
- Assumptions/dependencies: Further research to make alignments faithful and robust; user studies; calibration methods
- Robotics and autonomous systems that read and follow visual instructions
- Sectors: warehousing, manufacturing, maintenance
- What: Robots that read signs, labels, SKUs, and step-by-step visual instructions for task execution
- Tools/workflows: Multimodal controllers with GenLIP encoders; task graphs; safety interlocks
- Assumptions/dependencies: Real-world robustness (lighting, occlusion); integration with perception stacks; additional training for action grounding
- Domain-specific encoders with less data/compute
- Sectors: niche industries (e.g., aviation logs, lab instruments)
- What: Train specialized GenLIP encoders on modest domain corpora leveraging the minimalist objective for data efficiency
- Tools/workflows: Small-scale continued pretraining; domain adapters/LoRA; evaluation harnesses
- Assumptions/dependencies: Availability/curation of domain captions; transfer learning best practices
- Standardized any-resolution serving and dynamic token budgeting
- Sectors: AI platforms, cloud inference
- What: Serving frameworks that accept native aspect ratios and dynamically allocate visual tokens for quality–cost trade-offs
- Tools/workflows: Token budget schedulers; autoscaling based on content complexity; billing linked to token use
- Assumptions/dependencies: Scheduler policies; user experience design for quality/cost controls
- Training frameworks that adopt prefix-LM + gated attention as defaults
- Sectors: open-source ML, enterprise AI R&D
- What: General-purpose libraries for single-transformer, generative multimodal pretraining with stability enhancements
- Tools/workflows: Reference implementations; evaluation leaderboards; recipe cards for data/model scaling
- Assumptions/dependencies: Community adoption; benchmarking across tasks beyond OCR/captioning
- Compliance and redaction automation
- Sectors: legal, enterprise security
- What: Automatically detect and redact sensitive text in images/documents prior to storage/sharing
- Tools/workflows: Policy-driven detectors; redaction UIs and audit logs; integration with DLP systems
- Assumptions/dependencies: High-precision detection across fonts/scripts; false positive control; regulatory acceptance
Notes on feasibility across applications:
- Model size vs deployment: GenLIP-g/16 (~1.1B params) offers best accuracy but higher latency/memory; So/16/L/16 are better suited for edge or high-throughput use.
- Language coverage: Pretraining data and tokenizer (Qwen3) likely bias toward English; multilingual deployments need additional training.
- Data quality and safety: Web captions can introduce bias/hallucinations; human-in-the-loop and calibration are recommended for high-stakes use.
- Licensing and availability: Adoption depends on the release terms of GenLIP weights/code and the rights to use Recap-DataComp-derived models.
- Privacy/compliance: Document applications must ensure secure processing and storage; on-device or private-cloud deployment may be required.
Glossary
- Attention sink: A failure mode where attention disproportionately focuses on a specific token, degrading representation quality. "attention becomes overly concentrated on the first token of the input sequence, a phenomenon known as the attention sink."
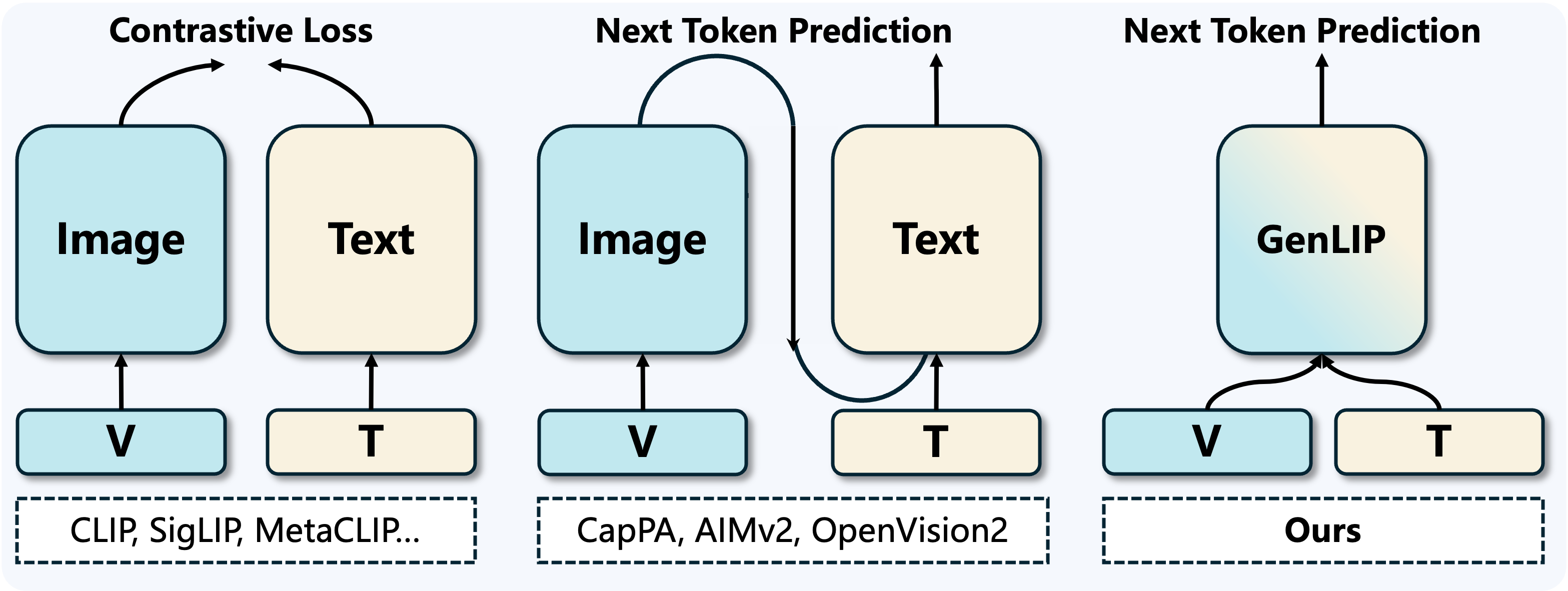
- Autoregressive language modeling objective: A training objective where the model predicts each next token conditioned on previous tokens. "These methods typically couple a vision encoder with a text decoder and train the resulting model with an autoregressive language modeling objective."
- Bidirectional attention: An attention pattern that allows tokens to attend to both past and future tokens. "image tokens attend bidirectionally and text tokens attend causally."
- Causal attention: An attention pattern that restricts each token to attend only to earlier positions to preserve autoregressive ordering. "text tokens attend causally."
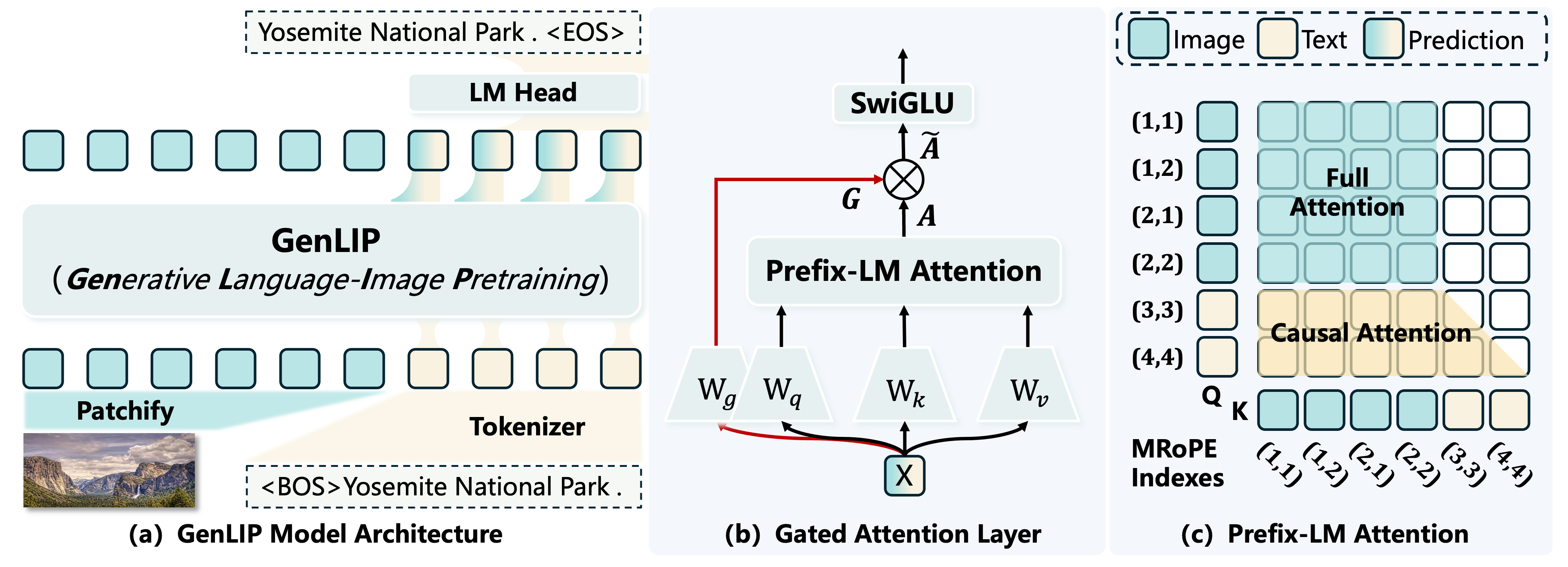
- Convolutional patch embedding: A layer that uses a convolution to partition an image into patch embeddings for transformer input. "using a convolutional patch embedding layer"
- Contrastive learning: A representation learning approach that aligns paired samples and separates unpaired ones via a contrastive objective. "These methods typically employ a dual-encoder architecture that encodes each modality separately and align them using a contrastive objective."
- Dual-encoder (two-tower) architecture: A design with separate encoders for each modality whose outputs are aligned, often via contrastive loss. "These methods typically employ a dual-encoder architecture"
- Drop path: A regularization technique that randomly drops entire residual paths during training to stabilize deep networks. "We apply two regularization techniques during GenLIP pretraining for effectively training deeper networks: layer scale and drop path."
- Flex-attention: A flexible attention implementation that supports variable sequence lengths and arbitrary masks efficiently. "we implement exact per-sample Prefix-LM attention by the flex-attention in PyTorch"
- Frozen visual representation evaluation: An evaluation protocol where the vision encoder is kept fixed while the LLM is fine-tuned. "we mainly adopt frozen visual representation evaluation, where the vision encoder is kept frozen and the LLM is fine-tuned on downstream tasks."
- Gated attention: An attention mechanism that modulates attention outputs with learned gates to control information flow. "we introduce a gated attention mechanism to regulate information flow in the mixed-modality modeling space."
- InfoNCE: A contrastive loss that maximizes similarity of positive pairs relative to negatives within a batch. "using an InfoNCE or similar contrastive objective."
- Instruction tuning: Fine-tuning a model on instruction–response pairs to improve following of natural-language instructions. "and then fine-tune the LLM on an instruction tuning dataset."
- Layer Normalization (LN): A normalization technique applied across features of each token to stabilize and accelerate training. "a Layer Normalization (LN) layer"
- Layer scale: A stabilization technique scaling residual branches by small learnable factors to ease optimization in deep networks. "We apply two regularization techniques during GenLIP pretraining for effectively training deeper networks: layer scale and drop path."
- Language modeling (LM) head: The output layer that maps hidden states to token logits for next-token prediction. "and finally a language modeling (LM) head for token prediction."
- Multimodal LLMs (MLLMs): LLMs augmented to process and reason over multiple modalities such as vision and text. "Multimodal LLMs (MLLMs) have emerged as a transformative paradigm in artificial intelligence,"
- Multimodal Rotary Position Encoding (MRoPE): A rotary position encoding adapted to multimodal sequences to inject positional information into attention. "we use multimodal rotary position encoding (MRoPE)~\cite{wang2024qwen2vl} and discard the absolute position embeddings for image patches."
- Native aspect ratios: Preserving the original width-to-height ratio of images during processing, rather than forcing a fixed shape. "(iii) images are processed at their native aspect ratios."
- Negative log-likelihood: A loss function that penalizes the negative log probability of the observed sequence under the model. "The objective is to minimize the negative log-likelihood of the text sequence:"
- Optical Character Recognition (OCR): The task of detecting and transcribing text in images. "with particularly strong performance on optical character recognition (OCR) tasks."
- Packing strategy: A batching technique that concatenates variable-length samples into long sequences to maximize hardware utilization. "We use the packing strategy to pack samples of variable lengths into long sequences with max length ."
- Prefix-LM attention: An attention scheme where a prefix segment (e.g., image tokens) is fully visible while subsequent tokens attend causally. "we replace the basic full attention with prefix-LM attention~\cite{raffel2020exploring} in all transformer blocks, where image tokens attend bidirectionally and text tokens attend causally."
- Projector (MLP projector): A small neural network that maps vision features into the LLM’s input space. "feed them into a 2-layer MLP projector"
- Shared embedding space: A common vector space where representations from different modalities are aligned for comparison. "within a shared embedding space"
- Subword tokens: Tokens produced by subword segmentation algorithms that split words into smaller units for tokenization. "tokenized into a sequence of subword tokens"
- Vision-Language Pre-training (VLP): Pretraining on large image–text corpora to learn multimodal representations. "large-scale Vision-Language Pre-training (VLP) on billions of image-text corpora have become the dominant approach for developing strong vision encoders."
- Vision Transformer (ViT): A transformer-based architecture that processes images as sequences of patch tokens. "let the Vision Transformer (ViT) speak directly--requiring no contrastive batch construction and no additional text module."
Collections
Sign up for free to add this paper to one or more collections.

