- The paper introduces ViGoR-Bench to measure visual generative models’ logical reasoning using dual-track process and result metrics.
- It employs a diverse dataset across physical, knowledge, and symbolic tasks to expose cognitive and logical gaps.
- Reward-driven reinforcement learning with complex data improves generalization compared to standard supervised fine-tuning.
ViGoR-Bench: Systematic Evaluation of Visual Generative Models for Zero-Shot Reasoning
Motivation and Problem Statement
Visual generative models have advanced dramatically in photorealistic synthesis, yet their logical and causal reasoning capabilities remain largely unprobed. Existing benchmarks predominantly focus on visual fidelity and semantic alignment, overlooking the cognitive dimension required for genuine visual intelligence. Notably, evaluation protocols prioritize final outcome metrics (e.g., CLIPScore, FID), ignoring the generative process and failing to distinguish between models that understand structural constraints and those that merely replicate statistical data distributions. This deficiency manifests as a "logical desert," where even high-fidelity outputs contain physically or logically incoherent artifacts.

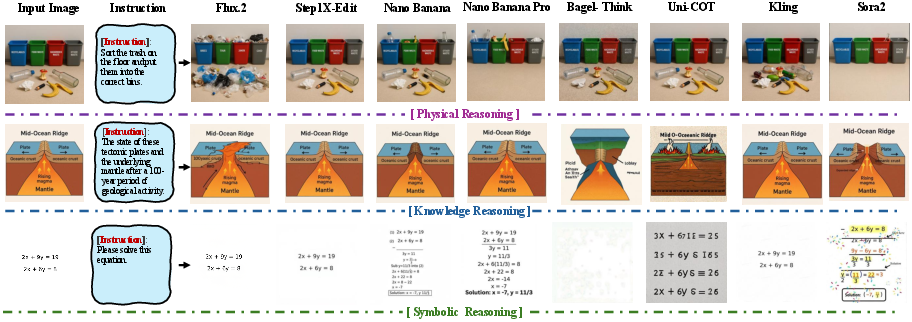
Figure 1: Overview of ViGoR-Bench; domain distribution, reasoning process examples, and performance comparison for state-of-the-art models.
Benchmark Architecture and Data Construction
ViGoR-Bench is designed as a unified evaluation suite spanning three primary reasoning domains: Physical, Knowledge, and Symbolic. The benchmark encompasses 20 distinct task categories, ranging from embodied spatial reasoning to algorithmic symbolic manipulation. Data generation follows a tripartite strategy:
- Generative Synthesis: Leveraging multimodal LLMs and high-fidelity generative image models to construct synthetic physical scenarios.
- Real-World Acquisition: Curating and manually photographing authoritative real-world data for knowledge grounding.
- Algorithmic Generation: Using procedural engines for tasks demanding mathematical rigor and unique solutions.
Each sample undergoes stringent human review for semantic consistency and, where applicable, symbolic solver validation. Ground-truth references are provided either as validated images or human-verified captions to facilitate evidence-grounded evaluation.
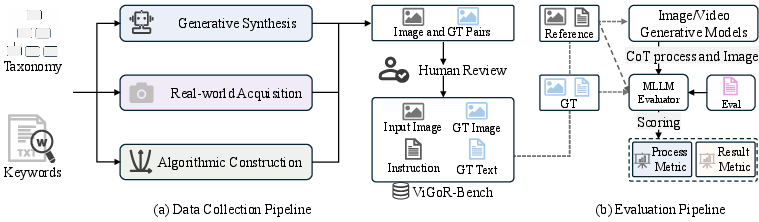
Figure 2: Dataset construction and dual-track evaluation pipelines, with MLLM used for process and result assessment.
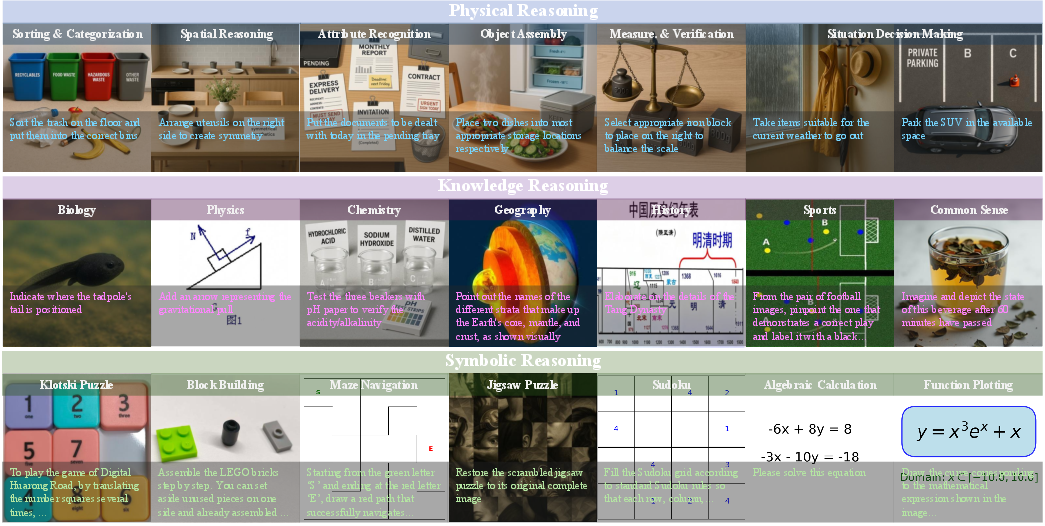
Figure 3: Task suite overview; hierarchical organization of representative tasks across Physical, Knowledge, and Symbolic Reasoning.
Dual-Track Evaluation Protocol
To address the ambiguity between procedural reasoning and final output validity, ViGoR-Bench establishes two orthogonal metric tracks:
- Process Metrics: Quantitative assessment of intermediate states, focusing on background consistency, instruction compliance, visual quality, and reasoning progression (beneficial action). Scores are real-valued (0--100), suitable for temporal and multi-step outputs.
- Result Metrics: Binary evaluation (pass/fail) of the final output over four dimensions: integrity, instruction following, realism, and task completion.
An automated judge based on Gemini-2.5-Pro achieves high MAE and Pearson correlation alignment with human expert rating, especially when ground-truth references are provided. The reliability analysis demonstrates the necessity of ground-truth inclusion to stabilize LLM-based evaluation.
Comprehensive experiments are performed on proprietary and open-source models, categorizing them as image editing, unified (with/without CoT), and video generation. Notable findings include:
Diagnostic Granularity and Failure Profiling
ViGoR-Bench extends beyond leaderboards by granularly profiling reasoning failures across cognitive axes. In symbolic domains (Sudoku, Maze, Jigsaw), performance degrades monotonically with increased problem complexity, consistent with human-like error scaling only in specific tasks. For others (Sudoku), inverted-U patterns indicate data distribution bias or overfitting to canonical instance sizes.
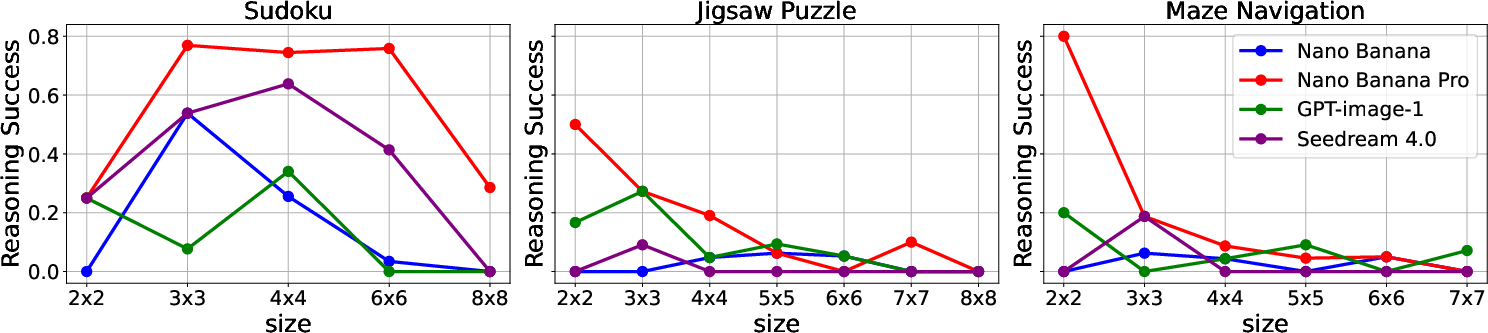
Figure 5: Impact of problem complexity on Reasoning Success for Sudoku, Jigsaw Puzzle, and Maze Navigation.
Process-level and result-level metrics are plotted for symbolic, physical, and knowledge tasks; diagnostic radar charts (Figures 10, 11, 12) reveal significant gaps in rule compliance and reasoning reliability, especially for multi-step combinatorial and embodied reasoning.
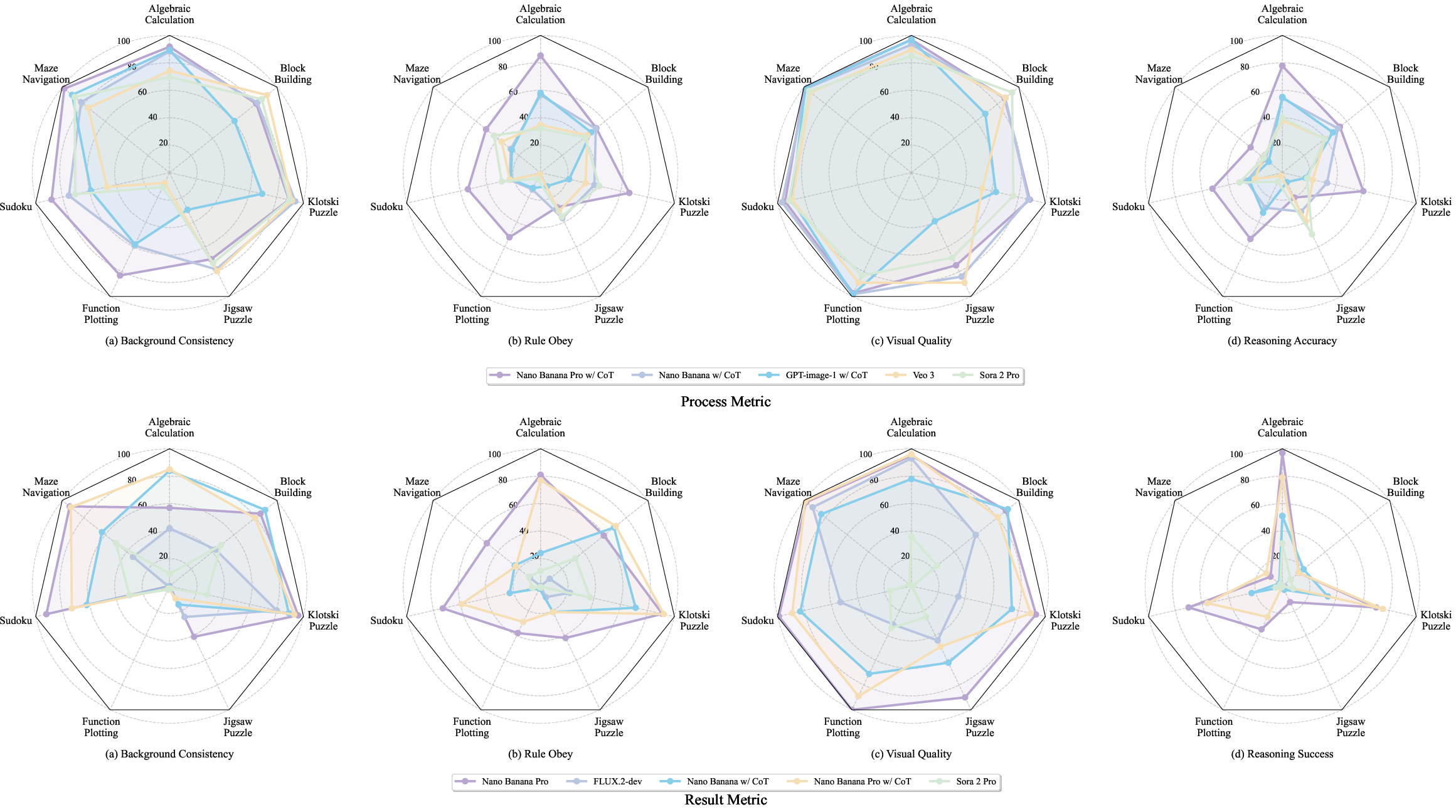
Figure 6: Symbolic reasoning profiling; pronounced gaps in reasoning accuracy and rule obey metrics for puzzle-oriented tasks.
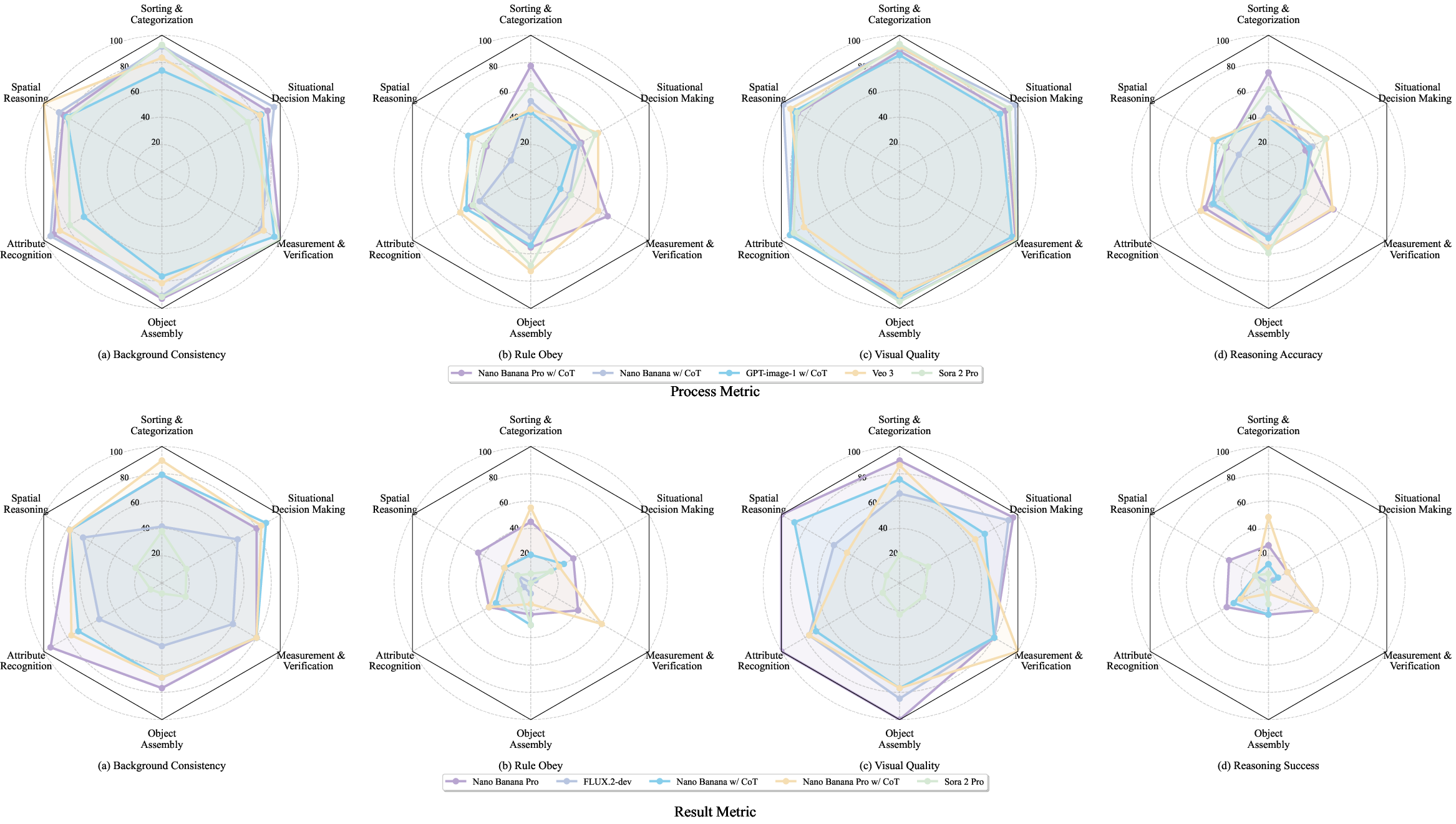
Figure 7: Physical reasoning profiling; strong visual quality but weak rule adherence and reasoning accuracy, especially in object assembly and verification.
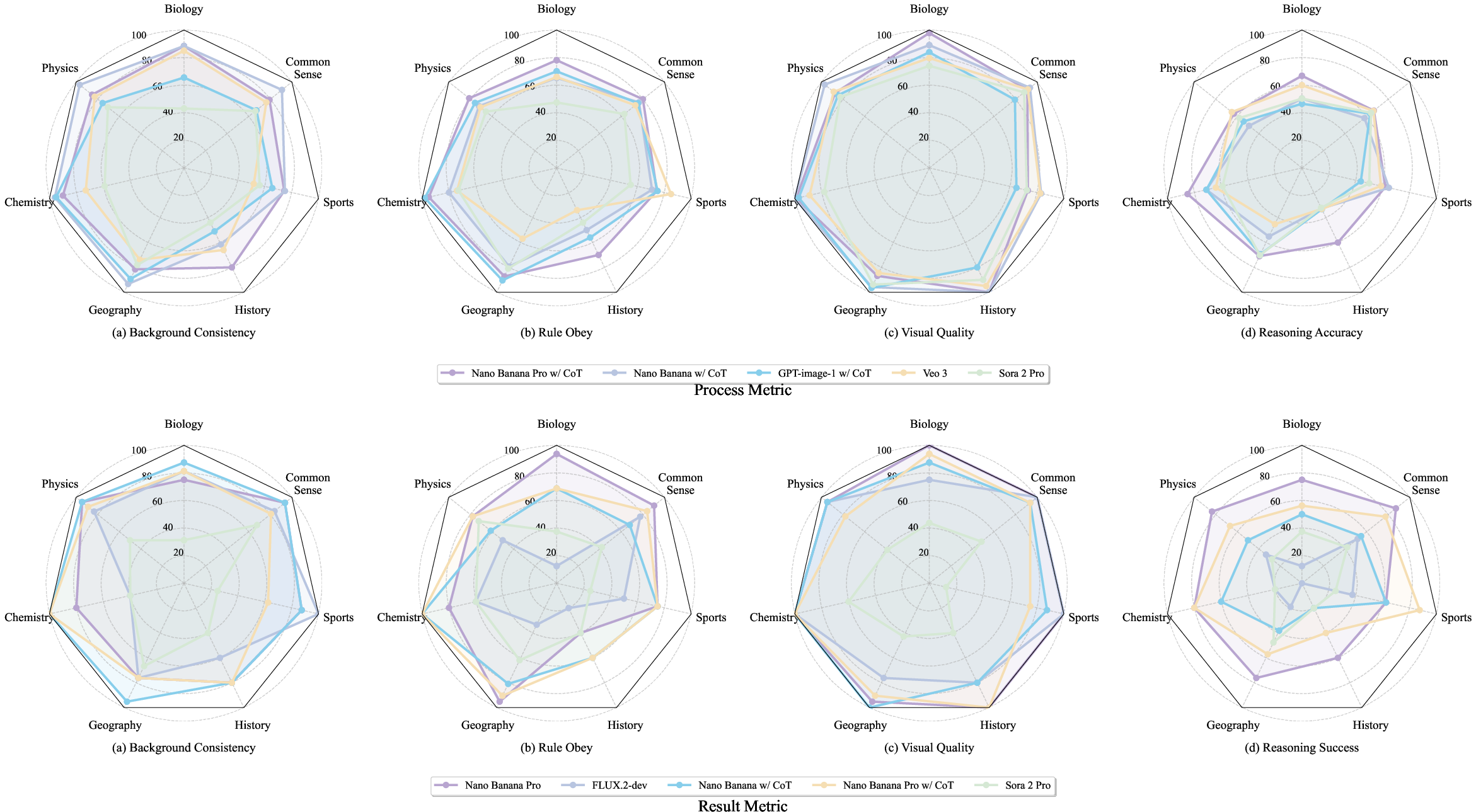
Figure 8: Knowledge reasoning profiling; factual grounding and causal reasoning remain limiting bottlenecks.
Post-Training Interventions and Generalization
ViGoR-Bench is also leveraged for model improvement via reward-driven RL. Supervised fine-tuning (SFT) induces saturation in validation metrics, whereas RL (GRPO) unlocks further gains, especially on high-complexity OOD tasks. Training on harder instances (e.g., 8×8 mazes) fosters robust logic transfer to easier in-distribution cases, suggesting that complex reasoning data is essential for generalization.
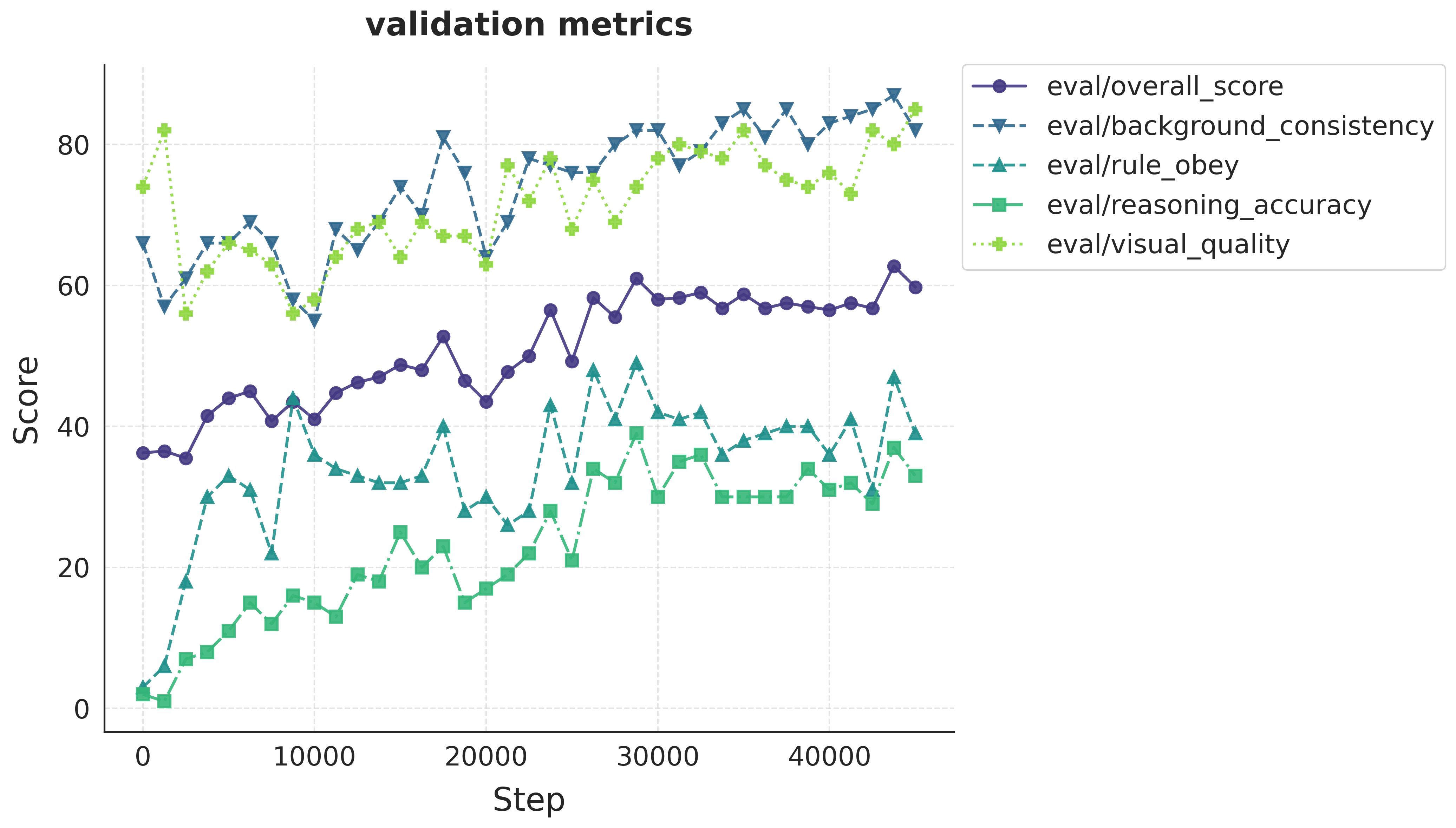
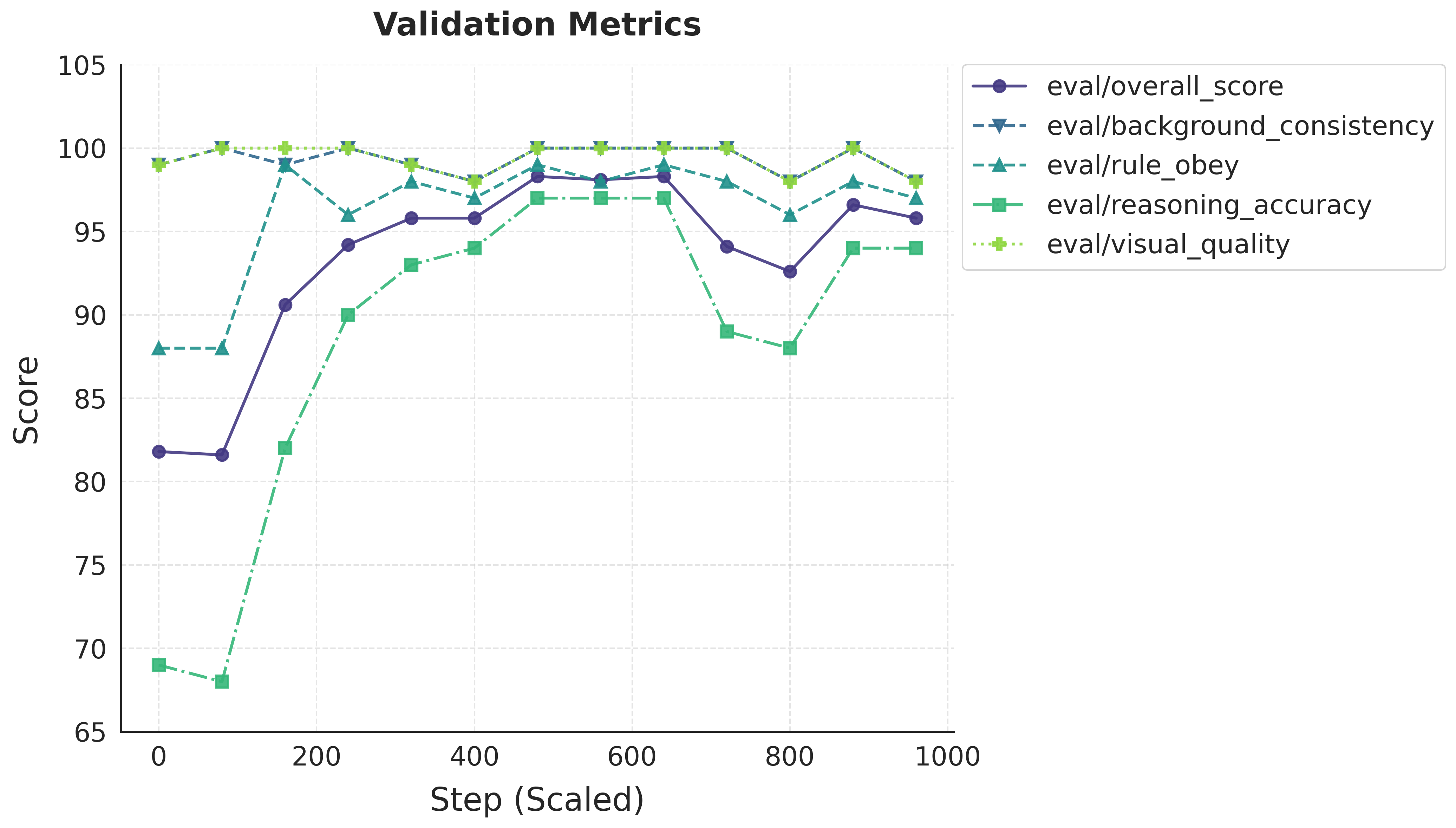
Figure 9: RL fine-tuning performance; RL elevates reasoning metrics above SFT, demonstrating regime unlocking.
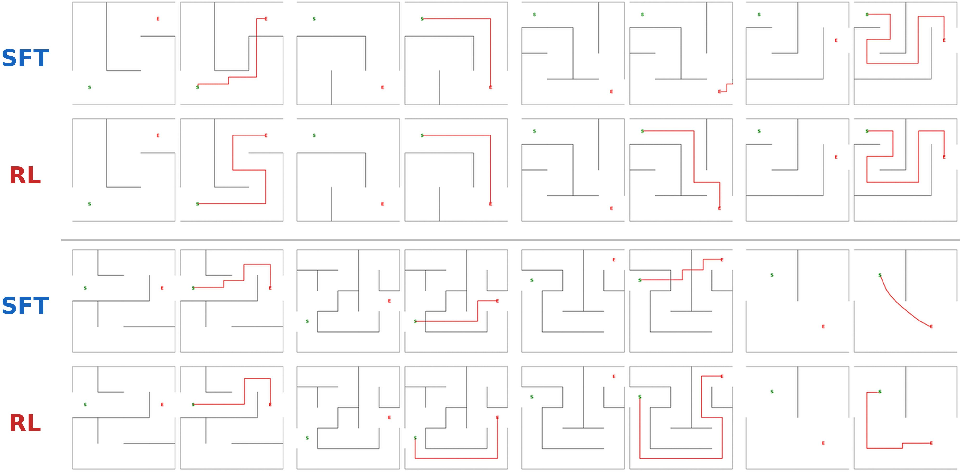
Figure 10: Qualitative results on ViGoR-Bench after SFT and RL; RL models achieve higher task completion and rule compliance.
Practical and Theoretical Implications
The findings unequivocally demonstrate that visual generative models, despite architectural and scaling advances, are still deficient in physical reasoning, world-knowledge grounding, and multi-step symbolic manipulation. Perceptual quality, compositionality, and instruction following can be decoupled from genuine reasoning capacity. Dual-track evaluation reveals systematic logical gaps not captured by conventional fidelity metrics.
Practical implications include the need for richer, process-aware benchmarks and evidence-grounded automated judges to steer model development. RL-based post-training—guided by ViGoR-style stress tests—proves critical for overcoming overfitting and saturation, enabling performance gains in reasoning-centric domains.
Theoretically, the results reinforce the paradigm shift from mere visual realism toward cognitive alignment and world modeling. Future research must focus on unified architectures capable of robust symbolic and causal reasoning, scalable data curation for complex tasks, and interpretability in generation chains.
Conclusion
ViGoR-Bench provides a holistic, cross-modal benchmark to diagnose and guide visual generative model development for zero-shot reasoning. The dual-track metrics and granular analysis expose persistent deficits in reasoning capabilities, undetectable by fidelity-centric evaluation. Reward-driven learning and complex data exposure are essential for unlocking generalization. The benchmark establishes an actionable framework for elevating visual intelligence beyond photorealistic synthesis toward robust logical understanding and execution (2603.25823).