- The paper demonstrates that hybrid-domain training with entropy dynamics alignment effectively mitigates entropy collapse in few-shot RLVR.
- It shows that HEAL achieves similar or superior performance compared to full-shot methods using minimal target-domain samples across varied domains.
- The study highlights that aligning temporal entropy variations rather than simple maximization promotes robust exploration and improved reasoning in LLMs.
HEAL: Hybrid-Domain Entropy Dynamics Alignment for Few-Shot RLVR
The paper "HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment" (2604.17928) targets one of the limiting bottlenecks in Reinforcement Learning with Verifiable Reward (RLVR) for LLMs: entropy collapse under low-resource (few-shot) settings. Although RLVR with binary (verifiable) correctness rewards has dramatically improved reasoning in LLMs, it is particularly brittle when target-domain data is scarce, often resulting in sharp entropy contraction, severe overfitting, and loss of exploration capacity. This entropy collapse drastically limits generalization and reasoning performance, especially in knowledge-scarce domains such as medicine, code, and physics.
The core research question addressed is: How can entropy collapse be robustly mitigated in few-shot RLVR, and can diverse exploration be enabled with minimal target-domain supervision?
HEAL Framework: Hybrid Exploration and Cross-Domain Entropy Dynamics
The proposed HEAL (Hybrid-domain Entropy dynamics ALignment) framework introduces a rigorous approach to counteracting entropy collapse in few-shot RLVR. The design is twofold:
- Hybrid-domain Data Incorporation: Selectively injects high-value, general-domain reasoning tasks into the few-shot RLVR training batch, computed via a dual criterion of reasoning uncertainty and exploratory diversity. This enables transfer of generic reasoning patterns to under-resourced, domain-specific RLVR, while avoiding training instabilities or computational overhead from naively mixing massive off-domain corpora.
- Entropy Dynamics Alignment (EDA) Reward: Imposes inter-domain alignment of the trajectory-level entropy dynamics between general and target domains. Instead of unconstrained entropy maximization (which can induce incoherence or instability), EDA quantitatively matches both entropy magnitude and its fine-grained temporal variation via a reward signal, favoring trajectories in the target domain whose entropy evolution is most similar to those in the general domain.
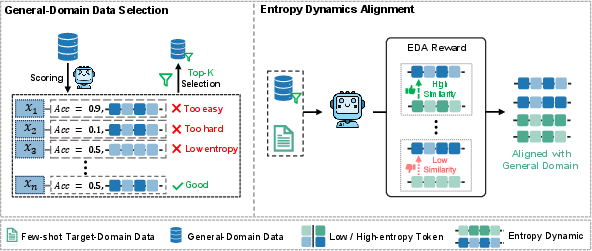
Figure 1: HEAL integrates selected general-domain data and introduces an entropy dynamics alignment reward, facilitating controlled increases in entropy and more diverse exploration in the target domain.
Empirical Investigation and Key Results
Comprehensive experiments are performed across models (Qwen3 and LLaMA-3.2 families) and domains (medicine, physics, code, and math), with extensive baselines (full-shot RLVR, naive hybrid training, alternate entropy regularization, general-domain only, etc.).
Main findings:
- Mitigation of Entropy Collapse: In low-resource settings, vanilla RLVR policies quickly contract their entropy, overfit to a handful of high-probability sequences, and fail to explore. Augmenting with HEAL, the average token-level entropy is restored to the magnitude obtained by full-shot RLVR, without overgenerating noise:
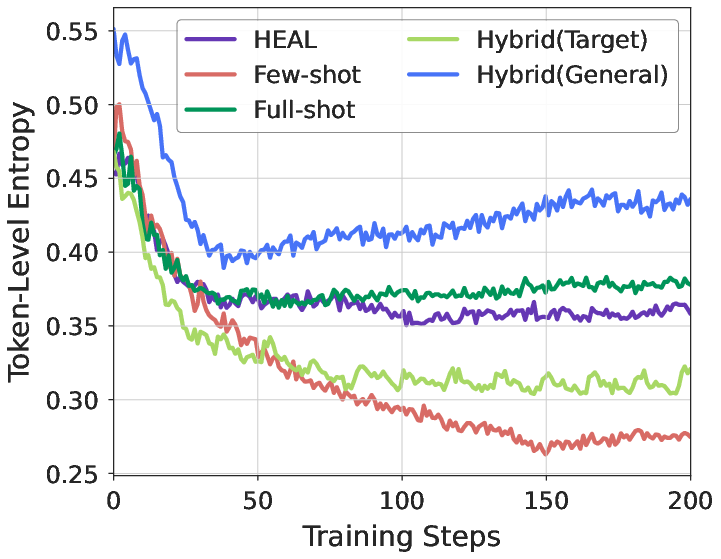
Figure 2: Few-shot RLVR rapidly collapses entropy; HEAL raises entropy to match full-shot training, permitting robust and controlled exploration.
- Performance Gains with Minimal Data: On several domains, HEAL with only 32 supervised target-domain samples matches or surpasses full-shot RLVR performance trained with 1,000 samples, particularly in code and physics domains. This effect is consistent across model scales, suggesting general applicability.
- Superiority over Classical Entropy Regularization: Standard entropy regularization (e.g., added entropy loss, high-entropy token selection, KL penalties) either fails to prevent collapse under severe data scarcity, or induces entropy explosions and incoherence. Only HEAL's EDA, with its cross-domain temporal alignment, consistently stabilizes entropy and improves accuracy:
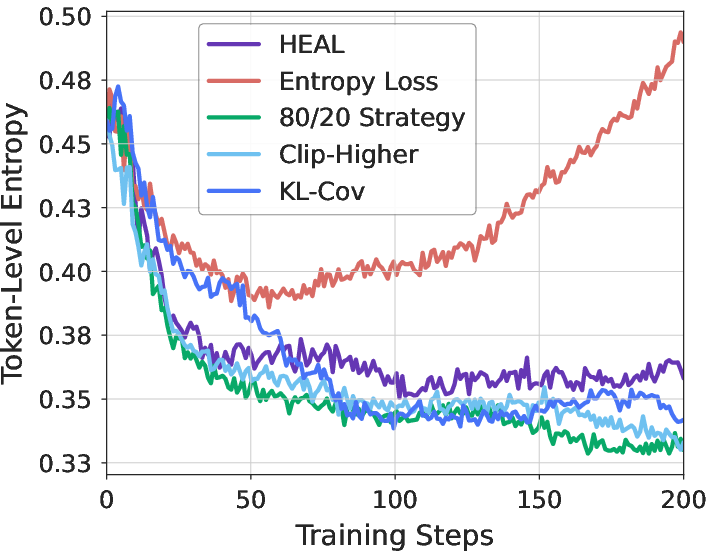
Figure 3: Entropy regularization methods exhibit limitations in low-resource RLVR, whereas HEAL achieves controlled, stable entropy and superior performance.
- Exploration Diversity: Visualization of pairwise distances in entropy dynamics (ED) space reveals that vanilla few-shot RLVR converges to homogeneous, trivial exploration strategies, whereas HEAL substantially increases diversity of entropy trajectories, indicating robust acquisition of novel reasoning paths:
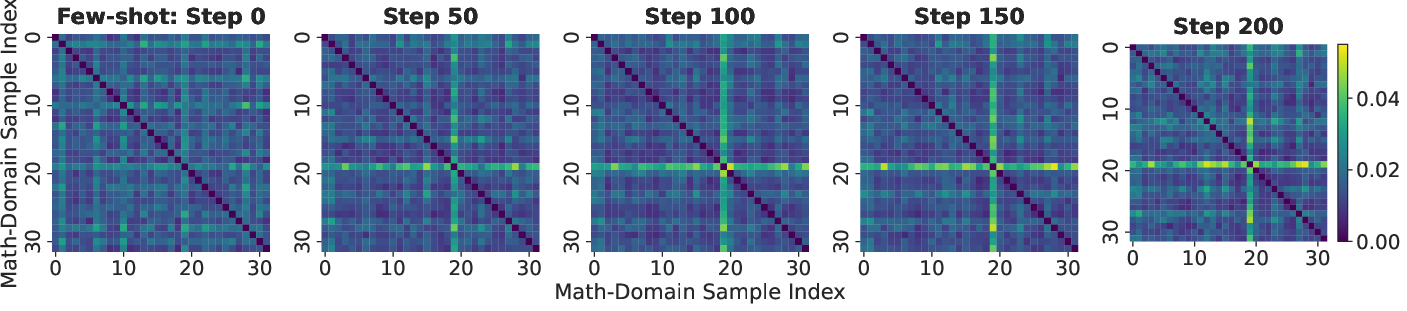
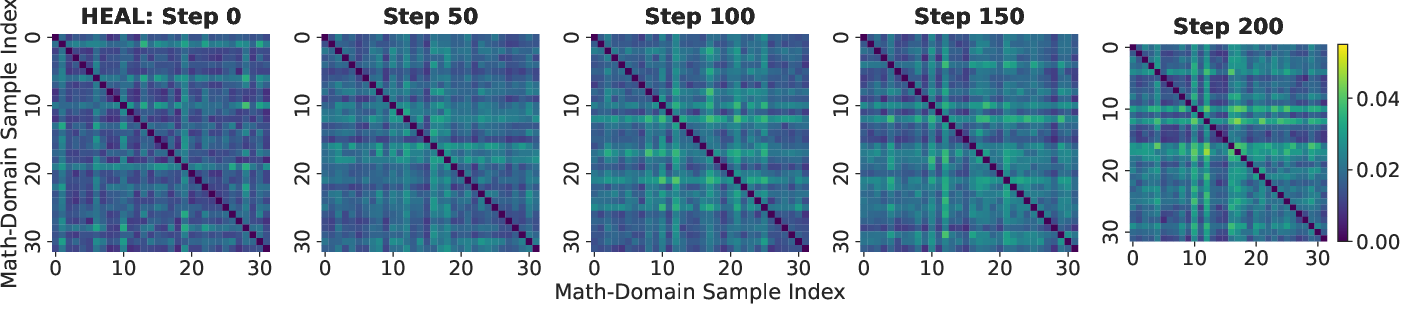
Figure 4: Heatmaps of pairwise ED distances reveal that HEAL expands the diversity of reasoning strategies throughout training, whereas few-shot RLVR remains homogeneous.
Theoretical and Practical Implications
The findings in this work have both direct practical and theoretical implications:
- Data-Efficient RLVR: HEAL establishes that strong performance on challenging reasoning benchmarks does not require massive domain-specific reward annotations when cross-domain trajectory dynamics can be effectively aligned.
- Advancement Beyond Entropy Maximization: The evidence demonstrates that the efficacy of exploration is not a simple function of high entropy per se, but rather of matched temporal entropy variation patterns. This aligns with recent perspectives on the importance of dynamic (rather than static) exploration in policy optimization.
- Foundation for Cross-Domain Transfer: The combination of careful general-domain data selection and temporal alignment in entropy space provides a template that could be extended to other modes of RL fine-tuning, curriculum learning, and adaptive reward shaping in LLMs.
Future Directions
Several future research avenues are suggested by these results:
- Scaling to Larger Models and Tasks: Validation of HEAL on even larger model scales, across additional domains with disparate reasoning requirements, and in the context of multi-round or interactive tasks.
- Fine-Grained Reward Shaping: Generalizing EDA to support richer notions of trajectory similarity, multi-agent reasoning, and more nuanced forms of temporal behavior modeling.
- Automatic Domain Selection: Integration with meta-learning or automated source domain selection to further decrease the reliance on manual curation of high-value general-domain data.
- Application to Safety and Robustness: Exploiting controlled exploration for safer RLVR training, avoiding reward hacking, and improving calibration under distribution shift.
Conclusion
The paper rigorously demonstrates that entropy collapse is a critical obstacle for RLVR in low-resource domains, and that its mitigation requires more than simple entropy regularization. By leveraging hybrid-domain training and, crucially, entropy dynamics alignment between domains, HEAL enables few-shot RLVR to achieve or surpass the performance of full-shot training, robustly expanding exploration diversity and reasoning generalization in LLMs. The implications are significant for scalable, data-efficient RL-based LLM optimization.