- The paper demonstrates that high-entropy tokens, quantified via conditional mutual information, are crucial for effective credit assignment in reasoning tasks.
- The paper introduces a four quadrant decomposition based on reward polarity and entropy to isolate and optimize causal token updates in LLM training.
- The experiments reveal that Entropy-Aware Policy Optimization (EAPO) significantly boosts accuracy and efficiency on math reasoning benchmarks compared to traditional methods.
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Introduction and Problem Setting
This work addresses foundational challenges in token-level credit assignment under Reinforcement Learning with Verifiable Rewards (RLVR) for LLMs, which is critical for advancing long-horizon mathematical and reasoning tasks. RLVR protocols, including the Group Relative Policy Optimization (GRPO), achieve strong generalization but suffer from allocating uniform reward signals to all tokens—this is fundamentally misaligned with the true causality of reasoning success, since only a subset of “decision-critical" tokens drive the final outcome. The central question is: Where does useful credit actually reside, and how should RLVR assign it for maximal reasoning gains?
The analysis formalizes token-level credit using Conditional Mutual Information (CMI): the information that a token’s choice carries about the final reward, conditioned on history. It is proven that the CMI for any token is upper-bounded by the token’s entropy, quantifying the model’s uncertainty at that sampling step. Thus, high-entropy tokens—where the model faces genuine alternatives—are the only positions with non-trivial capacity to carry outcome-relevant credit. Importantly, this provable bound implies that updates to low-entropy, routine tokens are information-theoretically ineffective in improving future reasoning (Figure 1).
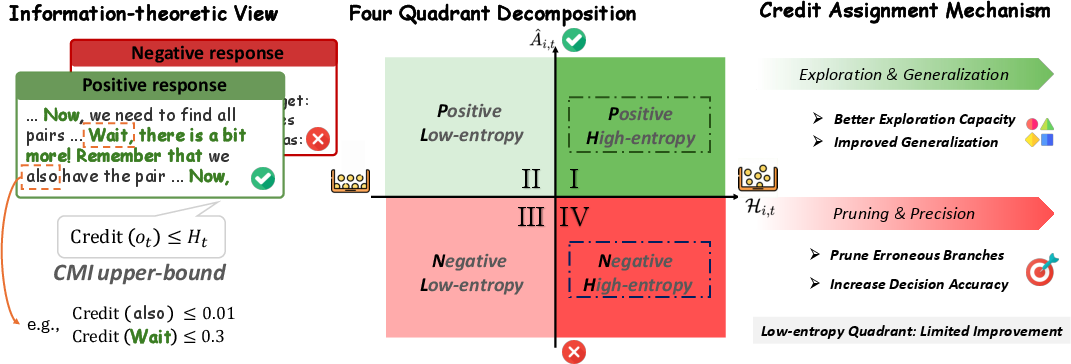
Figure 1: Tokens with high entropy (in bold) demarcate authentic reasoning forks, and the four-quadrant decomposition isolates update effects by reward polarity and entropy.
Four Quadrant Decomposition: Reward Polarity Meets Entropy
Building on both theoretical results and empirical confusion, the paper introduces the Four Quadrant Decomposition: token updates are categorized along two axes—reward polarity (positive/negative) and relative entropy (high/low). The four quadrants (PHR, PLR, NHR, NLR) correspond to positive/negative samples stratified by above/below mean group entropy. By restricting training updates to tokens in each quadrant, the authors rigorously isolate and quantify each category's causal effect on model behavior.
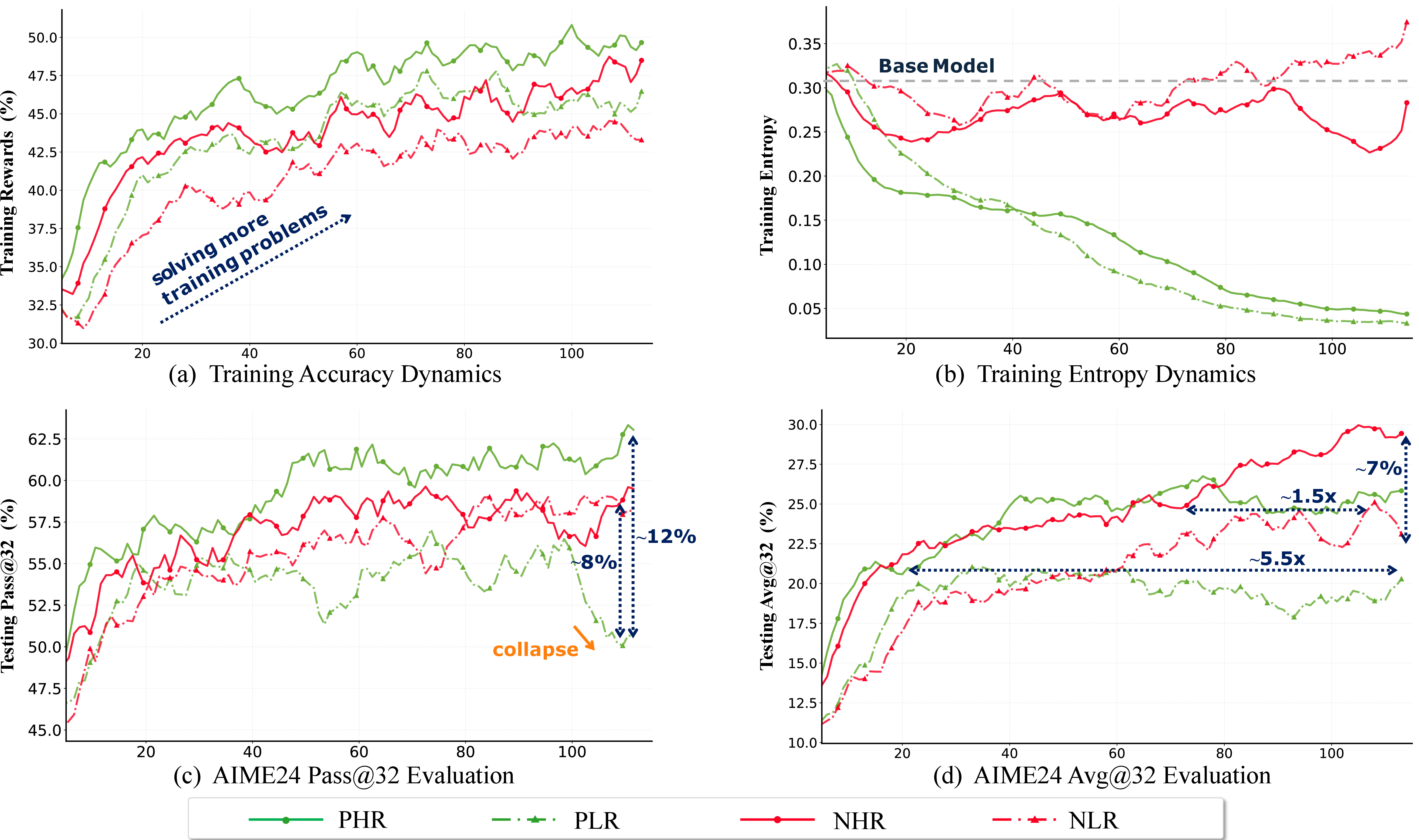
Figure 2: Four-quadrant decomposition of training dynamics, showing distinct trajectories for solve rate, entropy, Avg@32, and Pass@32 on AIME24.
Experimental results confirm three sharp predictions:
- Updates to low-entropy tokens (PLR/NLR) yield only modest, often transient optimization, with rapid entropy collapse and stunted generalization.
- High-entropy positive updates (PHR) drive sustained accuracy and diversity, catalyzing exploration and successful branch consolidation.
- High-entropy negative updates (NHR) are the most effective negative feedback, sharply pruning failing branches without destabilizing core knowledge.
Gradient-Level Mechanistic Analysis
A full derivation of token-level GRPO gradients shows that the effective update magnitude is naturally modulated by 1−πot, the model’s uncertainty about the sampled token. This amplifies gradients in high-entropy positions and suppresses them for deterministically chosen tokens—a consequence aligning directly with the CMI credit bound. However, GRPO’s uniform reward broadcasts, unconstrained by entropy, can over-credit non-informative positions, leading to misallocation and suboptimal reasoning refinement.
The Entropy-Aware Policy Optimization (EAPO) Algorithm
Leveraging the above insights, Entropy-Aware Policy Optimization (EAPO) is proposed: at each token, the advantage is modulated by a normalized, clipped token-entropy signal, further differentiated by reward polarity. In effect, EAPO up-weights high-entropy tokens on both positive and negative trajectories and down-weights routine, low-entropy segments, unlike binary masking or purely multiplicative shaping.
Experimental Results: Reasoning, Diversity, and Efficiency
Across two model families (Qwen2.5-Math-7B and DeepScaleR-1.5B-8k) and six math reasoning benchmarks, EAPO yields consistent and pronounced improvements in both exploitation (Avg@k) and exploration (Pass@k) metrics. For AIME24, EAPO boosts Avg@32 from 35.7 (DAPO) and 36.8 (EntroAdv) up to 39.8. On DeepScaleR-1.5B-8k, aggregate scores also increase, evidencing strong gains on challenging long-horizon tasks.
EAPO also achieves a better efficiency/performance Pareto frontier, requiring fewer tokens per correct solution compared with aggressive exploration-oriented baselines.
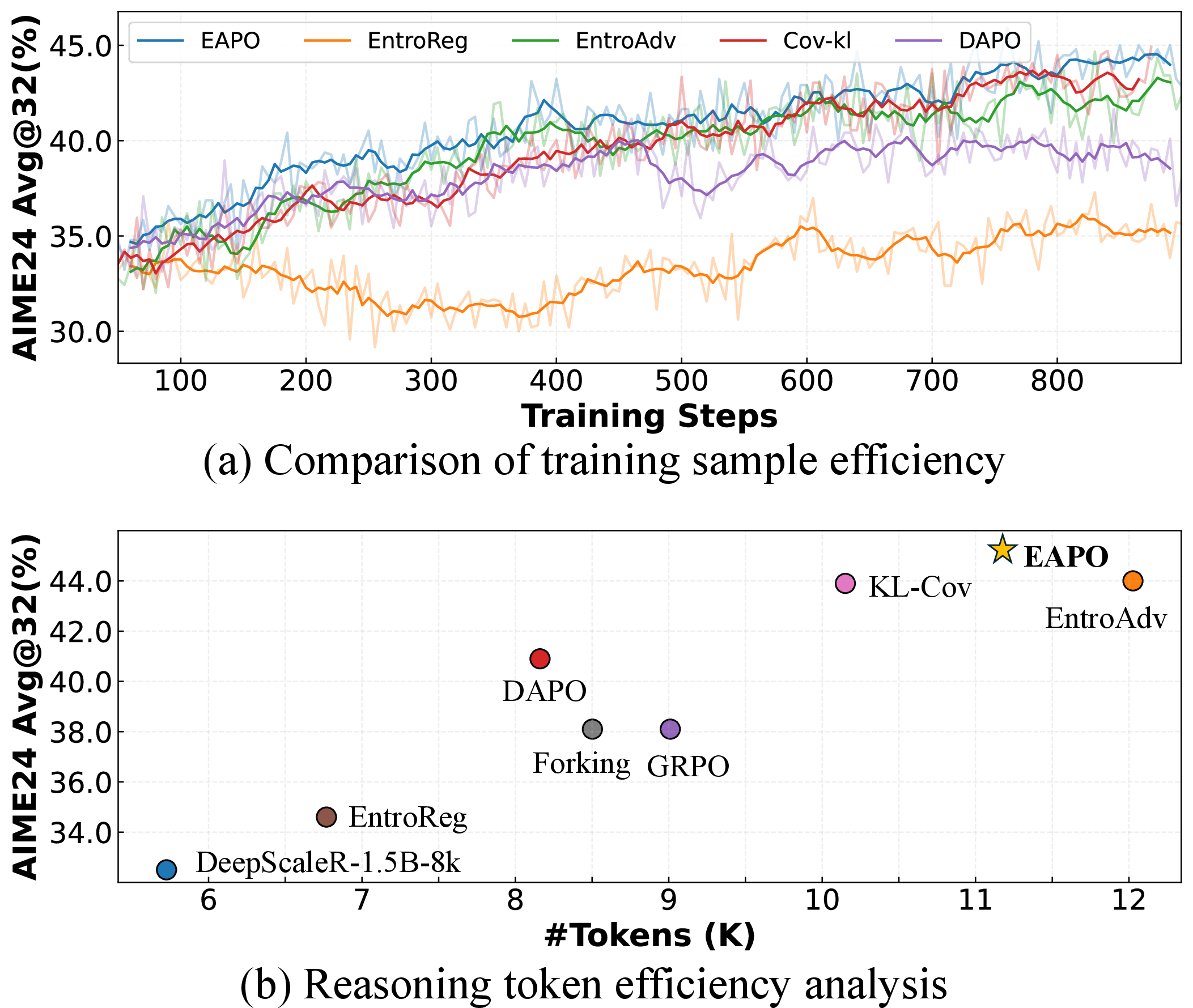
Figure 3: The performance–efficiency trade-off for EAPO relative to other methods, showing improved accuracy with lower token generation cost.
Empirical and Analytical Support
Ablation studies confirm that masking entropy-aware scaling for high-entropy quadrants sharply degrades performance, while low-entropy masking has little or even positive effect. Token entropy distributions, visualized over positive and negative samples, corroborate that reward-relevant signal diverges only in the high-entropy tail (Figure 4).
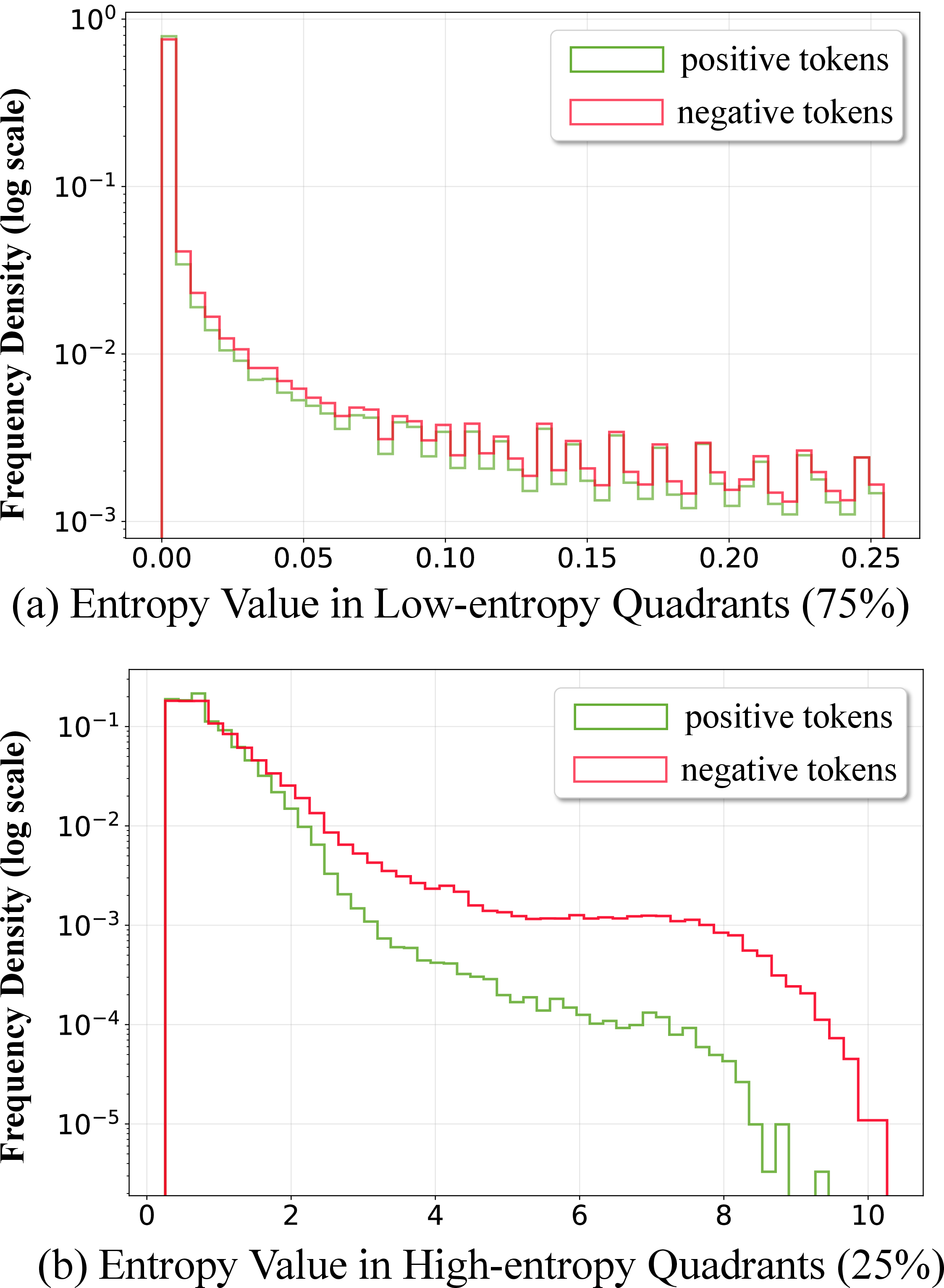
Figure 4: High-entropy token distribution diverges between correct (positive) and incorrect (negative) samples, validating information-theoretic predictions.
In-depth entropy dynamics analysis shows that EAPO preserves stable, healthy entropy levels needed for exploration throughout training, in contrast to rapid entropy collapse in conventional GRPO configurations (Figure 5).
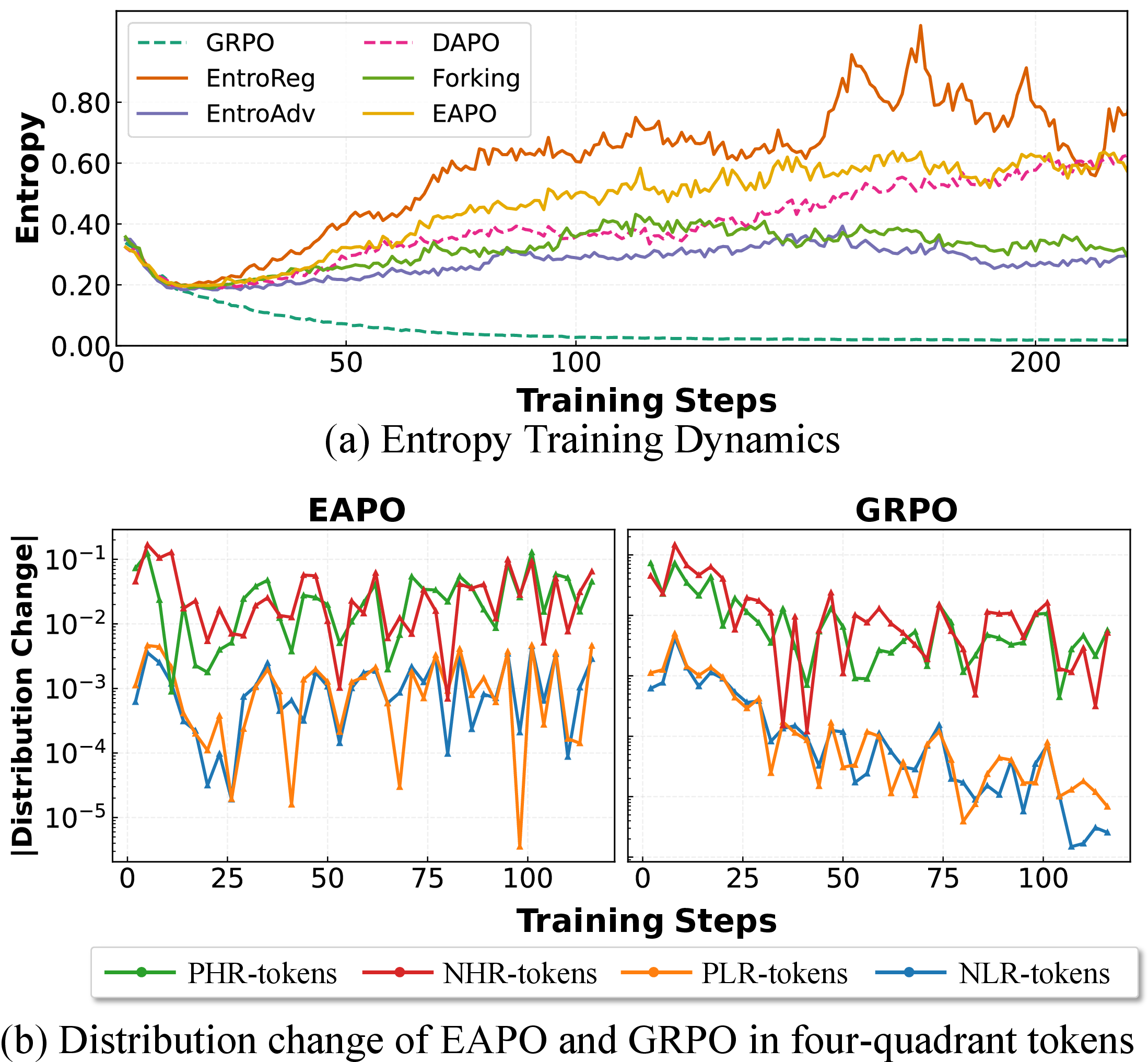
Figure 5: EAPO maintains stable token entropy throughout training, preventing collapse and supporting ongoing exploration.
Implications and Future Directions
This polarity-entropy analysis reconciles conflicting perspectives in prior RLVR work regarding the primacy of negative reinforcement and the importance of uncertainty modulation. By grounding token-level credit assignment in an information-theoretic framework, the paper provides a diagnostic and prescriptive foundation for outcome-based RL on LLMs. Practically, entropy-aware credit shaping constitutes an immediately usable tool for large-scale RLVR, guiding optimization toward true reasoning-critical forks rather than superficial sequence features.
Potential avenues include:
- Scaling EAPO to larger LLMs and more diverse tasks (e.g., open-ended generation with noisy or subjective rewards);
- Integrating entropy-aware methods with fine-grained, process-based reward models;
- Extending the four-quadrant analysis to hierarchical or compositional reasoning graphs, where causal bottlenecks span multiple abstraction levels;
- Formalizing the trade-offs between bias (focusing on high-entropy) and variance (preserving robust knowledge via low-entropy) in other RLHF and RLVR regimes.
Conclusion
The analysis and methodical studies in this work demonstrate that effective reasoning improvement in RLVR is best achieved by allocating token-level credit in proportion to information-theoretic uncertainty and reward polarity. EAPO operationalizes these principles via continuous, polarity-aware entropy shaping, yielding robust gains across exploitation, exploration, and efficiency axes. This polarity-entropy framework constitutes a principled approach to addressing the long-standing credit assignment bottleneck in LLM reinforcement learning for complex, multi-step reasoning tasks (2604.11056).