- The paper demonstrates that clipping bias reduces policy entropy and, paradoxically, enhances RLVR performance through spurious rewards.
- Empirical evaluations across various models reveal that deterministic rollouts induced by entropy minimization contribute to training stability and increased accuracy.
- The study highlights that reward misalignment, despite introducing noise, can beneficially balance exploration and exploitation in reinforcement learning.
Exploration v.s. Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
Introduction
The paper "Exploration v.s. Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward" (2512.16912) explores the nuances of exploration-exploitation trade-offs within the framework of reinforcement learning with verifiable rewards (RLVR). The authors focus on the dynamics of two counterintuitive mechanisms: entropy minimization, which pushes models towards more deterministic outputs, and spurious rewards, which seem to enhance performance despite being misaligned with true rewards. This paper seeks to elucidate how policy entropy interacts with model performance and explores the potential benefits of spurious rewards beyond traditional contamination models.
Theoretical Foundations
The paper presents a thorough investigation into RLVR, drawing comparisons with classical reinforcement learning. Unlike traditional approaches, RLVR employs sparse, outcome-based rewards evaluated at the end of extended rollouts, rendering intermediate actions reward-equivalent. Here, exploration unfolds in sequence space rather than state-local bonuses. Traditional RL's reward structure is disrupted by spurious rewards that inject noise into the learning process. Theorized as clips that favor high-priority responses, these rewards paradoxically lead to performance enhancements by minimizing policy entropy.
Clipping Bias and Policy Entropy
The paper explores the role of clipping in GRPO and its impact on policy entropy. Under spurious rewards, clipping bias reduces policy entropy, thus nudging policies toward deterministic outcomes. However, by itself, entropy reduction does not guarantee performance improvement. Instead, the authors introduce a reward-misalignment model, demonstrating that spurious rewards can enhance performance even outside contaminated environments.
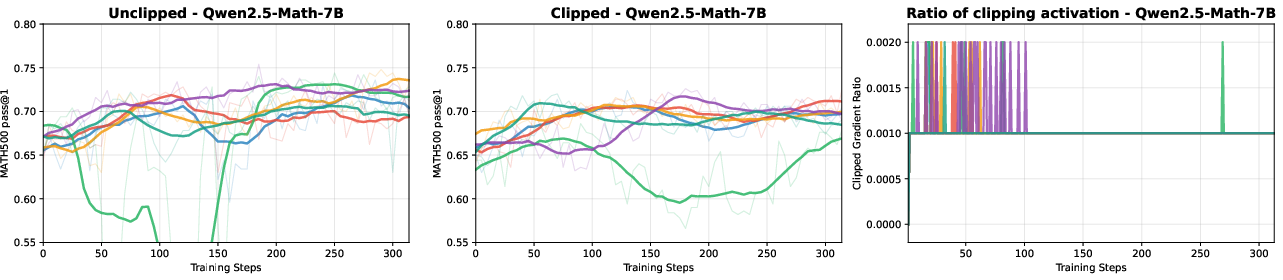
Figure 1: Independent trials over Qwen2.5-Math-7B on the MATH500 validation set, illustrating the effects of unclipped and clipped training.
To substantiate these theoretical propositions, Figure 1 shows that clipped training leads to a decrease in entropy and altered performance dynamics. The phenomenon of reduced entropy leading to more deterministic policy outputs underlines the authors' claim that clipping biases toward deterministic rollouts without directly improving performance itself.
Empirical Evaluation
Experimentation was conducted across a variety of models, including Qwen-Math, Llama, and QwQ, covering multiple sizes and variants. Findings confirmed that performance gains from spurious rewards were robust and not exclusive to specific models. The results demonstrated that despite spurious rewards being inherently noisy, they amplified prior deterministic paths, thereby leading to improved model accuracy.
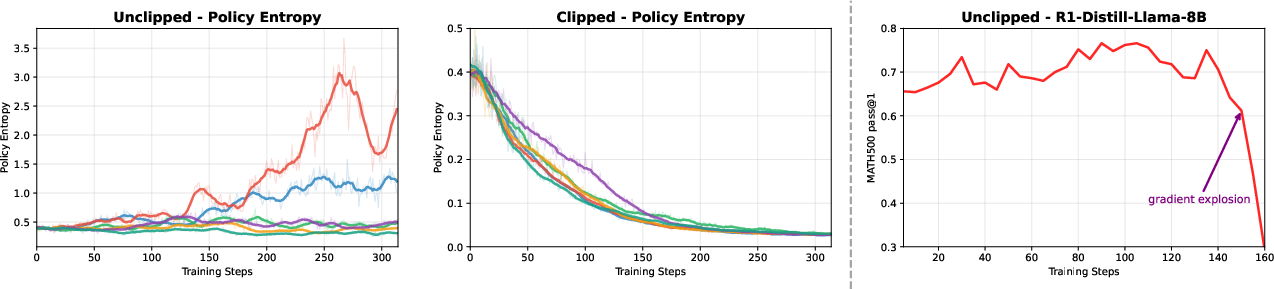
Figure 2: Policy entropy evolution of Qwen2.5-Math-7B under random-reward training, showing differential impacts of unclipped versus clipped training.
The authors also compared policy entropy evolution under different initialization conditions, as shown in Figure 2. Here, the clipped training consistently reduced policy entropy over time, further implying a stabilizing regularization effect.
Reward Misalignment and Model Dynamics
The research provides insights into how reward misalignment might inadvertently enhance model performance. By simulating various levels of contamination, the authors unpacked how spurious rewards could benefit models that were otherwise destabilized by noise. They leveraged statistical variance analysis to reveal subtle dynamics of model adaptation under misaligned reward structures.

Figure 3: Results on AIME training set across diverse models, showcasing entropy impacts in challenging environments.
As demonstrated in Figure 3, model performance responded variably to entropy and reward dynamics depending on the dataset complexity. Importantly, Qwen2.5-Math exhibited significant stabilization via clipped training, underscoring the nuanced interplay between policy regularization and dataset difficulty.
Conclusion
This paper challenges preconceived notions about exploration-exploitation trade-offs in reinforcement learning. It elucidates how factors such as clipping and spurious rewards paradoxically simplify deterministic rollouts despite apparent noise. The implications lie not merely in enhancing the understanding of RLVR dynamics but in advocating for strategic entropy modulation as a means to reconcile seemingly paradoxical learning outcomes.
Through comprehensive analysis and empirical substantiation, the findings pave the way for future explorations into hybrid reward systems that leverage the benefits of both stochastic exploration and deterministic exploitation. These insights could transform approaches to RLVR training by underscoring the beneficial roles of entropy regulation and reward misalignment.