Low-probability Tokens Sustain Exploration in Reinforcement Learning with Verifiable Reward
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has propelled LLMs in complex reasoning, yet its scalability is often hindered by a training bottleneck where performance plateaus as policy entropy collapses, signaling a loss of exploration. Previous methods typically address this by maintaining high policy entropy, yet the precise mechanisms that govern meaningful exploration have remained underexplored. Our analysis suggests that an unselective focus on entropy risks amplifying irrelevant tokens and destabilizing training. This paper investigates the exploration dynamics within RLVR and identifies a key issue: the gradual elimination of valuable low-probability exploratory tokens, which we term \textbf{\textit{reasoning sparks}}. We find that while abundant in pre-trained models, these sparks are systematically extinguished during RLVR due to over-penalization, leading to a degeneracy in exploration. To address this, we introduce Low-probability Regularization (Lp-Reg). Its core mechanism regularizes the policy towards a heuristic proxy distribution. This proxy is constructed by filtering out presumed noise tokens and re-normalizing the distribution over the remaining candidates. The result is a less-noisy proxy where the probability of \textit{reasoning sparks} is amplified, which then serves as a soft regularization target to shield these valuable tokens from elimination via KL divergence. Experiments show that Lp-Reg enables stable on-policy training for around 1,000 steps, a regime where baseline entropy-control methods collapse. This sustained exploration leads to state-of-the-art performance, achieving a $60.17\%$ average accuracy on five math benchmarks, an improvement of $2.66\%$ over prior methods. Code is available at https://github.com/CarlanLark/Lp-Reg.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to train LLMs to solve hard reasoning problems, like math questions, using reinforcement learning (RL). The key idea is called “Reinforcement Learning with Verifiable Rewards” (RLVR), where the model gets points when its answer is correct, and a program checks that automatically. The authors found a common training problem: the model stops improving because it loses the ability to explore different solution paths. They propose a new method, called Low-probability Regularization (Lp-Reg), to keep helpful “rare” word choices alive during training so the model can keep exploring and get better.
What questions does the paper ask?
- Why do LLMs trained with RLVR often hit a plateau and then collapse instead of steadily improving?
- Is the usual advice—“add more randomness” (higher entropy)—actually helping exploration or just adding noise?
- Can we protect specific low-probability word choices that spark new lines of reasoning, without boosting irrelevant words that derail thinking?
- Will this lead to better performance on math benchmarks?
How did they study it?
Key ideas explained in simple terms
- Tokens: Think of tokens as word pieces the model chooses one by one while writing its answer.
- Exploration vs. exploitation: Exploration means trying different solution paths; exploitation means sticking to one path the model already thinks is best.
- Entropy: A fancy word for “variety.” High entropy means the model is trying lots of different word choices; low entropy means it’s repeating the same choices.
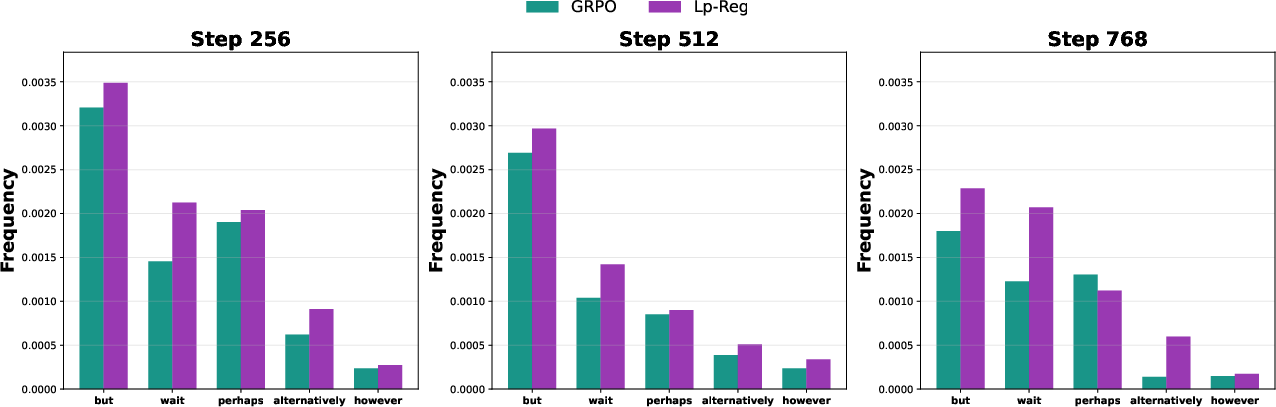
- Reasoning sparks: These are rare but helpful tokens like “wait,” “however,” or “perhaps,” which can kick off a new way of thinking about a problem.
- Noise: Rare tokens that are irrelevant or out of place (like “cost” in a math proof). Boosting these doesn’t help and can make training unstable.
RLVR in practice
The model learns by answering math problems. A checker verifies the final answer. If it’s correct, the model gets a reward. The training algorithm uses these rewards to adjust which tokens the model is more likely to choose next time.
What goes wrong in typical training
The model slowly stops exploring. Its “entropy” drops, and those rare, helpful tokens (reasoning sparks) disappear because they’re often punished when the final answer is wrong. Some methods try to fix this by just increasing entropy (adding randomness), but that can boost noise too, making things worse.
The proposed method: Lp-Reg
Lp-Reg selectively protects meaningful rare tokens without boosting noise. Here’s how it works:
- Step 1: Build a cleaner “proxy” distribution. Imagine the model’s next-token choices as a menu. Lp-Reg removes the obviously noisy items (very low-confidence tokens) and keeps the rest. This uses a smart threshold (min‑p) that adapts to how confident the model currently is.
- Step 2: Rebalance. After removing the noise, it re-spreads the probability among the remaining tokens, slightly boosting the useful rare ones.
- Step 3: Gentle guidance via KL divergence. The training adds a soft penalty if the model tries to ignore tokens that the proxy thinks are worth keeping. This “nudges” the model to not eliminate those reasoning sparks, especially when the training signal is negative (to avoid over-punishing them).
Analogy: It’s like cleaning up a messy brainstorming session. You remove obviously off-topic ideas, keep the promising ones—even if they’re unusual—and encourage the group not to dismiss these sparks too early.
What did they find?
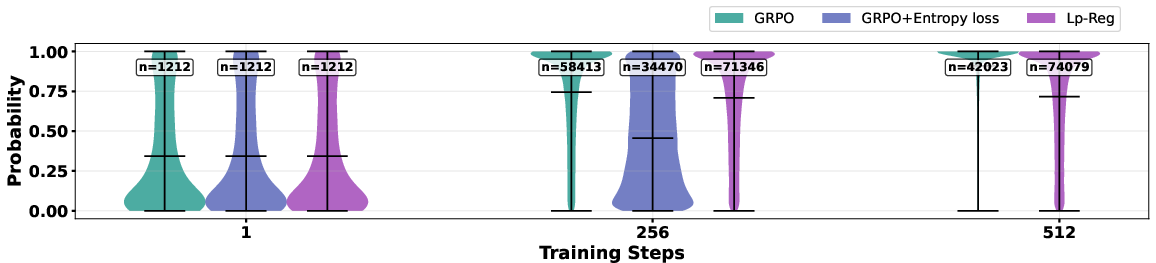
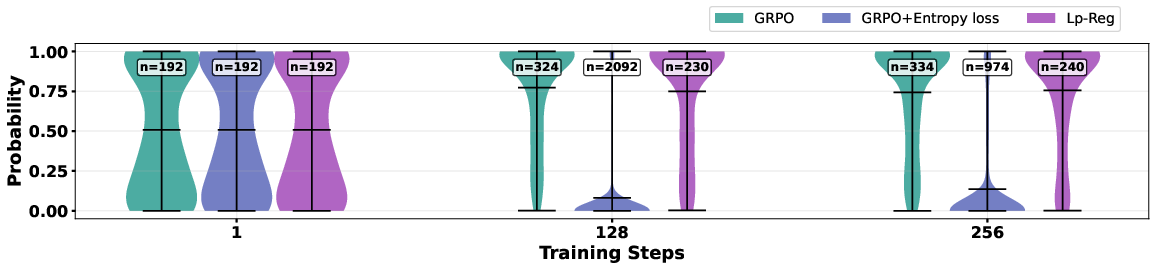
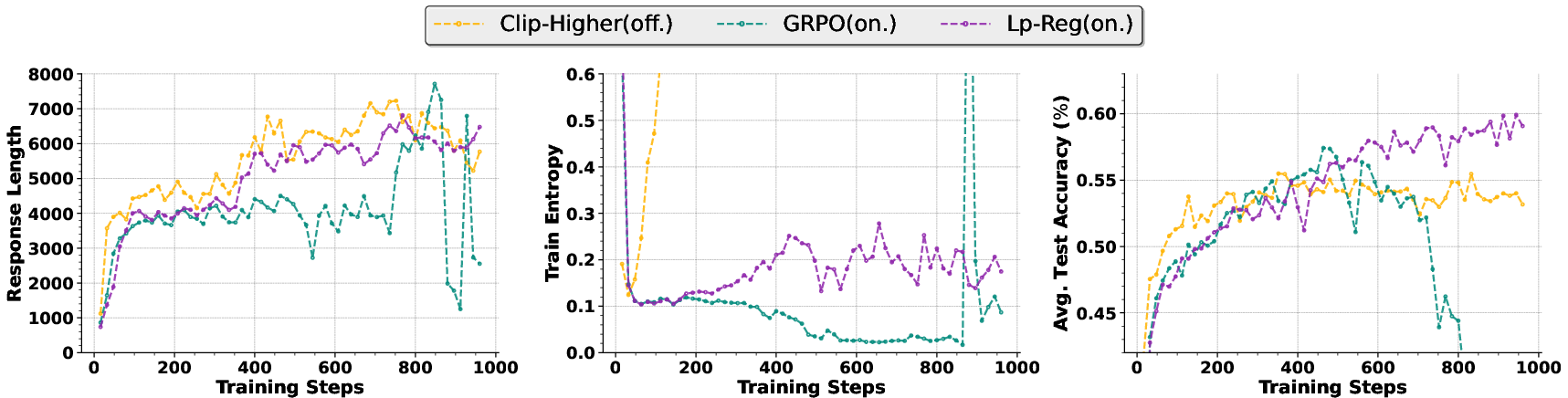
- Lp-Reg kept meaningful rare tokens (like “wait,” “however”) available during training. This sustained exploration and avoided the usual collapse.
- Methods that simply increase entropy (randomness) often amplified irrelevant tokens and made training less stable, sometimes collapsing faster.
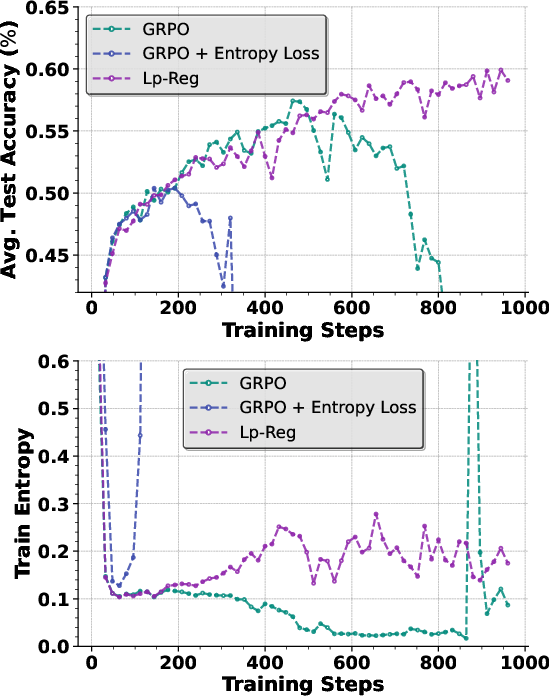
- With Lp-Reg, the model trained stably for around 1,000 steps, a regime where other methods failed.
- On five math benchmarks (AIME24, AIME25, MATH-500, OlympiadBench, Minerva), Lp-Reg achieved an average accuracy of 60.17% on the Qwen3‑14B base model, improving the best previous method by 2.66%.
- The model’s entropy showed a healthy pattern: it first drops (learning core skills), then rises (safe exploration), and finally stabilizes (balanced reasoning). This is better than forcing entropy up all the time.
Why is this important?
- It shows that exploration isn’t just about “more randomness.” It’s about protecting the right kind of rare choices—reasoning sparks—while filtering out noise.
- By keeping these sparks alive, the model can discover better solution paths and avoid getting stuck.
- The method improves accuracy on tough math tasks and makes training more reliable.
Implications and impact
- Better training: Lp-Reg offers a practical way to scale RL training for reasoning LLMs without hitting early plateaus.
- Smarter exploration: Future methods can focus on the quality of exploration—protecting meaningful low-probability tokens—rather than pushing overall randomness.
- Broader use: Although tested on math, the idea could help other complex reasoning areas (logic puzzles, code generation, scientific problems) where careful thinking matters.
- Open-source code: The authors provide code, so others can try and build on their approach.
In short, the paper’s message is simple: protect the helpful “rare words” that start new lines of thought, filter out the junk, and the model will keep exploring and learning—leading to better results.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research efforts:
- Generalization beyond math RLVR: Does Lp-Reg improve exploration and performance in non-mathematical reasoning tasks (e.g., code generation, scientific QA, theorem proving) and tasks without strict verifiers?
- Language and tokenization robustness: How does Lp-Reg perform for non-English languages and with different tokenization schemes, where “reasoning sparks” may not be captured by the same lexical markers?
- Domain transferability of “sparks”: Can a principled, domain-agnostic method discover and preserve domain-specific exploratory tokens without manual or lexical selection (beyond words like “wait,” “however”)?
- Formal characterization of sparks vs. noise: Develop an automated, measurable definition and detection strategy for “reasoning sparks” versus irrelevant noise, rather than relying on probability thresholds and hand-picked token sets.
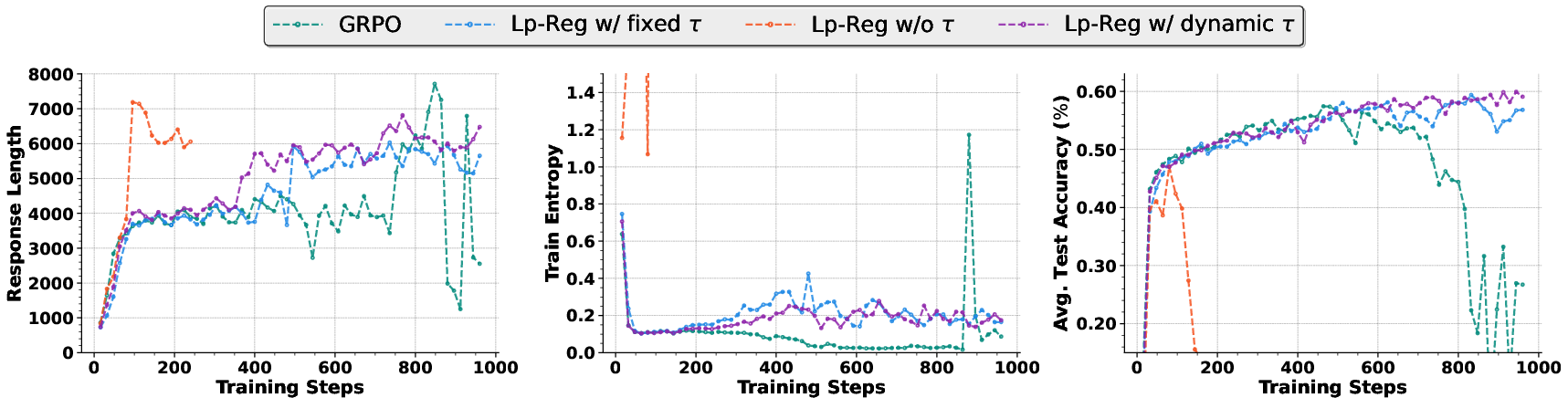
- Risk of filtering rare-but-essential tokens: Under what conditions does the τ-threshold inadvertently discard rare, context-critical tokens, and how can such cases be detected and mitigated?
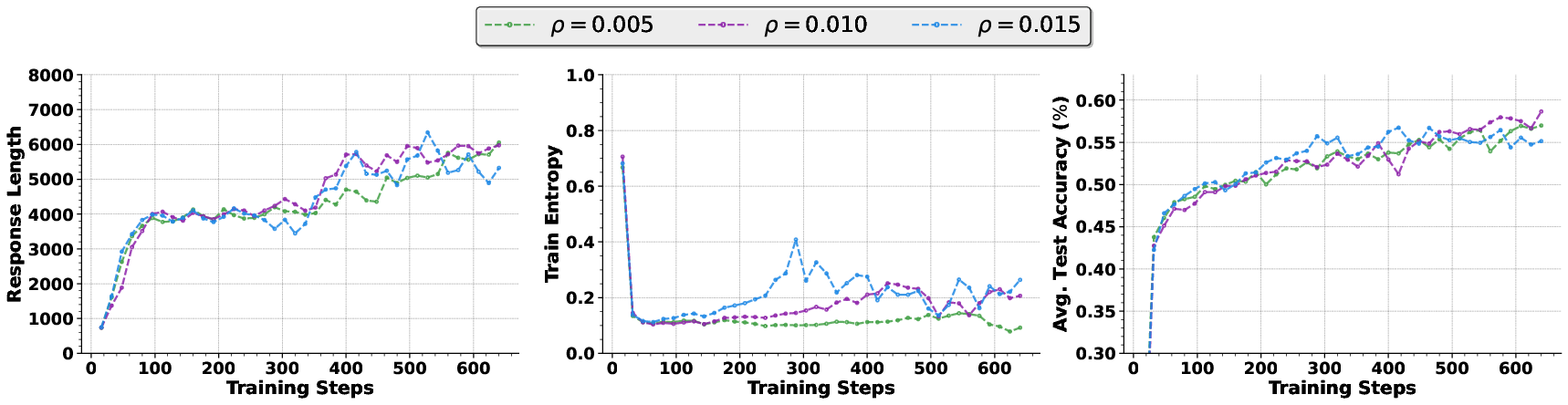
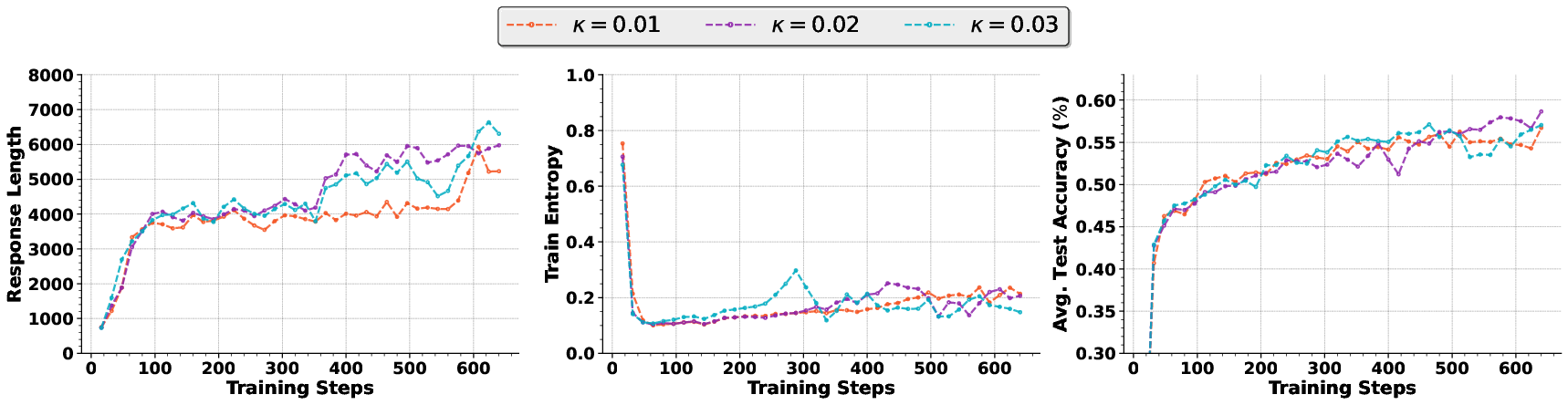
- Hyperparameter sensitivity and scheduling: Systematic analysis of sensitivity to τ, ρ (low-percentile activation), κ (min-p), β (KL weight), U (ratio cap), and batch-size; investigate adaptive/scheduled variants and robust default settings.
- Batch-dependent percentile activation: The activation condition using a batch-level percentile δρ may be unstable with smaller batches or shifting distributions; explore alternative activation criteria and their trade-offs.
- Proxy construction choices: Assess different proxy distributions (e.g., temperature adjustments, confidence reweighting, uniform redistribution, or learned proxies) and their impact on exploration quality.
- Divergence choice and direction: Compare forward KL with reverse KL, JS, Rényi, or Wasserstein divergences; analyze theoretical and empirical differences in preserving low-probability mass.
- Local (token-level) vs. structured regularization: Extend Lp-Reg from next-token probabilities to phrase-level, span-level, or plan-level structures to better capture exploratory trajectories that unfold over multiple tokens.
- Interaction with advantage estimation noise: Quantify robustness to noisy/biased advantage signals (A_{i,t}), including varying group sizes G, normalization strategies, and reward variance; evaluate alternative credit-assignment schemes.
- On-/off-policy proxy mismatch: When off-policy, the proxy is built from π_{θ_old}; analyze bias introduced by this mismatch and whether on-policy proxies (or mixed proxies) yield better stability.
- Compute and memory overhead: Measure and optimize the runtime and memory cost of per-step proxy filtering/renormalization at long sequence lengths; provide scaling analysis for larger vocabularies and longer contexts.
- Entropy measurement methodology: Standardize how policy entropy is computed (positions, masking, normalization) and report confidence intervals; verify that the “multi-phase entropy trajectory” is consistent across seeds and datasets.
- Statistical significance and reproducibility: Report multiple seeds, variance, effect sizes, and statistical tests to confirm that improvements are robust; provide more reproducible settings and ablation coverage.
- Long-horizon training behavior: The paper reports stability for ~1,000 steps; what happens beyond this horizon? Characterize long-term convergence, potential re-collapse, and steady-state behavior.
- Sequence length and verbosity effects: Does preserving exploratory tokens increase CoT verbosity or response length (especially with 8,192-token limits), and how does that impact compute, latency, and evaluation outcomes?
- Calibration and confidence dynamics: Study how Lp-Reg affects model confidence calibration (e.g., ECE) and whether confidence-aware regularization improves or harms calibration across tasks.
- Safety and alignment considerations: Investigate whether preserving low-probability tokens increases hedging or reduces hallucinations, and assess risks of amplifying undesirable content; integrate safety-aware filtering.
- Verifier noise and reward reliability: Evaluate Lp-Reg under noisy or partial verifiers and non-binary rewards; determine whether “sparks” remain beneficial when reward signals are less reliable.
- OOD generalization: Train on diverse datasets beyond Dapo-Math-17K and test on out-of-distribution tasks to assess whether Lp-Reg generalizes or overfits to the math domain.
- Architecture diversity: Validate Lp-Reg across different base models (smaller/larger LLMs, MoE, different pretraining recipes) and with alternative RL algorithms (PPO variants, actor-critic with value baselines).
- Decoding-time interactions: Study synergies or conflicts between Lp-Reg and inference-time strategies (e.g., min-p sampling, temperature scaling, entropy minimization) for optimized exploration at test time.
- Alternative activation logic: The current indicator requires A_{i,t}<0; test variants that activate on more nuanced signals (e.g., uncertainty estimators, value-function margins, plan-state divergence) rather than advantage sign alone.
- Token-function bias: Preserving certain rhetorical markers may bias style or grammar; quantify impacts on syntactic correctness, formatting (e.g., LaTeX), and task-specific conventions.
- Full-vocabulary analysis: The spark/noise analysis was limited to top-64 tokens due to storage constraints; replicate with full vocab and streaming statistics to ensure conclusions hold broadly.
- Threshold selection guidelines: Provide practical rules or meta-learned policies for choosing τ, ρ, κ across models and datasets, minimizing manual tuning.
- Proxy-induced bias: Analyze whether renormalization toward higher-confidence tokens entrenches existing biases (e.g., stylistic, cultural, domain), and propose corrective mechanisms if needed.
- Causal validation: Design controlled experiments that manipulate suppression/preservation of low-probability tokens to directly establish causal links to exploration collapse and performance plateaus.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams that train, evaluate, or use reasoning-focused LLMs, especially in domains with verifiable rewards (e.g., math, programming). Each item includes sector linkages, likely tools/products/workflows, and key dependencies or assumptions.
- Industry (Software/AI)
- Integrate Lp-Reg into RL pipelines for reasoning LLMs to prevent entropy collapse and sustain exploration
- Tools/workflows: A “Proxy-KL Regularizer” module in training frameworks (e.g., Verl, TRL-like stacks), using min‑p thresholding, proxy renormalization, and forward KL targeting negative-advantage low‑probability tokens; dashboards tracking spark preservation and entropy dynamics.
- Dependencies/assumptions: Availability of verifiable reward functions; access to token‑level advantages and behavior policy; base models exhibit an intrinsic confidence distribution where meaningful low‑probability tokens are separable from noise; sufficient compute; careful hyperparameter tuning (ρ, κ, β, U).
- Stabilize on‑policy RLVR runs for extended steps to cut off‑policy fragility
- Tools/workflows: On‑policy GRPO with Lp‑Reg enabling longer stable runs (~1,000 steps), multi‑phase entropy scheduling; training SLAs around “exploration health” metrics.
- Dependencies/assumptions: Compatible RL infrastructure; trust in forward KL regularization against proxy distribution; monitoring for unintended distribution sharpening.
- Exploration‑quality monitoring and audits for training teams
- Tools/workflows: Token‑level analytics (e.g., “reasoning spark index,” probability‑entropy scatter panels per token class), rule‑based alerting when low‑probability reasoning tokens collapse or noise rises; automated ablations (dynamic vs fixed τ).
- Dependencies/assumptions: Logging of next‑token distributions; curated lists of spark vs noise tokens per domain; standardized visualization pipelines.
- Education
- Improved math tutors and assessment systems trained with RLVR + Lp‑Reg
- Tools/products: Step‑by‑step solvers and practice generators with higher accuracy and more robust exploration (e.g., “wait,” “however” reasoning turns), integrated with Math‑Verify.
- Dependencies/assumptions: Math‑Verify or equivalent grading; alignment with curricula; safeguards for CoT verbosity and user privacy.
- Software Engineering
- Train coding assistants using unit tests as verifiable rewards
- Tools/workflows: RLVR pipelines where tests define rewards; Lp‑Reg preserves exploratory reasoning tokens that lead to alternative fixes (e.g., “perhaps,” “alternatively”), reducing mode collapse in patch generation.
- Dependencies/assumptions: Reliable test coverage; clear pass/fail verifiers; domain‑specific noise filtering (e.g., formatting tokens, spurious symbols).
- Academia (LLM/RL research)
- Use Lp‑Reg as a baseline for exploration‑aware RL studies
- Tools/workflows: Comparative experiments against entropy bonuses, sequence‑level clipping variants; shared benchmarks (AIME, MATH‑500, OlympiadBench), replication via Verl.
- Dependencies/assumptions: Access to datasets, compute, and open‑source code; reproducibility of “spark vs noise” probabilistic distinction beyond math.
- Daily Life
- More reliable problem‑solving assistants for math, puzzles, and logic with verifiable answers
- Tools/products: Consumer apps embedding reasoning LLMs trained with Lp‑Reg; explanation‑first interfaces that retain exploratory reconsideration tokens, improving solution robustness.
- Dependencies/assumptions: Verifiable tasks; UX that surfaces multiple reasoning pathways without confusing users; content filters to avoid noisy artifacts.
Long‑Term Applications
These applications require further research, domain‑specific verifiers, scaling, or validation beyond mathematical reasoning.
- Healthcare
- Clinical decision support that preserves exploratory “reflective” tokens to consider alternative diagnoses or treatments
- Tools/workflows: RLVR with structured verifiers (guidelines, knowledge graphs, simulated case reviews); Lp‑Reg to prevent premature pruning of alternate hypotheses.
- Dependencies/assumptions: High‑quality, legally compliant verifiers; rigorous clinical validation; safety and bias audits; human oversight.
- Finance
- Compliance and risk analysis models that sustain exploration of “what‑if” scenarios while avoiding noisy detours
- Tools/workflows: Verifiers based on regulatory rules, audit trails, and scenario backtesting; spark‑aware training to avoid over‑exploitation.
- Dependencies/assumptions: Formalizable reward functions; domain‑specific token curation; robust guardrails against speculative reasoning.
- Robotics and Planning
- Language‑conditioned planners that maintain alternative plan branches during training
- Tools/workflows: Simulator‑based verifiers (goal completion, safety constraints), Lp‑Reg to keep low‑probability exploratory actions viable; integration with task trees and option policies.
- Dependencies/assumptions: High‑fidelity simulators; alignment between language tokens and action semantics; stability across long horizons.
- Legal and Policy Analysis
- Argumentation models that preserve minority but valuable reasoning paths (e.g., “however,” “alternatively”) without amplifying irrelevant noise
- Tools/workflows: Verifiable reward frameworks using citation checks, precedent matching, and formal logic validators; spark‑aware training to reduce collapse into dominant arguments.
- Dependencies/assumptions: Reliable legal verifiers; ethical constraints; explainability requirements; jurisdictional variability.
- Energy and Infrastructure Planning
- Models that explore diverse grid or network planning options while maintaining training stability
- Tools/workflows: Structured verifiers (constraint solvers, cost simulators), Lp‑Reg for exploration quality under long‑horizon optimization.
- Dependencies/assumptions: Domain verifiers; data availability; multi‑objective reward designs.
- Spark‑aware inference‑time decoders and UX
- Decoding strategies that recognize and strategically allow or encourage “reasoning sparks” at inference (without indiscriminate entropy inflation)
- Tools/products: “Spark‑aware decoding” that modulates temperature/top‑p using min‑p‑like thresholds; interfaces that let users toggle exploration modes.
- Dependencies/assumptions: Generalization of spark vs noise beyond training; careful human factors design to avoid verbosity or distraction.
- Curriculum and data generation
- Teacher models that generate verifiable curricula tailored to sustain exploration
- Tools/workflows: RLVR with Lp‑Reg to train question generators balancing difficulty and exploratory pathways; automated ablation to calibrate τ per domain.
- Dependencies/assumptions: Reliable graders/verifiers; domain transfer; avoidance of spurious formatting artifacts.
- Standardization of exploration quality metrics
- Sector‑wide metrics for “exploration quality” during RL training (beyond entropy), adopted by regulators and industry
- Tools/workflows: Token‑level dashboards, percentile‑based thresholds (ρ), spark preservation indices; audit frameworks that report exploration collapse risks.
- Dependencies/assumptions: Acceptance of token‑level measures as meaningful; cross‑domain evidence; governance processes.
Cross‑cutting assumptions and dependencies
- Verifiable rewards are central: effectiveness hinges on tasks with reliable, rule‑based verification (math, programming, formal logic). Extending to open‑ended domains requires new verifiers.
- Base models must have intrinsic confidence distributions where meaningful low‑probability tokens are statistically distinguishable from noise; if this distinction weakens, Lp‑Reg’s filtering may need adaptation.
- Hyperparameter sensitivity: min‑p ratio κ, percentile ρ, KL weight β, and clipping bounds U affect stability and performance; domain‑specific tuning is expected.
- Computational scale and logging: token‑level distributions and advantages must be recorded for monitoring and ablations; large‑scale training infrastructure is assumed.
- Generalization beyond math: reported gains are strongest in math benchmarks; transferring the approach requires domain‑specific token curation and verifiers.
Glossary
Below is an alphabetical list of advanced domain-specific terms used in the paper.
- Actor-only policy gradient: A policy optimization approach that updates only the policy (actor) without learning a value function. "GRPO is a representative actor-only policy gradient method for optimizing LLMs."
- Advantage: A measure of how much better an action (or token) is compared to the average, guiding policy updates. "In this formulation, represents the advantage of the -th token in ."
- Behavior policy: The policy that generated the data used for training, often denoted as the old or reference policy. "where $\pi_{\theta_{\mathrm{old}$ denotes the behavior policy."
- Chain-of-thought (CoT) reasoning: A prompting and generation technique where models produce explicit step-by-step reasoning before answers. "These models generate extended chain-of-thought (CoT) reasoning~\citep{wei2023chainofthoughtpromptingelicitsreasoning} to solve challenging problems"
- Clip-Higher: An off-policy PPO-style variant that encourages higher entropy via asymmetric clipping to stabilize training. "Clip-Higher~\citep{yu2025dapoopensourcellmreinforcement}, a core component of DAPO that encourages higher entropy by using an asymmetric clipping range in the PPO objective"
- Clipping ratio: A PPO hyperparameter that bounds the policy update by limiting the probability ratio. "The hyperparameter specifies the clipping ratio, which constrains the updated policy from deviating excessively from the behavior policy"
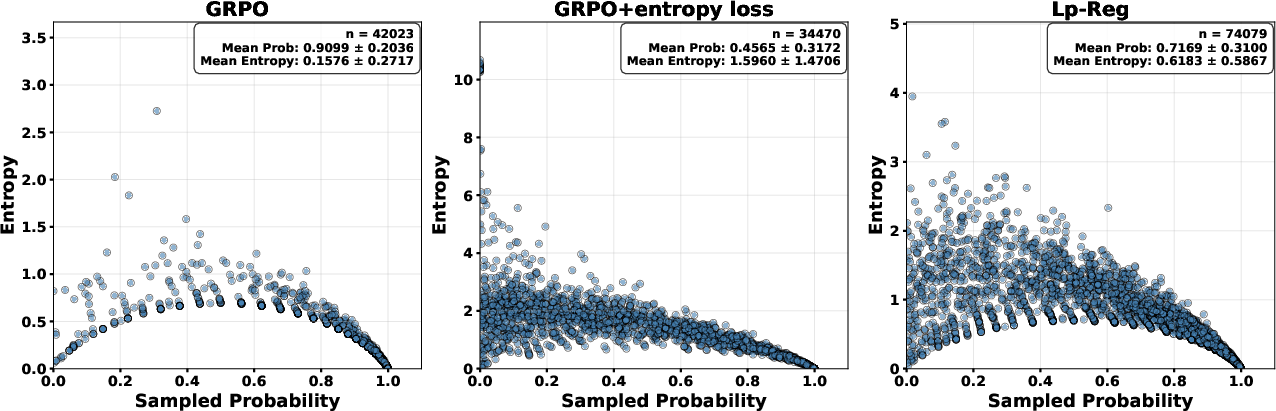
- Confidence-aware regularization: A regularization approach that leverages the model’s confidence to protect meaningful exploratory tokens while avoiding noise. "This adaptive behavior stems from our confidence-aware regularization, which selectively protects reasoning sparks without amplifying low-probability out-of-context irrelevant noise."
- Entropy bonus: An additional term in the RL objective that encourages exploration by increasing policy entropy. "We implement GRPO + Entropy Loss, which directly incorporates the principles of Maximum Entropy RL by adding a policy entropy bonus to the GRPO objective function."
- Entropy collapse: A training failure mode where policy entropy rapidly decreases, indicating loss of exploration and eventual performance degradation. "A recurring difficulty in training reasoning models with RL is the rapid collapse of policy entropy during the early stages of training."
- Entropy minimization: A technique that sharpens the model’s probability distribution to favor high-confidence predictions. "some work has explored entropy minimization, which sharpens the model's confidence distribution."
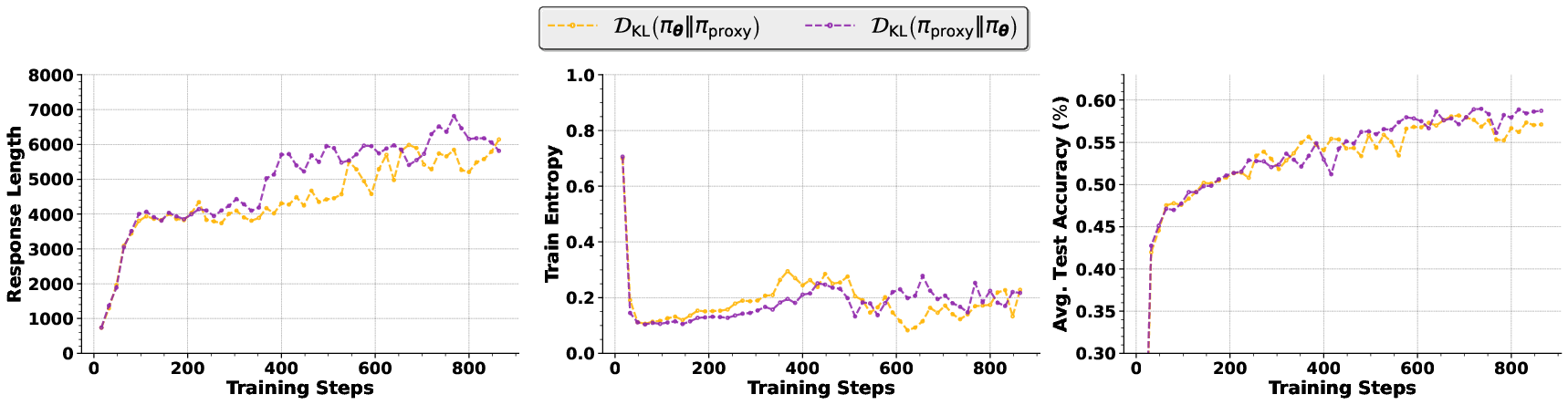
- Forward KL divergence: The Kullback–Leibler divergence used to penalize the current policy when it under-weights tokens present in a proxy distribution. "We use the forward KL divergence, $\mathcal{D}_\mathrm{KL}\left( \pi_{\text{proxy} \Vert \pi_{\boldsymbol{\theta} \right)$ as the regularization function."
- GRPO: Group-Relative Policy Optimization; an actor-only policy gradient method leveraging multiple samples per prompt to estimate advantages. "GRPO is a representative actor-only policy gradient method for optimizing LLMs."
- GSPO: Group Sequence Policy Optimization; a variant that applies clipping at the sequence level to promote exploration. "and GSPO~\citep{zheng2025groupsequencepolicyoptimization}, which modifies the clipping mechanism to operate at the sequence level to promote higher training entropy."
- High entropy change blocking: A strategy to prevent sharp entropy decreases by moderating updates at positions where entropy changes drastically. "Methods such as adaptive entropy regularization~\citep{he2025skyworkopenreasoner1}, high entropy change blocking~\citep{cui2025entropymechanismreinforcementlearning}, or selective token updates~\citep{wang20258020rulehighentropyminority} aim to maintain higher entropy as a proxy for exploration."
- Importance sampling clipping: Limiting the influence of off-policy samples by capping the importance weights to stabilize training. "Off-policy methods, such as Clip-Higher, often rely on importance sampling clipping, leading to instability."
- Importance sampling weight: The ratio of current-policy to behavior-policy probabilities used to correct off-policy updates. "serves as the importance sampling weight for off-policy training"
- Intrinsic confidence: The model’s internal sense of certainty reflected in its next-token probabilities, used to guide exploration. "they have demonstrated an increasingly strong and reliable sense of intrinsic confidence"
- KL-Cov: A selective KL penalty technique that targets tokens with high covariance between log-probability and advantage to prevent entropy collapse. "KL-Cov~\citep{cui2025entropymechanismreinforcementlearning}, which prevents entropy collapse by applying a selective KL-divergence penalty to tokens with the highest covariance between their log probabilities and advantages"
- KL regularization: A penalty encouraging the current policy to stay close to a reference policy measured by KL divergence. "where controls the strength of KL regularization between the current policy and the reference policy $\pi_{\mathrm{ref}$."
- Low-probability Regularization (Lp-Reg): The proposed method that filters presumed noise and regularizes the policy toward a proxy to protect valuable low-probability tokens. "To address this, we introduce Low-probability Regularization (Lp-Reg)."
- Math-Verify: A rule-based verifier for mathematical answers used to compute rewards in RLVR. "such as Math-Verify"
- Maximum Entropy RL: A reinforcement learning framework that explicitly optimizes for high-entropy policies to enhance exploration. "which directly incorporates the principles of Maximum Entropy RL"
- Min-p threshold: An adaptive probability threshold defined relative to the maximum next-token probability to filter noise. "Min-p threshold: Following~\citep{nguyen2025turningheatminpsampling}, is defined relative to the peak probability"
- Off-policy training: Training where the update policy differs from the data-generating policy, requiring importance weighting. "serves as the importance sampling weight for off-policy training"
- On-policy training: Training where the same policy both generates data and is updated, avoiding distribution mismatch. "Lp-Reg enables stable on-policy training for around 1,000 steps"
- Policy entropy: The randomness of the policy’s action distribution; higher entropy typically indicates more exploration. "performance plateaus as policy entropy collapses, signaling a loss of exploration."
- Policy gradient: A class of RL methods that optimize policies via gradients of expected return. "Eq.~\ref{eq:rl} is typically optimized using policy gradient methods"
- PPO (Proximal Policy Optimization): A widely used policy gradient algorithm with clipped updates to ensure training stability. "Proximal Policy Optimization (PPO) \citep{schulman2017proximal}"
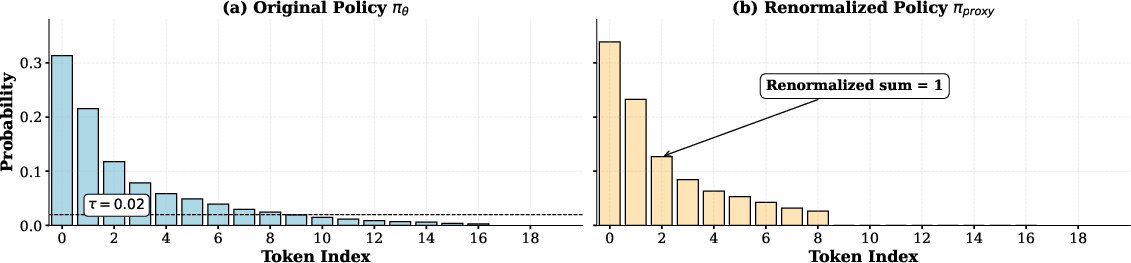
- Probability renormalization: The process of zeroing out filtered tokens and re-normalizing remaining probabilities to form a proxy distribution. "Probability Renormalization: As shown in Figure~\ref{fig:policy_renorm}, the proxy distribution $\pi_{\text{proxy}$ assigns zero probability to tokens filtered out in the previous step and renormalizes the probability mass across the remaining tokens"
- Proxy distribution: A filtered, re-normalized version of the current policy used as a soft regularization target. "The foundation of Lp-Reg is the construction of a proxy distribution"
- Reference policy: A fixed or slowly changing policy used to regularize the current policy via KL divergence. "between the current policy and the reference policy $\pi_{\mathrm{ref}$."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setup where rewards come from rule-based verification of outputs (e.g., math solutions). "Reinforcement Learning with Verifiable Rewards (RLVR) has propelled LLMs in complex reasoning"
- Reasoning sparks: Valuable low-probability tokens (e.g., “wait”, “however”) that initiate diverse reasoning paths and aid exploration. "We term these tokens Reasoning Sparks; they include words like “wait”, “however”, or “perhaps”"
- Reverse KL regularization: A variant of KL-based regularization that uses ; discussed in ablations. "We conduct further ablation studies on the high-entropy token regularization and reverse KL regularization."
- Rule-based verification: A deterministic checking mechanism to assign rewards based on correctness of outputs. "assigns reward to verifiable solutions through rule-based verification."
- Selective High-Entropy Training (80/20): A method that updates only high-entropy positions to sustain exploration. "Selective High-Entropy Training (80/20)~\citep{wang20258020rulehighentropyminority}, a method that restricts policy gradient updates to only the top 20\% of tokens with the highest generation entropy"
- Surrogate objective: The PPO objective function used to approximate the true RL objective while enabling stable optimization. "using the PPO surrogate objective:"
- Verifier rewards: Rewards assigned based on external verification tools (e.g., math checkers) rather than human feedback. "For the reinforcement learning from verifier rewards (RLVR) phase, models are trained on the Dapo-Math-17K~\cite{yu2025dapoopensourcellmreinforcement} dataset"
Collections
Sign up for free to add this paper to one or more collections.

