Clip-Low Increases Entropy and Clip-High Decreases Entropy in Reinforcement Learning of Large Language Models
Abstract: Reinforcement learning with verifiable rewards (RLVR) has recently emerged as the leading approach for enhancing the reasoning capabilities of LLMs. However, RLVR is prone to entropy collapse, where the LLM quickly converges to a near-deterministic form, hindering exploration and progress during prolonged RL training. In this work, we reveal that the clipping mechanism in PPO and GRPO induces biases on entropy. Through theoretical and empirical analyses, we show that clip-low increases entropy, while clip-high decreases it. Further, under standard clipping parameters, the effect of clip-high dominates, resulting in an overall entropy reduction even when purely random rewards are provided to the RL algorithm. Our findings highlight an overlooked confounding factor in RLVR: independent of the reward signal, the clipping mechanism influences entropy, which in turn affects the reasoning behavior. Furthermore, our analysis demonstrates that clipping can be deliberately used to control entropy. Specifically, with a more aggressive clip-low value, one can increase entropy, promote exploration, and ultimately prevent entropy collapse in RLVR training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how a common training trick used in reinforcement learning for LLMs quietly changes how “exploratory” the model is. The trick is called clipping, and it has two parts: clip-low and clip-high. The authors show that:
- clip-low makes the model more exploratory (higher entropy),
- clip-high makes the model less exploratory (lower entropy), and in typical settings, clip-high wins, so entropy goes down. They explain why this happens, prove it in a simple case, and show it in real experiments on math reasoning tasks. Finally, they suggest how to tune clipping to keep models exploring longer and avoid “entropy collapse.”
The big questions the paper asks
- Why do LLMs trained with reinforcement learning often become too predictable too quickly? (This is called entropy collapse.)
- Does the clipping rule in popular methods like PPO and GRPO push models toward more or less exploration?
- Can we control exploration (entropy) simply by adjusting clipping, without changing the reward?
How did the authors investigate it?
First, here are a few terms explained with everyday language:
- Entropy: Think of a student answering a problem. High entropy means the student tries many different ideas; low entropy means the student gives almost the same answer every time.
- Reinforcement Learning with Verifiable Rewards (RLVR): You ask a model to solve a problem, then you check if its final answer is correct. If yes, it gets a “good job” reward; if not, it does not.
- PPO/GRPO and clipping: These are training methods that include “guardrails” so the model doesn’t change too much in one step. The guardrails are two limits:
- clip-low: prevents big changes when the model is trying to downweight bad actions,
- clip-high: prevents big changes when the model is trying to upweight good actions.
- Advantage: A number that says whether a chosen action was better or worse than average.
The authors use two approaches:
- Simple theory with “random rewards”
- They analyze a toy case where rewards are totally random (they don’t depend on the model’s answer).
- In this case, learning shouldn’t prefer any answer. So if anything changes, it’s due to the training method itself.
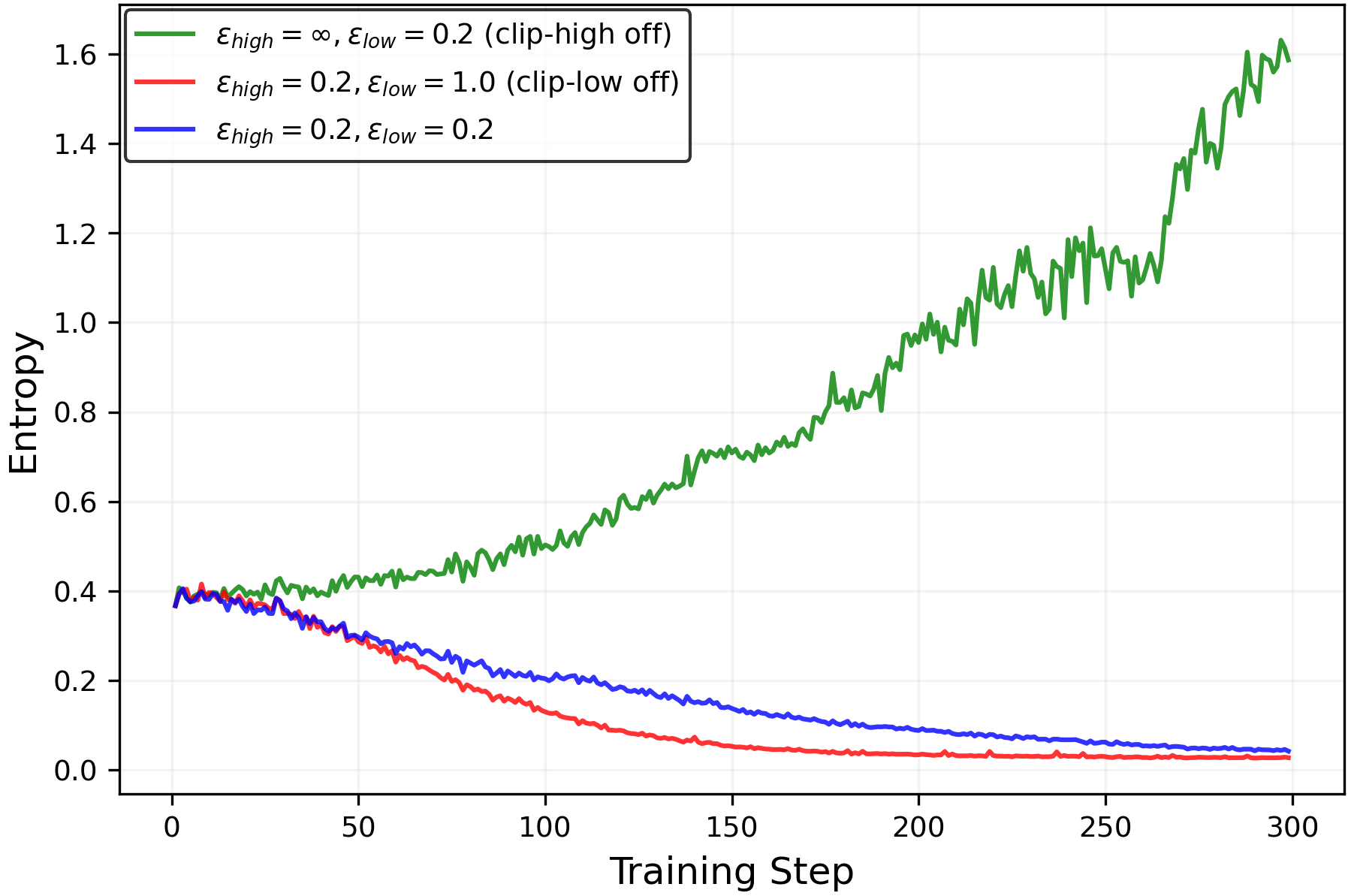
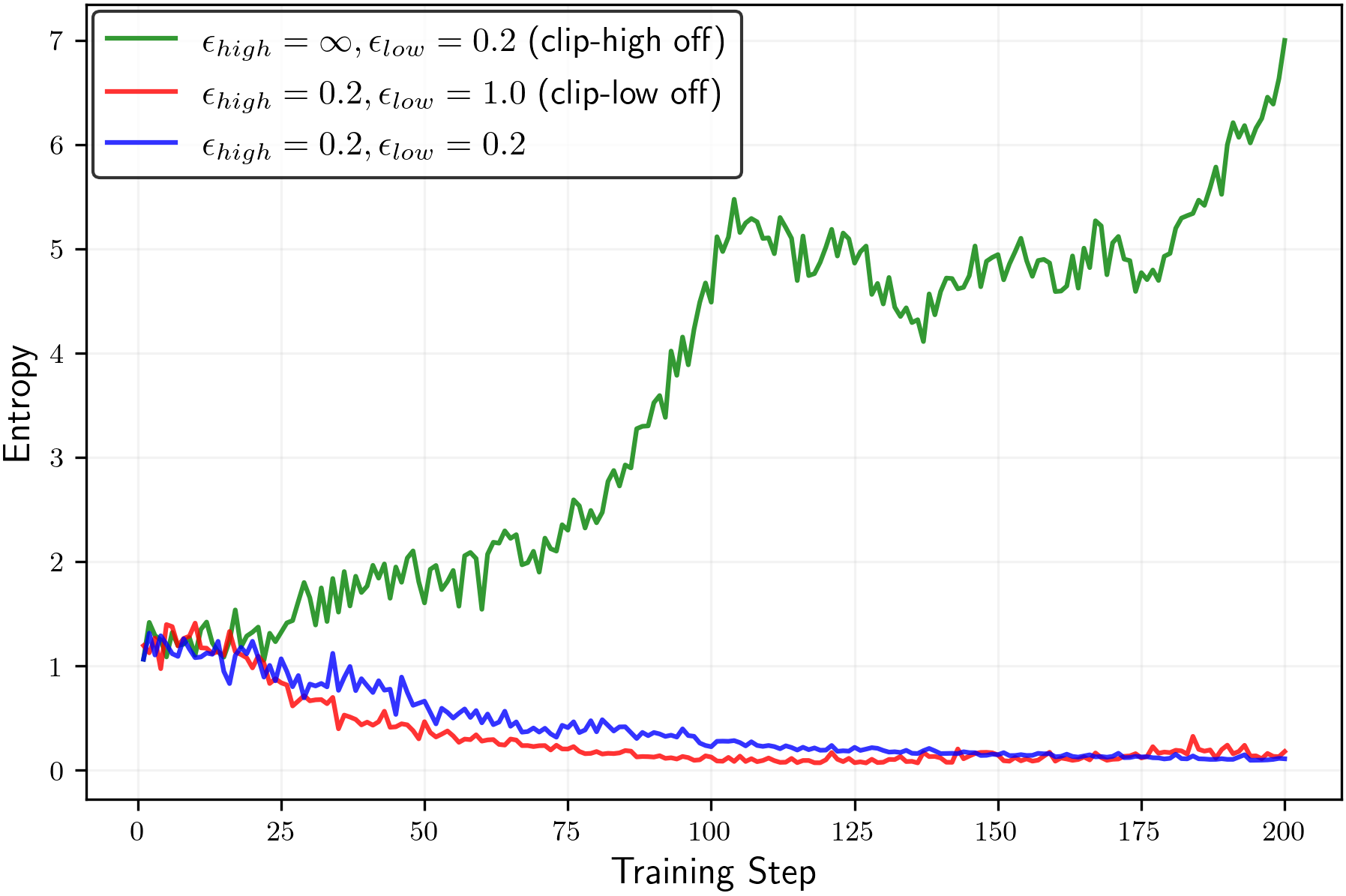
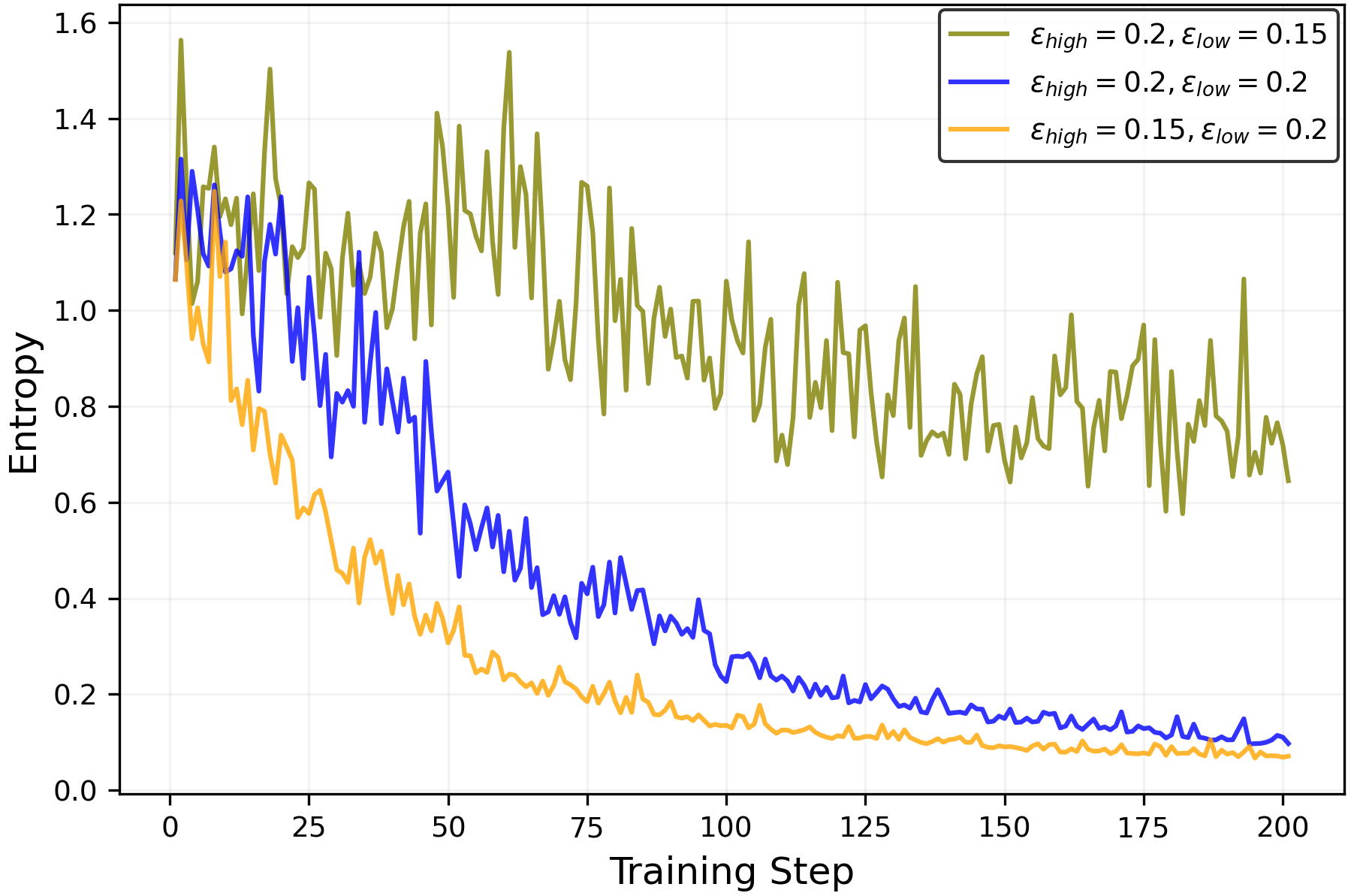
- They prove that clip-low tends to increase entropy and clip-high tends to decrease entropy. In normal settings, clip-high’s effect dominates, so entropy goes down.
- Real experiments on math reasoning
- They train LLMs (like Qwen and Llama) on math datasets using GRPO.
- They measure entropy and performance using:
- pass@k: If you sample k different answers, does at least one get it right?
- mean@k: How often an individual sample is right on average when sampling k answers.
- They try different clipping settings and see how entropy and performance change during training.
What did they find, and why does it matter?
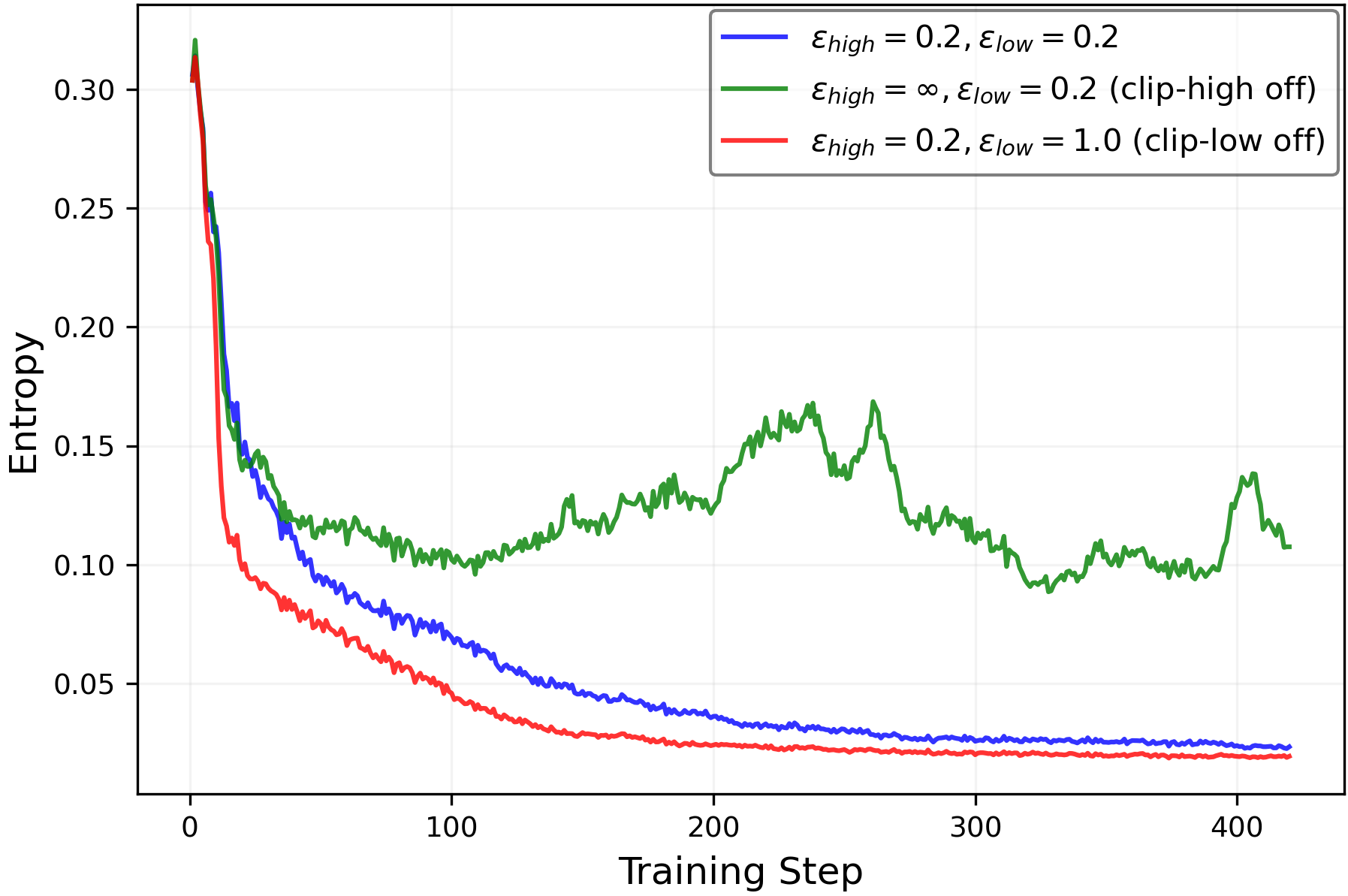
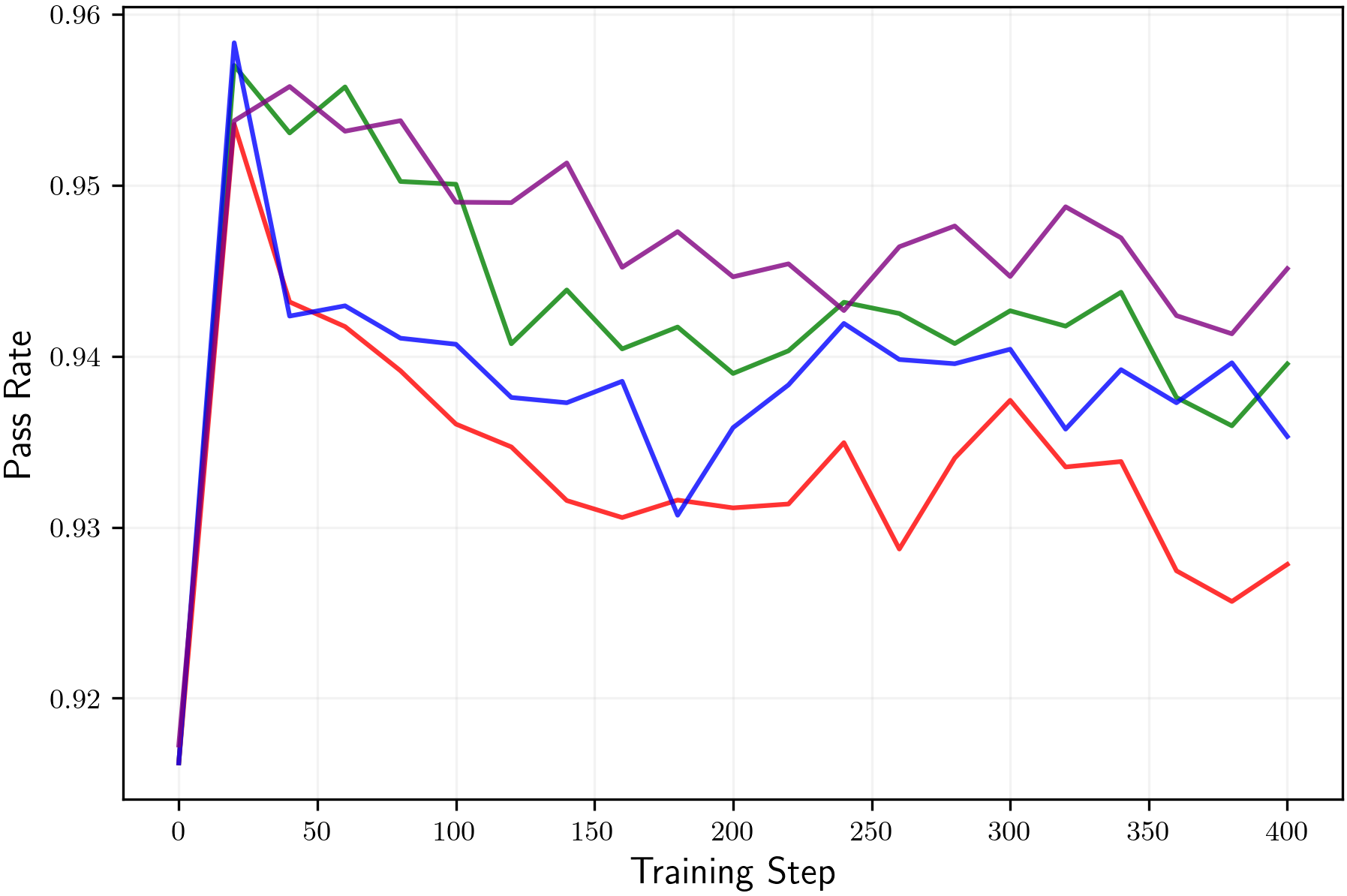
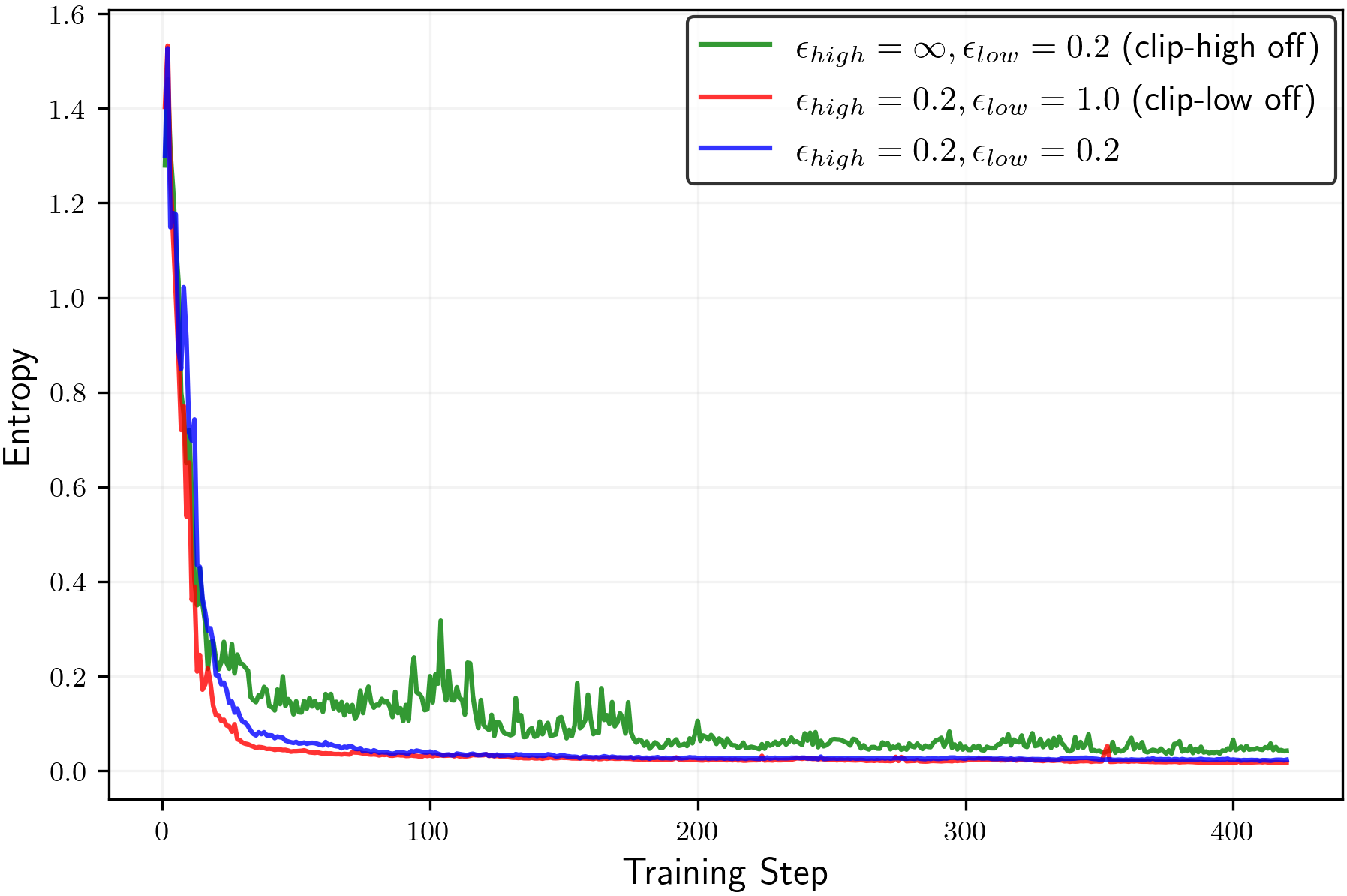
- Clip-low increases entropy; clip-high decreases entropy. This holds in the math tasks as well as in the simple “random reward” case.
- With common symmetric settings (same strength for clip-low and clip-high), clip-high’s entropy-lowering effect usually wins. That means the model becomes too predictable, even if the reward gives no useful information.
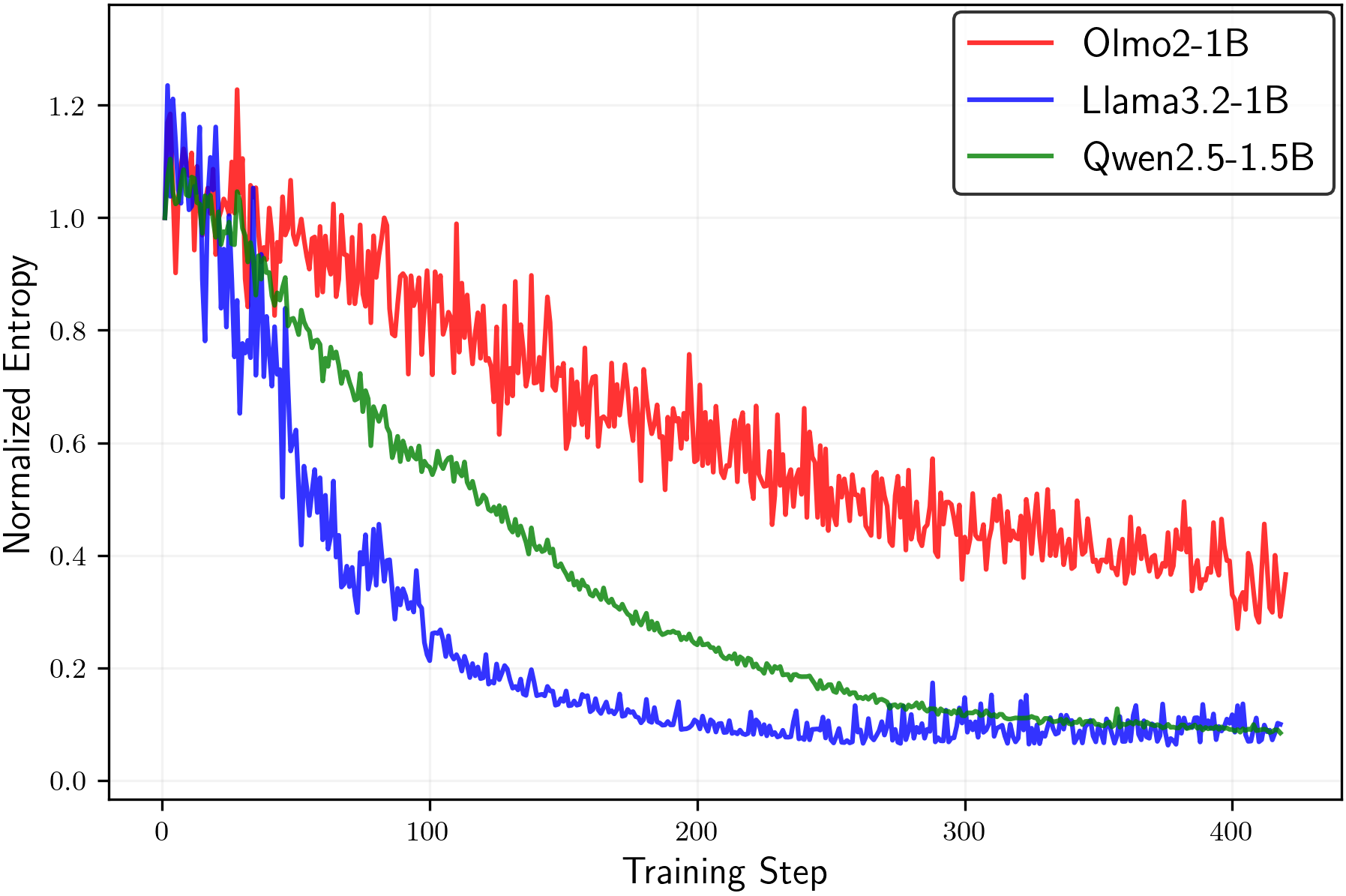
- Random or noisy rewards still reduce entropy across different model families. This suggests that the “improvements” some people report under random rewards might be driven by entropy minimization rather than actual learning from signal.
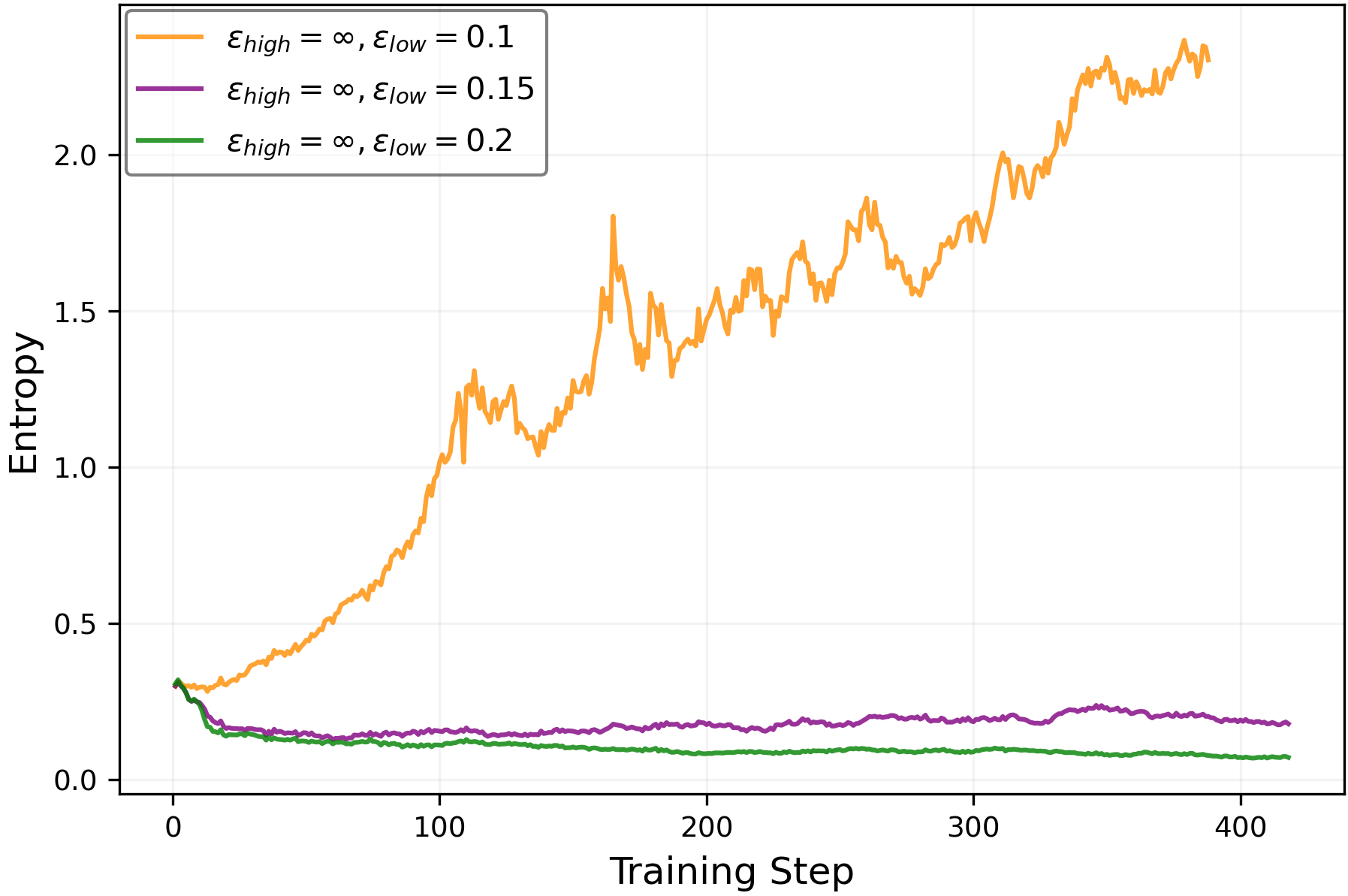
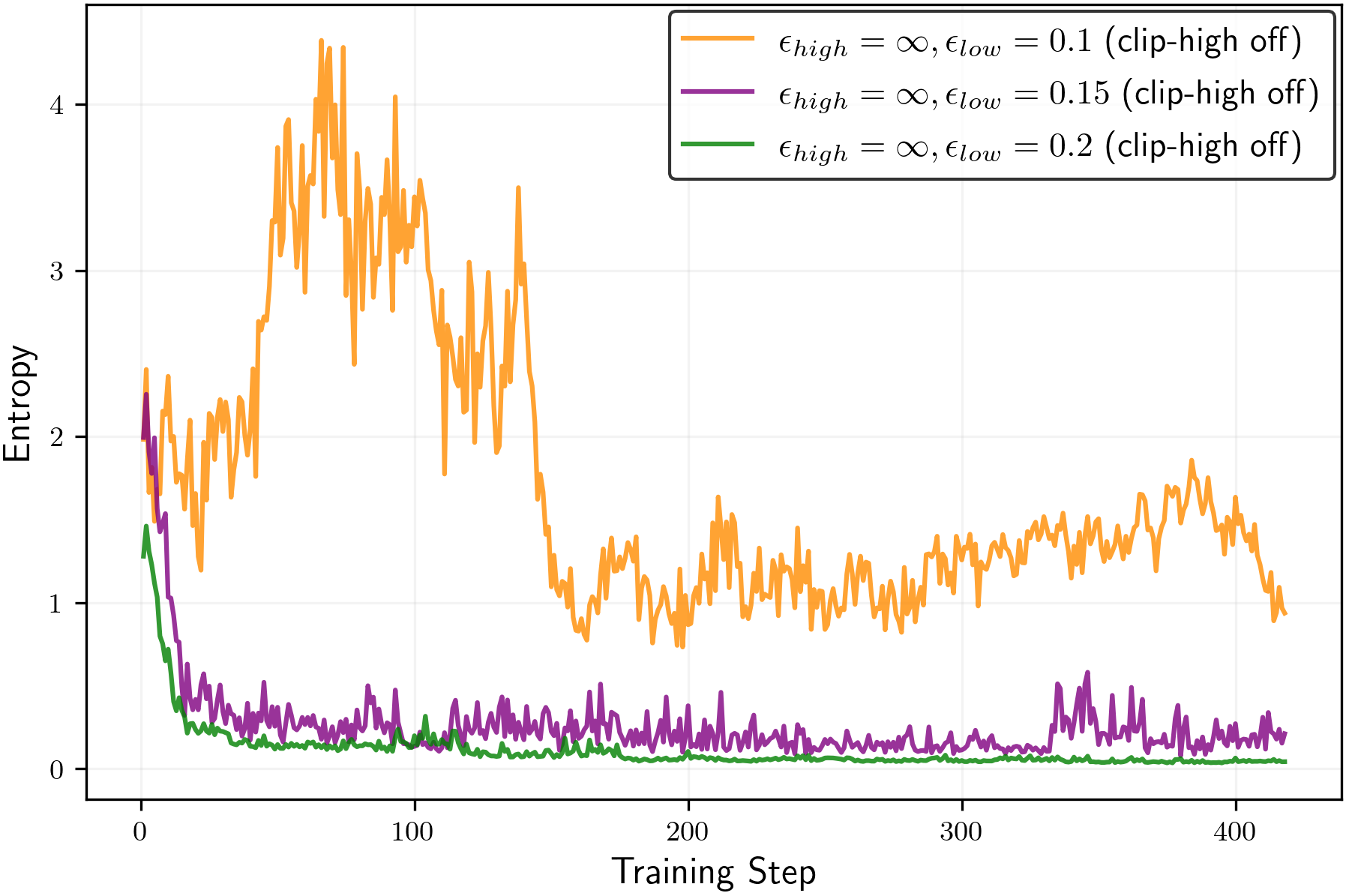
- Turning off clip-high and making clip-low stronger can keep entropy from collapsing. This helps the model keep exploring different reasoning paths longer.
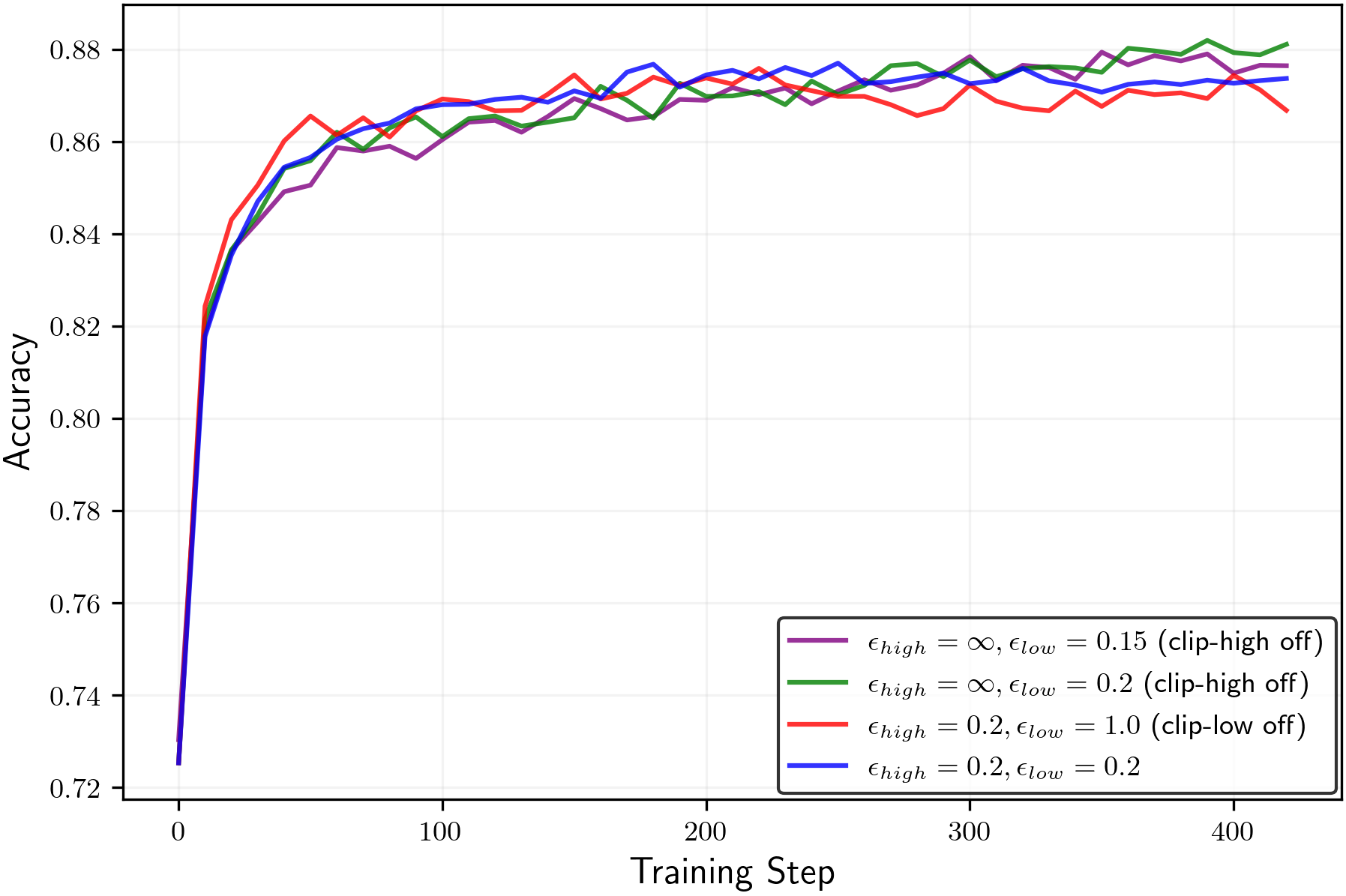
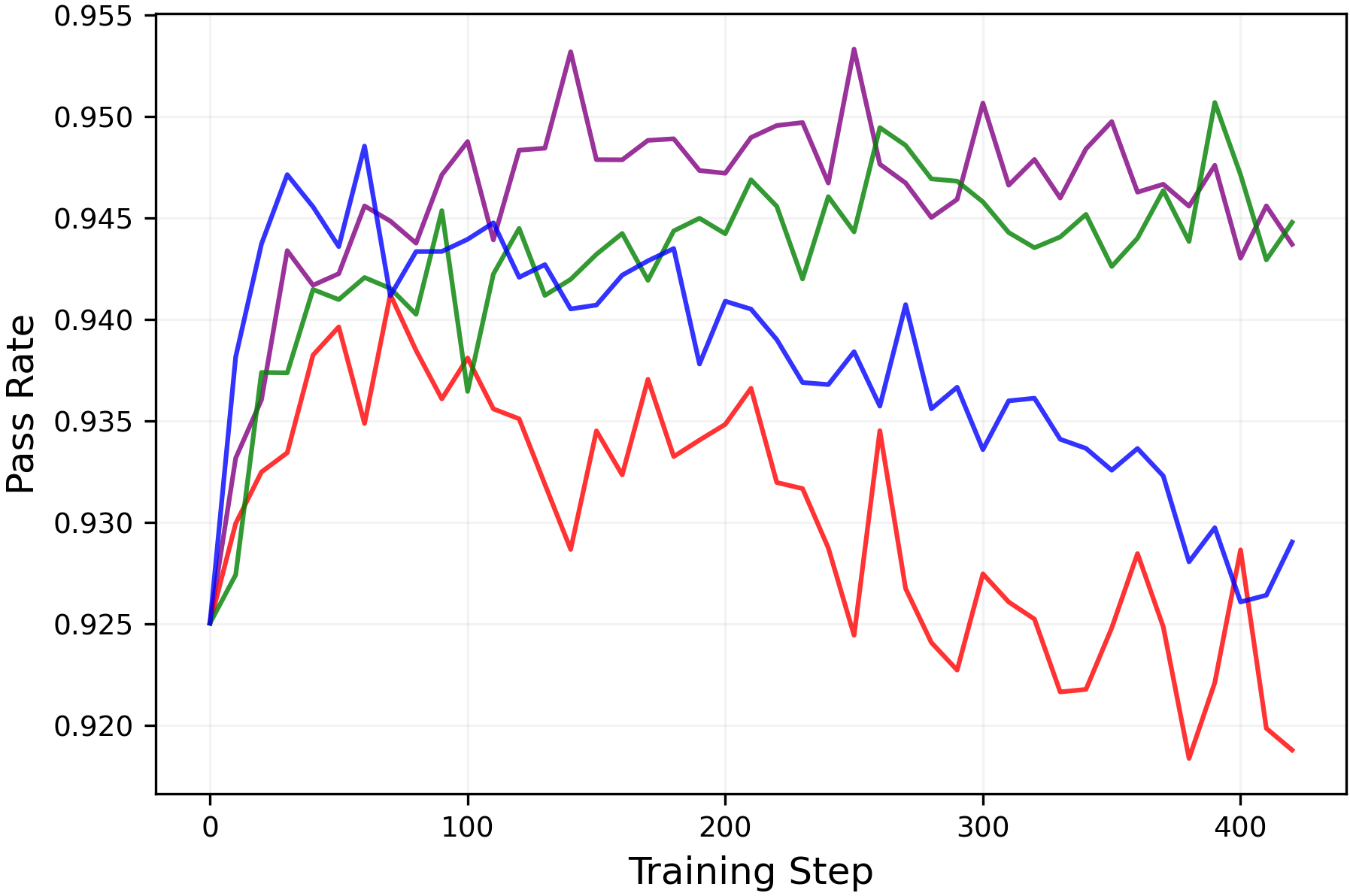
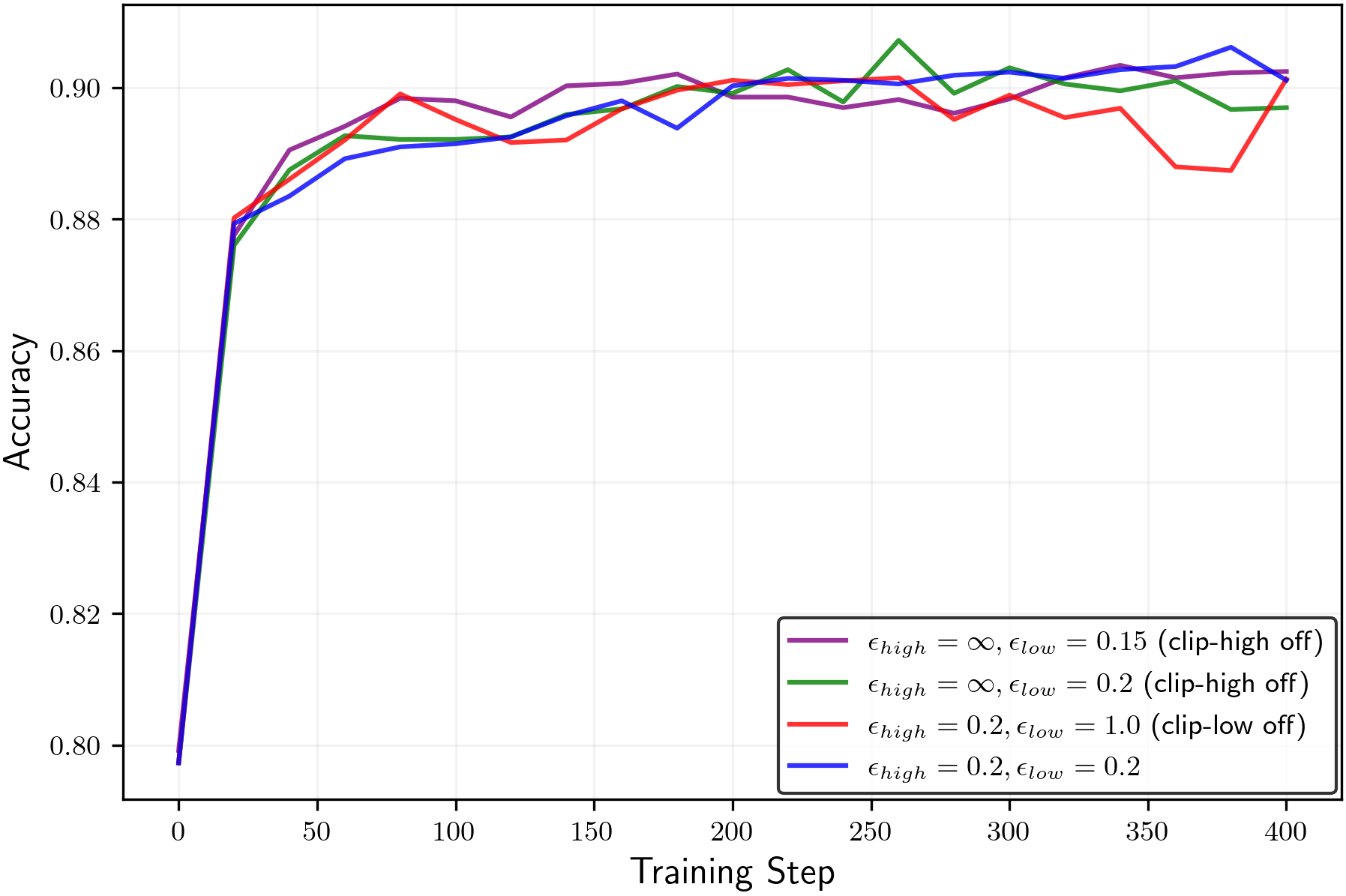
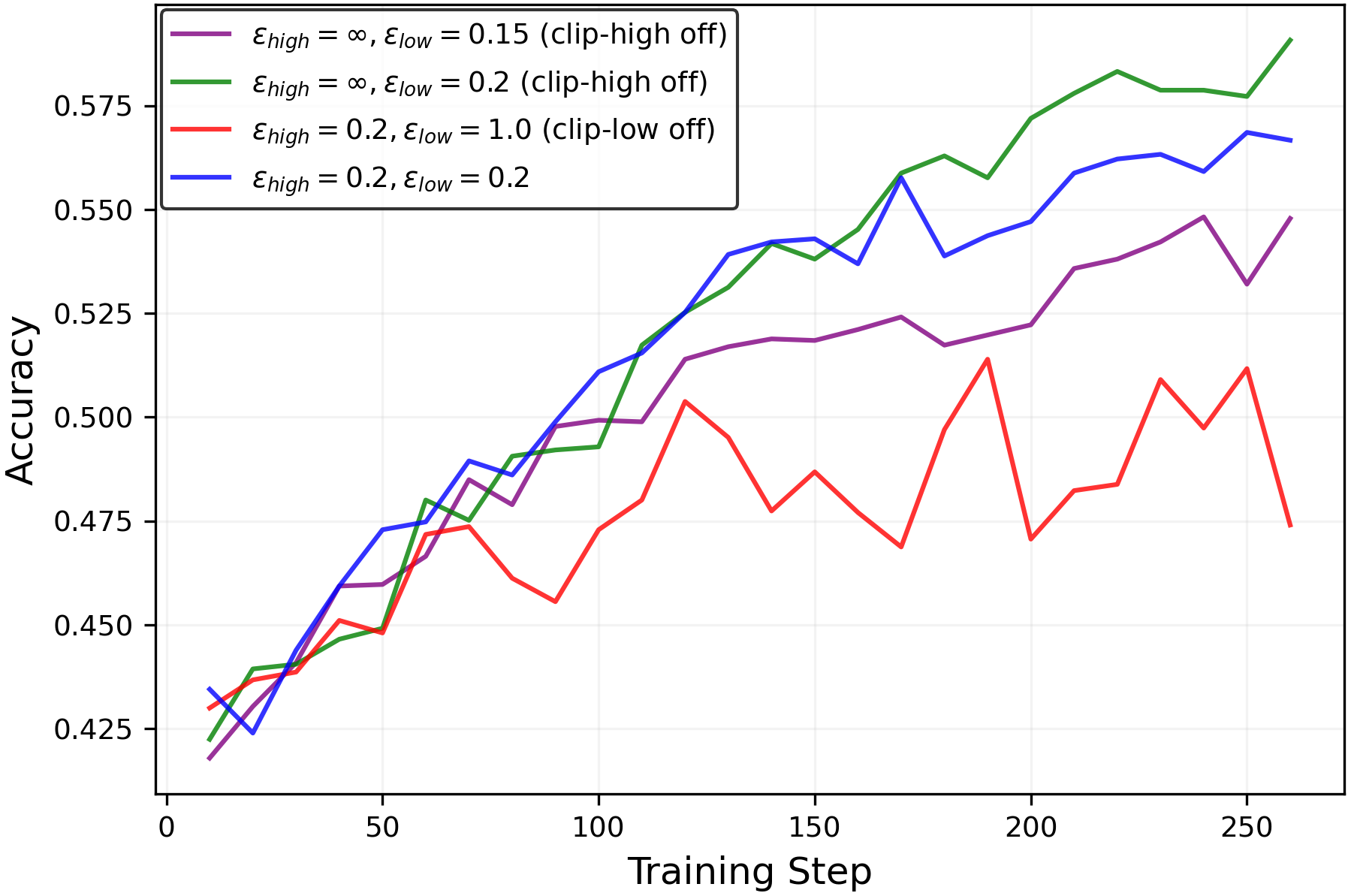
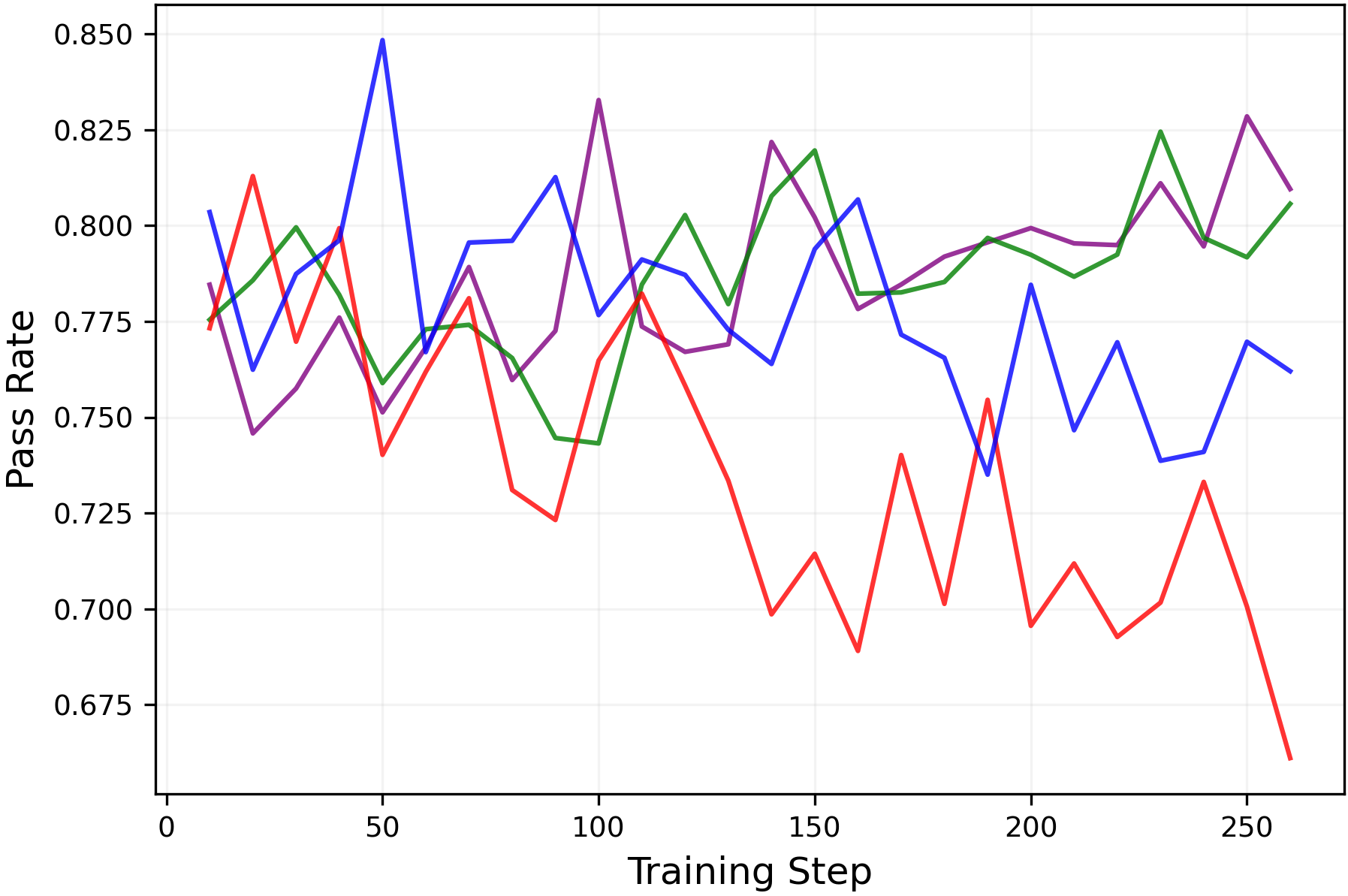
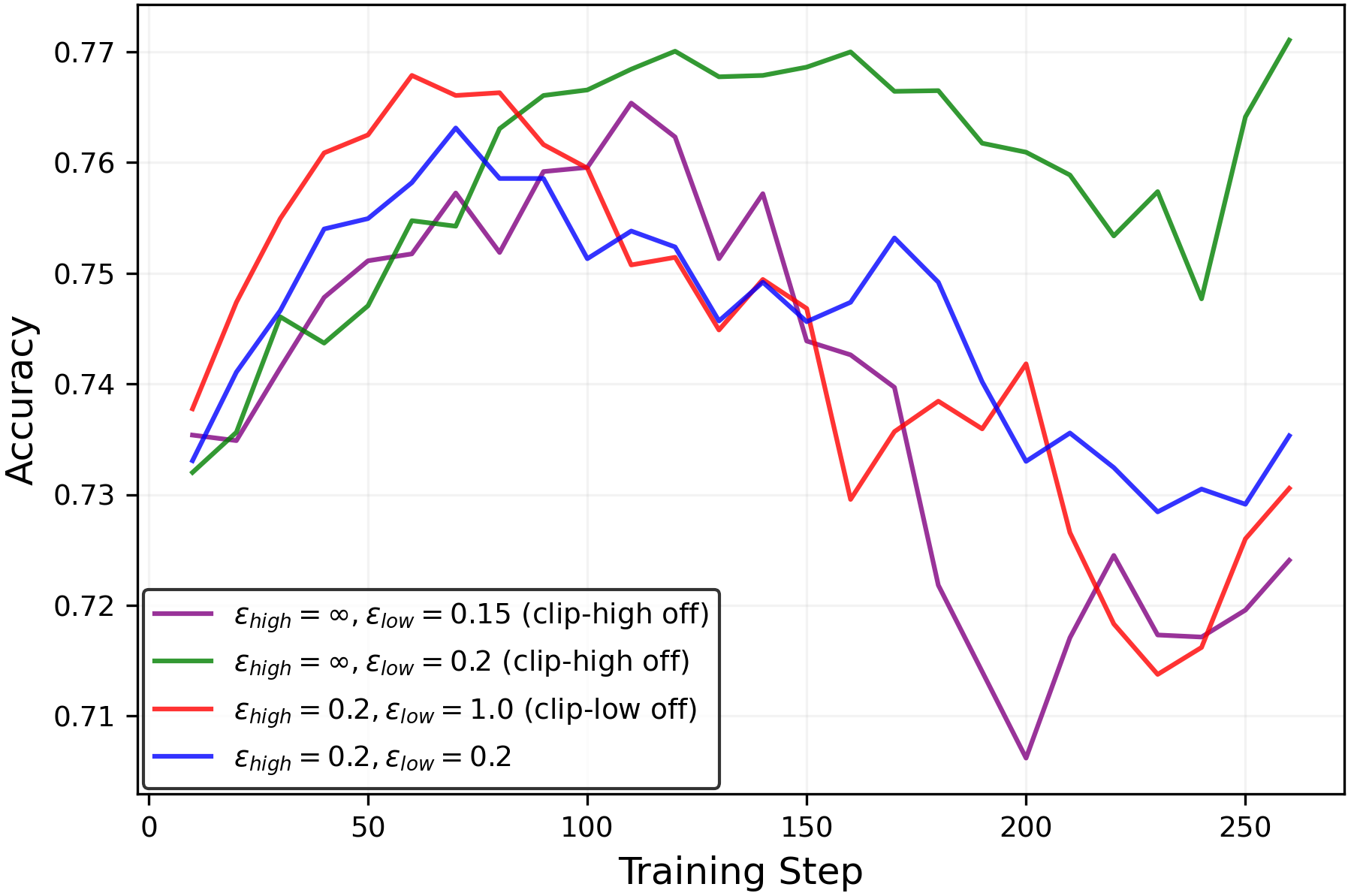
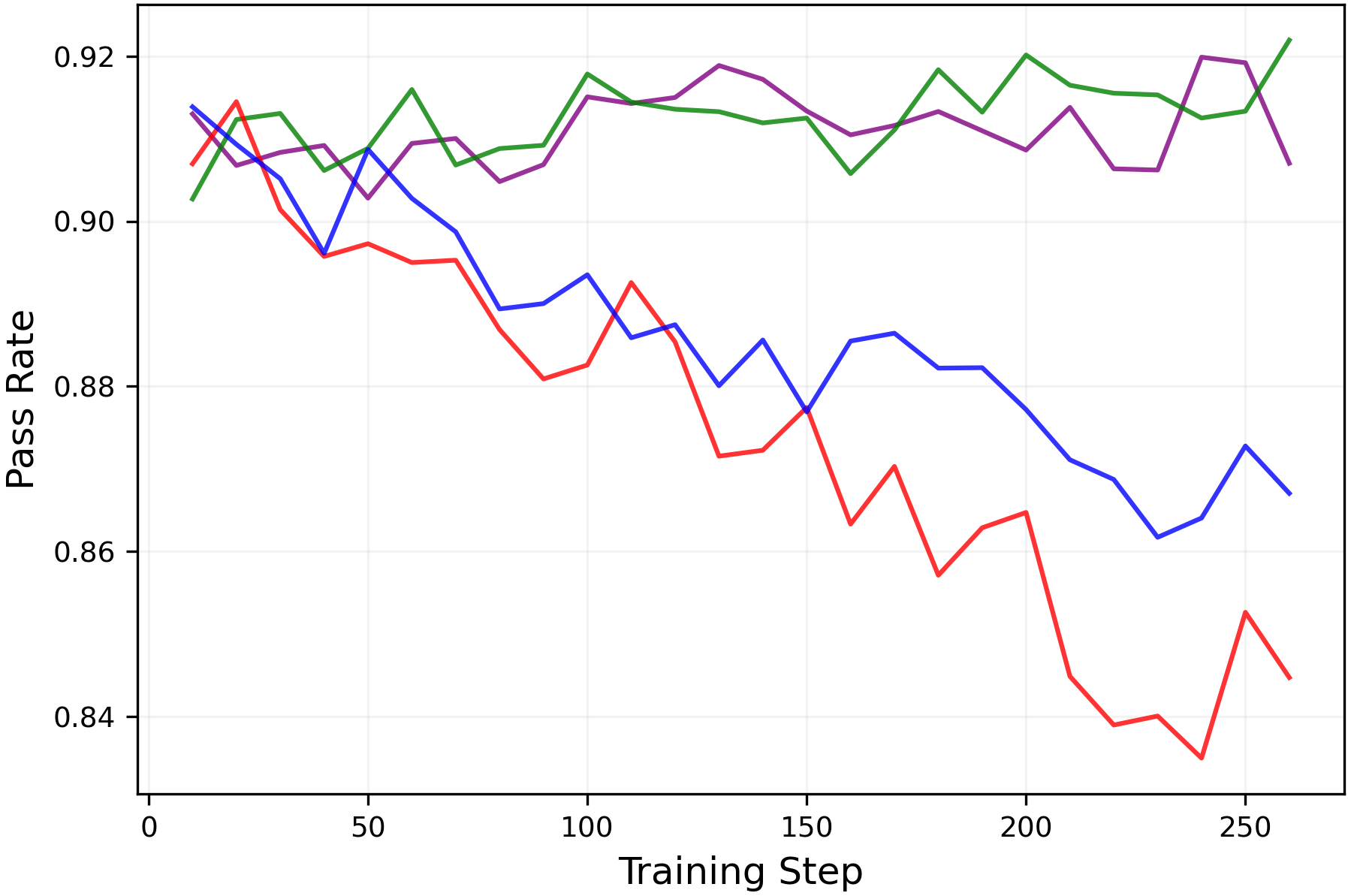
- In practice, keeping entropy higher preserved or improved pass@k (meaning the model is more likely to find at least one correct solution among several tries) without hurting mean@k. That’s valuable: better exploration without worse single-shot accuracy.
What does this mean going forward?
- Clipping isn’t just a safety feature; it shapes how the model explores, independent of the reward. That means it’s a hidden lever controlling reasoning behavior.
- By tuning clipping (for example, weaker clip-high and stronger clip-low), researchers can avoid entropy collapse, train longer, and maintain the diversity of reasoning paths.
- This reframes why “random rewards” sometimes show training gains: it’s often entropy minimization at work, not meaningful learning from the reward.
- Future work can tighten the theory beyond the toy case, and study how to best set clipping to maximize both performance and exploration.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of unresolved issues and concrete directions that are missing, uncertain, or left unexplored in the paper:
- Theory is confined to random rewards with independence and symmetry assumptions; extend analysis to realistic RLVR rewards that are skewed, sparse, verifier-dependent, and policy-correlated.
- The first-order (in η) entropy-change analysis ignores higher-order terms; derive non-asymptotic bounds that hold for practical step sizes and multi-step updates.
- Replace the policy-gradient/natural-policy-gradient surrogate with an analysis of the actual GRPO/PPO inner-loop updates under AdamW and minibatch stochasticity.
- Formalize and prove sufficient conditions for the key inequalities (the “Q-sign” and “log-sign” conditions) or characterize when they fail; quantify how often they hold in LLM training.
- Move beyond the tabular softmax assumption to neural policies with shared parameters and very large vocabularies; account for parameter coupling and curvature in realistic models.
- Model the outer loop that updates the reference policy π_old: quantify how refresh frequency, trust-region size, and surrogate adherence influence entropy drift over training.
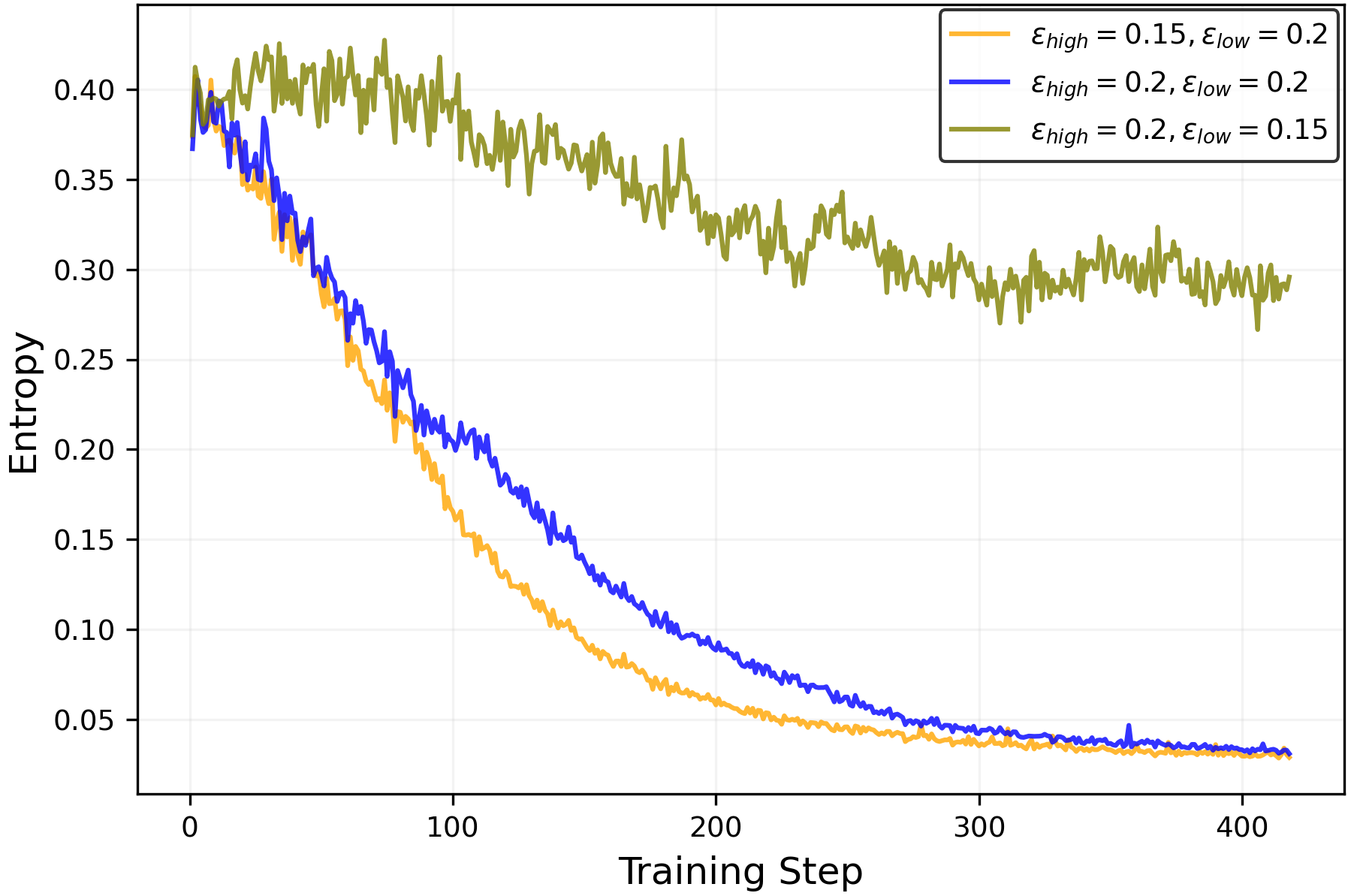
- Derive explicit, data-dependent thresholds on ε_low and ε_high for when clip-high dominates clip-low (and vice versa); provide estimators practitioners can compute online.
- Analyze the impact of advantage normalization (used in original GRPO) on entropy bias; current theory omits this widespread practice.
- The interaction with KL penalties and explicit entropy bonuses is not characterized; provide theoretical and empirical mappings of combined effects on entropy and performance.
- Study the role of GRPO group size K and group-baseline choice on entropy bias and variance; determine how K and sampling strategy modulate clipping events.
- Quantify sensitivity to rollout sampling temperature and decoding strategy during data collection; disentangle sampling-induced changes in state visitation from clipping effects.
- Examine token-position and token-type dependence: which tokens (early vs late, high-entropy minority tokens) are most affected by clip-low/high, and how this relates to reasoning steps.
- Connect token-level entropy to response-level diversity: develop sequence-level diversity metrics and link them causally to pass@k, beyond correlational evidence.
- Validate generalization beyond math reasoning (e.g., code generation, tool use, instruction following, safety alignment); check whether entropy control transfers without degradation.
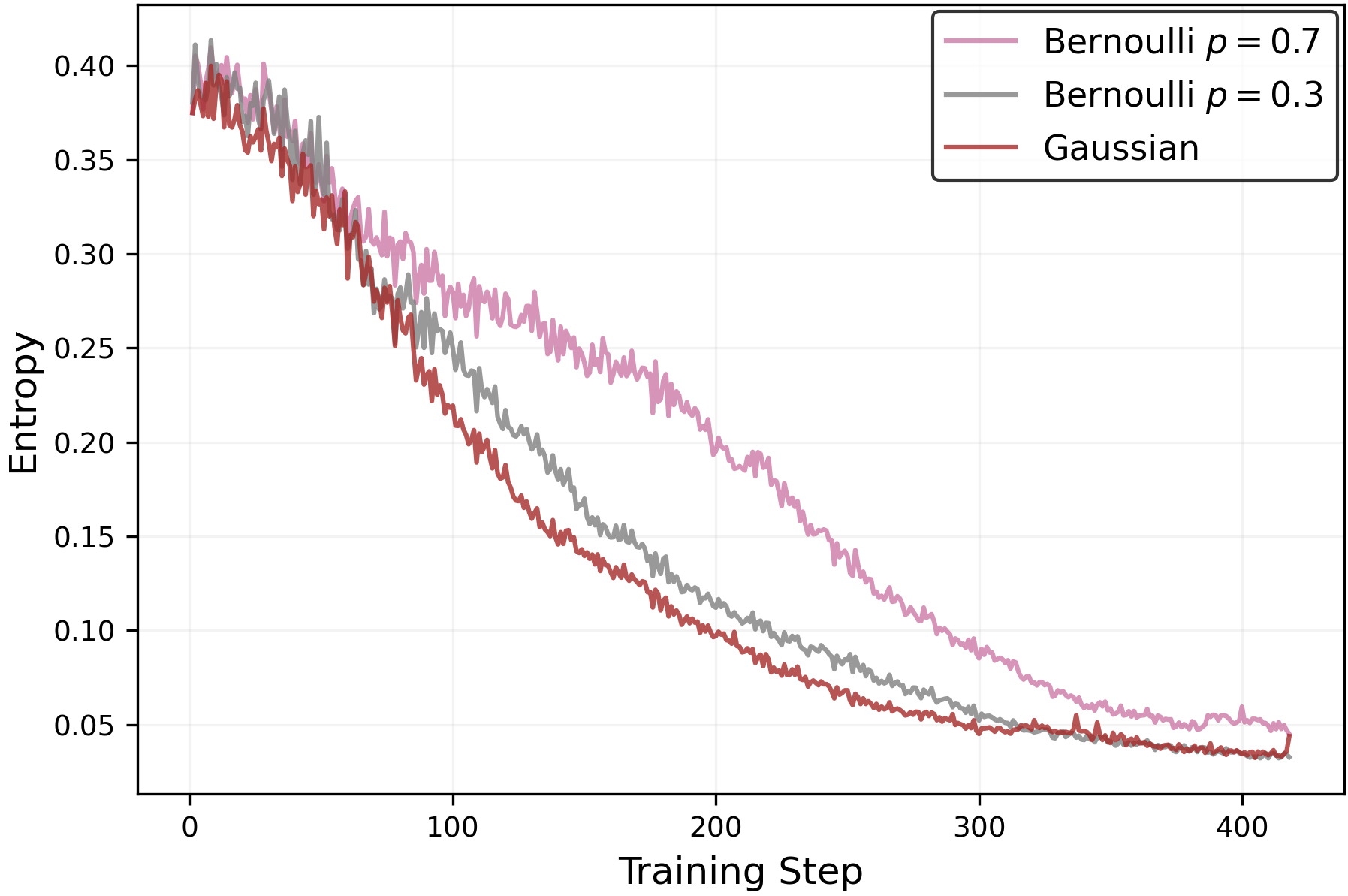
- Evaluate robustness under diverse noisy reward profiles: skewed Bernoulli, heavy-tailed, adversarial/spurious signals, and realistic verifier error modes.
- Assess stability and safety when turning off clip-high (ε_high = ∞): quantify risks of large, destabilizing policy updates, reward hacking, or collapse; propose concrete safeguards.
- Design automatic controllers (e.g., entropy targeting via adaptive ε_low/ε_high schedules or PID control) with convergence guarantees, rather than manual hyperparameter tuning.
- Investigate long-horizon and prolonged training regimes: does entropy control prevent collapse over millions of steps; what are the drift and forgetting dynamics?
- Measure effects on probability calibration, perplexity, and confidence calibration; understand trade-offs between entropy manipulation and calibrated reasoning.
- Establish causality between entropy changes and exploration gains: control for confounders like sequence length, decoding temperature, and sampling strategy in ablation studies.
- Study interactions with inference-time decoding (temperature, nucleus sampling, self-consistency): are training-time entropy adjustments complementary or redundant?
- Provide diagnostics and guardrails against entropy explosion (e.g., target ranges, early stopping criteria, adaptive step sizes); derive conditions that prevent blow-up.
- Compare clipping to alternative trust-region mechanisms (e.g., KL-penalized TRPO, mirror descent) that may decouple stability from entropy bias.
- Explore learned or value-based baselines (actor–critic variants) and their influence on entropy dynamics relative to the group-mean baseline used here.
- Strengthen empirical evidence: expand model families and scales, increase seeds, and report statistical significance to substantiate generalization claims (e.g., “consistent across Qwen/Llama/Olmo”).
- Translate entropy control into performance optimization: formalize objective/constraint formulations that jointly maximize reward while maintaining exploration, beyond keeping entropy “high enough.”
Glossary
- Advantage: In policy gradients, a scalar estimate of how much better or worse an action is compared to a baseline at a given state and time step. Example: "A_t is an advantage estimate derived from the trajectory-level rewards"
- Clipping mechanism: The PPO/GRPO rule that clips the policy ratio to a trust region to stabilize updates, which can bias entropy. Example: "we reveal that the clipping mechanism in PPO and GRPO induces biases on entropy."
- Clip-high: The upper clipping bound applied to positive advantages in PPO/GRPO that tends to decrease entropy. Example: "we show that clip-low increases entropy, while clip-high decreases it."
- Clip-higher: An asymmetric variant that relaxes the upper clipping bound to reduce clip-high events and slow entropy decay. Example: "they propose `clip-higher', an asymmetric clipping rule that reduces the clip-high events by setting"
- Clip-low: The lower clipping bound applied to negative advantages in PPO/GRPO that tends to increase entropy. Example: "we show that clip-low increases entropy, while clip-high decreases it."
- Entropy collapse: A phenomenon where the policy becomes near-deterministic, reducing exploration and harming long training. Example: "RLVR is prone to entropy collapse, where the LLM quickly converges to a near-deterministic form, hindering exploration and progress during prolonged RL training."
- Entropy explosion: A runaway increase of policy entropy during training, causing overly diffuse action distributions. Example: "preventing both entropy collapse and entropy explosion."
- Entropy minimization: The tendency or objective to reduce the policy’s entropy, often implicitly encouraged by certain training setups. Example: "methods that utilize entropy minimization of the policy model"
- Exploration tokens: Tokens that contribute to diverse sampling and exploration during training; suppressing them can accelerate entropy decay. Example: "prevents the `exploration tokens' from being pushed up, accelerating entropy decay."
- GRPO (Group Relative Policy Optimization): A PPO-style algorithm for trajectory-level rewards that uses group-relative advantages. Example: "We use the GRPO algorithm"
- Importance sampling ratio: The ratio between new and old policy probabilities for taken actions, clipped in PPO/GRPO to stabilize updates. Example: "the importance sampling ratio is clipped to lie within the range"
- KL divergence: A divergence measure used as a regularizer to keep the updated policy close to a reference policy. Example: "explicitly incorporating a KL-divergence loss term"
- Markov Decision Process (MDP): A formal framework with states, actions, and transitions used to cast sequence generation as RL. Example: "consider the MDP with a discrete state space"
- Mean@k: Accuracy averaged over k samples per prompt (i.e., average pass@1 across k draws). Example: "mean@k reflects the average single-response accuracy (pass@1) across those responses."
- Natural policy gradient: A policy gradient method that follows the geometry of the policy space via the Fisher metric for more stable updates. Example: "The second algorithm is the natural policy gradient algorithm"
- Pass@k: The probability that at least one of k sampled responses is correct; a measure of exploration breadth. Example: "The pass@k metric measures whether at least one of the sampled responses yields the correct solution"
- Policy entropy: The Shannon entropy of the policy’s action distribution, measuring its stochasticity. Example: "they can increase policy entropy to some extent"
- Policy gradient: An algorithmic family that directly ascends the expected reward by differentiating through the policy. Example: "the policy gradient algorithm"
- Proximal Policy Optimization (PPO): A widely used on-policy RL algorithm with a clipped objective for stable policy updates. Example: "proximal policy optimization (PPO)"
- REINFORCE: A Monte Carlo policy gradient estimator that uses sampled returns to update the policy. Example: "The classical REINFORCE policy gradient estimator"
- Reinforcement learning with verifiable rewards (RLVR): An RL setup where rewards are verifiable (e.g., by checking solutions), used to train LLM reasoning. Example: "Reinforcement learning with verifiable rewards (RLVR) has recently emerged as the leading approach for enhancing the reasoning capabilities of LLMs."
- State visitation measure: The expected number of visits to each state under a policy, used to weight contributions across states. Example: "we define its state visitation measure as"
- Tabular softmax policy: A parameterization where each state-action logit is stored explicitly and converted to probabilities via softmax. Example: "parameterized as a tabular softmax policy"
- Token-level (state-conditional) Shannon entropy: The per-state entropy of the token distribution produced by the policy. Example: "the token-level (state-conditional) Shannon entropy of the policy is defined as"
- Trajectory-level rewards: Rewards defined for entire generated sequences, rather than per-token, used in RL for LLMs. Example: "advantaged estimate derived from the trajectory-level rewards"
- Trust Region Policy Optimization (TRPO): A policy optimization method that constrains updates within a trust region, inspiring PPO’s clipping. Example: "trust-region policy optimization (TRPO)"
Practical Applications
Immediate Applications
The findings enable practical controls for entropy during RLVR training with PPO/GRPO-style clipping. The following applications can be deployed now with existing tooling and workflows.
- Entropy-controlled RLVR training in industry ML pipelines (software/AI)
- Use case: Prevent entropy collapse while fine-tuning reasoning LLMs for math, code, and logic tasks by making
clip-lowmore aggressive and relaxing or disablingclip-high. - Workflow: Integrate an “entropy budget” controller that monitors token-level entropy and automatically schedules
epsilon_lowandepsilon_highto maintain a target entropy band. A robust starting point from the paper isepsilon_high = ∞(off) andepsilon_low ≈ 0.15–0.2for true-reward RLVR; for random/noisy rewards, decreaseepsilon_lowto increase entropy, but beware entropy explosion. - Tools/products: Plugins for verl/TRL or custom PPO/GRPO trainers; a dashboard tracking entropy, pass@k, and mean@k; alarms when entropy deviates from target; YAML recipes for clip scheduling.
- Assumptions/dependencies: PPO/GRPO-style clipped objectives are used; verifiable reward signals exist; training monitors compute per-token entropy and pass@k; sign conditions observed in the paper typically hold but must be validated per model/domain.
- Use case: Prevent entropy collapse while fine-tuning reasoning LLMs for math, code, and logic tasks by making
- Exploration-preserving RLVR for education/tutoring systems (education)
- Use case: Train math tutors and educational assistants to keep diverse solution paths (high pass@k) while maintaining accuracy (mean@k), by tuning clipping to avoid exploration collapse.
- Workflow: During RLVR on datasets like GSM8K or MATH, schedule
epsilon_lowto maintain entropy and retain multiple reasoning strategies, improving pass@k without degrading mean@k. - Tools/products: “Multi-solution reasoning” training profiles; curricula that progressively adjust clip parameters; evaluation suites reporting exploration metrics alongside accuracy.
- Assumptions/dependencies: Availability of verifiable labels or programmatic checkers; careful monitoring to prevent entropy explosion; sampling temperature and k-values calibrated to downstream UX.
- RLVR experiment auditing and reproducibility protocols (academia and industry)
- Use case: Standardize reporting of clipping hyperparameters, entropy trajectories, and pass@k vs. mean@k to avoid confounding from clipping-induced entropy changes.
- Workflow: Add a “random reward stress test” to detect spurious improvements driven by entropy minimization rather than true learning; publish entropy curves and clip schedules with all RLVR results.
- Tools/products: Benchmark templates; CI checks gating model release on entropy/reporting compliance; leaderboards that include exploration metrics.
- Assumptions/dependencies: Consensus on reporting standards; ability to run controlled ablations (e.g.,
epsilon_highoff vs. on); adoption across labs and vendors.
- Robust RL under noisy/spurious rewards (software/AI)
- Use case: When reward signals are weak/noisy, use clipping controls to avoid unintended entropy collapse or explosion and maintain a useful exploration profile.
- Workflow: Run ablations with symmetric vs. asymmetric clipping to understand entropy dynamics; set clip schedules that avoid “random-reward gains” being just distribution sharpening.
- Tools/products: Automated “reward quality triage” that pairs entropy probes with reward diagnostics.
- Assumptions/dependencies: Access to reward validation; enough compute to run ablations; recognition that improvements under random rewards may be driven by entropy biases.
- MLOps monitoring of entropy as a first-class training KPI (software/AI)
- Use case: Track entropy alongside KL, accuracy, and pass@k to ensure exploration is preserved in production RLVR runs.
- Workflow: Define target entropy bands per task/model family; auto-adjust clipping or halt training if entropy collapses or explodes.
- Tools/products: Training dashboards; alerting; entropy-band controllers integrated with optimizer hyperparameter schedulers.
- Assumptions/dependencies: Metric plumbing for entropy and exploration; governance to gate deployments on exploration health.
- Policy and governance guidance for RLHF/RLVR disclosures (policy/regulation)
- Use case: Require disclosure of clipping hyperparameters, entropy curves, and exploration metrics to reduce misinterpretation of RLVR gains.
- Workflow: Update organizational or regulatory documentation to include “clipping and entropy reporting” in model cards and eval reports.
- Tools/products: Reporting templates; audit checklists; compliance playbooks.
- Assumptions/dependencies: Organizational buy-in; mapping to existing AI act or internal governance frameworks; alignment with reproducibility norms.
- Enhanced inference workflows using pass@k awareness (daily life/consumer AI)
- Use case: For consumer assistants that frequently solve math/logic tasks, encourage multi-sample solutions (e.g., k=8–32) where training has preserved diversity, improving the likelihood of at least one correct answer.
- Workflow: Expose “multi-solution mode” in apps; internally couple it with entropy-preserving training profiles.
- Tools/products: Product feature toggles; UI cues explaining pass@k; server-side sampling policies aligned with training-time entropy targets.
- Assumptions/dependencies: Inference cost budgets; UX acceptance of multi-sample solutions; reliable verification of answers for selection.
Long-Term Applications
These opportunities extend the core insight—clip-low increases entropy and clip-high decreases it—into new algorithms, domains, and governance structures. They require further research, scaling, or development.
- Adaptive “entropy governor” algorithms beyond clipping (software/AI, robotics)
- Use case: Replace fixed clipping with controllers that target a desired entropy range across states, using feedback from exploration metrics and trust-region constraints.
- Product/workflow: New PPO/GRPO variants with entropy targets (thermostat-like control); extensions to natural policy gradients; open-source “ClipEntropyControl” libraries.
- Dependencies: Stronger theory under general rewards and model architectures; stability proofs; broad validation across tasks and model families.
- Safety-aware entropy control for high-stakes domains (healthcare, finance, legal)
- Use case: Balance exploration (e.g., differential diagnoses, strategy search) with safety in domains where mistakes are costly by coupling entropy control with gated verifiable rewards and robust filters.
- Product/workflow: RLVR pipelines that use clinical/financial validators, uncertainty quantification, and entropy monitors; structured pass@k selection with human-in-the-loop.
- Dependencies: High-quality verifiers; domain-specific reward design; regulatory approvals; calibrated risk management.
- Standards for exploration metrics in RLHF/RLVR benchmarking (academia, policy, industry consortia)
- Use case: Establish shared benchmarks and leaderboards that track pass@k, mean@k, entropy trajectories, and clip schedules to compare models fairly across labs.
- Product/workflow: Consortium-led specifications; official “exploration boundary” metrics; certification programs for reproducible RLVR claims.
- Dependencies: Community consensus; funding; ongoing maintenance of datasets and evaluators.
- Curriculum and phase scheduling for entropy across training (software/AI, education)
- Use case: Design curricula that modulate entropy—early exploration via aggressive
clip-low, later exploitation via reintroducingclip-highor KL regularization—to maximize final performance. - Product/workflow: Phase-based RLVR schedulers; automated curriculum search integrating entropy targets.
- Dependencies: Large-scale experiments to map entropy-performance trade-offs; task-specific schedules; compute budgets.
- Use case: Design curricula that modulate entropy—early exploration via aggressive
- Cross-domain application to embodied agents and planning (robotics, operations, energy)
- Use case: Apply entropy control to LLM-augmented planners for robotics, grid planning, or operations research, improving exploration without destabilizing policies.
- Product/workflow: Hybrid symbolic–LLM planners with RLVR post-training; entropy-aware trust-region updates in simulators.
- Dependencies: Reliable simulators and verifiers; methods to translate token-level entropy to action-space entropy in non-text policies.
- User-facing “exploration tier” model releases (software/AI)
- Use case: Offer model variants trained with different entropy profiles (e.g., conservative, balanced, exploratory) for diverse application needs.
- Product/workflow: Release management with documented entropy profiles; guidance on pairing variants with inference settings (temperature, k).
- Dependencies: Repeatable training recipes; clear UX guidelines; monitoring of downstream impacts (e.g., hallucination rates).
- Entropy-aware reward shaping and multi-objective RL (software/AI)
- Use case: Combine verifiable rewards with entropy objectives to jointly optimize accuracy and exploration according to task needs.
- Product/workflow: Multi-objective optimization frameworks; policy-level regularizers that target exploration diversity.
- Dependencies: Theoretical guarantees for stability and convergence; empirical maps of trade-offs across diverse tasks.
- Auditable separation of algorithmic biases from reward informativeness (policy, governance, academia)
- Use case: Mandate tests that distinguish reward-driven learning from clipping-induced entropy effects (e.g., random-reward controls).
- Product/workflow: Audit protocols in model cards; external certification; reproducibility checklists.
- Dependencies: Adoption by publishers, conferences, and regulators; tooling to automate audits; community education.
- Educational AI that systematically exposes multiple reasoning paths (education)
- Use case: Train tutors to present alternative solutions calibrated by entropy-preserving RLVR, fostering conceptual understanding rather than single-path memorization.
- Product/workflow: Classroom tools that sample diverse chains-of-thought; analytics to measure student learning gains with exploration-heavy tutors.
- Dependencies: Longitudinal studies; integration with curricula; robust checking of solution correctness.
- Metrics and theory for “reasoning boundary” and exploration quality (academia)
- Use case: Formalize and measure how clipping and entropy affect the set of accessible reasoning trajectories; relate to pass@k dynamics.
- Product/workflow: New theoretical frameworks; empirical benchmarks; diagnostic probes for minority-token dynamics.
- Dependencies: Deeper analysis beyond toy settings; broader datasets; shared evaluation infrastructure.
Notes on feasibility across all applications:
- The core mechanism relies on PPO/GRPO-style clipping; results may differ for algorithms without clipped ratios.
- The paper’s sign conditions generally hold empirically but should be verified per model/domain.
- Entropy explosion is a real risk; any deployment should include guardrails and automated monitors.
- Gains observed with random rewards often reflect entropy minimization rather than true learning; run controls to avoid overclaiming.
Collections
Sign up for free to add this paper to one or more collections.