- The paper introduces entropy refinement by decomposing policy entropy into informative and spurious components to better guide exploration.
- It presents the AsymGRPO algorithm which applies bidirectional modulation—preserving successful rollouts and suppressing failures—to improve reasoning benchmarks.
- Experimental results show targeted entropy control outperforms standard methods with up to 2.86% accuracy gains and enhanced training stability.
Rethinking Exploration in RLVR: From Entropy Regularization to Refinement via Bidirectional Entropy Modulation
Overview
The paper "Rethinking Exploration in RLVR: From Entropy Regularization to Refinement via Bidirectional Entropy Modulation" (2604.04894) presents a critical analysis of entropy dynamics in Reinforcement Learning with Verifiable Rewards (RLVR) for LLMs. Standard entropy regularization strategies, the main vehicle for exploration in RL, are shown to yield only unreliable or marginal benefits in the RLVR setting, hampered by high sensitivity and lack of targeted effect on model policy. The paper decomposes the role of entropy into "informative" and "spurious" components, motivating the principle of entropy refinement: specifically, the goal is not blind entropy maximization, but the targeted preservation of solution diversity (informative entropy) while suppressing policy noise that does not contribute to functional exploration (spurious entropy). This conceptual advance is operationalized through the Asymmetric Group-Relative Policy Optimization (AsymGRPO) algorithm, which introduces tunable bidirectional control over entropy induced respectively by positive (successful) and negative (failed) rollouts.
Decomposition of Policy Entropy and RLVR Limitations
RLVR has proven valuable for reasoning tasks, mitigating reward hacking by leveraging programmatic verifiable rewards. However, restricted exploration, manifesting as rapid entropy collapse and premature performance plateaus, persists as a core limitation. Empirical evidence shows that global entropy regularization is ill-suited to the high-dimensional, long-horizon generative policies inherent to LLMs. Blind entropy inflation can introduce policy degeneracy, resulting in semantically uninformative and brittle policies.
To understand this, the paper presents a formal decomposition of policy entropy into two categories:
- Informative Entropy: Diversity in solution strategies that expands the model’s capacity for effective exploration and generalization.
- Spurious Entropy: Unstructured randomness that does not support learning and undermines coherent reasoning trajectories.
This taxonomy grounds an analysis of RLVR exploration failures and motivates entropy refinement, a mechanism for preserving only beneficial diversity in rollout generation.
Mechanistic Analysis of Advantage Estimation
The Group-Relative Policy Optimization (GRPO) framework provides the foundation for entropy refinement. Unlike value-based advantage estimates, GRPO leverages group statistics (empirical mean and variance of rewards over multiple rollouts per prompt) to compute advantages. The central insight is that the scaling and direction of the advantage signal can be decoupled for positive and negative samples, using a parametric family A(β)(p) where p is group-level accuracy:
For positive rollouts:
Apos(β)(p)=(p1−p)β
For negative rollouts:
Aneg(β)(p)=−(1−pp)β
Here, higher p implies greater in-group success and vice versa; β adjusts the sensitivity. This reweighting modulates the gradient dynamics, yielding a bidirectional effect on entropy: increased favorable entropy on success, targeted entropy suppression on failure.
Empirical analyses of group covariance between the policy log-probability and the advantage signal corroborate that group-relative estimation induces entropy dynamics that are robust to the natural tendencies of policy collapse or unproductive entropy growth.
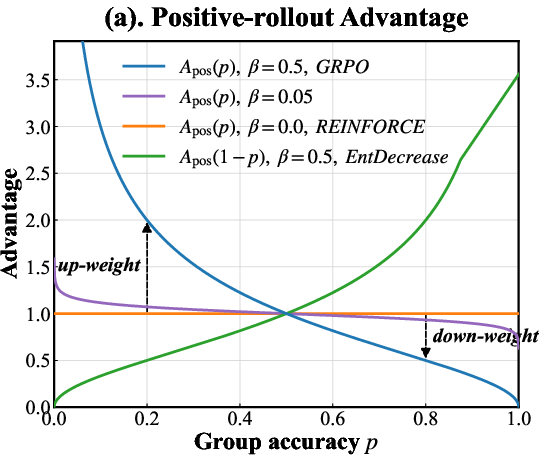
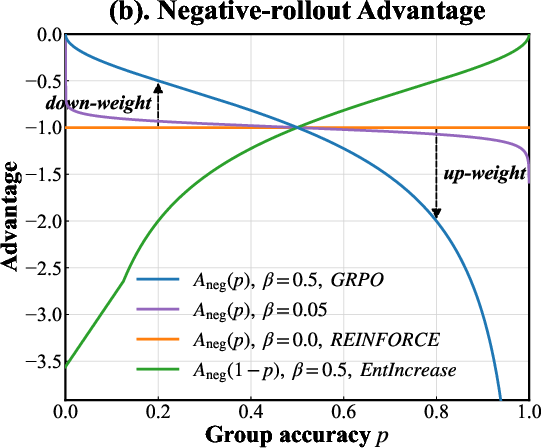
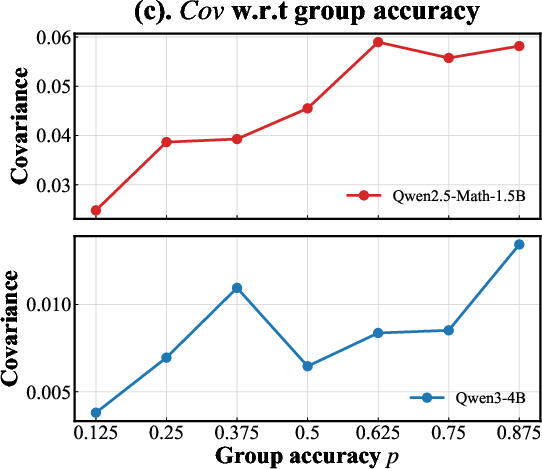
Figure 1: (a) Positive advantage increases with group accuracy for successful rollouts; (b) negative advantage diverges for failures as group accuracy increases; (c) sample covariance—quantifying entropy change—grows with group accuracy, indicating natural entropy reduction trends counteracted by GRPO's bidirectional weights.
Extensive experiments using Qwen2.5-Math-1.5B and Qwen3-4B illustrate that selective modulation of entropy via the GRPO parametrization yields distinct and measurable effects compared to standard baselines.
- Pos-Only Modulation (βpos>0, βneg=0): Sustains policy entropy, retards overconfidence and entropy collapse, leading to improved validation accuracy especially on previously unsolved queries.
- Neg-Only Modulation (βpos=0, βneg>0): Accentuates entropy decay for failed rollouts, reducing spurious noise without harming the exploration budget, yielding significant accuracy improvements.
- Standard Entropy Regularization: Consistently fails to deliver accuracy gains comparable to refined GRPO variants, despite achieving higher overall entropy.
Mechanistic ablation shows that informative entropy sustains exploration at the expanding boundary of solvable queries (reduction in "none-solved" group rates), while spurious entropy pruning mitigates negative gradient interference during unsuccessful rollouts, directly boosting the effective probability mass assigned to successful reasoning chains.
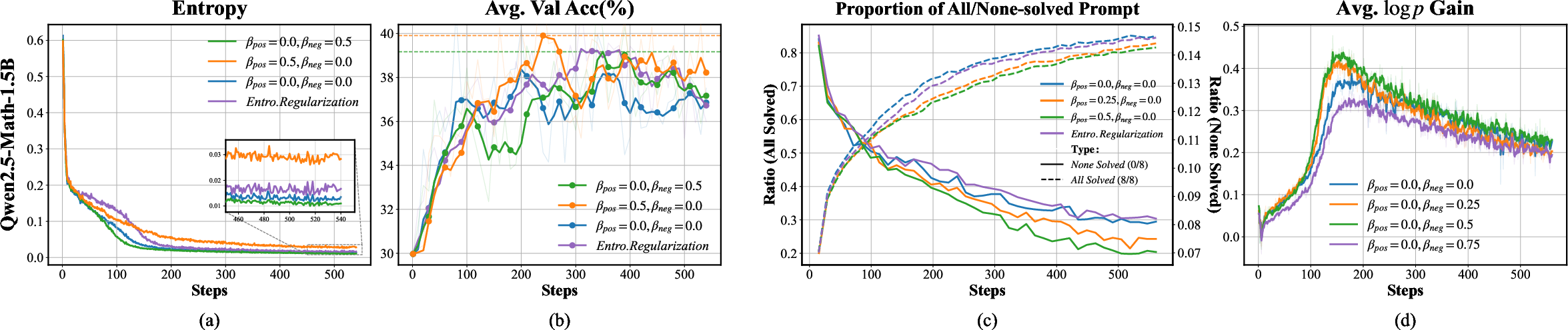
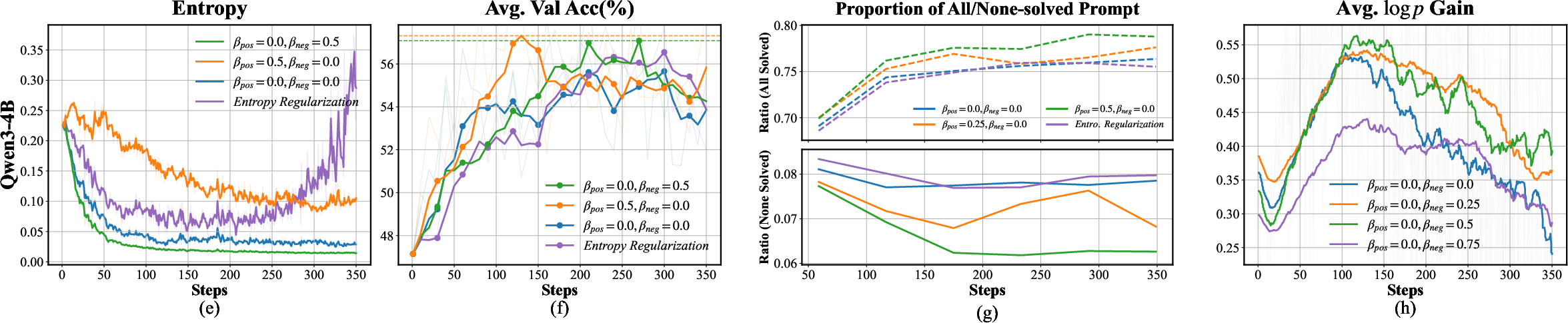
Figure 2: (a,e) Policy entropy evolution; (b,f) validation accuracy; (c,g) prompt composition statistics ("all-solved"/"none-solved"); (d,h) log-probability increment on positive samples—across Qwen2.5-Math-1.5B and Qwen3-4B.
Further, adversarial "entropy flipping" experiments confirm the necessity of directional entropy modulation: suppressing entropy on positive rollouts or inflating it on negative rollouts degrades generalization and destabilizes training, illustrating the nontrivial risk profile of naïve entropy-centric interventions.
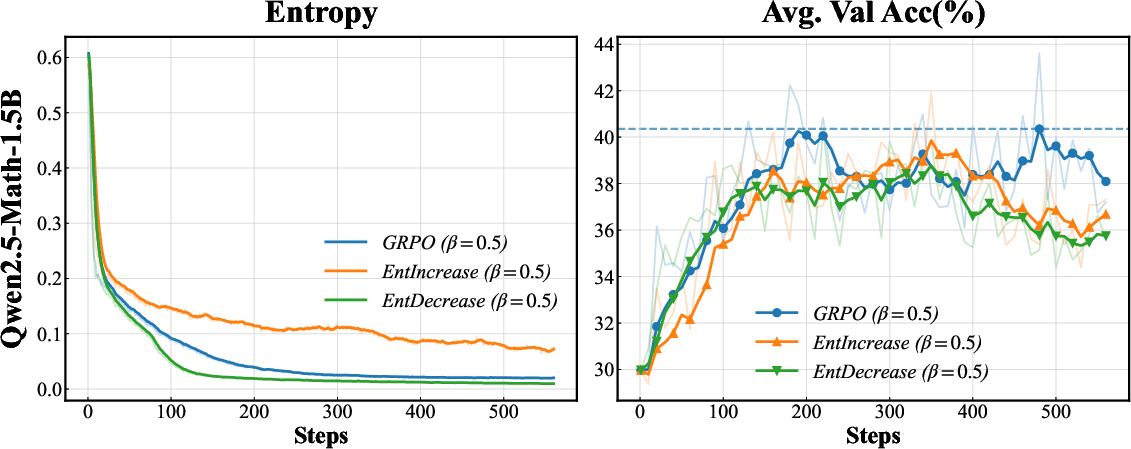
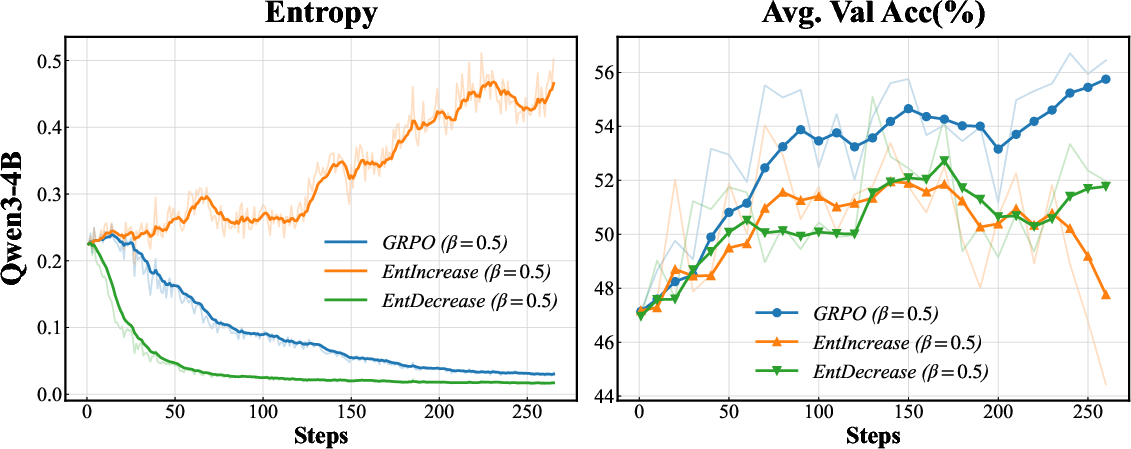
Figure 3: Entropy flipping experiments demonstrate that strategic bidirectional entropy modulation is critical for maintaining accuracy and stable training dynamics.
Asymmetric Group-Relative Policy Optimization (AsymGRPO)
Building on these insights, AsymGRPO is introduced, operationalizing targetable, decoupled entropy modulation via independent hyperparameters p0 and p1. This allows differential scaling of entropy preservation (on verified successes) and entropy pruning (on failures), optimizing the exploration–exploitation trade-off in RLVR. The policy gradient is correspondingly decomposed to enable this bidirectional control explicitly.
Main empirical evaluations on rigorous mathematical reasoning benchmarks exhibit a clear performance advantage. AsymGRPO achieves up to 2.86% higher average accuracy over standard GRPO, and consistently outperforms the strongest existing entropy-oriented methods (e.g., "Clip-higher", Dr.GRPO):
- AsymGRPO with optimally tuned modulation achieves the highest average benchmark score (59.36%), and when combined with the "Clip-higher" method reaches 60.32% accuracy.
- These gains are achieved without inflating overall entropy, substantiating that improved exploration comes from entropy refinement rather than indiscriminate entropy maximization.
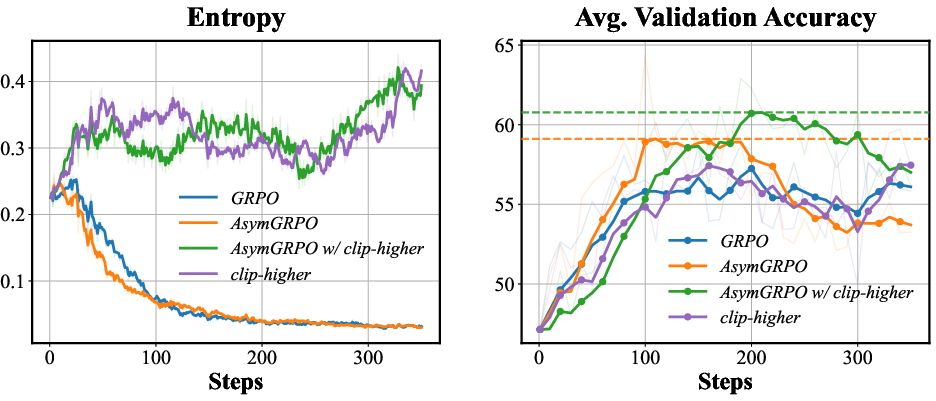
Figure 4: Entropy dynamics and validation accuracy under main variants show that targeted entropy refinement supports stable, high-performance training.
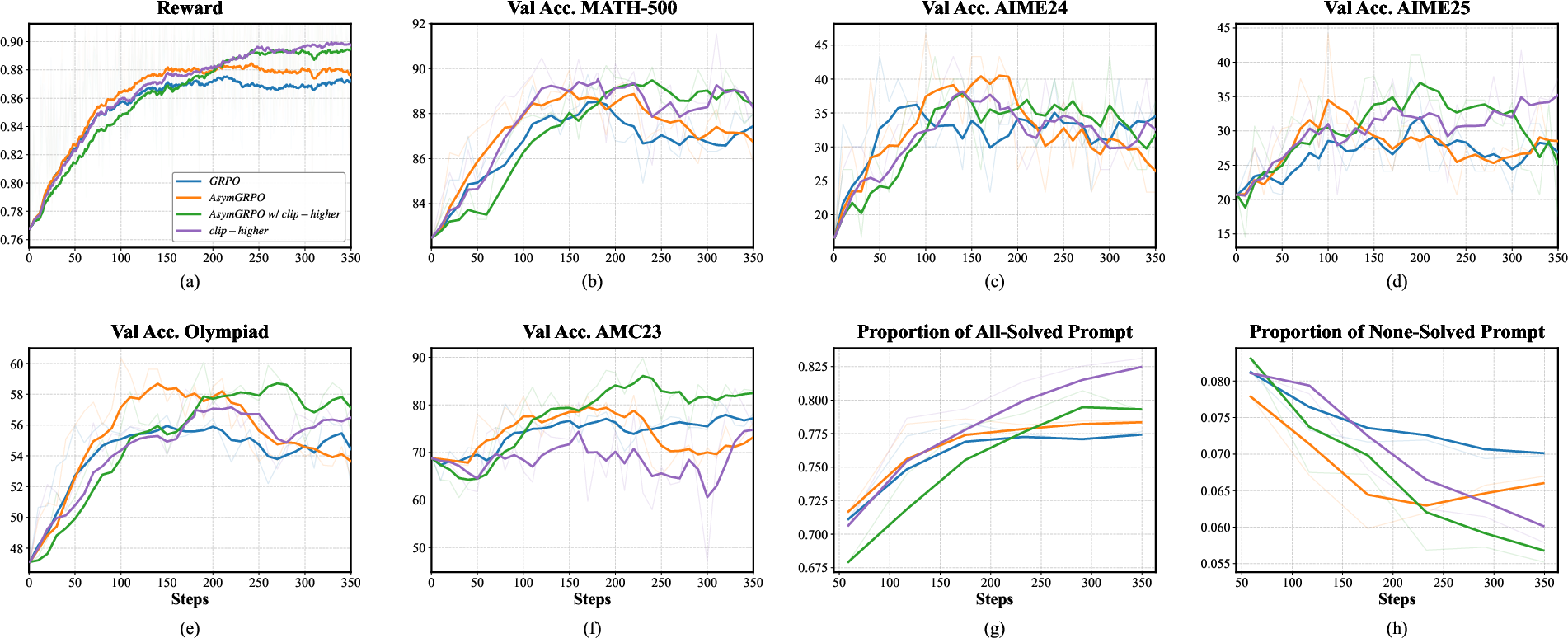
Figure 5: Detailed training and validation metrics across multiple mathematical reasoning benchmarks further validate the robustness and generality of AsymGRPO.
Implications and Future Directions
The theoretical and experimental analysis challenges the dominant notion that uniform entropy maximization is optimal for RL-based LLM post-training. Instead, it demonstrates that effective reasoning improvement requires discriminative, parametrized entropy management. Practically, AsymGRPO provides a tool for robustly scaling mathematical and logical reasoning skills in LLMs while avoiding unproductive exploration and model collapse.
Theoretically, the decomposition of policy entropy and mechanistic understanding of advantage-coupled modulation open directions for:
- Designing more granular, context-aware entropy metrics at the rollout or token level.
- Developing adaptive or automated modulation intensity schedules to optimize training across different domains and over time.
- Synergistically integrating selective entropy modulation with other forms of structured exploration, e.g., uncertainty-aware advantage shaping.
Conclusion
By dissecting the role and structure of policy entropy in RLVR, this study demonstrates that targeted entropy refinement—rather than blind regularization—is essential for scaling complex reasoning in LLMs. AsymGRPO enables independent, bidirectional entropy control, leveraging group-relative advantages to sustain productive solution diversity while eliminating detrimental policy noise. The implications extend to both robust deployment of RLVR for high-stakes reasoning and the theoretical understanding of optimization landscapes in large generative models.