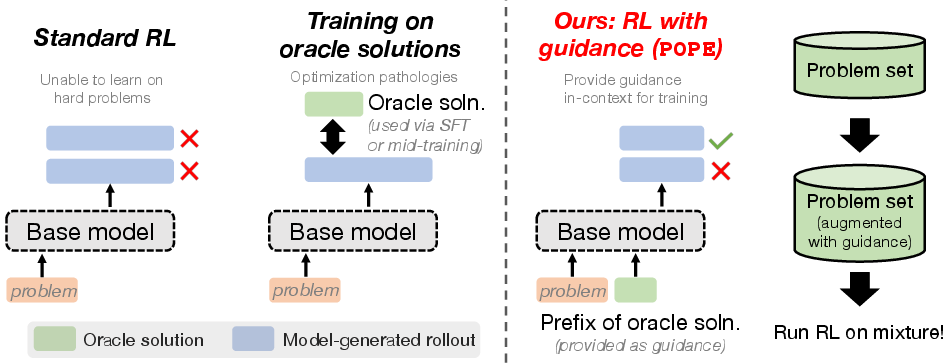
POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration
Abstract: Reinforcement learning (RL) has improved the reasoning abilities of LLMs, yet state-of-the-art methods still fail to learn on many training problems. On hard problems, on-policy RL rarely explores even a single correct rollout, yielding zero reward and no learning signal for driving improvement. We find that natural solutions to remedy this exploration problem from classical RL, such as entropy bonuses, more permissive clipping of the importance ratio, or direct optimization of pass@k objectives, do not resolve this issue and often destabilize optimization without improving solvability. A natural alternative is to leverage transfer from easier problems. However, we show that mixing easy and hard problems during RL training is counterproductive due to ray interference, where optimization focuses on already-solvable problems in a way that actively inhibits progress on harder ones. To address this challenge, we introduce Privileged On-Policy Exploration (POPE), an approach that leverages human- or other oracle solutions as privileged information to guide exploration on hard problems, unlike methods that use oracle solutions as training targets (e.g., off-policy RL methods or warmstarting from SFT). POPE augments hard problems with prefixes of oracle solutions, enabling RL to obtain non-zero rewards during guided rollouts. Crucially, the resulting behaviors transfer back to the original, unguided problems through a synergy between instruction-following and reasoning. Empirically, POPE expands the set of solvable problems and substantially improves performance on challenging reasoning benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs to solve tough math and coding problems using reinforcement learning (RL). The authors noticed that when problems are hard, standard RL training often gets “stuck” because the model never stumbles on a correct answer during training, so it receives no feedback to get better. Their new method, called POPE (Privileged On-Policy Exploration), helps the model explore better by giving it a short, human-written hint at the start of training rollouts—without forcing the model to copy the human solution. This guidance lets the model find at least one correct path, learn from it, and then transfer what it learned back to solving the original problem without any hints.
Goals and Questions
The paper asks simple questions that matter for training smarter models:
- Why does standard RL fail on hard problems?
- Can common tricks (like making the model more random or mixing easy problems with hard ones) fix this?
- If not, how do we get the model to explore the right ideas on hard problems?
- Can short human hints help the model learn to solve the hard problems on its own later?
Methods and Approach
To make the ideas clear, here’s some everyday language and analogies:
Background: Why normal RL struggles
- RL works a bit like practicing a sport: you try, and if something works, you repeat it more. But on very hard tasks, the model’s “tries” almost never succeed, so it gets zero reward and no clue what to repeat. Training just stalls.
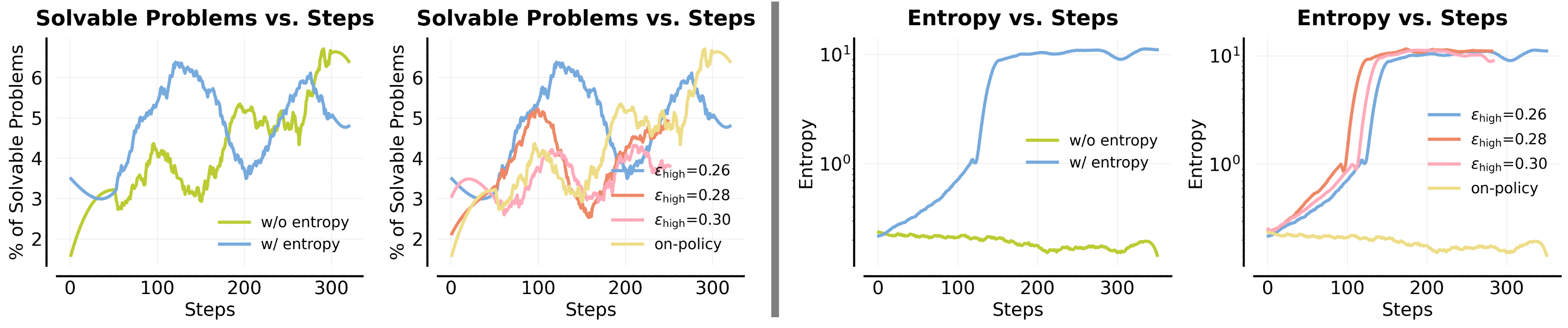
- Common fixes from RL:
- Entropy bonus (making the model more random): Imagine wildly changing strategies every turn. The model becomes chaotic and less confident, which often makes training worse.
- Looser clipping (letting bigger updates happen on rare good attempts): This can blow up uncertainty too, making the model’s next-word choices unstable.
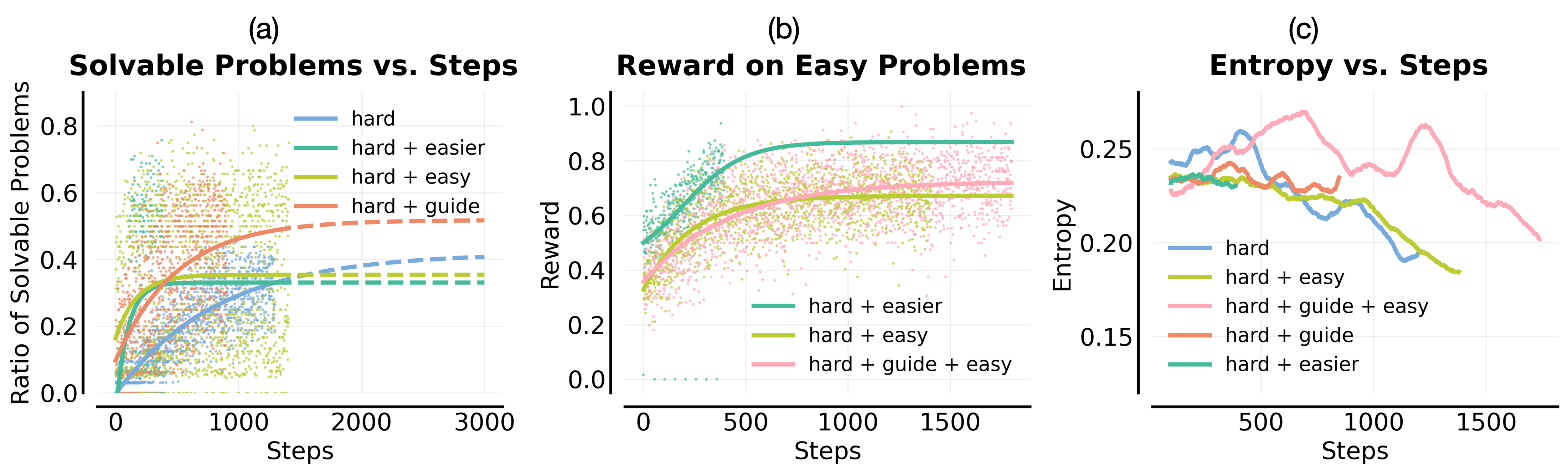
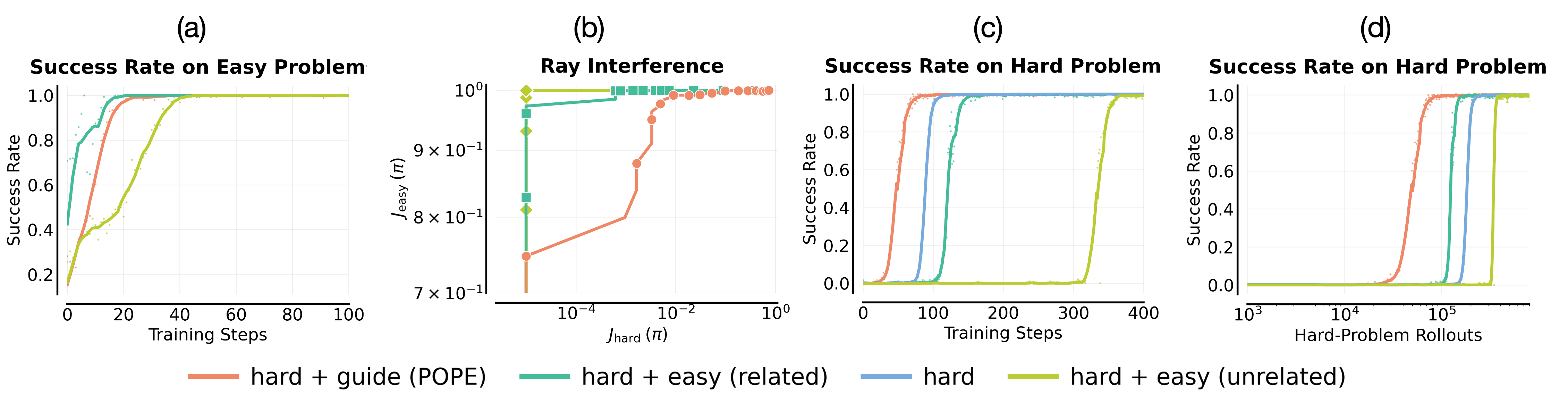
- Mixing easy and hard problems: Like studying algebra and calculus together. In practice, the model focuses on the easy wins and ignores the hard ones. This is called “ray interference”: training gets pulled toward what’s already working, slowing progress on what’s not.
- Directly optimizing “pass@k” (the chance that at least one of k tries works): This can reduce over-focusing on a single solution style, but it doesn’t help when the model almost never gets a correct attempt in the first place.
POPE: The new approach
Instead of making the model imitate human solutions, POPE uses a short prefix of a human (or oracle) solution as guidance during training rollouts:
- Think of it like giving the model a nudge in the right direction—just enough of a hint to get it into the “good part” of the solution space where it can actually learn from successes.
- The model is instructed to continue from the hint, not to copy it. Training remains on-policy (the model generates its own words), but the starting point is guided.
- The team chooses the shortest helpful prefix per problem: the smallest hint that makes it possible for the model to get at least one correct solution during sampling.
- They train on a balanced mix of:
- Unguided hard problems (no hint)
- Guided versions of those hard problems (with the short hint)
- Optionally, some easier problems
Why this transfers back: Long reasoning answers often include self-checking and backtracking. These behaviors help the model “stitch” together what it learned under guidance with the unguided starting point. So, after training with the guided rollouts, the model can apply similar steps on its own when no hint is present.
Main Findings and Why They Matter
Here are the most important results:
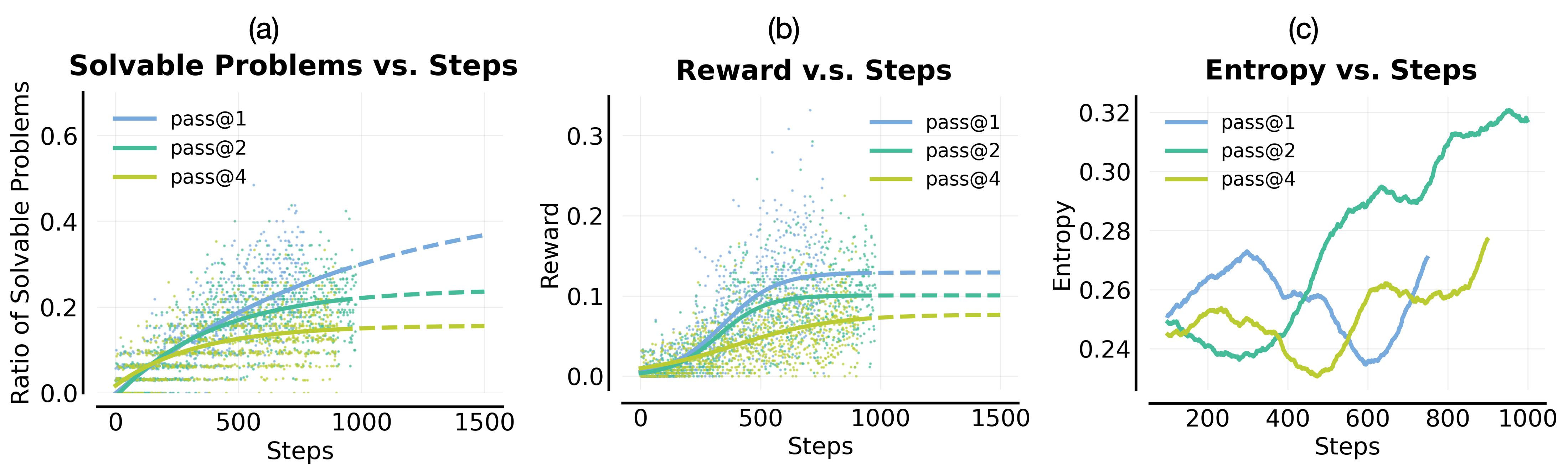
- Standard RL struggles on hard problems. Tricks like making the model more random or mixing easy tasks don’t fix it and often hurt training stability.
- POPE increases the number of hard problems the model can solve. On a tough training set, it solved about 10% more problems (measured with pass@16), even with heavy sampling (64 attempts and long outputs).
- POPE improves real benchmarks. On math contests like AIME 2025 and HMMT 2025:
- Pass@1 improved up to 58% (from 48% for the base model).
- Pass@16 improved up to 83% (from 77%).
- Guided learning helps the model learn “how to continue” good solution paths and then reuse those ideas without guidance. This shows strong transfer from guided to unguided solving.
These findings matter because they show a reliable way to unlock hard problems that RL normally gives up on, without needing the model to memorize full human solutions.
Implications and Impact
- Better training on genuinely hard problems: POPE helps models get the first successful trace needed for learning, so they stop stalling and start improving.
- Efficient use of human effort: You only need short, strategic hints (prefixes), not full worked solutions for everything. This lowers cost and still delivers big gains.
- More stable training: Instead of making the model randomly explore (which can destabilize it), POPE guides it to useful areas while keeping training on-policy.
- Broad potential: This idea could be applied to other domains (like coding or logic puzzles) where finding any correct rollout is rare.
In short, POPE is a practical way to teach models to reason through hard problems: help them explore with smart hints, let them learn the continuation, and watch those skills transfer back to solving without hints.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized to help future researchers target concrete follow-ups.
Data and guidance design
- Reliance on oracle solutions: scalability and practicality remain unclear when human or high-quality oracle solutions are scarce, expensive, or unavailable for large training corpora.
- Quality robustness: the impact of noisy, partially incorrect, stylistically mismatched, or low-quality guidance on learning and transfer is not analyzed; methods for filtering or denoising guidance are undeveloped.
- Guidance format: the paper uses solution prefixes; it remains open whether other privileged signals (hints, lemmas, decompositions, sketches, unit tests for code, solution outlines) are more cost-effective or yield better transfer.
- Prefix selection: prefix length is chosen via a coarse heuristic; there is no study of adaptive or learned prefix selection policies, nor analysis of sensitivity to prefix length, content, and placement.
- Multiple segments: the effect of using multiple short guidance segments or varied positions within a solution (rather than a single fixed prefix) on coverage and transfer is untested.
- Automated guidance: strategies to automatically generate privileged guidance (e.g., via stronger models, retrieval from solution banks, programmatic solvers) and their trade-offs in cost, quality, and bias are not explored.
Algorithmic and theoretical questions
- Formal guarantees: the paper provides a “stitching/overlap” mental model without theoretical analysis; conditions under which POPE guarantees transfer to unguided problems remain unproven.
- State overlap measurement: there is no quantitative metric for overlap between guided and unguided trajectories (e.g., representation similarity, trajectory edit distance, revisitation statistics); developing such metrics could validate the mechanism.
- Backtracking and reflection: claims that self-verification/backtracking aid transfer are not rigorously measured; methods to instrument and quantify these behaviors during training are missing.
- Mixture scheduling: the 1:1 guided–unguided mixture is fixed; optimal ratios, annealing schedules (reducing guidance over time), or adaptive curriculum policies are not studied.
- Sample efficiency: the minimal number/fraction of guided rollouts needed to achieve transfer (and the scaling behavior with model size/problem hardness) is unknown.
- Robustness of on-policy updates: potential bias or instability introduced by mixing off-policy states (guided prompts) with on-policy actions is not analyzed; a principled framework tying POPE to off-policy RL theory is missing.
- RL objective design: the paper shows entropy bonuses and higher clip ratios destabilize training, but does not propose or analyze alternative safe exploration bonuses/objectives tailored to LLMs.
- Value learning and credit assignment: POPE is evaluated with outcome-only rewards; the effect of integrating step-level rewards, learned reward models, or actor–critic/value functions on exploration and transfer is unexplored.
- Pass@k optimization: the negative result for direct pass@k optimization raises an open question of whether modified objectives (e.g., reward-gap preserving or correctness-weighted diversity) can improve solvability without entropy explosion.
- Interference mitigation: ray interference is observed but not formally characterized; the effectiveness of prioritized sampling, task-level anti-interference methods, or multi-task decoupling strategies remains untested.
- Hierarchical RL framing: viewing guidance as an “option” (subpolicy) suggests hierarchical RL avenues (learning to reach and then execute from “good states”); these formulations and algorithms are not explored.
- Generality across RL algorithms: POPE is tested with GRPO; behavior under other RL recipes (e.g., PPO with KL, actor–critic, Q-learning with sequence-level rewards, value bootstrapping) is unknown.
Generalization, evaluation, and compute
- Domain coverage: experiments focus on math reasoning; applicability to coding, logic puzzles, scientific QA, multi-hop retrieval, and multilingual settings is not established.
- Model scaling: results use Qwen3-4B-Instruct; dependency on model size, family, and instruction-following capability is not quantified; whether stronger base models reduce POPE’s benefits is unknown.
- Hardness spectrum: the approach targets “very hard” problems; performance across a graded hardness spectrum (and where guidance ceases being useful or becomes counterproductive) is not mapped.
- Compute and budget sensitivity: training/evaluation use long token budgets (up to 32k) and many rollouts; the efficacy under limited compute (shorter budgets, fewer rollouts) and sample-efficient variants is untested.
- Long-horizon stability: whether gains persist or degrade over extended training (e.g., catastrophic forgetting, overfitting to guided states, entropy drift) is not reported.
- Diversity of solutions: guidance may bias solutions toward a single approach; the effect on solution-path diversity, pass@k diversity, and robustness to alternative solution styles is unmeasured.
- Benchmark breadth: comparisons to strong baselines (curriculum learning, prioritized replay, retrieval-augmented RL, self-play, tool-use) across multiple standardized benchmarks are limited.
- Reproducibility and sensitivity: systematic ablations of hyperparameters (clip thresholds, advantage normalization, guidance frequency, instruction wording) and their variance across seeds are incomplete.
Safety, ethics, and deployment
- Guidance provenance: sourcing human-written solutions raises licensing, privacy, and data governance questions; guidelines and safeguards are not specified.
- Misleading/adversarial guidance: the method’s resilience to adversarial or subtly incorrect guidance (and detection/mitigation mechanisms) is unknown.
- Leakage and reliance: risk that models over-rely on guided scaffolds or memorize privileged content (data leakage) is not evaluated; mechanisms to prevent dependence on guidance at test time are undeveloped.
- Capability side-effects: impacts on non-reasoning capabilities, calibration, safety, or alignment (e.g., increased verbosity, hallucination under guidance cues) are not assessed.
- Deployment practicality: the cost/benefit analysis of acquiring and integrating guidance into large-scale RL pipelines (including retrieval, curation, and scheduling) is missing.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now by leveraging POPE’s core idea—using short, oracle (human or system) prefixes to guide on-policy exploration—together with the paper’s empirical insights on what not to do (e.g., avoid entropy bonuses or pass@k-only optimization) and how to monitor training (e.g., solvability/pass@k, entropy).
- Math and coding LLM fine-tuning with guided exploration (sectors: education, software) — Use POPE to RL-train small/midsize LLMs on hard math/coding sets by conditioning on short prefixes of trusted solutions (textbook snippets, community solutions, passing code fragments) and mixing guided and unguided versions during RL; expect higher pass@k on difficult items with stable optimization. — Tools/workflows: “POPE Trainer” for GRPO/PPO-style on-policy RL; “Prefix Selector” that picks shortest prefix yielding success once under the base model; reward harnesses (answer checkers, unit tests). — Assumptions/dependencies: Automatic reward checkers (e.g., unit tests, exact-answer parsers); instruction-following base model with long context; lawful access to solution data; compute budget for on-policy RL.
- Upgrade unit-test-driven code assistants via guided RL (sector: software) — Treat minimal passing diffs, failing stack traces, or partial patches as privileged prefixes; instruct the model to continue to a fully passing solution; train on a guided/unguided mix with unit-test reward. — Tools/workflows: CI-integrated RL loop; “Patch-as-Prefix” miner from code review logs; entropy/solvability dashboards to avoid collapse. — Assumptions/dependencies: High-quality test suites; de-duplication and license-compliant mining of code diffs; model can follow “continue from here” instructions.
- “Hint-driven” tutoring systems that learn to solve hard items (sector: education) — RL-train tutors to complete problems given short, teacher-authored hints; at inference, tutors can solve more problems from scratch and produce better step-by-step reasoning. — Tools/workflows: “HintBank” (short hints mined from teacher solutions); evaluation via pass@k solvability and learning gains per student concept. — Assumptions/dependencies: Reliable correctness checks (symbolic math solvers, rubric checkers); consented access to teacher materials; safeguards for CoT exposure aligned with institutional policies.
- SOP- and KB-grounded enterprise assistants (sectors: operations, customer support) — Use first steps of standard operating procedures or knowledge-base intros as prefixes; RL-train the assistant to complete multi-step resolutions correctly (ticket triage → diagnostics → fix). — Tools/workflows: “SOP Prefix Miner” from internal docs; resolution verifiers (policy conformance checks, workflow simulators). — Assumptions/dependencies: Internal policy checkers to define reward; careful handling of proprietary data; strong instruction following.
- Safer, more stable RL post-training playbooks (sector: MLOps/platforms) — Replace entropy bonuses and aggressive clip-ratio heuristics with POPE; monitor pass@k solvability, entropy, and ray interference to maintain stability and coverage on hard tasks. — Tools/workflows: “Ray Interference Monitor” (plots easy vs. hard reward trajectories); “Solvability Tracker” (per-item pass@k under long token budgets); default POPE system prompts. — Assumptions/dependencies: Ability to run long rollouts during evaluation (to avoid length-capped artifacts); logging infrastructure.
- Cost-effective human-in-the-loop data collection (sectors: data operations, research) — Collect short prefixes (first key step or plan sketch) instead of full solutions; POPE converts these inexpensive hints into exploration signal that improves unguided performance. — Tools/workflows: “Prefix Labeling UI” for SMEs; quality gates that confirm a prefix enables at least one success in base model sampling. — Assumptions/dependencies: Human time is limited—optimize for minimal prefixes; QA loops to prevent information leakage or overfitting.
- Legal/compliance and policy QA assistants (sectors: legal, governance) — Seed with partial citations or compliance checklists; RL-train to complete analyses consistent with regulations; rewards via static analyzers or expert audits on a sampled subset. — Tools/workflows: Checklist-to-Prefix converter; compliance conformance rules as weak reward. — Assumptions/dependencies: Imperfect reward models—needs human spot checks; regulatory text licensing.
- Research benchmarking and curriculum construction (sector: academia) — Build challenge sets with guided-unguided pairs; evaluate solvability gains and interference dynamics; share open “prefix+problem” corpora for reproducibility. — Tools/workflows: Benchmark curation with prefix-length sweeps; pass@k under varied budgets; ablations of prompt instructions (to test overlap/backtracking effects). — Assumptions/dependencies: Public data with clear licenses; standardized reward harnesses.
- Retrieval-as-guidance for reasoning-heavy QA (sectors: search, knowledge) — Use a single salient retrieved snippet as a “privileged” prefix to steer exploration during RL; train the model to stitch from snippet to final answer and later generalize without retrieval. — Tools/workflows: RAG-to-POPE bridge that converts a retrieved span into a continuation instruction; answer verifiers. — Assumptions/dependencies: Retrieval quality; copyright constraints on retrieved text; alignment between snippet and reward function.
- Personal study aids that leverage textbook partial solutions (sector: daily life/learning) — At inference, users paste a short excerpt of a worked example and instruct the model to complete a similar new problem; models trained with POPE transfer these patterns to unguided cases. — Tools/workflows: “Continue-from-hint” study prompts; local verification via CAS or code sandboxes. — Assumptions/dependencies: Access to worked examples; risk of over-reliance on hints—ensure progression to unguided practice.
Long-Term Applications
These directions require additional research, scaling, or domain adaptation (e.g., robust reward functions, safety validation, or multimodal integration), but follow directly from POPE’s mechanisms (guided roll-ins, stitching/overlap, interference-aware training).
- Automated theorem proving and formal program synthesis (sectors: software, academia) — Train with partial lemmas/proof sketches as prefixes; learn to complete proofs and later reproduce from scratch; integrate with proof checkers as reward. — Tools/products: “POPE-Prover” with Coq/Lean/Isabelle checkers; prefix mining from proof corpora. — Assumptions/dependencies: High-fidelity reward (proof checking); careful control of leakage from proofs to evaluation.
- Robotics and long-horizon planning with privileged roll-ins (sector: robotics) — Use short, expert partial plans as language prefixes to guide LLM planners; supervise with environment rewards; aim for transfer to unguided planning. — Tools/products: Plan-as-Prefix generators from demonstrations; sim-to-real stitching evaluators. — Assumptions/dependencies: Mapping text plans to executable policies; safety in real environments; reward credit assignment beyond text.
- Clinical decision support with protocol-guided exploration (sector: healthcare) — Seed reasoning with early protocol steps; learn to complete differential diagnosis or treatment plans; validate with retrospective outcomes and expert review. — Tools/products: Protocol Prefix Library; clinical reward estimators; human oversight portals. — Assumptions/dependencies: Safety, ethics, and regulatory approvals; robust evaluation; limited availability of gold feedback.
- Financial risk analysis and strategy evaluation (sector: finance) — Train with partial scenario setups (stress test parameters, known hedges) as guidance; learn to complete analyses and generalize. — Tools/products: Strategy Prefix Miner from research notes; backtesting reward harnesses. — Assumptions/dependencies: Noisy/indirect rewards; risk of spurious shortcuts; compliance constraints.
- Teacher–student multi-agent training via dynamic privileged guidance (sectors: platforms, research) — A stronger teacher generates adaptive prefixes; a student learns via POPE to solve from scratch; improves over static SFT distillation. — Tools/products: “Guidance Generator” agents; adaptive prefix scheduling policies (length, diversity, relatedness). — Assumptions/dependencies: Teacher cost and reliability; prevention of collapse into imitation; curriculum design.
- Retrieval-augmented RL that unifies RAG and POPE (sectors: search, enterprise knowledge) — Automatically extract and adapt prefixes from retrieval during training; learn stitching behaviors that later reduce retrieval dependence. — Tools/products: “Prefix-RAG Orchestrator” that tunes overlap/backtracking to maximize unguided transfer. — Assumptions/dependencies: Dynamic retrieval quality; copyright governance; long-context costs.
- Small-model uplift to near-large-model reasoning via guided RL (sectors: edge/mobile) — Use POPE to endow smaller models with hard-task competence learned from privileged guidance, narrowing the size–capability gap. — Tools/products: Edge-deployable POPE-trained models; mixed-precision RL toolchains. — Assumptions/dependencies: Sufficient instruction following in small models; compute budget for RL; domain-specific rewards.
- Automated curriculum and prefix selection policies (sector: MLOps/research) — Learn policies that pick prefix length/content to maximize solvability and overlap; detect and mitigate ray interference online. — Tools/products: “Interference-Aware Scheduler”; solvability-aware data sampler. — Assumptions/dependencies: Reliable online metrics; exploration–stability trade-offs; generalization across domains.
- Governance and data ecosystems for partial-solution sharing (sector: policy) — Establish licensing, privacy norms, and shared repositories for short prefixes/hints to power guided RL without distributing full solutions. — Tools/products: Public “HintBank” standards; audit trails for prefix provenance. — Assumptions/dependencies: Community adoption; IP and privacy frameworks; incentives for contributors.
- New RL objectives and theory for stitching/overlap (sector: research) — Formalize state-overlap in sequence models; design objectives that explicitly encourage stitchable continuations and discourage entropy explosion or unhelpful diversity. — Tools/products: Overlap-aware policy gradients; diagnostics beyond pass@k (e.g., guided–unguided mutual reachability). — Assumptions/dependencies: Scalable estimators of overlap; benchmarks that isolate stitching gains.
Notes on Key Assumptions and Dependencies
- Oracle guidance availability: Success depends on access to short, lawful prefixes (human-crafted, retrieved, or mined). The approach aims to minimize prefix length while retaining solvability.
- Automatic, faithful reward functions: Strong fit for domains with executable or checkable rewards (unit tests, proof checkers, exact-answer parsers, policy conformance). Weak or noisy rewards reduce gains.
- Model prerequisites: Good instruction following, long-context handling, and natural backtracking/self-verification behaviors are important for stitching/overlap.
- Training stability and monitoring: Avoid entropy bonuses and overly permissive clipping; track pass@k solvability and entropy; watch for ray interference when mixing tasks.
- Compliance and safety: Ensure licensing of solution sources; protect proprietary/regulated data; employ human oversight in high-stakes domains (healthcare, legal, finance).
- Compute and engineering: On-policy RL with long rollouts is compute-intensive; streaming/asynchronous implementations and careful batch design improve practicality.
Glossary
- Advantage: A normalized reward signal used in policy gradients, representing how much a rollout’s reward deviates from the batch mean. "where {A}(\mathbf{x}, \mathbf{y}) denotes the advantage estimate discussed above"
- Autoregressive MDP: A Markov decision process framing where the state is the entire sequence of tokens generated so far in an autoregressive model. "In an autoregressive MDP, a natural notion of state is the entire sequence of tokens produced so far."
- Backtracking: A reasoning behavior where the model revisits and revises earlier steps during generation. "Such models often self-verify, revisit earlier steps, and backtrack during generation"
- Chain-of-thought (CoT): Long, explicit reasoning traces produced by LLMs to solve problems. "longer chains of thought (CoT) can outperform much larger models"
- Clipped surrogate: A PPO-style objective that clips the policy ratio to stabilize training. "The GRPO loss uses a clipped surrogate similar to PPO"
- Clipping of the importance ratio: Restricting the policy probability ratio in PPO/GRPO updates to control variance and stabilize optimization. "more permissive clipping of the importance ratio"
- DAPO: A training recipe setting asymmetric clip thresholds to allow larger updates on positive samples. "DAPO~\citep{yu2025dapo} sets \epsilon_\text{high} > \epsilon_\text{low} to enable less conservative updates on positives"
- Dynamic sampling: A throughput-oriented heuristic that selectively samples data during training, often dropping hard instances. "Common throughput-oriented heuristics, such as dynamic sampling and zero-variance filtering, further discard these problems explicitly"
- Entropy bonus: An exploration incentive added to the objective to increase policy entropy. "we add an entropy bonus together with a KL penalty to the policy objective"
- Entropy explosion: Runaway growth of token-level entropy that destabilizes training. "This increase in entropy snowballs over training resulting in entropy explosion."
- Extrapolation: Leveraging skills learned on easier problems to solve harder ones by chaining strategies with more compute. "This idea is referred to as extrapolation~\citep{setlur2025e3learningexploreenables}"
- Function-approximation effect: An effect where shared model parameters cause interference or transfer across tasks in RL. "Ray interference is fundamentally a function-approximation effect in on-policy RL"
- GRPO: Group Relative Policy Optimization, an on-policy RL algorithm applied to LLMs. "We run a streaming, asynchronous implementation of GRPO ... as our RL training algorithm"
- Guidance: A short oracle-provided prefix appended to a problem to steer on-policy exploration. "we augment each hard problem with guidance in the form of a short prefix of an oracle solution"
- Importance-sampled policy gradient: A gradient estimator that reweights samples by the policy ratio to account for off-policy sampling. "when we use an importance-sampled policy gradient (Eq.~\ref{eq:grpo}) to train on rare positive traces"
- Instruction-following: The model’s ability to follow system prompts or directions to build upon provided content. "This effect is particularly pronounced when the base model has strong instruction-following capabilities"
- KL divergence: A regularizer measuring divergence from a reference policy, often used to stabilize RL fine-tuning. "without any entropy and KL divergence terms as default"
- KL penalty: A penalty term applied to discourage the policy from drifting too far from a reference. "we add an entropy bonus together with a KL penalty to the policy objective"
- Markov decision process (MDP): A formal framework for sequential decision making with states, actions, and rewards. "a simple mental model of exploration in a Markov decision process (MDP)."
- Monte-Carlo rollouts: Sampled trajectories used to estimate gradients or performance without an explicit value function. "and rely on Monte-Carlo rollouts for estimating the policy gradient."
- Off-policy RL: Reinforcement learning that uses data generated by a different behavior policy. "off-policy RL methods"
- On-policy RL: Reinforcement learning that updates a policy using data generated by the current policy. "on hard problems, on-policy RL rarely explores even a single correct rollout"
- Oracle solutions: Human-written or otherwise privileged correct solutions used to guide exploration. "POPE uses oracle (e.g., human-written) solutions to solely guide on-policy exploration during RL"
- Outcome-reward RL: RL setup where a scalar reward is given based on the final outcome (e.g., correctness) of a rollout. "This process is also called outcome-reward RL."
- pass@k: The probability that at least one of k independent samples solves a problem. "We study several measures of performance, including the pass@k metric"
- Pass@k optimization: Directly optimizing the pass@k objective to encourage diverse successful generations. "Directly optimizing pass@k fails to improve exploration on hard problems and primarily prevents over-sharpening on already-solvable ones."
- Policy gradient: A class of RL methods that optimize expected reward by ascending the gradient of the policy parameters. "Most RL algorithms train the base model \pi with a policy gradient"
- Population-level diversity: Diversity across multiple sampled solutions aimed at improving pass@k and reducing collapse. "optimizing pass@k-style rewards to encourage population-level diversity and reduce sharpening"
- PPO: Proximal Policy Optimization, an on-policy RL algorithm using a clipped objective. "similar to PPO~\citep{schulman2017ppo}"
- Privileged information: Information available only during training (e.g., oracle prefixes) used to guide exploration. "uses ... as privileged information to guide exploration on hard problems"
- Ray interference: An interference phenomenon where progress on easy tasks stalls or harms learning on harder ones. "ray interference, where optimization focuses on already-solvable problems in a way that actively inhibits progress on harder ones."
- Reference policy: A fixed or slowly updated policy used for sampling and computing ratios during training. "uses a reference policy \pi_{\text{old} for sampling"
- Roll-in policy: A policy used to bring the agent into regions of the state space from which reward is attainable. "Guidance acts as a roll-in policy that steers the agent into \mathcal{S}_\text{good}"
- Rollout: A full sampled trajectory (problem, tokens, and final answer) used to evaluate and train the policy. "for any given input problem x \sim \rho and a rollout y \sim \pi(\cdot \mid x) attempting to solve this problem"
- Self-verification: A reasoning behavior where the model checks or validates intermediate steps during generation. "Such models often self-verify, revisit earlier steps, and backtrack during generation"
- Sharpening: Collapse of the sampling distribution onto familiar solutions, prioritizing already-solvable problems. "avoids collapse into sharpening on already-solvable problems."
- SFT (Supervised fine-tuning): Training the model to imitate target sequences (e.g., oracle solutions) via supervised learning. "warmstarting from SFT"
- Solvability: The likelihood that at least one of multiple rollouts succeeds for a problem. "we observe no meaningful improvement in solvability (pass@32) of hard problems."
- Stitching: Learning continuations under guidance that can later be combined with unguided behaviors to solve problems from scratch. "our explanation is based on a simple mental model in which stitching plays a central role."
- Token-level entropy: The entropy of the next-token distribution, used to track exploration or instability. "average token-level entropy statistics over the course of RL training."
- Value function: A learned estimator of expected return; many LLM RL setups omit it and use Monte Carlo returns. "that do not train an explicit value function"
- Warmstarting: Initializing RL training from a model pre-trained/fine-tuned via another method (e.g., SFT). "warmstarting from SFT"
- Zero-variance filtering: A heuristic that filters out problems with no reward variance (all failures), often removing hard cases. "dynamic sampling and zero-variance filtering"
Collections
Sign up for free to add this paper to one or more collections.