- The paper introduces EPO, a novel RL framework that integrates entropy regularization, smoothing, and adaptive weighting to mitigate cascade failure.
- The methodology computes entropy across trajectory turns, ensuring controlled exploration and stable policy convergence in sparse reward environments.
- Experimental results show up to 152% improvement on benchmarks like ScienceWorld, demonstrating enhanced training stability and generalization.
EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning
Introduction
This paper introduces Entropy-regularized Policy Optimization (EPO), a framework designed to address the unique challenges faced by training LLM agents in multi-turn environments with sparse rewards. Traditional reinforcement learning (RL) methods such as Proximal Policy Optimization (PPO) suffer from the exploration-exploitation cascade failure in these settings, where early uncontrolled entropy growth leads to unstable policy foundations and late-stage uncertainty propagation hinders coherent strategy formation.
Figure 1 illustrates this cascade failure, highlighting the excessive early exploration and subsequent uncertainty propagation, and contrasting it with the stable entropy levels maintained by EPO.
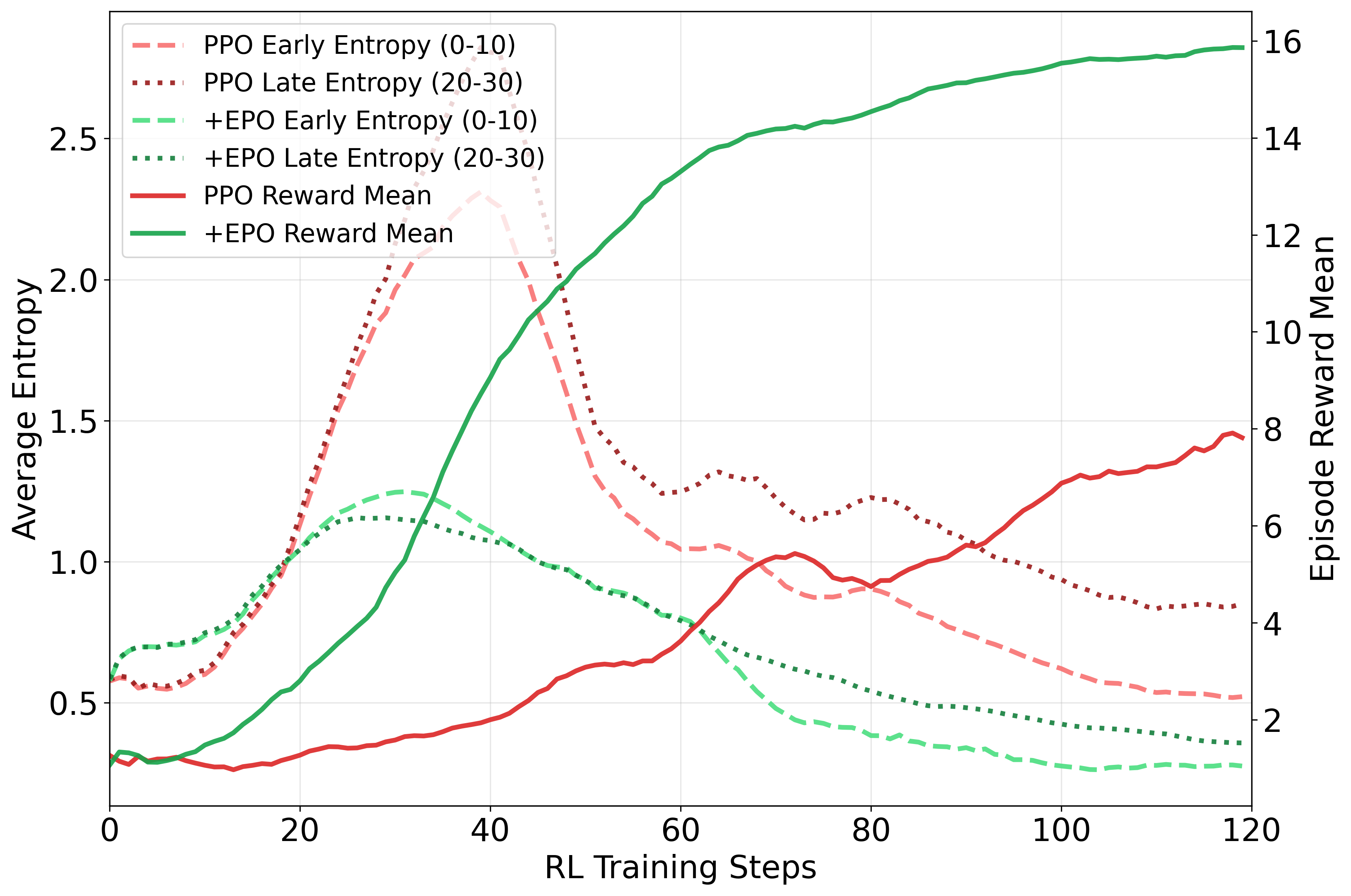
Figure 1: Exploration-exploitation cascade failure in multi-turn agent training.
Methodology
The proposed EPO framework comprises three synergistic components:
- Entropy Regularization: EPO computes entropy across all trajectory turns, adopting a temporal structure that captures early decision impacts on subsequent turns. The entropy regularization term in the policy loss enhances exploration while mitigating premature convergence.
- Entropy Smoothing Regularizer: This mechanism maintains policy entropy within dynamically adjusted historical bounds to prevent severe oscillations between overconfidence and over-exploration. The regularizer applies penalties for deviations outside acceptable entropy ranges, enforcing stable training dynamics.
- Adaptive Phase-based Weighting: EPO employs a dynamic weighting scheme that balances exploration and exploitation across training phases through a schedule for the smoothing coefficient. This adaptive approach ensures conservative early exploration, transitions through balanced exploration-exploitation, and strengthens stabilization as training progresses.
Algorithm 1 details the implementation steps for EPO, including entropy computations and dynamic coefficient updates.
Experiments
The experimental evaluation demonstrates EPO's significant improvements over traditional RL approaches on benchmarks such as ScienceWorld and ALFWorld.
Table 1 shows that PPO combined with EPO achieves up to 152% improvement in the average success rate on ScienceWorld IID tasks, highlighting the method's effectiveness in optimization and generalization robustness.
Figure 2 presents the training dynamics and performance across evaluation scenarios, illustrating EPO's enhanced training stability and substantial performance gains against baseline methods.
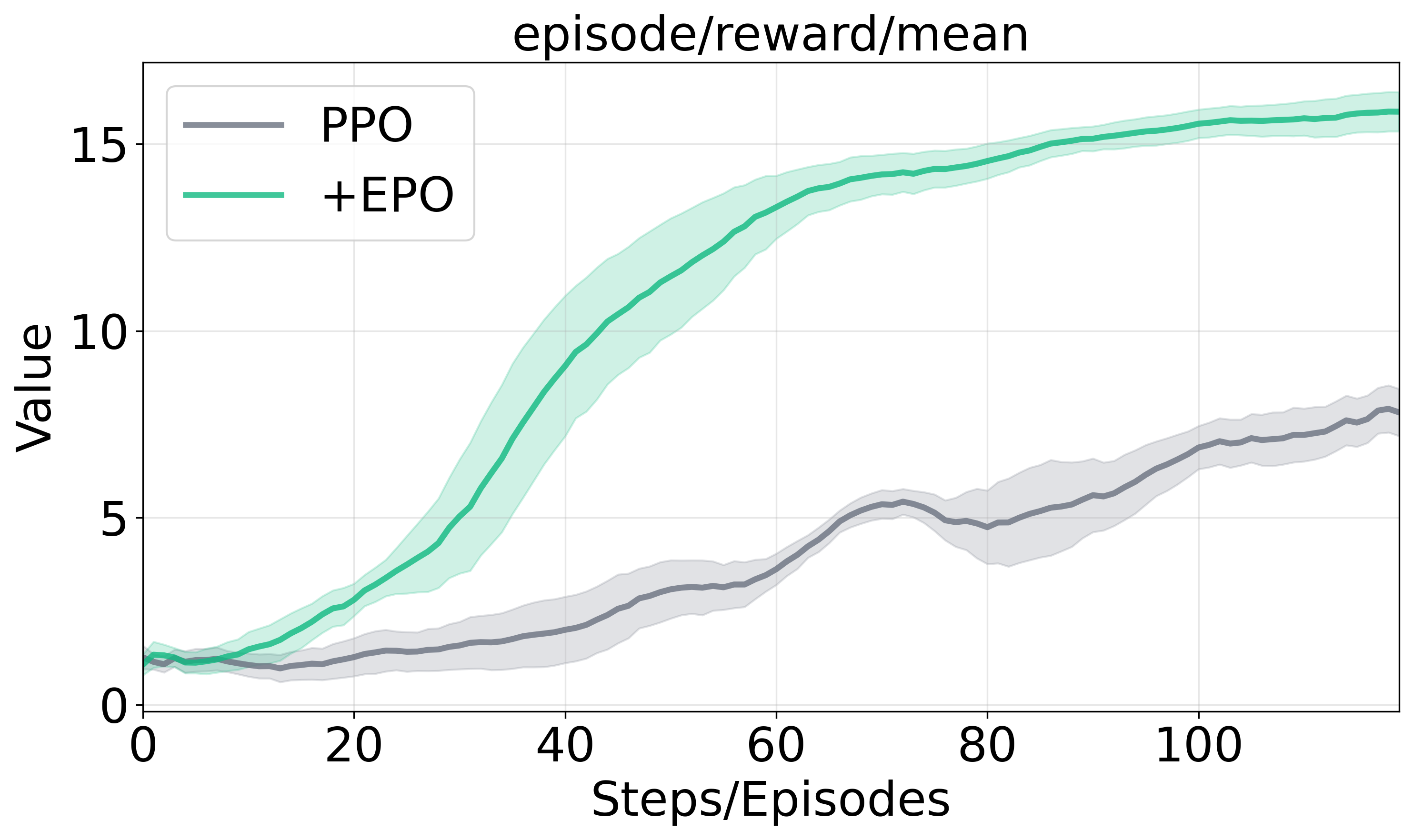
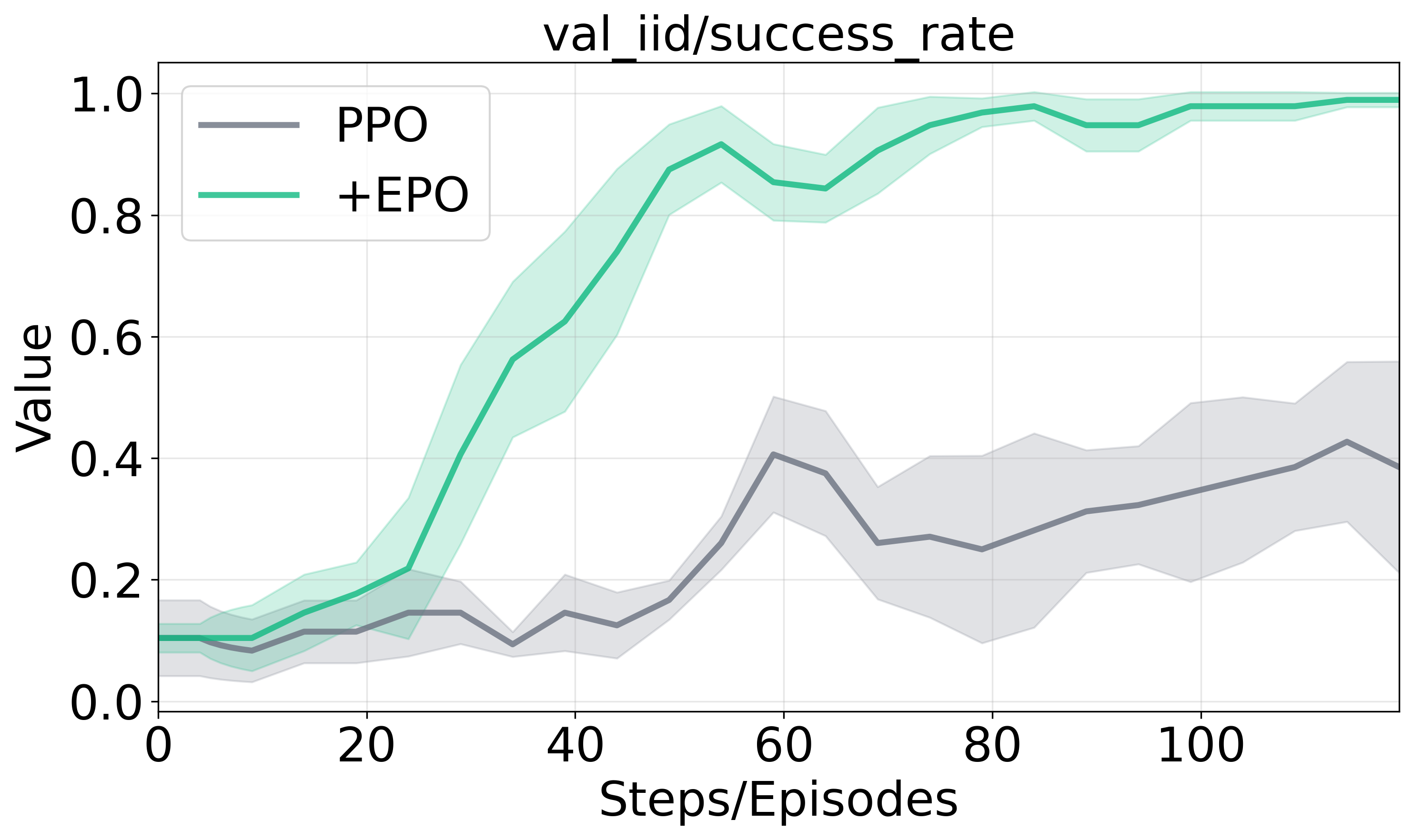
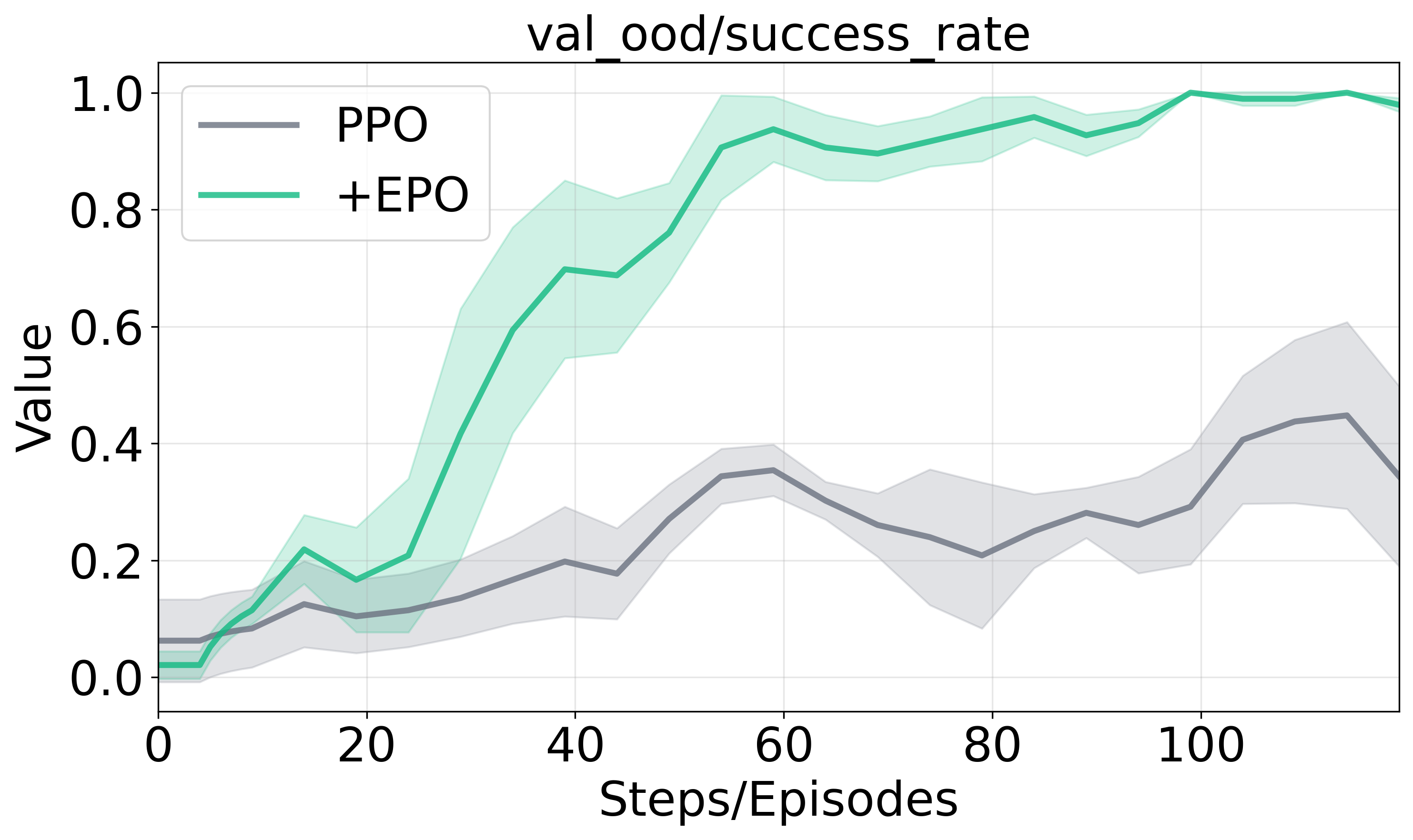
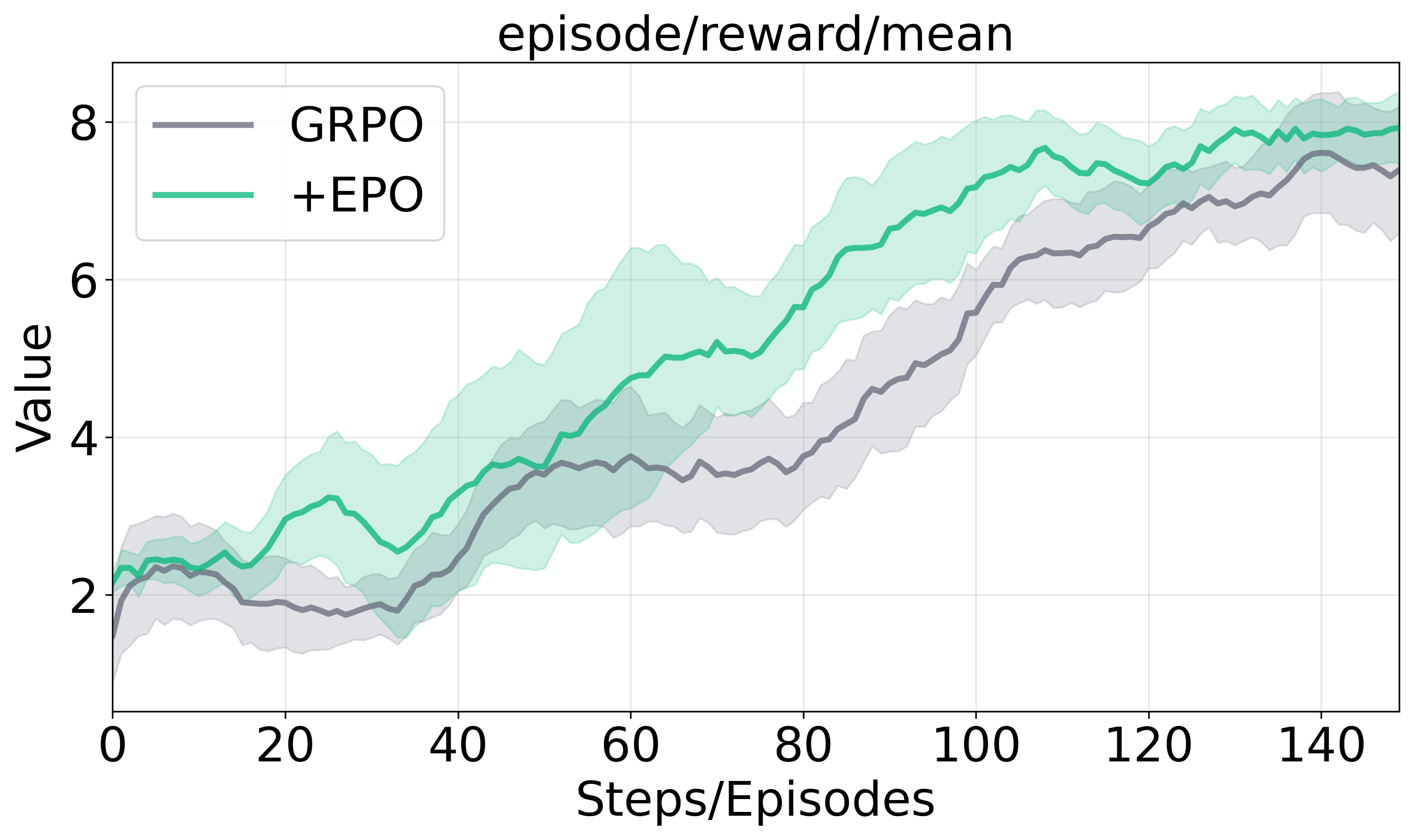
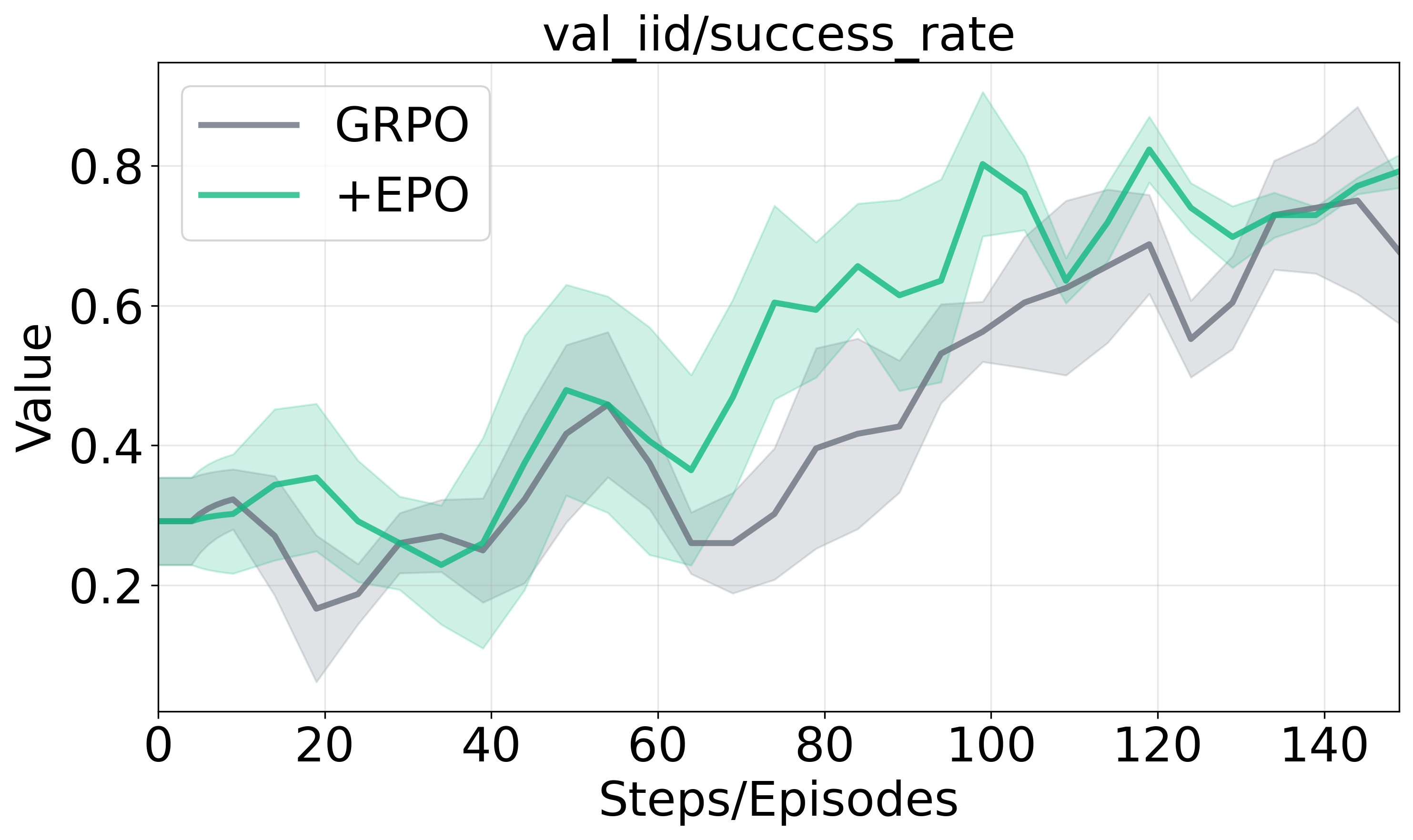
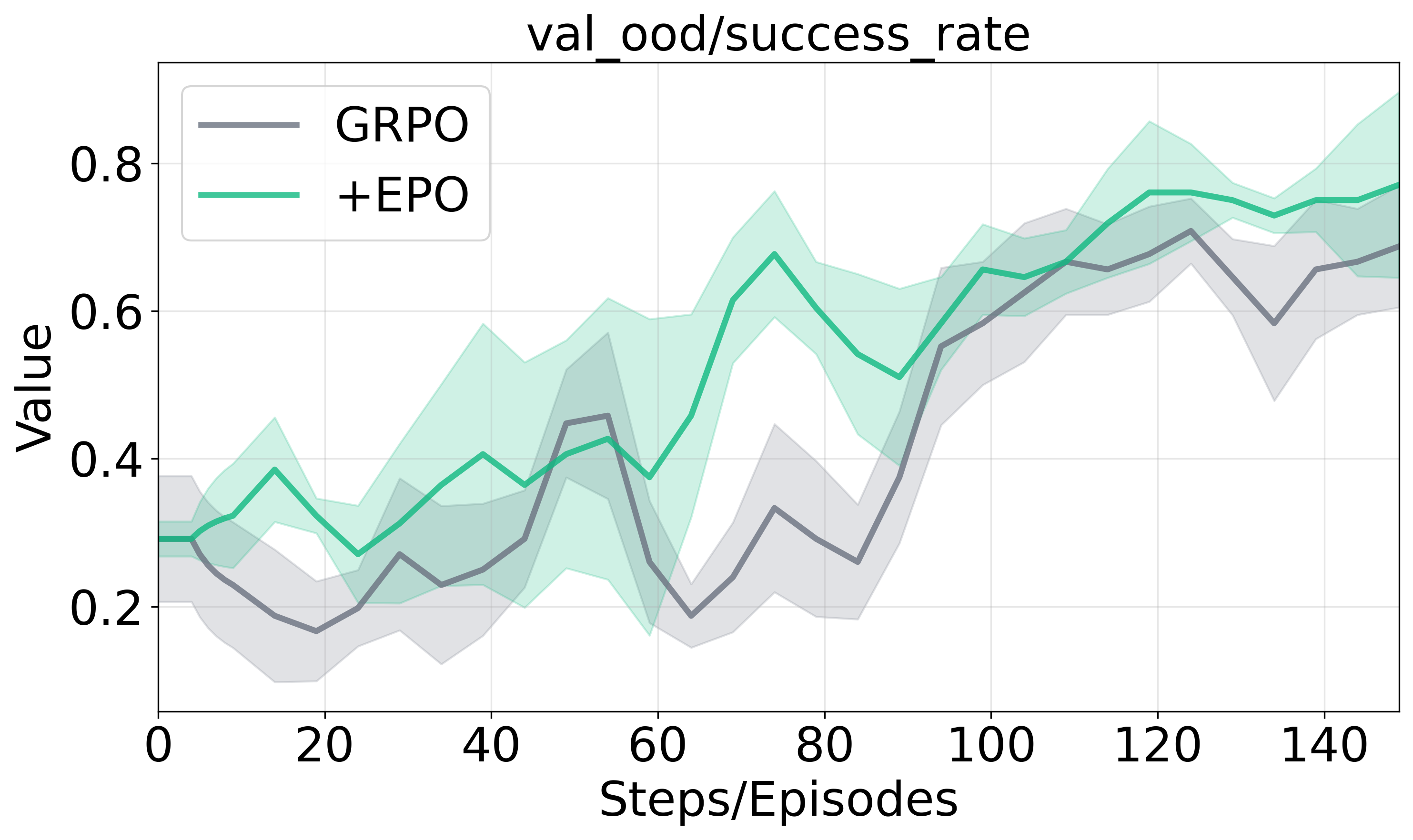
Figure 2: Training dynamics and generalization performance analysis.
Ablation Studies
A series of ablation studies validate the necessity of each component within the EPO framework:
- Entropy Smoothing Regularizer: Experiments reveal its critical role in stable convergence, particularly in sparse reward settings where uncontrolled entropy results in cascade failure.
- Adaptive Weighting Scheme: Adaptive coefficient βk accelerates early training progress by dynamically modulating regularization intensity.
Figure 3 illustrates the impact of these components on training progression and success rates in sparse environments.
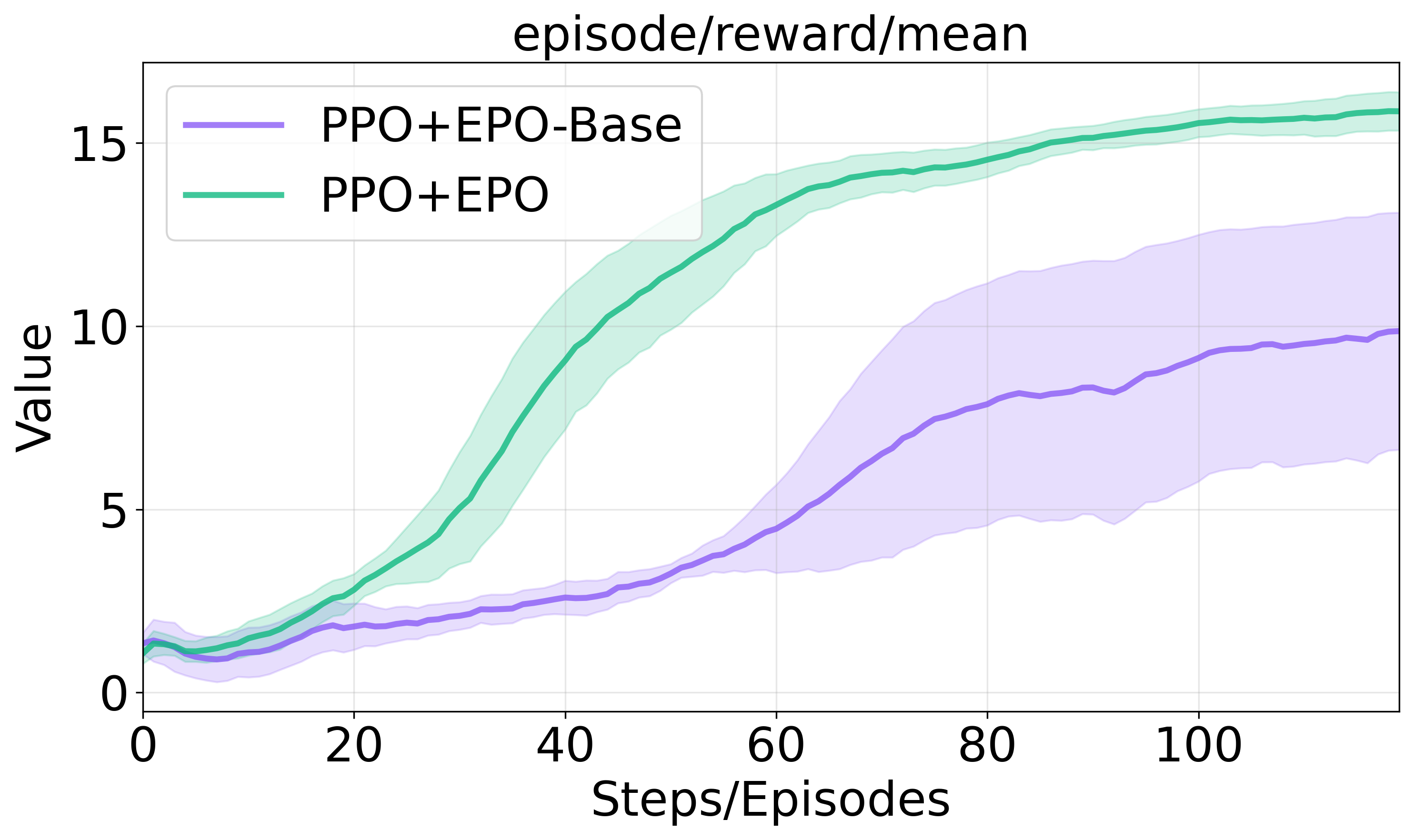
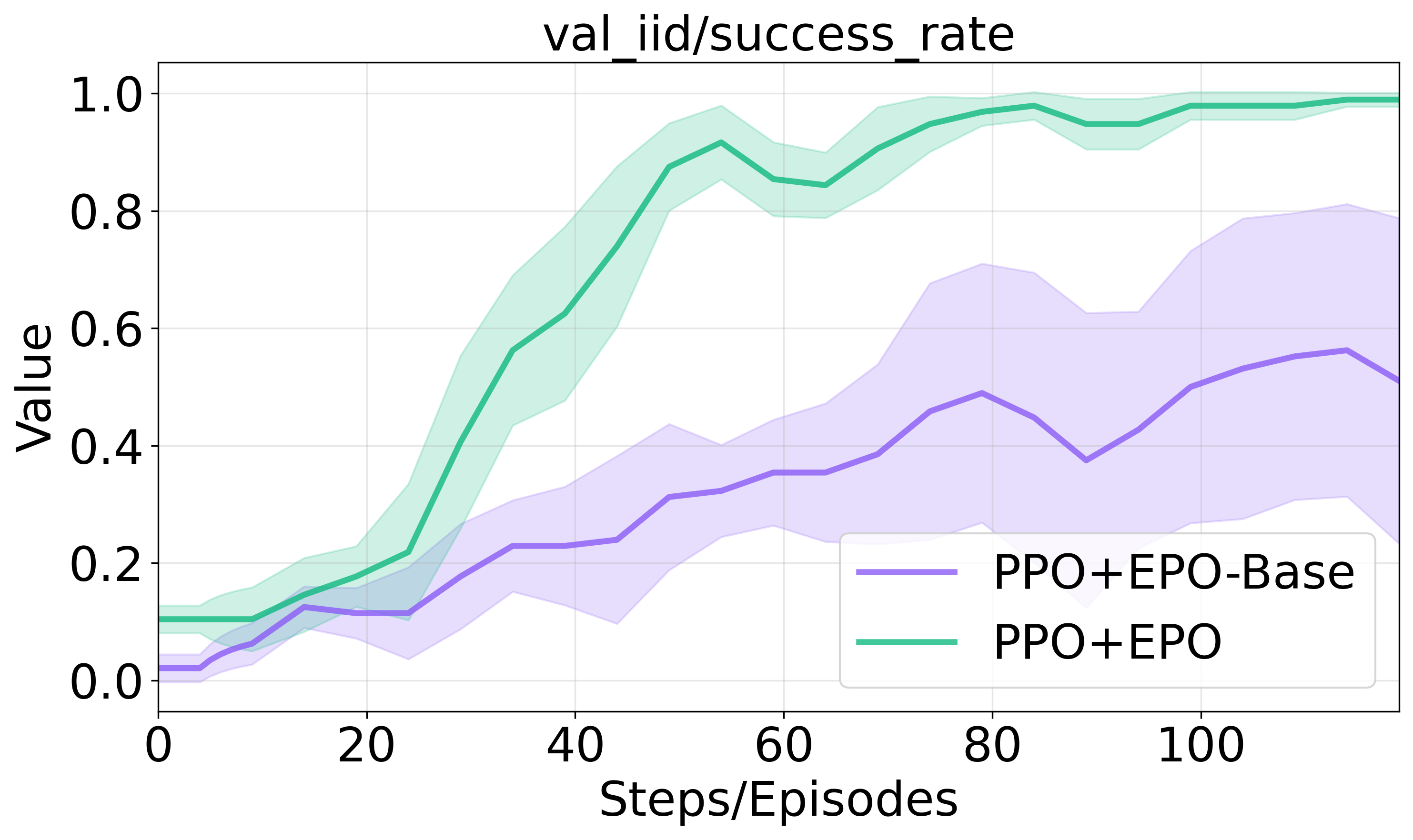
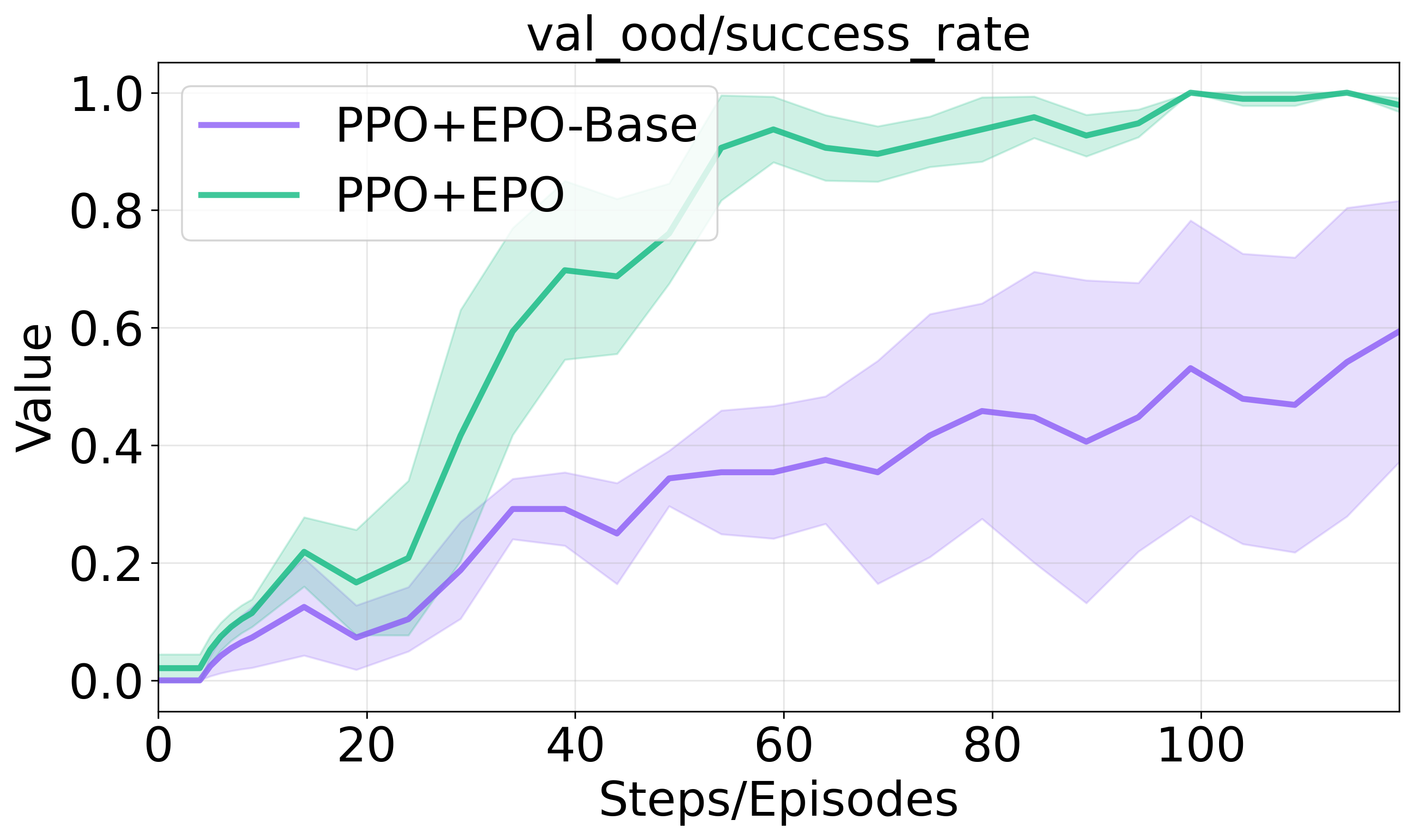
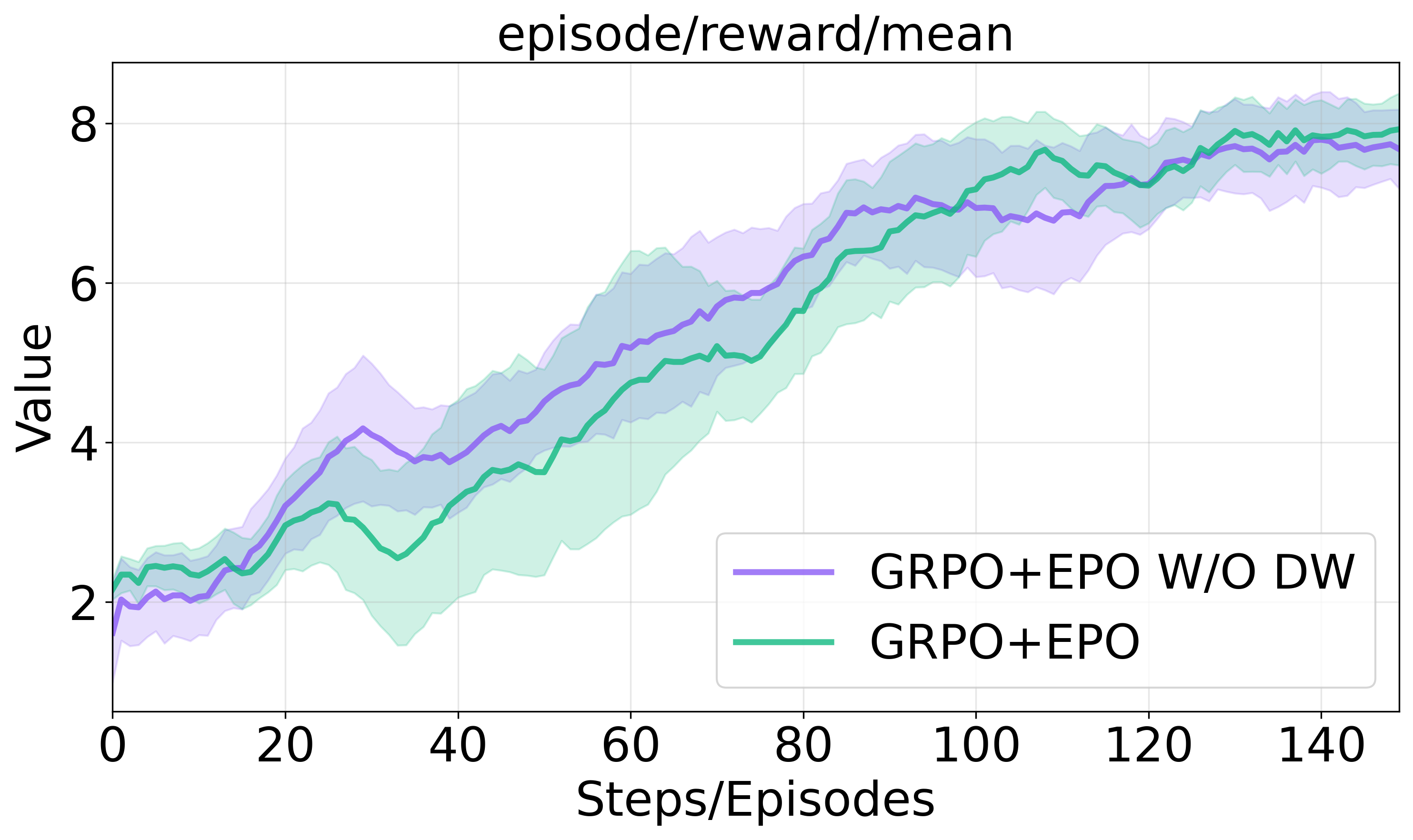
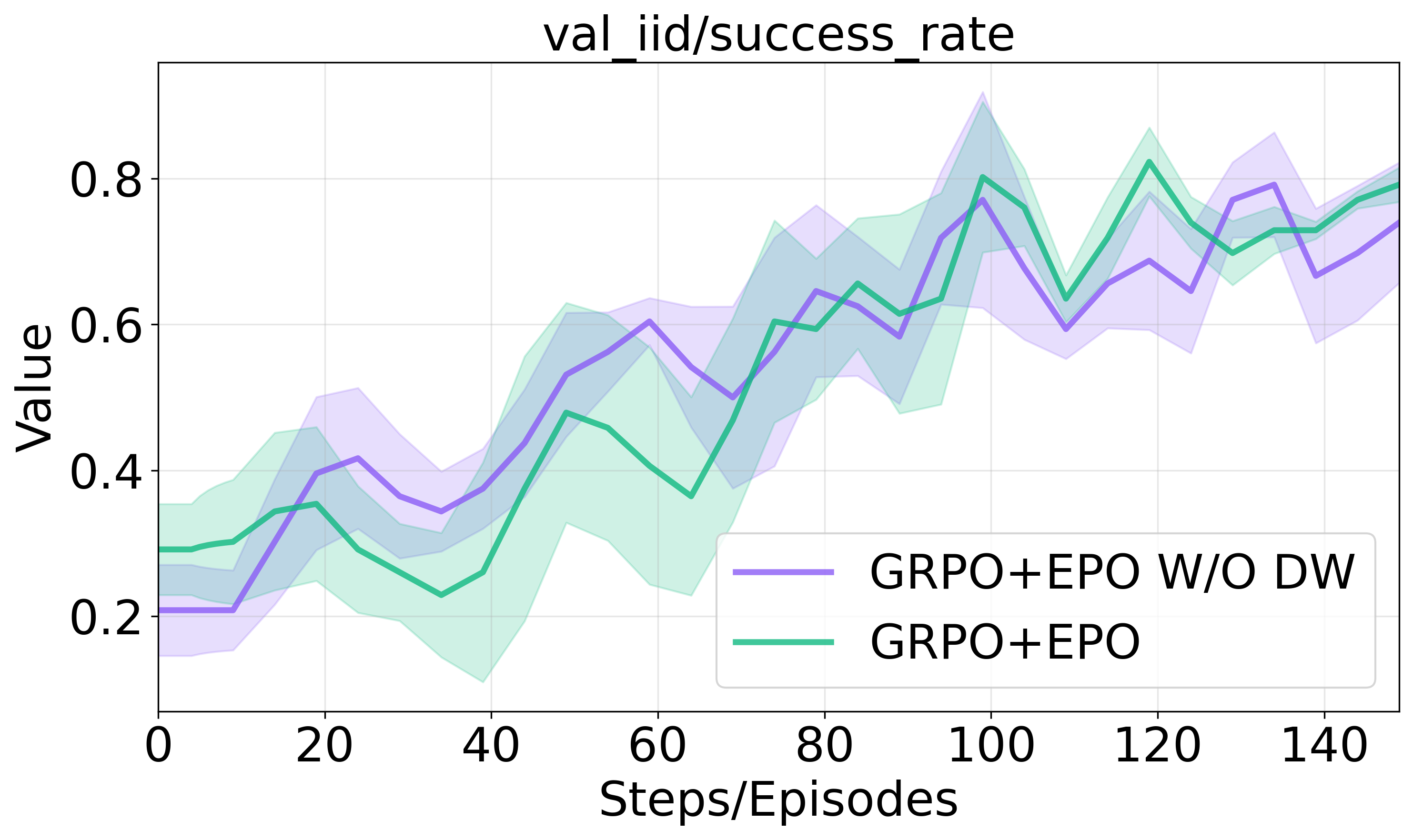
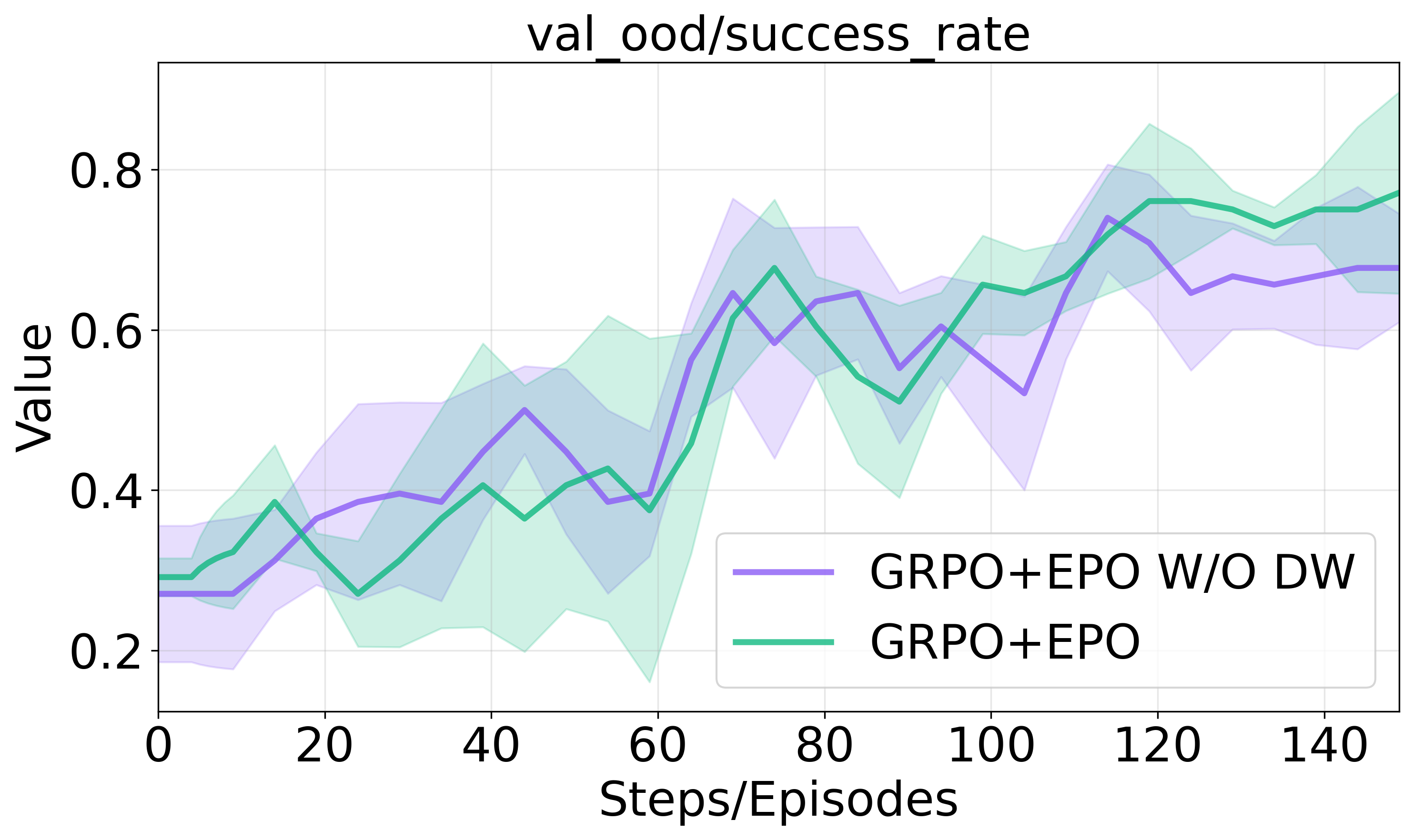
Figure 3: Ablation studies on entropy regularization components.
Model Studies
Additional experiments comparing EPO variants provide deeper insights into effective entropy management strategies in multi-turn tasks:
- Decaying Entropy Coefficient: A decaying schedule consistently underperforms due to prematurely suppressed early-turn exploration.
- Entropy-based Advantage: EPO outperforms methods that incorporate entropy indirectly, achieving near-perfect success rates due to direct integration into the policy loss.
Figure 4 offers a visual comparison of these strategies.
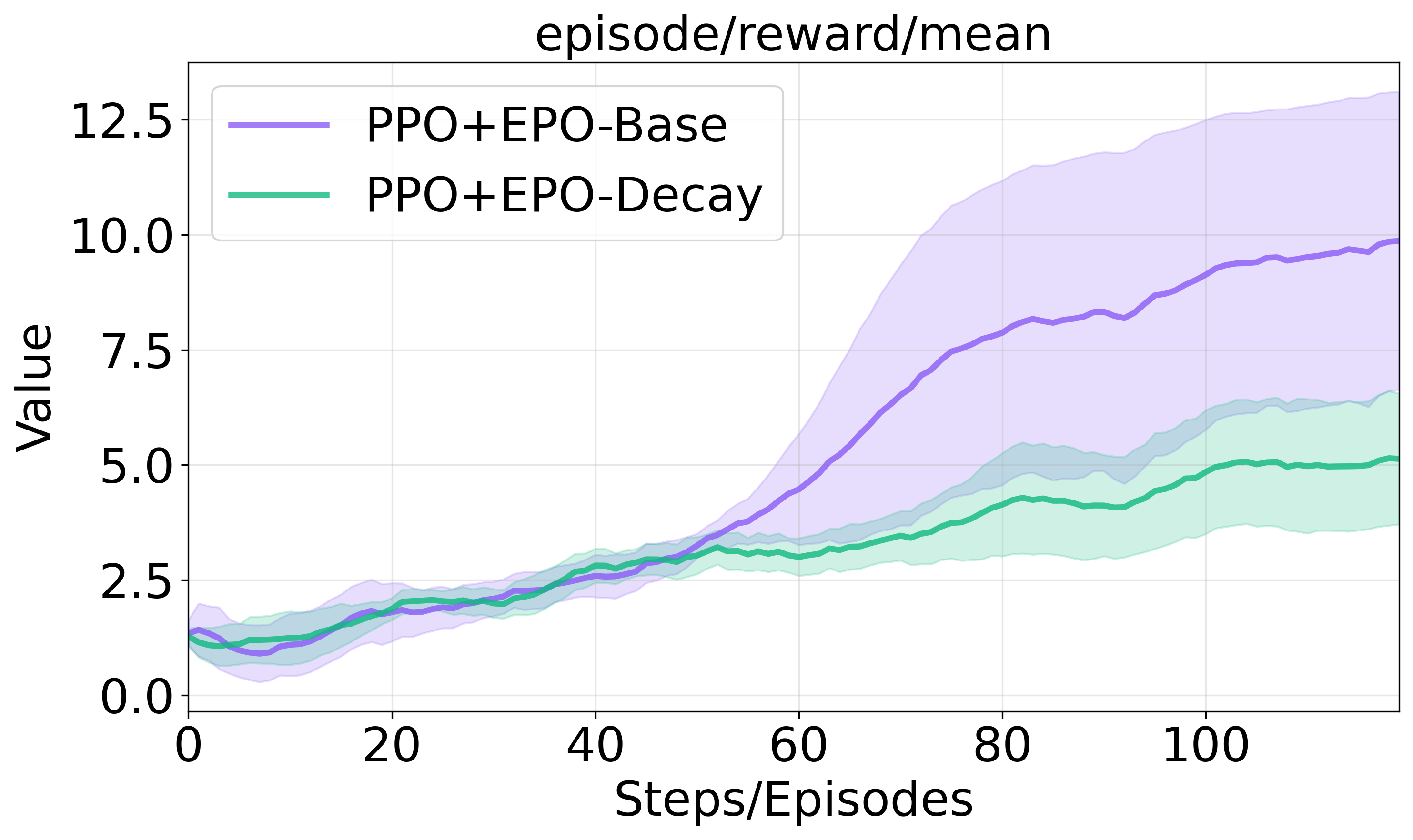
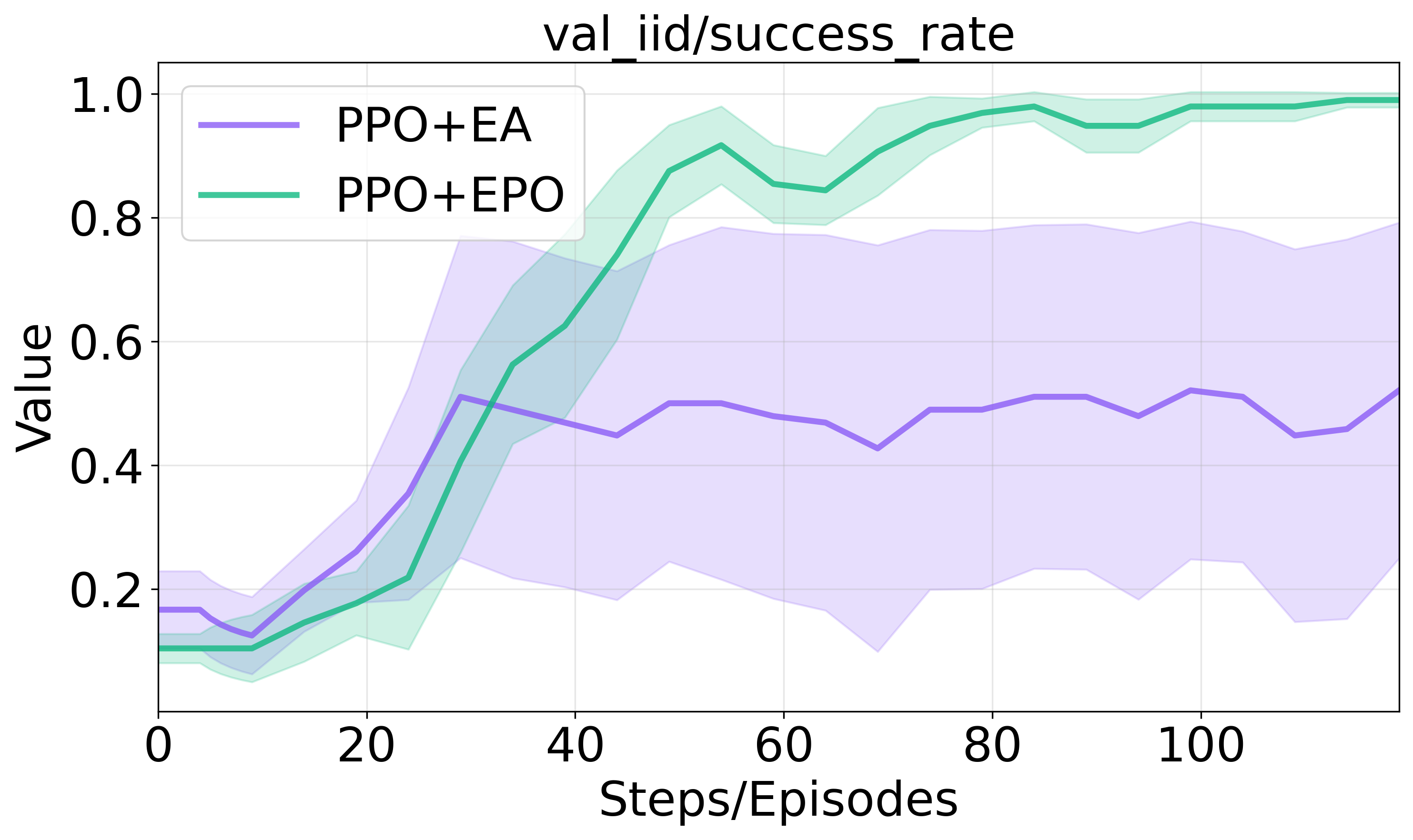
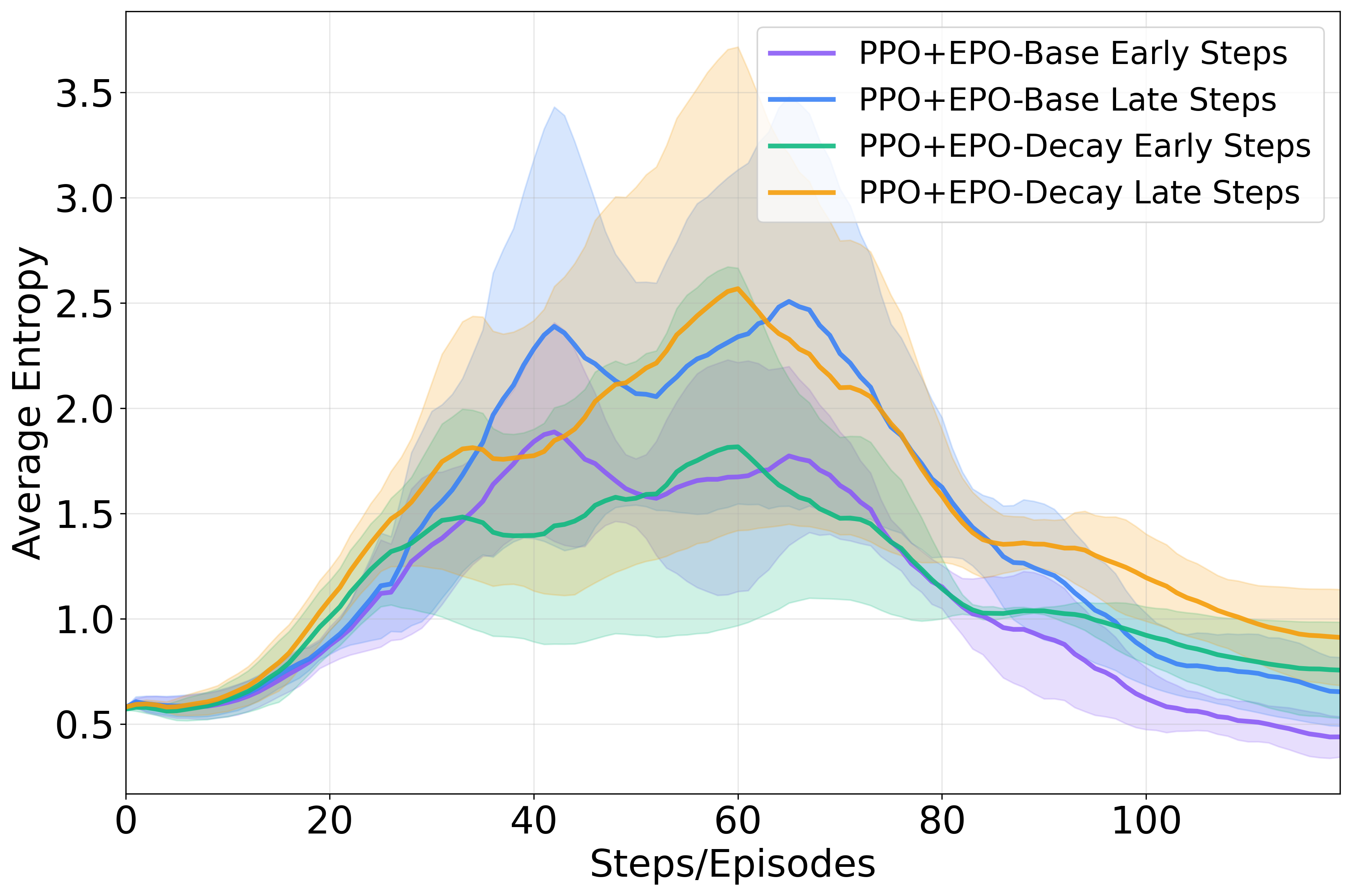
Figure 4: Model studies on ScienceWorld.
Conclusion
EPO establishes a new paradigm for training LLM agents in multi-turn environments by effectively addressing the exploration-exploitation cascade failure. The framework not only transforms previously untrainable scenarios into smoothly converged optimization problems but also suggests that multi-turn settings demand fundamentally different entropy control than traditional RL approaches. Future work includes integrating memory systems for enhanced trajectory learning and extending EPO to vision-LLMs in visual environments.

