Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
Abstract: Exploration remains the key bottleneck for LLM agents trained with reinforcement learning. While prior methods exploit pretrained knowledge, they fail in environments requiring the discovery of novel states. We propose Exploratory Memory-Augmented On- and Off-Policy Optimization (EMPO$2$), a hybrid RL framework that leverages memory for exploration and combines on- and off-policy updates to make LLMs perform well with memory while also ensuring robustness without it. On ScienceWorld and WebShop, EMPO$2$ achieves 128.6% and 11.3% improvements over GRPO, respectively. Moreover, in out-of-distribution tests, EMPO$2$ demonstrates superior adaptability to new tasks, requiring only a few trials with memory and no parameter updates. These results highlight EMPO$2$ as a promising framework for building more exploratory and generalizable LLM-based agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train AI agents that use LLMs so they can explore better and learn from their own experiences. The method is called EMPO², which stands for Exploratory Memory‑Augmented On‑ and Off‑Policy Optimization. The big idea is to let an AI agent both update its internal skills (its model) and collect useful notes in an external memory, so it gets better at solving tasks—even in places it has never seen before.
Key Questions
The paper focuses on three simple questions:
- How can we make LLM agents explore more, instead of just relying on what they already know?
- Can we help agents learn from their past attempts without constantly retraining their internal model?
- Can agents become more adaptable, so they do well even in new environments?
How Did They Do It?
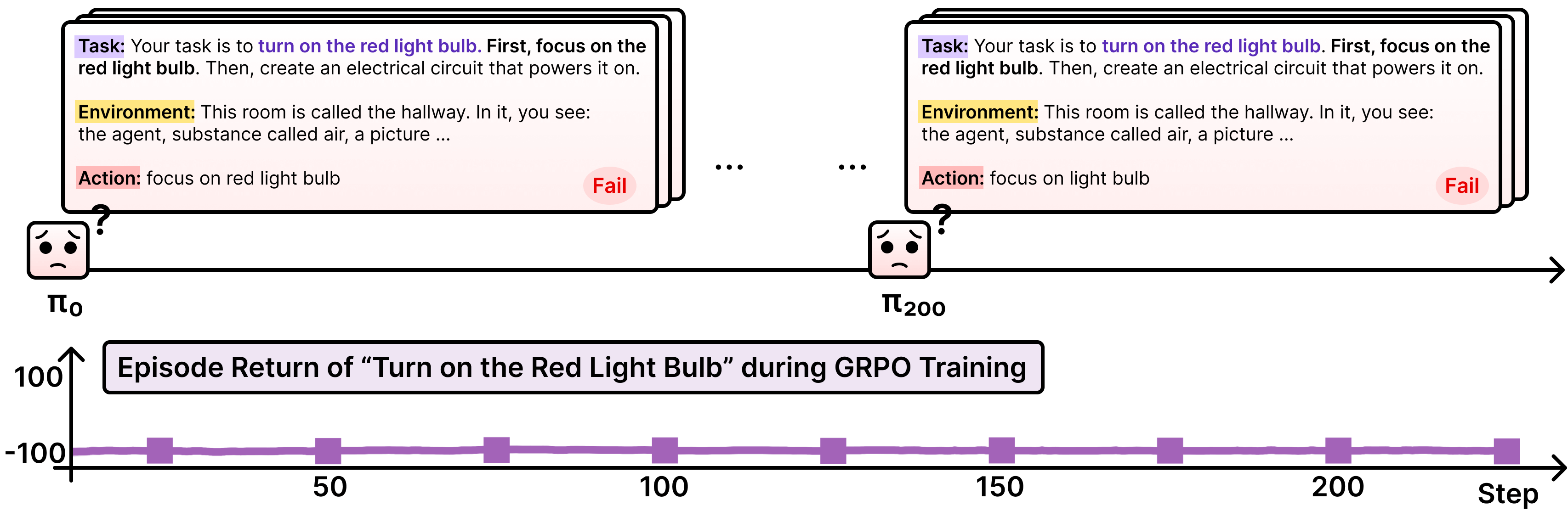
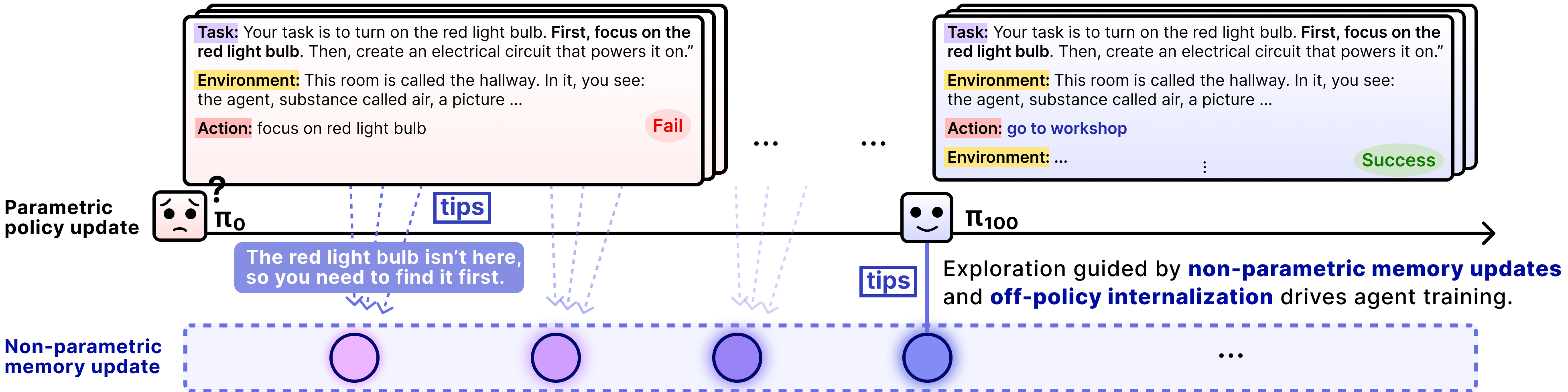
Think of the agent like a player in a video game who tries to complete challenges. After each attempt, the player writes down “tips” in a notebook about what worked and what didn’t. Next time, the player can read those tips before trying again.
Here are the key parts of EMPO², explained in everyday language:
- What is an LLM agent? An LLM agent is an AI that reads text, thinks, and acts using language (like planning steps or making choices on a website).
- What is reinforcement learning (RL)? RL is like training through trial and error. The agent tries things, gets rewards or penalties, and learns which actions lead to better results.
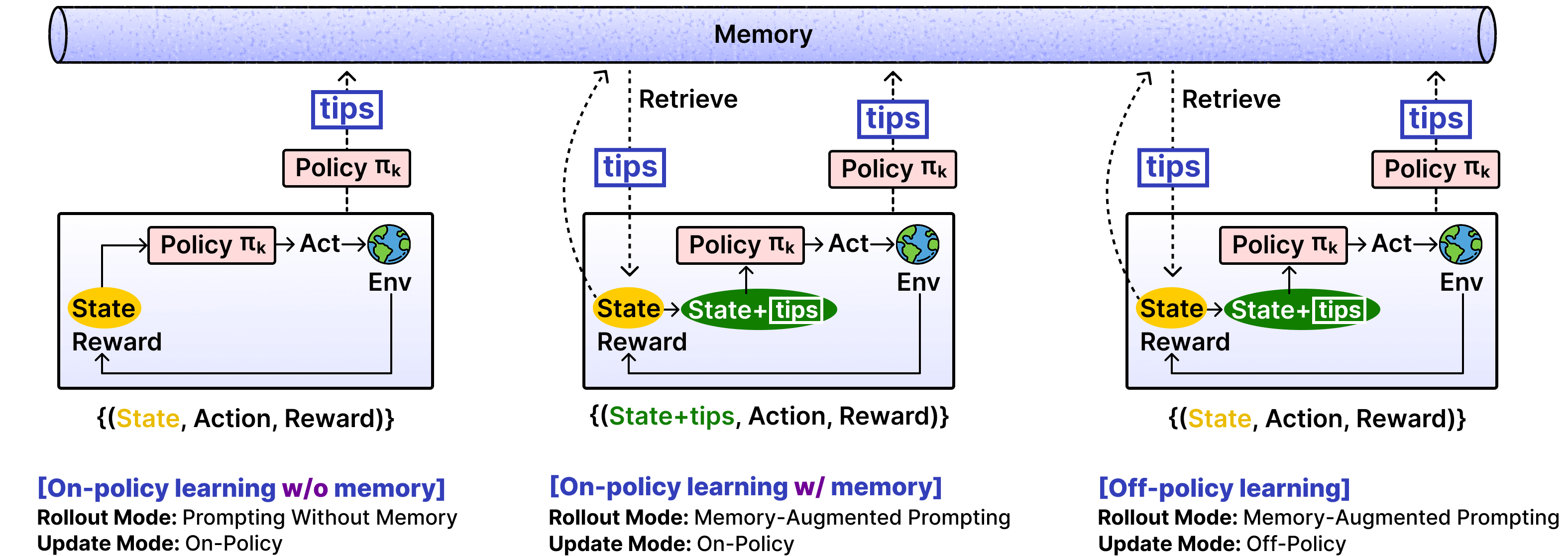
- What is “on-policy” vs. “off-policy” training?
- On‑policy: The agent learns from actions it took using its current strategy (like practicing with your current playstyle).
- Off‑policy: The agent learns from actions taken under different conditions, teaching itself to perform well even without extra help (like learning to repeat good moves from a walkthrough, but then practicing them without the walkthrough).
- Memory with “tips”: After each attempt, the agent writes short tips about mistakes and better strategies. These tips are stored in a memory bank. Later, when facing a similar situation, it retrieves the most relevant tips to avoid repeating errors and to try smarter actions.
- Two ways to play (rollout modes): 1) Without memory: The agent acts only using its current skills. 2) With memory: The agent acts while reading helpful tips.
- Two ways to learn (update modes): a) On‑policy with memory: It improves using the same setup it used during the attempt (with the tips). b) Off‑policy without memory: It removes the tips during training and tries to make the agent reproduce the good actions on its own. This is like a teacher‑student trick: the “with tips” version is the teacher showing good moves; the “without tips” version is the student practicing those moves independently until they become natural.
- Encouraging exploration: The agent gets a small “bonus” reward whenever it visits a new kind of situation it hasn’t seen before. This motivates the agent to explore, instead of only repeating safe, familiar steps.
- Keeping training stable: Sometimes training can break if the agent fixates on weird, super‑unlikely words or actions. EMPO² adds a simple filter to ignore those rare “spikes,” keeping learning smooth and stable.
Main Findings
The team tested EMPO² on two challenging environments:
- ScienceWorld: A text-based world where the agent performs simple science experiments (like building circuits or finding specific objects).
- WebShop: A website simulation where the agent searches and buys products that match instructions.
What they found:
- Big performance boosts:
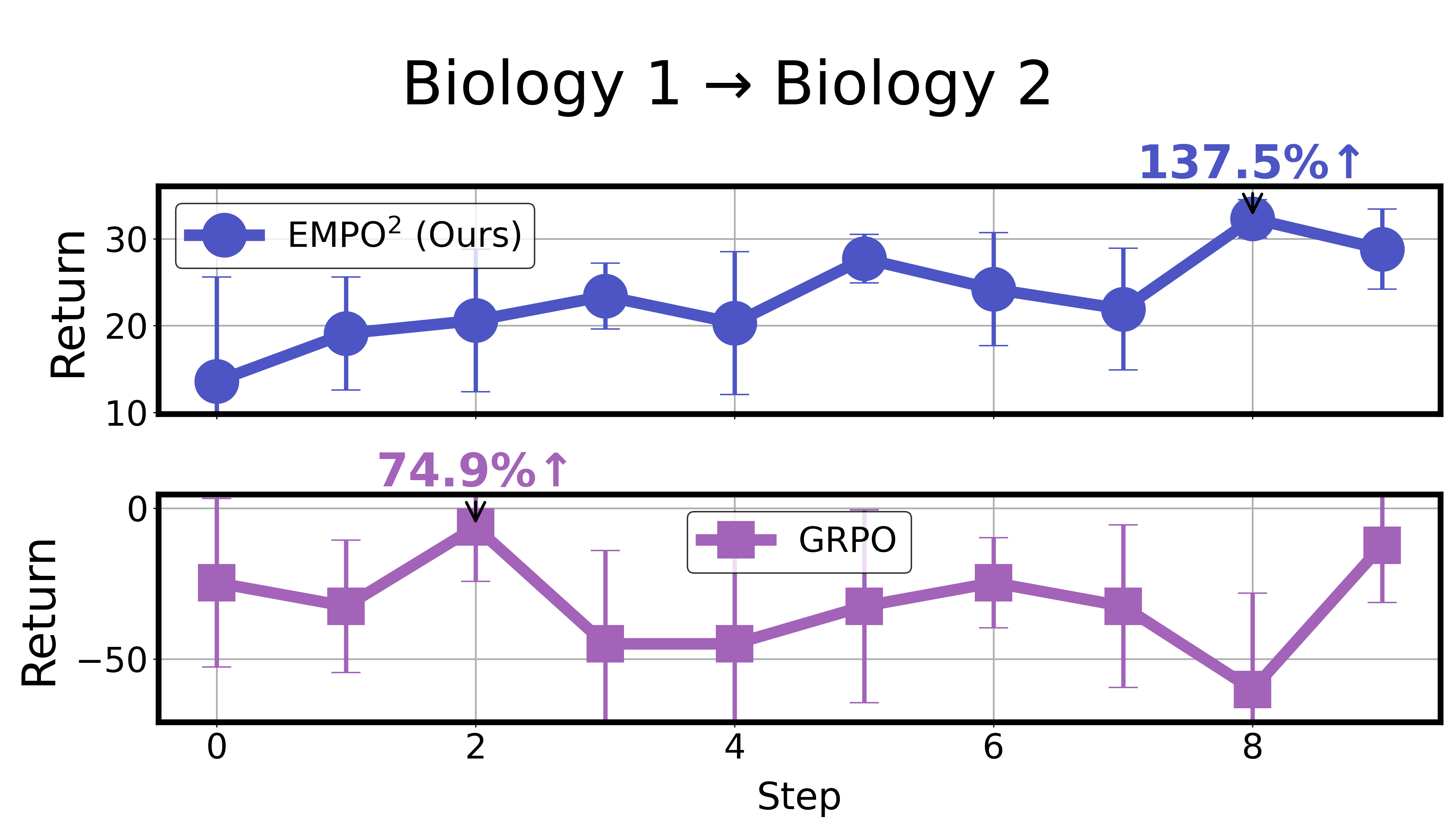
- In ScienceWorld, EMPO² improved results by 128.6% compared to a strong baseline (GRPO).
- In WebShop, EMPO² improved results by 11.3% over GRPO and also beat another competitive method (GiGPO).
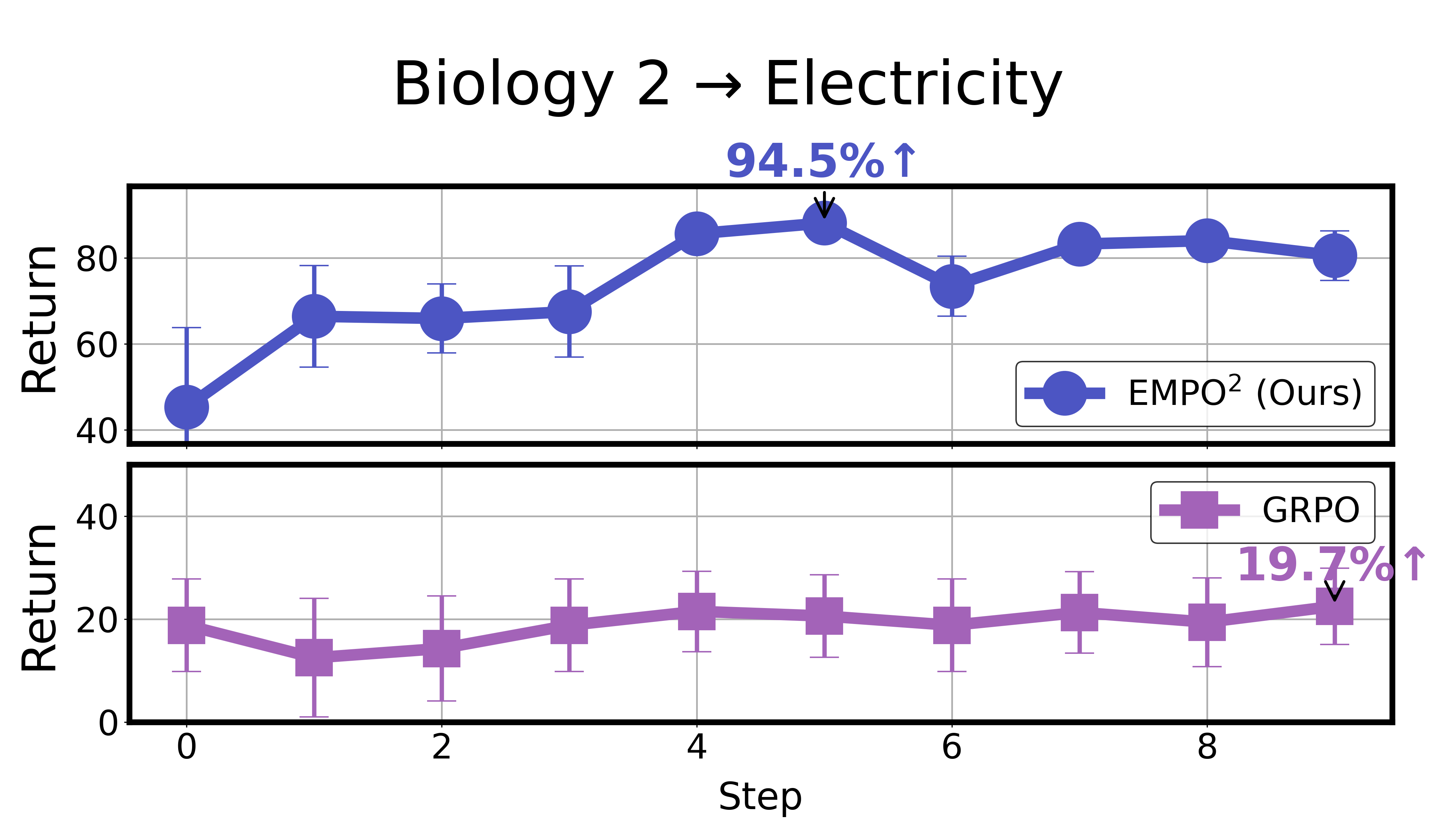
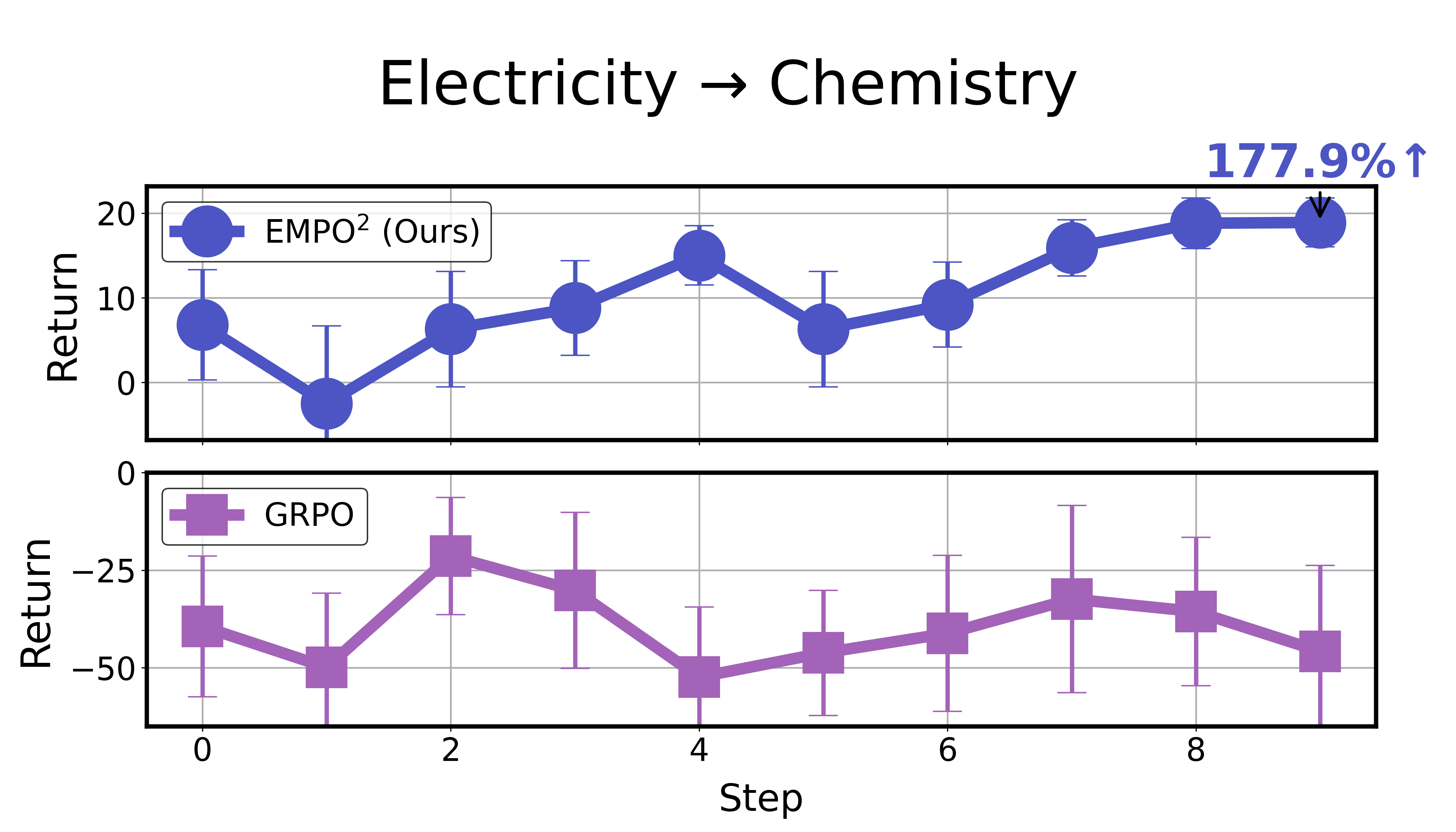
- Better at new tasks: Even when facing out‑of‑distribution tasks (new, unseen versions), the agent did well after just a few tries using memory—without changing its internal parameters. This shows EMPO² helps the agent adapt quickly to unfamiliar situations.
- More exploration, less getting stuck: Unlike standard methods that stop improving early, EMPO² keeps exploring and discovering better strategies over time.
Why This Matters
This research shows that giving LLM agents both:
- a way to remember and reuse useful tips, and
- a way to absorb those tips into their internal skills leads to smarter, more flexible behavior.
Why it’s important:
- Agents can learn faster from trial and error, not just from giant datasets or human‑crafted instructions.
- They adapt better when the rules or environment change.
- They become less dependent on external memory at test time, because good behaviors get “internalized” into the model.
Simple Takeaways and Potential Impact
- EMPO² helps AI agents act more like good learners: they explore, reflect, and improve.
- This approach could benefit many areas, like online shopping assistants, educational science labs, coding helpers, or even robots navigating new spaces.
- It points toward agents that require fewer hand‑crafted hints and are more capable of “figuring things out” on their own.
- Future work could add smarter memory retrieval, try larger models, or apply the method to math, reasoning, and multi‑modal tasks (like combining text with images or actions).
Overall, EMPO² is a practical step toward AI agents that don’t just reuse what they already know—they bravely explore, remember lessons, and become genuinely better over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Theoretical guarantees for the hybrid on-/off-policy updates are absent: no analysis of bias/consistency when replacing tips-conditioned log-probs with no-tips log-probs, nor convergence properties of the proposed importance-sampling-like objective.
- Lack of a formal treatment of credit assignment in multi-step, token-level RL without a value function; high-variance risks and how GRPO-like relative advantages interact with long-horizon dependencies remain unexamined.
- Off-policy “distillation” from memory-augmented rollouts may induce distribution shift; quantitative analysis of bias vs. stability trade-offs and comparison with alternative off-policy corrections (e.g., DAPO, V-trace, conservative policy updates) is missing.
- The impact and sensitivity of the low-probability token masking threshold () on stability, performance, and exploration are not ablated; alternative stabilization techniques (e.g., trust region penalties, adaptive clipping, variance reduction) are not compared.
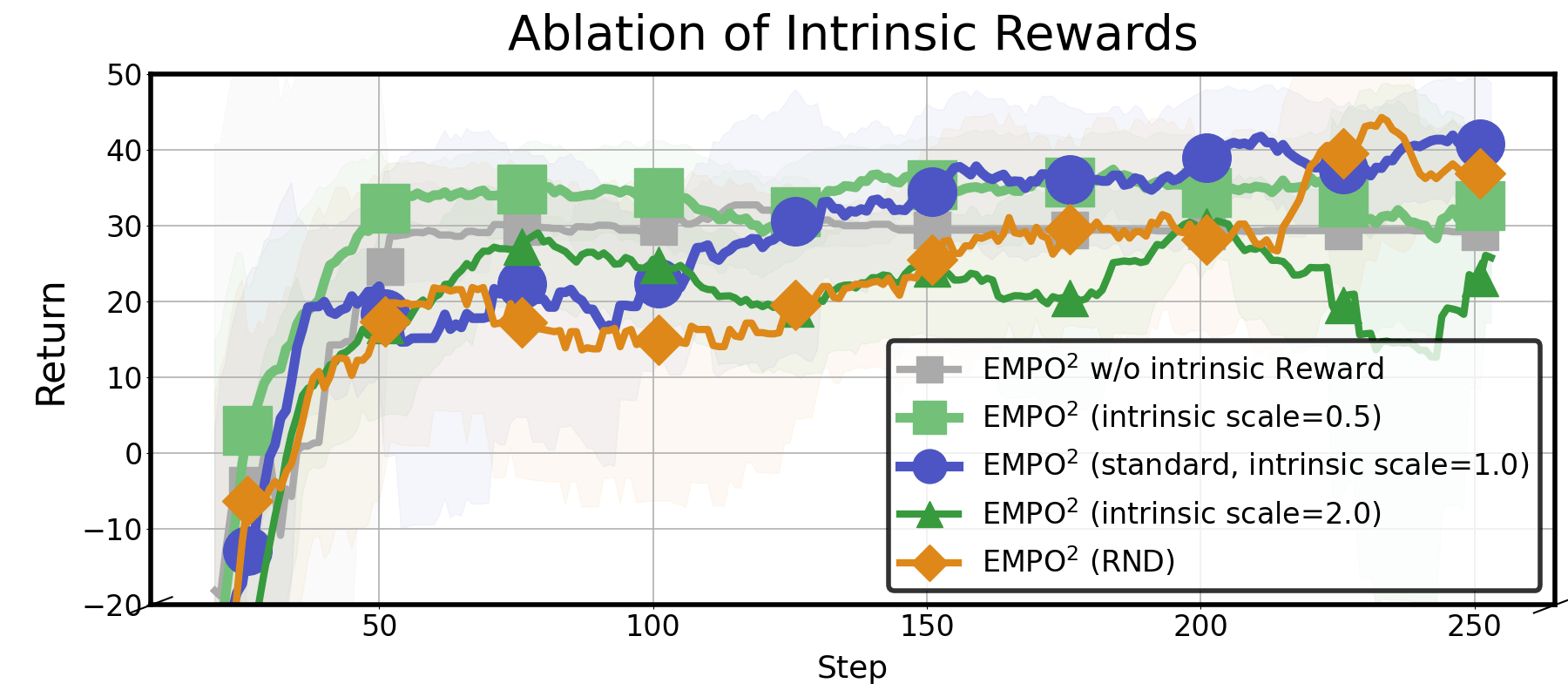
- The intrinsic reward design is under-specified and under-evaluated: details of the state representation used for novelty (embedding choice, update schedule, normalization) and hyperparameter selection are missing, as is an ablation of its effect on task returns (beyond entropy).
- Robustness to “reward hacking” via novelty-seeking is untested; no safeguards or diagnostics for agents exploiting intrinsic rewards without improving extrinsic objectives are provided.
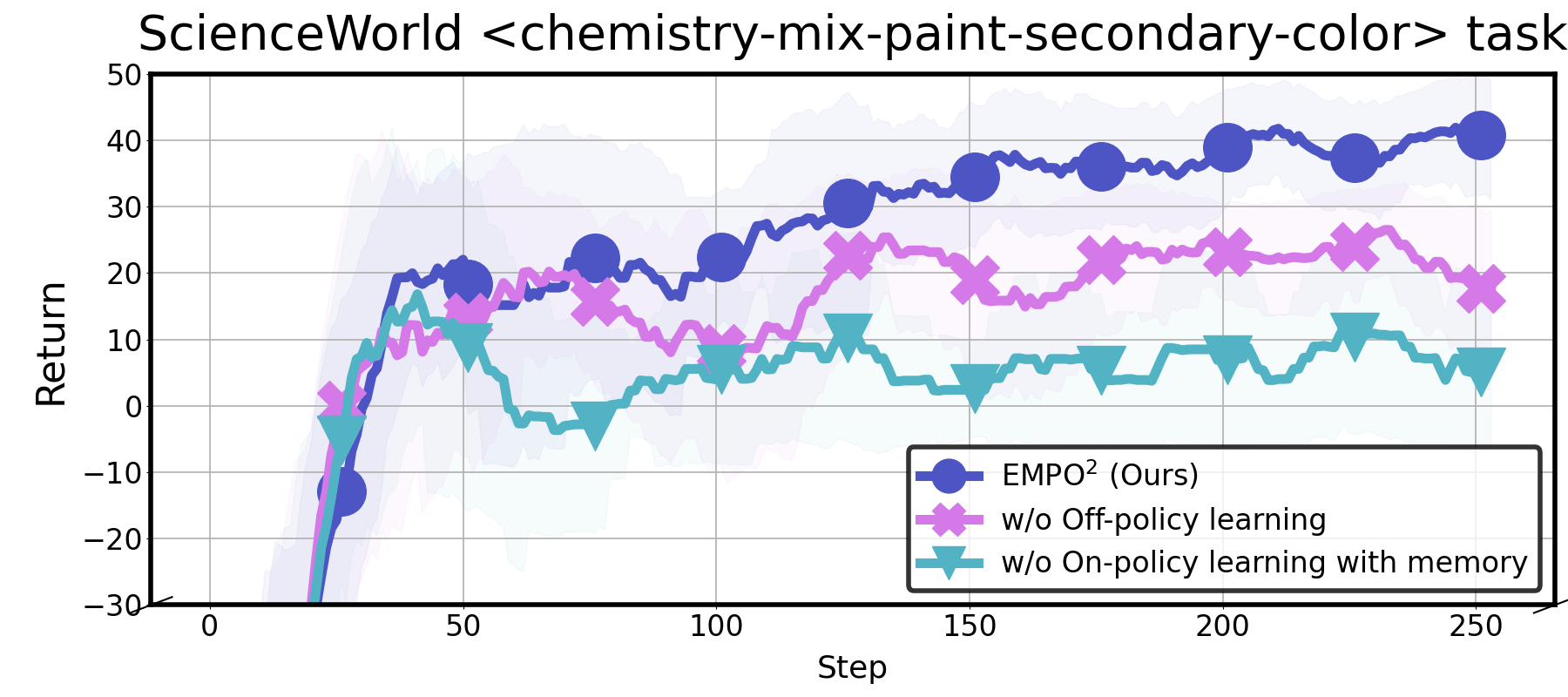
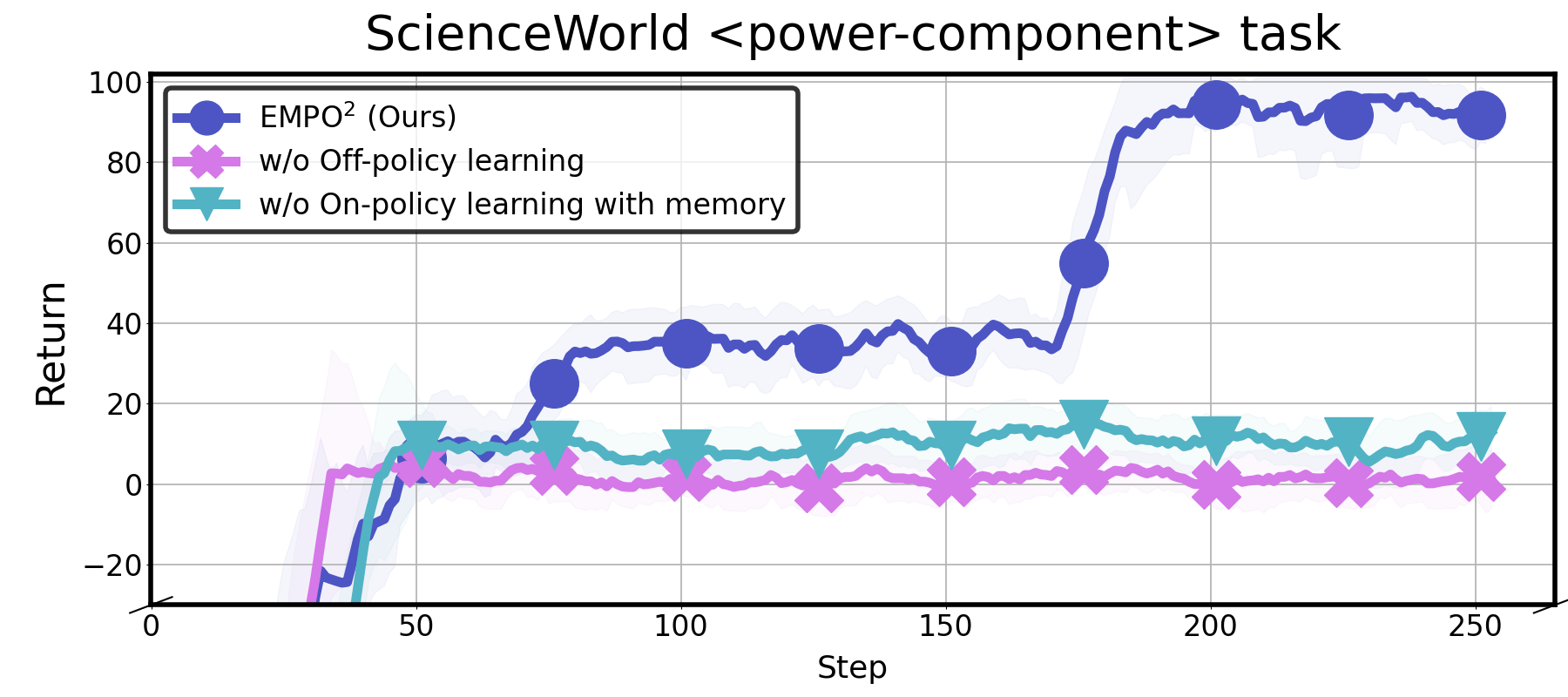
- The relative contribution of each component (memory-augmented rollouts, off-policy distillation, intrinsic rewards, token masking) to final performance lacks a comprehensive ablation; only partial mode ablations are shown.
- Scheduling/selection of rollout/update mode probabilities (p for memory rollout, q for off-policy update) is fixed and task-agnostic; the paper lacks adaptive schedules, sensitivity analysis across tasks, or principled selection strategies.
- The memory retrieval module uses basic similarity search with a cap of 10 tips; no ablations on retriever quality, cap size, embedding choice, or learned retrieval (e.g., trainable retrievers, re-ranking) are provided.
- Memory quality control and governance are not addressed: no mechanisms for deduplication, conflict resolution among tips, noise filtering, or forgetting policies to avoid stale/erroneous tips.
- No study of robustness to misleading or adversarial tips (e.g., prompt injection in WebShop-like settings) or to distributional contamination across tasks; attack surfaces of the memory channel remain unexplored.
- The feedback loop between self-generated tips and policy updates (confirmation bias, premature convergence on suboptimal strategies) is not analyzed; mechanisms to encourage diversity/anti-collapse (e.g., counterfactual tips, diversity regularization) are not considered.
- The paper evaluates final policy without memory at test time, but does not fully quantify the trade-off between parametric internalization and residual dependence on memory; performance with vs. without memory post-training needs systematic measurement.
- OOD adaptation is demonstrated only on a few task transitions; a comprehensive evaluation across diverse shift types (goals, dynamics, observation distributions) with standardized protocols is missing.
- Baselines omit some memory-centric methods (e.g., REMEMBERER) and stronger online/offline RL baselines (e.g., IQL-based online agents, replay-based PPO variants), limiting the strength of comparative claims.
- Sample efficiency is not rigorously quantified: the number of environment steps/tokens to reach specified performance, wall-clock compute, and memory overhead are not reported or compared across methods.
- Computational costs of dual-mode rollouts/updates, repeated log-prob evaluations (tips vs. no-tips), and memory retrieval at every step are not analyzed; scaling behavior with memory size and long horizons is unclear.
- The method is tested on two text-based environments (ScienceWorld, WebShop); generality to other domains (math/coding with strict correctness, multi-modal RL, tool use with complex APIs, robotics) is untested.
- Generalization across model families and sizes is limited to Qwen2.5-7B-Instruct; experiments on smaller and larger models and different instruction/RL-tuned bases (and their interaction with memory) are not reported.
- The interaction between KL-to-reference regularization and the intrinsic reward/exploration dynamics is not studied; how KL strength influences exploration-exploitation in this setup remains unclear.
- No analysis of long-horizon and sparse-reward regimes beyond the chosen benchmarks; failure modes on extremely hard-exploration tasks (e.g., deeper web navigation, longer ScienceWorld chains) are unknown.
- Experience replay is not used despite off-policy elements; whether prioritized replay or trajectory caching could improve stability and sample efficiency is untested.
- Tip-generation prompting is fixed; the effect of different prompting styles (structured schemas, critique vs. plan tips, counterfactuals) on exploration quality and distillation efficiency is not explored.
- Retrieval granularity and conditioning are simplistic (global tips per step); structured memory (graphs, causal schemas, reusable subroutines) and step-specific or subgoal-conditioned retrieval strategies are not investigated.
- Safety and alignment considerations are minimally addressed; the system’s behavior under risky exploration, harmful instructions, or unsafe web interactions, and safeguards for memory contents (e.g., PII, unsafe policies) remain open.
Glossary
- Ablation study: A controlled analysis where components of a method are removed or varied to assess their impact. "An ablation study confirms the importance of the three distinct modes of EMPO."
- Bootstrapping: Using one learning signal or component to kick-start and improve another, often iterative, process. "Non-parametric updates can encourage exploration, bootstrapping parametric updates."
- Context distillation: A training technique where a model learns to solve tasks from minimal prompts by distilling behavior from richer, teacher-style prompts. "introduced context distillation, where the model first solves tasks using a Teacher prompt"
- Count-based exploration: An exploration strategy that rewards visiting novel or less-frequent states based on visit counts. "Classical methods such as count-based exploration \citep{count-based} and Random Network Distillation \citep{rnd}"
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them. "we compute its cosine similarity with existing entries."
- Credit assignment: The process of determining which actions or states are responsible for observed outcomes or rewards. "enabling finer credit assignment and stronger performance."
- Embedding space: A continuous vector space where items (e.g., states, tips) are represented for similarity and retrieval operations. "via similarity search in the embedding space."
- Embodied AI: AI agents that interact with environments through perception and action, often across multiple steps. "interactive decision-making, tool use, and embodied AI"
- Few-shot: Adapting to new tasks or domains with only a small number of examples or trials. "adapt rapidly to new domains in a few-shot manner"
- GiGPO (Group-in-Group Policy Optimization): An RL algorithm that refines GRPO by grouping similar observations for improved advantage estimation. "GiGPO \citep{gigpo} advanced GRPO by grouping rollouts with similar observations"
- Go-Explore: An exploration method that saves and returns to promising states to systematically discover new behaviors. "Go-Explore \citep{go-explore} stores key states and re-explores from them"
- GRPO (Group Relative Policy Optimization): A policy optimization algorithm that compares multiple rollouts of the same task to compute relative advantages without a value function. "Group Relative Policy Optimization (GRPO) updates the policy by comparing multiple rollouts of the same task "
- Importance sampling ratio: A factor that reweights samples when the behavior policy differs from the target policy to obtain unbiased estimates. "Appendix~\ref{sec:is_ratio_details} provides an illustrative breakdown and a summary table for the calculation of the importance sampling ratio."
- Implicit Q-learning (IQL): An offline RL method that learns a Q-function by implicitly handling policy constraints, used to rescore or select actions. "uses a Q-function learned via Implicit Q-learning \citep{iql} to dynamically rescore actions."
- In-distribution (ID): Data or tasks that come from the same distribution as the training set or setting. "in-distribution (ID) and out-of-distribution (OOD) settings"
- Intrinsic reward: A reward signal generated by the agent to encourage behaviors like novelty or exploration, independent of external task rewards. "we introduce an intrinsic reward based on the novelty of the current state."
- Knowledge distillation: Transferring knowledge from a teacher model or setting to a student model, often via training on teacher-generated behaviors. "This construction can be interpreted as a form of reward-guided knowledge distillation."
- KL loss: A loss term based on Kullback–Leibler divergence that regularizes the policy toward a reference. "gradient normalization, entropy loss, KL loss, and policy gradient loss can all diverge to NaN."
- Likelihood ratio: The ratio of action probabilities under two policies, used in policy gradient methods and importance sampling. "unbounded likelihood ratios."
- Low-probability tokens: Rarely predicted tokens that can cause unstable training due to large gradient magnitudes in likelihood-ratio methods. "low-probability tokens destabilize training by amplifying gradient magnitudes through unbounded likelihood ratios."
- Memory-augmented prompting: Conditioning action generation on retrieved memory items (e.g., tips) to guide behavior. "In memory-augmented prompting, the policy conditions its action on both and \text{\fcolorbox{empo2}{white}{\textcolor{empo2}{tips}}"
- Non-parametric updates: Learning via external structures (e.g., memory) rather than updating model parameters, enabling rapid adaptation. "the non-parametric updates not only complement but also enhance the efficiency of parametric learning"
- Offline reinforcement learning (offline RL): Learning policies from fixed datasets without additional environment interaction. "offline RL, which learns optimal policies from large logged datasets"
- Off-policy updates: Learning from trajectories generated by a different behavior policy than the one being optimized. "Off-policy training is prone to instability and may collapse"
- Online reinforcement learning (online RL): Learning by interacting with the environment in real time, alternating between collecting data and updating the policy. "Online RL consists of alternating between a rollout phase"
- Out-of-distribution (OOD): Data or tasks that differ from those seen during training, testing generalization. "in-distribution (ID) and out-of-distribution (OOD) settings"
- Policy entropy: A measure of the randomness or diversity of the policy’s action distribution, often used to encourage exploration. "Policy entropy comparison with vs. without intrinsic rewards."
- Policy gradient loss: The objective used in policy gradient methods to adjust the policy parameters toward actions with higher estimated returns. "policy gradient loss can all diverge to NaN."
- Proximal Policy Optimization (PPO): A policy gradient method that stabilizes updates via clipping of likelihood ratios. "removing the need for the value function in PPO \citep{ppo}."
- Process-level rewards: Dense rewards assigned to intermediate reasoning or procedural steps, not just final outcomes. "provides dense, process-level rewards for each reasoning type"
- Q-function: A function estimating expected cumulative reward for state-action pairs, used for action evaluation. "uses a Q-function learned via Implicit Q-learning \citep{iql} to dynamically rescore actions."
- Q-values: Numerical estimates produced by a Q-function representing the value of taking specific actions in given states. "records observations, actions, rewards, and Q-values"
- Reference policy: A baseline policy toward which the current policy is regularized, often via KL penalties. "controlling the regularization strength toward a reference policy"
- Relative advantage: A measure comparing a trajectory’s return to the average within a group to assess how much better or worse it performed. "we define its relative advantage as:"
- Random Network Distillation (RND): An exploration method that rewards novelty by comparing predictions of a random target network and a learned predictor. "Classical methods such as count-based exploration \citep{count-based} and Random Network Distillation \citep{rnd}"
- Retrieval operator: A mechanism that selects relevant items from memory based on current context or similarity. "a retrieval operator selects tips most relevant to the current state "
- Rollout: The process of executing a policy in the environment to generate trajectories of states, actions, and rewards. "Online RL consists of alternating between a rollout phase"
- Return: The cumulative sum of rewards obtained along a trajectory. "Each trajectory receives a return"
- Scaffolding mechanism: An auxiliary aid that temporarily supports learning or exploration, with its benefits later internalized. "tips serve as an intermediate scaffolding mechanism"
- Similarity search: Retrieving items most similar to a query within a vector space, often via nearest neighbor methods. "via similarity search in the embedding space."
- Supervised fine-tuning (SFT): Further training a pretrained model on labeled examples to specialize it for specific tasks. "warm-start supervised fine-tuning (SFT)"
- Teacher demonstrations: High-quality example trajectories used to guide or supervise a student policy. "trajectories sampled under the tips-conditioned policy act as teacher demonstrations"
- Trajectory: A sequence of interactions consisting of states, actions, and rewards collected during an episode. "A rollout trajectory is thus defined as the sequence of states, actions, and rewards"
- Value function: A function estimating expected returns from a state (or state-action pair), used for learning and credit assignment. "removing the need for the value function in PPO"
- World model: An internal model that predicts environment dynamics or observations to support planning and reasoning. "build world models"
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging EMPO²’s hybrid on-/off-policy optimization, self-generated memory (“tips”), off-policy distillation (to operate without memory at inference), intrinsic novelty rewards, and off-policy stability via low-probability token masking.
- Industry — Retail/e-commerce: Autonomous shopping and procurement assistants
- What: Train web-interacting LLM agents to search, compare, and purchase products across diverse websites (akin to WebShop), reliably exploring unfamiliar site layouts and categories.
- Sector: Retail, finance (procurement)
- Tools/Products/Workflows:
- “Shopping Explorer” agent using EMPO² with a headless browser and a retrieval-backed tip memory
- Off-policy distillation pipeline to produce a robust, memory-free deployment model
- Intrinsic novelty rewards to systematically explore filters, categories, and price ranges
- Assumptions/Dependencies: Legal/ToS compliance, stable action APIs (click, type, scroll, buy), sandboxed browsing, reward shaping tied to match quality and cost, anti-bot mitigation.
- Industry — Enterprise IT/RPA: Form-filling and internal web app navigation
- What: Agents that generalize across dynamic enterprise dashboards, unknown forms, and new workflows (e.g., onboarding, finance approvals), using memory to avoid repeated mistakes, then distilling benefits into parameters for robust runtime behavior.
- Sector: Software/IT operations
- Tools/Products/Workflows:
- EMPO²-trained “RPA Explorer” that learns workflows via trial-and-error in a staging environment
- Tip generation/retrieval store for failure-mode notes, later distilled into the policy
- Guardrails/allowlists for safe actions and rollback policies
- Assumptions/Dependencies: Instrumented environments with measurable task rewards (completion/accuracy/time), secure log-prob access for RL updates, governance for sensitive data, compute for online RL.
- Industry — Software testing/QA: UI exploration, test generation, and fuzzing
- What: Agents automatically explore complex UIs to discover novel states (edge paths, error dialogs), generate tips on failure modes, and learn to reproduce high-yield exploratory trajectories without relying on memory at test time.
- Sector: Software engineering/DevOps
- Tools/Products/Workflows:
- “Exploration QA” pipeline: novelty-based intrinsic rewards mapped to coverage metrics (unique DOM paths/states)
- Token-masking stabilization for off-policy updates when replaying trajectories under non-tips prompts
- Assumptions/Dependencies: Reliable coverage/proxy reward metrics, safe sandboxing of apps, state de-duplication (embeddings + cosine similarity), reproducible environments.
- Academia — RL-for-LLM training framework adoption
- What: Use EMPO² to study exploration in multi-step text environments; compare on-policy vs. off-policy behaviors; benchmark memory-augmented rollouts and selective distillation.
- Sector: AI research
- Tools/Products/Workflows:
- Agent Lightning “empo2” recipe (open-source) integrated with verl and GRPO/GiGPO baselines
- Reproducible multi-step rollouts (ScienceWorld-like tasks), tip prompts, and retrieval ablations
- Assumptions/Dependencies: GPU resources, access to token-level log-probabilities, curated reward functions, institutional IRB/data-use compliance for any new environments.
- Education — Interactive science tutoring and simulated labs
- What: Deploy agents that explore simulated science tasks (ScienceWorld-like) and explain reasoning steps; memory tips serve as learner-facing hints; distilled policies reduce dependence on external memory during assessment.
- Sector: Education/EdTech
- Tools/Products/Workflows:
- “Lab Tutor” environment with task variants and structured rewards (correct procedures, safety steps)
- Tip retrieval for adaptivity; teacher-to-student distillation for assessments
- Assumptions/Dependencies: Age-appropriate content design, reward shaping aligned to pedagogical goals, safety checks for suggested actions, device/browser compatibility.
- Daily life — Personal shopping and comparison assistants
- What: A consumer-facing assistant that efficiently navigates unfamiliar e-commerce sites to find matching products, compares specs/prices, and maintains short-term memory during few trials but runs robustly without memory for routine use.
- Sector: Consumer applications
- Tools/Products/Workflows:
- Mobile/desktop agent integrating EMPO²-trained models with safe browsing and opt-in memory
- “Few-trial adaptation” mode that uses tips temporarily on unknown sites
- Assumptions/Dependencies: Consent for browsing and data storage, transparent disclosures, configurable spending limits, fallbacks to manual confirmation before purchase.
- Industry — Knowledge-base exploration and customer support triage
- What: Agents that explore heterogeneous internal KBs and ticketing systems, learn better routing and solution paths via memory tips, then distill behavior into a stable, memory-light assistant.
- Sector: Customer service/ITSM
- Tools/Products/Workflows:
- Tip memory capturing failure-to-resolution sequences
- Reward proxies: resolution rate/time-to-resolution/customer satisfaction
- Assumptions/Dependencies: Clear success signals, access controls, guardrails to prevent data leakage, privacy-preserving retrieval.
Long-Term Applications
Below are use cases that require further R&D, scaling to multimodal settings, tighter safety/governance, or more advanced retrieval and reward design.
- Healthcare — EMR navigation, order entry, and care-path exploration
- What: Agents that learn to navigate diverse EMRs, explore care-path options, and reduce workflow friction while maintaining strict safety guardrails and auditability.
- Sector: Healthcare
- Tools/Products/Workflows:
- EMPO² extended to multimodal inputs (text + UI visuals), fine-grained reward shaping (clinical correctness, policy compliance)
- Memory governance for PHI, plus safe off-policy distillation to reduce inference-time memory reliance
- Assumptions/Dependencies: Regulatory approval (HIPAA/GDPR), clinical validation, robust human-in-the-loop oversight, formal verification of action policies.
- Robotics — Generalizable household/task robots via memory-augmented multimodal RL
- What: Embodied agents that explore physical environments, use self-generated memory to avoid repeated failures, and distill exploratory gains into policies for reliable autonomy.
- Sector: Robotics/embedded systems
- Tools/Products/Workflows:
- EMPO² adapted to multimodal sensors (vision, audio, tactile), sim-to-real pipelines, and safe exploration strategies
- Intrinsic novelty rewards tied to physical state coverage (room layouts, object interactions)
- Assumptions/Dependencies: High-fidelity simulation, robust reward design, safety constraints (fall detection, restricted zones), scalable training compute.
- Industrial operations — Process optimization in digital twins
- What: Agents explore control policies in complex industrial simulations (energy plants, manufacturing lines), using memory to track failure patterns and distilling to robust policies for eventual deployment.
- Sector: Energy/manufacturing
- Tools/Products/Workflows:
- Digital twin integration with EMPO² (on-/off-policy hybrid), scenario libraries, tip generation for operator insights
- Safety envelopes and override systems
- Assumptions/Dependencies: Accurate simulators, domain-aligned rewards (efficiency, safety, throughput), rigorous testing before real-world use.
- Scientific discovery — Autonomous lab protocols and hypothesis exploration
- What: Agents that explore experimental procedures, record reflective tips (failure causes, promising variants), and distill learning into stable planning policies that reduce time to viable protocols.
- Sector: Chemistry/biotech/materials
- Tools/Products/Workflows:
- EMPO² extensions to lab automation platforms, structured logging of state/action/reward trajectories, and tip-based meta-notebooks
- Assumptions/Dependencies: Wet-lab safety compliance, interpretable reward functions (yield, purity, reproducibility), expert review.
- Finance/regulatory — Compliance workflow automation across changing portals
- What: Agents that navigate frequently changing regulatory sites (filings, disclosures), learn exploration strategies with tips, and distill reliable actions for routine filings.
- Sector: Finance/government
- Tools/Products/Workflows:
- EMPO² training in sandbox replicas of portals, audit trails of memory usage, policy constraints and reversible actions
- Assumptions/Dependencies: Legal approvals, robust identity and data protections, clear reward signals (successful filings, timeliness).
- Multi-agent systems — Shared memory and selective distillation across agents
- What: Teams of agents share tip memories (case libraries), then selectively distill high-advantage trajectories into individual policies for coordinated performance.
- Sector: Software/AI platforms
- Tools/Products/Workflows:
- “TipHub” with retrieval APIs and advantage-aware curation
- Cross-agent distillation protocols and privacy-preserving sharing
- Assumptions/Dependencies: Memory governance, conflict resolution across agents, secure communication, evaluation of emergent behaviors.
- Education — Adaptive curriculum generation and lifelong tutoring
- What: Systems that explore student learning states, automatically generate tailored exercises and hints (tips), and distill explorations into efficient teaching policies that generalize across curricula.
- Sector: Education/EdTech
- Tools/Products/Workflows:
- EMPO² with pedagogical reward shaping (retention, transfer, motivation), tip memory as explainable feedback
- Assumptions/Dependencies: Valid learning outcome measures, fairness and accessibility standards, parental/teacher oversight.
- Governance and policy — Standards for memory governance and exploratory autonomy
- What: Regulatory frameworks for storing/retrieving agent memory, auditing exploration risk, and controlling autonomy levels as behaviors are distilled into parameters.
- Sector: Policy/regulation
- Tools/Products/Workflows:
- “Memory Governance Module”: logging, retention policies, user consent
- “Exploration Risk Scoring”: thresholds for off-policy deployment, rollback plans
- Assumptions/Dependencies: Cross-industry consensus, compliance tooling, third-party audits, harmonized privacy rules.
Cross-cutting assumptions and dependencies (common to many applications)
- Access to environments with definable extrinsic rewards and reliable logging of state/action/reward trajectories.
- High-quality tip generation and retrieval (embedding models, similarity thresholds, memory size constraints).
- Availability of token-level log-probabilities and stable RL libraries (e.g., verl, agent-lightning) for on-/off-policy updates.
- Compute resources and MLOps for online RL, plus monitoring for training instabilities (importance ratios, low-probability token masking).
- Safety guardrails, sandboxed deployment, and human-in-the-loop oversight, especially in sensitive domains (healthcare, finance, robotics).
- Legal/privacy compliance for data and memory storage; transparent user consent and audit trails.
Collections
Sign up for free to add this paper to one or more collections.

