- The paper introduces AMPO, which adaptively replaces on-policy failures with teacher guidance to improve exploration and reasoning efficiency.
- The paper demonstrates significant performance gains on in-distribution and out-of-distribution tasks while using far fewer training samples.
- The paper validates that comprehension-based guidance selection and mixed-objective optimization are key to achieving robust pass@k and stable training dynamics.
Adaptive Multi-Guidance Policy Optimization: Enhancing LLM Reasoning via Diverse, On-Demand Teacher Guidance
Introduction
The paper introduces Adaptive Multi-Guidance Policy Optimization (AMPO), a reinforcement learning (RL) framework for LLMs that addresses the limitations of single-teacher mixed-policy RL approaches in reasoning tasks. AMPO leverages a pool of multiple teacher models, providing external guidance only when the on-policy model fails, and selects guidance adaptively based on the student model's comprehension. This approach is motivated by the need to overcome the exploration bottleneck and capacity-difficulty mismatch inherent in on-policy RLVR (Reinforcement Learning with Verifiable Rewards), and to avoid the diversity and generalization limitations of single-teacher distillation.
Methodology
Group Relative Policy Optimization (GRPO) Foundation
AMPO builds upon GRPO, which normalizes rewards within a group of sampled solutions for a given query, obviating the need for a value model and improving training efficiency. The GRPO objective is:
Ai,t=std(R(oi))R(oi)−mean(R(oi))
where R(⋅) is a rule-based verifier. The policy update uses a clipped surrogate objective, similar to PPO, but with group-based normalization.
Adaptive Multi-Guidance Replacement
AMPO introduces a Multi-Guidance Pool PG containing correct responses from multiple teacher models. For each query, the on-policy model generates G responses. If all responses are incorrect (reward below threshold τ), k of these are replaced with top-k off-policy responses from PG, selected via a comprehension-based metric. This ensures that external guidance is only injected when the model is unable to solve the problem, preserving self-exploration and minimizing unnecessary intervention.
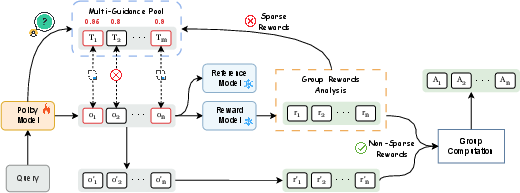
Figure 1: The AMPO training framework. It enhances exploration by adaptively replacing on-policy failures with external solutions from a Multi-Guidance Pool only when sparse rewards occur. The selection of external guidance is prioritized based on the Policy Model's comprehension score for each option, ensuring effective learning.
Comprehension-Based Guidance Selection
To maximize learning efficiency, AMPO ranks candidate teacher responses by the student model's likelihood of generating the correct answer given the teacher's reasoning path. The comprehension score rp is:
rp(ooff)=clip(exp(∣y∗∣1τi∈y∗∑logπθ(τi∣zoff,y<i∗)),0,1)
where ooff=(zoff,y) is the teacher's response, and y∗ is the ground-truth answer. This mechanism ensures that the student learns from guidance it is most likely to assimilate, balancing exploration and exploitation.
Mixed-Objective Policy Optimization
The final policy objective aggregates on-policy and off-policy losses, with sequence-level aggregation for off-policy responses to avoid length bias, and token-level aggregation for on-policy responses. The importance sampling ratios are adjusted according to the origin of each response (student or teacher policy).
Experimental Results
AMPO was evaluated on six in-distribution mathematical reasoning benchmarks and three out-of-distribution (OOD) tasks, using Qwen2.5-7B-Ins as the primary base model. AMPO outperformed GRPO by 4.3% on in-distribution and 12.2% on OOD tasks, and matched the performance of LUFFY (a strong single-teacher baseline) while using only 8.5k training samples compared to LUFFY's 46k. This demonstrates the data efficiency and generalization benefits of multi-teacher guidance.
Reasoning Efficiency
AMPO produces more concise solutions than SFT, SFT+GRPO, and LUFFY, with an average response length of 1268 tokens, indicating efficient reasoning without sacrificing accuracy.
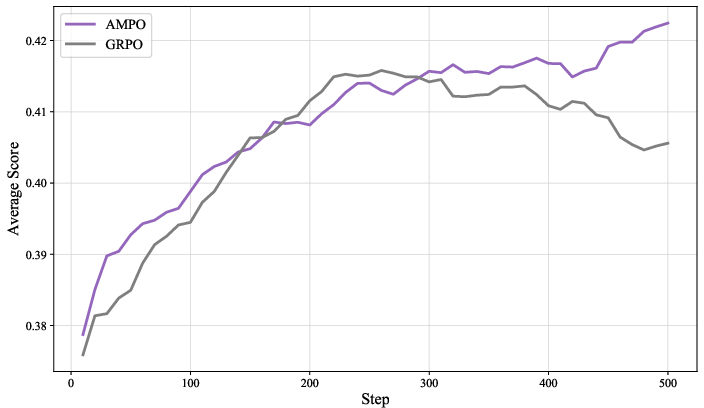
Figure 2: Training Average Score of Validation during GRPO and AMPO training.
Exploration and Pass@k Metrics
AMPO maintains higher pass@k values across multiple reasoning benchmarks, indicating superior exploration and the ability to generate diverse solutions. On challenging datasets such as AIME24/25, AMPO's pass@256 curve significantly outperforms both GRPO and the base model.
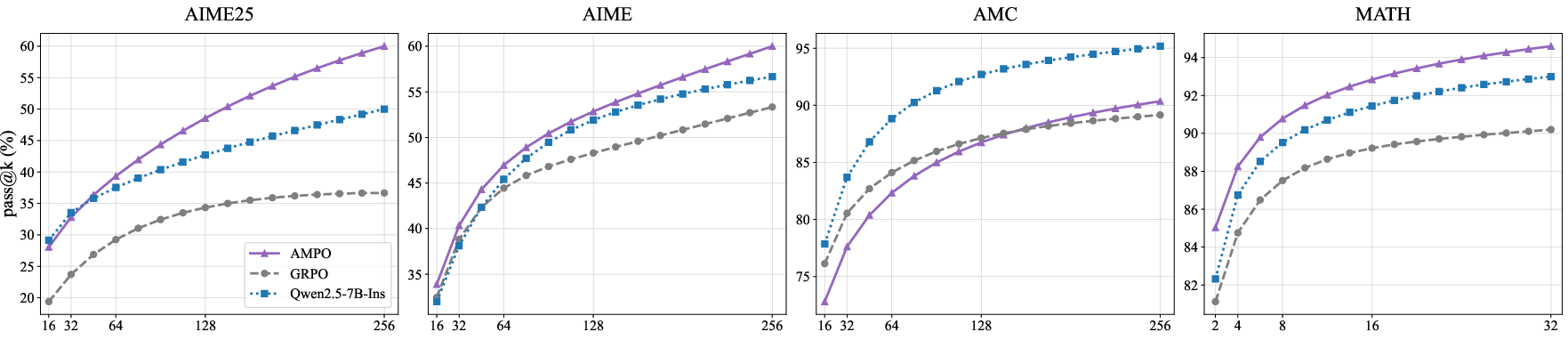
Figure 3: Pass@K Performance with different RL algorithms across several reasoning benchmarks.
Training Dynamics
AMPO exhibits higher and more stable training rewards, longer and more thoughtful responses, and maintains higher policy entropy throughout training compared to GRPO. This prevents premature convergence to suboptimal solutions and supports robust long-term learning.
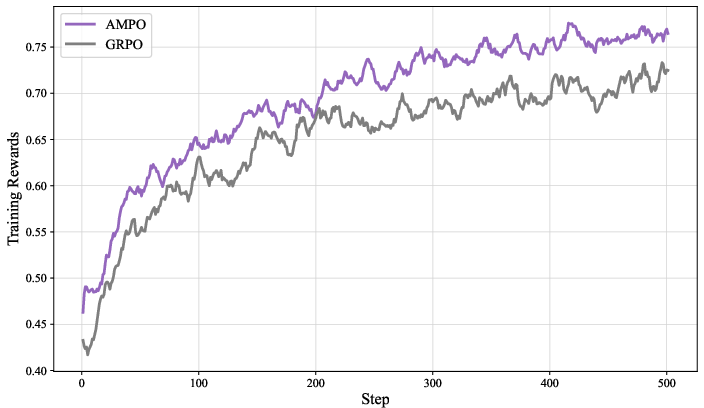
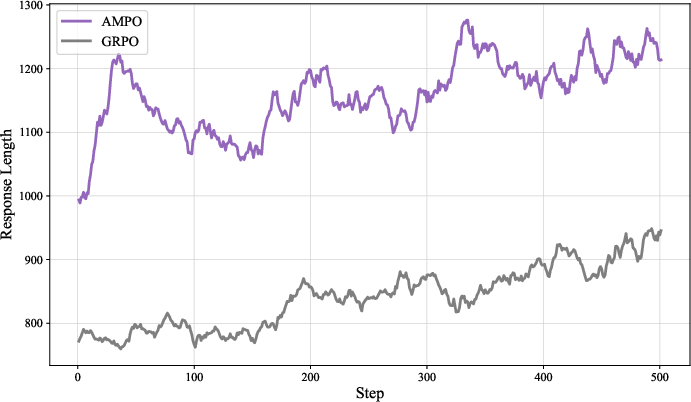
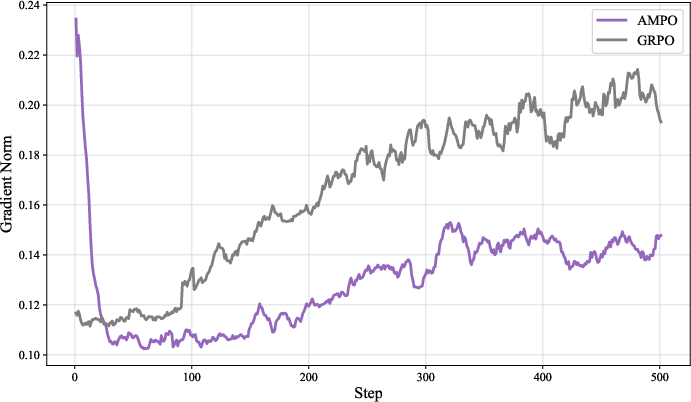
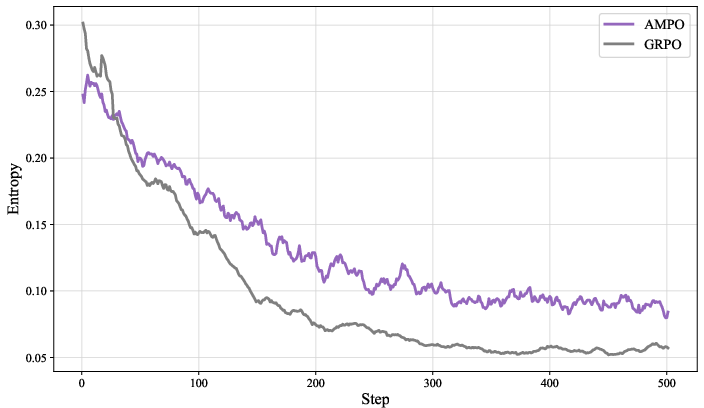
Figure 4: Training Rewards.
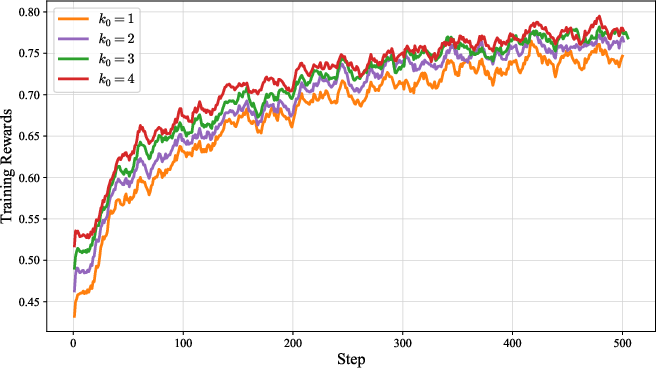
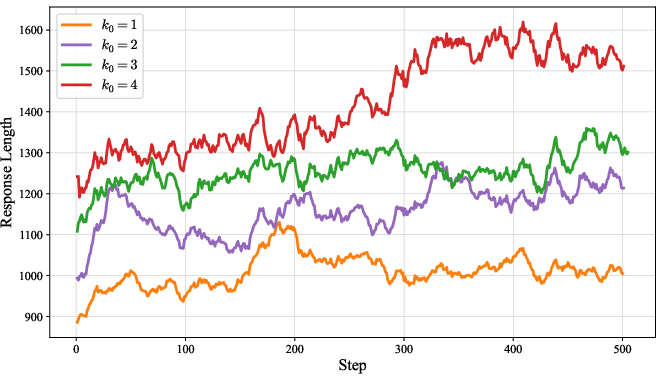
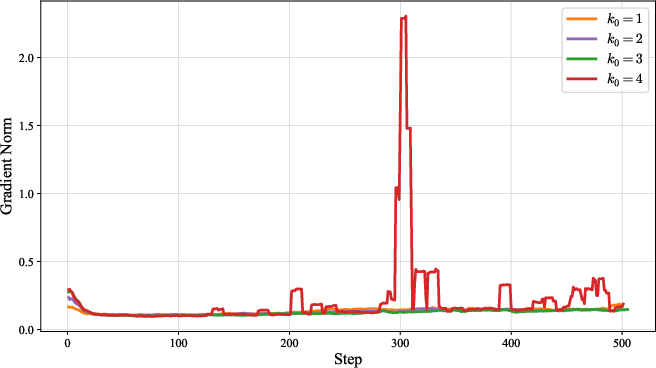
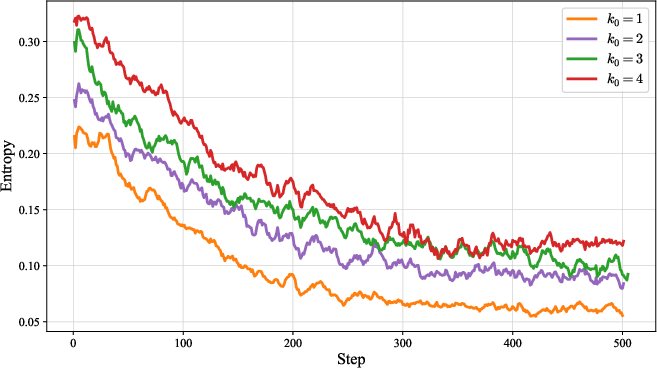
Figure 5: Training Rewards.
Ablation Studies
Ablations confirm the necessity of each AMPO component:
- Removing adaptive replacement increases response length without accuracy gain.
- Replacing comprehension-based selection with random or length-based heuristics reduces accuracy by up to 1.7%.
- Sequence-level aggregation for off-policy loss is critical to avoid bias.
Increasing the number of guidance replacements (k0) improves accuracy and exploration but can destabilize training and increase response length, indicating a trade-off between diversity and stability.
Teacher Pool Composition
Multi-teacher pools consistently outperform single-teacher setups, even when the single teacher is a much larger model (e.g., DeepSeek-R1). Combining LongCoT and ShortCoT teachers can further optimize the trade-off between accuracy and response length.
Computational Resource Analysis
AMPO incurs moderate computational overhead compared to GRPO, justified by its performance gains. The adaptive replacement mechanism is critical for efficiency, and teacher pool composition can be tuned to manage resource requirements.
Implications and Future Directions
AMPO demonstrates that multi-teacher, adaptive guidance in RLVR for LLMs yields superior reasoning, generalization, and exploration compared to single-teacher or static-mixing approaches. The framework is data-efficient, scalable, and robust across model sizes and architectures. The results challenge the prevailing assumption that a single, more powerful teacher is optimal for mixed-policy RL, showing that diversity and adaptivity are more important for robust reasoning.
Future research directions include:
- Systematic exploration of optimal teacher pool composition and size.
- Dynamic adjustment of k0 and rollout size for further stability and efficiency.
- Extension to other domains beyond mathematical reasoning, including code and multimodal tasks.
- Integration with verifier-free RLVR paradigms and open-ended exploration.
Conclusion
AMPO provides a principled, practical framework for leveraging diverse, on-demand teacher guidance in RLVR for LLMs. Its adaptive, comprehension-driven approach enables efficient exploration, robust generalization, and efficient reasoning, setting a new standard for mixed-policy RL in complex reasoning domains. The empirical results and ablation analyses substantiate the claim that multi-teacher, adaptive guidance is a more effective and scalable path to advanced LLM reasoning than reliance on a single, powerful teacher.

