- The paper introduces outcome-based exploration strategies to counteract RL-induced diversity degradation in LLM reasoning.
- It adapts UCB and batch-level exploration, with baseline corrections, to optimize both training metrics and test-time performance.
- Empirical and theoretical analyses demonstrate improved pass@k, robust accuracy, and enhanced generalization across datasets.
Outcome-based Exploration for LLM Reasoning: A Technical Analysis
Introduction and Motivation
The paper addresses a critical challenge in reinforcement learning (RL) post-training of LLMs for reasoning tasks: the systematic collapse of generation diversity when optimizing solely for outcome-based rewards (i.e., correctness of the final answer). While outcome-based RL yields substantial accuracy improvements, it induces a reduction in the diversity of generated solutions, which is detrimental for test-time scaling and real-world deployment where diversity is essential for robust performance. The authors provide a detailed empirical and theoretical analysis of this phenomenon and propose outcome-based exploration strategies to mitigate diversity collapse without sacrificing accuracy.
Diversity Degradation in RL Post-training
The authors frame RL post-training as a sampling process and empirically demonstrate that diversity loss is not confined to test-time but is already present during training. Specifically, as RL concentrates probability mass on correct answers for solved questions, this reduced diversity propagates to unsolved questions—a phenomenon termed "transfer of diversity degradation." This is evidenced by a lower number of distinct answers sampled on unsolved questions compared to the base model, even when the same number of samples is drawn.
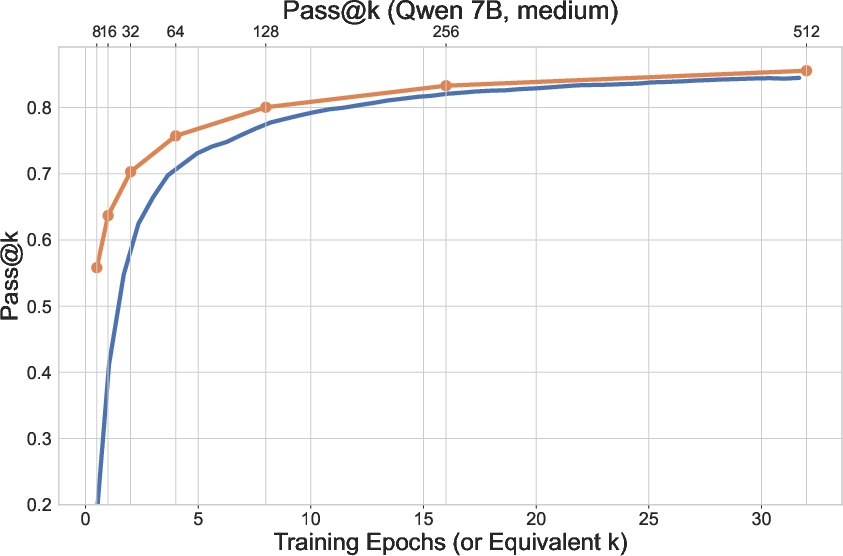
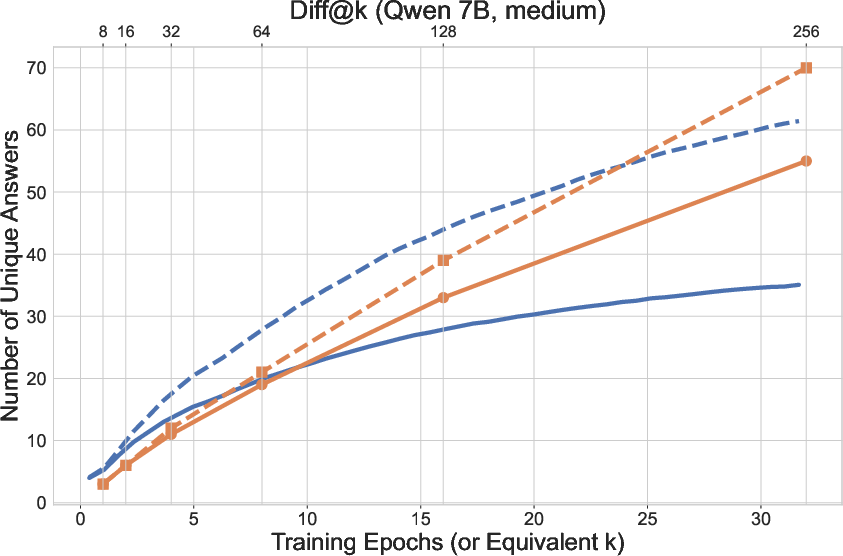
Figure 1: RL training reduces both the number of questions solved and the diversity of answers, with diversity degradation propagating from solved to unsolved questions.
The tractability of the outcome space in verifiable domains (e.g., mathematical reasoning) is also highlighted: the number of distinct final answers is small and enumerable, enabling direct optimization of answer diversity.
Outcome-based Exploration Algorithms
Historical Exploration via UCB
The authors adapt the classical Upper Confidence Bound (UCB) exploration strategy to the outcome space of LLM reasoning. The UCB bonus is computed based on the inverse square root of the historical visitation count of each answer, incentivizing exploration of rarely observed answers. However, naive application of UCB only improves training metrics (e.g., number of questions solved) but does not consistently enhance test-time diversity or generalization.
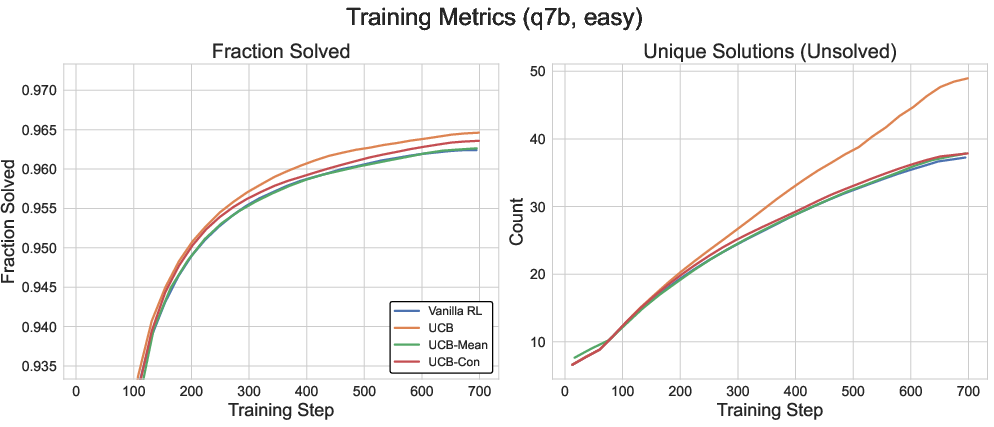
Figure 2: UCB-based exploration increases training diversity and question coverage but does not guarantee improved test-time diversity.
UCB with Baseline
To address the limitations of naive UCB, the authors introduce two baseline-corrected variants:
- UCB with Mean Baseline: The exploration bonus is centered by subtracting the batch mean, encouraging exploration of answers underrepresented in the current batch.
- UCB with Constant Baseline: A constant is subtracted from the UCB bonus, allowing explicit control over the trade-off between positive and negative exploration signals.
These variants yield improved test-time pass@k metrics across models and datasets, with the constant baseline variant achieving the best frontier performance for all k in most settings.
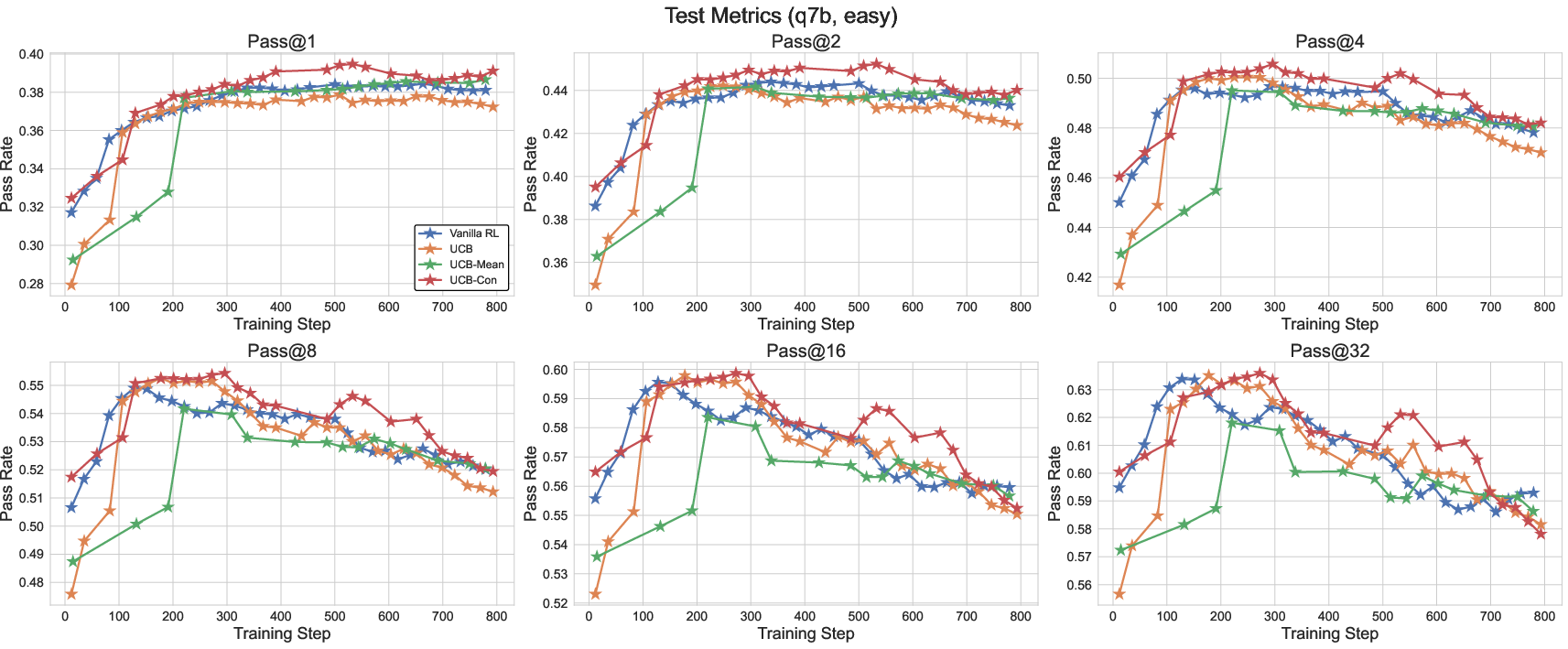
Figure 3: UCB with baseline variants consistently improve test-time pass@k metrics over the GRPO baseline.
Batch Exploration
Recognizing the distinction between historical and batch-level diversity, the authors propose a batch exploration strategy that penalizes within-batch answer repetition. This approach directly optimizes for batch-level diversity, which is more aligned with maximizing pass@k for large k at test time. Batch exploration achieves a better accuracy-diversity trade-off at the end of training, consistently producing more distinct answers per batch.
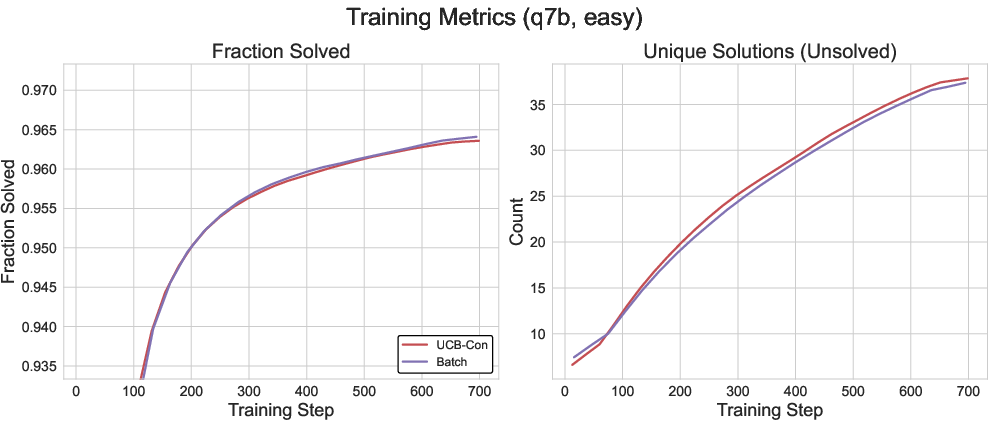
Figure 4: Batch exploration yields higher batch-level diversity compared to UCB, especially on unsolved questions.
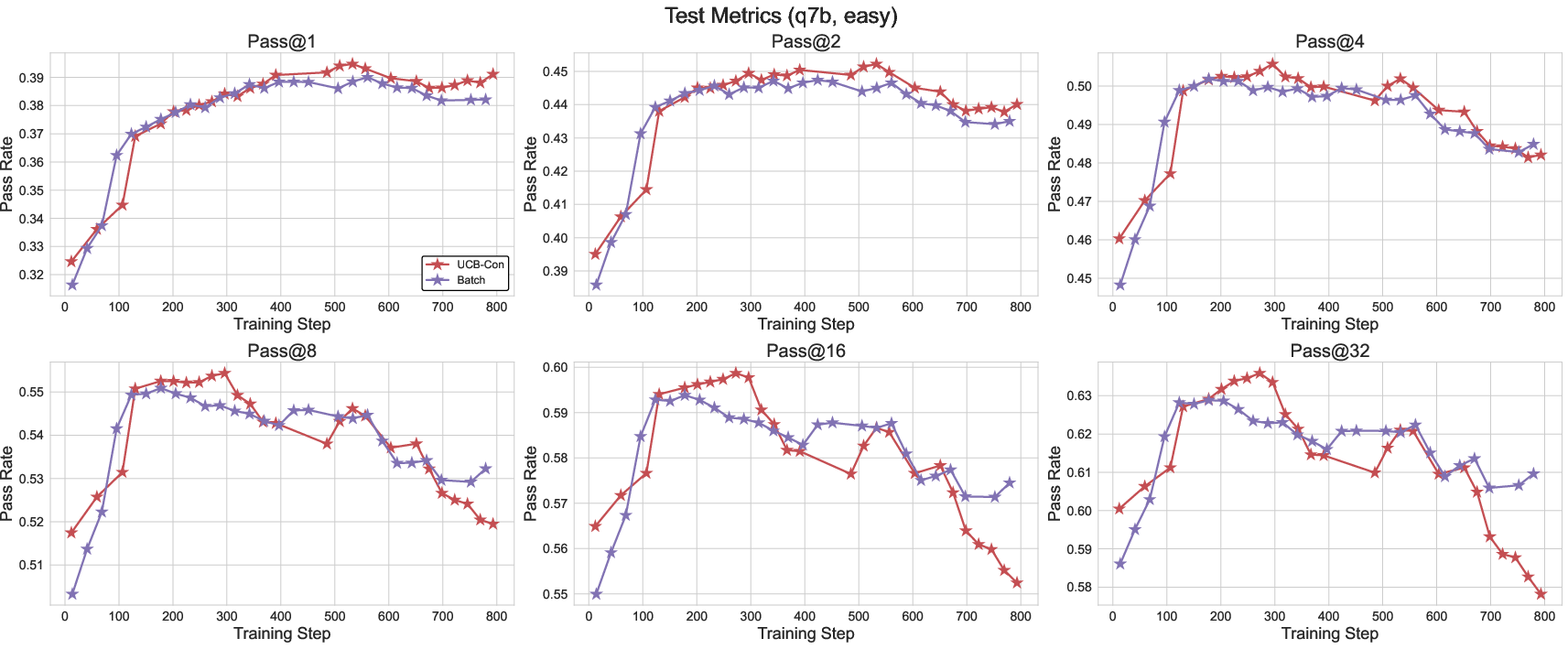
Figure 5: Batch exploration maintains superior pass@k for large k at test time, indicating improved diversity retention.
Analysis of Exploration Strategies
The paper provides a nuanced comparison between historical and batch exploration. Historical exploration (UCB-based) is superior for maximizing the number of questions solved and accumulating diverse answers over training, while batch exploration is more effective for maintaining diversity in the final model. The two strategies are shown to be complementary rather than mutually exclusive.
The authors also analyze entropy and batch-level diversity metrics, confirming that batch exploration leads to higher entropy and more distinct answers per batch, particularly for incorrect generations.
Theoretical Justification: Outcome-based Bandits
A theoretical analysis is presented via a novel outcome-based bandit model, which abstracts the gap between the large reasoning-trace space and the much smaller answer space. The analysis shows that, without generalization across traces yielding the same outcome, the regret scales with the number of traces. However, under a generalization assumption, outcome-based UCB exploration achieves regret scaling with the number of outcomes, justifying the proposed exploration strategies.
Empirical Results
Across multiple datasets (MATH, AIME, AMC) and models (Llama, Qwen), the proposed outcome-based exploration methods consistently outperform the GRPO baseline in both accuracy and diversity metrics. Notably, the exploration methods mitigate overoptimization, where vanilla RL degrades in pass@k after prolonged training.
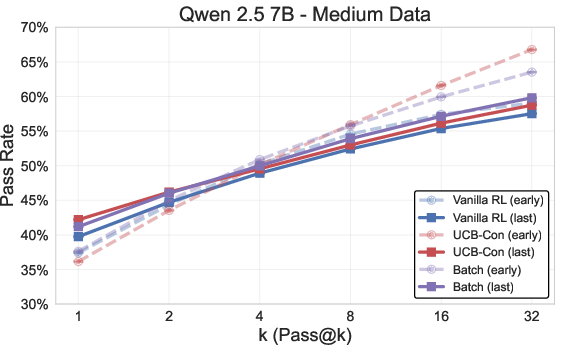
Figure 6: Outcome-based exploration methods (UCB, Batch) outperform the GRPO baseline in test pass@k across datasets and models, with improved trade-offs and mitigation of overoptimization.
Implications and Future Directions
The findings have significant implications for RL-based LLM post-training in verifiable domains. The outcome-based exploration framework is computationally tractable and agnostic to the underlying RL algorithm, making it broadly applicable. The distinction and complementarity between historical and batch exploration provide a foundation for designing hybrid strategies that optimize both accuracy and diversity.
The current methods are limited to domains with tractable outcome spaces and single-turn reasoning. Extending these techniques to multi-turn settings and non-verifiable domains remains an open challenge. Additionally, integrating outcome-based exploration with other diversity-promoting methods (e.g., entropy regularization, model-based verification) is a promising direction.
Conclusion
This work provides a rigorous empirical and theoretical investigation of diversity degradation in outcome-based RL for LLM reasoning. By introducing outcome-based exploration strategies—both historical (UCB-based) and batch-level—the authors demonstrate that it is possible to improve both accuracy and diversity, addressing a key limitation of standard RL post-training. The outcome-based bandit analysis further grounds these methods in a principled theoretical framework. These contributions advance the design of scalable, robust RL post-training algorithms for LLMs, with direct implications for real-world deployment in reasoning-intensive applications.