- The paper demonstrates that SFT using narrow teacher data causes up to 62% semantic diversity loss in the Think lineage, compared to only 4% during DPO.
- It employs four diversity metrics (SBERT, EAD, Vendi Score, NLI) to monitor diversity collapse across three distinct post-training strategies: Think, Instruct, and RL-Zero.
- Findings reveal that RL-Zero models retain about 93% of baseline diversity by bypassing SFT/DPO, though this comes with reduced reliability on reasoning tasks.
Output Diversity Collapse in Post-Training: A Lineage and Data Composition Perspective
Study Design and Methodological Framework
Post-training of LLMs, routinely applied to improve helpfulness and instruction compliance, is known to precipitate a substantial loss in output diversity. This phenomenon impedes sampling-based inference mechanisms and threatens content pluralism in creative and value-laden tasks. The present study deconstructs diversity collapse by tracing it across three parallel lineages of Olmo 3: Think (chain-of-thought distillation), Instruct (multi-source data, direct answering), and RL-Zero (direct RL, omitting SFT/DPO), encompassing 15 tasks with a suite of four complementary diversity metrics (SBERT, EAD, Vendi Score, NLI).
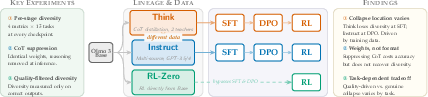
Figure 1: Study design tracing output diversity loss across Olmo 3 post-training lineages to identify when and why collapse occurs.
The experimental protocol leverages explicit checkpoints for all post-training stages, equipping the analysis with precise stage attribution for diversity reduction. Crucially, the study scrutinizes the role of training data composition, generation format, and post-training recipe, isolating their contributions and interactions.
Empirical Characterization of Diversity Collapse
The analysis reveals a sharp asymmetry in the location and magnitude of diversity collapse contingent on data composition. In the Think lineage, narrow two-teacher CoT distillation induces a precipitous collapse during SFT, erasing up to 62% of baseline semantic diversity; little (4%) is lost at the subsequent DPO stage. Conversely, the Instruct lineage—initialized from Think-SFT and augmented with broader multi-source data—experiences a more modest SFT loss (38%), but suffers a significant collapse at DPO (23%). RL stages exert lineage-specific effects: a modest recovery in Think and further narrowing in Instruct.
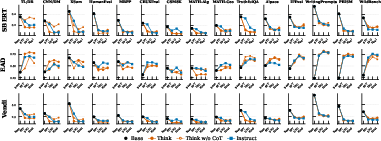
Figure 2: SBERT, EAD, and Vendi Score across post-training stages for Think, Instruct, and RL-Zero. Collapse occurs at SFT in Think, DPO in Instruct; CoT suppression does not restore diversity.
RL-Zero models, trained direct from base with RL and bypassing SFT/DPO, retain substantially greater diversity (~93% of baseline on average). Final diversity, as measured by Vendi Score, converges to similar floors across Think and Instruct (1.3–1.6 effective modes), with RL-Zero consistently higher.
Lexical diversity (EAD) is largely preserved or increased, even as semantic diversity collapses, indicating aligned models use highly varied phrasing but semantically homogenized content. On creative writing (WritingPrompts), EAD increases from 0.23 to 0.80, while SBERT falls from 0.54 to 0.20—mirroring patterns in other open-ended tasks.
Value-pluralism (e.g., PRISM, TruthfulQA) exhibits the deepest Think collapse, as the restricted teacher set cannot represent the full spectrum of legitimate perspectives. NLI analysis confirms that aligned models still generate logically distinct outputs, albeit with semantic convergence.
Suppressing CoT generation format at inference in Think models (“Think-not-thinking”) does not reverse diversity collapse; SBERT and Vendi metrics remain identical to Think, indicating that collapse is encoded in model weights, not imposed by generation format. However, accuracy on challenging reasoning tasks drops markedly with CoT suppression. This demonstrates that the diversity loss is not a format artifact, but a consequence of the learned distribution shaped during post-training.
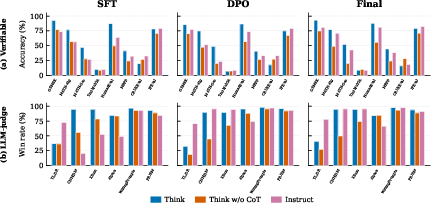
Figure 3: Quality of generations for Think, Think-not-thinking, and Instruct across stages. Top: accuracy on verifiable tasks. Bottom: LLM-judge win rates for open-ended/creative tasks.
CoT improves reliability for hard tasks by enabling the model to follow its learned strategy, yet does not widen the answer-level diversity distribution.
Quality-Filtered Diversity: Decomposition and Practical Impact
Diversity loss is decomposed into quality-control (removal of incorrect outputs) and genuine narrowing among correct outputs. The proportion attributable to genuine narrowing is highly task-dependent: 83% for IFEval, 57–64% for mathematical reasoning, and less than 10% for HumanEval.
Correct-answer diversity is critical for majority-voting and pass@k scaling. Aligned models with collapsed correct distributions gain only minimal benefit from repeated sampling, whereas base models with greater correct diversity extract substantial improvements. For instance, Think's majority-vote gain on GSM8K is +0.4%, compared to +24% for Base and +22–26% for RL-Zero.
Code tasks, analyzed with AST subtree Jaccard and UniXcoder metrics, confirm structural homogenization among correct outputs in aligned models.
Cross-Lineage Patterns and Theoretical Implications
Data composition affects the trajectory of collapse, not the final diversity floor. Algorithmic shifts (e.g., removing KL penalties, direct RL from base) are necessary for substantial changes to the diversity floor. For SFT, broadening the teacher pool mitigates collapse, but only alters the descent, not the ultimate homogenization.
SFT with cross-entropy on narrow data performs MLE on low-entropy distributions, inducing collapse. DPO, with mode-seeking reverse-KL, further compresses distributions unless the model is already collapsed. RL stages can partially reverse DPO compression if diversity exists post-DPO.
Task dependence governs whether diversity loss is beneficial or harmful: code generation sees helpful filtering, value-laden generation risks pluralism loss, and summarization trades diversity for quality.
Distributional diversity (semantic/logical spread) does not guarantee representational pluralism (distinct perspectives). Targeted probes beyond statistical diversity, including demographic and cultural axes, are required to assess the retention of value diversity.
Conclusion
Comprehensive tracing of output diversity across Olmo 3 post-training lineages demonstrates that diversity collapse is dictated primarily by data composition during SFT, not post-training algorithms or generation format. RL from base (RL-Zero) preserves diversity but sacrifices reliability. The quality-diversity tradeoff is task-specific; on some tasks nearly all narrowing reflects error filtering, on others genuine collapse among correct outputs dominates. Practical recommendations include broadening SFT sources and employing KL-free RL to mitigate collapse. However, only fundamental changes to preference optimization objectives appear sufficient to alter the diversity floor. Future investigations should deepen analysis of representational diversity, explore reasoning-path diversity, and probe interventions in domain-adaptive data composition.
For detailed breakdowns by task and metric, refer to data in the appendices and the accompanying figures in the study. The findings have implications across inference scaling, majority-voting methods, and content pluralism, suggesting targeted interventions at the data and algorithmic levels for diversity preservation in aligned LLMs.