- The paper introduces Dynamic Context Evolution (DCE) to mitigate cross-batch mode collapse, achieving 0% collapse and maintaining 17–18 conceptual clusters per seed across domains.
- It employs a modular pipeline—verbalized tail sampling, semantic memory deduplication, and adaptive prompt evolution—to effectively filter and steer diverse outputs.
- The framework is model-agnostic, incurs negligible computational overhead, and enhances synthetic data diversity, thereby improving downstream performance.
Dynamic Context Evolution for Scalable Synthetic Data Generation
This work articulates and empirically characterizes the phenomenon of cross-batch mode collapse in LLMs: when repeatedly prompted in stateless API calls, LLMs exhibit rapid loss of output diversity, leading to significant redundancy across batches. The model repeatedly generates high-probability outputs even across independent calls, and without persistent memory, previously sampled points in the distribution are resurfaced with only superficial variation. This collapse is shown to be severe in domains such as educational item generation (34% near-duplicate rate after 200 batches) and nontrivial across practical settings in synthetic data generation. Ad hoc industry practices (post-hoc deduplication, prompt paraphrasing, seed rotation) are the de facto mitigations, yet none offer principled or reproducible diversity control.
Dynamic Context Evolution: Mechanisms and Pipeline Design
Dynamic Context Evolution (DCE) is introduced as a unified, modular framework targeting cross-batch diversity degradation. The pipeline comprises three orthogonal interventions:
- Verbalized Tail Sampling (VTS): Each generated candidate is assigned a self-assessed probability by the model, indicating its estimated typicality (P). Candidates deemed too obvious (P≥τ) are filtered out, directly controlling for depth in the conceptual space.
- Semantic Memory Deduplication: Across batches, all accepted candidates are embedded into a high-dimensional semantic vector space and stored. Any new candidate exceeding a cosine similarity threshold (δ) to memory bank entries is rejected, enabling persistent, session-independent semantic-level deduplication.
- Adaptive Prompt Evolution: Prompts are dynamically constructed based on the evolving memory state, recent acceptances, and targeted diversity strategies (gap targeting, assumption inversion, cross-industry stimulus, constraint variation). This mechanism actively steers generation into underexplored regions.
The system is implemented without reliance on custom model architectures, finetuning, or modification of LLM decoding parameters (which are often not available, as for gpt-5-mini). Prompting and filtering utilizes only standard API calls.
Filtering Space and Diversity Metrics
DCE operationalizes diversity retention via the Effective Diversity Volume (EDV) metric, integrating both surprisingness (via VTS-estimated probability) and semantic novelty (embedding-based distance from prior memory):
- EDV is computed multiplicatively over batch acceptances, rewarding candidates that are simultaneously non-obvious and distant from previous concepts. This conjunction is pivotal for ensuring that retained samples are genuinely both original and informative.
- Collapse rate is defined as the fraction of later-batch items duplicating early-batch concepts (above thresholded cosine similarity).
- Clustering of accepted ideas (using HDBSCAN) provides a measure of conceptual breadth.
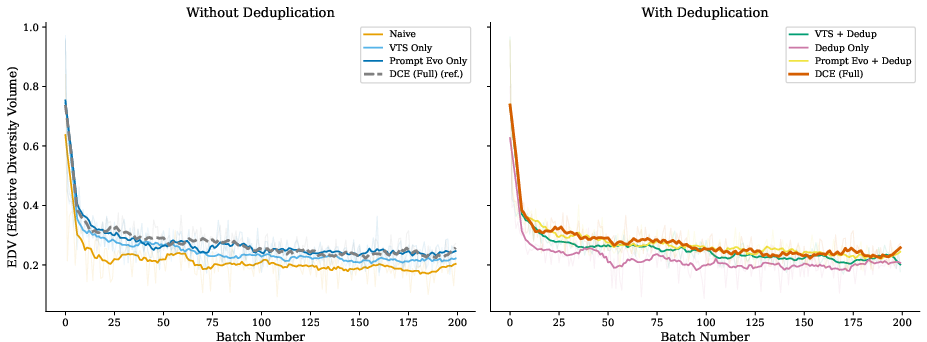
Figure 1: EDV over 200 batches (10-batch rolling averages, raw values faintly shown), partitioned by deduplication. Left: methods lacking deduplication show steady EDV decline; right: dedup-enabled methods realize 0% collapse, with DCE maintaining superior EDV throughout, highlighting the necessity of prompt evolution on top of deduplication.
Empirical Study: Domain and Model Generality
Extensive empirical evaluation is conducted across three domains (sustainable packaging, exam question synthesis, creative writing prompts) and two LLM families (gpt-5-mini, claude-haiku-4-5). Rigorous ablation experiments demonstrate the following:
- Collapse Prevention: Any configuration employing semantic memory deduplication achieves 0% collapse; configurations lacking it (including prompt evolution alone) do not.
- Diversity Retention: DCE outperforms naive, VTS-only, and dedup-only baselines in EDV retention and most consistently realizes high conceptual cluster counts (17–18 HDBSCAN clusters per seed at 200 batches, in contrast with naive's 2–17).
- Synergy of Mechanisms: Neither deduplication nor adaptive prompts alone suffice: filtering without steering narrows the output space, steering without filtering admits nontrivial semantic duplicates. Only the full DCE pipeline achieves both collapse elimination and maximal breadth.
- Cost: The pipeline incurs negligible computational/monetary overhead, with per-1,000-candidate costs below \$0.60 and latency suitable for practical deployment.
Ablation and Sensitivity Analyses
Comprehensive ablations establish the necessity and complementarity of each DCE component:
- Dedup-only configurations prevent collapse but generate fewer conceptual clusters.
- Prompt evolution only maintains breadth but does not prevent duplication.
- DCE exhibits robustness to VTS (τ) and deduplication (δ) thresholds over a wide range.
Analysis of the diversity-quantity tradeoff informs practical selection of dedup thresholds: in high-redundancy domains, relaxing δ (e.g., 0.90 instead of 0.85) increases dataset size without compromising collapse prevention, directly benefiting downstream classifier training.
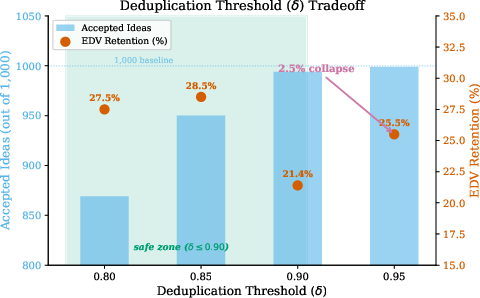
Figure 2: Diversity-quantity tradeoff as a function of dedup threshold δ. Bars: accepted idea count; markers: EDV retention. The 1000-candidate baseline is indicated; collapse appears at δ=0.95, establishing an empirical upper limit.
Embedding Space Visualization and Diversity Dynamics
Visualization of embedding spaces with UMAP projections reveals stark differences:
- Under naive prompting, early and late batch ideas densely overlap, indicating substantial mode collapse despite apparent lexical variety.
- DCE maintains spatial separation, with late-batch outputs occupying genuinely new regions.
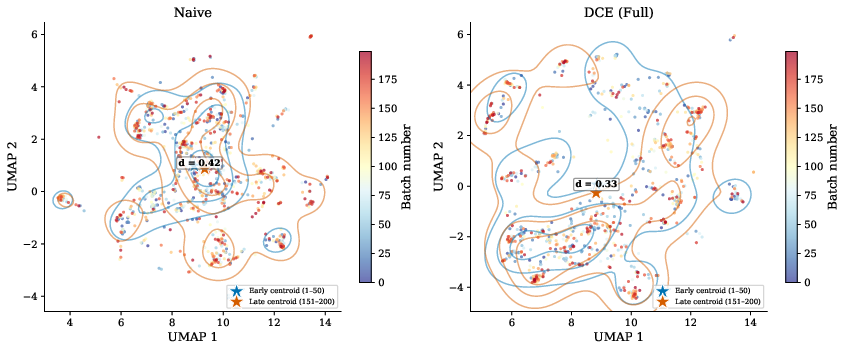
Figure 3: UMAP projection of generated ideas for naive (left) vs. DCE (right), with point color encoding batch number. Under DCE, batch trajectories explore distinct regions over time; naive prompting shows collapse towards previously populated areas.
Key Findings and Theoretical Implications
Strong Numerical and Empirical Claims
- 0.0% ± 0.0% collapse rate is consistently achieved by DCE in all tested domains and models, as opposed to 5.6% ± 2.0% for naive prompting.
- Consistent conceptual clustering: DCE retains 17–18 HDBSCAN clusters per seed, versus high volatility for naive runs.
- Model-agnostic benefit: DCE yields even greater gains on highly redundant LLMs (e.g., reducing rejection from 30% to 11% for Claude Haiku 4.5).
- Downstream utility: Classifiers trained on DCE-filtered outputs outperform those trained on naive or dedup-only synthetic data when sample size is not limiting.
Contradictory Evidence to Common Assumptions
- Token-level sampling parameters are insufficient for true diversity when model API does not expose them, and even when available, these controls only induce lexical variation, not conceptual novelty.
- Prompt steering and memory are both individually insufficient—the prevailing industry assumption that deduplication or prompt variation alone resolves diversity decay is rigorously invalidated.
Practical and Theoretical Implications
Practical Implications
- DCE furnishes a reproducible, parameterizable, API-compatible framework for generating large-scale, diverse, synthetic datasets with minimal engineering overhead.
- The framework is directly portable across heterogeneous LLM APIs and domains and does not rely on internal model modification, suited to current and future production LLM deployment environments.
Theoretical Implications and Future Prospects
- The formalization of cross-batch mode collapse suggests that any approach to synthetic data generation with LLMs must address statelessness at both the semantic and managerial levels.
- DCE demonstrates that structured pipeline-level interventions can compensate for fundamental architectural deficiencies (lack of cross-call memory) in current LLM APIs.
- Future work could focus on adaptive selection of diversity-promoting strategies, improved category clustering for prompt evolution, and algorithmic scaling for extremely large candidate sets (e.g., efficient approximate nearest neighbor deduplication).
- There are open questions regarding the optimal design of depth/breadth metrics, particularly in application-specific conceptual spaces, and the interplay between diversity, downstream performance, and training regime dynamics in large synthetic corpora.
Conclusion
Dynamic Context Evolution defines a rigorous, practical solution to the persistent challenge of cross-batch diversity collapse in LLM-generated synthetic data. Its deployment yields deterministic elimination of semantic collapse, reliable expansion of conceptual coverage, and direct applicability to practical synthetic dataset generation pipelines. The mechanisms described are robust, generalizable, and computationally efficient; no fine-tuning or model customization is required. This framework will likely serve as a foundational component in large-scale synthetic data pipelines and future research exploring the interface between controlled diversity and automated data generation (2604.07147).

