- The paper introduces DARLING, a diversity-aware reinforcement learning framework that integrates semantic partitioning with multiplicative reward fusion.
- The approach achieves superior quality and diversity metrics on tasks such as creative writing and competition math by optimizing semantic clustering.
- Multiplicative fusion and a learned semantic classifier enable robust, scalable optimization that counteracts the common tradeoff between response quality and diversity.
Joint Optimization of Diversity and Quality in LLM Generations
Motivation and Problem Statement
The post-training of LLMs has predominantly focused on maximizing response quality, often at the expense of output diversity. This leads to a phenomenon where models, after reinforcement learning (RL) with human feedback or reward models, produce highly similar or even near-duplicate responses to the same prompt, limiting their utility in creative, exploratory, or open-ended tasks. The paper introduces Diversity-Aware Reinforcement Learning (DARLING, denoted as "black"), a framework that explicitly incorporates semantic diversity into the RL objective, aiming to jointly optimize for both response quality and diversity.
Methodology: Diversity-Aware Reinforcement Learning (DARLING)
DARLING extends the standard RL post-training paradigm by introducing a learned semantic partition function to measure diversity at the response level. The core pipeline is as follows:
- Semantic Partitioning: For each prompt, multiple model generations are clustered into equivalence classes using a learned classifier that predicts semantic similarity, rather than relying on surface-level lexical overlap.
- Diversity Metric: The diversity of a response is defined as the normalized count of semantically distinct responses within the set of generations for a prompt.
- Reward Fusion: The effective reward for each response is computed as the product of its quality reward (from a reward model or task-specific metric) and its normalized diversity score. This multiplicative fusion ensures that only responses that are both high-quality and semantically distinct are strongly reinforced.
- RL Objective: The diversity-aware reward is integrated into a Group Relative Policy Optimization (GRPO) framework, with modifications to advantage normalization and loss aggregation to improve stability and avoid bias toward longer sequences.
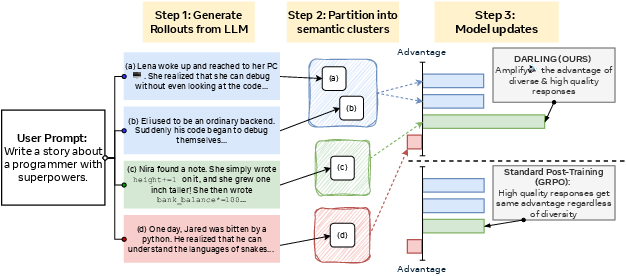
Figure 1: Diversity-Aware Reinforcement Learning (black): LLM generations are partitioned into semantically equivalent clusters; black amplifies the probability of diverse, high-quality responses.
Semantic Diversity Classifier
A key technical contribution is the use of a learned classifier to determine semantic equivalence between responses. This classifier is trained on human-annotated data and extended to handle long contexts (up to 8192 tokens). The classifier outperforms proprietary models in matching human judgments of semantic similarity, as shown in the paper's evaluation.
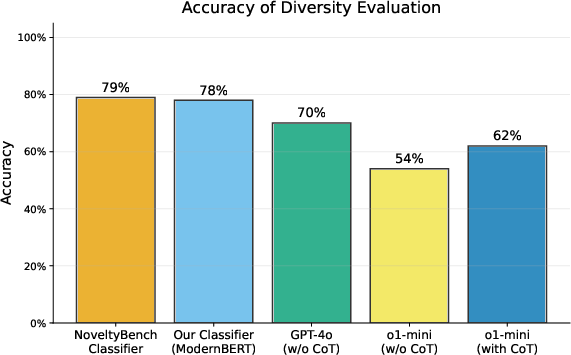
Figure 2: Classifier-based approaches outperform proprietary models in determining semantic similarity between responses.
Experimental Results: Non-Verifiable and Verifiable Tasks
Non-Verifiable Tasks
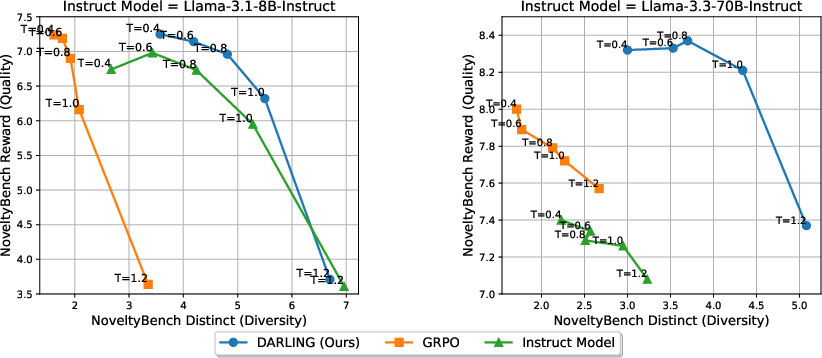
DARLING is evaluated on instruction following and creative writing tasks using Llama-3.1-8B-Instruct and Llama-3.3-70B-Instruct as base models. The method is compared against GRPO, DivPO, and GRPO-Unlikeliness baselines. Evaluation metrics include AlpacaEval 2.0, ArenaHard v2.0, EQ-Bench (ELO), and NoveltyBench (semantic and lexical diversity).
Key findings:
Qualitative analysis on EQ-Bench reveals that DARLING-trained models excel in rubrics such as "Interesting and Original" and "Avoids Cliche," directly attributable to increased semantic diversity.
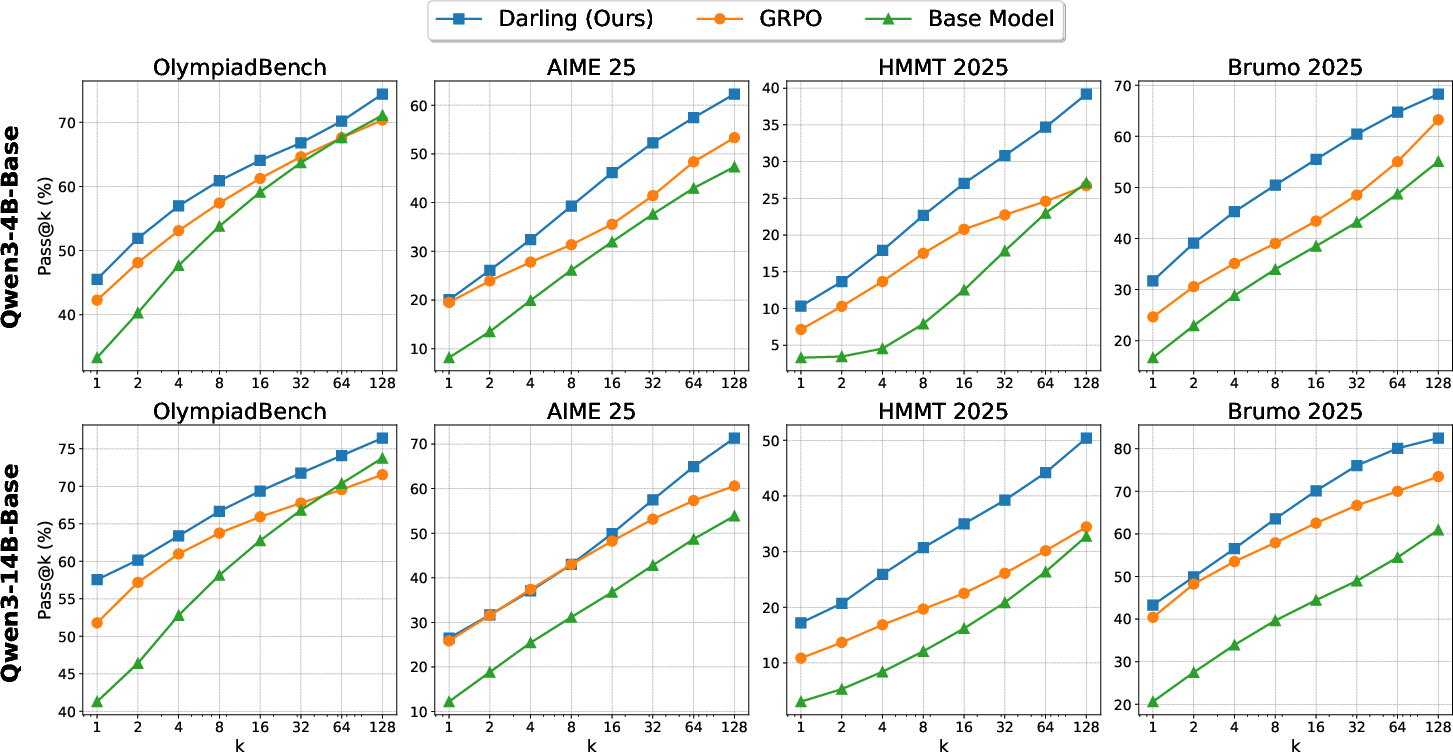
Verifiable Tasks (Competition Math)
DARLING is further evaluated on competition math benchmarks (AIME25, OlympiadBench, HMMT, Brumo) using Qwen3-4B-Base and Qwen3-14B-Base. The diversity classifier is adapted to the math domain via additional annotation and fine-tuning.
Key findings:
Ablation Studies
The paper conducts extensive ablations to justify design choices:
- Multiplicative vs. Additive Reward Fusion: Multiplicative fusion of quality and diversity rewards yields more robust improvements and avoids the need for scale tuning.
- Semantic vs. Lexical Diversity: Using n-gram-based diversity rewards underperforms semantic partitioning, especially in tasks requiring deep understanding (e.g., math), and can be gamed by the model.
- Advantage Normalization: Removing standard deviation normalization in advantage calculation improves performance in settings with dense, noisy rewards, as it prevents amplification of spurious differences.
Implementation Considerations
- Classifier Training: The semantic equivalence classifier must be trained on domain-relevant, human-annotated data and extended to the maximum context length expected in deployment.
- Batching and Rollouts: For each prompt, multiple rollouts are required to compute diversity; this increases computational cost but is necessary for accurate diversity estimation.
- Reward Model Selection: The quality reward should be well-calibrated and aligned with the target application; the diversity reward is domain-agnostic but depends on classifier accuracy.
- Scalability: The method is demonstrated at both 8B and 70B parameter scales, with consistent improvements, indicating scalability to large models.
Implications and Future Directions
DARLING demonstrates that explicit optimization for semantic diversity during RL post-training can simultaneously improve both the quality and variety of LLM outputs, contradicting the common assumption of an inherent tradeoff. This has significant implications for applications in creative generation, scientific discovery, and problem solving, where diversity is critical.
The approach is orthogonal to and compatible with inference-time diversity-promoting techniques (e.g., temperature scaling, diverse beam search) and can be combined with them for further gains. The reliance on a learned semantic classifier opens avenues for further research into more generalizable and robust diversity metrics, potentially leveraging contrastive or self-supervised objectives.
The findings suggest that future LLM training pipelines should incorporate diversity-aware objectives, especially for tasks where exploration and creativity are valued. The method's success in both non-verifiable and verifiable domains indicates broad applicability.
Conclusion
DARLING (black) provides a principled and empirically validated framework for jointly optimizing quality and diversity in LLM generations. By leveraging a learned semantic partition function and integrating diversity into the RL reward, the method overcomes diversity collapse and achieves superior performance across a range of tasks and model scales. This work establishes a new standard for diversity-aware LLM post-training and motivates further exploration of semantic-level diversity metrics and their integration into large-scale LLM optimization.