Bilevel Optimization of Agent Skills via Monte Carlo Tree Search
Published 17 Apr 2026 in cs.AI | (2604.15709v1)
Abstract: Agent \texttt{skills} are structured collections of instructions, tools, and supporting resources that help LLM agents perform particular classes of tasks. Empirical evidence shows that the design of \texttt{skills} can materially affect agent task performance, yet systematically optimizing \texttt{skills} remains challenging. Since a \texttt{skill} comprises instructions, tools, and supporting resources in a structured way, optimizing it requires jointly determining both the structure of these components and the content each component contains. This gives rise to a complex decision space with strong interdependence across structure and components. We therefore represent these two coupled decisions as \texttt{skill} structure and component content, and formulate \texttt{skill} optimization as a bilevel optimization problem. We propose a bilevel optimization framework in which an outer loop employs Monte Carlo Tree Search to determine the \texttt{skill} structure, while an inner loop refines the component content within the structure selected by the outer loop. In both loops, we employ LLMs to assist the optimization procedure. We evaluate the proposed framework on an open-source Operations Research Question Answering dataset, and the experimental results suggest that the bilevel optimization framework improves the performance of the agents with the optimized \texttt{skill}.
The paper introduces a bilevel optimization framework using MCTS to separate discrete structural decisions from content refinement.
It employs LLM-guided techniques to propose and evaluate modifications, yielding statistically significant improvements on the ORQA benchmark.
The approach demonstrates robust skill engineering by effectively managing LLM stochasticity and optimizing high-dimensional agent configurations.
Bilevel Optimization of Agent Skills via Monte Carlo Tree Search: Technical Summary
Problem Formulation and Motivation
The paper "Bilevel Optimization of Agent Skills via Monte Carlo Tree Search" (2604.15709) introduces a systematic approach to optimizing LLM agent skills—structured bundles of instructions, scripts, metadata, and supporting resources that define agent behavior for particular task classes. The heterogeneous, interdependent, and combinatorial nature of skill design precludes straightforward optimization: structural decisions about included components interact tightly with the natural language and code that form their content, and the decision space is large and highly nonconvex.
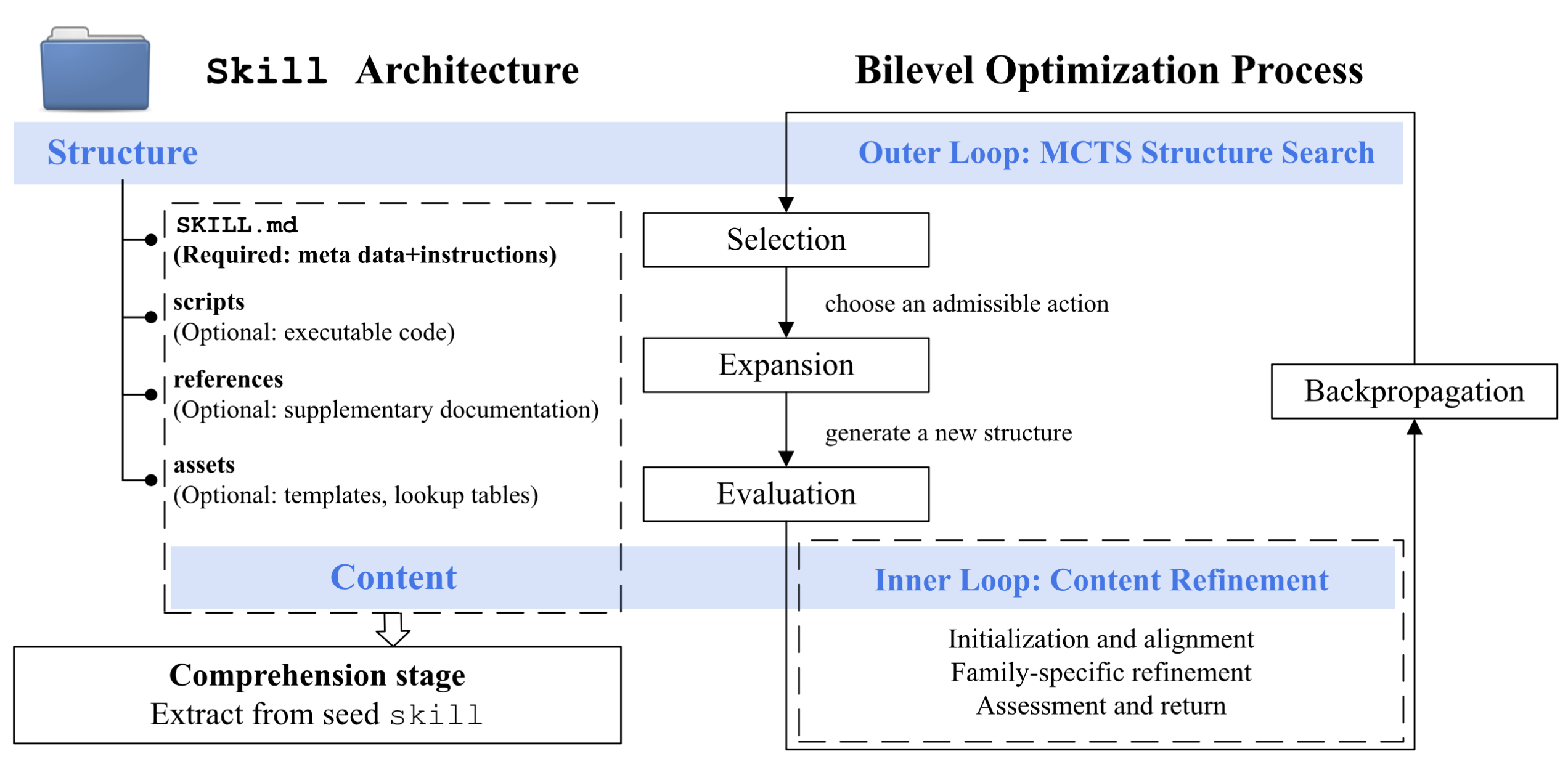
The authors formalize skill optimization as a bilevel optimization problem, where the outer loop searches over discrete skill structures (directory layout, component presence/order), and the inner loop optimizes the content instantiations (instructions, scripts, references, assets) within any fixed structure. Both loops must address unstructured, discrete variables under practical constraints (spec compliance, token budgets). This hierarchical separation enables more efficient and targeted search by decomposing high-level architectural design from low-level content engineering.
Figure 1: Bilevel Optimization Architecture for Agent Skill Modules.
Methodological Framework
Bilevel Optimization Procedure
Skill Representation: Skills are formalized as tuples S=(θ,ϕ), with θ encoding discrete structural decisions and ϕ representing all content compatible with θ (e.g., instruction Markdown, routing metadata, scripts).
Outer Loop (Structure Search): Employs Monte Carlo Tree Search (MCTS) to sequentially explore structure configurations. Each tree node encodes a candidate θ, with actions in the space of structural edits (add, remove, reorganize component types, etc.).
Inner Loop (Content Refinement): For a structure θ′, content ϕ0(θ′) is computed via a "bridge" operation that repurposes reusable information from parent nodes. Refinement then occurs within a bounded budget, using family-specific routines matched to the edit type (e.g., instruction rewriting, script adjustment, section triage).
Evaluation: Each structure-content pair (θ′,ϕ′) is evaluated via downstream task execution (LLM agent on target benchmarks), with results propagated up the MCTS tree (reward, diagnostic metrics).
This explicit separation provides explicit attribution of evaluation feedback to structural revisions and allows conservative, pessimistic content selection to mitigate the impact of LLM stochasticity and noisy evaluations.
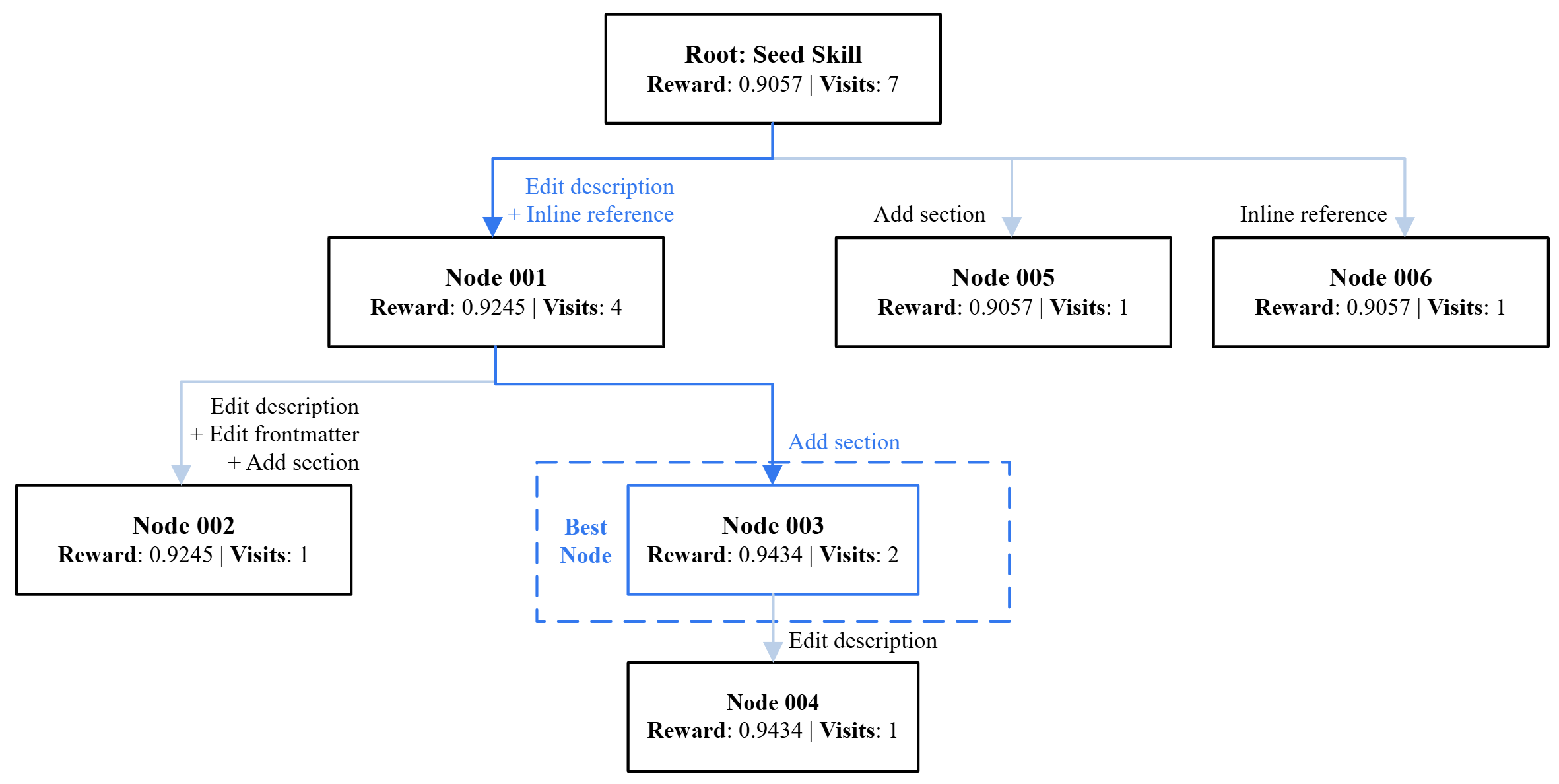
Figure 2: Illustration of MCTS search tree for Configuration B in the ORQA experiment. Nodes are labeled by the structure action and the resulting reward on search split. The winning path and selected node are highlighted in blue, while weaker alternatives are shown in a faded style.
LLM-Guided Operations
Both the structural search and content refinement procedures leverage LLMs (openai/gpt-5.4 for orchestration, openai/gpt-5.2-codex for runtime evaluation) as meta-reasoners. MCTS expansion and action proposals involve multi-stage LLM analysis, combining current structural state, search history, evaluation diagnostics, and domain-specific skill priors to guide edits. Similarly, content refinement routines use LLM generations to propose, compare, and select among content modifications.
Search Space Prioritization
An initial "comprehension" phase parses a seed skill, extracts its hierarchical structure, and builds a skill profile P, which specifies intended function, success criteria, promising revision axes, and a search prior Θ(P). This enables focused outer-loop search, reducing the otherwise intractable combinatorial burden.
Empirical Evaluation: Optimization on Operations Research QA
The framework is validated on the Operations Research Question Answering (ORQA) benchmark, which requires classifying and reasoning over complex optimization problems framed as MCQs. The seed skill is a two-file package created by an LLM-based skill generator, comprising a SKILL.md (instructions, frontmatter) and a separate reference file.
Experimental Protocol
The ORQA dataset is split into search, confirm, and test cohorts to enable optimization, model selection, and unbiased evaluation.
Two MCTS configurations are compared: a conservative (low-iteration, deterministic UCB1 selection) and an exploratory (high-iteration, mixed-probability with entropy regularization), each with different settings for convergence and admissible actions.
The experiment preserves fixed LLMs, agent settings, and token budgets per pipeline stage.
Quantitative Results
Local Maximum: Both configurations achieve a peak search split reward of θ0.
Confirm Split: Configuration B (exploratory) yields a higher confirmation mean score (θ1 versus θ2).
Held-Out Test Improvement: The baseline (seed) skill scores θ3 on test split; the optimized skill achieves θ4, for an absolute improvement of θ5.
This result reflects a statistically significant yet moderate improvement over the already strong baseline, demonstrating the practical value of structured skill optimization.
Qualitative Analysis
Structural modifications by the outer loop are synergistic with inner-loop content adjustment:
The winning skill consolidates essential reference guidance (e.g., question-type triage) from a separate file into SKILL.md, reducing fragmentation and improving agent access to crucial instructions.
New sections (explicit triage checklist) and frontmatter clarifications reduce ambiguity and support better error-checking.
Refined content imposes stricter output formatting and more explicit elimination heuristics, reducing agent confusion and improving answer reliability.
(Figure 2), which visualizes the MCTS search tree, shows that several branching strategies were considered and pruned, with the design converging on the structure-content configuration that maximized empirical downstream task performance.
Theoretical and Practical Implications
The methodology has several implications:
Generalizability: The bilevel decomposition applies to arbitrary agent skill definitions, orthogonal to the specific content language or task substrate.
Adaptability: The coupling of LLM-guided proposal and evaluation with MCTS enables dynamic exploration/exploitation scheduling, modulated for reward noise and search depth.
Skill Engineering as Discrete Optimization: The explicit handling of structure-content interdependence enables direct optimization of agent-level artifacts, which extends prior art in code-based workflow tuning and LLM tool selection.
Robustness: Conservative (pessimistic) return criteria for content refinement help control LLM stochasticity and evaluation noise—a significant challenge in artifact-level optimization.
Directions for Future Research
Potential future extensions include:
Integrating richer simulation optimization methods for reward estimation and uncertainty quantification, beyond basic lower confidence bounds.
Scaling to multi-agent, multi-skill settings, where dependencies and interoperability between skills must be optimized jointly.
Incorporating adversarial or safety-oriented constraints, especially in settings where security and malicious skill injection are concerns.
Leveraging active learning and meta-optimization over search priors, particularly as skill benchmarks (e.g., SkillsBench) are further developed.
Conclusion
This work provides a rigorous framework for LLM agent skill optimization, formulating the problem as a bilevel search over combinatorial structure spaces and high-dimensional content instantiations. By employing MCTS in the outer loop and LLM-guided, family-specific content refinement in the inner loop, the proposed method enables automated synthesis of high-quality, task-specialized skill packages. Empirical results on ORQA validate the efficacy of this approach, achieving measurable improvements over LLM-generated seed skills. The framework sets the stage for more principled, scalable agent skill engineering and has broad applicability across domains where LLM agents interact with structured artifact ecosystems.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.