How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
Abstract: Agent skills, which are reusable, domain-specific knowledge artifacts, have become a popular mechanism for extending LLM-based agents, yet formally benchmarking skill usage performance remains scarce. Existing skill benchmarking efforts focus on overly idealized conditions, where LLMs are directly provided with hand-crafted, narrowly-tailored task-specific skills for each task, whereas in many realistic settings, the LLM agent may have to search for and select relevant skills on its own, and even the closest matching skills may not be well-tailored for the task. In this paper, we conduct the first comprehensive study of skill utility under progressively challenging realistic settings, where agents must retrieve skills from a large collection of 34k real-world skills and may not have access to any hand-curated skills. Our findings reveal that the benefits of skills are fragile: performance gains degrade consistently as settings become more realistic, with pass rates approaching no-skill baselines in the most challenging scenarios. To narrow this gap, we study skill refinement strategies, including query-specific and query-agnostic approaches, and we show that query-specific refinement substantially recovers lost performance when the initial skills are of reasonable relevance and quality. We further demonstrate the generality of retrieval and refinement on Terminal-Bench 2.0, where they improve the pass rate of Claude Opus 4.6 from 57.7% to 65.5%. Our results, consistent across multiple models, highlight both the promise and the current limitations of skills for LLM-based agents. Our code is available at https://github.com/UCSB-NLP-Chang/Skill-Usage.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
Think of an AI “agent” as a very smart helper that can write code, use tools, and follow instructions. To make these helpers better at specific jobs (like data analysis or web dev), people give them “skills” — short, reusable how‑to guides with tips, code snippets, and best practices. This paper asks a simple question: do these skills actually help in the real world, where the agent has to find the right skills on its own?
The authors build a big library of 34,000 real skills and test how well different AI agents find and use them. They discover that skills help a lot under perfect conditions, but their benefits shrink when things get realistic. They also test ways to improve (refine) the skills so agents can use them better.
Key questions the paper tries to answer
- Do skills still help when an AI has to search a huge collection to find them (instead of being handed the perfect ones)?
- Can the AI pick the right skills from a mix of helpful and distracting ones?
- If the skills aren’t a perfect fit for the task, can the AI adapt them?
- Can “refining” the skills — either in general or tailored to a specific task — bring back the lost performance?
How the researchers studied it (in everyday language)
To make this easy to picture, think of three everyday steps:
- A giant library of “recipe cards” (skills): The team collected 34,000 real skill files from open-source projects. Each skill is like a recipe card with a name, description, and sometimes code examples.
- A search engine for skills: They built tools so the AI could look through this library. They tried different search styles:
- Keyword search: matches exact words (like typing “water level API”).
- Semantic search: matches meaning, even if the words differ (like a librarian who knows “river height” relates to “water level”).
- Hybrid + “agentic” search: the AI iteratively tries queries, checks results, and refines its search — similar to a student trying multiple Google searches and skimming the top links before deciding.
- Step-by-step testing from easy to realistic: They evaluated the same tasks under increasingly tough conditions:
- Best-case: give the AI hand-picked, task-specific skills and tell it to use them.
- Slightly harder: give the same skills but don’t force the AI to use them.
- Harder: mix in distracting, less relevant skills.
- Even harder: make the AI retrieve skills itself from the 34k library (sometimes the curated skills are still in the library, sometimes they’re removed).
- Hardest (no skills): give the AI no skills at all (a baseline to compare against).
They tracked:
- Pass rate: the percentage of tasks the AI solved.
- Skill usage: how often the AI actually loaded or used a skill.
- Retrieval quality: how often the correct skills show up in the top few search results (you can think of “Recall@5” as “did at least one correct skill show up in the first five results?”).
They tested multiple strong models and agent setups and also checked results on another benchmark, Terminal-Bench 2.0, which contains realistic command-line tasks and no hand-crafted skills.
Main findings and why they matter
Here are the key takeaways, explained simply:
- Skill benefits are fragile in the real world.
- When the AI is handed perfectly tailored skills and told to use them, it performs best.
- But if the AI has to choose which skills to use, or retrieve them from a big library, performance drops — sometimes close to the “no skills” baseline. In other words, the magic disappears when the conditions are less controlled.
- Two big problems hold skills back: 1) Selection: Even when good skills are available, AIs often fail to pick or load them. Adding distracting skills makes this worse. 2) Quality/adaptation: Skills found in a big, general library may not fit the task closely enough. They can be noisy, vague, or slightly off-topic. Using these can waste time or even mislead the agent.
- Smarter searching helps.
- Letting the agent run “agentic hybrid search” (try queries, check candidates, iterate) beats simple one-shot search. Semantic matching (matching meaning, not just words) is essential.
- Refining skills can recover performance — especially when the initial skills are somewhat relevant.
- Query-specific refinement (customizing and combining retrieved skills for the exact task at hand) helps a lot. It’s like tailoring a recipe to your kitchen and ingredients before cooking. This substantially boosted success in many cases.
- Query-agnostic refinement (cleaning up skills in general without knowing the task) helps a little but not nearly as much. It’s like making recipes clearer but not adapting them to tonight’s dinner.
- Important nuance: query-specific refinement works best when the initial skills are at least somewhat on-topic. If the retrieved skills are irrelevant, refinement can’t invent the missing knowledge from scratch.
- The approach generalizes beyond one benchmark.
- On Terminal-Bench 2.0 (a separate, realistic set of tasks), retrieving and then refining skills improved Claude Opus 4.6’s pass rate from 57.7% to 65.5%, which is a solid gain.
Why this matters: If we want AI agents to be truly useful day-to-day, they must find, judge, and adapt the right skills from large, messy libraries. This study shows what’s working, what’s not, and where to focus improvements.
What this means going forward (implications)
- Better search matters: We need smarter retrieval that finds not only keyword matches but also semantically relevant, high-quality skills — and helps the AI judge which ones to load.
- Skill quality and metadata count: Clearer, better organized skills (especially their titles and descriptions) make it easier for agents to recognize usefulness quickly.
- Task-aware refinement is powerful: Letting the AI examine the task and then reshape multiple skills into one tailored guide can noticeably boost performance.
- But refinement isn’t magic: If relevant skills don’t exist in the library, even the best refinement won’t help much. Growing better skill libraries — with broader coverage and higher quality — is essential.
- Practical takeaway: Skills are promising, but we can’t rely on hand-picked, task-specific “cheat sheets.” To make skills work “in the wild,” we need robust search, thoughtful curation, and smart, task-aware refinement.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it:
- Representativeness of the 34k-skill corpus: The collection is sourced from two aggregators and restricted to MIT/Apache licenses; its domain balance, language coverage, and real-world representativeness (e.g., enterprise workflows, data engineering pipelines, non-code tasks) are not quantified.
- Skill quality diagnostics at scale: Beyond basic filtering and content deduplication, there is no systematic assessment of skill quality (e.g., correctness, recency, maintainability), nor semantic deduplication or clustering to reduce redundancy and noise.
- Retrieval metrics breadth: Retrieval evaluation uses Recall@k against curated skills as “ground truth,” which may overfit to benchmark-specific artifacts; precision, nDCG/MRR, calibration, and harm-aware metrics (e.g., false-positive rate) are not reported.
- Sensitivity to k and context budget: The study largely fixes top-k=5; the trade-off between k, context window limits, and downstream performance/latency remains unexplored.
- Cost and latency of retrieval and refinement: The compute/time overhead of agentic hybrid search and query-specific refinement is not measured; no cost–performance frontier or budget-aware policies are proposed.
- Harness and prompting confounds: Differences in agent harnesses (e.g., Claude Code vs Terminus-2 vs Qwen-Code) materially affect skill loading, but prompt templates, tool APIs, and decision policies are not ablated or standardized.
- Why agents fail to load useful skills: The paper identifies low loading rates but does not provide a causal analysis (e.g., misinterpreted metadata, poor affordances, decision thresholds) or interventions (e.g., metadata redesign, routing rules, UI affordances).
- Robust gating to prevent negative transfer: Skills sometimes hurt performance (especially w/o curated); no gating, abstention, or benefit prediction mechanism is proposed to suppress harmful or low-utility skills at inference time.
- Generalization beyond two benchmarks: Evaluation focuses on SkillsBench and Terminal-Bench; applicability to other domains (web/GUI agents, data science notebooks, APIs, robotics, knowledge work) and multi-turn tasks remains untested.
- Multilingual and cross-domain retrieval: All experiments appear English-centric and code-heavy; robustness of skill retrieval/refinement across languages, domains, and mixed modalities is unknown.
- Security and trust of third‑party skills: Although related work notes risks, this study does not evaluate injection/malicious content, supply-chain integrity, or sandboxing/approval workflows for retrieved skills.
- Ground-truth definition for retrieval: Treating curated skills as ground truth can bias Recall@k and may not reflect the best possible non-curated alternatives; alternative relevance judgments (human or task outcome–based) are not used.
- Limited analysis of error modes: The paper reports pass rates and loading rates but lacks fine-grained failure taxonomies (e.g., retrieval miss vs wrong load vs misuse vs adaptation error), making targeted fixes harder.
- Lack of significance testing and variance reporting: With three runs per task, confidence intervals and statistical tests are not reported; sensitivity to seeds and run-to-run variance is unknown.
- Query-specific refinement reliability: The explore–self-evaluate loop sometimes degrades performance (e.g., Kimi on SkillsBench w/ curated); failure modes, verifier design, and mitigations (e.g., synthetic tests, consensus checking) are not studied.
- Query-agnostic refinement scalability: Only retrieved skills are refined per task due to cost; the feasibility, cost, and policy for offline refinement of an entire skill corpus (e.g., prioritization via active learning) remain open.
- Reusability vs overfitting of refined skills: Whether query-specific refined skills generalize to future tasks or overfit to the triggering task is not measured; no longitudinal reuse evaluation is provided.
- Composition algorithms for multi-skill synthesis: Query-specific refinement “merges” skills heuristically; principled methods (e.g., submodular coverage, graph planning, constraint-aware synthesis) are not explored.
- Alternative retrieval pipelines: Only BM25 + dense embeddings are tested; cross-encoder rerankers, LLM-as-judge reranking, multi-hop/attribute-aware retrieval, and learning-to-rank approaches are not evaluated.
- Metadata design and structure: The SKILL.md format’s metadata may be insufficient for routing; richer, machine-readable schemas (APIs, dependencies, preconditions, I/O, quality signals) are not examined.
- Dependency and version management: Skills can depend on specific library versions or tools; mechanisms for versioning, compatibility checks, and environment provisioning are not addressed.
- Detecting “no relevant skill” cases: When the corpus lacks relevant skills, agents perform near/below baseline; methods to detect this and fall back to alternative strategies (e.g., general web/doc retrieval or tool induction) are not implemented.
- Human evaluation and task realism: Outcome metrics are automated; human-in-the-loop assessments (usability, maintainability of outputs/skills) and studies on real user tasks/workflows are absent.
- Benchmark contamination and data leakage: It’s unknown whether skills encode solutions for benchmark tasks; contamination checks and safeguards are not documented.
- Lifecycle and continual evolution of skill libraries: The work does not study how to curate, retire, or evolve skills over time based on usage signals, success/failure logs, or versioned improvements.
- Safety and policy constraints in refinement: Refinement uses a proprietary meta-skill and proprietary models; reproducibility across open-weight models and adherence to safety policies are not evaluated.
- Coverage scoring with LLM judges: The coverage metric relies on an LLM judge without human validation; bias, reliability, and agreement with human ratings are not quantified.
- Comparison to non-skill baselines: The study does not compare skill-based augmentation to alternative knowledge tools (e.g., RAG over manuals/docs, code search, API schema retrieval) under matched budgets.
- Task/time efficiency metrics: Only pass rates and load rates are reported; time-to-solution, tool-call counts, and token/compute costs are not benchmarked, limiting practical deployment guidance.
- Robustness to noisy/long skills: Effects of skill length, verbosity, and noise on agent decision-making and context overflow are not systematically measured; summarization or chunking strategies are not assessed.
- Parameter and model scaling effects: The study uses three strong models; scaling laws (smaller models, distilled models) and how model capability interacts with skill utility/gating are not investigated.
- Non-code modalities and tools: Many practical skills involve images, GUIs, or external APIs; how the skill format and retrieval/refinement extend to multimodal tools is not explored.
- Public release stability: The dynamic nature of GitHub skills means corpora drift; snapshotting, versioned releases, and reproducibility of the 34k corpus over time are not detailed.
- Ethical and licensing scope: Excluding non-permissive licenses may skew toward certain communities; the impact of licensing constraints on skill diversity and performance is not analyzed.
Practical Applications
Immediate Applications
The following opportunities can be deployed with current agent platforms, retrieval tech, and the released code/skill corpus. They leverage the paper’s findings that agentic hybrid search improves recall, skill benefits are fragile under realistic conditions, and query-specific refinement recovers performance when relevant skills are retrieved.
- Intelligent skill search in agent platforms (Software/DevTools, SaaS)
- Integrate agentic hybrid search (semantic + keyword over metadata and full content) into IDEs, code assistants, and agent runtimes to fetch top‑k skills per task; expose “preview and score” loops so agents can iteratively refine queries.
- Potential product/workflow: “Skill Finder” widget in IDEs; API endpoint for agent orchestrators that returns ranked skills with relevance evidence.
- Assumptions/dependencies: Vector and BM25 indices; access to a skill corpus (internal or public); embedding model quality; cost budget for multi-step agentic search.
- On-demand query-specific skill refinement for critical tasks (Software engineering, DevOps, Data/ML ops)
- Add a pre-execution refinement pass where the agent tests and composes retrieved skills into a task-tailored skill before attempting the task, especially for hard tickets or CI-critical runs.
- Potential product/workflow: “Refine-before-run” toggle in agent pipelines; CI step that synthesizes a task-specific SKILL.md from retrieved skills.
- Assumptions/dependencies: Refinement compute budget; decent initial retrieval coverage (the paper shows refinement amplifies existing skill quality rather than inventing missing knowledge).
- Offline query-agnostic skill cleanup at ingestion (Agent marketplaces, Enterprise knowledge management)
- Apply low-cost, offline skill-creation/meta-skill pipelines (e.g., skill-creator) to normalize formatting, improve metadata clarity, and remove obvious noise for all newly submitted or updated skills.
- Potential product/workflow: Skill linting and “quality gate” on submission; scheduled batch cleanup for top N most-used skills.
- Assumptions/dependencies: No per-task context, so benefits are modest; requires automated scoring and human-in-the-loop for acceptance.
- Skill loading guardrails and fallbacks (Agent platforms, Risk/Compliance)
- Because irrelevant skills can hurt performance, add policies to suppress low-scoring skills, limit the number of loaded skills, or fall back to a no-skill baseline when retrieval confidence is low.
- Potential product/workflow: “Load only if predicted gain > threshold” policy; runtime toggles for forced load vs. autonomous selection; telemetry for load/use outcomes.
- Assumptions/dependencies: Confidence scoring from retrieval and/or a “coverage estimator”; harness support for load policies.
- Internal enterprise skill repositories with search and refinement (Industry IT, Data/Analytics teams)
- Convert SOPs, API playbooks, and internal runbooks into SKILL.md format; index them with agentic hybrid search; enable per-ticket query-specific refinement.
- Potential product/workflow: “Enterprise SkillHub” with governance and access control; incident-response agents that fetch runbook skills and refine them for the current outage.
- Assumptions/dependencies: Document-to-skill conversion workflows; permissioning and PII controls; alignment with internal coding conventions.
- Benchmarking and QA using progressive settings (Academia, Vendor evaluation, MLOps)
- Adopt the paper’s progressive evaluation (forced→curated→retrieved with/without curated→no skills) to diagnose retrieval vs. selection vs. adaptation gaps before production deployment.
- Potential product/workflow: A QA dashboard tracking pass rate, Recall@k, and “skill usage rate” across settings for each model/harness version.
- Assumptions/dependencies: Access to test tasks (e.g., SkillsBench, Terminal‑Bench) and the released evaluation harness; consistent agent runtime.
- Metadata improvement assistants for skill maintainers (Agent marketplaces, Open-source maintainers)
- Use agentic analysis of observed failures (e.g., not loaded when present) to auto-suggest better names, tags, and descriptions that increase selection probability.
- Potential product/workflow: “Metadata fixer” bot that proposes PRs; automated A/B tests showing increased load rates.
- Assumptions/dependencies: Telemetry on load decisions; content moderation to avoid misleading metadata.
- IDE and notebook integrations for skill retrieval (Software, Data Science)
- Provide contextual skill suggestions in editors (e.g., Jupyter, VS Code) tied to the current file or cell intent; allow one-click “refine+inject” of a synthesized skill.
- Potential product/workflow: Side panel showing top-5 skills with rationale and code snippets; cache of recently effective skills per project.
- Assumptions/dependencies: Local embeddings or cloud retrieval; minimal latency; developer consent and privacy constraints.
- Customer support and operations playbook automation (Customer service, ITSM)
- Treat procedural playbooks as skills; let agents retrieve and refine them for ticket-specific context, increasing first-contact resolution.
- Potential product/workflow: Ticket triage agent that loads 3–5 playbook skills and synthesizes a step-by-step resolution skill for the case.
- Assumptions/dependencies: Playbooks in structured text; safe execution policies; supervision for escalations.
- Procurement and risk checklists for third‑party skills (Policy, Vendor management)
- Update due-diligence templates to include: retrieval quality metrics (e.g., Recall@5), load/usage rates, guardrails to prevent degradation below no-skill baseline, and provenance/license filtering.
- Potential product/workflow: Vendor RFP requirements for skill ecosystems; acceptance criteria tied to “progressive gap” analysis.
- Assumptions/dependencies: Vendors expose metrics and audit logs; standard reporting formats.
- Reproducible research and teaching modules on agentic skills (Academia, Education)
- Use the released 34k-skill corpus and code to teach retrieval, selection, and refinement; replicate the degradation curves and run ablations in coursework.
- Potential product/workflow: Lab assignments on building hybrid search; projects on refinement strategies and their limits.
- Assumptions/dependencies: Compute credits for agentic search/refinement; course-safe datasets.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development. They build on the paper’s evidence that skill utility is sensitive to retrieval/selection quality and that task-aware refinement is most effective when relevant skills exist.
- Certified, rankable skill marketplaces with standardized quality signals (Software, Policy)
- Establish community or regulator-backed standards for skill metadata, test coverage, benchmarks, and security scanning; surface rank/quality scores in marketplaces.
- Potential product/workflow: “Skill Quality Index” and certification badges; discoverability boosted by task-level relevance and outcome telemetry.
- Assumptions/dependencies: Consensus on metrics (e.g., pass-rate under progressive settings), governance bodies, and submission pipelines.
- Adaptive skill loading policies learned per model/harness (Agent platforms, MLOps)
- Train policies that decide when to retrieve, how many skills to load, and when to refine based on model capability and task signals; personalize for different harness behaviors (paper shows harness affects loading).
- Potential product/workflow: Policy learners embedded in orchestrators that minimize “harmful load” events and cost.
- Assumptions/dependencies: Large-scale logs across tasks; offline RL or bandit frameworks; privacy/telemetry agreements.
- Sector-specific, governed skill corpora (Healthcare, Finance, Public sector)
- Curate compliant skill libraries (e.g., HIPAA, SOX) with provenance and versioning; layer query-specific refinement in a sandbox with auditable outputs.
- Potential product/workflow: EHR integration skills or KYC/AML procedure skills vetted by compliance; change-management workflow for updates.
- Assumptions/dependencies: Regulatory approval; domain experts in the loop; strong access controls and audit trails.
- Continuous self-improvement loops for skills (Enterprise knowledge, DevOps)
- Deploy pipelines that monitor usage/failures and automatically propose skill edits or merges; accept via human review.
- Potential product/workflow: “Skill Ops” platform that runs nightly refinement jobs using real task traces and updates a canary cohort.
- Assumptions/dependencies: Safe learning from production logs; rollback mechanisms; drift detection.
- Skill coverage and gain predictors in orchestrators (Cross-sector)
- Build predictors that estimate “coverage” of retrieved skills and expected gain vs. baseline; route tasks to retrieval+refinement only when payoff is likely.
- Potential product/workflow: Coverage Estimator microservice used to gate refinement; explainable signals (semantic diversity, overlap with task).
- Assumptions/dependencies: Labeled data or self-supervised proxies; calibration under dataset shift.
- Multi-skill composition and de-duplication at scale (Software, Research)
- Algorithms that detect complementary coverage across retrieved skills and synthesize minimal, coherent composites automatically.
- Potential product/workflow: “Skill composer” that outputs a single merged SKILL.md with deduplicated steps and consistent APIs.
- Assumptions/dependencies: Reliable content parsing; robust evaluation to avoid semantic drift; scalable synthesis.
- Security and provenance frameworks for third‑party skills (Security, Policy)
- Require signed skills, SBOM-like manifests for helper files, and sandboxed execution; integrate security findings into marketplace ranking.
- Potential product/workflow: Skill signing and verification service; static/dynamic analyzers tailored to SKILL.md ecosystems.
- Assumptions/dependencies: Key management infrastructure; standardized manifests; threat models for agent-executed artifacts.
- Consortium benchmarks and reporting for skills (Academia, Standards bodies)
- Extend progressive evaluation to cross-domain suites and mandate standardized reporting (pass rate, load rate, degradation vs. baseline).
- Potential product/workflow: Annual “Agent Skill Challenge” akin to MLPerf for agents; leaderboards stratified by setting.
- Assumptions/dependencies: Broad community adoption; funding for maintenance and compute.
- Robotics and embodied agents skill adaptation (Robotics, Manufacturing)
- Translate the retrieval+refinement paradigm to embodied skills (procedural steps, sensor-actuator patterns); robustly adapt general-purpose skills to novel tasks.
- Potential product/workflow: Robot skill libraries with hybrid search over task descriptors and telemetry; refinement via simulation before deployment.
- Assumptions/dependencies: High-fidelity simulators; safe sim-to-real transfer; richer skill schemas for embodiment.
- Grid and infrastructure operations assistants (Energy, Utilities)
- Encode operational runbooks and contingency procedures as skills; agents retrieve and refine during incidents with strict guardrails and human-in-the-loop approvals.
- Potential product/workflow: Control-room copilots that surface refined response steps under alarms; post-incident skill updates.
- Assumptions/dependencies: Safety cases; certified datasets; robust fallback to operator control.
- Financial operations and audit-friendly automations (Finance)
- Use certifiable skills with provenance for back-office processes; agents attach the refined skill artifact to each execution for audit.
- Potential product/workflow: “Executable procedures with attached SKILL.md” for reconciliations, reporting, and compliance checks.
- Assumptions/dependencies: End-to-end traceability; approval workflows; immutable logs.
- Education at scale with skill-centric curricula (Education)
- Courses where students build, retrieve, and refine skill libraries; evaluate with progressive settings to learn about robustness and generalization.
- Potential product/workflow: MOOC modules on building hybrid retrieval and task-aware refinement; peer-reviewed skill marketplaces for classes.
- Assumptions/dependencies: Accessible compute; pedagogical materials and rubrics; academic-safe corpora.
- Privacy-preserving, on-device personal skill curation (Consumer assistants)
- Local indexing and refinement of personal automations/scripts as skills; avoid sending sensitive data to cloud retrieval/refinement.
- Potential product/workflow: On-device “Personal Skill Vault” with periodic offline cleanups; selective sharing with signed exports.
- Assumptions/dependencies: Efficient on-device embeddings; storage and battery constraints; user consent UX.
- Cross-model compatibility layers for skills (Agent ecosystems)
- Normalize skill formats and metadata so different agent harnesses can load and benefit similarly despite different selection behaviors.
- Potential product/workflow: “Skill shim” libraries per harness; translation layers for tool invocation conventions.
- Assumptions/dependencies: Community schemas; backward compatibility; versioning discipline.
Glossary
- Agent harness: The runtime framework or tooling that wraps a model to provide agent capabilities (e.g., tools, execution, and interaction logic). "Each model is paired with its native agent harness:"
- Agent skills: Reusable, domain-specific knowledge artifacts designed to extend LLM-based agents’ capabilities. "Agent skills, which are reusable, domain-specific knowledge artifacts, have become a popular mechanism for extending LLM-based agents,"
- Agentic hybrid search: A retrieval strategy where an agent iteratively issues and refines queries using multiple signals (e.g., keyword and semantic) and evaluates candidates. "agentic hybrid search, where the agent iteratively formulates queries and evaluates candidate skills, significantly outperforms other approaches."
- Agentic search: An iterative, tool-using retrieval process in which the agent formulates queries, fetches candidates, and judges their relevance. "Agentic search: the agent is given access to search tools and iteratively formulates queries, retrieves candidates, and evaluates their relevance before selecting a final set of skills."
- Agentic skills: A standardized format of skills as file-system knowledge artifacts (e.g., SKILL.md plus helpers) for agents. "A standardized notion of agentic skills has been recently proposed: file-system-based knowledge artifacts consisting of a skill file (SKILL.md) with structured metadata and content,"
- BM25: A classic sparse term-based ranking function commonly used for keyword retrieval. "We use Qwen3-Embedding-4B for dense embeddings and BM25 for sparse keyword matching."
- Coverage scores: Judged measures of how well retrieved skills collectively cover the target task. "Average coverage scores of initially retrieved skills, judged by an LLM."
- Dense embeddings: Vector representations of text used for semantic similarity retrieval. "We use Qwen3-Embedding-4B for dense embeddings and BM25 for sparse keyword matching."
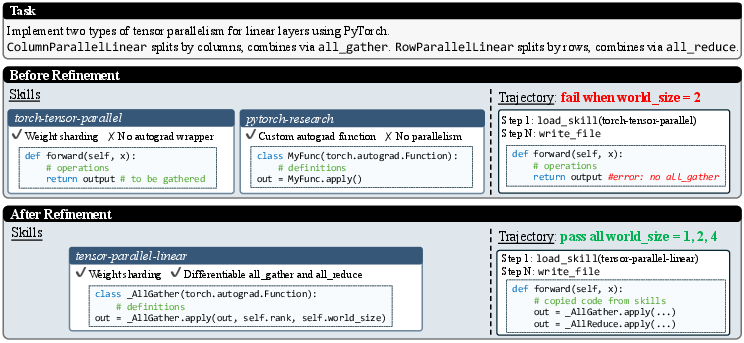
- Differentiable collective operations: Collective communication ops (e.g., all-reduce) implemented so gradients can flow through them for training. "synthesizing them into a single skill with differentiable collective operations that neither original skill provides on its own."
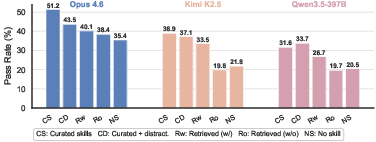
- Distractors: Irrelevant or less relevant skills added to the available set to make selection harder. "Curated + distractors: all curated skills remain available to the agent, but we add distracting skills retrieved via agentic search from the 34k collection"
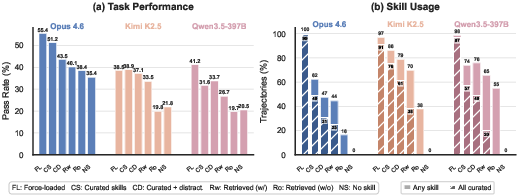
- Force-loading (skills): Mandating the agent to load specified skills, bypassing its own selection. "Force-loading curated skills yields 55.4% for Claude, but simply letting the agent decide which to load reduces this to 51.2%,"
- Full skill content (index): An index built over the entire SKILL.md content (not just metadata) used for retrieval scoring. "hybrid w/ content: same as \ding{174}, but similarity is a weighted average over both the metadata and full skill content indices."
- Ground-truth verifier: The authoritative checker (e.g., tests or oracle) used to determine correctness, withheld in some settings. "the agent does not have access to the ground-truth verifier"
- Hybrid search: A retrieval approach combining multiple signals (e.g., keyword and semantic) to rank skills. "including keyword, semantic, hybrid, and agentic search"
- Hybrid tool: A retrieval tool that fuses scores from different search methods. "a hybrid tool that combines their scores"
- LLM judge: An LLM used to assess or score the relevance/coverage/quality of retrieved skills. "we assess the relevance and coverage of the initially retrieved skills using an LLM judge (GPT-5.4)"
- Pass rate: The percentage of tasks completed successfully according to the benchmark’s verifier. "they improve the pass rate of Claude Opus 4.6 from 57.7% to 65.5%."
- Query-agnostic refinement: Offline improvement of skills without access to the specific downstream task. "query-agnostic refinement, where skills are improved offline without knowledge of the downstream task."
- Query-specific refinement: Task-aware improvement that explores the target query and adapts/merges retrieved skills accordingly. "query-specific refinement, where the agent explores and adapts retrieved skills to the target task,"
- Recall@: Retrieval metric measuring the fraction of relevant items appearing in the top k results. "We measure retrieval quality using Recall@: the fraction of ground-truth skills that appear in the top- retrieved results"
- Retrieval pool: The set of candidate skills searched over during retrieval. "The retrieval pool contains the curated skills among 34k total skills."
- Semantic search: Retrieval based on vector similarity of embeddings to capture meaning beyond exact keywords. "semantic: the agent has access to a dense embedding search tool only;"
- Semantic similarity: Similarity computed from meaning-aware representations (e.g., embeddings) rather than exact term overlap. "indicating that semantic similarity is essential for skill retrieval."
- SKILL.md: The canonical file in a skill that contains structured metadata and instructional content. "a skill file (SKILL.md) with structured metadata and content,"
- Skill adaptation: Adjusting or extracting useful parts from imperfectly matched, general-purpose skills for a given task. "Skill adaptation. When no skills have been specifically authored for the task at hand, the agent must work with retrieved skills that only partially align with the task requirements,"
- Skill index: The data structures (e.g., metadata and content indices) used to support skill retrieval. "Skill index. Each skill is indexed with two representations:"
- Skill metadata: Structured descriptive fields (e.g., name, description) used for indexing, retrieval, and loading decisions. "refining skill metadata may help agents better select which skills to load."
- Skill refinement: Processes that transform retrieved skills to improve their clarity, relevance, and utility. "we study skill refinement strategies"
- Skill retrieval: The process of searching a large skill collection to find relevant skills for a task. "A critical challenge in realistic skill usage is retrieving relevant skills from a large collection."
- Skill selection: Choosing which among available or retrieved skills to actually load and use. "Skill selection. Even when relevant skills are provided to the agent, it must correctly identify which ones are useful and decide to load them,"
- Sparse keyword matching: Retrieval based on exact or weighted keyword overlap (e.g., BM25). "BM25 for sparse keyword matching."
- Tensor parallelism: Splitting neural network tensors across multiple devices/processes to enable parallel computation. "a Terminal-Bench 2.0 tensor parallelism task."
- Top- retrieval: Returning only the top k ranked items from a retrieval system. "the top- retrieved results"
Collections
Sign up for free to add this paper to one or more collections.