- The paper demonstrates that diffusion language models, MDLM and USDM, improve ASR by enabling bidirectional, non-autoregressive decoding.
- It introduces normalization techniques that reduce WER, notably lowering MDLM's error from 5.08% to 4.52% in hypothesis rescoring.
- The joint CTC-USDM decoding framework combines acoustic and language probabilities to effectively overcome traditional decoding bottlenecks.
Diffusion LLMs for ASR: A Comprehensive Technical Analysis
Context and Motivation
The presented study investigates the use of discrete diffusion LLMs (DiffLMs) as standalone components for automatic speech recognition (ASR), focusing on two variants: Masked Diffusion LLMs (MDLM) and Uniform-State Diffusion Models (USDM). Traditional autoregressive LLMs constrain joint decoding to left-to-right sequential operations, limiting parallelism and speed. The introduction of DiffLMs enables bidirectional attention and parallel text generation, and their non-autoregressive nature sidesteps inherent bottlenecks in standard language modeling for ASR. Prior studies have explored diffusion models conditioned on audio or as decoders for speech recognition; this paper advances the field by directly integrating DiffLMs into ASR for hypothesis rescoring and proposes a novel joint CTC-USDM decoding framework.
Diffusion LLM Architectures
Masked Diffusion LLM (MDLM)
MDLM applies token-level corruption through masking, governed by a monotonically decreasing noise schedule. For each token, with probability 1−αt, masking occurs, progressively leading to a sequence that is fully masked at the final diffusion step. The reverse process reconstructs the original text via cross-entropy minimization on the masked positions. The explicit mask token serves as a reconstruction signal, facilitating model training and efficient context recovery.
USDM corrupts tokens by replacing each with a random sample from the vocabulary, devoid of mask tokens. The forward process produces a marginal distribution blending the original token with uniform noise. The reverse process must update every position at all steps—enabling self-correction and dense, full-vocabulary outputs. This allows USDM to directly align with the frame-level probabilities from CTC during ASR decoding and provides a structurally richer context than MDLM.
Joint CTC-USDM Decoding Framework
A novel joint-decoding method is proposed, integrating framewise probability distributions from CTC and token-level distributions from USDM at each denoising step. This synergy leverages strong language priors from USDM alongside acoustic evidence from CTC, producing hypotheses that are continuously refined and informed by both modalities. The token-level USDM provides flexibility for ancestral sampling, enhancing the search for optimal transcriptions.
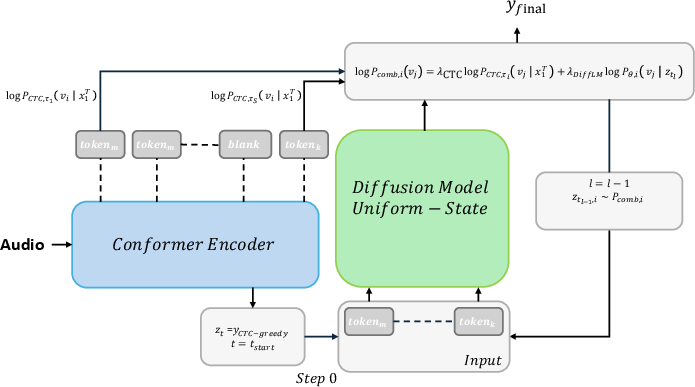
Figure 1: Overview of the proposed joint CTC-USDM decoding. The USDM token-level distribution and CTC frame-level distribution are combined at each denoising step.
Rescoring Strategies and Technical Contributions
The authors address key issues in DiffLM-based rescoring, notably the bias introduced by sequence-length normalization that overweights heavily corrupted samples. They propose:
- Sample-level mask normalization: Normalize each sample by its own mask count before averaging, mitigating domination by heavily masked cases.
- Global mask normalization: Pool all masked predictions across samples, dividing by the total mask count to ensure equitable token contribution.
- Coupled scoring: Inspired by coupled-sampling schemes, ensures every token is masked exactly once across paired forward passes, guaranteeing balanced scoring.
Additionally, for USDM, the evidence lower bound (ELBO) is applied as the scoring objective, leveraging uniform corruption and dense token participation.
Experimental Setup
DiffLMs (MDLM and USDM) are trained on LibriSpeech LM data and train-other transcriptions, employing a 24-layer Diffusion Transformer (DiT) for the primary model and SentencePiece tokenization. Experiments vary diffusion epochs, normalization strategies, and sampling parameters.
LLM Training:
MDLM achieves lower perplexity at early training epochs, but USDM overtakes at higher epochs, indicating superior long-term scaling for USDM under uniform noise corruption.
Rescoring Performance:
MDLM, using proposed normalization, reduces WER from a CTC baseline of 5.08% to 4.52% at 25 epochs. USDM rescoring yields improved WER but remains inferior to MDLM (down to 4.80% with extended training).
Joint Decoding:
CTC-USDM joint decoding surpasses USDM rescoring, reaching 4.71% WER at 25 epochs. Optimal results are achieved with careful tuning of the initial diffusion noise level and denoising steps.
Comparison with Autoregressive LMs:
Autoregressive LMs achieve lowest WERs (3.86% in joint decoding) but show less favorable scaling with increased model capacity, whereas MDLM benefits substantially from scaling. USDM’s performance in joint decoding approaches that of MDLM, but does not close the gap with autoregressive models.
Analysis of Scaling, Claims, and Implications
- Strong empirical claim: MDLM and USDM considerably improve ASR accuracy over CTC-only baselines, with MDLM outperforming USDM in rescoring, mainly due to explicit masking facilitating context recovery.
- Contradictory scaling claim: Increasing model capacity degrades the rescoring performance of autoregressive LMs but improves it for MDLM, suggesting DiffLMs benefit from deeper architectures and larger model sizes.
- Theoretical implications: USDM’s full-vocabulary probability outputs and self-correcting nature offer a promising direction for joint language-acoustic modeling. However, their more complex objective increases data and computational requirements, with MDLM’s explicit masking delivering superior performance on limited data.
- Practical implications: DiffLMs open avenues for faster and more parallel ASR decoding, albeit current autoregressive LMs maintain a performance lead. DiffLMs are suited to future architectures where parallelism, bidirectional attention, and data scaling can be leveraged.
Future Directions
The study suggests further scaling of DiffLMs and USDM, assessment on larger ASR datasets, and extension of the joint decoding framework to MDLM. Increased data and model sizes are expected to close the performance gap with autoregressive models.
Conclusion
This work rigorously demonstrates the utility of discrete diffusion LLMs for ASR. MDLMs and USDMs both offer significant gains in hypothesis rescoring and joint decoding, especially when paired with normalization strategies tailored to diffusion-style corruption. CTC-USDM joint decoding leverages dense, self-correcting distributions for hypothesis refinement, approaching—but not surpassing—autoregressive LMs in WER. The authors’ methodological advances provide a foundation for scaling diffusion LMs in speech recognition, highlighting both the flexibility and current limitations of non-autoregressive paradigms. Future lines of investigation include expanded dataset evaluation, further model scaling, and more advanced joint decoding mechanisms.